大家好,我是灵魂画师向阳
前言
AI绘画Stable Diffusion 在 ControlNet 出现之前,基于扩散模型的 AI 绘画是极难控制的,因为扩散的过程充满了随机性。
如果只是纯粹自娱自乐,这种随机性并不会带来多大困扰;但在产业化上应用就难以普及了,因为随机性的直接导致的就是缺乏稳定性,每次出图都要依赖不断抽卡,极大影响了工作效率。
然而 ControlNet 赋予了我们自由组织画面内容的能力:固定构图、定义姿势、描绘轮廓,单凭线稿就能生成一张丰满精致的插画,甚至有人用它画出了二维码 … ControlNet 的出现使得对 AI 绘画的完全控制成为现实。
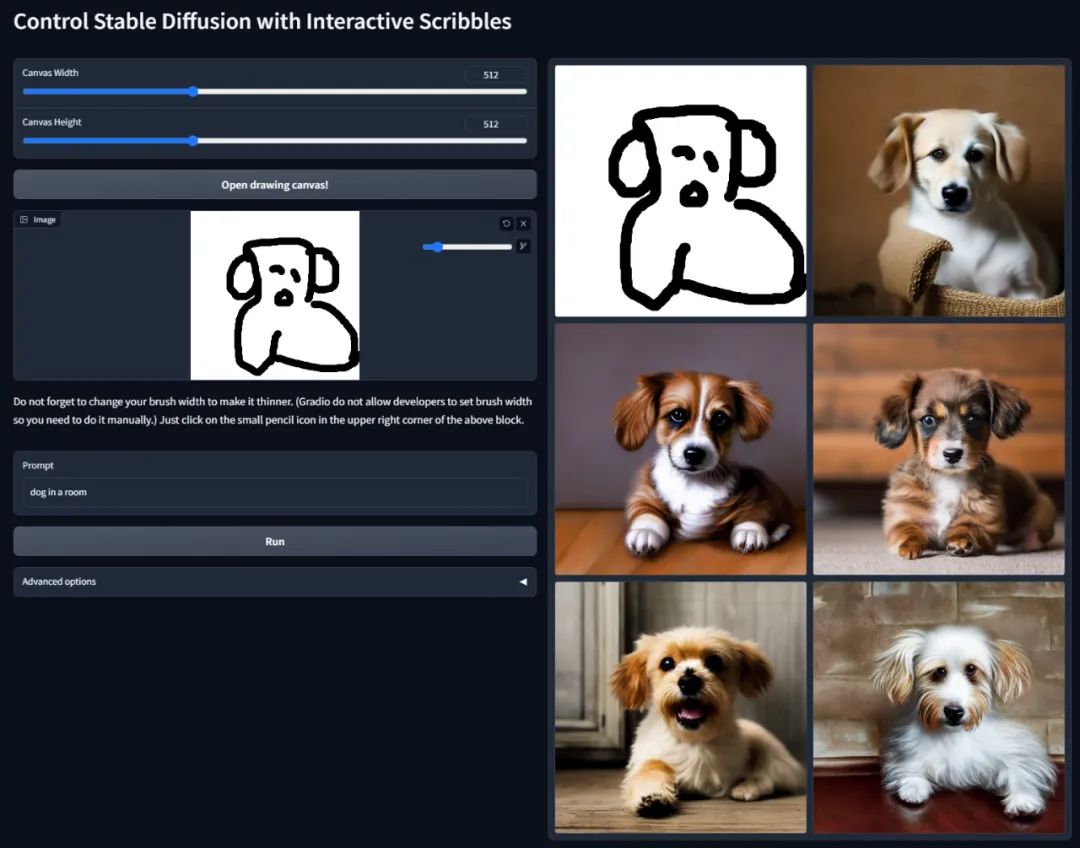
基本原理
ControlNet 亦即控制网络,它本质上是 SD 的一个扩展插件。在作用原理上,它和 LoRA 是有许多相似的地方的,定位都是对大模型做微调的额外网络。
控制网络的核心作用是基于一些额外输入给它的信息、来给扩散模型的生成内容提供明确的指引。
举个例子,譬如在 Prompt 中输入 “跳舞” 的提示词,AI 可以画出无数种跳舞的姿势,在过去,我们只能通过图生图让 AI 仅可能地接近我们期望的那个姿势。但是 ControlNet 出现之后,我们可以通过给它输入一张纯粹记录了某种特定姿势(由 openpose 识别出来的、以点线组成的人体骨架图)信息的图片来画出指定的姿势,实现精准控制。

❝
在我刚刚学 ControlNet、得知可以调用 openpose[2] 的时候,确实有种殊途同归的感概 —— 终于又回到了我熟悉的领域:曾经被我用来研究游戏视觉 AI 辅助的 openpose,没想到竟然也可以在 AI 绘画中也占据半壁江山 …
❞
ControlNet 安装
插件安装
核心只需要安装一个插件 sd-webui-controlnet:
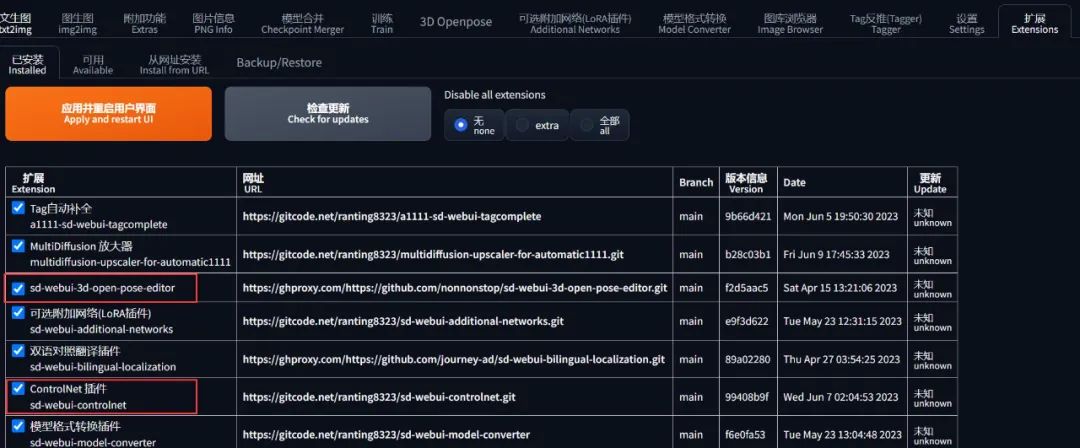
重启界面后可以看到新增的这个选区即安装完成:
另外为了后续方便编辑自定义的 pose,这里再安装一个 sd-webui-3d-open-pose-editor 插件(使用方法见
模型安装
ControlNet v1.1 (目前最新版)的常用模型都是在 huggingface 里面下载:
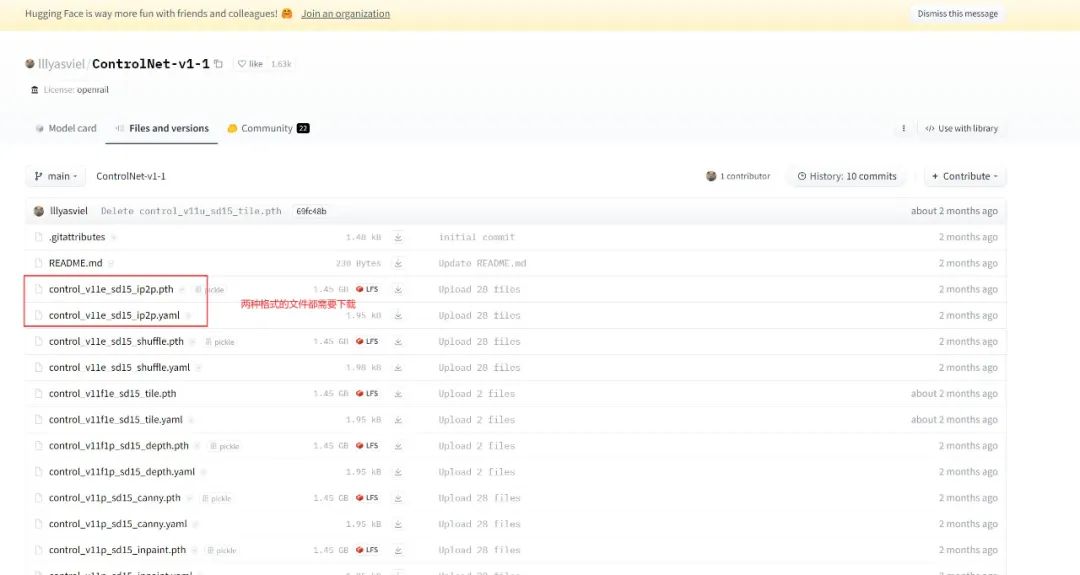
每个模型由两种文件组成:*.pth 和 *.yaml
安装某一个模型的时候,两种格式都需要下载回来、并放到 %SD/models/ControlNet/ 目录下即可使用。
注意:ControlNet模型插件下载需科学上网,如无法下载,请扫描获取模型插件安装包
预处理器安装
预处理器一般是在使用 ControlNet 的时候按需自动下载的,但是由于网络原因,可能下载不了,此时界面会报错:
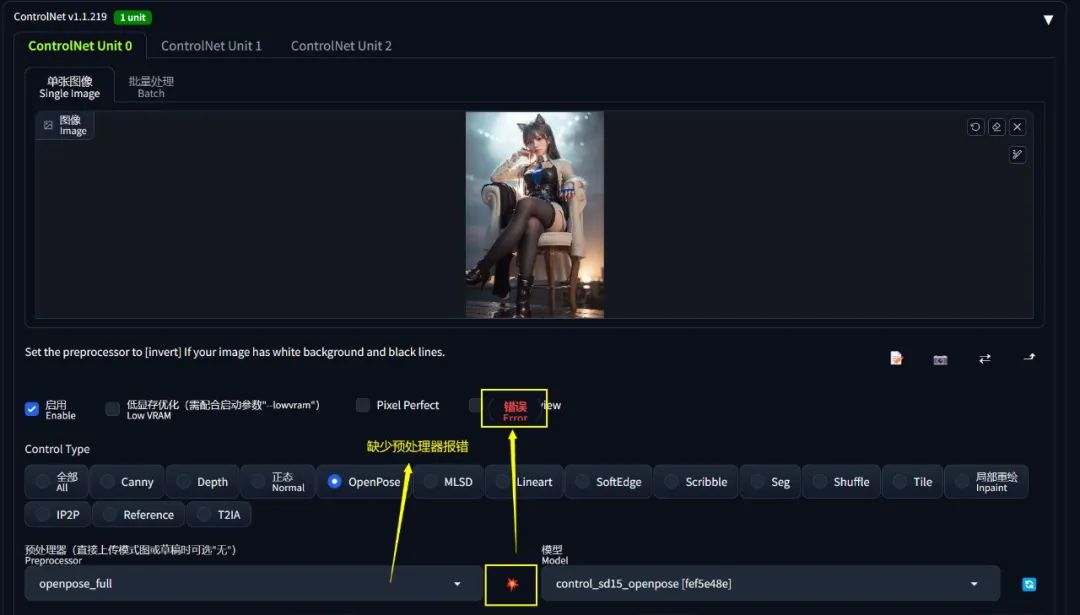
这里提供一个通用的解决方法。先在 SD 的 dos 终端中找到异常信息:
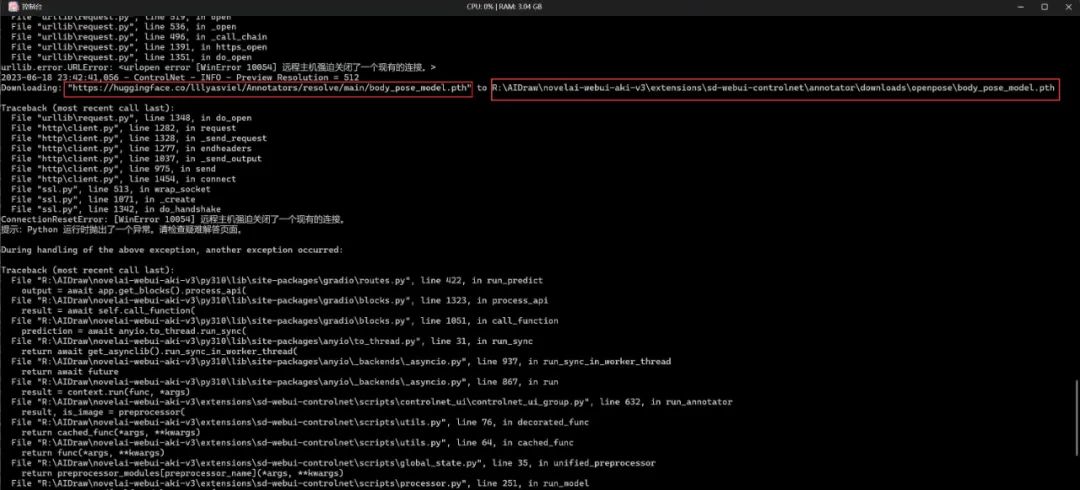
核心失败原因解读一下:
Downloading: “https://huggingface.co/lllyasviel/Annotators/resolve/main/hand_pose_model.pth” to R:\AIDraw\novelai-webui-aki-v3\extensions\sd-webui-controlnet\annotator\downloads\openpose\hand_pose_model.pth
主要就是说:下载 hand_pose_model.pth 到 %SD/extensions/sd-webui-controlnet/annotator/downloads/openpose/ 目录失败。
根本原因就是 dos 终端没科学上网导致下载不到文件,可看上方
类似地,其他预处理器也会有此问题,届时参考这个方法举一反三地处理即可。
常用 ControlNet 模型推荐
在 ControlNet v1.1 中,它能控制的方向已经远远不止人体姿态这一种,而是多达 14 个不同方向的控制,每一个方向对应一个模型。

为了方便选择困难症的同学,这里推荐最常用的几个模型(当然如果你有时间也可以把 14 个模型全部下载):
| 名称 | openpose |
|---|---|
| 功能 | 人体姿态控制、脸部特征控制(表情控制)、手部特征控制(解决画手问题) |
| 模型下载 | control_v11p_sd15_openpose.pth[7], |
| control_v11p_sd15_openpose.yaml[8] | |
| 模型位置 | %{NovelAI}/models/ControlNet/ |
| 预处理器 | body_pose_model.pth[9], |
| hand_pose_model.pth[10], | |
| facenet.pth[11] | |
| 预处理器 | |
| 放置位置 | %SD/extensions/sd-webui-controlnet/annotator/downloads/openpose/ |
| 名称 | depth |
|---|---|
| 功能 | 描绘富有空间感的多层次场景(景深控制)、人物肢体交叠(人体透视) |
| 模型下载 | control_v11f1p_sd15_depth.pth[12], |
| control_v11f1p_sd15_depth.yaml[13] | |
| 模型位置 | %SD/models/ControlNet/ |
| 预处理器1 | dpt_hybrid-midas-501f0c75.pt[14] |
| 预处理器1 | |
| 放置位置 | %SD/extensions/sd-webui-controlnet/annotator/downloads/midas/ |
| 预处理器2 | res101.pt[15], |
| latest_net_G.pth[16] | |
| 预处理器2 | |
| 放置位置 | %SD/extensions/sd-webui-controlnet/annotator/downloads/leres/ |
| 预处理器3 | ZoeD_M12_N.pt[17] |
| 预处理器3 | |
| 放置位置 | %SD/extensions/sd-webui-controlnet/annotator/downloads/zoedepth/ |
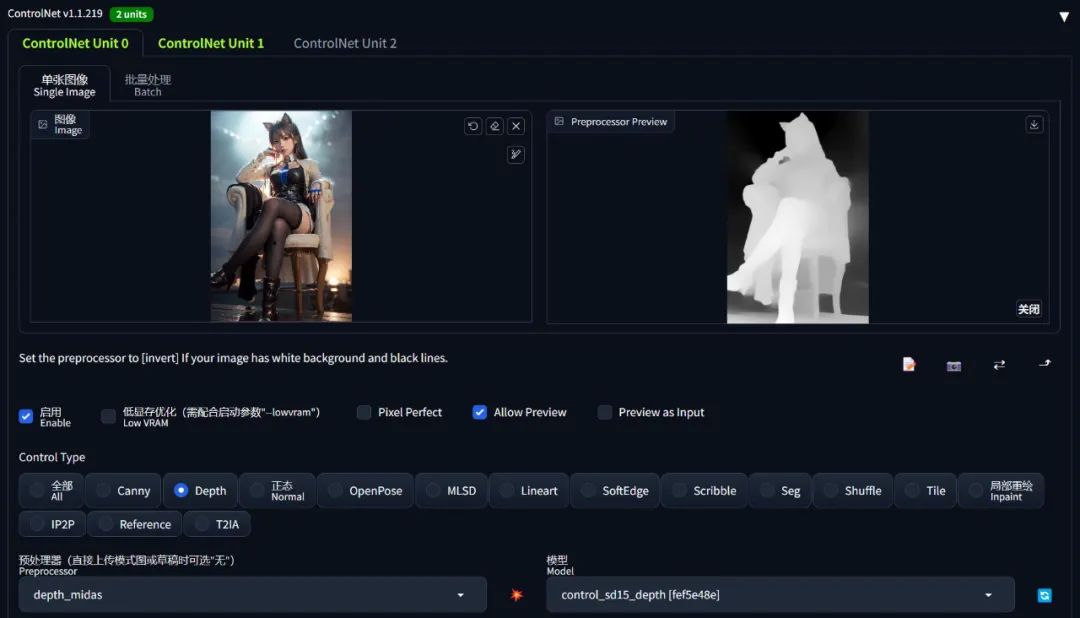
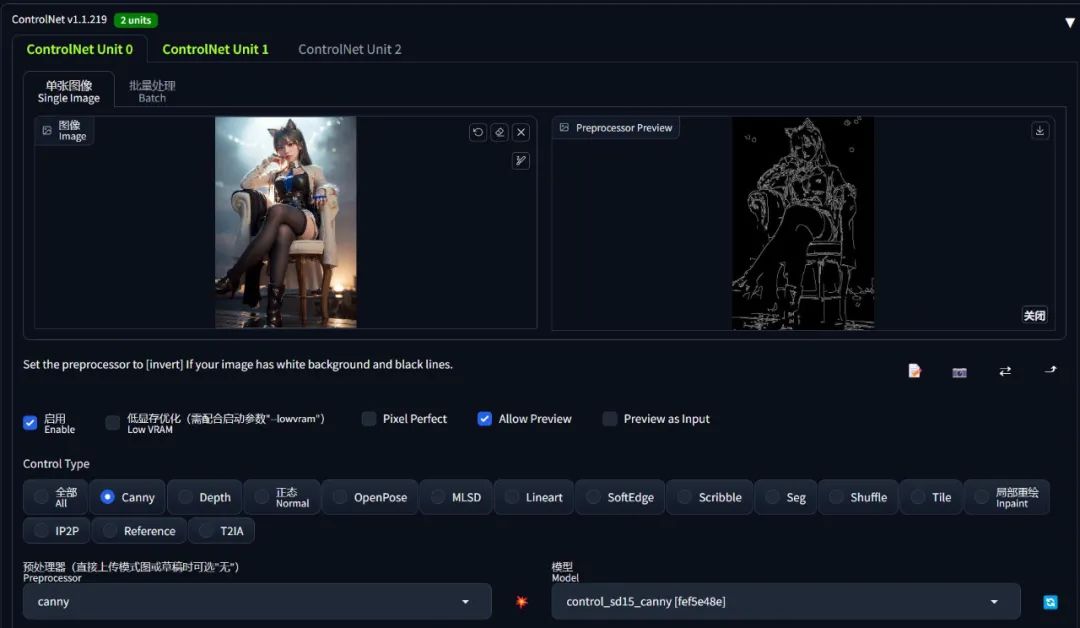
| 名称 | canny |
|---|---|
| 功能 | 勾勒图像的边沿特征(还原图像外形特征)、且会保留内部细节,可用于线稿上色。 |
| 模型下载 | control_v11p_sd15_canny.pth[18], |
| control_v11p_sd15_canny.yaml[19] | |
| 模型位置 | %SD/models/ControlNet/ |
| 预处理器 | 无 |
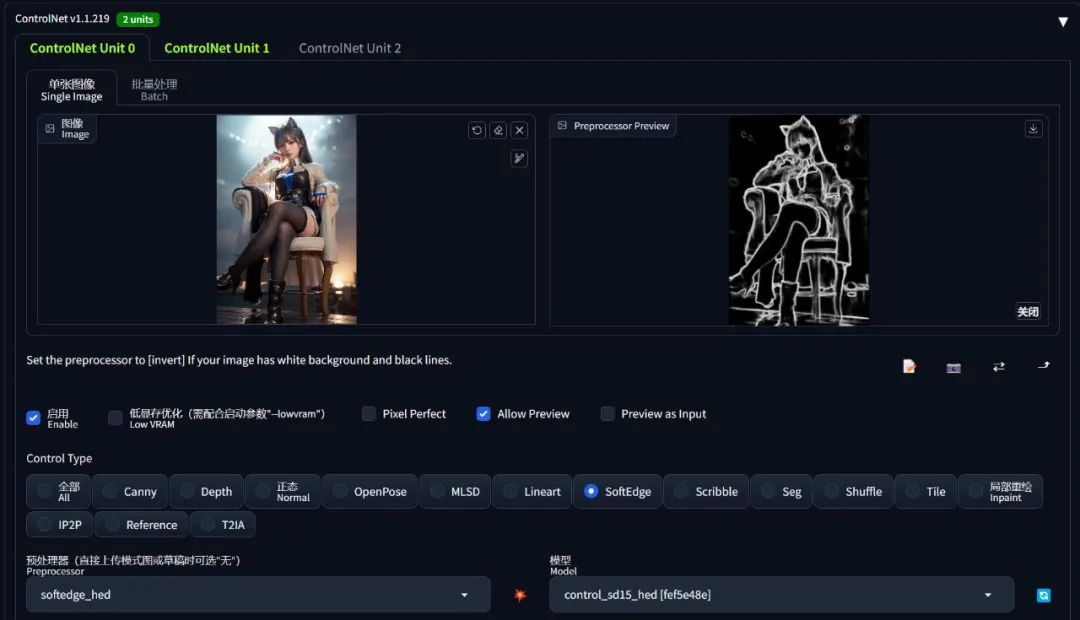
| 名称 | hed / softEdge |
|---|---|
| 功能 | 柔和边沿,和 canny 功能类似,但是边沿会更模糊,只保留轮廓特征。 |
| 模型下载 | control_v11p_sd15_softedge.pth[20], |
| control_v11p_sd15_softedge.yaml[21] | |
| 模型位置 | %SD/models/ControlNet/ |
| 预处理器 | 无 |
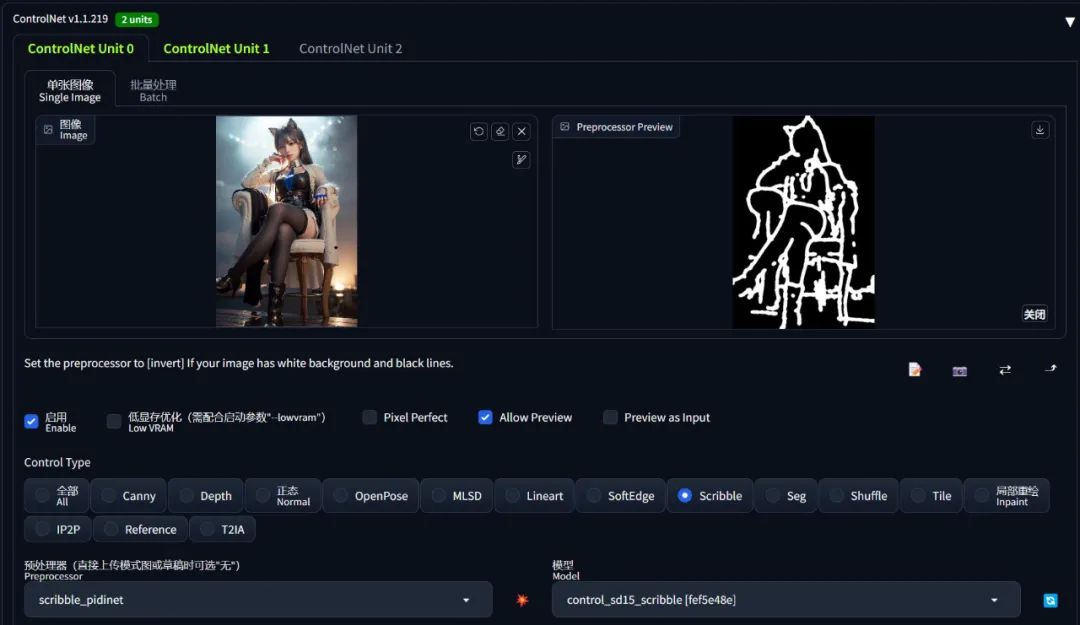
| 名称 | scribble |
|---|---|
| 功能 | 比 softEdge 更自由奔放的描摹(涂鸦乱画、灵魂画手) |
| 模型下载 | control_v11p_sd15_scribble.pth[22], |
| control_v11p_sd15_scribble.yaml[23] | |
| 模型位置 | %SD/models/ControlNet/ |
| 预处理器1 | table5_pidinet.pth[24] |
| 预处理器1 | |
| 放置位置 | %SD/extensions/sd-webui-controlnet/annotator/downloads/pidinet/ |
| 预处理器2 | ControlNetHED.pth[25] |
| 预处理器2 | |
| 放置位置 | %SD/extensions/sd-webui-controlnet/annotator/downloads/hed/ |
| 名称 | tile |
|---|---|
| 功能 | 搭配 MultiDiffusion 区块化放大图片 |
| 模型下载 | control_v11f1e_sd15_tile.pth[26], |
| control_v11f1e_sd15_tile.yaml[27] | |
| 模型位置 | %SD/models/ControlNet/ |
| 预处理器 | 无 |
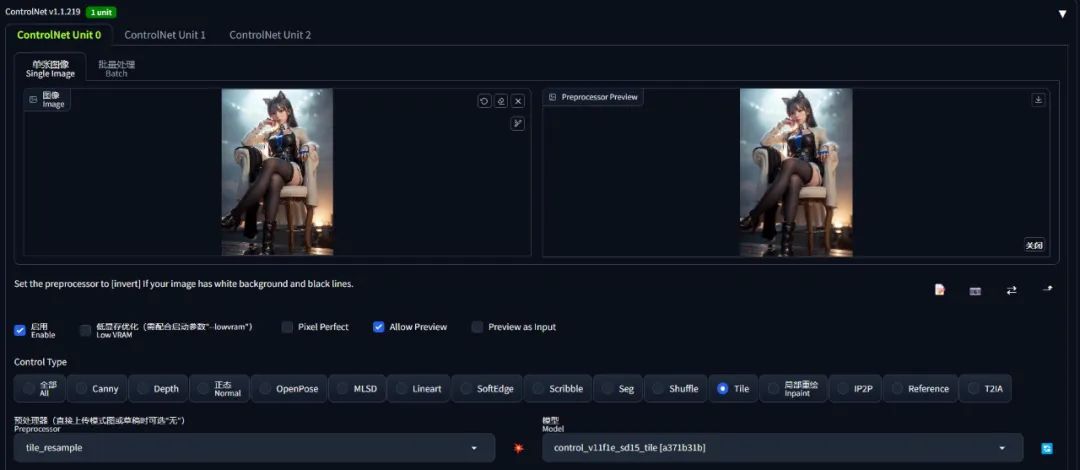
基本使用
可以说,ControlNet 最困难的部分就是安装。使用它其实非常简单。
例如我现在希望让 AI 画出「刻晴在海边弹尤克里里」的画面,在过去我们的做法就是:
-
找一个 刻晴 的角色 LoRA
-
添加提示词
sunset, beach, stand in sea, play ukulele, -
无限重绘直到得到自己满意的图
那我们就可能得到大量的 “刻晴拿着琴身”、“刻晴掰断琴头”、“刻晴抱着琴不弹” 等一堆无法满足需求的画面。最后万不得已挑了一张稍微能接受的 “刻晴抱着琴不弹”,就完事了:

但现在有了 ControlNet,我们就可以一步到位、不需要碰运气了。
在前面的基础上,我们再从网上找一张自己满意的「弹尤克里里」的图片,要是真的找不到,哪怕自拍一张拿着扫帚的照片也是可以的:

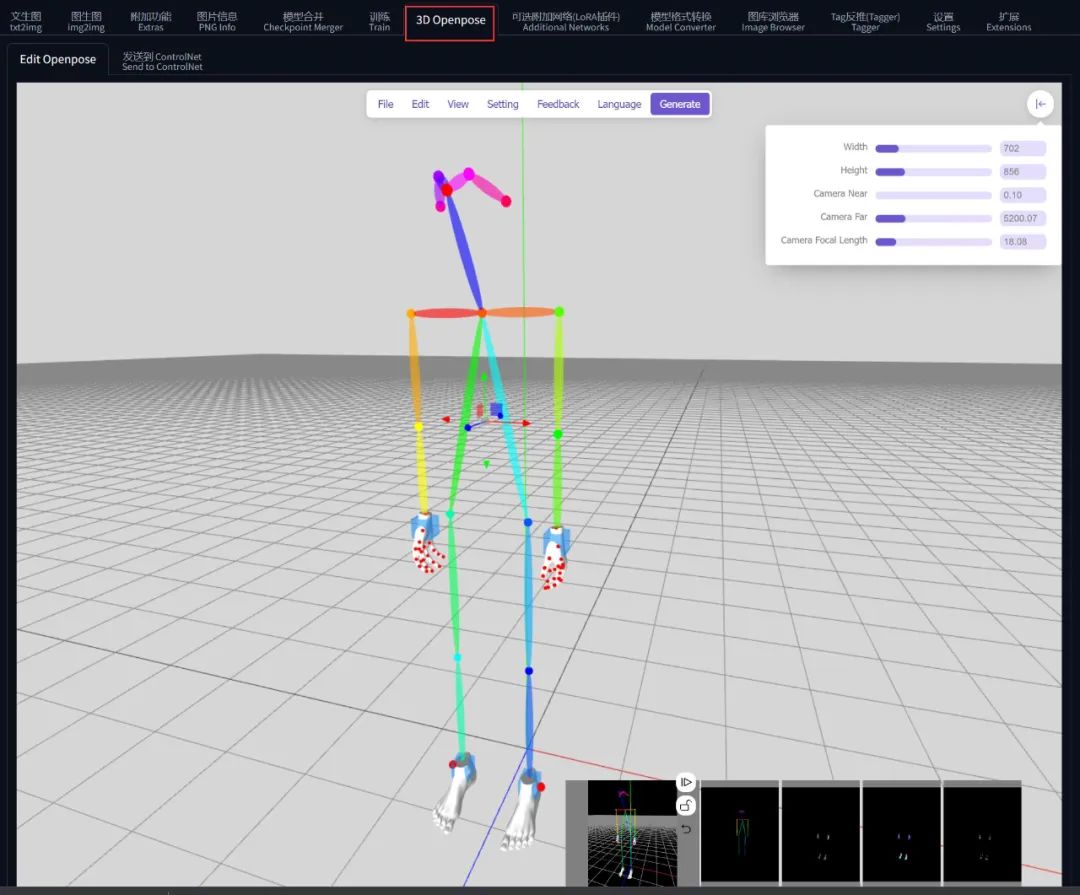
使用 3D Openpose 捏动作
还记得前面装了一个 sd-webui-3d-open-pose-editor 插件吧?
其实也可以用它去把自己想要的姿势捏出来:
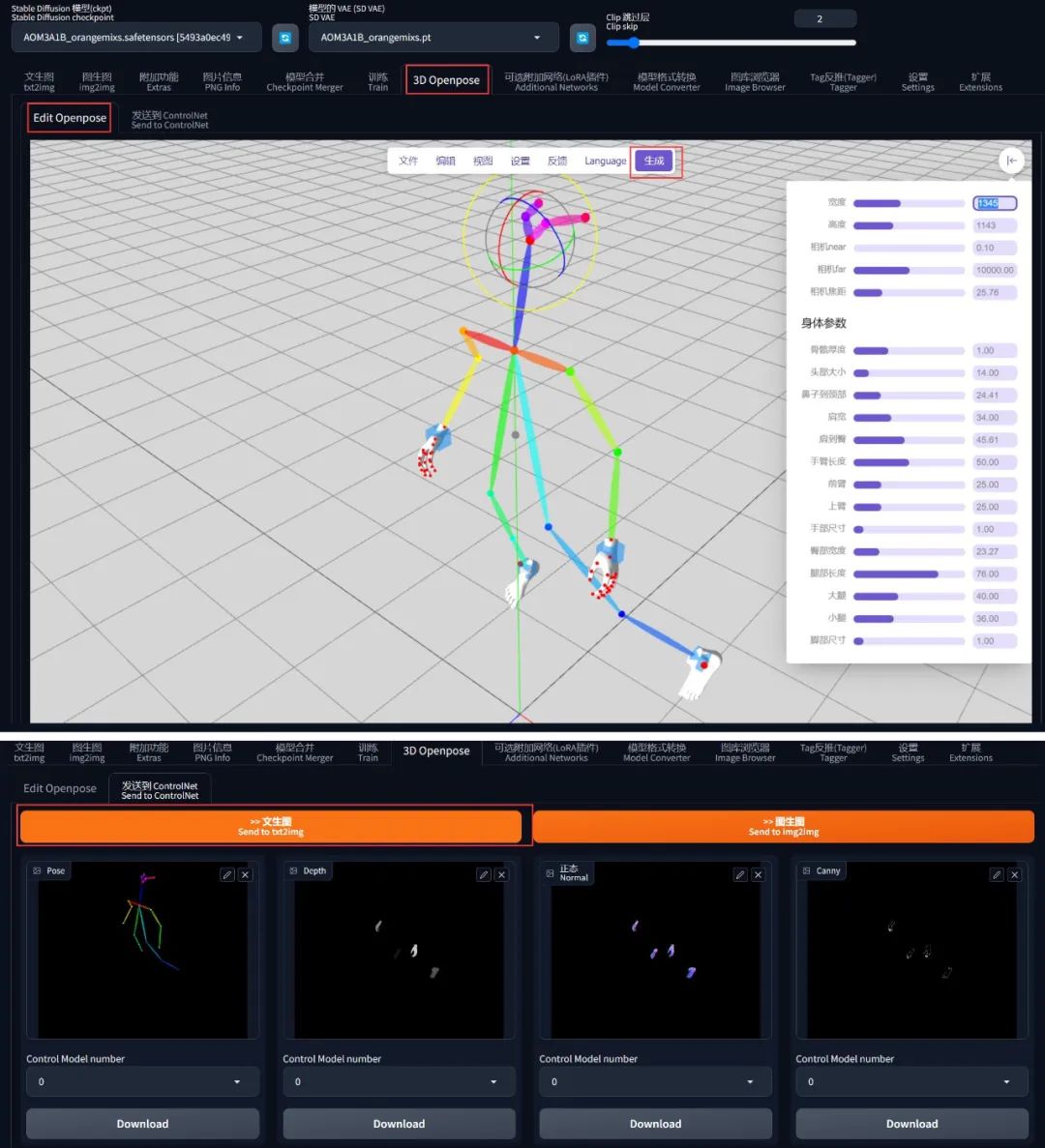
不过捏的时候虽然是 3D,实际上发送到 ControlNet 之后会投影到 2D 平面上, z 轴的坐标还是被抹掉了。
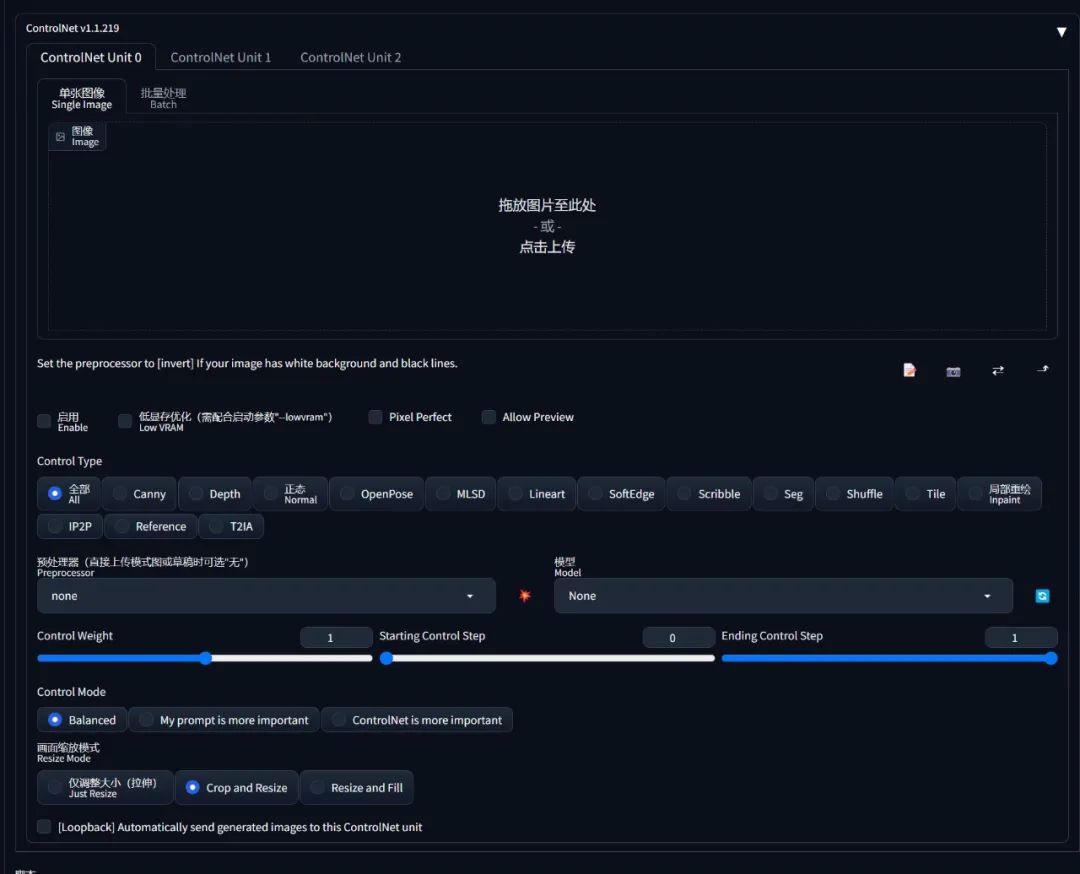
然后把这个照片导入 ControlNet (导入前需要裁剪宽高比例和出图比例一致):
-
勾选启用
-
选择 Control Type 为 openpose, 然后预处理器和模型都会自动选中 openpose 相关的选项(需要提前安装模型)
-
openpose 的预处理器有五种类型,按需选择即可:
-
openpose: 仅识别人体姿态骨架
-
openpose_face: 识别人体姿态骨架 + 脸部特征
-
openpose_faceonly: 仅识别脸部特征
-
openpose_full: 识别人体姿态骨架 + 脸部特征 + 手部特征
-
openpose_hand: 识别人体姿态骨架 + 手部特征
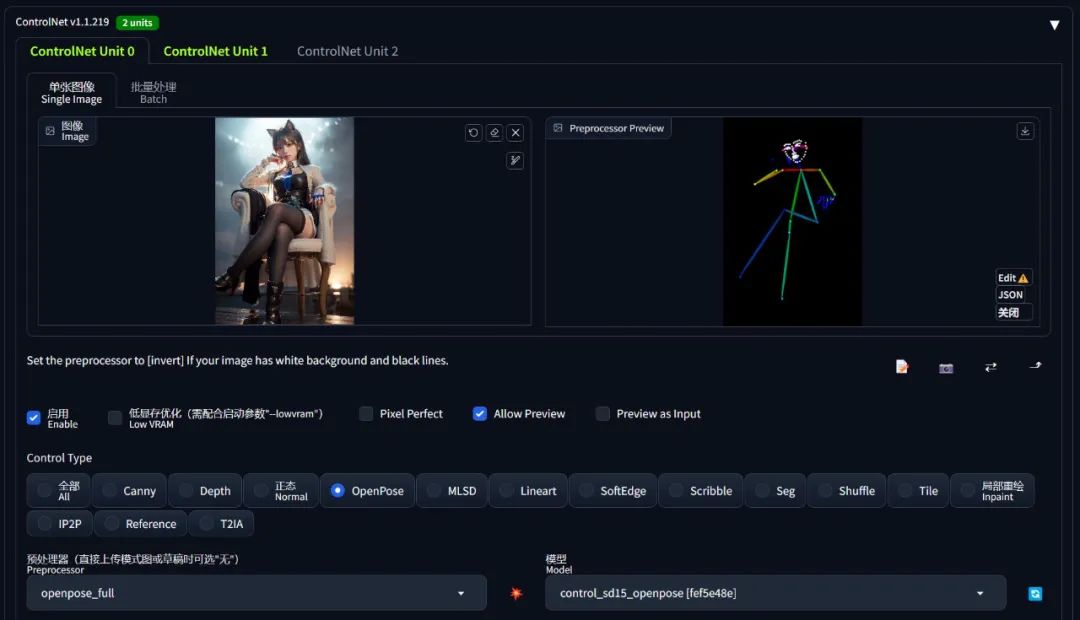
- 点击预处理器旁边的「爆炸」按钮,就会识别中图片中的人体,生成人体姿态的预览图
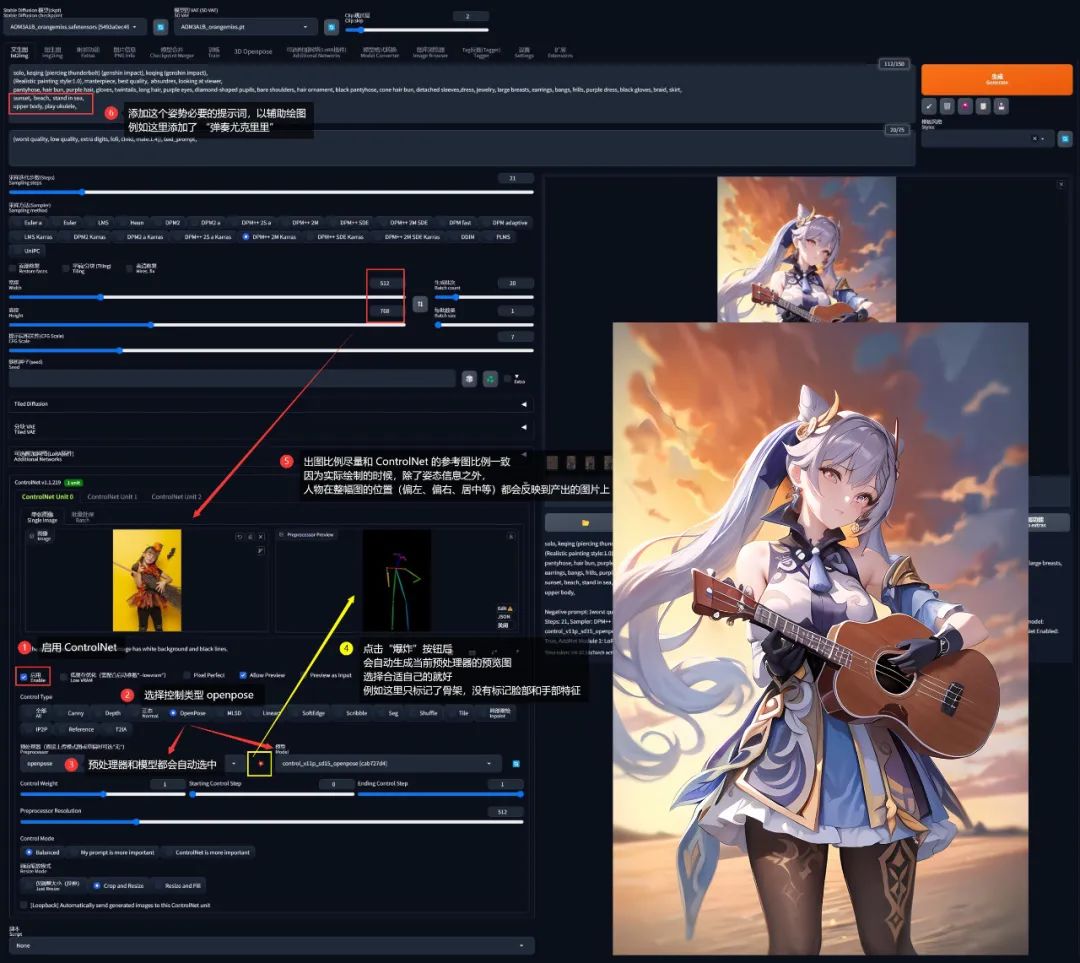
当点击「生成」图片按钮后,ControlNet 就会把 「人体姿态信息」 + 「人体在图像中的相对位置」 都输入到 AI 绘图。
由于 ControlNet 的 openpose 不会识别人体姿态以外的任何信息,故参考图中的人物拿着什么、AI 是不知道的,因此我们需要在提示词中进一步打辅助:告诉 AI “刻晴正在用这个姿势 play ukulele”, AI 就会 get 到手上空出来的位置是拿着尤克里里了。
多重控制网
不难注意到,ControlNet 其实最多支持同时使用 3 个模型,当使用 2 个以上的 ControlNet 时,称之为多重控制网。

那什么场景下会用到多重控制网呢?一个典型的例子就是人体遮挡透视。
例如我现在希望画一张「刻晴双手遮住眼睛」的图像,虽然从网上找到了我想要的动作,但是 openpose 只能识别出人体各个部位的平面位置、却不能很好的反映出它们之间的透视信息(亦可理解为景深):
❝
其实熟知视觉 AI 的同学就知道,openpose 提供的关键点 landmarks 只有 2D 的,z 轴信息被弱化了,导致不能呈现透视效果。反之如果 ControlNet 未来能引入像 mediapipe 之类的框架,就能提供 3D 的 landmarks,届时不需要多重控制网也能解决透视问题。
❞
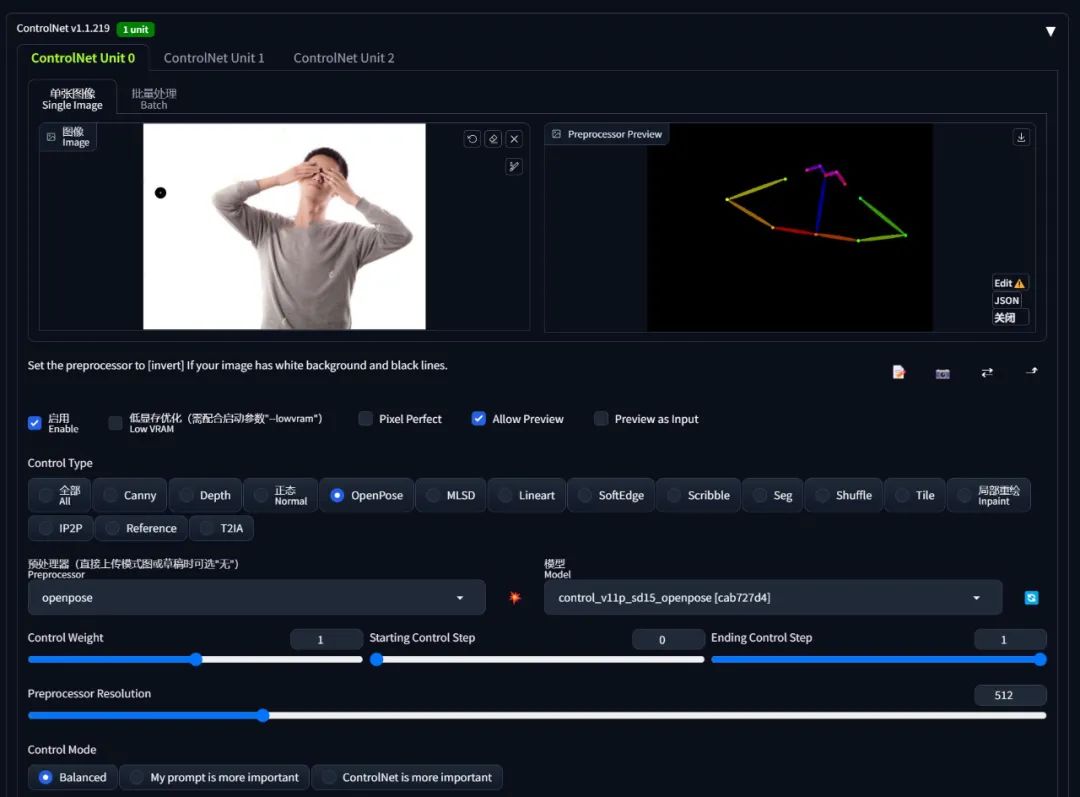
故而只使用 openpose 一个控制网,画出来的效果可能就是「刻晴双手抱在脑后」了:

解决的办法是引入另一张控制网打配合。
在这个场景下,因为透视/景深信息缺失才导致出图不准,因此可以引入擅长做这个事情的 depth 控制网:
-
保持 openpose 配置不变,切换到第二张控制网
-
选择控制网类型为 depth(需要提前安装模型)
-
导入和 openpose 一样的参考图,点击预处理器旁边的「爆炸」按钮,生成透视信息。在透视图中可以明显看到人物的手在头部前面,而不是脑后
-
适当减少 depth 控制网的权重,避免过多约束画面内容,我们的目的只需要让 AI 知道“手在眼前”的信息就够了
-
提示词可以添加
cover eyes with hands打配合
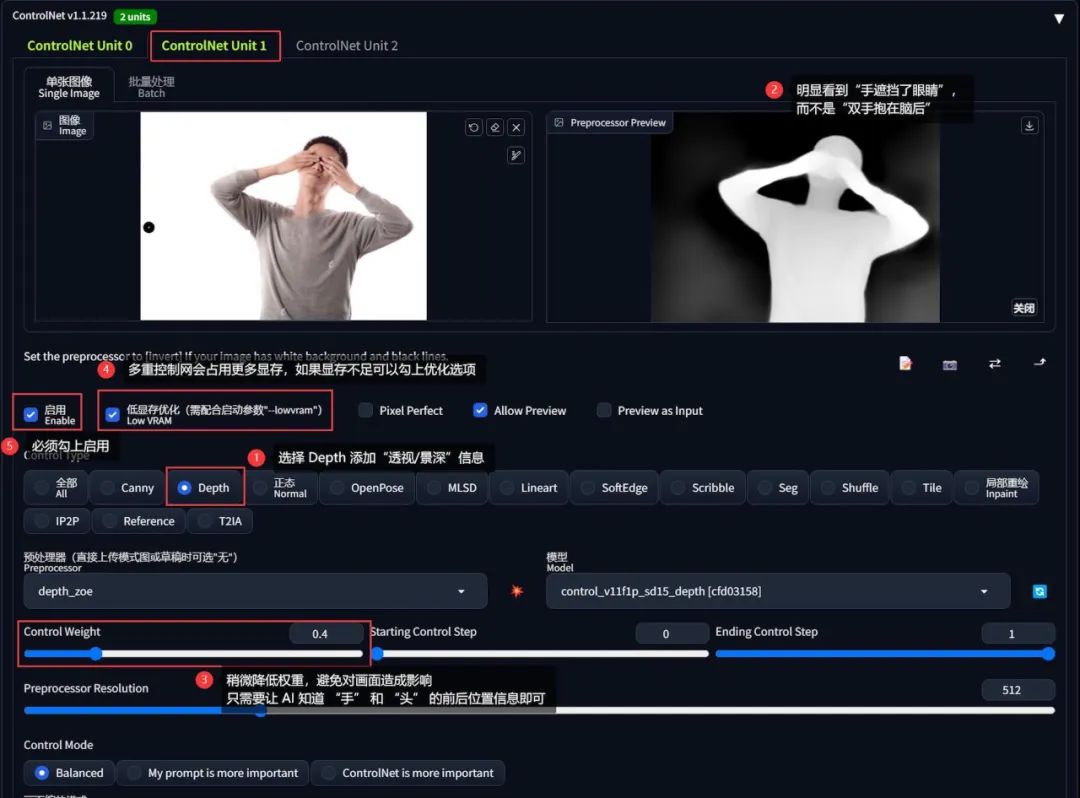
看一下出图效果,这次就能够正确画出我们期望的结果:

建议使用多重控制网时,所选的多个 ControlNet 在能力上应该是**「互补」**的,否则徒增显存却不会提升多大的出图效果、甚至还有可能变差。
❝
如果你的显存确实不够支撑多张控制网,不妨勾选「低显存优化」功能试试,当然出图效率会降低就是了
❞
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
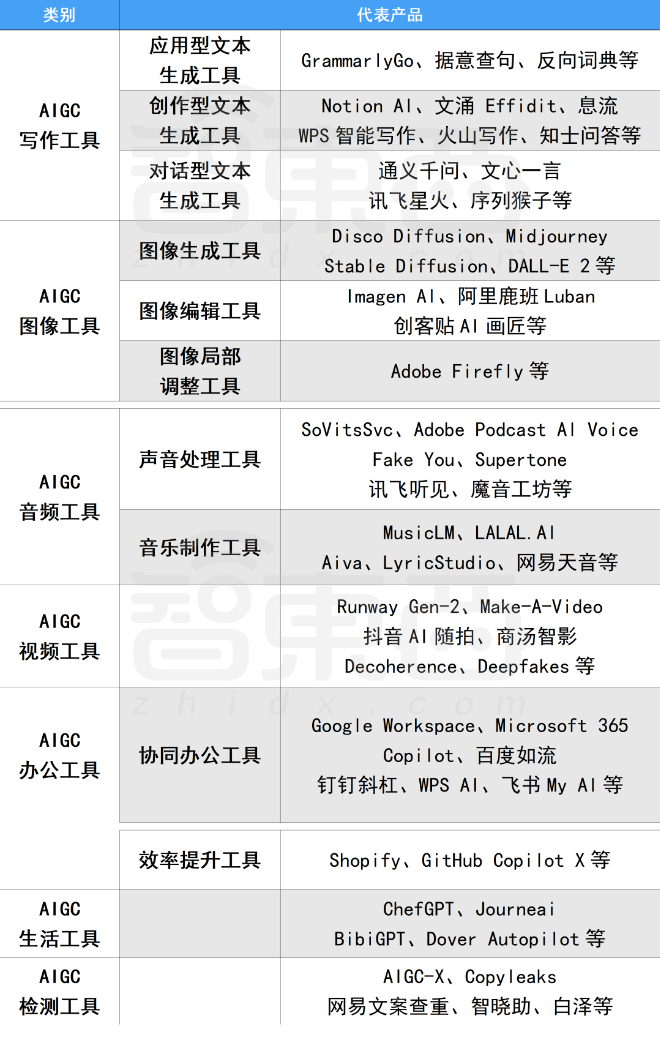
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
 若有侵权,请联系删除
若有侵权,请联系删除