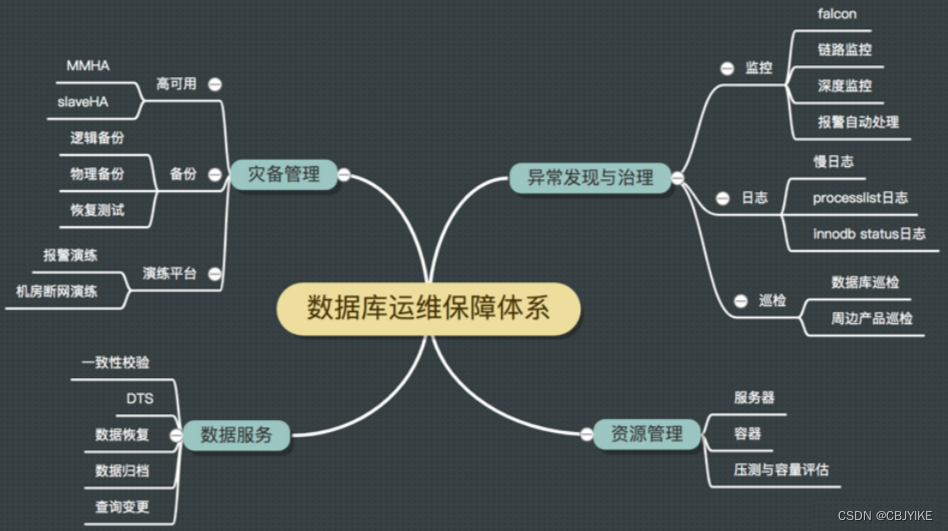
一、概述
本文旨在整理mysql从场景化运维角度来整理,常用的检查命令和处理方式,以供参考查看,为相关活动提供便利指导
二、MySQL巡检参考
数据库巡检项目根据负责方可简单分为DBA和RD,DBA主要负责处理数据库基础功能组件以及影响服务稳定性的隐患。RD(后端工程师)主要负责库表设计缺陷、数据库使用不规范等引起的业务故障或性能问题的隐患。他们同时又都参与治理的巡检项,比如“磁盘可用空间预测”等。
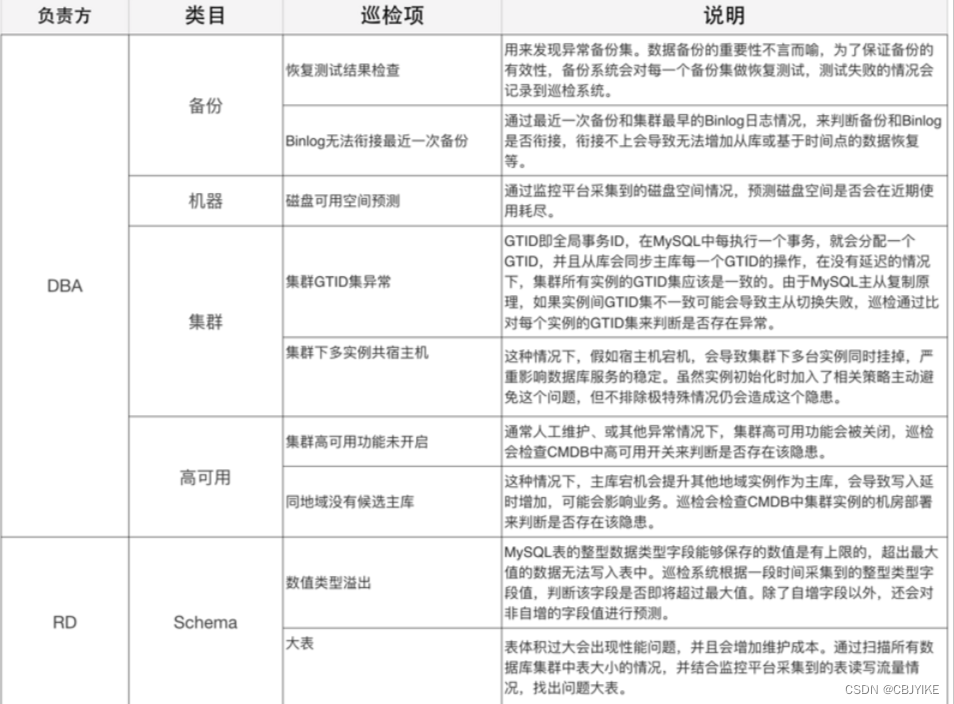
可从以下几个方面进行巡检:
- 集群:主要检查集群拓扑、核心参数等集群层面的隐患;
- 机器:主要检查服务器硬件层面的隐患;
- Schema/SQL:检查表结构设计、数据库使用、SQL质量等方面的隐患;
- 高可用/备份/中间件/报警:主要检查相关核心功能组件是否存在隐患。
2.1、检查MySQL主从复制健康状态
show slave status\G #通过重要字段来判断当前主机的主从复制状态是否健康
……
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
……
Slave_SQL_Running_State: Reading event from the relay log
Seconds_Behind_Master: 4508
#检查进程,查看是否异常连接
show processlist; #或show full processlist;
#查看当前失败连接数
show global status like 'aborted_connects';
#查看有多少由于客户没有正确关闭连接而死掉的连接数
show global status like 'aborted_clients';
#查看最大连接数
show variables like '%max_connections%';
show global status like 'max_connections';
#查看Innodb死锁
show engine innodb status\G #当遇到死锁时Innodb会回滚事务;我们应了解死锁何时发生对于追溯其发生的根本原因非常重要。我们必须知道产生了什么样的死锁,相关应用是否正确处理或已采取了相关措施
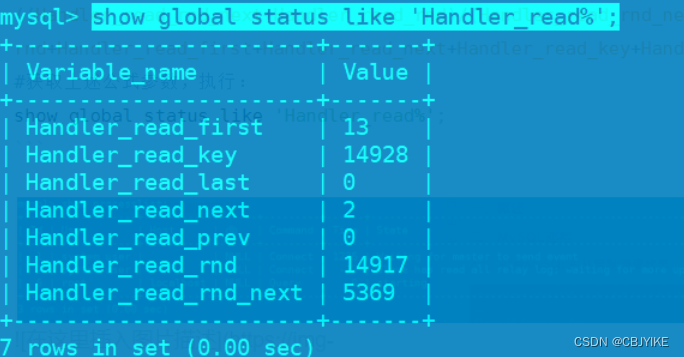
#全表扫描比例计算方式如下:
((Handler_read_rnd_next+Handler_read_rnd)/(Handler_read_rnd_next+Handler_read_rnd+Handler_read_first+Handler_read_next+Handler_read_key+Handler_read_prev))
#获取上述公式参数,执行:
show global status like 'Handler_read%';

检查脚本示例1:
#!/bin/bash
# @author:
# @title:检查MySQL主从健康情况
#
# 基本配置
#
MYSQL_USER="root"
MYSQL_PASSWORD="123456"
MYSQL_HOST="localhost"
MYSQL_PORT=3306
#
# 检查MySQL主从健康情况
#
show_slave_status=`mysql -h"$MYSQL_HOST" -P"$MYSQL_PORT" -u"$MYSQL_USER" -p"$MYSQL_PASSWORD" -A -e 'show slave status\G;' 2>/dev/null`
slave_sql_running_state=`echo "$show_slave_status" |grep Slave_SQL_Running_State |awk -F ': ' '{print $2}'` # Slave上SQL运行状态
# 检查日志同步状态,IO、SQL线程运行状态:2表示健康,!2表示不健康
Sync_status=`echo "$show_slave_status" |grep Running: |awk -F ': ' '{if($2=="Yes"){sum += 1}}; END{print sum}'`
# 如果主从复制状态是不健康的则在屏幕上打印Slave主机SQL运行状态
if [ $ms_status -eq 2 ];then
echo "ms running status: 1"
else
echo "ms running status: 0"
echo "error: $slave_sql_running_state"
fi
脚本示例2:只检查mysql进程是否存在
#!/bin/sh
#date:2015-12-07
#filename:check_mysql.sh
#作者:
#Email:
#version:v1.0
#port=`netstat -tunlp|grep 3306|wc -l`
#process=`ps -ef|grep mysqld|grep -v grep|wc -l`
value=`/application/mysql/bin/mysql -u root -poldboy -e "select version();" >/dev/null 2>&1`
while true
do
if [ $? -ne 0 ]
then
#echo "ERROR! MySQL is not running"
/etc/init.d/mysqld start
else
echo "MySQL is running,now!"
fi
sleep 5
value=`/application/mysql/bin/mysql -u root -poldboy -e "select version();" >/dev/null 2>&1`
if [ $? -ne 0 ]
then
#echo "ERROR! MySQL is not running"
/etc/init.d/mysqld start
else
echo "MySQL is running,now!"
fi
sleep 5
done
2.2、查看SQL语句执行效率
这里要用到Explain语句,Explain可以用来查看 SQL 语句的执行效 果,可以帮助选择更好的索引和优化查询语句,写出更好的优化语句。
语法:explain select … from … [where …]

输出字段说明:
1、id:这是SELECT的查询序列号
2、select_type:select_type就是select的类型,可以有以下几种:
SIMPLE:简单SELECT(不使用UNION或子查询等)
PRIMARY:最外面的SELECT
UNION:UNION中的第二个或后面的SELECT语句
DEPENDENT UNION:UNION中的第二个或后面的SELECT语句,取决于外面的查询
UNION RESULT:UNION的结果。
SUBQUERY:子查询中的第一个SELECT
DEPENDENT SUBQUERY:子查询中的第一个SELECT,取决于外面的查询
DERIVED:导出表的SELECT(FROM子句的子查询)
3、table:显示这一行的数据是关于哪张表的
4、type:这列最重要,显示了连接使用了哪种类别,有无使用索引,是使用Explain命令分析性能瓶颈的关键项之一。
结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。
5、possible_keys:列指出MySQL能使用哪个索引在该表中找到行
6、key:显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
7、key_len:显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好
8、ref:显示使用哪个列或常数与key一起从表中选择行。
9、rows:显示MySQL认为它执行查询时必须检查的行数。
10、Extra:包含MySQL解决查询的详细信息,也是关键参考项之一。
Distinct:一旦MYSQL找到了与行相联合匹配的行,就不再搜索了
Not exists:MYSQL 优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
Range checked for each
Record(index map:#):没有找到理想的索引,因此对于从前面表中来的每一 个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一
Using filesort:看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来 排序全部行
Using index:列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表 的全部的请求列都是同一个索引的部分的时候
Using temporary:看到这个的时候,查询需要优化了。这 里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
Using where:使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index, 这就会发生,或者是查询有问题2.3、mysql几种性能测试工具
1)mysqlslap:模拟并发测试数据库性能。
不足:不能指定生成的数据规模,测试过程不清楚针对十万级还是百万级数据做的测试,感觉不太适合做综合测试,比较适合针对既有数据库,对单个sql进行优化的测试。
eg1:
mysqlslap -u root -p --concurrency=100 --iterations=1 --auto-generate-sql --auto-generate-sql-add-autoincrement --auto-generate-sql-load-type=mixed --engine=myisam --number-of-queries=10
eg2:指定数据库和sql语句:
mysqlslap -h localhost -P 123456 --concurrency=100 --iterations=1 --create-schema='mysql' --query='select * from user;' --number-of-queries=10 -u root -p -only-print
eg3:
mysqlslap -uroot -p123456 --concurrency=100 --iterations=1 --engine=myisam --create-schema='haodingdan112' --query='select * From order_boxing_transit where id = 10' --number-of-queries=1 --debug-info
2)sysbench
下载:http://sourceforge.net/projects/sysbench/
tar zxf sysbench-0.4.12.tar.gz
cd sysbench-0.4.12
./autogen.sh
./configure && make && make install
strip /usr/local/bin/sysbench作用:模拟并发,可以执行CPU/内存/线程/IO/数据库等方面的性能测试。数据库目前支持MySQL/Oracle/PostgreSQL
优点:可以指定测试数据的规模,可以单独测试读、写的性能,也可以测试读写混合的性能。
不足:测试的时候,由于网络原因,测试的非常慢,但是最终给的结果却很好,并发支持很高,可能不太准确
3)tpcc-mysql
export C_INCLUDE_PATH=/usr/include/mysql
export PATH=/usr/bin:$PATH
export LD_LIBRARY_PATH=/usr/lib/mysql
cd /tmp/tpcc/src
make
作用:测试mysql数据库的整体性能
优点:符合tpcc标准,有标准的方法,模拟真实的交易活动,结果比较可靠。
不足:不能单独测试读或者写的性能,对于一些以查询为主或者只写的应用,就没有这么大的意义了。
eg1:单进程加载:
./tpcc_load 192.168.11.172 tpcc10 root pwd 300
eg2:并发加载
./load.sh tpcc300 300
eg3:
./tpcc_start -h192.168.11.172 -d tpcc -u root -p ‘pwd’ -w 10 -c 10 -r 10 -l 60 -i 10 -f /mnt/hgfs/mysql/tpcc100_2013522.txt
参考;http://baike.baidu.com/view/2776305.htm
4) MySQL Benchmark Suite
5)MySQL super-smack
一个强大的广受赞誉的压力测试工具,支持MySQL和PostgreSQL。
参看:http://jeremy.zawodny.com/mysql/super-smack/
6)MyBench: A Home-Grown Solution
MyBench是一种基于Perl语言易于扩展的测试工具。
注:上述来源于网络,未验证,只用于参考,待后续测试后补充。
2.4、MySQL基础巡检
#确认当前MySQL版本,只针对mysql 5.6.8以上版本
select version();
//检查mysql运行时长
SHOW STATUS LIKE "Uptime";
2.5、Mysql自带的库
1)information_schema数据库:
是MySQL自带的,提供了访问数据库元数据的方式;如数据库名或表名,列的数据类型,或访问权限等,有的也称为“数据词典”和“系统目录”。 information_schema 实际是一个信息数据库,其中保存着关于MySQL服务器所维护的所有其他数据库的信息。information_schema中,有多个只读表。它们实际上是视图,而不是基本表。
#information_schema中78个表
+---------------------------------------+
| Tables_in_information_schema |
+---------------------------------------+
| ADMINISTRABLE_ROLE_AUTHORIZATIONS |
| APPLICABLE_ROLES |
| CHARACTER_SETS |
| CHECK_CONSTRAINTS |
| COLLATIONS |
| COLLATION_CHARACTER_SET_APPLICABILITY |
| COLUMNS |
| COLUMNS_EXTENSIONS |
| COLUMN_PRIVILEGES |
| COLUMN_STATISTICS |
| ENABLED_ROLES |
| ENGINES |
| EVENTS |
| FILES |
| INNODB_BUFFER_PAGE |
| INNODB_BUFFER_PAGE_LRU |
| INNODB_BUFFER_POOL_STATS |
| INNODB_CACHED_INDEXES |
| INNODB_CMP |
| INNODB_CMPMEM |
| INNODB_CMPMEM_RESET |
| INNODB_CMP_PER_INDEX |
| INNODB_CMP_PER_INDEX_RESET |
| INNODB_CMP_RESET |
| INNODB_COLUMNS |
| INNODB_DATAFILES |
| INNODB_FIELDS |
| INNODB_FOREIGN |
| INNODB_FOREIGN_COLS |
| INNODB_FT_BEING_DELETED |
| INNODB_FT_CONFIG |
| INNODB_FT_DEFAULT_STOPWORD |
| INNODB_FT_DELETED |
| INNODB_FT_INDEX_CACHE |
| INNODB_FT_INDEX_TABLE |
| INNODB_INDEXES |
| INNODB_METRICS |
| INNODB_SESSION_TEMP_TABLESPACES |
| INNODB_TABLES |
| INNODB_TABLESPACES |
| INNODB_TABLESPACES_BRIEF |
| INNODB_TABLESTATS |
| INNODB_TEMP_TABLE_INFO |
| INNODB_TRX |
| INNODB_VIRTUAL |
| KEYWORDS |
| KEY_COLUMN_USAGE |
| OPTIMIZER_TRACE |
| PARAMETERS |
| PARTITIONS |
| PLUGINS |
| PROCESSLIST |
| PROFILING |
| REFERENTIAL_CONSTRAINTS |
| RESOURCE_GROUPS |
| ROLE_COLUMN_GRANTS |
| ROLE_ROUTINE_GRANTS |
| ROLE_TABLE_GRANTS |
| ROUTINES |
| SCHEMATA |
| SCHEMA_PRIVILEGES |
| STATISTICS |
| ST_GEOMETRY_COLUMNS |
| ST_SPATIAL_REFERENCE_SYSTEMS |
| ST_UNITS_OF_MEASURE |
| TABLES |
| TABLESPACES |
| TABLESPACES_EXTENSIONS |
| TABLES_EXTENSIONS |
| TABLE_CONSTRAINTS |
| TABLE_CONSTRAINTS_EXTENSIONS |
| TABLE_PRIVILEGES |
| TRIGGERS |
| USER_ATTRIBUTES |
| USER_PRIVILEGES |
| VIEWS |
| VIEW_ROUTINE_USAGE |
| VIEW_TABLE_USAGE |
+---------------------------------------+
78 rows in set (0.00 sec)
#查询的当前数据库中所有的数据库名
mysql> select schema_name from schemata;#SCHEMA_NAME字段保存了所有的数据库名
+--------------------+
| SCHEMA_NAME |
+--------------------+
| mysql |
| information_schema |
| performance_schema |
| sys |
| zabbix |
+--------------------+
#看下tables的表结构
mysql> desc tables;
+-----------------+--------------------------------------------------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+--------------------------------------------------------------------+------+-----+---------+-------+
| TABLE_CATALOG | varchar(64) | NO | | NULL | |
| TABLE_SCHEMA | varchar(64) | NO | | NULL | |
| TABLE_NAME | varchar(64) | NO | | NULL | |
| TABLE_TYPE | enum('BASE TABLE','VIEW','SYSTEM VIEW') | NO | | NULL | |
| ENGINE | varchar(64) | YES | | NULL | |
| VERSION | int | YES | | NULL | |
| ROW_FORMAT | enum('Fixed','Dynamic','Compressed','Redundant','Compact','Paged') | YES | | NULL | |
| TABLE_ROWS | bigint unsigned | YES | | NULL | |
| AVG_ROW_LENGTH | bigint unsigned | YES | | NULL | |
| DATA_LENGTH | bigint unsigned | YES | | NULL | |
| MAX_DATA_LENGTH | bigint unsigned | YES | | NULL | |
| INDEX_LENGTH | bigint unsigned | YES | | NULL | |
| DATA_FREE | bigint unsigned | YES | | NULL | |
| AUTO_INCREMENT | bigint unsigned | YES | | NULL | |
| CREATE_TIME | timestamp | NO | | NULL | |
| UPDATE_TIME | datetime | YES | | NULL | |
| CHECK_TIME | datetime | YES | | NULL | |
| TABLE_COLLATION | varchar(64) | YES | | NULL | |
| CHECKSUM | bigint | YES | | NULL | |
| CREATE_OPTIONS | varchar(256) | YES | | NULL | |
| TABLE_COMMENT | text | YES | | NULL | |
+-----------------+--------------------------------------------------------------------+------+-----+---------+-------+
21 rows in set (0.03 sec)
mysql> select table_name,table_schema from tables;
+------------------------------------------------------+--------------------+
| TABLE_NAME | TABLE_SCHEMA |
+------------------------------------------------------+--------------------+
| ADMINISTRABLE_ROLE_AUTHORIZATIONS | information_schema |
| APPLICABLE_ROLES | information_schema |
| CHARACTER_SETS | information_schema |
| CHECK_CONSTRAINTS | information_schema |
| COLLATIONS | information_schema |
| COLLATION_CHARACTER_SET_APPLICABILITY | information_schema |
| COLUMNS | information_schema |
| COLUMNS_EXTENSIONS | information_schema |
| COLUMN_PRIVILEGES | information_schema |
| COLUMN_STATISTICS | information_schema |
| ENABLED_ROLES | information_schema |
| ENGINES | information_schema |
| EVENTS | information_schema |
| FILES | information_schema |
#查询某数据库中包含的所有表
mysql> select TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA = 'mysql';
+---------------------------+
| TABLE_NAME |
+---------------------------+
| columns_priv |
| component |
| db |
| default_roles |
| engine_cost |
| func |
| general_log |
相当于show tables from mysql;
#查看某个表中的字段情况:
mysql> show columns from mysql.user;
+--------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------------------+-----------------------------------+------+-----+-----------------------+-------+
| Host | char(255) | NO | PRI | | |
| User | char(32) | NO | PRI | | |
| Select_priv | enum('N','Y') | NO | | N | |
| Insert_priv | enum('N','Y') | NO | | N | |
| Update_priv | enum('N','Y') | NO | | N | |
| Delete_priv | enum('N','Y') | NO | | N | |
| Create_priv | enum('N','Y') | NO | | N | |
| Drop_priv | enum('N','Y') | NO | | N | |
| Reload_priv | enum('N','Y') | NO | | N | |
| Shutdown_priv | enum('N','Y') | NO | | N | |
| Process_priv | enum('N','Y') | NO | | N | |
| File_priv | enum('N','Y') | NO | | N | |
| Grant_priv | enum('N','Y') | NO | | N | |
| References_priv | enum('N','Y') | NO | | N | |
| Index_priv | enum('N','Y') | NO | | N | |
#单表记录数超过1000W的数据库查询
mysql> select table_schema,table_name,table_rows from information_schema.tables where table_rows >=100000;
+--------------------+----------------------------------------------+------------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_ROWS |
+--------------------+----------------------------------------------+------------+
| performance_schema | events_errors_summary_by_account_by_error | 187264 |
| performance_schema | events_errors_summary_by_host_by_error | 187264 |
| performance_schema | events_errors_summary_by_thread_by_error | 374528 |
| performance_schema | events_errors_summary_by_user_by_error | 187264 |
| performance_schema | events_waits_summary_by_thread_by_event_name | 141824 |
| performance_schema | memory_summary_by_thread_by_event_name | 115200 |
| performance_schema | session_account_connect_attrs | 131072 |
| performance_schema | session_connect_attrs | 131072 |
| performance_schema | variables_by_thread | 159488 |
| zabbix | history | 7517515 |
| zabbix | history_uint | 5756152 |
| zabbix | trends | 6700891 |
| zabbix | trends_uint | 5228958 |
+--------------------+----------------------------------------------+------------+
13 rows in set (0.00 sec)
##查看数据库所有索引
SELECT * FROM mysql.`innodb_index_stats` a WHERE a.`database_name` = 'zabbix';
#查看某一表索引
mysql> SELECT * FROM mysql.`innodb_index_stats` a WHERE a.`database_name` = 'zabbix' and a.table_name like '%events%';
+---------------+------------+------------+---------------------+--------------+------------+-------------+--------------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+------------+------------+---------------------+--------------+------------+-------------+--------------------------------------+
| zabbix | events | PRIMARY | 2022-01-28 03:03:27 | n_diff_pfx01 | 54917 | 20 | eventid
#数据库表空间大于1T检查
SELECT table_schema as 'Database',table_name, \
CONCAT(ROUND(data_length/(1024*1024*1024),6),' G') AS 'Data Size', \
CONCAT(ROUND(index_length/(1024*1024*1024),6),' G') AS 'Index Size', \
CONCAT(ROUND((data_length+index_length)/(1024*1024*1024),6),' G') AS'Total' \
FROM information_schema.TABLES;
+--------------------+------------------------------------------------------+------------+------------+------------+
| Database | TABLE_NAME | Data Size | Index Size | Total |
+--------------------+------------------------------------------------------+------------+------------+------------+
| information_schema | ADMINISTRABLE_ROLE_AUTHORIZATIONS | 0.000000 G | 0.000000 G | 0.000000 G |
| information_schema | APPLICABLE_ROLES | 0.000000 G | 0.000000 G | 0.000000 G |
| information_schema | CHARACTER_SETS | 0.000000 G | 0.000000 G | 0.000000 G |
information_schema数据库表说明:
SCHEMATA表:提供了当前mysql实例中所有数据库的信息。是show databases的结果取之此表。
TABLES表:提供了关于数据库中的表的信息(包括视图)。详细表述了某个表属于哪个schema,表类型,表引擎,创建时间等信息。是show tables from schemaname的结果取之此表。不管在哪个数据库中的表,在这里都会有一条记录对应,如果你在一个数据库中创建了一个表,相应地在这个表里,也会有一条记录对应你创建的那个表。
COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。是show columns from schemaname.tablename的结果取之此表。
STATISTICS表:提供了关于表索引的信息。是show index from schemaname.tablename的结果取之此表。
USER_PRIVILEGES(用户权限)表:给出了关于全局权限的信息。该信息源自mysql.user授权表。是非标准表。
SCHEMA_PRIVILEGES(方案权限)表:给出了关于方案(数据库)权限的信息。该信息来自mysql.db授权表。是非标准表。
TABLE_PRIVILEGES(表权限)表:给出了关于表权限的信息。该信息源自mysql.tables_priv授权表。是非标准表。
COLUMN_PRIVILEGES(列权限)表:给出了关于列权限的信息。该信息源自mysql.columns_priv授权表。是非标准表。
CHARACTER_SETS(字符集)表:提供了mysql实例可用字符集的信息。是SHOW CHARACTER SET结果集取之此表。
COLLATIONS表:提供了关于各字符集的对照信息。
COLLATION_CHARACTER_SET_APPLICABILITY表:指明了可用于校对的字符集。这些列等效于SHOW COLLATION的前两个显示字段。
TABLE_CONSTRAINTS表:描述了存在约束的表。以及表的约束类型。
KEY_COLUMN_USAGE表:描述了具有约束的键列。
ROUTINES表:提供了关于存储子程序(存储程序和函数)的信息。此时,ROUTINES表不包含自定义函数(UDF)。名为“mysql.proc name”的列指明了对应于INFORMATION_SCHEMA.ROUTINES表的mysql.proc表列。
VIEWS表:给出了关于数据库中的视图的信息。需要有show views权限,否则无法查看视图信息。
TRIGGERS表:提供了关于触发程序的信息。必须有super权限才能查看该表.2)PERFORMANCE_SCHEMA库
MySQL 5.5开始新增了该数据库:PERFORMANCE_SCHEMA,主要用于收集数据库服务器性能参数。并且库里表的存储引擎均为PERFORMANCE_SCHEMA,而用户是不能创建存储引擎为PERFORMANCE_SCHEMA表的。MySQL5.5默认是关闭的,需要手动开启,
在配置文件里添加:
[mysqld]
performance_schema=ON #该参数为只读参数,需要在实例启动之前设置才生效
主要功能:
①提供了一种在数据库运行时实时检查server的内部执行情况的方法。performance_schema 数据库中的表使用performance_schema存储引擎。该数据库主要关注数据库运行过程中的性能相关的数据,与information_schema不同,information_schema主要关注server运行过程中的元数据信息。提供进程等待的详细信息,包括锁、互斥变量、文件信息;
②保存历史的事件汇总信息,为提供MySQL服务器性能做出详细的判断;performance_schema通过监视server的事件来实现监视server内部运行情况, “事件”就是server内部活动中所做的任何事情以及对应的时间消耗,利用这些信息来判断server中的相关资源消耗在了哪里?一般来说,事件可以是函数调用、操作系统的等待、SQL语句执行的阶段(如sql语句执行过程中的parsing 或 sorting阶段)或者整个SQL语句与SQL语句集合。事件的采集可以方便的提供server中的相关存储引擎对磁盘文件、表I/O、表锁等资源的同步调用信息。performance_schema中的事件与写入二进制日志中的事件(描述数据修改的events)、事件计划调度程序(这是一种存储程序)的事件不同。performance_schema中的事件记录的是server执行某些活动对某些资源的消耗、耗时、这些活动执行的次数等情况。performance_schema中的事件只记录在本地server的performance_schema中,其下的这些表中数据发生变化时不会被写入binlog中,也不会通过复制机制被复制到其他server中。
③对于新增和删除监控事件点都非常容易,并可以改变mysql服务器的监控周期,例如(CYCLE、MICROSECOND)。
通过该库得到数据库运行的统计信息,更好分析定位问题和完善监控信息。
当前活跃事件、历史事件和事件摘要相关的表中记录的信息。能提供某个事件的执行次数、使用时长。进而可用于分析某个特定线程、特定对象(如mutex或file)相关联的活动。
performance_schema存储引擎使用server源代码中的“检测点”来实现事件数据的收集。对于performance_schema实现机制本身的代码没有相关的单独线程来检测,这与其他功能(如复制或事件计划程序)不同。
收集的事件数据存储在performance_schema数据库的表中。这些表可以使用SELECT语句查询,也可以使用SQL语句更新performance_schema数据库中的表记录(如动态修改performance_schema的setup_*开头的几个配置表,但要注意:配置表的更改会立即生效,这会影响数据收集)。
performance_schema的表中的数据不会持久化存储在磁盘中,而是保存在内存中,一旦服务器重启,这些数据会丢失(包括配置表在内的整个performance_schema下的所有数据)。
MySQL支持的所有平台中事件监控功能都可用,但不同平台中用于统计事件时间开销的计时器类型可能会有所差异。
performance_schema实现机制遵循以下设计目标:
启用performance_schema不会导致server的行为发生变化。例如,它不会改变线程调度机制,不会导致查询执行计划(如EXPLAIN)发生变化。
启用performance_schema之后,server会持续不间断地监测,开销很小。不会导致server不可用。
在该实现机制中没有增加新的关键字或语句,解析器不会变化。
即使performance_schema的监测机制在内部对某事件执行监测失败,也不会影响server正常运行。
如果在开始收集事件数据时碰到有其他线程正在针对这些事件信息进行查询,那么查询会优先执行事件数据的收集,因为事件数据的收集是一个持续不断的过程,而检索(查询)这些事件数据仅仅只是在需要查看的时候才进行检索。也可能某些事件数据永远都不会去检索。
需要很容易地添加新的instruments监测点。
instruments(事件采集项)代码版本化:如果instruments的代码发生了变更,旧的instruments代码还可以继续工作。
#查看是否开启:
mysql>show variables like 'performance_schema';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| performance_schema | ON |
+--------------------+-------+
1 row in set (0.04 sec)
#值为ON表示performance_schema已初始化成功且可以使用了
mysql> select version(); #从MySQL5.6开始,performance_schema引擎默认打开
+-----------+
| version() |
+-----------+
| 8.0.21 |
+-----------+
1 row in set (0.00 sec)
#检查performance_schema存储引擎支持情况
mysql> select engine,support from information_schema.engines where engine='PERFORMANCE_SCHEMA';
+--------------------+---------+
| engine | support |
+--------------------+---------+
| PERFORMANCE_SCHEMA | YES |
+--------------------+---------+
1 row in set (0.00 sec)
#查询哪些表使用performance_schema引擎,
mysql> select table_name from information_schema.tables where engine='performance_schema';
#查看数据库系统中打开了文件的对象:包括ibdata文件,redo文件,binlog文件,用户的表文件等,open_count显示当前文件打开的数目,如果重来没有打开过,不会出现在表中。
mysql> select * from file_instances limit 2,5;
+--------------------------------+---------------------------------------+------------+
| FILE_NAME | EVENT_NAME | OPEN_COUNT |
+--------------------------------+---------------------------------------+------------+
| /video/mysql/ibdata1 | wait/io/file/innodb/innodb_data_file | 3 |
| /video/mysql/#ib_16384_0.dblwr | wait/io/file/innodb/innodb_dblwr_file | 2 |
| /video/mysql/#ib_16384_1.dblwr | wait/io/file/innodb/innodb_dblwr_file | 2 |
| /video/mysql/ib_logfile0 | wait/io/file/innodb/innodb_log_file | 2 |
| /video/mysql/ib_logfile1 | wait/io/file/innodb/innodb_log_file | 2 |
+--------------------------------+---------------------------------------+------------+
5 rows in set (0.00 sec)
#查看哪个SQL执行最多
mysql> select schema_name,digest_text,count_star,sum_rows_sent,sum_rows_examined,first_seen,last_seen from events_statements_summary_by_digest order by count_star desc limit 1\G
*************************** 1. row ***************************
schema_name: zabbix
digest_text: BEGIN
count_star: 228311169 #执行次数
sum_rows_sent: 0
sum_rows_examined: 0
first_seen: 2021-03-16 10:43:00.830886
last_seen: 2022-01-27 22:56:10.547003
1 row in set (0.04 sec)
#哪个SQL平均响应时间最多
mysql> select schema_name,digest_text,count_star,avg_timer_wait,sum_rows_sent,sum_rows_examined,first_seen,last_seen from events_statements_summary_by_digest order by avg_timer_wait desc limit 1\G
*************************** 1. row ***************************
schema_name: zabbix
digest_text: SELECT `clock` , `ns` , VALUE FROM HISTORY WHERE `itemid` = ? AND `clock` > ? AND `clock` <= ?
count_star: 576
avg_timer_wait: 250369909000 #该SQL平均响应时间,皮秒(1000000000000皮秒=1秒)
sum_rows_sent: 1564
sum_rows_examined: 1564
first_seen: 2021-03-18 02:10:54.662146
last_seen: 2022-01-24 17:04:28.496527
1 row in set (0.00 sec)
#哪个SQL扫描的行数最多
mysql> select schema_name,digest_text,count_star,avg_timer_wait,sum_rows_sent,sum_rows_examined,first_seen,last_seen from events_statements_summary_by_digest order by sum_rows_examined desc limit 1\G
*************************** 1. row ***************************
schema_name: zabbix
digest_text: SELECT DISTINCTROW `d` . `triggerid_down` , `d` . `triggerid_up` FROM `trigger_depends` `d` , TRIGGERS `t` , HOSTS `h` , `items` `i` , `functions` `f` WHERE `t` . `triggerid` = `d` . `triggerid_down` AND `t` . `flags` != ? AND `h` . `hostid` = `i` . `hostid` AND `i` . `itemid` = `f` . `itemid` AND `f` . `triggerid` = `d` . `triggerid_down` AND `h` . `status` IN (...)
count_star: 456338
avg_timer_wait: 14573128000
sum_rows_sent: 209333096
sum_rows_examined: 4484007395 ##主要关注
first_seen: 2021-03-16 10:43:14.363971
last_seen: 2022-01-27 23:01:58.261088
1 row in set (0.01 sec)
#哪个SQL使用的临时表最多
mysql> select schema_name,digest_text,count_star,avg_timer_wait,sum_rows_sent,sum_rows_examined,sum_created_tmp_tables,sum_created_tmp_disk_tables,first_seen,last_seen from events_statements_summary_by_digest order by sum_created_tmp_tables desc limit 1\G
*************************** 1. row ***************************
schema_name: zabbix
digest_text: SELECT DISTINCTROW `g` . `graphid` , `g` . `name` , `g` . `width` , `g` . `height` , `g` . `yaxismin` , `g` . `yaxismax` , `g` . `show_work_period` , `g` . `show_triggers` , `g` . `graphtype` , `g` . `show_legend` , `g` . `show_3d` , `g` . `percent_left` , `g` . `percent_right` , `g` . `ymin_type` , `g` . `ymin_itemid` , `g` . `ymax_type` , `g` . `ymax_itemid` , `g` . `discover` FROM `graphs` `g` , `graphs_items` `gi` , `items` `i` , `item_discovery` `id` WHERE `g` . `graphid` = `gi` . `graphid` AND `gi` . `itemid` = `i` . `itemid` AND `i` . `itemid` = `id` . `itemid` AND `id` . `parent_itemid` = ?
count_star: 7359187
avg_timer_wait: 443879000
sum_rows_sent: 14083781
sum_rows_examined: 306592148
sum_created_tmp_tables: 7359204 ##主要关注
sum_created_tmp_disk_tables: 0
first_seen: 2021-03-16 10:43:02.510002
last_seen: 2022-01-27 23:05:19.469465
1 row in set (0.00 sec)
#哪个SQL返回的结果集最多
mysql> select schema_name,digest_text,count_star,avg_timer_wait,sum_rows_sent,sum_rows_examined,sum_created_tmp_tables,first_seen,last_seen from events_statements_summary_by_digest order by sum_rows_sent desc limit 1\G
*************************** 1. row ***************************
schema_name: zabbix
digest_text: SELECT `i` . `itemid` , `i` . `hostid` , `i` . `templateid` FROM `items` `i` INNER JOIN HOSTS `h` ON `i` . `hostid` = `h` . `hostid` WHERE `h` . `status` = ?
count_star: 456344
avg_timer_wait: 5604268000
sum_rows_sent: 1706726560 #主要关注
sum_rows_examined: 1770168229
sum_created_tmp_tables: 0
first_seen: 2021-03-16 10:43:14.292694
last_seen: 2022-01-27 23:07:58.857928
1 row in set (0.00 sec)
#哪个SQL排序数最多,其中IO(SUM_ROWS_EXAMINED),CPU消耗(SUM_SORT_ROWS),网络带宽(SUM_ROWS_SENT)
mysql> select schema_name,digest_text,count_star,avg_timer_wait,sum_rows_sent,sum_rows_examined,sum_sort_rows,first_seen,last_seen fromevents_statements_summary_by_digest order by sum_sort_rows desc limit 1\G
*************************** 1. row ***************************
schema_name: zabbix
digest_text: SELECT `pp` . `item_preprocid` , `pp` . `itemid` , `pp` . `type` , `pp` . `params` , `pp` . `step` , `i` . `hostid` , `pp` . `error_handler` , `pp` . `error_handler_params` , `i` . `type` , `i` . `key_` , `h` . `proxy_hostid` FROM `item_preproc` `pp` , `items` `i` , HOSTS `h` WHERE `pp` . `itemid` = `i` . `itemid` AND `i` . `hostid` = `h` . `hostid` AND ( `h` . `proxy_hostid` IS NULL OR `i` . `type` IN (...) ) AND `h` . `status` IN (...) AND `i` . `flags` != ? ORDER BY `pp` . `itemid`
count_star: 456346
avg_timer_wait: 14210098000
sum_rows_sent: 1069260615
sum_rows_examined: 3582380844
sum_sort_rows: 1069260615 #主要关注
first_seen: 2021-03-16 10:43:14.313793
last_seen: 2022-01-27 23:09:59.091879
1 row in set (0.00 sec)
#哪个表、文件逻辑IO最多(热数据):file_summary_by_instance表,意味着这个表经常需要访问磁盘IO
mysql> select file_name,event_name,count_read,sum_number_of_bytes_read,count_write,sum_number_of_bytes_write from file_summary_by_instance order by sum_number_of_bytes_read+sum_number_of_bytes_write desc limit 2\G
*************************** 1. row ***************************
file_name: /video/mysql/#ib_16384_0.dblwr
event_name: wait/io/file/innodb/innodb_dblwr_file
count_read: 1
sum_number_of_bytes_read: 1179648
count_write: 5546947
sum_number_of_bytes_write: 523535138816
*************************** 2. row ***************************
file_name: /video/mysql/ib_logfile1
event_name: wait/io/file/innodb/innodb_log_file
count_read: 0
sum_number_of_bytes_read: 0
count_write: 180237316
sum_number_of_bytes_write: 266296773120
2 rows in set (0.00 sec)
#查看哪个表逻辑IO最多,亦即最“热”的表
mysql> SELECT
-> object_name,
-> COUNT_READ,
-> COUNT_WRITE,
-> COUNT_FETCH,
-> SUM_TIMER_WAIT
-> FROM table_io_waits_summary_by_table
-> ORDER BY sum_timer_wait DESC limit 1\G
*************************** 1. row ***************************
object_name: history #关注
COUNT_READ: 384830011
COUNT_WRITE: 750076101
COUNT_FETCH: 384830011
SUM_TIMER_WAIT: 29159481894425960
1 row in set (0.01 sec)
#获得系统运行到现在,哪个表的具体哪个索引(包括主键索引,二级索引)使用最多
mysql> select object_name,index_name,count_fetch,count_insert,count_update,count_delete from table_io_waits_summary_by_index_usage order by sum_timer_wait desc limit 1\G
*************************** 1. row ***************************
object_name: history
index_name: NULL
count_fetch: 0
count_insert: 374268229
count_update: 0
count_delete: 0
1 row in set (0.00 sec)
+-------------+------------+-------------+--------------+--------------+--------------+
| object_name | index_name | count_fetch | count_insert | count_update | count_delete |
+-------------+------------+-------------+--------------+--------------+--------------+
| history | NULL | 0 | 374268557 | 0 | 0 |
+-------------+------------+-------------+--------------+--------------+--------------+
#获取哪个索引没有使用过
mysql> select object_schema,object_name,index_name from table_io_waits_summary_by_index_usage \
-> where index_name is not null and \
-> count_star =0 and \
-> object_schema <> 'mysql' order by object_schema,object_name;
+--------------------+------------------------------------------------------+----------------------------------+
| object_schema | object_name | index_name |
+--------------------+------------------------------------------------------+----------------------------------+
| performance_schema | accounts | ACCOUNT |
| performance_schema | cond_instances | PRIMARY |
| performance_schema | cond_instances | NAME |
| performance_schema | data_lock_waits | BLOCKING_THREAD_ID |
| performance_schema | data_lock_waits | REQUESTING_ENGINE_LOCK_ID |
| performance_schema | data_lock_waits | BLOCKING_ENGINE_LOCK_ID |
| performance_schema | data_lock_waits | REQUESTING_ENGINE_TRANSACTION_ID |
| performance_schema | data_lock_waits | BLOCKING_ENGINE_TRANSACTION_ID |
| performance_schema | data_lock_waits | REQUESTING_THREAD_ID |
| performance_schema | data_locks | OBJECT_SCHEMA |
| performance_schema | data_locks | THREAD_ID |
| performance_schema | data_locks | ENGINE_TRANSACTION_ID |
| performance_schema | data_locks | PRIMARY |
| performance_schema | events_errors_summary_by_account_by_error | ACCOUNT |
| performance_schema | events_errors_summary_by_host_by_error | HOST |
| performance_schema | events_errors_summary_by_thread_by_error | THREAD_ID |
| performance_schema | events_errors_summary_by_user_by_error | USER |
| zabbix | task_result | task_result_1 |
| zabbix | task_result | PRIMARY |
| zabbix | timeperiods | PRIMARY |
| zabbix | trigger_depends | PRIMARY |
| zabbix | trigger_depends | trigger_depends_2 |
| zabbix | trigger_tag | trigger_tag_1 |
| zabbix | trigger_tag | PRIMARY |
| zabbix | triggers | triggers_1 |
| zabbix | triggers | triggers_2 |
| zabbix | triggers | triggers_3 |
| zabbix | users_groups | users_groups_2 |
| zabbix | users_groups | users_groups_1 |
| zabbix | users_groups | PRIMARY |
| zabbix | widget_field | widget_field_5 |
| zabbix | widget_field | PRIMARY |
| zabbix | widget_field | widget_field_4 |
| zabbix | widget_field | widget_field_6 |
| zabbix | widget_field | widget_field_3 |
| zabbix | widget_field | widget_field_2 |
| zabbix | widget_field | widget_field_1 |
+--------------------+------------------------------------------------------+----------------------------------+
331 rows in set (0.00 sec)
#查询哪个等待事件消耗的时间最多
mysql> select event_name,count_star,sum_timer_wait,avg_timer_wait from events_waits_summary_global_by_event_name where event_name != 'idle' order by sum_timer_wait desc limit 1;
+-------------------------+------------+---------------------+----------------+
| event_name | count_star | sum_timer_wait | avg_timer_wait |
+-------------------------+------------+---------------------+----------------+
| wait/io/file/sql/binlog | 195515509 | 1538632653524464190 | 7869619450 |
+-------------------------+------------+---------------------+----------------+
1 row in set (0.02 sec)
#InnoDB监控
#打开标准的innodb监控:
CREATE TABLE innodb_monitor (a INT) ENGINE=INNODB;
#打开innodb的锁监控:
CREATE TABLE innodb_lock_monitor (a INT) ENGINE=INNODB;
#打开innodb表空间监控:
CREATE TABLE innodb_tablespace_monitor (a INT) ENGINE=INNODB;
#打开innodb表监控:
CREATE TABLE innodb_table_monitor (a INT) ENGINE=INNODB;
#剖析某条SQL的执行情况,该SQL在执行各个阶段的时间消耗,可查看events_statements_xxx表和events_stages_xxx表,包括statement信息,stage信息和wait信息
#eg:比如分析包含count(*)的某条SQL语句
mysql> SELECT
-> EVENT_ID,
-> sql_text
-> FROM events_statements_history
-> WHERE sql_text LIKE '%count(*)%';
+----------+-------------------------------------------------------------------------------------------+
| EVENT_ID | sql_text |
+----------+-------------------------------------------------------------------------------------------+
| 246 | select count(*) from zabbix.task |
| 248 | select count(*) from zabbix.items |
| 242 | SELECT
EVENT_ID,
sql_text
FROM events_statements_history
WHERE sql_text LIKE '%count(*)%' |
| 243 | select count(*) from zabbix.tasks |
+----------+-------------------------------------------------------------------------------------------+
4 rows in set (0.00 sec)
#查看每个阶段的时间消耗,时间单位以皮秒表示,注意默认情况下events_stages_history表中只为每个连接记录了最近10条记录,为了确保获取所有记录,需要访问events_stages_history_long表
mysql> SELECT
-> event_id,
-> EVENT_NAME,
-> SOURCE,
-> TIMER_END - TIMER_START
-> FROM events_stages_history_long
-> WHERE NESTING_EVENT_ID = 248;
#查看某个阶段的锁等待情况;针对每个stage可能出现的锁等待,一个stage会对应一个或多个wait,events_waits_history_long这个表容易爆满[默认阀值10000]。由于select count(*)需要IO(逻辑IO或者物理IO),所以在stage/sql/Sending data阶段会有io等待的统计
mysql> SELECT
-> event_id,
-> event_name,
-> source,
-> timer_wait,
-> object_name,
-> index_name,
-> operation,
-> nesting_event_id
-> FROM events_waits_history_long
-> WHERE nesting_event_id = 248;
Empty set (0.00 sec)
3)sys 库
sys schem在5.7.x版本默认安装,sys schema是一组对象(包括相关的视图、存储过程和函数),可以方便地访问performance_schema收集的数据。同时检索的数据可读性也更高(例如:performance_schema中的时间单位是皮秒,经过sys schema查询时会转换为可读的us,ms,s,min,hour,day等单位)。sys中的数据实际上主要是从performance_schema、information_schema中获取。通过sys库不仅可以完成MySQL信息的收集,还可以用来监控和排查问题。
sys库主要内容:
1)这个库是通过视图的形式把information_schema 和performance_schema结合起来,查询出更加令人容易理解的数据
2)存储过程可以可以执行一些性能方面的配置,也可以得到一些性能诊断报告内容
3)存储函数可以查询一些性能信息
#查看用户、连接情况
查看每个客户端IP过来的连接消耗资源情况。
mysql> select host,current_connections,total_connections,unique_users,current_memory,total_memory_allocated from sys.host_summary;
+-----------+---------------------+-------------------+--------------+----------------+------------------------+
| host | current_connections | total_connections | unique_users | current_memory | total_memory_allocated |
+-----------+---------------------+-------------------+--------------+----------------+------------------------+
| localhost | 20 | 458106 | 2 | 20.99 GiB | 46.42 TiB |
+-----------+---------------------+-------------------+--------------+----------------+------------------------+
1 row in set (0.01 sec)
#查看每个用户消耗资源情况
mysql> select user,table_scans,file_ios,file_io_latency,current_connections,current_memory from sys.user_summary;
+------------+-------------+-----------+-----------------+---------------------+----------------+
| user | table_scans | file_ios | file_io_latency | current_connections | current_memory |
+------------+-------------+-----------+-----------------+---------------------+----------------+
| zabbix | 12575536 | 195754143 | 17.84 d | 19 | 10.49 GiB |
| root | 32 | 84 | 335.81 ms | 1 | 2.48 MiB |
| background | 0 | 442868581 | 14.88 d | 53 | 233.65 MiB |
+------------+-------------+-----------+-----------------+---------------------+----------------+
3 rows in set (0.01 sec)
#查看当前正在执行的SQL
mysql> select conn_id,pid,user,db,command,current_statement,last_statement,time,lock_latency from sys.session;
+---------+-------+---------------------+--------+---------+-------------------------------------------------------------------+-------------------------------------------------------------------+------+--------------+
| conn_id | pid | user | db | command | current_statement | last_statement | time | lock_latency |
+---------+-------+---------------------+--------+---------+-------------------------------------------------------------------+-------------------------------------------------------------------+------+--------------+
| 28 | 17167 | zabbix@localhost | zabbix | Sleep | select itemid from items where ... and flags<>2 and hostid=10084 | select itemid from items where ... and flags<>2 and hostid=10084 | 203 | 46.00 us |
| 15 | 17168 | zabbix@localhost | zabbix | Sleep | select itemid from items where ... and flags<>2 and hostid=10084 | select itemid from items where ... and flags<>2 and hostid=10084 | 164 | 52.00 us |
| 24 | 17147 | zabbix@localhost | zabbix | Sleep | select co.corr_operationid,co. ... o.correlationid and c.status=0 | select co.corr_operationid,co. ... o.correlationid and c.status=0 | 58 | 44.00 us |
| 30 | 17169 | zabbix@localhost | zabbix | Sleep | select itemid from items where ... and flags<>2 and hostid=10084 | select itemid from items where ... and flags<>2 and hostid=10084 | 44 | 42.00 us |
| 26 | 17166 | zabbix@localhost | zabbix | Sleep | commit | commit | 40 | 0 ps |
| 10 | 17149 | zabbix@localhost | zabbix | Sleep | commit | commit | 13 | 0 ps |
| 16 | 17151 | zabbix@localhost | zabbix | Sleep | select dcheckid,type,key_,snmp ... re druleid=3 order by dcheckid | select dcheckid,type,key_,snmp ... re druleid=3 order by dcheckid | 6 | 48.00 us |
| 22 | 17170 | zabbix@localhost | zabbix | Sleep | select itemid from items where ... and flags<>2 and hostid=10084 | select itemid from items where ... and flags<>2 and hostid=10084 | 5 | 60.00 us |
| 21 | 17154 | zabbix@localhost | zabbix | Sleep | commit | commit | 5 | 0 ps |
| 14 | 17165 | zabbix@localhost | zabbix | Sleep | commit | commit | 4 | 0 ps |
| 23 | 17153 | zabbix@localhost | zabbix | Sleep | commit | commit | 3 | 0 ps |
| 8 | 17159 | zabbix@localhost | zabbix | Sleep | select taskid,type,clock,ttl f ... tatus in (1,2) order by taskid | select taskid,type,clock,ttl f ... tatus in (1,2) order by taskid | 3 | 100.00 us |
| 20 | 17156 | zabbix@localhost | zabbix | Sleep | select escalationid,actionid,t ... ,triggerid,itemid,escalationid | select escalationid,actionid,t ... ,triggerid,itemid,escalationid | 3 | 47.00 us |
| 9 | 17150 | zabbix@localhost | zabbix | Sleep | select min(t.nextcheck) from h ... tus=0 or h.maintenance_type=0) | select min(t.nextcheck) from h ... tus=0 or h.maintenance_type=0) | 2 | 62.00 us |
| 11 | 17155 | zabbix@localhost | zabbix | Sleep | commit | commit | 2 | 0 ps |
| 458094 | 8986 | root@localhost | sys | Query | SET @sys.statement_truncate_le ... ('statement_truncate_len', 64) | NULL | 1 | 996.00 us |
| 13 | 17182 | zabbix@localhost | zabbix | Sleep | select h.hostid,h.host,h.name, ... tid and hd.parent_itemid=31891 | select h.hostid,h.host,h.name, ... tid and hd.parent_itemid=31891 | 1 | 59.00 us |
| 17 | 17181 | zabbix@localhost | zabbix | Sleep | select h.hostid,h.host,h.name, ... tid and hd.parent_itemid=31832 | select h.hostid,h.host,h.name, ... tid and hd.parent_itemid=31832 | 1 | 81.00 us |
| 18 | 17152 | zabbix@localhost | zabbix | Sleep | commit | commit | 1 | 0 ps |
| 19 | 17183 | zabbix@localhost | zabbix | Sleep | commit | commit | 1 | 0 ps |
| 5 | NULL | sql/event_scheduler | NULL | Sleep | NULL | NULL | NULL | NULL |
+---------+-------+---------------------+--------+---------+-------------------------------------------------------------------+-------------------------------------------------------------------+------+--------------+
21 rows in set (0.08 sec)
#查看发生IO请求前5名的文件
mysql> select * from sys.io_global_by_file_by_bytes order by total limit 5;
#查看总共分配了多少内存
mysql> select * from sys.memory_global_total;
mysql> select * from sys.memory_global_by_current_bytes;
#每个库(database)占用多少buffer pool;pages是指在buffer pool中的page数量;pages_old指在LUR 列表中处于后37%位置的page。当出现buffer page不够用时,就会征用这些page所占的空间。37%是默认位置,具体可以自定义。
mysql> select * from sys.innodb_buffer_stats_by_schema order by allocated desc;
+---------------+-----------+------------+--------+--------------+-----------+-------------+
| object_schema | allocated | data | pages | pages_hashed | pages_old | rows_cached |
+---------------+-----------+------------+--------+--------------+-----------+-------------+
| mysql | 5.95 MiB | 3.33 MiB | 381 | 185 | 275 | 1380 |
| zabbix | 2.25 GiB | 1.74 GiB | 147654 | 104738 | 55439 | 401231 |
| sys | 16.00 KiB | 338 bytes | 1 | 0 | 1 | 6 |
+---------------+-----------+------------+--------+--------------+-----------+-------------+
3 rows in set (2.58 sec)
#统计每张表具体在InnoDB中具体的情况,比如占多少页
mysql> select * from sys.innodb_buffer_stats_by_table;
+---------------+------------------------------+------------+-------------+-------+--------------+-----------+-------------+
| object_schema | object_name | allocated | data | pages | pages_hashed | pages_old | rows_cached |
+---------------+------------------------------+------------+-------------+-------+--------------+-----------+-------------+
| zabbix | history | 873.78 MiB | 629.83 MiB | 55922 | 36446 | 25499 | 9101216 |
| zabbix | history_uint | 598.88 MiB | 449.53 MiB | 38328 | 27248 | 16863 | 6572995 |
| zabbix | trends | 457.16 MiB | 388.25 MiB | 29258 | 22582 | 7277 | 7040277 |
| zabbix | trends_uint | 337.12 MiB | 291.23 MiB | 21576 | 17373 | 4991 | 5291601 |
| zabbix | events | 16.50 MiB | 11.24 MiB | 1056 | 582 | 263 | 66166 |
| zabbix | history_str | 5.12 MiB | 2.52 MiB | 328 | 40 | 86 | 29315 |
#查询每个连接分配了多少内存
mysql> SELECT b.USER, current_count_used, current_allocated, current_avg_alloc, current_max_alloc, total_allocated, current_statement FROM sys.memory_by_thread_by_current_bytes a, sys.session b WHERE a.thread_id = b.thd_id;
#查看表自增字段最大值和当前值,有时候做数据增长的监控,可以作为参考
mysql> select * from sys.schema_auto_increment_columns;
#MySQL索引使用情况统计
mysql> select * from sys.schema_auto_increment_columns;
#MySQL中有哪些冗余索引和无用索引;若库中展示没有冗余索引,则没有数据;当有联合索引idx_abc(a,b,c)和idx_a(a),那么idx_a就算冗余索引了。
mysql> select * from sys.schema_redundant_indexes;
#查看INNODB 锁信息
mysql> select * from sys.innodb_lock_waits;
#查看库级别的锁信息,这个需要先打开MDL锁的监控:
#打开MDL锁监控
update performance_schema.setup_instruments set enabled='YES',TIMED='YES' where name='wait/lock/metadata/sql/mdl';
mysql> select * from performance_schema.setup_instruments where name='wait/lock/metadata/sql/mdl';
+----------------------------+---------+-------+------------+------------+---------------+
| NAME | ENABLED | TIMED | PROPERTIES | VOLATILITY | DOCUMENTATION |
+----------------------------+---------+-------+------------+------------+---------------+
| wait/lock/metadata/sql/mdl | YES | YES | | 0 | NULL |
+----------------------------+---------+-------+------------+------------+---------------+
1 row in set (0.00 sec)
#MySQL内部有多个线程在运行,线程类型及数量
mysql> select user,count(*) from sys.`processlist` group by user;
#查看MySQL自增id的使用情况
mysql> SELECT
-> table_schema,
-> table_name,
-> ENGINE,
-> Auto_increment
-> FROM
-> information_schema.TABLES
-> WHERE
-> TABLE_SCHEMA NOT IN ( "INFORMATION_SCHEMA", "PERFORMANCE_SCHEMA", "MYSQL", "SYS" );
+--------------------+------------------------------------------------------+--------------------+----------------+
| TABLE_SCHEMA | TABLE_NAME | ENGINE | AUTO_INCREMENT |
+--------------------+------------------------------------------------------+--------------------+----------------+
| information_schema | ADMINISTRABLE_ROLE_AUTHORIZATIONS | NULL | NULL |
2.6、数据引擎
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.00 sec)
#查看当前数据库默认隔离级别
mysql> show global variables like '%isolation%';
+-----------------------+----------------+
| Variable_name | Value |
+-----------------------+----------------+
| transaction_isolation | READ-COMMITTED |
+-----------------------+----------------+
1 row in set (0.00 sec)
mysql> select @@global.transaction_isolation;
+--------------------------------+
| @@global.transaction_isolation |
+--------------------------------+
| READ-COMMITTED |
+--------------------------------+
1 row in set (0.00 sec)
#查看默认自动提交事务是否开启
mysql> show global variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> select @@global.autocommit;
+---------------------+
| @@global.autocommit |
+---------------------+
| 1 |
+---------------------+
1 row in set (0.00 sec)
mysql> show engine innodb status \G
*************************** 1. row ***************************
Type: InnoDB
Name:
Status:
=====================================
2022-10-12 19:07:39 0x7fea8ffff700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 35 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 1908188 srv_active, 0 srv_shutdown, 6489032 srv_idle
srv_master_thread log flush and writes: 8397210
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 3531015
OS WAIT ARRAY INFO: signal count 3558501
RW-shared spins 0, rounds 7415601, OS waits 3415283
RW-excl spins 0, rounds 748278, OS waits 20602
RW-sx spins 552, rounds 11861, OS waits 244
Spin rounds per wait: 7415601.00 RW-shared, 748278.00 RW-excl, 21.49 RW-sx
------------
TRANSACTIONS
------------
Trx id counter 19243668
Purge done for trx's n:o < 19243668 undo n:o < 0 state: running but idle
History list length 32
LIST OF TRANSACTIONS FOR EACH SESSION:
---TRANSACTION 422123507920512, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507919600, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507915952, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507914128, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507918688, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507917776, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507916864, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507912304, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507913216, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507915040, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507910480, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
---TRANSACTION 422123507911392, not started
0 lock struct(s), heap size 1136, 0 row lock(s)
--------
FILE I/O
--------
I/O thread 0 state: waiting for completed aio requests (insert buffer thread)
I/O thread 1 state: waiting for completed aio requests (log thread)
I/O thread 2 state: waiting for completed aio requests (read thread)
I/O thread 3 state: waiting for completed aio requests (read thread)
I/O thread 4 state: waiting for completed aio requests (read thread)
I/O thread 5 state: waiting for completed aio requests (read thread)
I/O thread 6 state: waiting for completed aio requests (write thread)
I/O thread 7 state: waiting for completed aio requests (write thread)
I/O thread 8 state: waiting for completed aio requests (write thread)
I/O thread 9 state: waiting for completed aio requests (write thread)
Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,
ibuf aio reads:, log i/o's:, sync i/o's:
Pending flushes (fsync) log: 0; buffer pool: 0
6223404 OS file reads, 24323047 OS file writes, 16317333 OS fsyncs
0.00 reads/s, 0 avg bytes/read, 2.74 writes/s, 2.23 fsyncs/s
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 1, free list len 0, seg size 2, 659 merges
merged operations:
insert 913, delete mark 103, delete 35
discarded operations:
insert 0, delete mark 0, delete 0
Hash table size 34673, node heap has 3 buffer(s)
Hash table size 34673, node heap has 9 buffer(s)
Hash table size 34673, node heap has 13 buffer(s)
Hash table size 34673, node heap has 2 buffer(s)
Hash table size 34673, node heap has 2 buffer(s)
Hash table size 34673, node heap has 6 buffer(s)
Hash table size 34673, node heap has 13 buffer(s)
Hash table size 34673, node heap has 2 buffer(s)
4.40 hash searches/s, 1.77 non-hash searches/s
---
LOG
---
Log sequence number 8268087675
Log flushed up to 8268087675
Pages flushed up to 8268087153
Last checkpoint at 8268087144
0 pending log flushes, 0 pending chkp writes
10746170 log i/o's done, 1.46 log i/o's/second
----------------------
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 137428992
Dictionary memory allocated 1082657
Buffer pool size 8191
Free buffers 1024
Database pages 7117
Old database pages 2607
Modified db pages 4
Pending reads 0
Pending writes: LRU 0, flush list 0, single page 0
Pages made young 772098, not young 39906636
0.00 youngs/s, 0.00 non-youngs/s
Pages read 6223019, created 102083, written 11737689
0.00 reads/s, 0.00 creates/s, 1.03 writes/s
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
LRU len: 7117, unzip_LRU len: 0
I/O sum[48]:cur[0], unzip sum[0]:cur[0]
--------------
ROW OPERATIONS
--------------
0 queries inside InnoDB, 0 queries in queue
0 read views open inside InnoDB
Process ID=19101, Main thread ID=140648158062336, state: sleeping
Number of rows inserted 12977848, updated 1936730, deleted 7422, read 388089484821
0.00 inserts/s, 0.26 updates/s, 0.00 deletes/s, 6.37 reads/s
----------------------------
END OF INNODB MONITOR OUTPUT
============================
1 row in set (0.04 sec)
#结果说明
Log:Innodb 事务日志相关信息,包括当前的日志序列号(Log sequence number),已经刷新同步到那个序列号,最近的check point到那个序列号了。除此之外,还显示了系统从启动到现在已经做了多少次check point,多少次日志刷新。不同时刻的lsn的值的差值/时间差==日志的产生速度
Log sequence number 2560255(当前的日志序列号,log buffer中已经写入的LSN值,//字节,日志生成的最新位置,最新位置出现在log buffer中),表刷出去了多少日志;Log sequence number - Log flushed up to== 当前logbuffer的值<1M;不同时刻的差值/时间间隔==日志的写入速度
Log flushed up to 2560255(刷新到日志重做日志文件的lsn,已经刷新到redo logfile的LSN值//字节,日志已经写入到log file的位置,1-2=log buffer日志量,最好是<=1M)
Pages flushed up to 2560255(写入磁盘的脏页的lsn。记录在checkpoint中//字节,脏页的数量(日志字节数来衡量),2-3=脏页的数量(日志字节为单位));Log sequence number - Pages flushed up to 值很小,说明脏页写入的很快
Last checkpoint at 2560246(刷新到磁盘的lsn,最近一次checkpoint时的LSN值//字节,共享表空间上的日志记录点,最后一次检查点,及崩溃恢复时指定的起点,3-4就是崩溃恢复多跑的日志,值越大说明需要提升checkpoint的跟进速度);系统启动的时候,日志恢复的起点,肯定比Pfut的值低。防止系统崩;Log flushed up to - Last checkpoint at == 系统要恢复的日志数;Pages flushed up to - Last checkpoint at == checkpoint的跟进速度,如果大的话,说明checkpoint需要增大。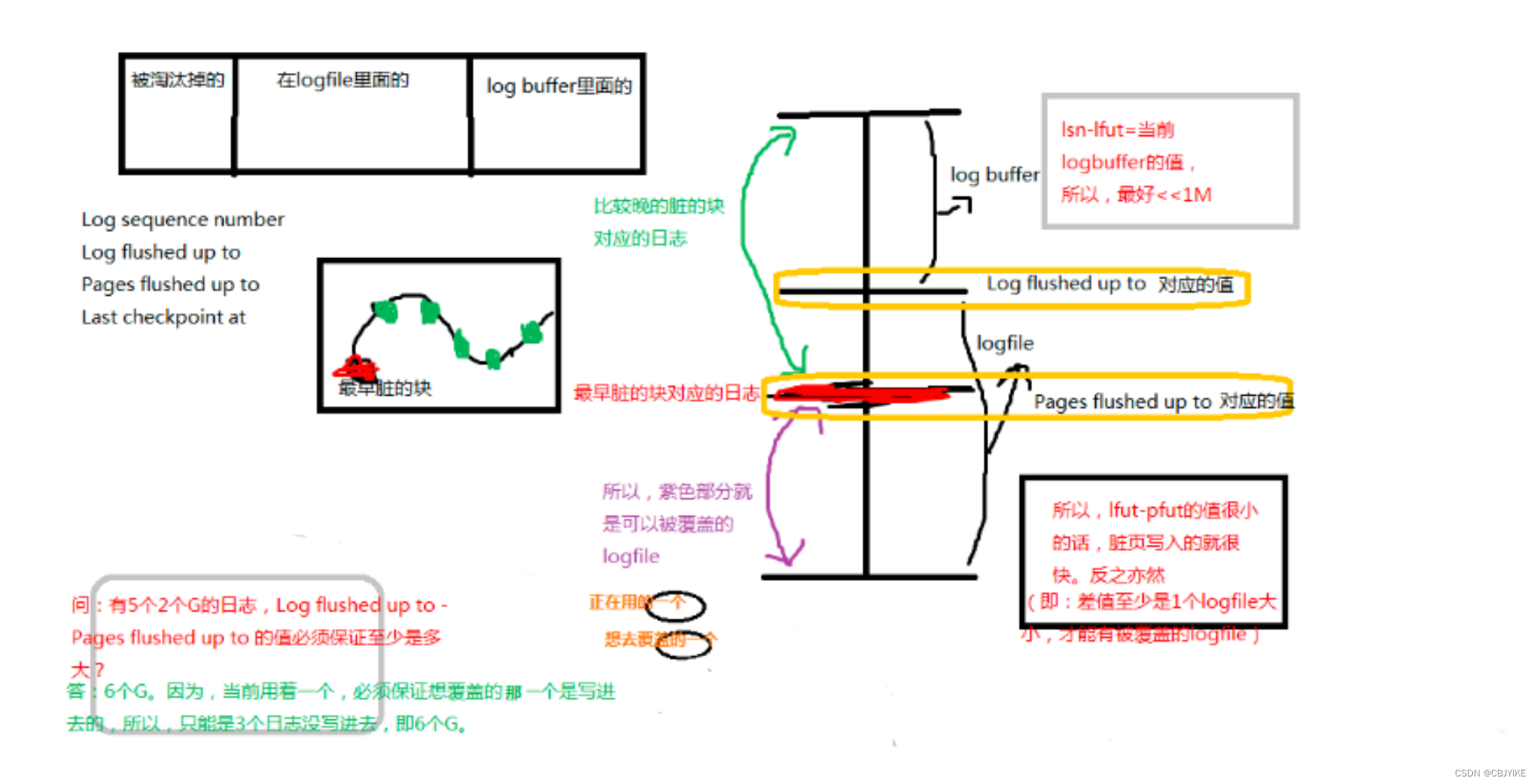
2.7、基础巡检
#数据文件存放路径
mysql> show variables like 'datadir';
+---------------+---------------+
| Variable_name | Value |
+---------------+---------------+
| datadir | /video/mysql/ |
+---------------+---------------+
1 row in set (0.00 sec)
#告警 mysql错误日志存放路径
mysql> show variables where variable_name = 'log_error';
+---------------+-----------------------------+
| Variable_name | Value |
+---------------+-----------------------------+
| log_error | /video/mysql/log/mysqld.log |
+---------------+-----------------------------+
1 row in set (0.00 sec)
#慢查询日志
mysql> show variables WHERE variable_name = 'slow_query_log_file';
+---------------------+---------------------------------------------+
| Variable_name | Value |
+---------------------+---------------------------------------------+
| slow_query_log_file | /video/mysql/yangguangcaigoutest02-slow.log |
+---------------------+---------------------------------------------+
1 row in set (0.00 sec)
#查询写入慢查询日志的时间阈值
mysql> show variables WHERE variable_name = 'long_query_time';
+-----------------+----------+
| Variable_name | Value |
+-----------------+----------+
| long_query_time | 2.000000 |
+-----------------+----------+
1 row in set (0.00 sec)
#查询哪个sql消耗资源情况
mysql> select Id,User,Host,db,Time,Info from information_schema.`PROCESSLIST` where info is not null;
+--------+------+-----------+------+------+-----------------------------------------------------------------------------------------------+
| Id | User | Host | db | Time | Info |
+--------+------+-----------+------+------+-----------------------------------------------------------------------------------------------+
| 458094 | root | localhost | sys | 0 | select Id,User,Host,db,Time,Info from information_schema.`PROCESSLIST` where info is not null |
+--------+------+-----------+------+------+-----------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
#查询是否锁表
show OPEN TABLES where In_use > 0;
#查询所有数据的大小
mysql> select concat(round(sum(data_length/1024/1024),2),'MB') as data from information_schema.tables;
+-----------+
| data |
+-----------+
| 1825.38MB |
+-----------+
1 row in set (0.00 sec)
# 检查mysql数据库各个表空间的大小(数据空间和索引空间以及总和)
select TABLE_NAME, \
concat(truncate(data_length/1024/1024/1024, 2), 'GB') as data_size, \
concat(truncate(index_length /1024/1024/1024, 2), 'GB') as index_size, \
truncate(data_length/1024/1024/1024, 2)+ truncate(index_length /1024/1024/1024, 2) \
from information_schema.tables where TABLE_SCHEMA = 'smapuum' order by data_length desc;
#查看锁情况
mysql> show status like 'innodb_row_lock_%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 124 |
| Innodb_row_lock_time_avg | 0 |
| Innodb_row_lock_time_max | 15 |
| Innodb_row_lock_waits | 386 |
+-------------------------------+-------+
5 rows in set (0.04 sec)
#nnodb_row_lock_current_waits : 当前等待锁的数量
#Innodb_row_lock_time : 系统启动到现在,锁定的总时间长度
#Innodb_row_lock_time_avg : 每次平均锁定的时间
#Innodb_row_lock_time_max : 最长一次锁定时间
#Innodb_row_lock_waits : 系统启动到现在总共锁定的次数
#查询是否锁表
mysql> show OPEN TABLES where In_use > 0;
#锁等待的对应关系
mysql> mysql> select * from sys.innodb_lock_waits\G
#当前运行的所有事务
select * from information_schema.innodb_trx\G
#show status like '%跟下面变量%';
Aborted_clients 由于客户没有正确关闭连接已经死掉,已经放弃的连接数量。
Aborted_connects 尝试已经失败的MySQL服务器的连接的次数。
Connections 试图连接MySQL服务器的次数。
Created_tmp_tables 当执行语句时,已经被创造了的隐含临时表的数量。
Delayed_insert_threads 正在使用的延迟插入处理器线程的数量。
Delayed_writes 用INSERT DELAYED写入的行数。
Delayed_errors 用INSERT DELAYED写入的发生某些错误(可能重复键值)的行数。
Flush_commands 执行FLUSH命令的次数。
Handler_delete 请求从一张表中删除行的次数。
Handler_read_first 请求读入表中第一行的次数。
Handler_read_key 请求数字基于键读行。
Handler_read_next 请求读入基于一个键的一行的次数。
Handler_read_rnd 请求读入基于一个固定位置的一行的次数。
Handler_update 请求更新表中一行的次数。
Handler_write 请求向表中插入一行的次数。
Key_blocks_used 用于关键字缓存的块的数量。
Key_read_requests 请求从缓存读入一个键值的次数。
Key_reads 从磁盘物理读入一个键值的次数。
Key_write_requests 请求将一个关键字块写入缓存次数。
Key_writes 将一个键值块物理写入磁盘的次数。
Max_used_connections 同时使用的连接的最大数目。
Not_flushed_key_blocks 在键缓存中已经改变但是还没被清空到磁盘上的键块。
Not_flushed_delayed_rows 在INSERT DELAY队列中等待写入的行的数量。
Open_tables 打开表的数量。
Open_files 打开文件的数量。
Open_streams 打开流的数量(主要用于日志记载)
Opened_tables 已经打开的表的数量。
Questions 发往服务器的查询的数量。
Slow_queries 要花超过long_query_time时间的查询数量。
Threads_connected 当前打开的连接的数量。
Threads_running 不在睡眠的线程数量。
Uptime 服务器工作了多少秒。
mysql> show variables like 'table_open%'; //MySQL线程一共能同时打开多少个表
mysql> show status like 'open%';
mysql> show global status like 'open%'; //Open_tables就是当前打开表的数目,通过flush tables命令可以关闭当前打开的表。而全局范围内查看的Opened_tables是个历史累计值。 这个值如果过大,并且如果没有经常的执行flush tables命令,可以考虑增加table_open_cache参数的大小。
mysql> show variables like 'max_tmp%'; //max_tmp_tables表单个客户端连接能打开的临时表数目
mysql> show global status like '%tmp%table%'; //对比Created_tmp_disk_tables和Created_tmp_tables这两个值来判断临时表的创建位置
mysql> show variables like 'open_files%'; //打开文件描述符最大数,open_files_limit受OS关于该项的限制
mysql> show global status like '%open%file%'; //两个状态变量记录了当前和历史的文件打开信息
#查看表的修改时间
mysql>SELECT update_time FROM information_schema.tables WHERE table_schema = 'database_name' AND table_name = 'table_name';
mysql> desc information_schema.tables;
+-----------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------+---------------------+------+-----+---------+-------+
| TABLE_CATALOG | varchar(512) | NO | | | |
| TABLE_SCHEMA | varchar(64) | NO | | | |
| TABLE_NAME | varchar(64) | NO | | | |
| TABLE_TYPE | varchar(64) | NO | | | |
| ENGINE | varchar(64) | YES | | NULL | |
| VERSION | bigint(21) unsigned | YES | | NULL | |
| ROW_FORMAT | varchar(10) | YES | | NULL | |
| TABLE_ROWS | bigint(21) unsigned | YES | | NULL | |
| AVG_ROW_LENGTH | bigint(21) unsigned | YES | | NULL | |
| DATA_LENGTH | bigint(21) unsigned | YES | | NULL | |
| MAX_DATA_LENGTH | bigint(21) unsigned | YES | | NULL | |
| INDEX_LENGTH | bigint(21) unsigned | YES | | NULL | |
| DATA_FREE | bigint(21) unsigned | YES | | NULL | |
| AUTO_INCREMENT | bigint(21) unsigned | YES | | NULL | |
| CREATE_TIME | datetime | YES | | NULL | |
| UPDATE_TIME | datetime | YES | | NULL | |
| CHECK_TIME | datetime | YES | | NULL | |
| TABLE_COLLATION | varchar(32) | YES | | NULL | |
| CHECKSUM | bigint(21) unsigned | YES | | NULL | |
| CREATE_OPTIONS | varchar(255) | YES | | NULL | |
| TABLE_COMMENT | varchar(2048) | NO | | | |
+-----------------+---------------------+------+-----+---------+-------+
21 rows in set (0.00 sec)
2.8、数据量统计
Mysql多使用InnoDB存储引擎,它的最小储存单元是页,一页大小就是16k。B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据;
假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16。非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(int是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是8+6=14字节,16k/14B =16*1024B/14B = 1170因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400,即可以存放两千万左右的记录。B+树高度一般为1-3层,就可满足千万级别的数据存储。如果B+树想存储更多的数据,那树结构层级就会更高,查询一条数据时,消耗的磁盘IO也就大幅增加,查询性能就会变慢。当然我们可以分库分表,比如分表后单表数据量降低,树的高度变低,查询经历的磁盘io变少,从而提高效率;或者分区将数据分布存到多个数据文件上,提高查询的并行和减少数据查询的遍历数量;
#统计各数据库的数据量大小:bytes
mysql -uroot -p -e "SELECT table_schema AS 'Database', SUM(data_length + index_length)/1024/1024 AS 'Total Size (MB)' FROM information_schema.tables GROUP BY table_schema ORDER BY 'Total Size (MB)' DESC;"
#或登录后执行:其中,information_schema.tables的data_length、index_length默认单位为bytes,更多参看:https://dev.mysql.com/doc/refman/5.7/en/information-schema-tables-table.html
SELECT table_schema AS 'Database', SUM(data_length + index_length)/1024/1024 AS 'Total Size (MB)' FROM information_schema.tables GROUP BY table_schema ORDER BY 'Total Size (MB)' DESC;
#多表联合查看系统表统计索引大小,其中IF函数判断是否表压缩,round函数用于计算结果四舍五入到整数
mysql> SELECT a.NAME, a.FILE_FORMAT, a.ROW_FORMAT,
@page_size :=
IF(a.ROW_FORMAT='Compressed',
b.ZIP_PAGE_SIZE, b.PAGE_SIZE)
AS page_size,
ROUND((@page_size * c.CLUST_INDEX_SIZE)
/(1024*1024)) AS pk_mb,
ROUND((@page_size * c.OTHER_INDEX_SIZE)
/(1024*1024)) AS secidx_mb
FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES a
INNER JOIN INFORMATION_SCHEMA.INNODB_SYS_TABLESPACES b on a.NAME = b.NAME
INNER JOIN INFORMATION_SCHEMA.INNODB_SYS_TABLESTATS c on b.NAME = c.NAME
WHERE a.NAME LIKE '你的表名%'
ORDER BY a.NAME DESC;
#查看所有数据库容量大小
mysql> select table_schema as '数据库',
sum(table_rows) as '记录数',
sum(truncate(data_length/1024/1024, 2)) as '数据容量(MB)',
sum(truncate(index_length/1024/1024, 2)) as '索引容量(MB)'
from information_schema.tables
group by table_schema
order by sum(data_length) desc, sum(index_length) desc;
#查看所有表容量大小,其中TRUNCATE() 函数,用于截断(或截短)数字的小数部分,保留指定位数的小数位,下面为保留两位小数
mysql> select table_schema as '数据库',
table_name as '表名',
table_rows as '记录数',
truncate(data_length/1024/1024, 2) as '数据容量(MB)',
truncate(index_length/1024/1024, 2) as '索引容量(MB)'
from information_schema.tables
order by data_length desc, index_length desc;
#查看单个数据库的大小
mysql -uroot -ppassword -e "SELECT table_name AS 'Table', sum(data_length + index_length)/1024 AS 'Size (MB)' FROM information_schema.tables WHERE table_schema = 'database_name' ORDER BY 'Size (MB)' DESC;"
#查看单个表的详细大小信息
mysql -uroot -ppassword -e "SELECT table_schema, table_name, round((sum(data_length + index_length) /1024/1024), 2) AS 'Size (MB)' FROM information_schema.tables WHERE table_name = 'table_name';"
#查询当天的数据记录
mysql> SELECT * FROM 表名 WHERE TO_DAYS(日期列) = TO_DAYS(NOW());
mysql> SELECT * FROM 表名 WHERE DATE(日期列) = CURDATE();
#统计一定范围内,每个单位时间内的数据数量【单位可以天,月、周、年、等】
- #按天统计:
SELECT DATE_FORMAT( 日期列, '%Y-%m-%d' ) days, count(*) FROM 表名 GROUP BY days;
- #按周统计:
SELECT DATE_FORMAT( 日期列, '%Y-%u' ) weeks, count(*) FROM 表名GROUP BY weeks;
- #按月统计:
SELECT DATE_FORMAT( 日期列, '%Y-%m' ) months, count(*) FROM 表名 GROUP BY months;
#统计最近七天内的数据并按天分组:
mysql> SELECT DATE_FORMAT( 日期列, '%Y-%m-%d' ) dates,count(*) FROM ( SELECT * FROM 表名 WHERE DATE_SUB( CURDATE(), INTERVAL 7 DAY )<= date( 日期列 ) ) AS v GROUP BY dates;
#查询1分钟内的数据
mysql> SELECT * FROM 表名 WHERE 日期列 >= CURRENT_TIMESTAMP - INTERVAL 1 MINUTE;
#查询一个数据库中每个表的总行数,数据大小,索引大小和总大小,CONCAT_WS字符串函数,用于连接多个字符串,并在它们之间插入一个指定的分隔符,语法:CONCAT_WS(separator, str1, str2, ...);
SELECT concat_ws('.',a.table_schema ,a.table_name),CONCAT(a.table_schema,'.',a.table_name),
CONCAT(ROUND(table_rows/1000,4),'KB') AS 'Number of Rows',
CONCAT(ROUND(data_length/(1024*1024),4),',') AS 'data_size',
CONCAT(ROUND(index_length/(1024*1024),4),'M') AS 'index_size', CONCAT(ROUND((data_length+index_length)/(1024*1024),4),'M') AS'Total'
FROM information_schema. TABLES a WHERE a.table_schema = '要查询的库名' ORDER BY 'Total' DESC;
#查看特定数据库特定表的数据部分大小,索引部分大小和总占用磁盘大小,加LIMIT 1,30查看指定行的数据
SELECT
a.table_schema ,
a.table_name ,
concat(round(sum(DATA_LENGTH / 1024 / 1024) + sum(INDEX_LENGTH / 1024 / 1024) ,2) ,'MB') total_size ,
concat(round(sum(DATA_LENGTH / 1024 / 1024) , 2) ,'MB') AS data_size ,
concat(round(sum(INDEX_LENGTH / 1024 / 1024) , 2) ,'MB') AS index_size
FROM
information_schema. TABLES a
WHERE
a.table_schema = 'db_name'
AND a.table_name = 'table_name';
# 查询每日数据增量,用CURDATE() 获取当前日期,通过 DATE(date_column) = CURDATE() - INTERVAL 1 DAY 条件筛选前一天的数据;使用COUNT(*) - (SELECT COUNT(*)) 计算每日数据增量,sql如下(执行报错,待进一步优化):
SELECT
table_name,
CURDATE() AS today,
COUNT(*) AS today_count,
(
SELECT COUNT(*)
FROM table_name
WHERE DATE(date_column) = CURDATE() - INTERVAL 1 DAY
) AS yesterday_count,
COUNT(*) - (
SELECT COUNT(*)
FROM table_name
WHERE DATE(date_column) = CURDATE() - INTERVAL 1 DAY
) AS daily_increment
FROM information_schema.tables T
WHERE table_schema = 'your_database_name'
AND table_type = 'BASE TABLE';
#存储过程
DELIMITER //
CREATE PROCEDURE CalculateDailyIncrement()
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE tableName VARCHAR(255);
DECLARE curTables CURSOR FOR
SELECT table_name
FROM information_schema.tables
WHERE table_type = 'BASE TABLE';
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = 1;
OPEN curTables;
readTables: LOOP
FETCH curTables INTO tableName;
IF done THEN
LEAVE readTables;
END IF;
SET @query = CONCAT('
SELECT
"', tableName, '" AS table_name,
CURDATE() AS today,
COUNT(*) AS today_count,
(
SELECT COUNT(*)
FROM ', tableName, '
WHERE DATE(date_column) = CURDATE() - INTERVAL 1 DAY
) AS yesterday_count,
COUNT(*) - (
SELECT COUNT(*)
FROM ', tableName, '
WHERE DATE(date_column) = CURDATE() - INTERVAL 1 DAY
) AS daily_increment
FROM ', tableName, '
WHERE DATE(date_column) = CURDATE();
');
PREPARE stmt FROM @query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END LOOP;
CLOSE curTables;
END //
DELIMITER ;
#调用
CALL CalculateDailyIncrement();
三、数据库优化
MySQL数据库是常见的两个瓶颈是CPU和I/O的瓶颈,CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据时候。磁盘I/O瓶颈发生在装入数据远大于内存容量的时候,如果应用分布在网络上,那么查询量相当大的时候那么平瓶颈就会出现在网络上,我们可以用mpstat, iostat, sar和vmstat来查看系统的性能状态;使用索引,使用EXPLAIN分析查询以及调整MySQL的内部配置;常见的分析手段有慢查询日志,EXPLAIN 分析查询,profiling分析以及show命令查询系统状态及系统变量,通过定位分析性能的瓶颈,以更好的优化数据库系统的性能。大体我们可从以下几方面进行优化考虑:1.MySQL集群架构;2. 性能问题排查;3. 优化方法;4. 其他;
1)慢查询优化
[mysqld]
slow_query_log = on
slow-query-log-file=/var/log/mysql/slowquery.log
long_query_time=2 #查询超过两秒才记录
log-queries-not-using-indexes #表示记录下没有使用索引的查询
----
mysql> show variables like "slow%";
#查询long_query_time 的值
mysql> show variables like "long%";
#修改慢查询时间为5秒
mysql> set long_query_time = 5;
因mysql-slow.log慢查询日志里记录了所有慢查询的sql语句,more mysql-slow.log来管哈哪些语句执行有问题,找出影响最大的,跟研发侧评估论证确定优化方案。也可以使用mysqldumpslow工具(MySQL客户端安装自带)来对慢查询日志进行分类汇总。它会对慢查询日志文件进行了分类汇总,显示汇总后摘要结果,可以非常明确的得到各种我们需要的查询语句。执行:
mysqldumpslow mysql-slow.log
#输出记录次数最多的10条SQL语句
mysqldumpslow -s c -t 10 /var/log/mysql/mysql-slow.log
#返回记录集最多的10个查询
mysqldumpslow -s r -t 10 /var/log/mysql/mysql-slow.log
#按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/log/mysql/mysql-slow.log
参数说明:
-s, 是表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒叙;
-t, 是top n的意思,即为返回前面多少条的数据;
-g, 后边可以写一个正则匹配模式,大小写不敏感的;
第2种就是explain分析查询:通过它优化器可模拟执行SQL查询语句,从而知道MySQL是如何处理哪些SQL语句的,从而分析那些查询语句或是表结构的性能瓶颈。通过explain命令可以得到:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
第3种就是profiling分析查询:
通过慢日志查询可以知道哪些SQL语句执行效率低下,通过explain我们可以得知SQL语句的具体执行情况,索引使用等,还可以结合show命令查看执行状态。而通过profiling命令得到更准确的SQL执行消耗系统资源的信息,通过profiling资源耗费信息,我们可以采取针对性的优化措施;profiling默认是关闭的。
mysql> select @@profiling;
#开启
mysql> set profiling=1;
mysql> show profiles\G; #可以得到被执行的SQL语句的时间和ID
mysql> show profile for query 1; #得到对应SQL语句执行的详细信息
mysql> set profiling=0
2)索引
1、索引的类型
Ø 普通索引:这是最基本的索引类型,没唯一性之类的限制。
Ø 唯一性索引:和普通索引基本相同,但所有的索引列值保持唯一性。
Ø 主键:主键是一种唯一索引,但必须指定为”PRIMARY KEY”。
Ø 全文索引:MYSQL从3.23.23开始支持全文索引和全文检索。在MYSQL中,全文索引的索引类型为FULLTEXT。全文索引可以在VARCHAR或者TEXT类型的列上创建。
Ø 其他索引:大多数MySQL索引(PRIMARY KEY、UNIQUE、INDEX和FULLTEXT)使用B树中存储。空间列类型的索引使用R-树,MEMORY表支持hash索引。
Ø 单列索引和多列索引(复合索引):
索引可以是单列索引,也可以是多列索引。对相关的列使用索引是提高SELECT操作性能的最佳途径之一。
多列索引:
MySQL可以为多个列创建索引。一个索引可以包括15个列。对于某些列类型,可以索引列的左前缀,列的顺序非常重要。
多列索引可以视为包含通过连接索引列的值而创建的值的排序的数组。一般来说,即使是限制最严格的单列索引,它的限制能力也远远低于多列索引。
多列索引有一个特点,即最左前缀(Leftmost Prefixing)。假如有一个多列索引key(firstname lastname age),当搜索条件是以下各种列的组合和顺序时,MySQL将使用该多列索引,也就是说,相当于还建立了key(firstname lastname)和key(firstname)。:
firstname,lastname,age
firstname,lastname
firstname
2、索引的使用
Ø 快速找出匹配一个WHERE子句的行。
Ø 删除行。当执行联接时,从其它表检索行。
Ø 对具体有索引的列key_col找出MAX()或MIN()值。由预处理器进行优化,检查是否对索引中在key_col之前发生所有关键字元素使用了WHERE key_part_# = constant。在这种情况下,MySQL为每个MIN()或MAX()表达式执行一次关键字查找,并用常数替换它。如果所有表达式替换为常量,查询立即返回。例如:SELECT MIN(key2), MAX (key2) FROM tb WHERE key1=10;
Ø 如果对一个可用关键字的最左面的前缀进行了排序或分组(例如,ORDER BY key_part_1,key_part_2),排序或分组一个表。如果所有关键字元素后面有DESC,关键字以倒序被读取。
Ø 在一些情况中,可以对一个查询进行优化以便不用查询数据行即可以检索值。如果查询只使用来自某个表的数字型并且构成某些关键字的最左侧前缀的列,为了更快,可以从索引树检索出值。
SELECT key_part3 FROM tb WHERE key_part1=1
合理的建立索引的建议:
(1) 越小的数据类型通常更好:越小的数据类型通常在磁盘、内存和CPU缓存中都需要更少的空间,处理起来更快。
(2) 简单的数据类型更好:整型数据比起字符,处理开销更小,因为字符串的比较更复杂。在MySQL中,应该用内置的日期和时间数据类型,而不是用字符串来存储时间;以及用整型数据类型存储IP地址。
(3) 尽量避免NULL:应该指定列为NOT NULL,除非你想存储NULL。在MySQL中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
SQL语句注意事项:
1、当结果集只有一行数据时使用 Limit 1
2、避免SELECT *,始终指定你需要的列
从表中读取越多的数据,查询会变得更慢。这增加了磁盘需要操作的时间,还是在数据库服务器与WEB服务器是独立分开的情况下。你将会经历非常漫长的网络延迟,仅仅是因为数据不必要的在服务器之间传输。
3、使用连接(JOIN)来代替子查询(Sub-Queries)
连接(JOIN)之所以更有效率一些,是因为MySQL不需要在内存中创建临时表来完成这个逻辑上的需要两个步骤的查询工作。
4、使用ENUM、CHAR 而不是VARCHAR,使用合理的字段属性长度
5、尽可能的使用NOT NULL
6、 固定长度的表会更快
7、 拆分大的DELETE 或INSERT 语句
8、查询的列越小越快
9、尽量少且合理使用where条件,在多个条件的时候,把会提取尽量少数据量的条件放在前面,减少后一个where条件的查询时间。有些where条件会导致索引无效:
Ø where子句的查询条件里有!=,MySQL将无法使用索引。
Ø where子句使用了Mysql函数的时候,索引将无效,比如:select * from tb where left(name, 4) = ‘xxx’
Ø 使用LIKE进行搜索匹配的时候,这样索引是有效的:select * from tbl1 where name like ‘xxx%’,而like ‘%xxx%’ 时索引无效
3)Mysql配置优化
这里主要关注对性能优化影响较大的变量,简单分为连接请求的变量和缓冲区变量。
● 最大连接数:max_connections
MySQL的最大连接数,增加该值就是增加mysqld 能打开的文件描述符的数量。如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,但是连接数越多同时也会加大主机负载,数值过小又会经常出现ERROR 1040: Too many connections错误,可以过**’conn%’通配符查看当前状态的连接数量**,以核定该值的大小。MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,尽量取一个平衡。
mysql> show variables like ‘max_connections’ #最大连接数
mysql> show status like ‘max_used_connections’#响应的连接数
参考标准: max_used_connections / max_connections * 100% (理想值≈ 85%) ;如果max_used_connections跟max_connections相同 那么就是max_connections设置过低或者超过服务器负载上限了,低于10%则设置过大。
● MySQL能暂存的连接数量: back_log
- 如果MySQL的连接数据达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,被拒绝连接。
- back_log的值指出在MySQL暂时停止回答新请求之前的短时间内有多少个请求可以被存在堆栈中。只有当现场实际确实存在一个短时间内有很多连接的情况,简单理解,这值可表到来的TCP/IP连接的侦听队列的大小。当观察mysql进程列表(mysql> show full processlist),发现大量264084 | unauthenticated user | xxx.xxx.xxx.xxx | NULL | Connect | NULL | login | NULL 的待连接进程时,就要加大back_log 的值了。
参考标准: 默认数值是50,可调优为128,对于Linux系统设置范围为小于512的整数。
● 交互连接超时时间:interactive_timeout
该值表一个交互连接在被服务器在关闭前等待行动的秒数。一个交互的客户被定义为对mysql_real_connect()使用CLIENT_INTERACTIVE 选项的客户。
参考标准: 默认数值是28800,可调优为7200。
● 索引缓冲区 :key_buffer_size —>只对MyISAM表起作用
key_buffer_size可指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度,增加它可得到更好处理的索引(对所有读和多重写),对MyISAM表性能影响最大的一个参数。如果太大,系统将开始换页并且真的变慢了。严格说是它决定了数据库索引处理的速度,尤其是索引读的速度。通过检查状态值Key_read_requests和Key_reads,可以知道key_buffer_size设置是否合理。比例key_reads / key_read_requests应该尽可能的低,至少是1:100,1:1000更好(上述状态值可以使用SHOW STATUS LIKE ‘key_read%’获得)。对于内存在4GB左右的服务器该参数可设置为256M或384M。
其中,key_buffer_size只对MyISAM表起作用。即使你不使用MyISAM表,但是内部的临时磁盘表是MyISAM表,也要使用该值。可以使用检查状态值created_tmp_disk_tables得知详情。通过检查状态值Key_read_requests和Key_reads,利用公式计算得到该值表现情况,key_reads / key_read_requests应该尽可能的低,比如1:100,1:1000 ,1:10000。
mysql> show variables like ‘key_buffer_size‘;
mysql> show global status like ‘key_read%‘; #其中,Key_reads表多少个请求在内存中没有找到,直接从硬盘读取索引
计算索引未命中缓存的概率:
key_cache_miss_rate =Key_reads / Key_read_requests * 100%参考标准: 默认配置数值是8388600(8M),建议设置在1/1000左右较好,主机有4GB内存,可以调优值为268435456(256MB)。
● 查询缓冲:query_cache_size
主要用来缓存MySQL中的ResultSet,也就是一条SQL语句执行的结果集。因MySQL会将查询结果存放在缓冲区中,之后对于同样的SELECT语句(区分大小写),就可直接从缓冲区中读取结果。Query Cache也有一个致命的缺陷,那就是当某个表的数据有任何任何变化,都会导致所有引用了该表的select语句在Query Cache中的缓存数据失效。所以,当我们的数据变化非常频繁的情况下,使用Query Cache可能会得不偿失;Query Cache的使用需要多个参数配合,其中最为关键的是query_cache_size和query_cache_type,前者设置用于缓存 ResultSet的内存大小,后者设置在何场景下使用Query Cache
通过检查状态值Qcache_*,可以知道query_cache_size设置是否合理(上述状态值可以使用SHOW STATUS LIKE ‘Qcache%’ 获得)。如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,如果Qcache_hits的值也非常大,则表明查询缓冲使用非常频繁,此时需要增加缓冲大小;如果Qcache_hits的值不大,则表明你的查询重复率很低,这种情况下使用查询缓冲反而会影响效率,那么可以考虑不用查询缓冲。此外,在SELECT语句中加入SQL_NO_CACHE可以明确表示不使用查询缓冲。另外与查询缓冲有关的参数还有query_cache_type、query_cache_limit、query_cache_min_res_unit。
query_cache_type指定是否使用查询缓冲,可以设置为0、1、2,该变量是SESSION级的变量。
query_cache_limit指定单个查询能够使用的缓冲区大小,缺省为1M。
query_cache_min_res_unit是在4.1版本以后引入的,它指定分配缓冲区空间的最小单位,缺省为4K。检查状态值Qcache_free_blocks,如果该值非常大,则表明缓冲区中碎片很多,这就表明查询结果都比较小,此时需要减小query_cache_min_res_unit。
mysql> show global status like ‘qcache%‘;
mysql> show status like 'Qcache_%'; //查看目前系统Query catch使用大小
mysql> show variables like ‘query_cache%‘;
- 查询缓存碎片率= Qcache_free_blocks / Qcache_total_blocks * 100%;
- 查询缓存利用率= (query_cache_size – Qcache_free_memory) / query_cache_size * 100%
- 查询缓存命中率= (Qcache_hits – Qcache_inserts) / Qcache_hits * 100%
参考标准: 如果查询缓存碎片率超过20%,可以用FLUSH QUERY CACHE整理缓存碎片,或者试试减小query_cache_min_res_unit,如果你的查询都是小数据量的话。
查询缓存利用率在25%以下的话说明query_cache_size设置的过大,可适当减小;查询缓存利用率在80%以上而且Qcache_lowmem_prunes > 50的话说明query_cache_size可能有点小,要不就是碎片太多。
● 单进程缓冲区:record_buffer_size
每个进行一顺序扫描的线程都会为其扫描的每张表分配该值指定大小的一个缓冲区。如果存在很多顺序扫描,可能需要增加该值。
参考标准: 默认数值是131072(128K),可改为16773120 (16M)
● 随机读缓冲区:read_rnd_buffer_size
MySql的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大。
参考标准: 一般可设置为16M
● 排序线程缓冲区:sort_buffer_size
是MySql执行排序使用的缓冲大小;每个需要进行排序的线程分配该大小的一个缓冲区。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。如果不能,可以尝试增加sort_buffer_size变量的大小增加这值加速ORDER BY或GROUP BY操作。
参考标准: 默认数值是2097144(2M),可改为16777208 (16M)。
● 联合查询缓冲区:join_buffer_size
联合查询操作所能使用的缓冲区大小
record_buffer_size,read_rnd_buffer_size,sort_buffer_size,join_buffer_size为每个线程独占,也就是说,如果有100个线程连接,则占用为16M*100
● 表高速缓存: table_cache
每当MySQL访问一个表时,如果在表缓冲区中还有空间,该表就被打开并放入其中,这样可以更快地访问表内容。通过检查峰值时间的状态值Open_tables和Opened_tables,可以决定是否需要增加table_cache的值。如果你发现open_tables等于table_cache,并且opened_tables在不断增长,那么你就需要增加table_cache的值了(上述状态值可以使用SHOW STATUS LIKE ‘Open%tables’获得)。注意,不能盲目地把table_cache设置成很大的值。如果设置得太高,可能会造成文件描述符不足,从而造成性能不稳定或者连接失败。
参考标准: 1G内存机器,推荐值是128-256。内存在4GB左右的服务器该参数可设置为256M或384M。
● 用户最大内存表: max_heap_table_size
该值表用户可以创建的内存表(memory table)的大小。这个值用来计算内存表的最大行数值。这个变量支持动态改变,即set @max_heap_table_size=#;这个变量和tmp_table_size一起限制了内部内存表的大小。如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。
● 临时表大小:tmp_table_size
它是MySql的heap (堆积)表缓冲大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表即可以完成。大多数临时表是基于内存的(HEAP)表。如果调高该值,MySQL同时将增加heap表的大小,可达到提高联接查询速度的效果,建议尽量优化查询,要确保查询过程中生成的临时表在内存中,避免临时表过大导致生成基于硬盘的MyISAM表。如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置tmp_table_size选项来增加临时表的大小。也就是说,如果调高该值,MySql同时将增加heap表的大小,可达到提高联接查询速度的效果。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。通过设置tmp_table_size选项来增加一张临时表的大小,例如:做高级GROUP BY操作生成的临时表。
mysql> show global status like ‘created_tmp%‘;
参考标准: 每次创建临时表,Created_tmp_tables增加,如果临时表大小超过tmp_table_size,则是在磁盘上创建临时表,Created_tmp_disk_tables也增加,Created_tmp_files表示MySQL服务创建的临时文件文件数,比较理想的配置是:
Created_tmp_disk_tables / Created_tmp_tables * 100% <= 25%
Created_tmp_disk_tables / Created_tmp_tables * 100% =1.20%默认为16M,可调到64-256最佳,线程独占,太大可能内存不够I/O堵塞
● 线程复用缓冲区: thread_cache_size
可以复用的保存在缓存中的线程的数量。如果有,新的线程从缓存中取得,当断开连接的时候如果有空间,客户的线置在缓存中。如果有很多新的线程,为了提高性能可以这个变量值。通过比较 Connections和Threads_created状态的变量,可以看到这个变量的作用。
mysql> show status like ‘thread%’;
连接线程池的命中率:
(Connections - Threads_created) / Connections * 100 % #命中率超过90%以上,设定合理
参考标准: 默认值为110,可调优为80。 根据物理内存设置规则如下:1G —> 8,2G —> 16,3G —> 32 ,3G —> 64
● thread_concurrency
参考标准: 推荐设置为服务器 CPU核数的2倍,例如双核的CPU, 那么thread_concurrency的应该为4;2个双核的cpu, thread_concurrency的值应为8。默认为8
● wait_timeout
指定一个请求的最大连接时间,对于4GB左右内存的服务器可以设置为5-10。
● innodb_buffer_pool_size
对于InnoDB表来说,innodb_buffer_pool_size的作用就相当于key_buffer_size对于MyISAM表的作用一样,对InnoDB表性能影响最大的一个参数。InnoDB使用该参数指定大小的内存来缓冲数据和索引。对于单独的MySQL数据库服务器,最大可以把该值设置成物理内存的80%。不同的是,MyISAM 的 key_buffer_size 只能缓存索引键,而 innodb_buffer_pool_size 却可以缓存数据块和索引键。适当的增加这个参数的大小,可以有效的减少 InnoDB 类型的表的磁盘 I/O 。可以通过 :
show status like ‘Innodb_buffer_pool_read%’;
(Innodb_buffer_pool_read_requests – Innodb_buffer_pool_reads) / Innodb_buffer_pool_read_requests * 100% 计算缓存命中率,并根据命中率来调整 innodb_buffer_pool_size 参数大小进行优化,命中率越高越好。
参考标准: 根据MySQL手册,对于2G内存的机器,推荐值是1G(50%)。
● innodb_flush_log_at_trx_commit
主要控制了innodb将log buffer中的数据写入日志文件并flush磁盘的时间点,取值分别为0、1、2三个。0,表示当事务提交时,不做日志写入操作,而是每秒钟将log buffer中的数据写入日志文件并flush磁盘一次;1,则在每秒钟或是每次事物的提交都会引起日志文件写入、flush磁盘的操作,确保了事务的ACID;设置为2,每次事务提交引起写入日志文件的动作,但每秒钟完成一次flush磁盘操作。
参考标准: 实际测试发现,该值对插入数据的速度影响非常大,设置为2时插入10000条记录只需要2秒,设置为0时只需要1秒,而设置为1时则需要229秒。因此,MySQL手册也建议尽量将插入操作合并成一个事务,这样可以大幅提高速度。根据MySQL手册,在允许丢失最近部分事务的危险的前提下,可以把该值设为0或2。
● innodb_log_buffer_size
它是InnoDB存储引擎的事务日志所使用的缓冲区,表InnoDB 将日志写入日志磁盘文件前的缓冲大小。类似于Binlog Buffer,InnoDB在写事务日志的时候,为了提高性能,也是先将信息写入Innofb Log Buffer中,当满innodb_flush_log_trx_commit参数所设置的相应条件(或者日志缓冲区写满)之后,才会将日志写到文件 (或者同步到磁盘)中。可以通过innodb_log_buffer_size 参数设置其可以使用的最大内存空间。大的日志缓冲允许事务运行时不需要将日志保存入磁盘而只到事务被提交(commit)时才进行。因此,如果有大的事务处理,设置大的日志缓冲可以减少磁盘I/O。 在 my.cnf中以数字格式设置。
参考标准: 一般为1-8M,默认为1M,对于较大的事务,默认是8MB,可以增大缓存大小, 可设置为4M或8M。这个参数实际上还和另外的flush参数相关。一般来说不建议超过32MB
● innodb_additional_mem_pool_size
该参数指定InnoDB用来存储数据字典和其他内部数据结构的内存池大小。缺省值是1M。通常不用太大,只要够用就行,应该与表结构的复杂度有关系。如果不够用,MySQL会在错误日志中写入一条警告信息。当MySQL Instance中的数据库对象非常多的时候,是需要适当调整该参数的大小以确保所有数据都能存放在内存中提高访问效率的。当过小的时候,MySQL会记录Warning信息到数据库的error log中,这时候就该调整这个参数大小了。当查看当前系统mysql的error日志 发现有很多waring警告时,就应该调整该值了
参考标准: 根据MySQL手册,对于2G内存的机器,推荐值是20M,32G内存的 100M。可适当增加。
● innodb_thread_concurrency=8
参考标准: 推荐设置为 2*(NumCPUs+NumDisks),默认一般为8;
● read_buffer_size
用来表MySql读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySql会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能.
3)参数优化
1、max_connect_errors
- 它是一个MySQL中与安全有关的计数器值,它负责阻止过多尝试失败的客户端以防止暴力破解密码的情况。max_connect_errors的值与性能并无太大关系。默认需要手动配置该参数,格式如:max_connect_errors = 10,设置此值,可防止穷举密码的攻击手段,执行 FLUSH HOSTS;后针对某一客户端的max_connect_errors会清零;该值表示每个主机的连接请求异常中断的最大次数,当超过该次数,MYSQL服务器将禁止host的连接请求,直到mysql服务器重启或通过flush hosts命令清空此host的相关信息。
- max_connect_errors参数表示如果MySQL服务器连续接收到了来自于同一个主机的请求,且这些连续的请求全部都没有成功的建立连接就被断开了,当这些连续的请求的累计值>max_connect_errors的设定值时,MySQL服务器就会阻止这台主机后续的所有请求。相关的登录错误信息会记录到performance_schema.host_cache表中。遇到这种情况,可以清空host cache来解决,具体的清空方法是执行flush hosts或者在MySQL服务器的shell里执行mysqladmin flush-hosts操作,其实就是清空performance_schema.host_cache表中的记录。参数max_connect_errors从MySQL 5.6.6开始默认值为100,小于该版本时默认值为10。当这一客户端成功连接一次MySQL服务器后,针对此客户端的max_connect_errors会清零。
- 如果max_connect_errors的设置过小,则可能提示无法连接数据库服务器;而通过SSH的mysql命令连接数据库,则会返回:
- ERROR 1129 (00000): Host is blocked because of many connection errors; unblock with ‘mysqladmin flush-hosts’错误。
2、max_connections:
- 即最大连接数,默认为 151 ,可动态修改。 全局变量, 对所有用户生效。实际上允许 max_connections + 1 个客户端连接,额外一个连接供具有 SUPER 特权的用户使用;对应配置单个数据库用户允许的最大同时连接数使用max_user_connections参数,默认为 0 ,即表示无限制,可动态修改。
- set @@global.max_user_connections=2; #针对所有用户有效
- grant usage on . to keyman@% with max_user_connections 2; #针对单个用户有效
3、connect_timeout
- 表等待一个连接响应的时间,默认为 10s ,在获取连接阶段起作用,可动态修改。
- 超过该值会报:Lost connection to MySQL server at ‘XXX’ 错误,这时可要考虑增大 connect_timeout 值,默认值 10s 对于网络良好的情况下是够用的,如果客户端和服务端网络有延迟的情况,可以将 connect_timeout 参数调大来避免发生连接超时的错误。
4、back_log:
- 用于表示暂存的连接数量,如果MySQL的连接数据达到max_connections 时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即 back_log,如果等待连接的数量超过back_log,将不被授予连接资源;即表明暂时停止回应新请求之前的短时间内多少个请求可以被存在堆栈中;back_log值不能超过TCP/IP连接的侦听队列的大小。若超过则无效,查看当前系统的TCP/IP连接的侦听队列的大小命令:cat /proc/sys/net/ipv4/tcp_max_syn_backlog。
- show variables like ‘back_log’; //查看当前数量
- select * from performance_schema.global_status where variable_name like ‘%thread%’;
- select * from performance_schema.global_status where variable_name=‘Connections’ 服务启动以来,总共连接次数
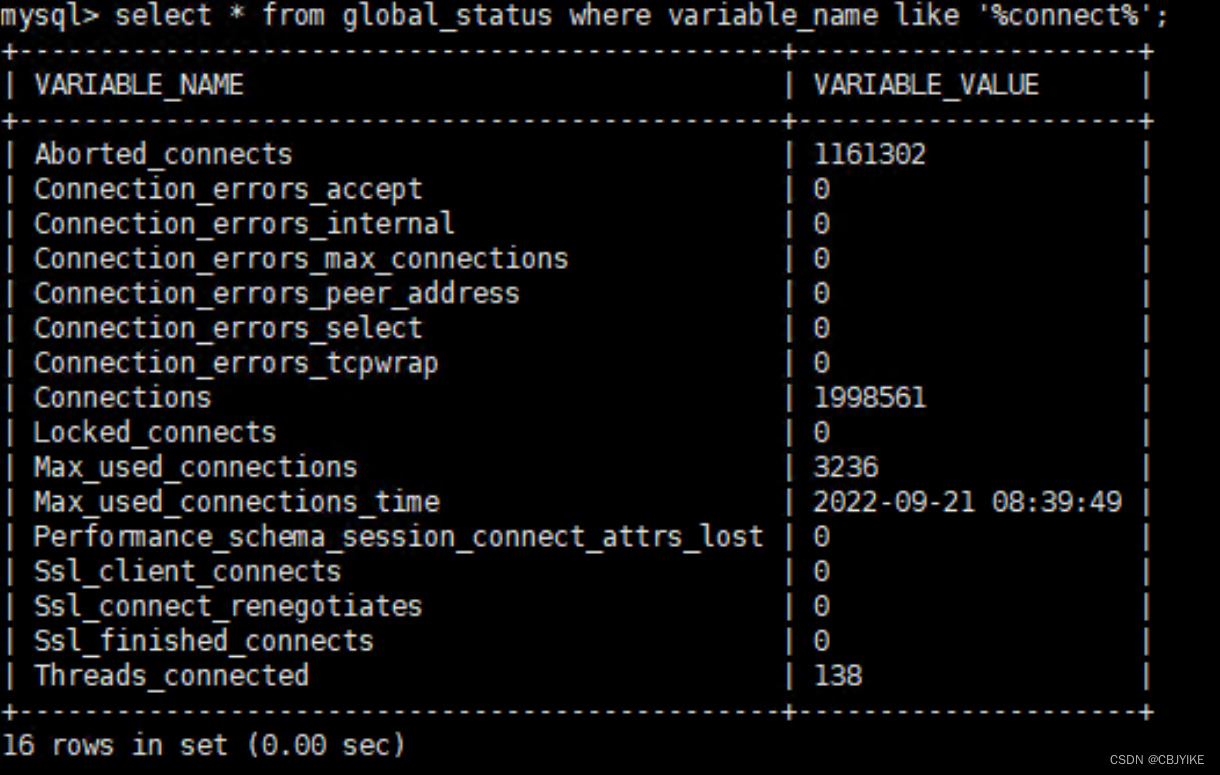
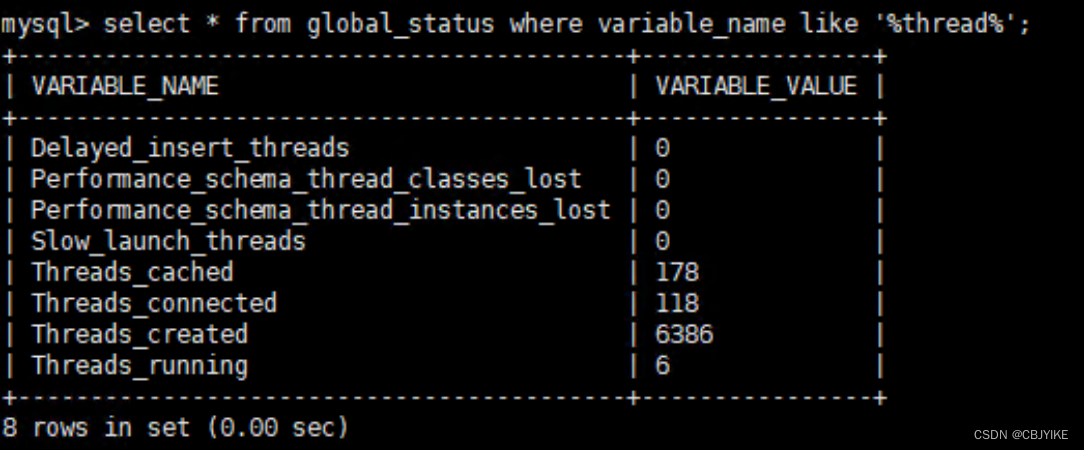
其中:
- Max_used_connections : 服务启动到现在,同一时刻并行连接数的最大值;注意的是,Max_used_connections是指从这次MySQL服务启动到现在,同一时刻并行连接数的最大值。它不是指当前的连接情况,而是一个比较值。如果在过去某一个时刻,MySQL服务同时有1000个请求连接过来,而之后再也没有出现这么大的并发请求时,那么Max_used_connections=1000。
- Max_used_connections_time 服务启动到现在, Max_used_connections达到当前值的时间
- thread_cache_size 线程缓存
- threads_connected 与 show processlist一致
注意:注意的,变量值(show variables)是以小写字母开头的,而状态值(show status)是以大写字母开头。
5、wait_timeout(单位为秒)
指明MySQL客户端的数据库连接闲置最大时间值。当MySQL连接闲置超过一定时间后将会被强行关闭。MySQL默认的wait-timeout 值为8个小时,可以通过命令show variables like 'wait_timeout’查看结果值。
6、thread_concurrency
- 用于向操作系统建议期望的并发线程数;thread_concurrency的值的正确与否, 对mysql的性能影响很大。在多个cpu(或多核)的情况下,错误设置了thread_concurrency的值, 会导致mysql不能充分利用多cpu(或多核), 出现同一时刻只能一个cpu(或核)在工作的情况。thread_concurrency应设为CPU核数的2倍. 比如有一个双核的CPU, 那thread_concurrency 的应该为4; 2个双核的cpu, thread_concurrency的值应为8.
- 查看系统当前thread_concurrency默认配置命令:
- show variables like ‘thread_concurrency’;
7、连接线程参数
mysql> show variables like 'thread%';
+--------------------+---------------------------+
| Variable_name | Value |
+--------------------+---------------------------+
| thread_cache_size | 9 |
| thread_concurrency | 10 |
| thread_handling | one-thread-per-connection |
| thread_stack | 262144 |
+--------------------+---------------------------+
//查看线程状态信息
mysql> show status like 'Thread%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 1 | //当前线程池的线程数
| Threads_connected | 1 | //当前的连接数
| Threads_created | 2 | //当前连接线程创建数, 如果这个值过高,可以调整threadcachesize 也就是调整线程缓存池的大小
| Threads_running | 1 | //当前活跃的线程数
+-------------------+-------+
mysql> show variables like 'slow_launch_time';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| slow_launch_time | 2 | //创建线程的时间过长,超过slow_launch_time的设定值,则会记录
+------------------+-------+
其中:
- thread_cache_size 设置连接线程缓存的数目。这个缓存相当于MySQL线程的缓存池(thread cache pool),将空闲的连接线程放入连接池中缓存起来,而非立即销毁。当有新的连接请求时,如果连接池中有空闲的连接,则直接使用。否则要重新创建线程。创建线程是一个不小的系统开销。MySQL的这部分线程处理和Nginx 的线程处理有异曲同工之妙,以后介绍Nginx的线程处理时,会拿来做对比。
- thread_handling 默认值是: one-thread-per-connection 表示为每个连接提供或者创建一个线程来处理请求,直至请求完毕,连接销毁或者存入缓存池。当值是no-threads 时,表示在始终只提供一个线程来处理连接,一般是单机做测试使用的。
- thread_stack stack 是堆的意思,由PHP 进程详解这篇博客,知道进程和线程都是有唯一的ID的,进程的ID系统会维护,二线程的ID,则由具体的线程库区维护,当进程或者线程休眠的时候,进程的上下文信息要在内存中开辟出一块区域,保存进程的上下文信息,以便于迅速唤醒程序。默认为MySQL的每个线程设置的堆栈大小为:262144/1024=256k
4)缓存参数
一般包括如下方向:
- 查询缓存优化
- 结果集缓存
- 排序缓存
- join 连接缓存
- 表缓存Cache 与表结构定义缓存Cache
- 表扫描缓存buffer
- MyISAM索引缓存buffer
- 日志缓存
- 预读机制
- 延迟表与临时表
5)数据量优化
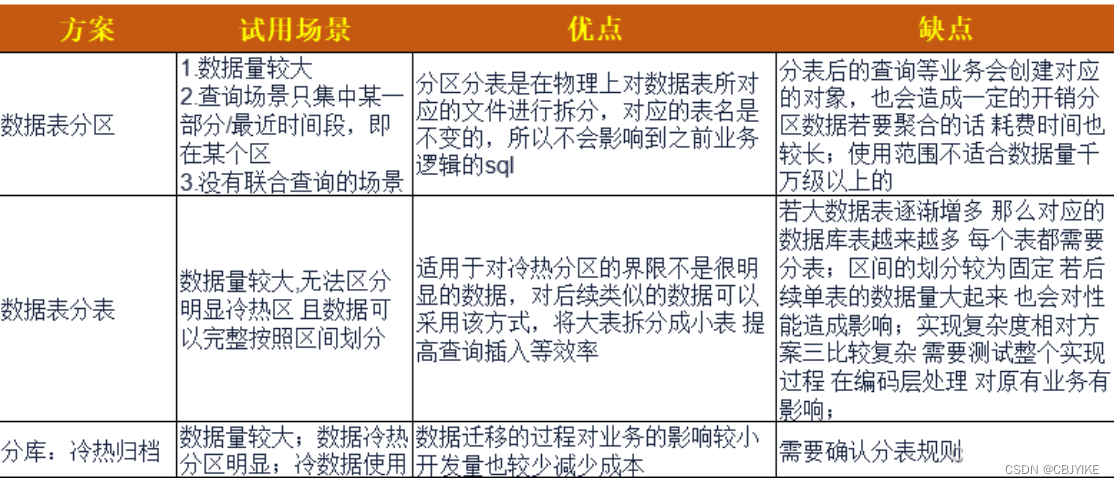
四、概念参考
1)checkpoint
checkpoint是一个内部事件,这个事件激活以后会触发数据库写进程(DBWR)将数据缓冲(DATABUFFER CACHE)中的脏数据块写出到数据文件中。它负责将缓冲池(buffer pool)中的脏页刷回磁盘。每次刷新多少页到磁盘,每次从哪里取脏页,以及什么时间触发Checkpoint。
在数据库系统中,写日志和写数据文件是数据库中IO消耗最大的两种操作,在这两种操作中写数据文件属于分散写,写日志文件是顺序写,因此为了保证数据库的性能,通常数据库都是保证在提交(commit)完成之前要先保证日志都被写入到日志文件中,而脏数据块则保存在数据缓存(buffer cache)中再不定期的分批写入到数据文件中。也就是说日志写入和提交操作是同步的,而数据写入和提交操作是不同步的。这样就存在一个问题,当一个数据库崩溃的时候并不能保证缓存里面的脏数据全部写入到数据文件中,这样在实例启动的时候就要使用日志文件进行恢复操作,将数据库恢复到崩溃之前的状态,保证数据的一致性。检查点是这个过程中的重要机制,通过它来确定,恢复时哪些重做日志应该被扫描并应用于恢复。
一般所说的checkpoint是一个数据库事件(event),checkpoint事件由checkpoint进程(LGWR/CKPT进程)发出,当checkpoint事件发生时DBWN会将脏块写入到磁盘中,同时数据文件和控制文件的文件头也会被更新以记录checkpoint信息。checkpoint的2个主要作用如下:
- 保证数据库的一致性,这是指将脏数据写入到硬盘,保证内存和硬盘上的数据是一样的;
- 缩短实例恢复的时间,实例恢复要把实例异常关闭前没有写出到硬盘的脏数据通过日志进行恢复。如果脏块过多,实例恢复的时间也会很长,检查点的发生可以减少脏块的数量,从而提高实例恢复的时间。
存在2种Checkpoint:
sharp Checkpoint(完全检查点):数据库关闭时,会将所有的脏页都刷新回磁盘,这是默认的工作方式。参数 innodb_fast_shutdown=1;
Fuzzy Checkpoint(模糊检查点):使用Fuzzy Checkpoint进行页的刷新,即只刷新一部分脏页,而不是将所有的脏页刷回磁盘。先读LRU list,把一部分脏页(相对冷的)写到磁盘上;再找Frush list,把最早脏的写到磁盘上。(更新检查点)
1、Master Thread Checkpoint
对于Master Thread 中发生的Checkpoint,差不多以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回去磁盘。这个过程是异步的,即此时InnoDB存储引擎可以进行其他的操作,用户查询线程不会阻塞。即:常规性的fuzzy checkpoint,写入操作不阻塞用户线程
FLUSH_LRU_LIST Checkpoint
FLUSH_LRU_LIST Checkpoint是因为InnoDB存储引擎需要保证LRU列表中需要有差不多100个空闲页可供使用。在innodb1.1X版本以前,需要检查LRU列表中是否有足够的可用空间操作发生在用户查询线程中,显然会阻塞用户的查询操作。若没有100个可用空闲页,那么innodb会将LRU列表末端的页移除。如果这些页中有脏页,那就要进行Checkpoint,而这些页是来自LRU列表的,因此成为FLUSH_LRU_LIST Checkpoint。即:Flush lru list checkpoint:flush list上的脏页数量超过阈值;会阻塞用户线程。
Async/Sync Flush list Checkpoint
(在数据库的报错日志里能够看到!)
Async/Sync Flush list Checkpoint指的是重做日志文件不可用的情况,这时需要强制将一些页刷新回磁盘,而此时脏页是从脏页列表中选取的。若将已经写入到redo log的LSN(Log sequence number)记作redo_lsn,将已经刷新回磁盘最新页的LSN记为checkpoint_lsn,则可定义:
redo_lsn - checkpoint_lsn == checkpoint_age
又定义:
async_water_mark75% * total_redo_log_file_size
sync_water_mark90% * total_redo_log_file_size
假设每个redo log的大小是1G,并且定义两个redo log,则redo log总共2G。
则,async_water_mark=1.5G,sync_water_mark=1.8G。则:
① checkpoint_age< async_water_mark 时,不需要刷新任何脏页到磁盘;
② async_water_mark < checkpoint_age<
sync_water_mark(即:有25%的日志能被覆盖时) 时,触发Async Flush,从Async Flush
列表中刷新足够的脏页回磁盘。最终满足①;
③ checkpoint_age > sync_water_mark
时(即有90%的日志能被覆盖时),极少发生,除非设置的redo log太小,并且在进行类似LOAD DATA的BULK
INSERT操作。此时触发Sync Flush操作,从Flush列表中刷新足够的脏页回磁盘,使得刷新后满足①。
注意:在较早版本的innodb中,Async Flush list Checkpoint会阻塞发现问题的用户查询线程,而Sync Flush list Checkpoint会阻塞所有的用户查询线程,并且等待脏页刷新完成。
但在5.6版本(即innodb1.2x版本)开始,这部分的刷新操作同样放入到了单独的Page Cleaner Thread中,所以不会再阻塞用户查询线程了。
2) MySQL的缓冲池
MySQL组织数据的最小单位是数据页,数据页在Buffer Pool中是以LRU链表的数据结构组织在一起的。MySQL的缓冲池(innodb_buffer_pool_instances,innodb_buffer_pool_size)是通过LRU(Least Recently Used)算法来进行管理的。即最频繁使用的页在LRU列表的最前端,而最少使用的页在LRU列表的尾端。当缓冲池不能存放新读取到的页时,将首先释放LRU列表尾端的页。在INNODB引擎中,缓冲池页的大小默认为16KB。在Innodb改进了LRU算法,InnoDB 管理 Buffer Pool 的 LRU 算法,是用链表来实现的。所谓的LRU链表本质上就是一个双向循环链表;它实质上将内存链表分成两段。 靠近头部的young和靠近末尾的old,取5/12段为分界。 新数据在一定时间内只能在old段的头部,当在old段保持了一定的时间后被再次访问才能升级到young。我们将从磁盘中读取的数据页称为young page,young page会被直接放在链表的头部。已经存在于LRU链表中数据页如果被使用到了,那么该数据页也被认为是young page而被移动到链表头部。这样链表尾部的数据就是最近最少使用的数据了,当Buffer Pool容量不足,或者后台线程主动刷新数据页时,就会优先刷新链表尾部的数据页。实质上是分了两段lru,这样做的好处是防止大表扫描时,内存数据被全量替换,导致内存命中率急剧下降而造成性能雪崩。比如当你执行select * from xxx;时,如果表中的数据页非常多,那这些数据页就会一一将Buffer Pool中的经常使用的缓存页挤下去,这样可能留在LRU链表中的全部是你不经常使用的数据。下图是一个 LRU 算法的基本模型。
- 在状态 1 里,链表头部是 P1,表示 P1 是最近刚刚被访问过的数据页;假设内存里只能放下这么多数据页;
- 这时候有一个读请求访问 P3,因此变成状态 2,P3 被移到最前面;
- 状态 3 中,当访问的数据页是不存在于链表中时,就需要在 Buffer Pool 中新申请一个数据页 Px,加到链表头部。但是由于内存已经满了,不能申请新的内存。于是,会清空链表末尾 Pm 这个数据页的内存,存入 Px 的内容,然后放到链表头部。也就是最久没有被访问的数据页 Pm,被淘汰了。
改进后: LRU 算法在 InnoDB 实现上,按照 5:3 的比例把整个 LRU 链表分成了 young 区域和 old 区域。下图中 LRU_old 指向的就是 old 区域的第一个位置,是整个链表的 5/8 处。也就是说,靠近链表头部的 5/8 是 young 区域,靠近链表尾部的 3/8 是 old 区域。LRU链表就是为了处理类似全表扫描的操作量身定制的,保证了 Buffer Pool 响应正常业务的查询命中率,因为该机制减少了大表查询时写入Buffer Pool 的压力, 查询的插入old 区域,业务的隔离在young区域。
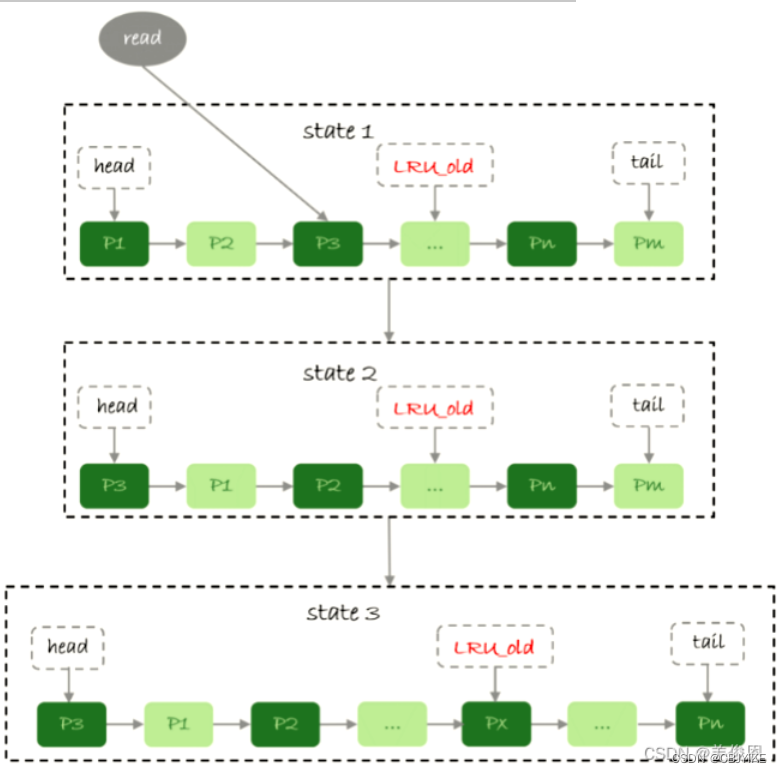
- 状态 1,要访问数据页 P3,由于 P3 在 young 区域,因此和优化前的 LRU 算法一样,将其移到链表头部,变成状态 2。
- 之后要访问一个新的不存在于当前链表的数据页,这时候依然是淘汰掉数据页 Pm,但是新插入的数据页 Px,是放在 LRU_old 处。
- 处于 old 区域的数据页,每次被访问的时候都要做下面这个判断:
- 若这个数据页在 LRU 链表中存在的时间超过了 1 秒,就把它移动到链表头部。
- 如果这个数据页在 LRU 链表中存在的时间短于 1 秒,位置保持不变。1 秒这个时间,是由参数 innodb_old_blocks_time 控制的。其默认值是 1000,单位毫秒。
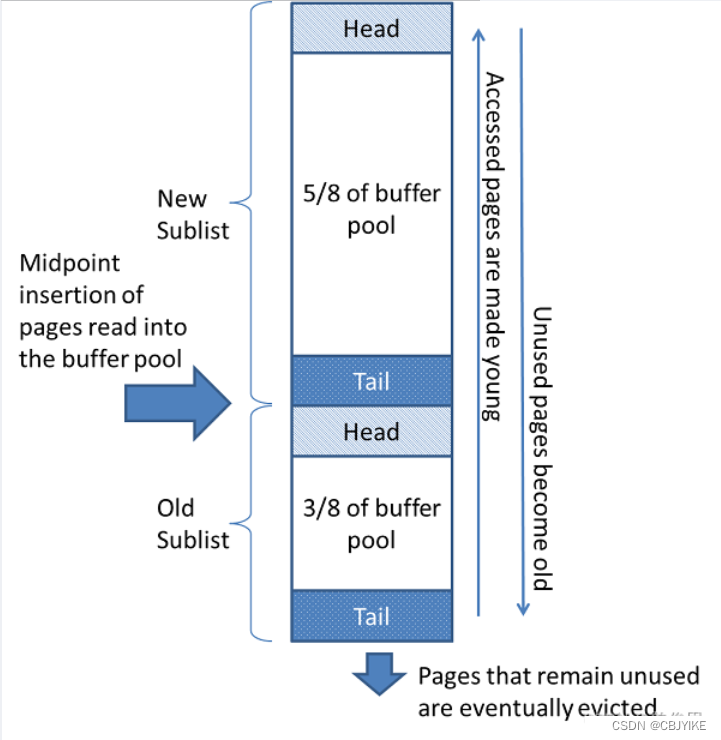
当业务进行大量的CRUD时,需要不断的将数据页读取到buffer pool中的LRU链表中。LRU链表被MidPoint分成了New Sublist和Old Sublist两部分。其中New Sublist大概占比5/8,Old Sublist占比3/8。New Sublist存储着young page,而Old Sublist存储着Old Page。可通过show variables like ‘%innodb_old_blocks_pct%’;查看当前的MidPoint,该参数可动态调整;当从磁盘中新读出的数据会放在Old Sublist的头部。这样即使你真的使用select * from t;也不会导致New Sublist中的经常被访问的数据页被刷入磁盘中,从而保障了业务的缓存命中率。正常情况下,访问Old Sublist中的缓存页,那么该缓存页会被提升到New Sublist中成为热数据。但是当你通过 select * from t 将一大批数据加载到Old Sublist时,然后在不到1s内你又访问了它,那在这段时间内被访问的缓存页并不会被提升为热数据。另New SubList也是经过优化的,如果你访问的是New SubList的前1/4的数据,他是不会被移动到LRU链表头部去的。比如全表扫描200G 的表, 改进后的 LRU 算法的操作逻辑:
- 扫描过程中,需要新插入的数据页,都被放到 old 区域 ;
- *一个数据页里面有多条记录,这个数据页会被多次访问到,但由于是顺序扫描,这个数据页第一次被访问和最后一次被访问的时间间隔不会超过 1 秒,因此还是会被保留在 old 区域;
- *之后再继续扫描后续的数据,之前的这个数据页之后也不会再被访问到,于是始终没有机会移到链表头部(也就是 young 区域),只有那些非热点数据会被淘汰出去。
参数重新调整:
mysql> set global innodb_old_blocks_pct=20;
mysql> set global innodb_old_blocks_time=500;
mysql> show engine innodb status\G; #可以查看LRU队列的使用情况
#观察缓冲池的运行状态:
select pool_id,hit_rate,pages_made_young,pages_not_made_young from information_schema.innodb_buffer_pool_stats\G;
# 查看LRU列表中每个页的具体信息:
select table_name,space,page_number,page_type from information_schema.innodb_buffer_page_lru where space=1;
结果说明:
- Buffer pool size:表示当前缓冲池中内存页的数量,内存池的大小=Buffer pool size*16KB
- Free buffers:表示当前FREE列表中页的数量;
- Database pages:LRU列表中页的数量;
- Modified db pages:显示了脏页的数量;
- Pages made young 0, not young 0 :表示是否发生了页在LRU队列上的移动;
- 0.00 youngs/s, 0.00 non-youngs/s:表示每秒两类操作发生的次数;
- Buffer pool hit rate:表示缓冲池的命中率,正常情况下命中率如果低于95%,则需要观察是否因为全表扫描引起了LRU队列被污染的问题
- Per second averages calculated from the last 18 seconds:表示show engine innodb status\G;打印的是过去18秒内的数据库状态。
注意:脏页既存在于LRU列表中,也存在于Flush列表中。LRU列表用来管理缓冲池中页的可用性,Flush列表用来管理将页刷新回磁盘,二者互不影响。