人脸表情检测
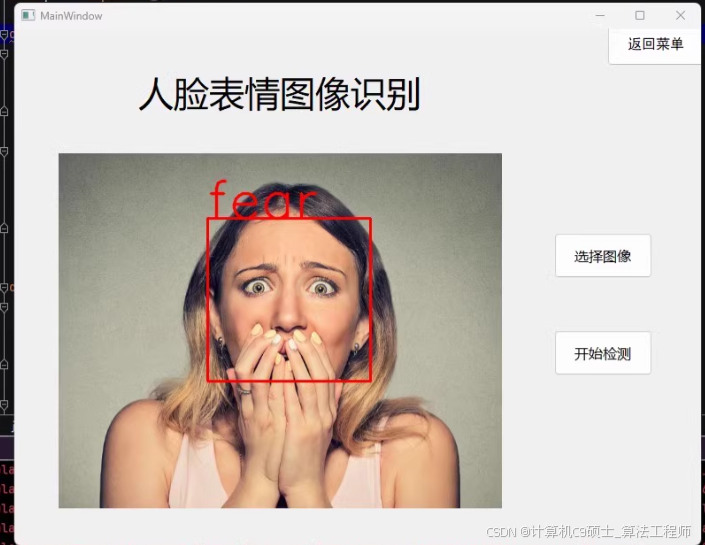
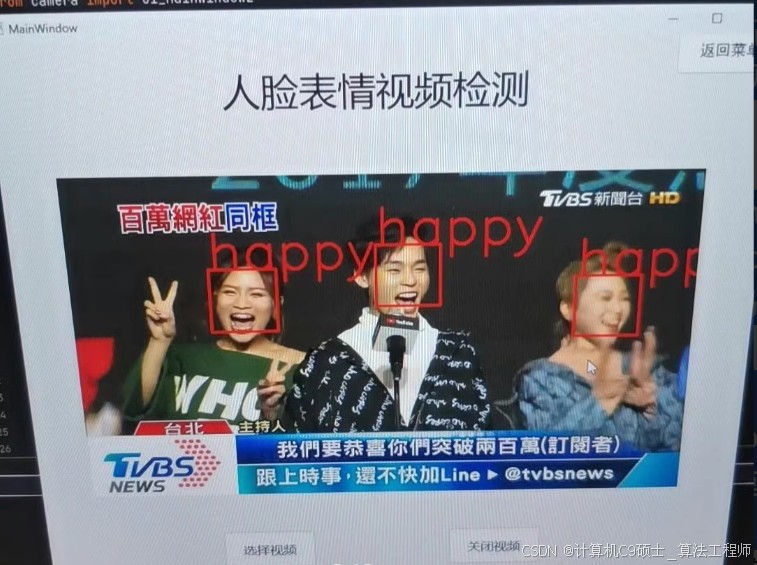
该项目已训练好网络模型,配置好环境即可运行使用,效果见图像,实现图像识别、摄像头识别、摄像头识别
/识别分类项目-说明文档-UI界面-cnn网络
项目基本介绍:
【网络】深度学习CNN网络 mini-xception网络
【环境】python>=3.5 tensorflow2 opencv pyqt5
【文件】训练预测全部源代码、训练好的模型、fer2013数据集、程序算法讲解文档
【类别】对7种表情检测:anger;disgust;fear;happy;normal;sad;surprised
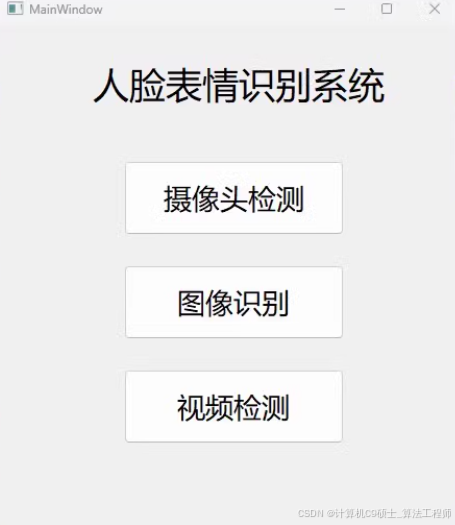
【功能】可训练、可预测,包含图像、摄像头和视频检测功能,配置好环境即可使用。
好的,我们将构建一个完整的人脸表情检测/识别分类项目,使用Mini-Xception网络。该项目已经训练好模型,并提供了训练预测的全部源代码、数据集和文档。以下是详细的说明文档和UI界面实现。
项目结构
face_expression_recognition/
├── data/
│ └── fer2013.csv
├── models/
│ └── mini_xception.h5
├── src/
│ ├── train.py # 训练脚本
│ ├── predict.py # 预测脚本
│ ├── utils.py # 工具函数
│ ├── app.py # Flask应用入口
│ └── ui_app.py # PyQt5 UI应用入口
├── README.md # 项目说明文档
└── requirements.txt # 依赖项
安装依赖项
首先,安装所需的Python库:
pip install tensorflow opencv-python pyqt5 pandas matplotlib scikit-learn
数据集准备
假设你已经有一个FER2013数据集文件 fer2013.csv 在 data 目录下。如果没有,可以从 Kaggle 下载。
模型训练
src/train.py 文件
虽然你提到模型已经训练好,但为了完整性,这里提供一个训练脚本示例。
模型预测
src/predict.py 文件
前端界面 (Flask)
src/app.py 文件
templates/index.html 文件
创建一个简单的HTML模板用于上传图片并显示预测结果:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Face Expression Recognition</title>
<style>
body {
font-family: Arial, sans-serif;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
background-color: #f4f4f4;
}
.container {
text-align: center;
background-color: white;
padding: 20px;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
}
input[type="file"] {
margin-bottom: 20px;
}
button {
padding: 10px 20px;
background-color: #007bff;
color: white;
border: none;
border-radius: 5px;
cursor: pointer;
}
button:hover {
background-color: #0056b3;
}
.result {
margin-top: 20px;
font-size: 1.2em;
}
.video-feed {
margin-top: 20px;
}
</style>
</head>
<body>
<div class="container">
<h1>Upload Face Image</h1>
<form id="upload-form" enctype="multipart/form-data">
<input type="file" id="file-input" name="file" accept="image/*" required>
<br><br>
<button type="submit">Predict</button>
</form>
<div class="result" id="result"></div>
<h1>Camera Feed</h1>
<button onclick="startVideo()">Start Video</button>
<button onclick="stopVideo()">Stop Video</button>
<div class="video-feed">
<video id="video" width="640" height="480" autoplay></video>
<canvas id="canvas" style="display:none;"></canvas>
</div>
</div>
<script>
document.getElementById('upload-form').addEventListener('submit', function(event) {
event.preventDefault();
const formData = new FormData(this);
fetch('/predict-image', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => {
document.getElementById('result').innerText = `Prediction: ${data.prediction}`;
})
.catch(error => console.error('Error:', error));
});
let videoStream;
async function startVideo() {
try {
videoStream = await navigator.mediaDevices.getUserMedia({ video: true });
const videoElement = document.getElementById('video');
videoElement.srcObject = videoStream;
videoElement.play();
setInterval(captureAndPredict, 1000); // Capture and predict every second
} catch (error) {
console.error('Error accessing camera:', error);
}
}
function stopVideo() {
if (videoStream && videoStream.getTracks().length > 0) {
videoStream.getTracks()[0].stop();
const videoElement = document.getElementById('video');
videoElement.srcObject = null;
}
}
async function captureAndPredict() {
const videoElement = document.getElementById('video');
const canvasElement = document.getElementById('canvas');
const context = canvasElement.getContext('2d');
canvasElement.width = videoElement.videoWidth;
canvasElement.height = videoElement.videoHeight;
context.drawImage(videoElement, 0, 0, canvasElement.width, canvasElement.height);
const imageData = canvasElement.toDataURL('image/png');
const blob = await fetch(imageData).then(res => res.blob());
const formData = new FormData();
formData.append('file', blob, 'captured.png');
fetch('/predict-image', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => {
console.log('Prediction:', data.prediction);
})
.catch(error => console.error('Error:', error));
}
</script>
</body>
</html>
UI界面 (PyQt5)
src/ui_app.py 文件
运行项目
-
启动Flask服务器:
python src/app.py -
启动PyQt5 UI应用:
python src/ui_app.py
解释
- 数据预处理: 使用
ImageDataGenerator进行数据增强。 - 模型训练: 使用自定义的Mini-Xception模型进行训练。
- 模型预测: 提供图像预测和视频流预测功能。
- Flask应用: 提供一个简单的Web界面用于上传图像和实时视频流预测。
- PyQt5 UI应用: 提供一个图形化的用户界面用于上传图像和实时视频流预测。
通过这些步骤,你可以构建一个完整的人脸表情检测/识别分类系统,包括训练、评估、前端和服务端代码。