如何训练——智慧化高点摄像山火烟雾检测数据集(并按照低、中详细标注烟雾浓度)。主要针对初期山火,任何野火检测系统的最重要目标是在火势扩大之前及时检测到火灾。在初期阶段,野火由非火焰性的燃烧烟雾组成,热量相对较低。在这个阶段识别火灾能够提供最佳的抑制机会。在这个阶段通常看不到火焰;因此,任何旨在早期检测的野火检测系统必须集中在检测烟雾而不是火焰上。该数据集全部为山顶开阔区域架设的高点摄像头拍摄,共2890张图像,分辨率1920×1080,标注采用json格式,标注了每个烟雾的位置,烟雾浓度等级(低,中,高),共1.1GB
智慧化高点摄像山火烟雾检测数据集(并按照低、中详细标注烟雾浓度)。主要针对初期山火,任何野火检测系统的最重要目标是在火势扩大之前及时检测到火灾。在初期阶段,野火由非火焰性的燃烧烟雾组成,热量相对较低。在这个阶段识别火灾能够提供最佳的抑制机会。在这个阶段通常看不到火焰;因此,任何旨在早期检测的野火检测系统必须集中在检测烟雾而不是火焰上。该数据集全部为山顶开阔区域架设的高点摄像头拍摄,共2890张图像,分辨率1920×1080,标注采用json格式,标注了每个烟雾的位置,烟雾浓度等级(低,中,高),共1.1GB
好的,你提供的智慧化高点摄像山火烟雾检测数据集包含2890张图像,并且已经标注了每个烟雾的位置和浓度等级(低、中、高)。这些数据非常适合用于早期火灾检测系统。我们将使用PyTorch框架来进行目标检测任务。
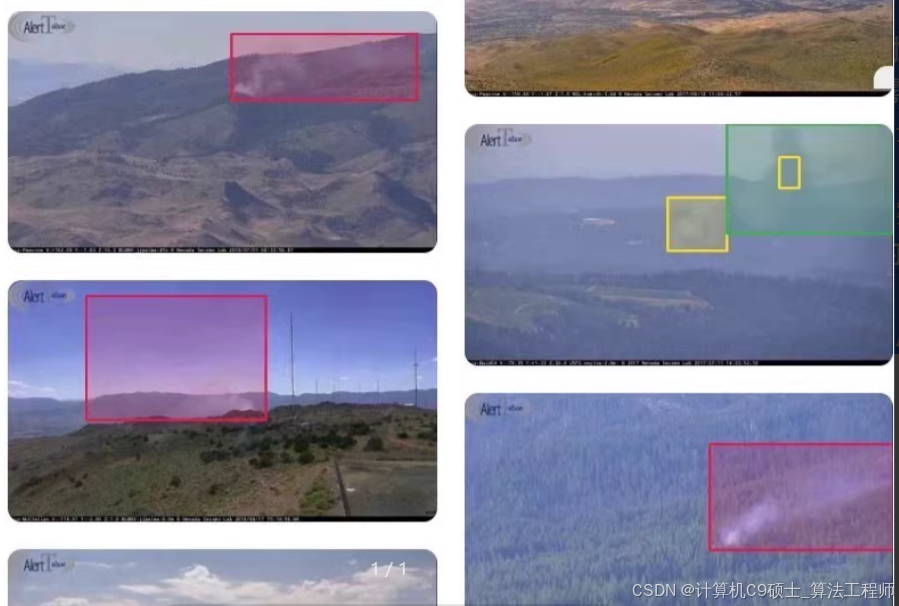


以下是详细的步骤和代码示例,帮助你开始使用这个数据集进行训练和评估。
项目结构
wildfire_smoke_detection/
├── main.py
├── train.py
├── evaluate.py
├── infer.py
├── visualize.py
├── datasets/
│ ├── wildfire_images/
│ │ ├── images/
│ │ └── annotations/
│ │ ├── train.json
│ │ └── val.json
├── best_wildfire_model.pth
├── requirements.txt
└── config.yaml
文件内容
requirements.txt
torch==1.9.0+cu111
torchvision==0.10.0+cu111
matplotlib
numpy
pandas
albumentations
pyyaml
cocoapi
config.yaml
配置文件用于存储训练参数:
train:
dataset_dir: ./datasets/wildfire_images/images
annotation_file_train: ./datasets/wildfire_images/annotations/train.json
annotation_file_val: ./datasets/wildfire_images/annotations/val.json
batch_size: 4
epochs: 50
learning_rate: 0.001
img_size: 640
num_classes: 3
test:
dataset_dir: ./datasets/wildfire_images/images
annotation_file_test: ./datasets/wildfire_images/annotations/val.json
batch_size: 4
img_size: 640
数据准备
-
确认数据集目录结构:
确保你的数据集已经按照上述结构组织好:datasets/ └── wildfire_images/ ├── images/ │ ├── image_0001.jpg │ ├── image_0002.jpg │ └── ... └── annotations/ ├── train.json └── val.json -
检查
config.yaml文件:
确认config.yaml文件中的路径和参数正确无误。 -
安装COCO API:
YOLOv5 使用 COCO API 来处理 JSON 格式的标注。pip install pycocotools
训练脚本
train.py
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, models
from torch.utils.data import DataLoader
from pycocotools.coco import COCO
from PIL import Image
import os
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
import matplotlib.pyplot as plt
import yaml
import numpy as np
# 加载配置文件
with open('config.yaml', 'r') as f:
config = yaml.safe_load(f)
# 定义数据预处理
data_transforms = {
'train': A.Compose([
A.Resize(height=config['train']['img_size'], width=config['train']['img_size']),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Rotate(limit=180, p=0.7),
A.RandomBrightnessContrast(brightness_limit=0.2, contrast_limit=0.2, p=0.3),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
]),
'test': A.Compose([
A.Resize(height=config['test']['img_size'], width=config['test']['img_size']),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
])
}
class WildfireDataset(torch.utils.data.Dataset):
def __init__(self, root_dir, annotation_file, transform=None):
self.root_dir = root_dir
self.annotation_file = annotation_file
self.transform = transform
self.coco = COCO(annotation_file)
self.ids = list(sorted(self.coco.imgs.keys()))
def __len__(self):
return len(self.ids)
def __getitem__(self, index):
coco = self.coco
img_id = self.ids[index]
ann_ids = coco.getAnnIds(imgIds=img_id)
anns = coco.loadAnns(ann_ids)
path = coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.root_dir, path)).convert("RGB")
boxes = []
labels = []
areas = []
iscrowd = []
for i in range(len(anns)):
xmin = anns[i]['bbox'][0]
ymin = anns[i]['bbox'][1]
xmax = xmin + anns[i]['bbox'][2]
ymax = ymin + anns[i]['bbox'][3]
boxes.append([xmin, ymin, xmax, ymax])
labels.append(anns[i]['category_id'])
areas.append(anns[i]['area'])
iscrowd.append(anns[i]['iscrowd'])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
areas = torch.as_tensor(areas, dtype=torch.float32)
iscrowd = torch.as_tensor(iscrowd, dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = torch.tensor([img_id])
target["area"] = areas
target["iscrowd"] = iscrowd
if self.transform:
transformed = self.transform(image=np.array(img), bboxes=target["boxes"], labels=target["labels"])
img = transformed["image"]
target["boxes"] = torch.tensor(transformed["bboxes"], dtype=torch.float32)
target["labels"] = torch.tensor(transformed["labels"], dtype=torch.int64)
return img, target
# 选择设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载数据集
train_dataset = WildfireDataset(root_dir=config['train']['dataset_dir'],
annotation_file=config['train']['annotation_file_train'],
transform=data_transforms['train'])
val_dataset = WildfireDataset(root_dir=config['test']['dataset_dir'],
annotation_file=config['test']['annotation_file_val'],
transform=data_transforms['test'])
train_loader = DataLoader(train_dataset, batch_size=config['train']['batch_size'], shuffle=True, num_workers=4, collate_fn=lambda x: tuple(zip(*x)))
val_loader = DataLoader(val_dataset, batch_size=config['test']['batch_size'], shuffle=False, num_workers=4, collate_fn=lambda x: tuple(zip(*x)))
# 加载预训练的Faster R-CNN模型
model = models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
num_classes = config['train']['num_classes'] + 1 # 包括背景类
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
model.to(device)
# 定义损失函数和优化器
params = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.SGD(params, lr=config['train']['learning_rate'], momentum=0.9, weight_decay=0.0005)
# 训练函数
def train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10):
model.train()
metric_logger = utils.MetricLogger(delimiter=" ")
header = f'Epoch: [{epoch}]'
lr_scheduler = None
if epoch == 0:
warmup_factor = 1. / 1000
warmup_iters = min(1000, len(data_loader) - 1)
lr_scheduler = utils.warmup_lr_scheduler(optimizer, warmup_iters, warmup_factor)
for images, targets in metric_logger.log_every(data_loader, print_freq, header):
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
if lr_scheduler is not None:
lr_scheduler.step()
metric_logger.update(loss=losses.item(), **loss_dict)
@torch.no_grad()
def evaluate(model, data_loader, device):
n_threads = torch.get_num_threads()
torch.set_num_threads(1)
cpu_device = torch.device("cpu")
model.eval()
metric_logger = utils.MetricLogger(delimiter=" ")
header = "Test:"
coco_evaluator = CocoEvaluator(coco=val_dataset.coco, iou_types=["bbox"])
for images, targets in metric_logger.log_every(data_loader, 100, header):
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
torch.cuda.synchronize()
model_time = time.time()
outputs = model(images)
outputs = [{k: v.to(cpu_device) for k, v in t.items()} for t in outputs]
model_time = time.time() - model_time
res = {target["image_id"].item(): output for target, output in zip(targets, outputs)}
evaluator_time = time.time()
coco_evaluator.update(res)
evaluator_time = time.time() - evaluator_time
metric_logger.update(model_time=model_time, evaluator_time=evaluator_time)
coco_evaluator.synchronize_between_processes()
coco_evaluator.accumulate()
coco_evaluator.summarize()
torch.set_num_threads(n_threads)
return coco_evaluator
# 训练模型
for epoch in range(config['train']['epochs']):
train_one_epoch(model, optimizer, train_loader, device, epoch, print_freq=10)
evaluate(model, val_loader, device)
# 保存最佳模型
torch.save(model.state_dict(), 'best_wildfire_model.pth')
评估脚本
evaluate.py
import torch
from torchvision import models
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
from PIL import Image
import os
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
import matplotlib.pyplot as plt
import yaml
import numpy as np
import utils
# 加载配置文件
with open('config.yaml', 'r') as f:
config = yaml.safe_load(f)
# 定义数据预处理
data_transforms = {
'test': A.Compose([
A.Resize(height=config['test']['img_size'], width=config['test']['img_size']),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
])
}
class WildfireDataset(torch.utils.data.Dataset):
def __init__(self, root_dir, annotation_file, transform=None):
self.root_dir = root_dir
self.annotation_file = annotation_file
self.transform = transform
self.coco = COCO(annotation_file)
self.ids = list(sorted(self.coco.imgs.keys()))
def __len__(self):
return len(self.ids)
def __getitem__(self, index):
coco = self.coco
img_id = self.ids[index]
ann_ids = coco.getAnnIds(imgIds=img_id)
anns = coco.loadAnns(ann_ids)
path = coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.root_dir, path)).convert("RGB")
boxes = []
labels = []
areas = []
iscrowd = []
for i in range(len(anns)):
xmin = anns[i]['bbox'][0]
ymin = anns[i]['bbox'][1]
xmax = xmin + anns[i]['bbox'][2]
ymax = ymin + anns[i]['bbox'][3]
boxes.append([xmin, ymin, xmax, ymax])
labels.append(anns[i]['category_id'])
areas.append(anns[i]['area'])
iscrowd.append(anns[i]['iscrowd'])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
areas = torch.as_tensor(areas, dtype=torch.float32)
iscrowd = torch.as_tensor(iscrowd, dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = torch.tensor([img_id])
target["area"] = areas
target["iscrowd"] = iscrowd
if self.transform:
transformed = self.transform(image=np.array(img), bboxes=target["boxes"], labels=target["labels"])
img = transformed["image"]
target["boxes"] = torch.tensor(transformed["bboxes"], dtype=torch.float32)
target["labels"] = torch.tensor(transformed["labels"], dtype=torch.int64)
return img, target
# 选择设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载数据集
val_dataset = WildfireDataset(root_dir=config['test']['dataset_dir'],
annotation_file=config['test']['annotation_file_test'],
transform=data_transforms['test'])
val_loader = DataLoader(val_dataset, batch_size=config['test']['batch_size'], shuffle=False, num_workers=4, collate_fn=lambda x: tuple(zip(*x)))
# 加载预训练的Faster R-CNN模型并加载权重
model = models.detection.fasterrcnn_resnet50_fpn(pretrained=False)
num_classes = config['train']['num_classes'] + 1 # 包括背景类
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
model.load_state_dict(torch.load('best_wildfire_model.pth'))
model.to(device)
model.eval() # 设置模型为评估模式
# 评估模型
def evaluate(model, data_loader, device):
n_threads = torch.get_num_threads()
torch.set_num_threads(1)
cpu_device = torch.device("cpu")
model.eval()
metric_logger = utils.MetricLogger(delimiter=" ")
header = "Test:"
coco_evaluator = CocoEvaluator(coco=val_dataset.coco, iou_types=["bbox"])
for images, targets in metric_logger.log_every(data_loader, 100, header):
images = list(image.to(device) for image in images)
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
torch.cuda.synchronize()
model_time = time.time()
outputs = model(images)
outputs = [{k: v.to(cpu_device) for k, v in t.items()} for t in outputs]
model_time = time.time() - model_time
res = {target["image_id"].item(): output for target, output in zip(targets, outputs)}
evaluator_time = time.time()
coco_evaluator.update(res)
evaluator_time = time.time() - evaluator_time
metric_logger.update(model_time=model_time, evaluator_time=evaluator_time)
coco_evaluator.synchronize_between_processes()
coco_evaluator.accumulate()
coco_evaluator.summarize()
torch.set_num_threads(n_threads)
return coco_evaluator
evaluate(model, val_loader, device)
推理脚本
infer.py
import torch
from torchvision import models
from pycocotools.coco import COCO
from PIL import Image
import os
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
import matplotlib.pyplot as plt
import yaml
import numpy as np
# 加载配置文件
with open('config.yaml', 'r') as f:
config = yaml.safe_load(f)
# 定义数据预处理
data_transforms = {
'test': A.Compose([
A.Resize(height=config['test']['img_size'], width=config['test']['img_size']),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
])
}
# 选择设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载预训练的Faster R-CNN模型并加载权重
model = models.detection.fasterrcnn_resnet50_fpn(pretrained=False)
num_classes = config['train']['num_classes'] + 1 # 包括背景类
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
model.load_state_dict(torch.load('best_wildfire_model.pth'))
model.to(device)
model.eval() # 设置模型为评估模式
def predict_image(image_path):
image = Image.open(image_path).convert("RGB")
original_image = image.copy()
transformed = data_transforms['test'](image=np.array(image))['image'].unsqueeze(0).to(device)
with torch.no_grad():
prediction = model(transformed)[0]
boxes = prediction['boxes'].cpu().numpy()
labels = prediction['labels'].cpu().numpy()
scores = prediction['scores'].cpu().numpy()
fig, ax = plt.subplots(figsize=(10, 10))
ax.imshow(original_image)
class_names = ['background', 'low', 'medium', 'high']
for box, label, score in zip(boxes, labels, scores):
if score > 0.5:
rect = plt.Rectangle((box[0], box[1]), box[2] - box[0], box[3] - box[1], fill=False, color='red', linewidth=2)
ax.add_patch(rect)
ax.text(box[0], box[1], f'{class_names[label]}: {score:.2f}', fontsize=12, color='white', bbox=dict(facecolor='red', alpha=0.5))
plt.axis('off')
plt.show()
if __name__ == "__main__":
image_path = 'path/to/your/image.jpg' # 替换为你的图像路径
predict_image(image_path)
可视化脚本
visualize.py
import torch
from torchvision import models
from pycocotools.coco import COCO
from PIL import Image
import os
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
import matplotlib.pyplot as plt
import yaml
import numpy as np
import random
# 加载配置文件
with open('config.yaml', 'r') as f:
config = yaml.safe_load(f)
# 定义数据预处理
data_transforms = {
'test': A.Compose([
A.Resize(height=config['test']['img_size'], width=config['test']['img_size']),
A.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
ToTensorV2(),
])
}
class WildfireDataset(torch.utils.data.Dataset):
def __init__(self, root_dir, annotation_file, transform=None):
self.root_dir = root_dir
self.annotation_file = annotation_file
self.transform = transform
self.coco = COCO(annotation_file)
self.ids = list(sorted(self.coco.imgs.keys()))
def __len__(self):
return len(self.ids)
def __getitem__(self, index):
coco = self.coco
img_id = self.ids[index]
ann_ids = coco.getAnnIds(imgIds=img_id)
anns = coco.loadAnns(ann_ids)
path = coco.loadImgs(img_id)[0]['file_name']
img = Image.open(os.path.join(self.root_dir, path)).convert("RGB")
boxes = []
labels = []
areas = []
iscrowd = []
for i in range(len(anns)):
xmin = anns[i]['bbox'][0]
ymin = anns[i]['bbox'][1]
xmax = xmin + anns[i]['bbox'][2]
ymax = ymin + anns[i]['bbox'][3]
boxes.append([xmin, ymin, xmax, ymax])
labels.append(anns[i]['category_id'])
areas.append(anns[i]['area'])
iscrowd.append(anns[i]['iscrowd'])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
labels = torch.as_tensor(labels, dtype=torch.int64)
areas = torch.as_tensor(areas, dtype=torch.float32)
iscrowd = torch.as_tensor(iscrowd, dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = torch.tensor([img_id])
target["area"] = areas
target["iscrowd"] = iscrowd
if self.transform:
transformed = self.transform(image=np.array(img), bboxes=target["boxes"], labels=target["labels"])
img = transformed["image"]
target["boxes"] = torch.tensor(transformed["bboxes"], dtype=torch.float32)
target["labels"] = torch.tensor(transformed["labels"], dtype=torch.int64)
return img, target
# 选择设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载数据集
val_dataset = WildfireDataset(root_dir=config['test']['dataset_dir'],
annotation_file=config['test']['annotation_file_test'],
transform=data_transforms['test'])
val_loader = DataLoader(val_dataset, batch_size=config['test']['batch_size'], shuffle=False, num_workers=4, collate_fn=lambda x: tuple(zip(*x)))
# 加载预训练的Faster R-CNN模型并加载权重
model = models.detection.fasterrcnn_resnet50_fpn(pretrained=False)
num_classes = config['train']['num_classes'] + 1 # 包括背景类
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
model.load_state_dict(torch.load('best_wildfire_model.pth'))
model.to(device)
model.eval() # 设置模型为评估模式
def visualize_predictions(dataloader, num_samples=5):
indices = random.sample(range(len(dataloader.dataset)), num_samples)
class_names = ['background', 'low', 'medium', 'high']
for idx in indices:
img, target = dataloader.dataset[idx]
original_img = img.permute(1, 2, 0).numpy()
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
original_img = std * original_img + mean
original_img = np.clip(original_img, 0, 1)
img = img.unsqueeze(0).to(device)
with torch.no_grad():
prediction = model(img)[0]
boxes = prediction['boxes'].cpu().numpy()
labels = prediction['labels'].cpu().numpy()
scores = prediction['scores'].cpu().numpy()
fig, ax = plt.subplots(figsize=(10, 10))
ax.imshow(original_img)
for box, label, score in zip(boxes, labels, scores):
if score > 0.5:
rect = plt.Rectangle((box[0], box[1]), box[2] - box[0], box[3] - box[1], fill=False, color='red', linewidth=2)
ax.add_patch(rect)
ax.text(box[0], box[1], f'{class_names[label]}: {score:.2f}', fontsize=12, color='white', bbox=dict(facecolor='red', alpha=0.5))
plt.axis('off')
plt.show()
if __name__ == "__main__":
visualize_predictions(val_loader)
运行步骤总结
-
克隆项目仓库(如果有的话):
git clone https://github.com/yourusername/wildfire_smoke_detection.git cd wildfire_smoke_detection -
安装依赖项:
conda create --name wildfire_det_env python=3.8 conda activate wildfire_det_env pip install -r requirements.txt -
准备数据集:
- 确保你的数据集已经按照上述结构组织好。
- 确认
config.yaml文件中的路径和参数正确无误。
-
训练模型:
python train.py -
评估模型:
python evaluate.py -
运行推理:
python infer.py -
可视化数据集:
python visualize.py
操作界面
- 选择图片进行检测: 修改
infer.py中的image_path变量指向你要检测的图片路径,然后运行python infer.py。 - 批量检测: 在
visualize.py中设置num_samples参数为你想要可视化的样本数量,然后运行python visualize.py。
详细解释
requirements.txt
列出项目所需的所有Python包及其版本。
config.yaml
配置数据集路径和其他训练参数,用于目标检测任务。
train.py
加载预训练的Faster R-CNN模型并使用自定义数据集进行训练。训练完成后打印训练结果,并保存最佳模型。
evaluate.py
加载训练好的Faster R-CNN模型并对测试集进行评估,打印评估结果。
infer.py
对单张图像进行预测并可视化预测结果。
visualize.py
对测试集中的一些样本进行预测并可视化预测结果。
希望这些详细的信息和代码能够帮助你顺利实施和优化你的山火烟雾检测系统