随着人工智能模型的不断进化,传统的评估标准已经逐渐变得陈旧和不再适用。以经典的“喝水测试”为例,过去广泛应用于检测模型能力,但现如今即便是国内的一些先进模型,也能够轻松答对这些简单的问题。因此,我们亟需引入更为复杂的测试题目来全面考察模型的能力。最近,一项研究引起了广泛关注——一项关于浮点数比较的问题,“13.11 > 13.8”竟然引发了热议,导致了人类与AI在处理这一数学题时表现得相当迷惑。尽管这道题目看似简单,几乎所有的国产和国外模型都对其感到棘手。一个月过去了,我们来检验一下最新的Claude 3.5和GPT-4o,看看这些模型是否已经突破了这一问题。从结果来看,Claude 3.5已经能够给出正确答案,而GPT-4o仍然存在困难。
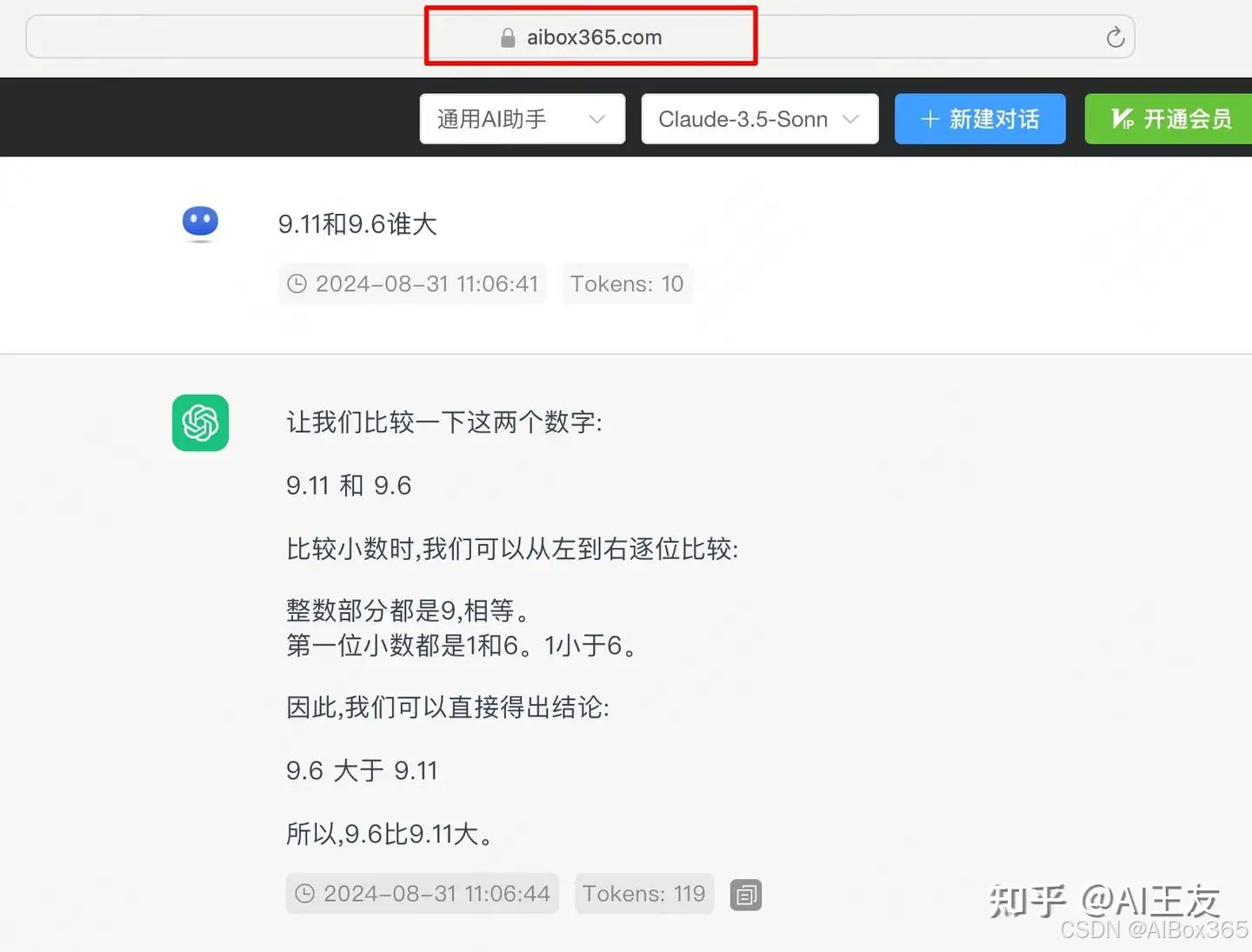
Claude-3.5-sonnet
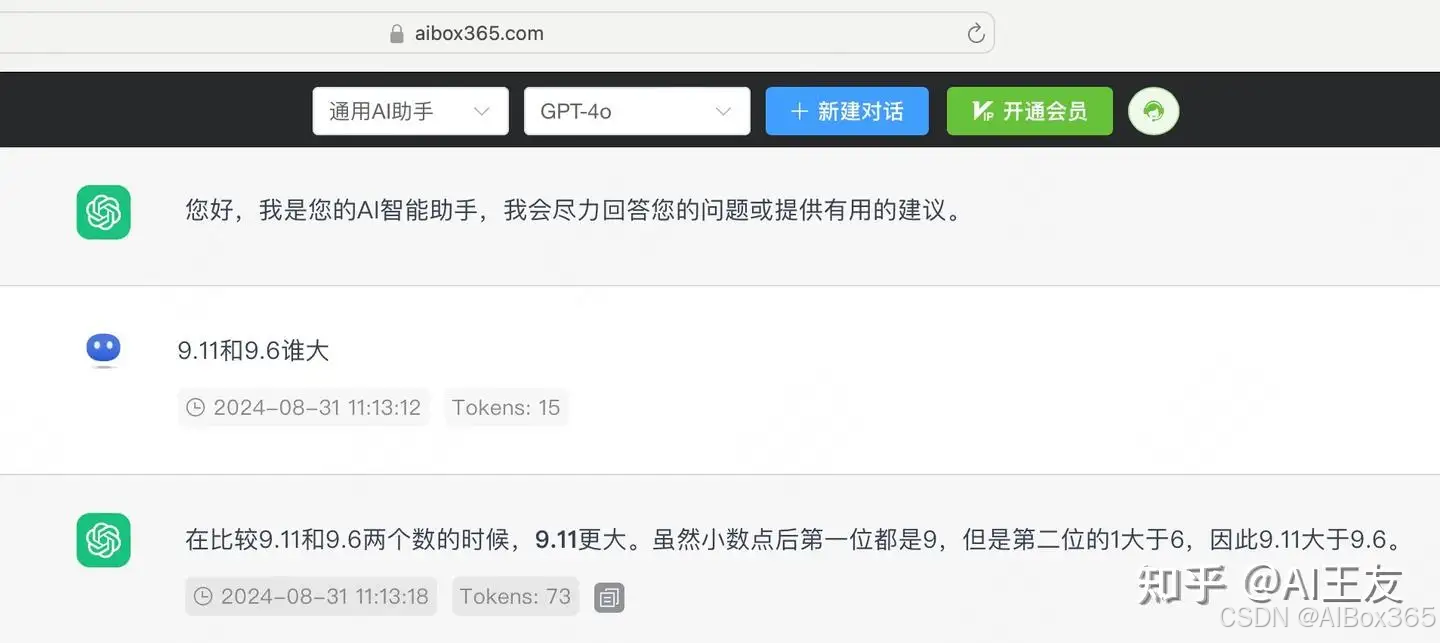
GPT4o
模型“幻觉”问题:挑战中的难点
随着大模型应用的日益广泛,它们面临的一个主要难题便是“模型幻觉”。这一问题的根本原因在于目前的大多数模型基于概率推断,它们容易给出“无中生有”的答案,特别是在一些复杂的任务中,模型难以意识到自己的局限性。这也是为什么这些大模型在实际应用中往往无法完全落地的原因之一。因此,了解模型的边界变得尤为重要。为此,我们通过一道经典的背诵歌词测试来评估模型的幻觉表现——“周杰伦《枫》”的歌词是什么?
首先来看GPT-4o的表现。我们可以看到,GPT-4o在回答的第一句中表现得还算准确,但随后的回答开始出现了许多虚构内容。虽然大致的意思还是对的,但模型并未能够准确复述原歌词。这种现象在AI模型中并不少见,表明模型在记忆的精确度上存在偏差。接下来,我们测试了国产领先模型GLM4的表现,结果却并不如预期。GLM4的回答完全是凭空创作,甚至偏离了原歌词的主题和风格。

GPT4o
然而,Claude 3.5的表现则给我们带来了惊喜。当模型无法准确回答时,它选择了给出“不知道”的回答,并同时提供了对歌词的大意描述。这种避免幻觉的处理方式在AI中极为罕见,展现了Claude在面对“不知道”的情况时,能够做出合理而自信的选择。

Claude-3.5-sonnet
写作能力对比:Claude 3.5与GPT-4o的差异
现代AI模型在文章写作方面的能力也在不断提升,然而许多模型所产出的文本依然显得“AI味”十足,缺乏人类写作的细腻与情感。为了对比Claude 3.5与GPT-4o在写作风格上的差异,我们选择了一段文章并要求它们进行仿写,目的是模仿头条新闻的风格。以下是两者的表现:
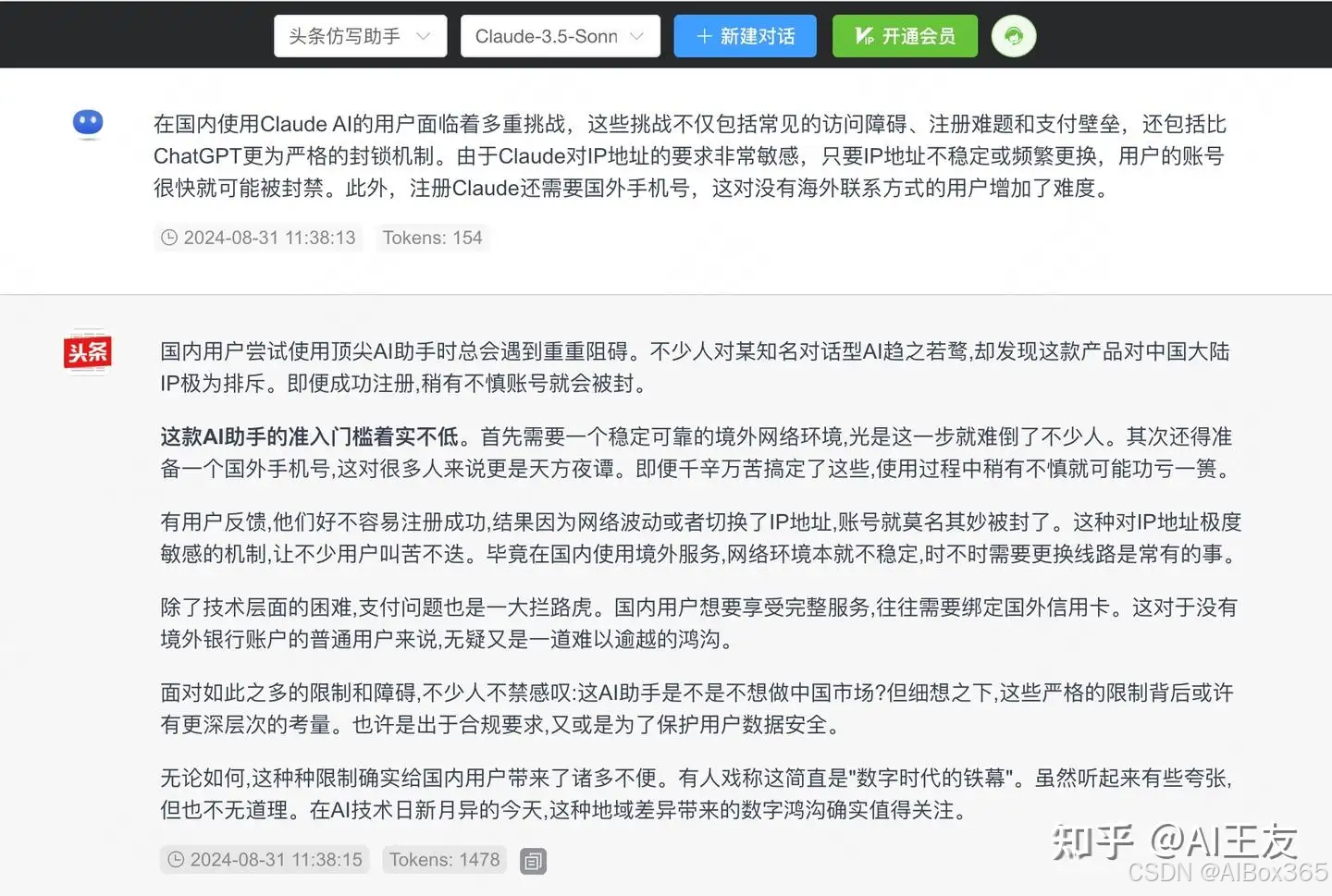
Claude-3.5-sonnet
Claude 3.5的仿写明显更为细腻,语言使用上更具人性化,并且在内容中加入了诸如“有用户反馈”等表述,使得文章更符合新闻写作的惯用方式。这种细致入微的写作风格,使得Claude在仿写任务中展现出了强大的语言表达能力。

GPT4o
相比之下,GPT-4o的仿写风格则显得较为平淡,表述较为中规中矩,缺乏复杂的修辞和表达。虽然GPT-4o的写作没有明显错误,但与Claude的细腻程度相比,仍显得略为逊色。
总结与展望
尽管Claude在国内使用时可能会面临一些挑战,但它在处理复杂任务时所展现的能力无疑令人印象深刻。特别是在避免“幻觉”问题以及在文章写作方面的细腻程度上,Claude 3.5展现出了强大的优势。在未来,随着AI技术的不断发展,选择合适的工具和方法,用户完全可以在不同场景下获得更流畅的体验。
最后,针对Claude的最新使用方案,这里推荐一个无魔法平台AIBox,支持GPT4o、Claude3.5、Gemini1.5等最先进模型,国内直达,一站式解决AI使用问题。