目录
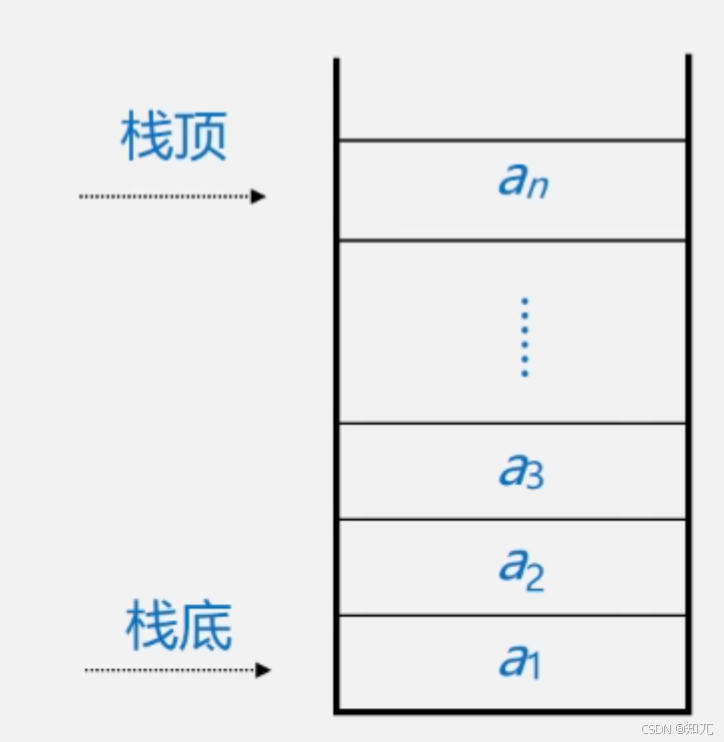
栈
- 栈(stack) 是仅在表尾进行插入和删除操作的线性表
- 又称为后进先出(Last In First Out)的线性表,简称LIFO结构
- 表尾(即aₙ端)称为栈顶(Top),表头(即a₁端)称为栈底(Base)
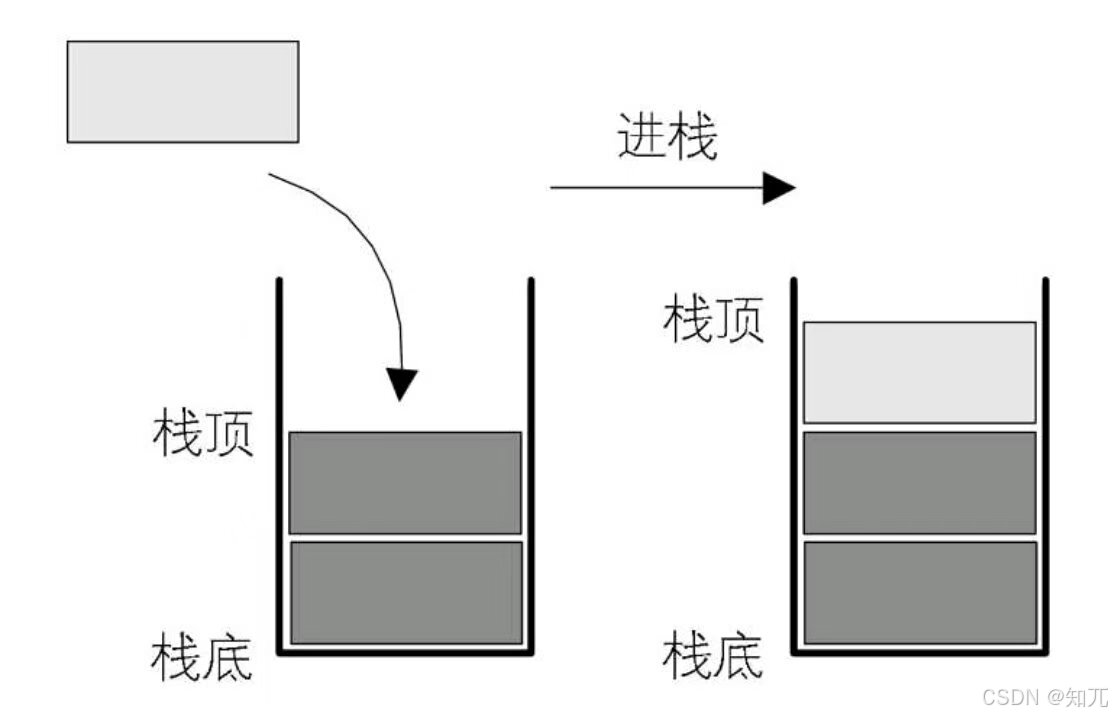
- 插入元素的栈顶(即表尾)的操作,称为入栈(进栈、压栈,PUSH)
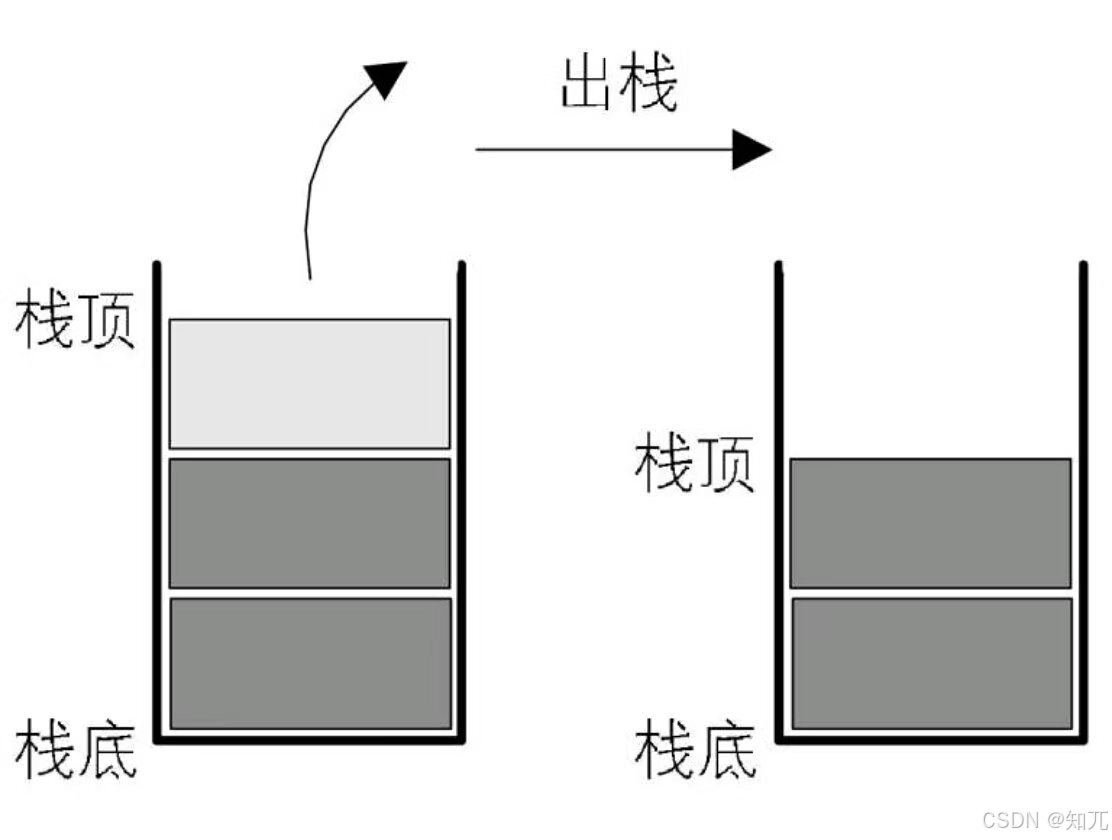
- 从栈顶(即表尾)删除最后一个元素的操作,称为出栈(弹出,POP)

栈的示意图
入栈、出栈的操作示图
先进栈不一定最后出栈
- 栈对线性表的插入和删除的位置进行了限制,但并没有对元素进出的时间进行限制
- 假设有三个元素a,b,c,入栈顺序是a,b,c,则它们的出栈顺序有几种?
- c-b-a:a入栈,b入栈,c入栈。c出栈,b出栈,a出栈
- a-b-c:a入栈,a出栈,b入栈。b出栈,c入栈,c出栈
- a-c-b:a入栈,a出栈。b入栈,c入栈,c出栈,b出栈
- b-a-c:a入栈,b入栈,b出栈,a出栈,c入栈,c出栈
- b-c-a:a入栈,b入栈,b出栈,c入栈,c出栈,a出栈
栈的抽象数据类型定义
ADT Stack{
数据对象:
D:{ ai | ai ∈ ElemSet, i = 1, 2, ...,n, n >= 0 }
数据关系:
R1 = { < ai - 1, ai >|ai - 1, ai ∈ D, i = 2, ..., n }
约定 aₙ 端为栈顶, a₁端 为栈底
基本操作:
InitStack(*S)
操作结果:初始化操作,构造一个空栈S
DestroyStack(*S)
初始条件:栈S已存在
操作结果:栈S被销毁
ClearStack(*S)
初始条件:栈S已存在
操作结果:将S清为空栈
StackEmpty(S)
初始条件:栈S已存在
操作结果:若栈S为空栈,则返回TRUE, 否则FALSE
GetTop(S, *e)
初始条件:栈S已存在且非空
操作结果:用e返回S的栈顶元素
Push(*S, e)
初始条件:栈S已存在
操作结果:插入元素e为新的栈顶元素
Pop(*S, *e)
初始条件:栈S已存在且非空
操作结果:删除S的栈顶元素aₙ,并用e返回其值
StackLength(S)
初始条件:栈S已存在
操作结果:返回S的元素个数,即栈的长度
}ADT Stack
顺序栈的表示和实现
- 存储方式:同一般线性表的顺序存储结构完全相同
- 利用一组地址连续的存储单元一次存放自栈底到栈顶的数据元素。栈底一般在低地址端
- 附设top指针,指示栈顶元素在顺序栈中的位置(为了方便操作,通常top指示真正的栈顶元素之上的下标位置)
- 另设base指针,指示栈底元素在顺序栈中的位置
- 用stacksize表示栈可使用的最大容量
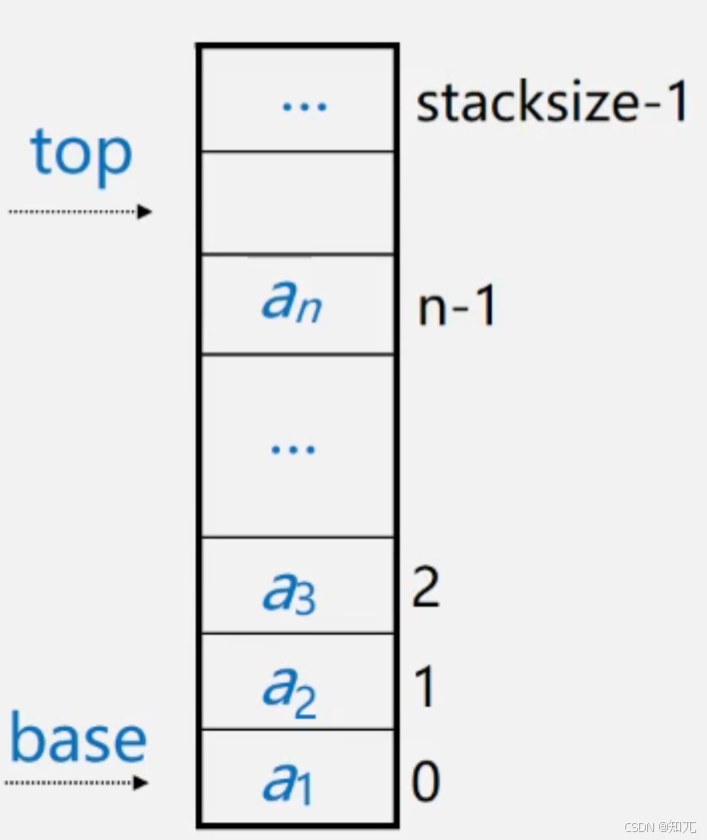
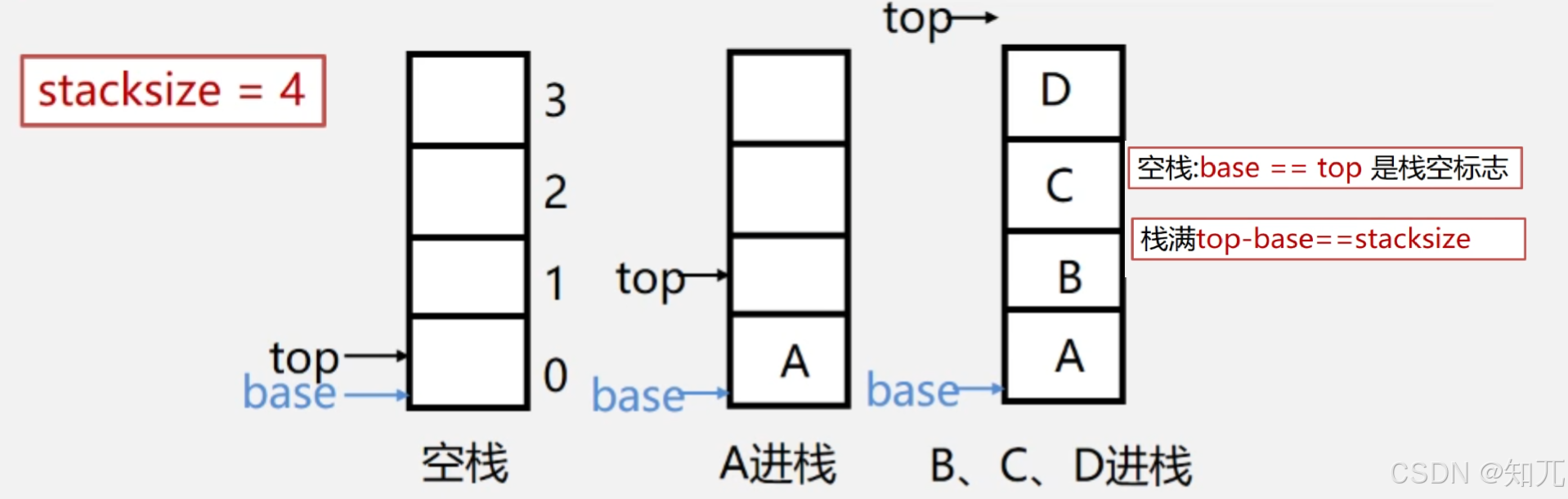
空栈和栈满
- base == top 是栈空的标志
- top - base == stacksize 是栈满的标志
- 栈满时的操作
- 报错,返回操作系统
- 分配更大的空间,作为栈的存储空间,将原栈的内容移入新栈(操作费时)
使用数组作为顺序栈存储方式的特点
- 简单、方便、但易产生溢出(数组大小固定)
- 上溢(overflow):栈已经满,又要压入元素
- 下溢(underflow):栈已经空,还要弹出元素
- 上溢是一种错误,使问题的处理无法进行;而下溢一般认为是一种结束条件可,即问题处理结束
顺序栈类型定义
typedef int SElemType; #define MAXSIZE 100 typedef struct { SElemType* base; // 栈底指针 SElemType* top; // 栈顶指针 int stacksize; // 栈可用最大容量 }SqStack;
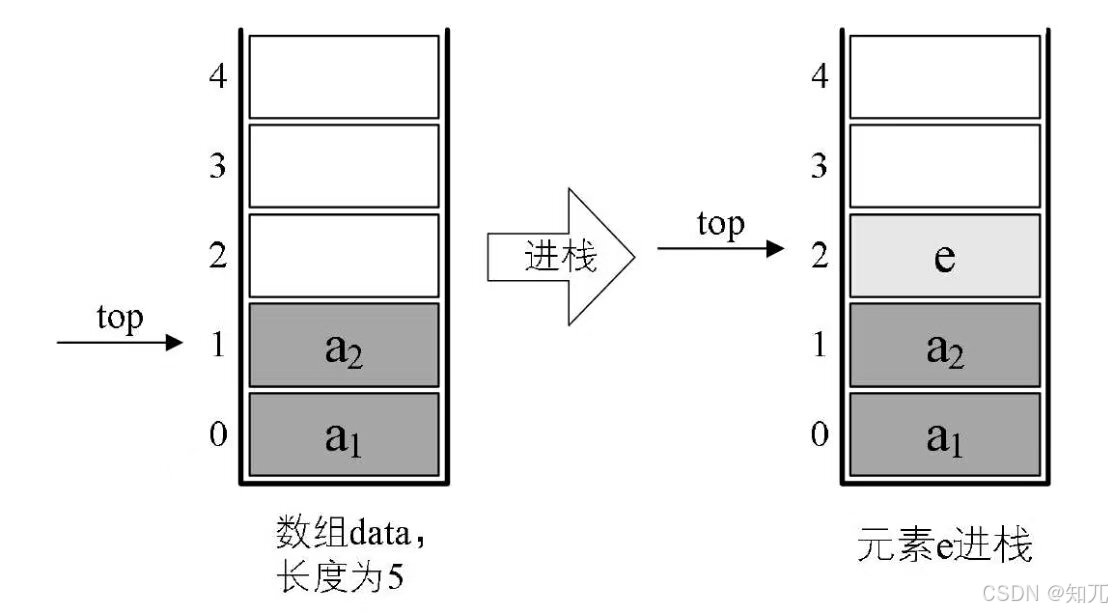
顺序栈的入栈
/* 顺序栈的入栈 */ Status Push(SqStack* S, SElemType e) { // 栈满 if (S->top - S->base == S->stacksize) return ERROR; /* 将新元素e赋值给栈顶空间,然后top指针指向下一空间 */ *S->top = e; S->top++; // 等同于:*S.top++ = e; return OK; }
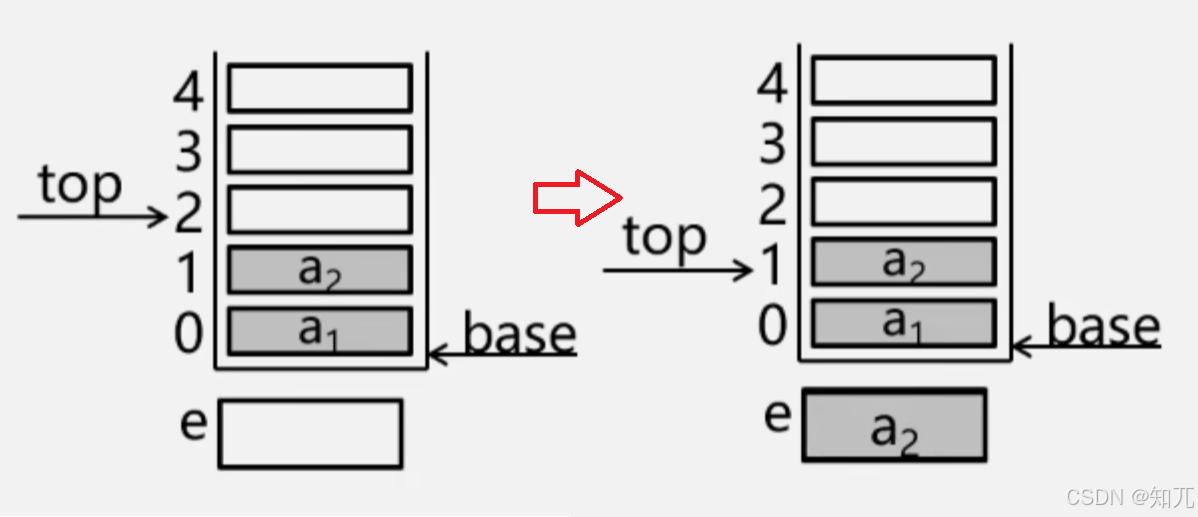
顺序栈的出栈
Status Pop(SqStack* S, SElemType* e) { if (S->top == S->base) return ERROR;// 判断是否栈空 /* 将top指针下移,然后将指的元素复制给变量e */ S->top--; e = *S->top; // 等于:e = *--S->top return OK; }
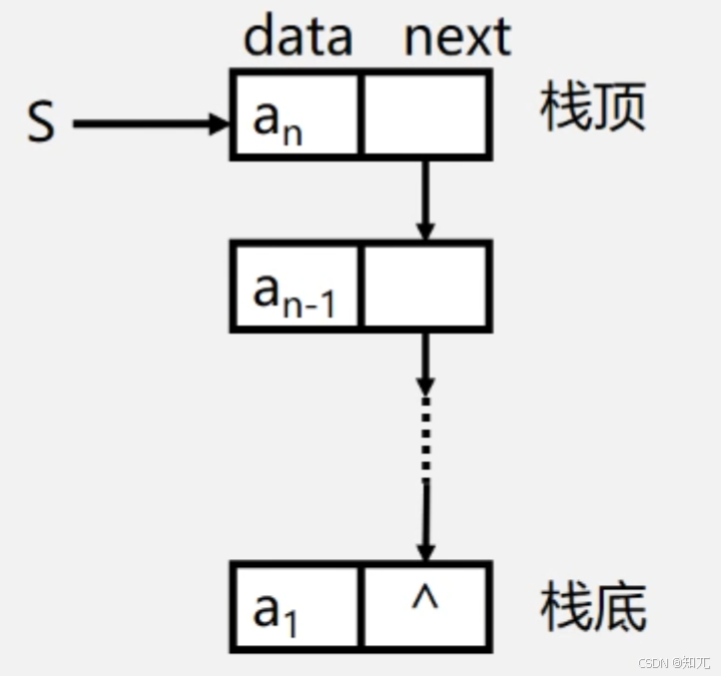
链栈的表示和实现
- 链栈是运算受限的单链表,只能在链表头部进行操作
链栈的类型定义
/* StackNode:栈的结点类型 *LinkStack:指向这个结点的指针类型 */ typedef struct StackNode { SElemType data; // 数据域,存放元素 struct StackNode* next; // 指针域,指向下一元素,类型仍为struct }StackNode, *LinkStack;
- 链栈中的指针的方向是反过来的
- 指针域中存放的是前驱元素
- 链表的头指针就是栈顶
- 不需要头结点
- 基本不存在栈满的情况
- 空栈相当于头指针指向空
- 插入和删除仅在栈顶处执行
链栈的入栈
Status Push(LinkStack* S, SElemType e) { // 生成新结点p LinkStackPtr p = (LinkStackPtr)malloc(sizeof(StackNode)); // 将元素放入新结点数据域 p->data = e; /* 将当前栈顶元素赋值给新结点的直接后继 即,让新结点指向当前栈顶元素 */ p->next = S->top; // 让栈顶指针指向新结点 S->top = p; S->cnt++; return OK; }
链栈的出栈
Status Pop(LinkStack* S, SElemType* e) { LinkStackPtr p; /* S == NULL 检查链栈对象是否存在。 S->top == NULL 检查链栈是否为空。 */ if (S == NULL || S->top == NULL) return ERROR; // 检查栈是否为空 *e = S->top->data; /* 将栈顶结点赋值给p */ p = S->top; /* 让栈顶指针后移,指向后一结点 */ S->top = S->top->next; /* 释放结点 */ free(p); S->cnt--; return OK; }
递归
- 若一个对象部分地包含它自己,或用它自己给自己定义,则成这更对象是递归的
- 若一个过程直接地或间接地调用自己,则称这个过程是递归的过程
- 每个递归定义必须至少有一个条件,满足时递归不在进行,即不再引用自身而是返回值退
递归问题(用分治法求解)
- 分治法:对于一个较为复杂的问题,能够分解成几个相对简单且解法相同或类似的子问题来求解
- 必备的三个条件
- 能将一个胃转变成一个新问题,而新问题与原问题的解法相同或类同,不同的仅是处理的对象,且这些处理对象是变化有规律的
- 可以通过上述转化而使问题简化
- 必须有一个明确的递归出口,或称递归的边界

函数调用过程
- 调用前,系统完成
- 将实参、返回地址等传递给被调用函数
- 为被调用函数的局部变量分配存储区
- 将控制转移到被调用函数的入口
- 调用后,系统完成
- 保存被调用函数的计算结果
- 释放被调用函数的数据
- 依照被调用函数保存的返回地址,将控制转移到调用函数
求解阶乘n!的过程

递归函数调用的实现

例:进行fact(4)系统栈的变化状态

- 递归
- 优点:结构清晰,程序易读
- 缺点:每次调用要生成工作记录,保存状态信息,入栈;返回时要出栈,恢复状态信息。时间开销大
递归→非递归
- 递归时间开销大,对时间效率要求高时,要将递归→非递归
- 方法
- 尾递归、单向递归→循环结构
- 自用栈模拟系统的运行时栈
尾递归

单向递归
- 虽然有一处以上的递归调用语句,但各次递归调用语句的参数只和主调函数有关,相互之间参数无关,并且这些递归调用语句处于算法的最后

案例引入
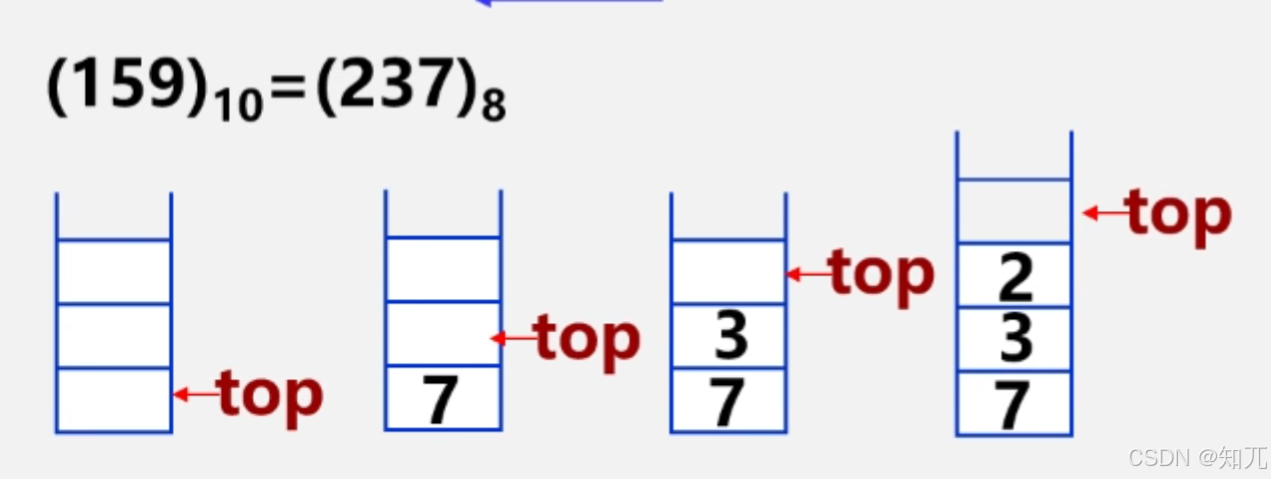
进制转换
- 十进制整数 N 向其他进制数d(二、八、十六)转换
- 转换法则:除以 d 倒取余
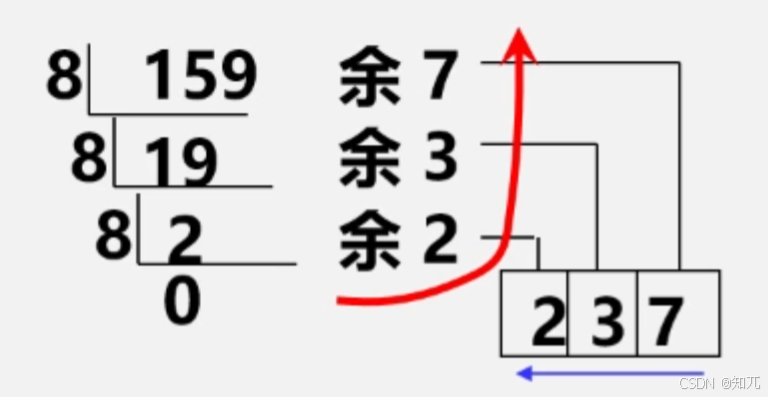
- 使用栈
括号匹配的检验
- 假设表达式中允许包含两种括号:圆括号和方括号
- 其嵌套的顺序随意,即:
- ( [ ] ( ) ) 或 [ ( [ ] [] ) ] 为正确格式
- [ ( ] ) 为错误格式,交叉了,只能嵌套
- ( [ ( ) ) 或 ( ( ) ] ) 为错误格式,数量不对
- 遇到左括号,就放进栈中,遇到右括号,就与左括号匹配,然后把左括号出栈
- 最后进入右方括号,无法匹配左方括号

表达式求值
- 表达式的组成
- 操作数(operand):常数、变量
- 运算符(operator):算术运算符、关系运算符和逻辑运算符
- 界限符(delimiter):左右括弧和表达式结束符
- 任何一个算术表达式都由操作数(常数、变量)、算术运算符(+ - * /)和界限符(括号、表达式结束符#、虚设的表达式符#)组成
- 如:# 3 * (7 - 2) #
- 为了实现表达式求值。需要设置两个栈:
- 一个是算法栈OPTR,用于寄存运算符
- 另一个称为操作数栈OPND,用于寄存运算数和运算结果
- 求值的处理过程是自左至右扫描表达式的每一个字符
- 当扫描到的是运算数,则将其压入栈OPND
- 当扫描到的是运算符时
- 若这个运算符比OPTR栈顶运算符的优先级高,则入栈OPTR,继续向后处理
- 若这个运算符比OPTR栈顶运算符有限级低,则从OPND栈中弹出两个运算数,从栈OPTN中弹出栈顶运算符进行运算,并将运算结果压入栈OPND
- 继续处理当前字符,直到遇到结束符为止
舞伴问题
- 假设在舞会上,男士和女士各自排成一队。舞会开始时,依次从男队和女队的队头各自出一个配成 舞伴。如果两对初始人数不相同,则较长的那一队中未配对者等待下一轮舞曲
- 要求写算法模拟上述舞伴配对问题
思路:
- 先入队的男士或女士先出队配成舞伴。因此该问题具有典型的先进先出特性,可以用队列作为算法的数据结构
- 首先构造两个队列
- 依次将队头元素出队配成舞伴
- 某队为空,则另外一队等待着则是下一舞曲第一个可获得舞伴的人
