自从ChatGPT发布以来,大型语言模型 (LLMs) 已经获得了很大的普及。尽管你可能没有足够的资金和计算资源在你的地下室从头开始训练一个LLM,但你仍然可以使用预先训练的LLMs来构建一些很酷的东西,例如:
- 可以根据为您的目的而定制的数据聊天机器人
- 与外界进行交互的个人助理分析
- 对您的文档或代码进行汇总
凭借其怪异的api和快速的工程设计,LLMs正在改变我们构建人工智能产品的方式。这就是为什么新的开发工具在 “LLMOpS” 一词下随处可见,其中一个新工具是LangChain(https://github.com/hwchase17/langchain)。
什么是LangChain?
LangChain是一个框架,旨在通过为您提供以下内容来帮助您更轻松地构建LLM支持的应用程序:
- 各种不同基础模型的通用接口 (请参阅模型);
- 帮助您管理提示的框架 (请参阅提示);
- 以及用于LLM无法处理 (例如计算或搜索) 的长期内存 (请参阅内存),外部数据 (请参阅索引),其他LLM (请参阅链) 和其他代理的中央接口。代理)。这是哈里森·蔡斯创建的一个开源项目 (GitHub存储库)。
由于LangChain功能众多,这就是为什么我们将在本文中介绍LangChain目前的六个关键模块,以使您更好地了解其功能。
安装环境
在本教程中,您将需要安装langchain Python软件包,并准备好使用所有相关的API密钥。安装LangChain在安装langchain软件包之前,请确保您的Python版本 ≥ 3.8.1且<4.0。
要安装langchain Python包,您可以pip安装它。
代码语言:javascript
pip install langchain
在本教程中,我们使用的是0.0.147版。GitHub库提交非常活跃; 因此,请确保您拥有当前版本。全部设置完毕后,导入langchain Python包。
代码语言:javascript
import langchain
API keys
使用LLMs构建应用程序需要您要使用的某些服务的API密钥,并且某些API是付费的。
LLM供应商 (必填): 您首先需要使用LLM提供程序的API密钥。我们目前正在经历 “AI的Linux时刻”,开发人员必须基于主要在性能和成本之间的权衡,在专有或开源基础模型之间进行选择。

LLM提供者: 专有和开源基础模型 (作者的图片,灵感来自Fiddler.ai,首次发布在W & B的博客上)
专有模型是拥有大型专家团队和大型AI预算的公司拥有的封闭式基础模型。它们通常比开源模型更大,因此具有更好的性能,但它们也具有昂贵的api。专有模型提供商的示例是OpenAI,co:here,AI21 Labs或Anthropic。大多数可用的LangChain教程使用OpenAI,但请注意,OpenAI API (对于实验来说并不昂贵,但它) 不是免费的。要获取OpenAI API密钥,您需要一个OpenAI帐户,然后在API密钥下 “创建新的密钥”。
代码语言:javascript
import os
os.environ["OPENAI_API_KEY"] = ... # insert your API_TOKEN here
开源模型通常是较小的模型,其功能比专有模型低,但比专有模型更具成本效益。开源模型的示例包括:
- BLOOM by BigScience
- LLaMA by Meta AI
- Flan-T5 by Google
- GPT-J by Eleuther AI
作为社区中心,许多开源模型都是在Hugging Face组织和托管的。要获得Hugging Face API密钥,您需要一个Hugging Face帐户,并在访问令牌下创建一个 “新令牌”。
代码语言:javascript
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"] = ... # insert your API_TOKEN here
对于开源LLM,您可以免费使用Hugging Face,但是您将被限制在性能较低的较小LLM中。
个人笔记: 您可以在此处尝试开源基础模型。我尝试使本教程仅与托管在常规帐户(google/flan-t5-xl和sentence transformer/all-MiniLM-L6-v2) 上的Hugging Face上的开源模型一起使用。它适用于大多数示例,但是让一些示例起作用也是一种痛苦。最后,我为OpenAI设置了一个付费帐户,因为LangChain的大多数示例似乎都针对OpenAI的API进行了优化。总的来说,为教程运行一些实验花了我大约1美元。
矢量数据库 (可选): 如果要使用特定的矢量数据库,例如Pinecome,Weaviate或Milvus,则需要向他们注册以获取API密钥并确认其定价。在本教程中,我们使用的是Faiss,它不需要注册。
工具 (可选): 根据您希望LLM与之交互的工具 (例如OpenWeatherMap或SerpAPI),您可能需要向它们注册以获取API密钥并检查其定价。在本教程中,我们仅使用不需要API密钥的工具。
我们可以用LangChain做什么?
该软件包为许多基础模型提供了通用接口,可以进行提示管理,并通过代理充当其他组件 (如提示模板,其他LLM,外部数据和其他工具) 的中央接口。在撰写本文时,LangChain (版本0.0.147) 涵盖了六个模块:
- 模型: 从不同的LLMs和嵌入模型中进行选择
- 提示: 管理LLM
- 输入链: 将LLMs与其他组件相结合
- 索引: 访问外部数据
- 存储器: 记住以前的对话
- 代理: 访问其他工具
以下各节中的代码示例是从LangChain文档中复制和修改的。
模型: 从不同的LLM中选择和嵌入模型
目前,许多不同的LLM正在出现。LangChain为各种模型提供了集成,并为所有模型提供了简化的界面。LangChain区分了三种类型的模型,它们的输入和输出不同:
- LLMs将字符串作为输入 (提示),并输出字符串 (完成)。
代码语言:javascript
# Proprietary LLM from e.g. OpenAI
# pip install openai
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003")
# Alternatively, open-source LLM hosted on Hugging Face
# pip install huggingface_hub
from langchain import HuggingFaceHub
llm = HuggingFaceHub(repo_id = "google/flan-t5-xl")
# The LLM takes a prompt as an input and outputs a completion
prompt = "Alice has a parrot. What animal is Alice's pet?"
completion = llm(prompt)

LLM 模型
- 聊天模型类似于LLM。他们将聊天消息列表作为输入,并返回聊天消息。
- 文本嵌入模型采用文本输入并返回浮点数 (嵌入) 列表,浮点数是输入文本的数字表示形式。嵌入有助于从文本中提取信息。随后可以使用该信息,例如,用于计算文本之间的相似性 (例如,电影摘要)。
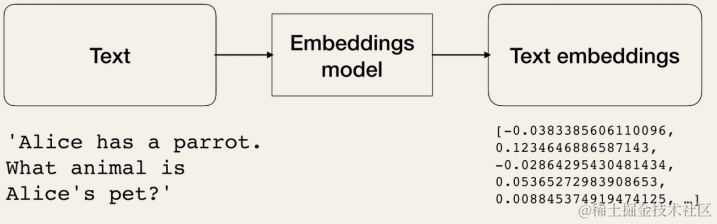
文本嵌入模型
提示: 管理LLM输入
LLM有怪异的api。尽管用自然语言向LLM输入提示应该感觉很直观,但在从LLM获得所需的输出之前,需要对提示进行大量调整。这个过程称为提示工程。一旦有了好的提示,您可能希望将其用作其他目的的模板。因此,LangChain为您提供了所谓的提示模板,可帮助您从多个组件构建提示。
代码语言:javascript
from langchain import PromptTemplate
template = "What is a good name for a company that makes {product}?"
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
prompt.format(product="colorful socks")
上面的提示可以看作是Zero-shot Learning(零射击学习是一种设置,模型可以学习识别以前在训练中没有明确看到的事物),您希望LLM在足够的相关数据上进行了训练,以提供令人满意的结果。改善LLM输出的另一个技巧是在提示中添加一些示例,并使其成为一些问题设置。
代码语言:javascript
from langchain import PromptTemplate, FewShotPromptTemplate
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
]
example_template = """
Word: {word}
Antonym: {antonym}\n
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_template,
)
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Word: {input}\nAntonym:",
input_variables=["input"],
example_separator="\n",
)
few_shot_prompt.format(input="big")
上面的代码将生成一个提示模板,并根据提供的示例和输入组成以下提示:
代码语言:javascript
Give the antonym of every input
Word: happy
Antonym: sad
Word: tall
Antonym: short
Word: big
Antonym:
Chain: 将LLMs与其他组件组合
在LangChain中Chain简单地描述了将LLMs与其他组件组合以创建应用程序的过程。一些示例是: 将LLM与提示模板组合 (请参阅本节),通过将第一个LLM的输出作为第二个LLM的输入来顺序组合多个LLM (请参阅本节),将LLM与外部数据组合,例如,对于问题回答 (请参阅索引),将LLM与长期记忆相结合,例如,对于上一节中的聊天记录 (请参阅内存),我们创建了一个提示模板。当我们想将其与我们的LLM一起使用时,我们可以使用LLMChain,如下所示:
代码语言:javascript
from langchain.chains import LLMChain
chain = LLMChain(llm = llm,
prompt = prompt)
# Run the chain only specifying the input variable.
chain.run("colorful socks")
如果我们想使用这个第一个LLM的输出作为第二个LLM的输入,我们可以使用一个SimpleSequentialChain:
代码语言:javascript
from langchain.chains import LLMChain, SimpleSequentialChain
# Define the first chain as in the previous code example
# ...
# Create a second chain with a prompt template and an LLM
second_prompt = PromptTemplate(
input_variables=["company_name"],
template="Write a catchphrase for the following company: {company_name}",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# Combine the first and the second chain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Run the chain specifying only the input variable for the first chain.
catchphrase = overall_chain.run("colorful socks")

结果示例
索引:访问外部数据
LLM的一个限制是它们缺乏上下文信息 (例如,访问某些特定文档或电子邮件)。您可以通过允许LLMs访问特定的外部数据来解决此问题。为此,您首先需要使用文档加载器加载外部数据。LangChain为不同类型的文档提供了各种加载程序,从pdf和电子邮件到网站和YouTube视频。让我们从YouTube视频中加载一些外部数据。如果你想加载一个大的文本文档并用文本拆分器拆分它,你可以参考官方文档。
代码语言:javascript
# pip install youtube-transcript-api
# pip install pytube
from langchain.document_loaders import YoutubeLoader
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=dQw4w9WgXcQ")
documents = loader.load()
现在,您已经准备好外部数据作为文档,您可以使用矢量数据库 (VectorStore) 中的文本嵌入模型 (请参阅模型) 对其进行索引。流行的矢量数据库包括Pinecone,weavviate和Milvus。在本文中,我们使用的是Faiss,因为它不需要API密钥。
代码语言:javascript
# pip install faiss-cpu
from langchain.vectorstores import FAISS
# create the vectorestore to use as the index
db = FAISS.from_documents(documents, embeddings)
您的文档 (在本例中为视频) 现在作为嵌入存储在矢量存储中。现在你可以用这个外部数据做各种各样的事情。让我们将其用于带有信息寻回器的问答任务:
代码语言:javascript
from langchain.chains import RetrievalQA
retriever = db.as_retriever()
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True)
query = "What am I never going to do?"
result = qa({"query": query})
print(result['result'])

结果示例
存储器: 记住先前的对话
对于像聊天机器人这样的应用程序来说,他们能够记住以前的对话是至关重要的。但是默认情况下,LLMs没有任何长期记忆,除非您输入聊天记录。

有无记忆的聊天机器人的对比
LangChain通过提供处理聊天记录的几种不同选项来解决此问题:
- 保留所有对话
- 保留最新的k对话
- 总结对话
在这个例子中,我们将使用ConversationChain作为这个应用程序会话内存。
代码语言:javascript
from langchain import ConversationChain
conversation = ConversationChain(llm=llm, verbose=True)
conversation.predict(input="Alice has a parrot.")
conversation.predict(input="Bob has two cats.")
conversation.predict(input="How many pets do Alice and Bob have?")
这将生成上图中的右手对话。如果没有ConversationChain来保持对话记忆,对话将看起来像上图中左侧的对话。
代理: 访问其他工具
尽管LLMs非常强大,但仍有一些局限性: 它们缺乏上下文信息 (例如,访问训练数据中未包含的特定知识),它们可能很快就会过时 (例如,GPT-4在2021年9月之前就接受了数据培训),并且他们不擅长数学。
因为LLM可能会对自己无法完成的任务产生幻觉,所以我们需要让他们访问补充工具,例如搜索 (例如Google搜索),计算器 (例如Python REPL或Wolfram Alpha) 和查找 (例如,维基百科)。此外,我们需要代理根据LLM的输出来决定使用哪些工具来完成任务。
请注意,某些LLM(例如google/flan-t5-xl) 不适用于以下示例,因为它们不遵循会话-反应-描述模板。对我来说,这是我在OpenAI上设置付费帐户并切换到OpenAI API的原因。
下面是一个例子,代理人首先用维基百科查找奥巴马的出生日期,然后用计算器计算他2022年的年龄。
代码语言:javascript
# pip install wikipedia
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
tools = load_tools(["wikipedia", "llm-math"], llm=llm)
agent = initialize_agent(tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True)
agent.run("When was Barack Obama born? How old was he in 2022?")
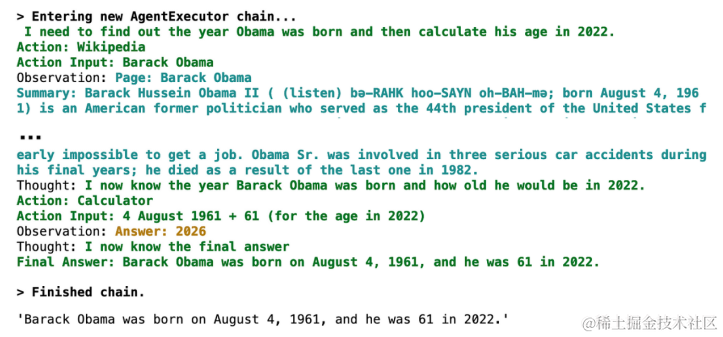
结果图片
总结
就在几个月前,我们所有人 (或至少我们大多数人) 都对ChatGPT的功能印象深刻。现在,像LangChain这样的新开发人员工具使我们能够在几个小时内在笔记本电脑上构建同样令人印象深刻的原型–这是一些真正令人兴奋的时刻!
LangChain是一个开源的Python库,它使任何可以编写代码的人都可以构建以LLM为动力的应用程序。该软件包为许多基础模型提供了通用接口,可以进行提示管理,并在撰写本文时通过代理充当其他组件 (如提示模板,其他LLM,外部数据和其他工具) 的中央接口。该库提供了比本文中提到的更多的功能。以目前的发展速度,这篇文章也可能在一个月内过时。
在撰写本文时,我注意到库和文档围绕OpenAI的API展开。尽管许多示例与开源基础模型google/flan-t5-xl一起使用,但我在两者之间选择了OpenAI API。尽管不是免费的,但在本文中尝试OpenAI API只花了我大约1美元。
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

阶段1:AI大模型时代的基础理解
- 目标:了解AI大模型的基本概念、发展历程和核心原理。
- 内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践 - L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
- 目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
- 内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例 - L2.2 Prompt框架
- L2.2.1 什么是Prompt
- L2.2.2 Prompt框架应用现状
- L2.2.3 基于GPTAS的Prompt框架
- L2.2.4 Prompt框架与Thought
- L2.2.5 Prompt框架与提示词 - L2.3 流水线工程
- L2.3.1 流水线工程的概念
- L2.3.2 流水线工程的优点
- L2.3.3 流水线工程的应用 - L2.4 总结与展望
- L2.1 API接口
阶段3:AI大模型应用架构实践
- 目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
- 内容:
- L3.1 Agent模型框架
- L3.1.1 Agent模型框架的设计理念
- L3.1.2 Agent模型框架的核心组件
- L3.1.3 Agent模型框架的实现细节 - L3.2 MetaGPT
- L3.2.1 MetaGPT的基本概念
- L3.2.2 MetaGPT的工作原理
- L3.2.3 MetaGPT的应用场景 - L3.3 ChatGLM
- L3.3.1 ChatGLM的特点
- L3.3.2 ChatGLM的开发环境
- L3.3.3 ChatGLM的使用示例 - L3.4 LLAMA
- L3.4.1 LLAMA的特点
- L3.4.2 LLAMA的开发环境
- L3.4.3 LLAMA的使用示例 - L3.5 其他大模型介绍
- L3.1 Agent模型框架
阶段4:AI大模型私有化部署
- 目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
- 内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
学习计划:
- 阶段1:1-2个月,建立AI大模型的基础知识体系。
- 阶段2:2-3个月,专注于API应用开发能力的提升。
- 阶段3:3-4个月,深入实践AI大模型的应用架构和私有化部署。
- 阶段4:4-5个月,专注于高级模型的应用和部署。
这份完整版的所有 ⚡️ 大模型 LLM 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
全套 《LLM大模型入门+进阶学习资源包》↓↓↓ 获取~