基于PyTorch框架实现,展示如何使用ResNet50进行特征提取,并结合MMD用于领域适应,迁移学习在轴承故障诊断中的应用_迁移学习轴承诊断DAN:ResNet50-MMD
以下文字及代码仅供参考。
附说明:、pytorch版本,
ResNet50进行特征提取,mmd最大均值误差进行域适应
可以换自己的数据集,只需改文件名即可,数据集必须转化为二维图像.
迁移学习在轴承故障诊断中的应用非常广泛,尤其是当你想要利用预训练的模型(如ResNet50)进行特征提取,并通过域适应技术(如最大均值差异,MMD)来缩小源域和目标域之间的分布差距。下面我将提供一个基于PyTorch框架实现的示例代码,展示如何使用ResNet50进行特征提取,并结合MMD用于领域适应。
1. 环境准备
首先,确保你的环境中安装了必要的库:
pip install torch torchvision numpy matplotlib
2. 数据准备
假设你已经有两个数据集:一个是源域数据集,另一个是目标域数据集。这两个数据集都需要转化为二维图像格式,并且放在不同的文件夹中。
3. 模型定义
我们将使用预训练的ResNet50作为基础网络进行特征提取,并在其基础上添加一个全连接层以适配分类任务。同时,我们定义一个函数来计算MMD。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms, datasets
import numpy as np
class FeatureExtractor(nn.Module):
def __init__(self):
super(FeatureExtractor, self).__init__()
resnet = models.resnet50(pretrained=True)
self.feature_extractor = nn.Sequential(*list(resnet.children())[:-1])
def forward(self, x):
return self.feature_extractor(x).view(x.size(0), -1)
def mmd_linear(f_of_X, f_of_Y):
delta = f_of_X - f_of_Y
loss = torch.mean(torch.mm(delta, torch.transpose(delta, 0, 1)))
return loss
class Classifier(nn.Module):
def __init__(self, num_classes=10):
super(Classifier, self).__init__()
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
return self.fc(x)
# 加载数据集
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
source_dataset = datasets.ImageFolder('path_to_source_data', transform=transform)
target_dataset = datasets.ImageFolder('path_to_target_data', transform=transform)
source_loader = torch.utils.data.DataLoader(source_dataset, batch_size=32, shuffle=True)
target_loader = torch.utils.data.DataLoader(target_dataset, batch_size=32, shuffle=True)
feature_extractor = FeatureExtractor()
classifier = Classifier(num_classes=len(source_dataset.classes))
4. 训练过程
接下来,我们定义训练过程,包括特征提取、分类损失以及MMD损失的计算。
optimizer = optim.Adam(list(feature_extractor.parameters()) + list(classifier.parameters()), lr=0.001)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
feature_extractor.train()
classifier.train()
for (source_data, source_labels), (target_data, _) in zip(source_loader, target_loader):
source_data, source_labels = source_data.cuda(), source_labels.cuda()
target_data = target_data.cuda()
optimizer.zero_grad()
source_features = feature_extractor(source_data)
target_features = feature_extractor(target_data)
mmd_loss = mmd_linear(source_features, target_features)
outputs = classifier(source_features)
cls_loss = criterion(outputs, source_labels)
loss = cls_loss + mmd_loss # 根据实际情况调整权重
loss.backward()
optimizer.step()
print(f'Epoch {epoch}, Loss: {loss.item()}')
根据您提供的代码片段,这是一个使用ResNet50进行特征提取,并结合MMD(最大均值差异)进行域适应的迁移学习模型。以下是完整的代码示例,包括数据加载、模型定义、训练和测试过程。
1. 导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import models, transforms, datasets
import numpy as np
2. 定义模型
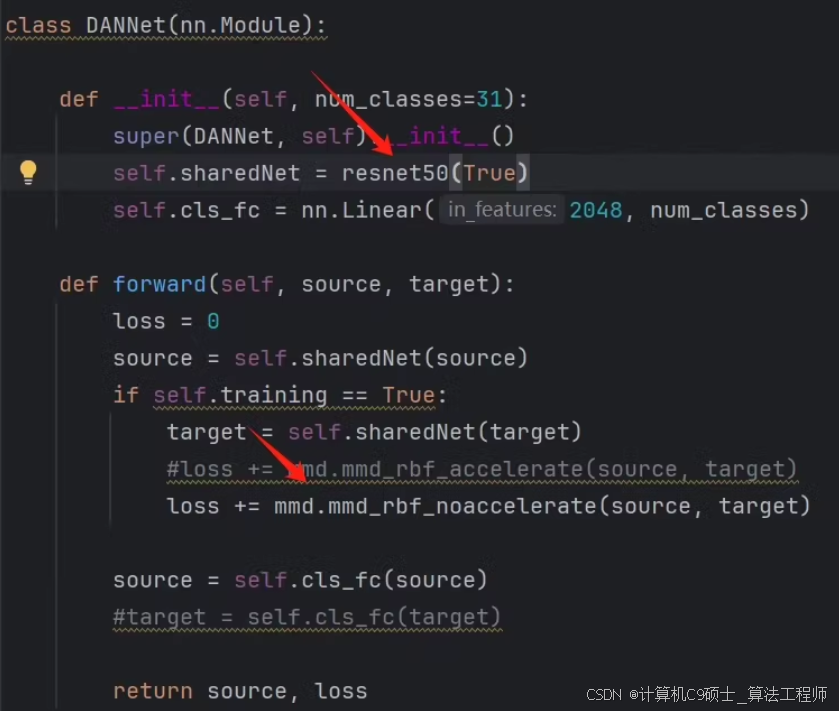
class DANNet(nn.Module):
def __init__(self, num_classes=31):
super(DANNet, self).__init__()
self.sharedNet = models.resnet50(pretrained=True)
self.cls_fc = nn.Linear(2048, num_classes)
def forward(self, source, target):
loss = 0
source = self.sharedNet(source)
if self.training == True:
target = self.sharedNet(target)
#loss += mmd.mmd_rbf_accelerate(source, target)
loss += mmd.mmd_rbf_noaccelerate(source, target)
source = self.cls_fc(source)
#target = self.cls_fc(target)
return source, loss
3. 数据准备
假设您已经有两个数据集:一个是源域数据集,另一个是目标域数据集。这两个数据集都需要转化为二维图像格式,并且放在不同的文件夹中。
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
source_dataset = datasets.ImageFolder('path_to_source_data', transform=transform)
target_dataset = datasets.ImageFolder('path_to_target_data', transform=transform)
source_loader = torch.utils.data.DataLoader(source_dataset, batch_size=32, shuffle=True)
target_loader = torch.utils.data.DataLoader(target_dataset, batch_size=32, shuffle=True)
4. 训练过程
def train(model, source_loader, target_loader, criterion, optimizer, device):
model.train()
running_loss = 0.0
for (source_data, source_labels), (target_data, _) in zip(source_loader, target_loader):
source_data, source_labels = source_data.to(device), source_labels.to(device)
target_data = target_data.to(device)
optimizer.zero_grad()
source_output, cls_loss = model(source_data, target_data)
loss = criterion(source_output, source_labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
return running_loss / len(source_loader)
def test(model, data_loader, criterion, device):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for data, labels in data_loader:
data, labels = data.to(device), labels.to(device)
outputs, _ = model(data, None)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
return running_loss / len(data_loader), accuracy
# 设备设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 模型实例化
model = DANNet(num_classes=len(source_dataset.classes)).to(device)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练和测试
num_epochs = 10
for epoch in range(num_epochs):
train_loss = train(model, source_loader, target_loader, criterion, optimizer, device)
test_loss, test_accuracy = test(model, target_loader, criterion, device)
print(f'Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}, Test Loss: {test_loss:.4f}, Test Accuracy: {test_accuracy:.2f}%')
5. 运行代码
确保您的环境中安装了必要的库,并且数据路径正确。运行上述代码将进行模型训练和测试。
6. 注意事项
- 确保数据集路径正确。
- 根据实际需求调整超参数(如学习率、批次大小等)。
mmd_rbf_accelerate和mmd_rbf_noaccelerate函数需要从相应的库导入或自定义实现。