【深度学习基础|知识概述】神经网络基础中的神经元结构是怎么样的?以及常用的激活函数有哪些?各有什么优缺点和应用场景。附公式及代码。(二)
【深度学习基础|知识概述】神经网络基础中的神经元结构是怎么样的?以及常用的激活函数有哪些?各有什么优缺点和应用场景。附公式及代码。(二)
文章目录
欢迎铁子们点赞、关注、收藏!
祝大家逢考必过!逢投必中!上岸上岸上岸!upupup
大多数高校硕博生毕业要求需要参加学术会议,发表EI或者SCI检索的学术论文会议论文:
可访问艾思科蓝官网,浏览即将召开的学术会议列表。会议详细信息可参考:https://ais.cn/u/EbMjMn
2. 常见的激活函数
在深度学习中,激活函数(Activation Function)是神经网络中至关重要的组成部分。它决定了神经元的输出,并使得神经网络具有非线性变换的能力,从而能够学习复杂的映射关系。不同的激活函数在不同的任务和网络架构中有不同的应用和效果。接下来,我们将详细介绍常用的激活函数,包括它们的优缺点、应用场景,并附上相应的公式和代码。
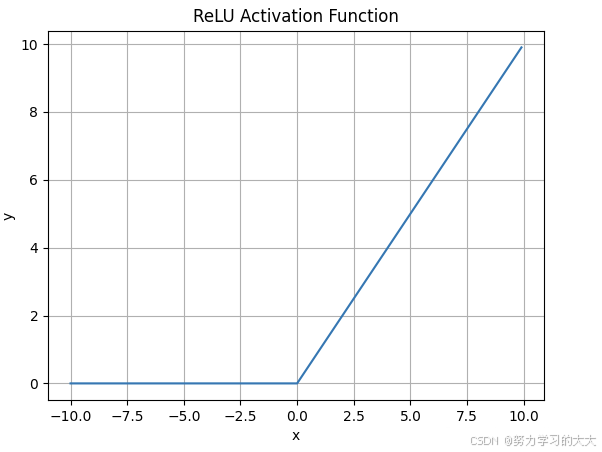
3. ReLU(Rectified Linear Unit)激活函数
公式:
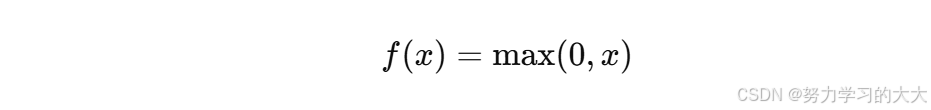
图像:
优点:
- 计算简单:ReLU 的计算非常简单,只需要比较输入和零,计算开销非常小。
- 避免了梯度消失问题:由于 ReLU 对于正值输入不会饱和,因此在训练过程中不会出现梯度消失问题,能够有效地加速训练。
- 稀疏性:ReLU 在负输入时输出 0,这种稀疏性可以促进特征选择和减少过拟合。
缺点:
- “死亡神经元”问题:当输入为负时,ReLU 输出为 0,导致神经元“死亡”,即该神经元在训练过程中永远不会更新。
- 对初始化敏感:ReLU 对权重初始化较为敏感,若权重初始化不好,可能导致神经元输出为 0。
应用场景:
- 卷积神经网络(CNN)和深度神经网络(DNN):ReLU 是深度神经网络中最常用的激活函数,尤其在图像分类和其他任务中有广泛应用。
代码实现:
def relu(x):
return np.maximum(0, x)
x = np.array([-10, -1, 0, 1, 10])
y = relu(x)
print(y)
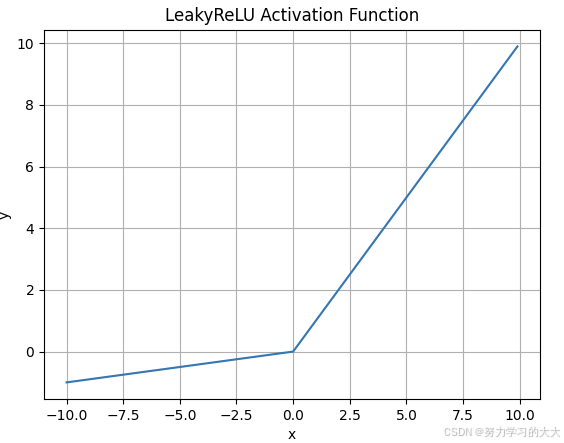
4. Leaky ReLU 激活函数
公式:
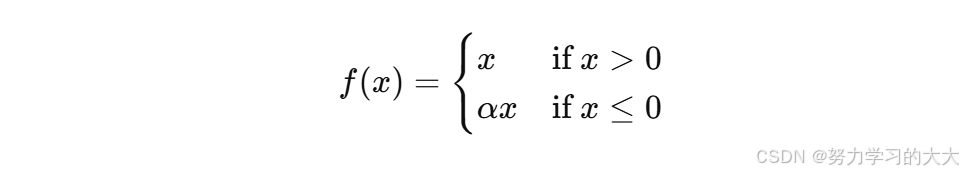
图像:
优点:
- 解决死亡神经元问题:Leaky ReLU 对负值输入也有一个小的斜率( α α α),避免了神经元完全“死亡”的问题。
- 计算简单:和 ReLU 一样,Leaky ReLU 的计算也非常简单,且开销较小。
缺点:
- 仍然可能导致死神经元:虽然 Leaky ReLU 改善了 ReLU 的问题,但如果 α α α 设置不当,仍然可能导致一些神经元不更新。
应用场景:
- 深层神经网络:Leaky ReLU 在深层神经网络中应用,尤其是在卷积神经网络(CNN)中,避免了部分神经元死掉的现象。
代码实现:
def leaky_relu(x, alpha=0.01):
return np.where(x > 0, x, alpha * x)
x = np.array([-10, -1, 0, 1, 10])
y = leaky_relu(x)
print(y)
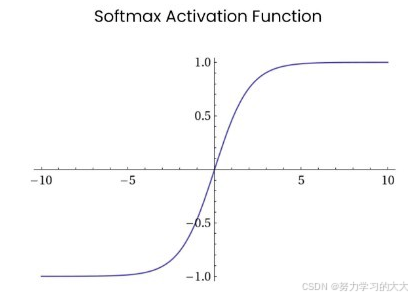
5. Softmax 激活函数
公式:
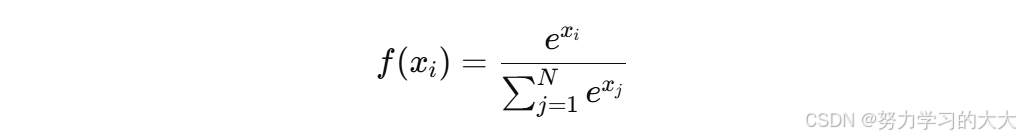
图像:
优点:
- 多分类问题:Softmax 将每个类别的得分转化为概率值,适用于多分类任务。
- 概率输出:Softmax 的输出值为概率,可以用来进行分类决策。
缺点:
- 计算复杂:计算 Softmax 函数时涉及指数运算,对于较大的输入值,可能导致数值不稳定。
应用场景:
- 多分类问题:Softmax 激活函数常用于神经网络的输出层,特别是在多分类问题中,输出每个类别的概率分布。
代码实现:
def softmax(x):
e_x = np.exp(x - np.max(x)) # 防止溢出
return e_x / e_x.sum(axis=0, keepdims=True)
x = np.array([1.0, 2.0, 3.0])
y = softmax(x)
print(y)
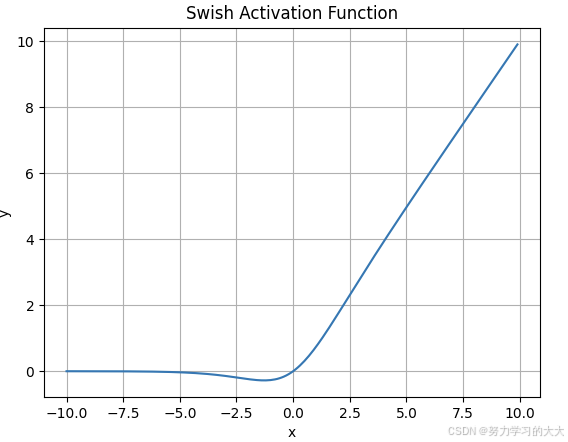
6. Swish 激活函数
公式:
其中
σ
(
x
)
σ(x)
σ(x) 是 Sigmoid 函数。
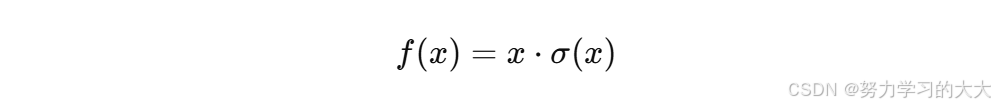
图像:
优点:
- 性能优越:Swish 函数在一些任务中比 ReLU 和 Sigmoid 更有效,能够提高训练效果,尤其是在深度网络中。
- 平滑:Swish 函数是平滑的,不容易出现梯度消失或梯度爆炸问题。
缺点:
- 计算复杂:相较于 ReLU,Swish 计算复杂,可能会带来一些性能开销。
应用场景:
- 深度神经网络和卷积神经网络:Swish 常用于更复杂的网络,尤其是在 ImageNet 等大规模图像分类任务中。
代码实现:
def swish(x):
return x * sigmoid(x)
x = np.array([-10, -1, 0, 1, 10])
y = swish(x)
print(y)
总结
每种激活函数都有其特定的优缺点和适用场景。选择合适的激活函数取决于任务的要求以及网络的深度和结构。在深度学习中,常用的激活函数包括 Sigmoid、Tanh、ReLU、Leaky ReLU、Softmax 和 Swish。对于大多数神经网络,ReLU 是最常用的激活函数,而在一些特殊任务中,其他激活函数(如 Softmax、Leaky ReLU 或 Swish)可能会带来更好的性能。
补充激活函数介绍请参考:【深度学习基础|知识概述】神经网络基础中的神经元结构是怎么样的?以及常用的激活函数有哪些?各有什么优缺点和应用场景。附公式及代码。(三)
第四届能源利用与自动化国际学术会议(ICEUA 2025)
- 2025 4th International Conference on Energy Utilization and Automation (ICEUA 2025)
- 大会官网:www.iceua.org
- 会议时间:2025年1月17-19日
- 会议地点:中国-北京
- 接受/拒稿通知:投稿后1周内
- 提交检索:EI Compendex、Scopus