- 集合(Collection):用来存储和操作一组对象。集合类通常都是在 java.util 包下。
常见的集合:
List:有序集合,元素可重复,用collections.sort()对List进行排序(常见实现类(子类)有ArrayList、LinkedList)
Set:无序集合,元素不可重复;可用作字符串去重(HashSet、TreeSet、 LinkedHashSet)
Map:键值对(HashMap、TreeMap、LinkedHashMap 和 Hashtable)
Queue:队,先进先出
Stack:栈,后进先出
1. List
1. List和set的区别
List: 有序,可重复
Set: 无序,不可重复
2. ArrayList和LinkedList的区别
ArrayList: 采用数组实现,可随机访问,插入和删除性能不好(移动元素)
LinkedList:采用双向链表实现,不可随机访问,插入和删除性能好
3. 数组与ArrayList的区别
| 类型 | 数组 | ArrayList |
| 存放类型 | 基本类型、对象 | 对象 |
| 内存大小 | 固定,初始化指定 | 动态大小 |
| 数据存放 | 连续存放 | 对象的引用是连续,对象本身在内存中不一定连续 |
| 插入与删除 | 不能添加和删除 | 可以在任意位置出入和删除 |
| 效率 | 高 | 低 |
4. ArrayList扩容机制
当执行add()操作时,容量不足,行扩容:
(1)计算新的容量,一般是当前容量的1.5倍
(2)创建新的数组,其长度为新的容量,把当前数组的元素复制到新的数组
(3)更新容量和数组引用
扩容涉及到数组复制和重新分配内存,引起性能开销。为尽量避免扩容,可在创建时指定初始容量。
5. List去重/排序
- 使用stream的distinct方法(去重)
-
public static List<Integer> stream (List<Integer> list){ -
return list.stream().distinct().collect(Collectors.toList()); -
}
- 转为HashSet、TreeSet(去重且排序)
-
public static List<Integer> HashSet (List<Integer> list) { -
HashSet<Integer> h = new HashSet<>(list); -
return new ArrayList<>(h); -
}
篇幅限制下面就只能给大家展示小册部分内容了。整理了一份核心面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记【点击此处即可】免费获取
2.Map
Map(接口)一种映射关系(key、value)。Map接口有多个实现类(子类),其中最常用的是HashMap、TreeMap和LinkedHashMap。
1. HashMap、TreeMap、LinkedHashMap的区别
| 类型 | HashMap | TreeMap | LinkedHashMap |
| 按插入顺序排放 | 不支持 | 不支持 | 支持 |
| 按key排序 | 不支持 | 支持,默认按key升序排序 | 不支持 |
| 数据结构 | 数组+链表+红黑树 | 红黑树 | HashMap+双向链表 |
| Kv值 | 只允许一条key的值为null;允许多条value的值为null | 不允许key的值为null | 同HashMap |
8. HashMap
实现:
JDK<1.8,数组+链表;JDK>1.8,数组+链表+红黑树
当链表长度大于8,数组长度大于等于64,自动升级为红黑树;红黑树节点小于6,红黑树转为链表
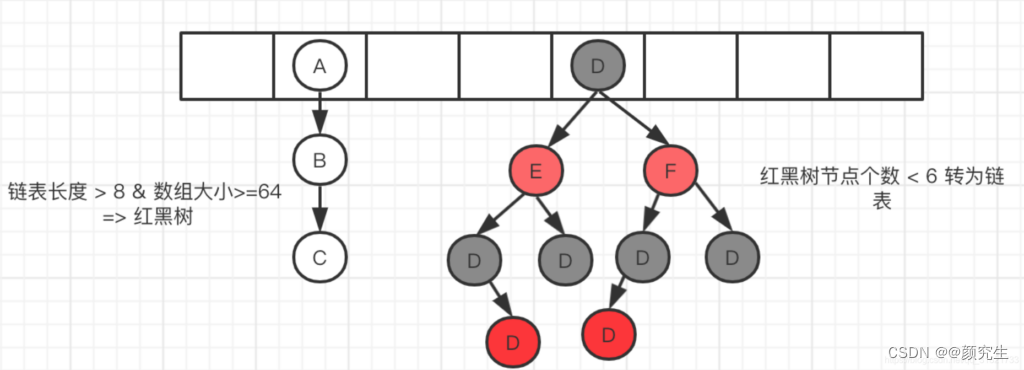
解决冲突:链地址法(JDK7是头插法;JDK8是尾插法)
9. collection和collections的区别
collections是一个工具类,在java.util中。它提供一些列的静态方法包括排序、查找、
同步等,用于操作集合对象
Eg: List<String> myList = new ArrayList<>();
myList.add("Apple");
myList.add("Orange");
Collections.sort(myList);
三.多线程
1. 线程的六种状态
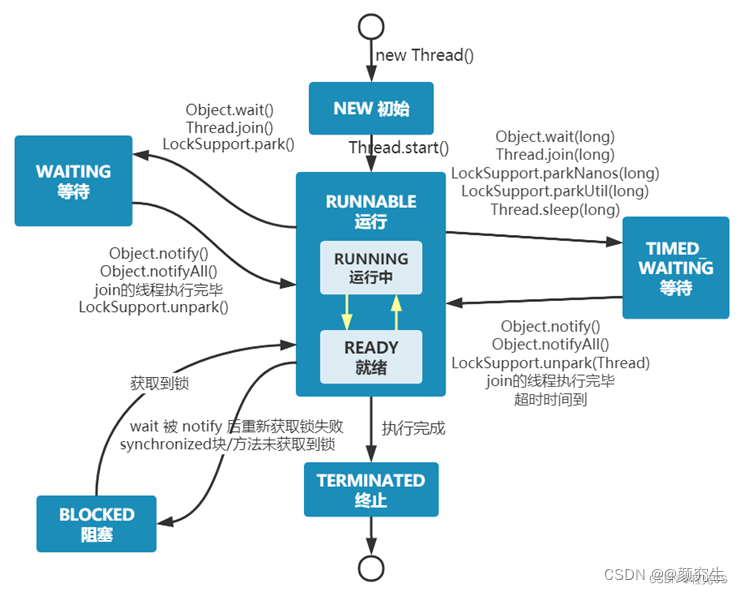
- 初始状态New ß new了一个线程
- 就绪状态Runnable(运行和就绪状态runing/ready)
- 阻塞状态Blocked ß synchronized方法拿不到锁
- 等待状态Waiting ß wait方法(手动notify解锁)
- 计时等待 Timed_Waiting ß sleep/休眠转态(自动唤醒)
- 终止状态Terminated ß 执行完所有任务,run方法已经结束
2. 实现多线程的三种方式(一个类,两个接口)
a.继承Thread类(重写run方法)
b.实现Runnable接口(重写run方法)
c.实现Callable接口(重写call方法)
3. 停止线程方法
1. stop方法,强制结束(方法已经过时)
让线程的run方法结束来停止线程:
2. 使用共享变量(声明一个共享变量(flag),根据变量的值(flag=true)来判断并结束线程)(全局)
3. 使用interrupt方法(改变interrupt的状态(true/false))(线程内部)(推荐使用)
4. sleep() 和 wait() 有什么区别?ip
用于暂停线程
类的不同:sleep()来自Thread类;wait()来自Object类(任何对象皆可调用)
释放锁:sleep()不会释放锁(睡着了);wait()会释放锁(等待久了就会放弃)
用法不同:sleep()时间到会自动恢复;wait()可用notify()\notifyAll()手动唤醒
对用转态:sleep属于TIME_WAITING;wait属于WAITING
sleep暂停线程、但监控状态仍然保持,结束后会自动恢复
5. 什么是死锁,如何避免
是指两个或多个事务相互等待对方释放资源下,无法继续执行的状态
避免死锁:
- 避免嵌套事务: 尽量减少事务的嵌套层数
- 固定顺序加锁
- 设置合理的超时时间
- 资源预分配
- 回滚规则:出现死锁时自动回滚并释放资
6. 项目哪些地方用到多线程
定时任务:定时处理数据进行统计
异步处理:发邮件、发短信、记录日志
批量处理,缩短响应时间
7. JMM
所有变量都存储在主内存
所有线程都有自己的工作内存,保存了使用到变量的主内存的副本拷贝
线程对变量的操作均在工作内存中(先拷贝到工作内存->操作->写回主内存)
不同线程不能直接访问对方工作内存的变量,线程之间值的传递通过主内存完成
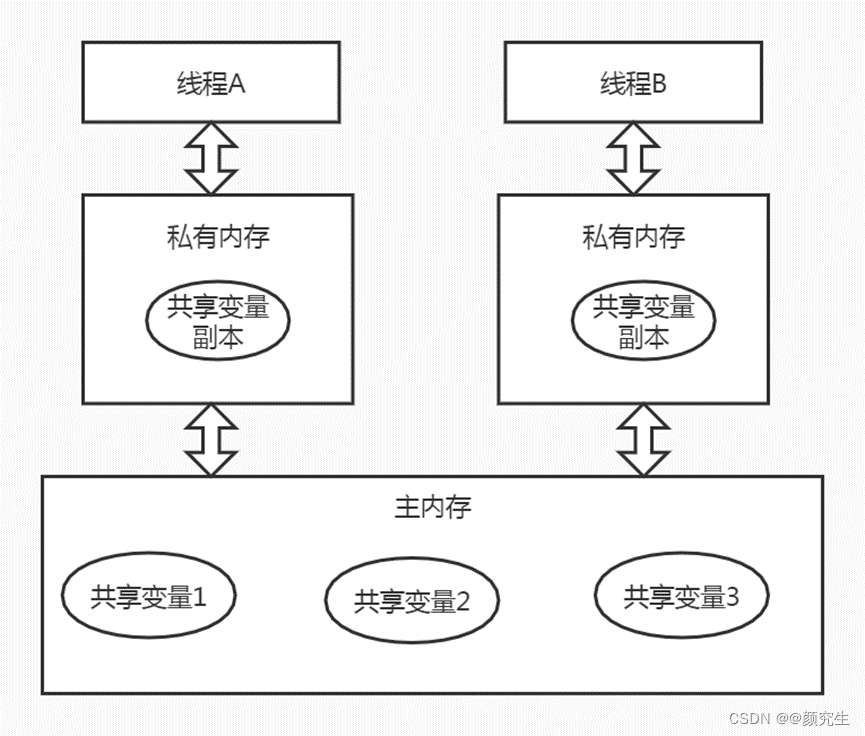
JMM三大特性:
原子性:一个或多个操作在执行过程不被中断
可见性:一个线程对共享变量的修改,另一个线程能立即看到
有序性:程序执行的顺序按代码的先后顺序执行
Happens-before八大原则
程序顺序原则:按程序顺序执行
锁原则:先解锁后加锁
Volatile变量原则:volatile变量的写发生在读之前,保证volatile变量的可见性
线程启动原则:线程的start()方法先于他的每一个操作
传递性原则
线程终止原则:线程的所有操作先于线程的终止
线程中断原则:中断方法interrupt()先于监测发生线程中断的方法interrupted()方法
对象终结原则:对象构造函数执行的结束,先于finalize()方法
Synchronized的作用
保证原子性、有序性、可见性
Volatile的作用
保证有序性、可见性,不保证原子性
8. 为什么使用线程池
没有线程池情况下,多次创建、销毁线程开销较大。如果开辟的线程执行完当前任务后不销毁,之后的任务可以复用已创建的线程,可以降低开销,控制最大并发数。
优点:降低资源消耗、提高响应速度、提高线程的可管理性
缺点:1.多线程会占用CPU
9. 线程池本身的缺点:
a.适用于生存周期较短的任务
b.不能对线程池的任务设置优先级
c.不能表示线程的各个状态(如启动、终止线程)
d. ...
10. 线程池的参数
1. corePoolSize:常驻核心线程数
2. maximumPoolSize:最大线程数
3. keeyAliveTime:线程存活时间,达到该时间后线程会被销毁,直到corePoolSize个线程
4.workQueue:工作队列,提交的任务会被放到这个队列里
5.threadFactory:线程工厂,用来创建线程
6.handler:拒绝策略。当线程池里线程被耗尽,队列也满时会被调用;默认拒绝策略AbortPolicy,丢弃任务并抛出运行异常
11. 拒绝策略的类型(饱和策略)
AbortPolicy:丢弃任务并抛出异常
CallerRunsPolicy:重新尝试提交该任务
DiscardPolicy:直接抛弃当前任务但不抛出异常
DiscardOldestPolicy:抛弃队列里等待最久的任务并把当前任务加入队列
12. 阻塞队列
ArrayBlockingQueue:底层时由数组组成的有界阻塞队列
LinkedBlockingQueue:底层时由链表组成的有界阻塞队列
PriorityBlockingQueue:阻塞优先队列
DelayQueue:
SynchronousQueue
。。。
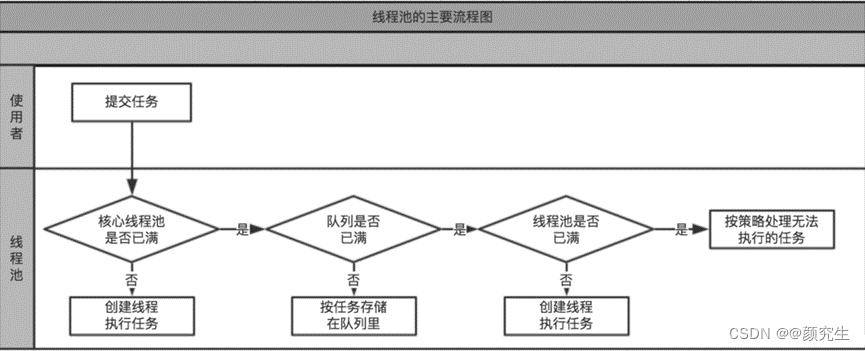
13. 线程池执行流程
14. 线程池状态
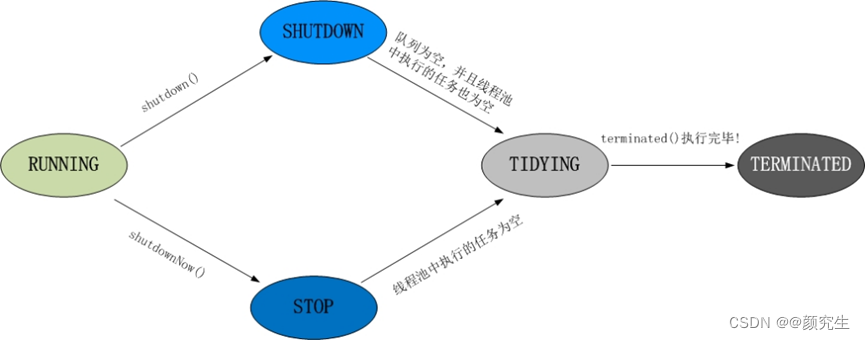
Running:正常运行,既能接受新任务,也会处理队列中的任务
ShutDown:不接受新任务,但能处理已添加的任务
Stop:不接受新任务,也不处理已添加的任务,终止正在处理的任务
Tidying:线程池没有任务在执行,会进入Tidying状态
Terminated:调用terminated()后,线程池彻底终止时进入的状态
Juc
15. 简述Lock与ReentrantLock
Lock时Java并发包的顶层接口
ReentrantLock是Lock接口的一个实现类,与synchronized 一样是可重入。ReentrantLock默认情况是非公平的,也可使用构造方法指定公平。一旦使用公平锁,性能下降
16. CAS
CAS是一种乐观锁
CAS原理:
从内存中读取当前值(预期值)
预期值与内存中实际值进行比较
若相等,表示其他线程没有修改该值,进行更新操作;若不等,表示已经修改,更新失败,重新尝试。
优点:性能高(一直自旋等待锁)
缺点:CPU开销大
ABA问题:一个值原来是A,然后变成B,最后又变成A,CAS会认为他没有变
能保证一个共享变量原子操作:要保证多个时,要使用Synchronized
17. AQS
篇幅限制下面就只能给大家展示小册部分内容了。整理了一份核心面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafka 面试专题
需要全套面试笔记【点击此处即可】免费获取
18. ynchronized与volatile
Ynchronized:
锁定的对象,只有当前线程可以访问,其他线程阻塞
使用范围:变量、方法、类
可以保证变量的可见性、原子性;可能造成线程阻塞;标记的变量可以被编译器优化
Volatile:
本质是告诉jvm当前变量在工作内存的值是不确定的,需要从主内存中读取
使用范围:变量
仅能实现变量的可见性;不会造成线程阻塞;标记的变量不会被编译器优化
19. synchronized 和 Lock 有什么区别?
| 类型 | synchronized | Lock |
| 使用范围 | 可给类、方法、代码块加锁 | 只能给代码块加锁 |
| 获取/释放方式 | 不需要手动获取锁和释放锁 | 需要自己手动加锁和释放锁 |
| 是否会死锁 | 发生异常会自动释放锁,不会造成死锁 | 如果不用unlock释放锁会造成死锁 |
| 属性 | java内嵌关键字,在jvm层面 | Java类(接口) |
| 判断是否获得锁 | 无法判定 | 可以判定 |
20. 线程池创建方法
1. newFixedThreadPool:创建固定大小线程池。
2. newSingleThreadExecutor:单线程线程池
3. newCachedThreadPool:可缓存线程池,maximumPoolSize
4. newScheduleThreadPool:定时线程池
5. newWorkStealingPool:拥有多个任务的线程池
四. JVM
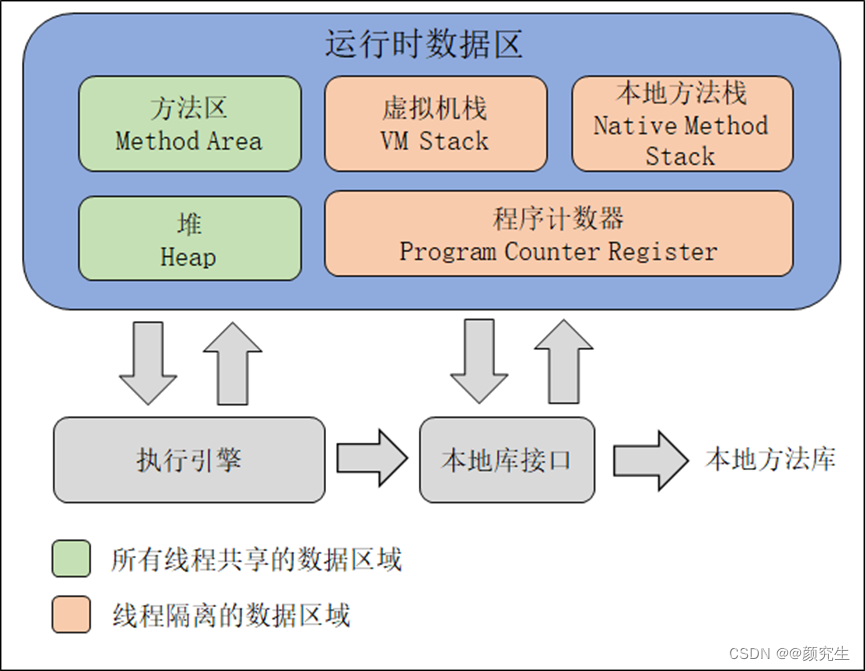
JVM内存模型
用于描述JVM如何管理内存以支持java程序执行的规范
JVM定义的内存区域:
(1)线程共享数据区:
方法区:类信息(被虚拟机加载过)、静态变量、常量(被Final修饰)
堆:(new)对象实例、数组。堆又分为新生代和老年代
(2)线程隔离数据区:
栈/虚拟机栈(Stack/VM Stack): 基本类型和引用类型(String)的变量;存储方法调用的局部变量、操作数栈、方法的返回值
本地方法栈:存储java调用本地方法(Native方法)的相关数据(根栈是一样的)
程序计数器(Program Counter Register):保存当前线程执行的字节码指令地址;不会发生内存泄露
1. JVM类加载过程
1.加载:
通过全类名获取类的二进制字节流
将类的静态存储结构转化为方法区运行时数据结构
在内存中生成类的Class对象,作为方法区数据入口
2.验证:检查载入的class文件数据的正确性
3.准备:在方法区为类变量分配内存并设置为零值
4.解析:将常量池内的符号引用转换为直接引用
5.初始化:初始化类静态变量,执行静态语句块
2. JDK8垃圾回收器流程(内存管理)
JDK8内存模型
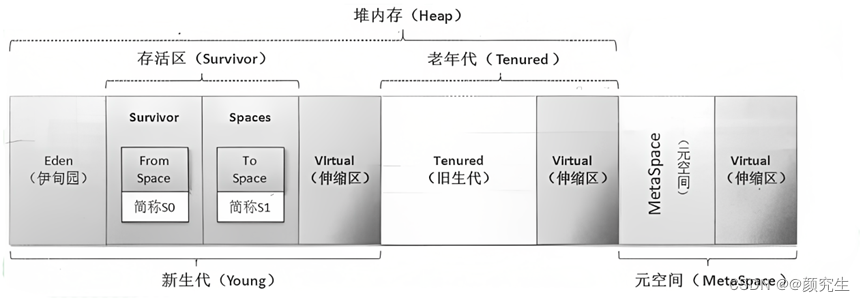
垃圾收集流程:
1. new一个对象时,首先保存在Eden区,前提判断Eden空间是否充足
空间足够:在Eden区为新对象申请空间
空间不够:执行MinorGC(年轻代GC)
2. MinorGC会回收不活跃对象,释放Eden间,接着再判断空间是否充足
空间足够:在Eden区为新对象申请内存空间
空间不够:将部分活跃对象保存在Survivor区
3. Survivor空间也要先判断是否充足
空间足够:保存Eden发来的对象。此时Eden空间得以释放,在Eden区为新对象申请空间
空间不够:将Survivor区部分活跃对象保存在Tenured区
4. 依然要判断Tenured空间是否充足
空间足够:保存Survivor发来的对象,在Eden区为新对象申请空间
空间不够:将执行FullGC(完全GC),以释放年轻代和老年代中保存的不活跃对象。
5. 执行FullGC后再次判断Tenured区空间
空间足够:保存Survivor发来的对象,Survivor也会保存Eden发来的对象,然后就可以在Eden区为新对象申请空间
空间不够:抛出OutOfMemoryError(OOM),程序将中断运行
3. Java引用类型
强引用:这个对象永远不会被回收,即使内存不足;使用new方法创建
(User user = new User() )
软引用:只有内存不足时,JVM才会回收该对象
弱引用:不管内存是否充足,只要发生GC,弱引用就会被回收
虚引用:无法通过虚引用获取一个对象的真实引用
4. Young GC(Minor GC)
多数情况,对象在年轻代中的Eden区进行分配,若Eden没有足够的空间,就会触发YGC
5. Full GC(Major GC)
FGC处理的区域包括年轻代和老年代
以下会触发Full GC:
1.老年代使用率达到了一定阈值(默认92%)
2.元空间扩容到指定值
3.程序执行了System.gc():只是提醒JVM执行Full GC,不一定执行
6. CMS与G1的区别
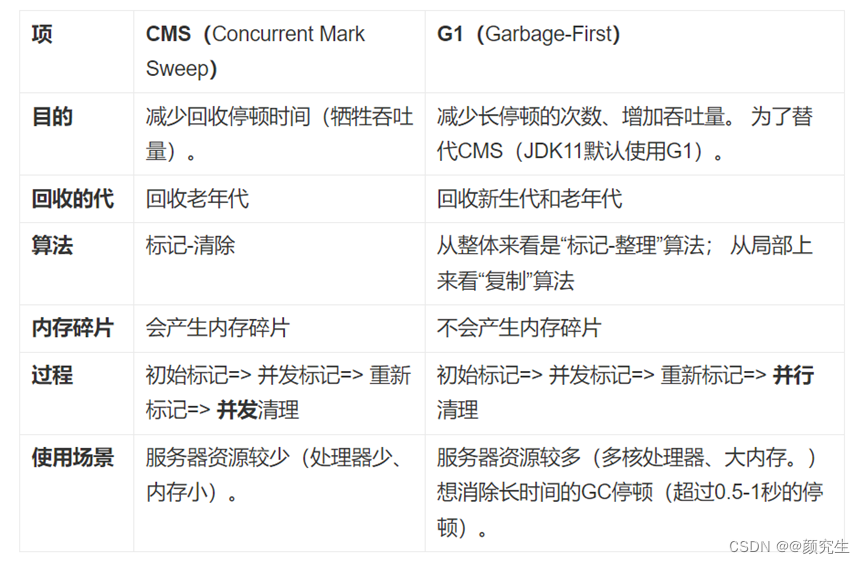
7. JVM调优的常用配置
-Xms:初始堆大小
-Xmx:最大堆大小
-Xmn /-XX:NewSize:年轻代大小
-XX:MaxNewSize:年轻代最大值
-XX:PermSize:老年代/永生代初始值
-XX:MaxPermSize:老年代/永生代最大值
-XX:NewRatio:新生代与老年代的比例
五.MySQL
1. 基础
1. SQL优化你了解哪些?
a. 避免全表扫描: 在没有索引的情况,对整个表进行扫描;应该使用索引来查询
b. 避免使用select * (查询所有列):指定所需的列可以减少数据传输量和查询时间
c. 避免使用子查询(嵌套查询):子查询会增加数据库的负担,导致性能下降
d. 使用join代替子查询:join可将多个查询合并为一个查询,减少数据库的负担
e. 避免使用where子句中的函数:会对整个表进行计算,导致性能下降
f. 避免使用order by 中的函数:会对整个结果集进行计算,导致性能下降
g. 使用explain命令分析查询计划: explain命令可查看查询执行计划,从而确定哪部分需要优化
总之,SQL优化是一个综合性的过程,需要综合考虑多个因素。通过合理的SQL编写和优化,可以提高数据库的性能和效率。
2. Mysql日志你了解哪些,有什么作用?
a. 二进制日志(Binary Log): 记录了MySQL数据库所有的增删改操作;用于主从复制、数据备份和恢复等场景
b. 慢查询日志(Slow Query Log):记录执行时间超过指定阈值的SQL语句
c. 错误日志(Erroy Log):记录 SQL运行时的发生的错误信息,如连接问题、权限问题
3. 针对一条慢 SQL,通常会怎样去优化它?
a. 优化SQL语句
b. 添加索引:对经常被查询的列建立索引
c. 分页查询:对于数据量比较大的表,使用分页避免一次性查询所有的数据,从而减少查询时间
d. 缓存结果集:对于一些计算复杂的SQL语句,将查询结果缓存起来,避免重复计算
e. 调整服务器配置:若以上都无法解决问题,可增加内存、优化硬盘读写等方式提高数据库性能
在进行SQL语句优化时,需要综合考虑多个因素,包括数据量、查询频率、硬件配置等等。
4. 数据库的基本属性
ACID是数据库系统中的四个基本属性,用于描述事务的正确性、一致性、隔离性、持久性。
原子性(A):保证事务中的所有操作要么全部成功,要么全部失败回滚
一致性(C):保证事务执行前后,数据库应保持一致性状态,避免数据的不一致性
隔离性(I):多个事务操作同一数据时,事务之间相互隔离(一个事务执行不被其他事务干扰)
持久性(D):一旦事务提交,对数据的修改应该是永久性的,即使系统发生故障或崩溃也不会丢失
5. 索引失效的情景
LIKE以 % 或 _ 开头
OR语句前后没有同时使用索引
联合索引没有遵循最左前缀原则
索引列数据类型出现隐式转换
对索引列进行计算或使用函数
ORDER BY 使用错误
全表扫描速度比索引速度快
6. 事务的隔离级别(级别越高,数据一致性越强,并发性能越低)
1.读未提交:允许事务读取未提交(修改但未持久化)的数据;存在脏读、不可重复读和幻读(最低隔离级别)
2.读已提交:只允许读取已提交的事务;存在不可重复读、幻读(多数数据库默认隔离级别)
3.可重复读:同一条件的查询返回的结果是一样的 ;存在幻读(MySQL默认隔离级别)
4.可串行化:(最高隔离级别)强制所有事务以串行方式执行;解决所有并发问题,但导致性能下降
7. 脏读、幻读、不可重复读
脏读:读取了一个事务未提交的数据(未持久化),这个数据在后续的事务执行中可能会修改或删除
幻读:事务在执行中,两次查询相同条件的数据,返回了第一次查询未返回的新数据,这是因为其他事务插入的新的数据
不可重复读:事务在执行时,两次读取了同一个数据的结果不一致,因为另一个事务对其进行修改或删除
8. MySQL索引的优点、缺点
优点:
提高查询效率;改善排序性能;优化分组操作;支持范围查询(eg: 大于、小于)
缺点:
降低数据写入效率;增加了查询优化器的选择时间;占物理空间
9. 创建索引的原则
对查询频率高的字段创建索引
为经常需要排序、分组和联合操作的字段建立索引
尽量使用唯一以索引
使用短索引
使用前缀来索引
索引的数目不要太多
避免索引失效
10.drop delete truncate的区别
Drop: 删除数据库中的对象(如:表、索引等)
Delete: 删除表中的数据行,可回滚撤销删除
Truncate:快速删除表中的所有数据,不可回滚数据
11. 四大范式
第一范式:数据库中每个字段都是不可分割的原子数据项
第二范式:在1NF基础上,非主键列完全依赖于主键(通过主键唯一确定非主键列数据)
第三范式:在2NF基础上,非主键列之间不应该存在传递依赖关系的(通过另一个与主键依赖)
第四范式:在3NF基础上,复合关键字(多个属性组成的候选键或主键)之间不能存在函数依赖关系
12. 段式存储:将内存划分为若干个段
访问段式存储地址需要:段号和段内地址(偏移)