2周
导学
Beautiful Soup解析HTML页面,信息标记和提取方法
Beautiful Soup库安装
pip install beautifulsoup4
Html页面解析和获取源代码
1.手动检查
2.requests.get() demo=r.text
Beautiful Soup库使用
- 导入库:from bs4 import BeautifulSoup
- soup=BeautifulSoup(demo,’html.parser’)
- soup=BeautifulSoup(’
data
’,’html.parser’)
Beautiful Soup库基本元素
Beautiful Soup库也叫beatifulsoup4或bs4(大小写敏感)
如果要对bs4里面的基本变量判断,就直接import bs4
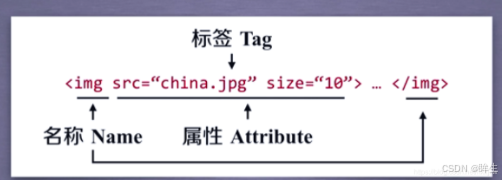
- html文件:由一组尖括号构成的标签组织起来的,每一个尖括号都是一个标签,而标签之前存在上下游关系,形成了标签树
- Beautiful Soup库是解析,遍历,维护“标签树的功能库”。只要文件是标签类型,就能很好解析
Beautiful Soup库解析器
| 解析器 | 使用方法 | 条件 |
|---|---|---|
| bs4的HTML解析器 | BeautifulSoup(mk,’html.parser’) | 安装bs4库 |
| lxml的HTML解析器 | BeautifulSoup(mk,’lxml’) | pip install lxml |
| lxml的XML解析器 | BeautifulSoup(mk,’xml’) | pip install lxml |
| html5lib的解析器 | BeautifulSoup(mk,’html5lib’) | pip install html5lib |
Beautiful Soup类的基本元素
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
| Name | 标签的名字, … 的名字是’p’,格式:.name |
| Attributes | 标签的属性,字典形式组织,格式:.attrs |
| NavigableString | 标签内非属性字符串,<>…</>中的字符串,格式:.string.可以跨越多个层次 |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型(尖括号叹号表示注释开始: ) |
python123.io
当html中有多个相同标签时,soup.tag只能返回第一个
soup.tag.name
soup.tag.attrs
soup.tag.attrs[’class’]
soup.tag.attrs[’href’]
type(tag.arrts)
基于bs4库的HTML内容遍历方法
HTML是一个树形结构
三种遍历方法(具体可以参考数据结构的内容)
下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将所有的所有儿子节点存入列表。也包括字符串节点。len()函数可以提取数量。既然是列表就可以用索引 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
上行遍历
| 属性 | 说明 |
|---|---|
| .parant | 节点的父亲标签 |
| .parants | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
print(soup.title.parent)
print(soup.html.parent)#html的parent是他自己
print(soup.parent)#soup本身是一种标签,但他的parent是空的
print("----------------------------------------------------------------------------")
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
#生成器遍历时不会包含 None ,课上老师可能说错了,所以不要if-else
# 只有当直接访问根节点的 .parent 属性时才会得到 None 。
# 建议在实际使用中通过打印每个 parent 对象来验证遍历结果。
平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
注意:平行遍历条件,平行遍历发生在同一个父亲节点下的各节点间
Basic Python and Advanced Python.
soup.a.next._sibling→’and’
标签的NavigableString.也构成标签树的节点。所以遍历不一定是标签类型
基于bs4库的HTML格式输出
友好显示
prettify()
prettify() 是 BeautifulSoup 对象的一个方法,用于将 HTML 或 XML 文档格式化为更易读的形式。以下是它的详细解释:
1. 功能
- 格式化文档 :将 HTML/XML 文档中的标签、属性和内容进行缩进和换行,使其结构更清晰。
- 美化输出 :适用于调试或查看网页源代码时,使内容更易读。
2. 语法
soup.prettify()
返回值 :返回一个格式化后的字符串。
3. 示例
假设有以下 HTML 文档:
<html><body><h1>标题</h1><p>段落内容</p></body></html>
使用 prettify() 后:
from bs4 import BeautifulSoup
html = "<html><body><h1>标题</h1><p>段落内容</p></body></html>"
soup = BeautifulSoup(html, 'html.parser')
print(soup.prettify())
输出:
<html>
<body>
<h1>
标题
</h1>
<p>
段落内容
</p>
</body>
</html>
4. 参数
prettify() 可以接受以下可选参数:
- encoding :指定输出字符串的编码(默认为 None )。
- formatter :指定格式化器(如 minimal 、 html 等)。
示例:
print(soup.prettify(encoding='utf-8', formatter='html'))
5. 使用场景
- 调试 :查看网页的结构和内容。
- 保存文件 :将格式化后的 HTML 保存到文件中,便于后续分析。
- 展示 :在控制台或日志中输出更易读的 HTML 内容。
6. 注意事项
- 性能 : prettify() 会生成一个新的字符串,对于非常大的文档可能会占用较多内存。
- 修改文档 : prettify() 不会修改原始的 BeautifulSoup 对象,而是返回一个新的格式化字符串
总结: prettify() 是 BeautifulSoup 中用于美化 HTML/XML 文档输出的方法,适合在调试或查看网页结构时使用。
编码bs4 UTF-8
信息标记的三种形式
信息的标记
标记后的信息可形成信息组织结构,增加了信息维度
标记后的信息可用于通信,存储或展示
标记的结构与信息一样具有重要价值
标记后的信息更有利于程序理解和运用
HTML的信息标记
HTML是www的信息组织方式,将一些声音,图像,视频等超文本嵌入到文本中。
通过预定义的标签形式组织不同类型的信息
信息标记上的一般类型的种类
XML,JSON,YAML
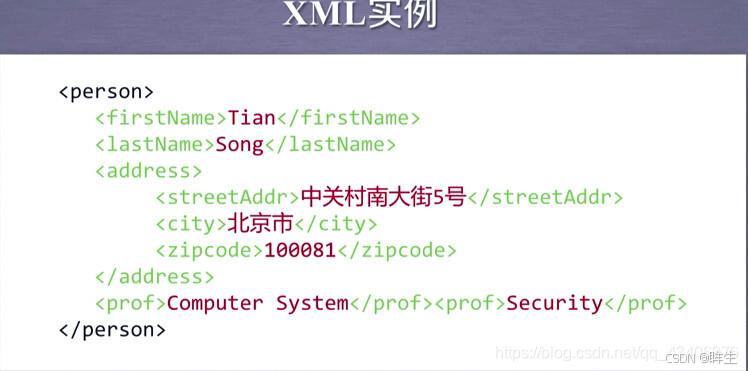
XML(extensible Markup Language)
以标签为主来构建信息
当标签中有内容时,用一对标签来表达这个信息
没有内容。用一对尖括号表达,同时增加注释
json(javaScript Object Notion)
有类型的键值对 key:value。
无论时键还是值,都需要加双引号来表达他是字符串的形式
如果不是字符串,是数字,就直接写数字。多个值可以加方括号
键值对之间可以嵌套使用:大括号括出键值对、
YAML (YAML AIN‘t Markup Language)
无类型的键值对 key:value。都无双引号,全部默认字符串
通过缩进来描述所属关系
用减号表示并列关系
|表示整块数据 #表示注释
三种信息标记形式的比较


XML 最早的通用信息标记语言,可扩展性好,但繁琐
JSON 信息有类型,适合程序处理(js),较XML简洁。可以说本身就是程序,并被程序直接运行
YAML 信息无类型,文本信息比例最高,可读性好
XML Internet上的信息交互与传递
JSON 移动应用云端和节点的信息通信,无注释。程序对接口处理的地方
YAML 各类系统的配置文件,有注释易读
信息提取的一般方法
方法一:完整解析信息的标记形式,再提取关键信息
XML JSON YAML
需要标记解析器 例如:bs4库的标签树遍历
优点:信息解析准确
缺点:提取过程繁琐,速度慢,也需要的整个文件的信息组织形式有一个清楚的认识理解
方法二:无视标记形式,直接搜索关键信息
搜索
对信息的文本查找函数即可
优点:提取过程简洁,速度较快
缺点:提取结果准确性与信息内容相关
融合方法:结合形式解析与搜索方法,提取关键信息
XML JSON YAML 搜索
需要标记解析器及文本查找函数
实例:
提取HTML中的所有URL链接
思路:1)搜索到所有标签
2)解析<a>标签格式,提取href后的链接内容
Beautiful Soup库的HTML内容查找方法
<>.find_all(name,attrs,recursive,string,**kwargs)
返回一个列表类型,存储查找的结果
name:对标签名称的检索字符串。
如果name=True,将显示当前soup的所有标签信息。如果希望只显示其中以b开头的标签,包括b和body,就需要使用正则表达式库
attrs:对标签属性值的检索字符串,可标注属性检索
在对属性进行查找的时候,必须精确的赋值这个信息,如果想要查找属性的部分信息
,仍然需要正则表达式的支持
recursove:是否对子孙全部搜索,默认True
string:<>….</>中字符串区域的检索字符串
(…)等价于.find_all(…)
soup(…)等价于 soup.find_all(…)
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_next_siblings() | 在后序平行节点节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后序平行节点中返回一个结果,字符串类型,同.find_all()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,字符串类型,同.find_all()参数 |
正则表达式
搜索词的一部分,如果不使用正则表达式,就要完整准确的给出要搜索的信息
代码
Python 3.9.9 (tags/v3.9.9:ccb0e6a, Nov 15 2021, 18:08:50) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license()" for more information.
>>> import requests
>>> r=requests.get("http://python123.io/ws/demo.html")
>>> r.status_code
200
>>> demo=r.text
>>> demo
'<html><head><title>This is a python demo page</title></head>\r\n<body>\r\n<p class="title"><b>The demo python introduces several python courses.</b></p>\r\n<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:\r\n<a href="http://www.icourse163.org/course/BIT-268001" class="py1" id="link1">Basic Python</a> and <a href="http://www.icourse163.org/course/BIT-1001870001" class="py2" id="link2">Advanced Python</a>.</p>\r\n</body></html>'
>>> from bs4 import BeautifulSoup
>>> soup=BeautifulSoup(demo,"html.parser")
>>> soup.find_all('a')
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
>>> soup.find_all(['a','b'])
[<b>The demo python introduces several python courses.</b>, <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
>>> for tag in soup.find_all(True):
print(tag.name)
html
head
title
body
p
b
p
a
a
>>> import re
>>> for tag in soup.find_all(re.compile('b')):
print(tag.name)
body
b
>>> soup.find_all('p','course')
[<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>]
>>> soup.find_all(id='link1')
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>]
>>> soup.find_all(id='link')
[]
>>> import re
>>> soup.find_all(id=re.compile('link'))
[<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>]
>>> soup.find_all('a',recursive=False)
[]
>>> soup
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
>>> soup.find_all(string = re.compile("python"))
['This is a python demo page', 'The demo python introduces several python courses.']
>>> soup.find_all(string = "Basic Python")
['Basic Python']
>>>
信息标记的三种基本形式(XML、JSON、YAML)与HTML的主要区别在于设计目的和应用场景:
- 核心差异
- XML/JSON/YAML 是 数据描述型标记 ,专注于结构化数据存储与传输
- HTML 是 内容展示型标记 ,专为网页内容呈现设计
- 功能特性对比
| 特性 | HTML | XML/JSON/YAML |
|-------------|---------------|------------------|
| 标签自由度 | 预定义标签集 | 完全自定义标签 |
| 数据携带能力 | 少量数据嵌入 | 专业数据存储 |
| 解析复杂度 | 浏览器渲染 | 需专用解析器 |
| 扩展性 | 有限 | 高度可扩展 |
- 实际应用示例 假设需要存储商品信息:
HTML实现(展示导向)
<div class="product">
<h2>Java编程书</h2>
<p class="price">¥59.99</p>
<img src="book.jpg">
</div>
XML实现(数据导向)
<product id="1001">
<name>Java编程书</name>
<price currency="CNY">59.99</price>
<image>book.jpg</image>
</product>
- 历史发展脉络 HTML源于SGML(1986)→ XML为简化SGML而生(1998)→ JSON从JavaScript演化(2001)→ YAML追求更人性化的格式(2004)
- 技术互补关系 在实际应用中常组合使用:
结论:HTML未归类为信息标记基础形式,是因为其核心使命是内容可视化而非数据序列化,但这不妨碍它与XML/JSON/YAML在现代Web开发中形成技术互补。
中国大学排名定向爬虫
https://www.shanghairanking.cn/rankings/bcur/2024
输入:url链接
输出:大学排名信息的屏幕输出(排名,大学名称,总分)
技术路线:requests-bs4
定向爬虫:仅对输入URL进行爬取,不扩展爬取
实验前判断:
- 页面右键查看源代码
- 源代码页面ctrl+f搜索清华大学
- 看是否信息写在了HTML代码中,判断是否可以定向爬虫实现
- 看是否提供了robots协议约定
程序的结构设计:
- 步骤一:从网络上获取大学排名网页内容(getHTNLText())
- 步骤二:提取网页内容中信息到合适的数据结构(fillUnivList())(可以二维列表)
- 步骤三:利用数据结构展示并输出结果(printUnivList())
import requests
from bs4 import BeautifulSoup
def getHTMLText(url):
return ""
def fillUnivList(ulist,html):
pass
def printUnivList(ulist,num):
print("suc"+str(num))
def main():
unifo=[]
url='https://www.shanghairanking.cn/rankings/bcur/2024'
html=getHTMLText(url)
fillUnivList(unifo,html)
printUnivList(unifo,20)
main()

采用中文字符的空格填充
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def fillUnivList1(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string])
pass
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# 修正字段获取方式,使用text属性替代string
rank = tds[0].text.strip() # 获取排名文本并去除空白
name = tds[1].find('span', class_='name-cn').text # 精确获取中文名称
score = tds[4].text.strip() # 总分在第5列
ulist.append([rank, name, score])
def printUnivList1(ulist, num):
# 添加空值检查
print("{:^10}\t{:^6}\t{:^10}".format("排名", "学校名称", "总分"))
for i in range(min(num, len(ulist))): # 防止列表越界
u = ulist[i]
# 确保所有值都是字符串
print("{:^10}\t{:^6}\t{:^10}".format(u[0] or '', u[1] or '', u[2] or ''))
def printUnivList(ulist,num):
tplt="{0:^10}\t{1:{3}^30}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u=ulist[i]
print(tplt.format(u[0].strip() or '', u[1].strip() or '', u[2].strip() or '',chr(12288)))
print("suc"+str(num))
def main():
unifo=[]
url='https://www.shanghairanking.cn/rankings/bcur/2024'
html=getHTMLText(url)
fillUnivList(unifo,html)
printUnivList(unifo,20)
main()
注意:
函数名后面为1的是先前无优化的
- 在printUnivList函数增加了空值保护以及处理西文填充造成的格式问题
- 还处理了空字符串造成的格式问题
- 由下面的解释,我们可以发现:先前函数代码利用string产生了None值,导致format格式化错误,因此改进代码便使用了text,并根据find精确找到中文名称
<td class="align-left" data-v-389300f0><div class="univname-container" data-v-389300f0><div class="logo" data-v-389300f0><img alt="清华大学" onerror='this.src="/images/blank.svg"' src="https://www.shanghairanking.cn/_uni/logo/27532357.png" class="univ-logo" data-v-389300f0></div> <div class="univname" data-v-389300f0><div data-v-2b687c30 data-v-389300f0><div class="tooltip" data-v-2b687c30><div class="link-container" style="width:200px" data-v-2b687c30><span class="name-cn" data-v-2b687c30>清华大学
</span> <div class="collection" style="display:none" data-v-2b687c30><
在爬虫中,text 和 string 通常是处理 HTML/XML 解析时用到的方法(常见于解析库如 BeautifulSoup)。它们用于从标签中提取文本内容,但行为和适用场景有所不同:
1. text 属性
-
作用:返回当前标签及其所有子标签的文本内容,合并成一个字符串。
-
特点:
- 自动拼接所有子标签的文本(包括嵌套的标签)。
- 会保留文本中的空格、换行符等空白字符。
-
示例:运行 HTML
html
复制
<div><p>Hello</p><p>World</p></div>使用
div.text会返回"\nHello\nWorld\n"(包含换行符)。 -
适用场景:需要提取标签内所有文本(包括子标签的文本)。
2. string 属性
-
作用:返回当前标签的直接文本内容(仅当标签只有一个子节点且为字符串时有效)。
-
特点:
- 如果标签有多个子节点(例如嵌套标签),则返回
None。 - 仅返回直接子节点的文本,不递归提取子标签内容。
- 如果标签有多个子节点(例如嵌套标签),则返回
-
示例:运行 HTML
html
复制
<div><p>Hello World</p></div>p.string会返回"Hello World"(<p>标签内只有一个文本节点)。div.string会返回None(因为<div>的子节点是<p>标签,而非直接文本)。
-
适用场景:明确知道标签只包含纯文本(无嵌套标签)时使用。
对比总结
| 特性 | text | string |
|---|---|---|
| 返回值类型 | 字符串 | 字符串或 None |
| 子标签处理 | 递归合并所有子标签的文本 | 仅直接文本(无子标签时有效) |
| 空白字符 | 保留原始格式(包括换行) | 保留直接文本的格式 |
| 适用场景 | 提取所有文本内容 | 提取简单标签的纯文本 |
常见问题
-
text返回内容包含多余空白?可以用
.strip()或正则表达式清理,例如div.text.strip()。 -
何时用
string?当明确知道标签内部没有嵌套,且只包含纯文本时(如
<title>标题</title>)。 -
get_text()方法BeautifulSoup 还提供
get_text()方法,功能与text类似,但可通过参数控制分隔符,例如:python
复制
div.get_text(" ", strip=True) # 用空格拼接文本,并删除首尾空白