一. 概述
前面两篇文章大致介绍了CFS调度的基本原理和代码实现(详解CFS调度(一)-CSDN博客、详解CFS调度(二)-CSDN博客)。本篇介绍一下组调度的概念和实现。
我们假设服务器有两个用户在使用,如果两个用户各自启动了一个task(假设都是优先级相同的普通进程),那他们各自占用一半的CPU资源;那如果A用户启动了9个task,而B用户只启动了一个task,那A用户将占用cpu 90%的资源,这与我们预期相去甚远。我们可能希望两个用户各自占据一半的CPU资源,无论每个用户后续有多少个task,都在自己的cpu份额中进行细分,而组调度就是用来实现这个功能的。引入组调度后,多个task可以归并到一个group中,以组为单位计算负载,分配CPU资源,以保证资源分配、调度更加合理。
Linux kernel中需要使能CONFIG_FAIR_GROUP_SCHED来启用CFS组调度,因此也可以搜索这个config来查看组调度的关键逻辑都在代码中什么位置。
二. 原理简述
在没有组调度的情况下,单cpu中有三个task,他们占据的cpu资源如下
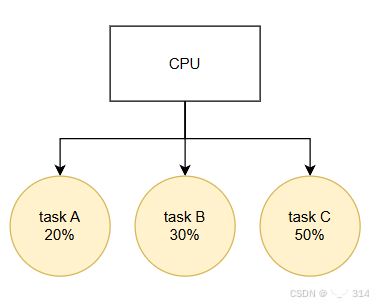
在引入组调度后,可以将task A和task B放在一个group中,该group所占据的cpu资源与其包含的所有task的权重有关。
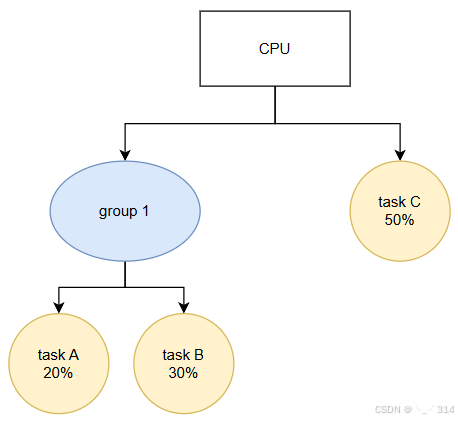
task group相关结构体是task_group,一个group也被视为一个调度实体,所以也有sched_entity成员;cfs_rq是他的runqueue,保存他所掌管的所有task,在多核系统中,一个group的多个task可能运行在不同的cpu中,所以task group在每个cpu上都会有一个se和cfs_rq。shares用来保存该task group的权重,相当于task的weight。
/* Task group related information */
struct task_group {
struct cgroup_subsys_state css;
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each CPU */
struct sched_entity **se;
/* runqueue "owned" by this group on each CPU */
struct cfs_rq **cfs_rq;
unsigned long shares;
/* A positive value indicates that this is a SCHED_IDLE group. */
int idle;
...
}下面举个例子,看多核cpu中存在group时如何分配cpu资源
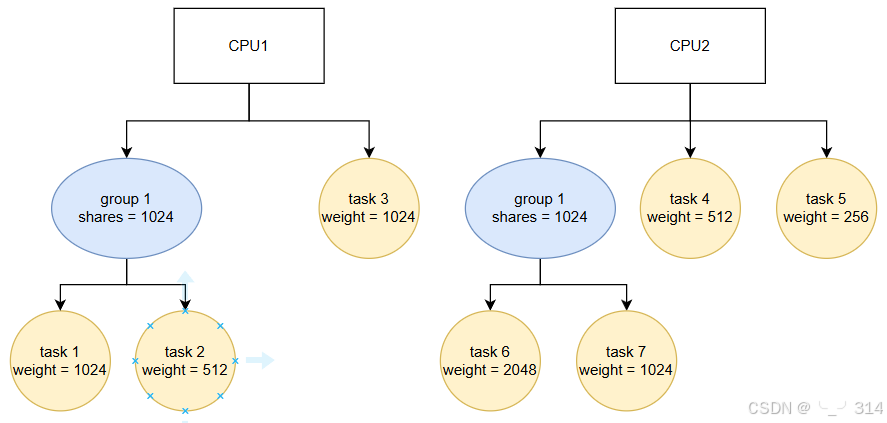
group在shares时1024,在cpu1上有两个task,weight总和为1024+512=1536;在cpu2上有两个task,weight总和为2048+1024=3072。相当于它在cpu1上的weight = 1024*1535/(1536+3072)=341,在cpu2上的weight = 1024-341=683。所以group1在cpu1上能占用的cpu资源为:341/(341+1024) = 25%,在cpu2上能占用的cpu资源为:683/(683+512+256) = 47%,然后每个cpu的group1中的task再按照task weight分配对应的cpu资源。
三. 代码详解
主要看一下如何计算shares值,也就是task group的权重。主要涉及函数是calc_group_shares。由于该计算涉及到很多近似替换,所以我们先看公式推导:
涉及到的变量:
tg->weight: task group的总权重
grq->load.weight: task group在当前cpu上的runqueue中所有task的总权重
ge->load.weight: task group在当前cpu上的调度实体的权重
grq->avg.load_avg: task group在当前cpu上的平均负载
grq->load.weight: task group在当前cpu上的总权重
task group在当前cpu上的ge的权重是由当前cpu上group runqueue中所有task的总权重占该task group在所有cpu上task总权重的百分比决定的,即
tg->weight * grq->load. Weight
ge->load. Weight = ----------------------------- (1)
\Sum grq->load.weight但计算所有task总权重(即 \Sum grq->load.weight)时,由于需要去访问其他cpu上的数据,这个会访问会很慢,而且在多核架构中,多个cpu都做类似操作,会引起很激烈的数据竞争。想要避免这个问题,最好的办法是只访问本cpu上的数据或全局变量。因此,我们可以用grq->avg.load_avg来代替grq->load.weight,上述公式就变为了:
tg->weight * grq->avg.load_avg
ge->load. Weight = ------------------------------ (3)
tg->load_avg其中,分子中的grq->avg.load_avg是当前cpu的平均负载,而tg->laod_avg是全局变量
由于load_avg是缓慢变化的量(这个变量设定的目的就是为了让负载变化更平滑),这会导致一个问题:当该group从idle状态到有一个task开始运行时,由于load_avg只会随时间慢慢增长,这就导致新创建的进程无法及时运行,出现较大的延迟。
如果只有一个task,那么公式(1)中的分母其实就不需要计算Sum了,因为只有一个task,自然就只会在当前cpu上运行,所以公式(1)就变成了:
tg->weight * grq->load. Weight
ge->load. Weightt = ----------------------------- = tg->weight (4)
grp->load.weight为了兼顾这种情况,我们需要让公式(3)在这种特殊情况下可以达到公式(4)的效果:
tg->weight * grq->load. Weight
ge->load.weight = --------------------------------------------------- (5)
tg->load_avg - grq->avg.load_avg + grq->load.weight注意上述公式,去掉 tg->load_avg - grq->avg.load_avg 就变成了公式(4),而tg->load_avg - grq->avg.load_avg可以计算出除当前cpu外所有其他cpu上的总负载,在加上当前cpu上的负载,最终就等于tg->load_avg或者说是 \Sum grq->avg.load_avg。
经过这么多转换,我们终于可以在不访问其他cpu数据的情况下,能计算出ge->load.weight,且能兼顾特殊情况。但不要高兴的太早!
如果当前group重新进入idle了会出现什么情况?这时候grq->load.weight就为0,且在单cpu的情况下,tg->load_avg == grq->avg.load_avg,所以这时候分母就为0了。除0是会直接崩溃的,为避免这种异常,还需要做一下特殊处理:我们取weight和load_avg的较大值,这样即使weight为0了,load_avg也不会为0。
tg->weight * grq->load.weight
ge->load.weight = ----------------------------- (6)
tg_load_avg'
tg_load_avg' = tg->load_avg - grq->avg.load_avg +
max(grq->load.weight, grq->avg.load_avg)以上,我们就完成了ge->load.weight的整个计算公式推导。
完全搞懂了这个公式,再看代码就很好理解了,带入对应的变量计算就好了
static long calc_group_shares(struct cfs_rq *cfs_rq)
{
long tg_weight, tg_shares, load, shares;
struct task_group *tg = cfs_rq->tg;
tg_shares = READ_ONCE(tg->shares); //shares就是公式中的tg->load.weight
/*
*避免出现除0操作,这里取weight和load_avg的较大值
*/
load = max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg);
tg_weight = atomic_long_read(&tg->load_avg);
/* Ensure tg_weight >= load */
/*
*相当于公式中tg->load_avg - grq->avg.load_avg,这里tg_load_avg_contrib是
*上一次更新时tg->load_avg的值(为了避免频繁更新,两次更新差值大于一定程度时
*才会做实际的更新操作,参考:update_tg_load_avg)
*/
tg_weight -= cfs_rq->tg_load_avg_contrib;
tg_weight += load;
shares = (tg_shares * load);
if (tg_weight)
shares /= tg_weight;
/*
* MIN_SHARES has to be unscaled here to support per-CPU partitioning
* of a group with small tg->shares value. It is a floor value which is
* assigned as a minimum load.weight to the sched_entity representing
* the group on a CPU.
*
* E.g. on 64-bit for a group with tg->shares of scale_load(15)=15*1024
* on an 8-core system with 8 tasks each runnable on one CPU shares has
* to be 15*1024*1/8=1920 instead of scale_load(MIN_SHARES)=2*1024. In
* case no task is runnable on a CPU MIN_SHARES=2 should be returned
* instead of 0.
*/
return clamp_t(long, shares, MIN_SHARES, tg_shares);
}