简单版本
AppMaster: 整个Job任务的核心协调工具
MapTask: 主要用于Map任务的执行
ReduceTask: 主要用于Reduce任务的执行一个任务提交Job --> AppMaster(项目经理)--> 根据切片的数量统计出需要多少个MapTask任务 --> 向ResourceManager(Yarn平台的老大)索要资源 --> 执行Map任务,先读取一个分片的数据,传递给map方法。--> map 方法不断的溢写 --> reduce 方法 --> 将统计的结果存放在磁盘上。
分开讲解版
MapTask执行阶段
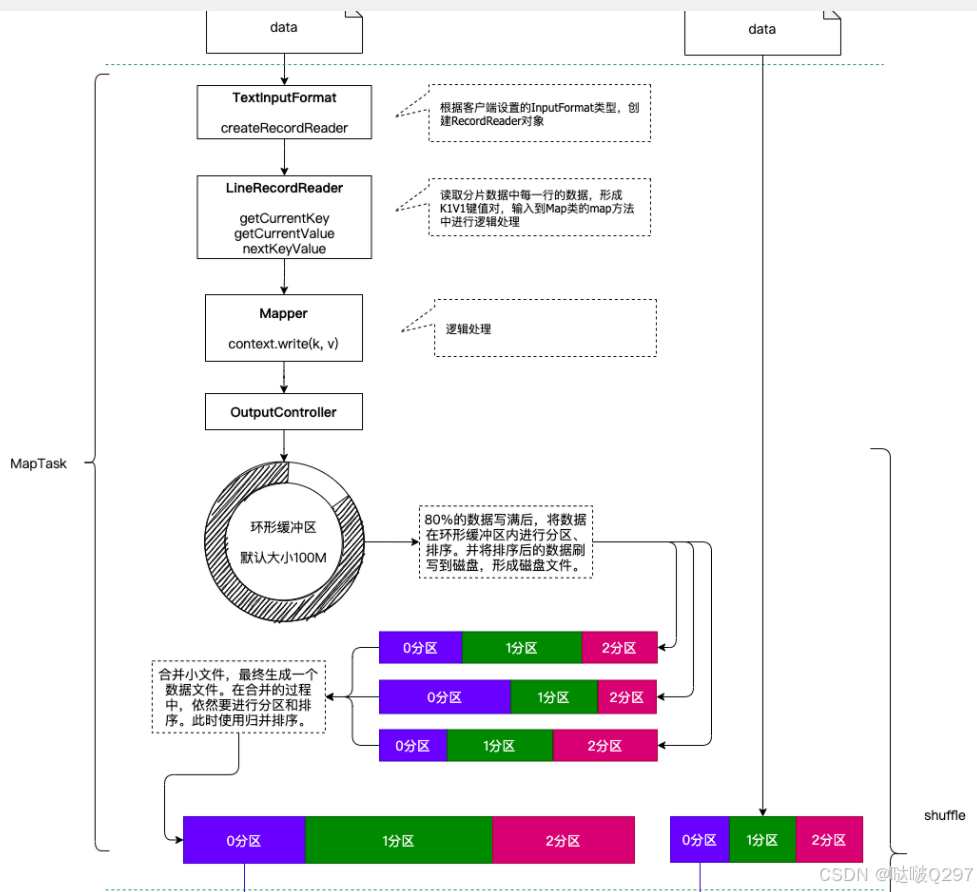
1. maptask调用FileInputFormat的getRecordReader读取分片数据
2. 每行数据读取一次,返回一个(K,V)对,K是offset(偏移量),V是一行数据
3. 将k-v对交给MapTask处理
4. 每对k-v调用一次map(K,V,context)方法,然后context.write(k,v)
5. 写出的数据交给收集器OutputCollector.collector()处理
6. 将数据写入环形缓冲区,并记录写入的起始偏移量,终止偏移量,环形缓冲区默认大小100M
7. 默认写到80%的时候要溢写到磁盘,溢写磁盘的过程中数据继续写入剩余20%
8. 溢写磁盘之前要先进行分区然后分区内进行排序
9. 默认的分区规则是hashpatitioner,即key的 hash%reduceNum
所有的mapreduce,其实都用到了分区,如果不写,使用的是默认的分区。
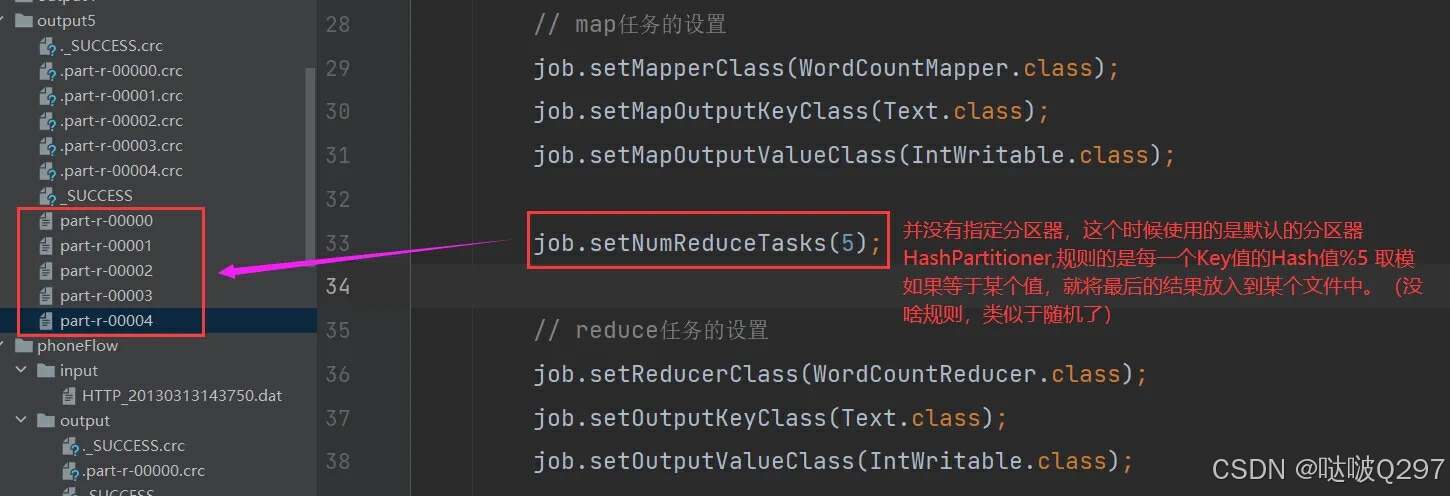
job.setNumReduceTask(3);
10. 默认的排序规则是key的字典顺序,使用的是快速排序
11. 溢写会形成多个文件,在maptask读取完一个分片数据后,先将环形缓冲区数据刷写到磁盘
12. 将数据多个溢写文件进行合并,分区内排序(外部排序===》归并排序)
关于9 的再次解释:
ReduceTask的执行流程:
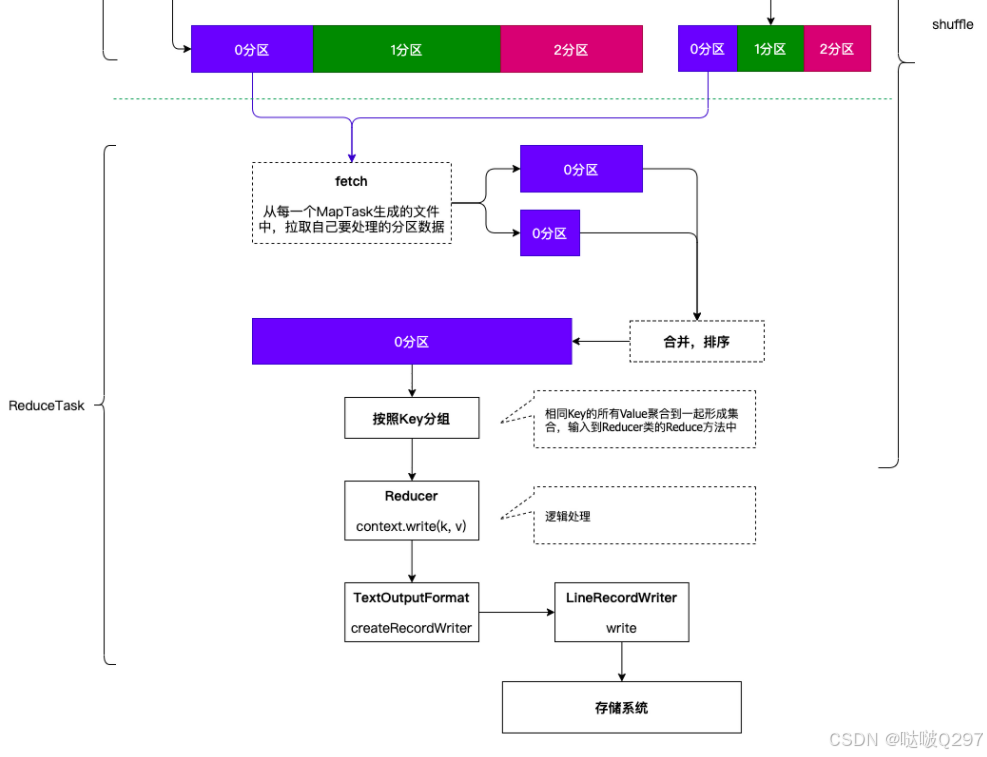
1. 数据按照分区规则发送到reducetask
2. reducetask将来自多个maptask的数据进行合并,排序(外部排序===》归并排序)
3. 按照key相同分组
4. 一组数据调用一次reduce(k,iterable<v>values,context)
5. 处理后的数据交由reducetask
6. reducetask调用FileOutputFormat组件
7. FileOutputFormat组件中的write方法将数据写出。
总结:
ReduceTask任务的数量是由谁决定的?
job.setNumReduceTasks(5);
是指定的,设置的几个就执行几个。
这个值不能瞎设置,要参考分区数量,假如有三个分区,ReduceTask任务就需要指定为3个。