1.MobileNet网络介绍
MobileNet V1 idea:
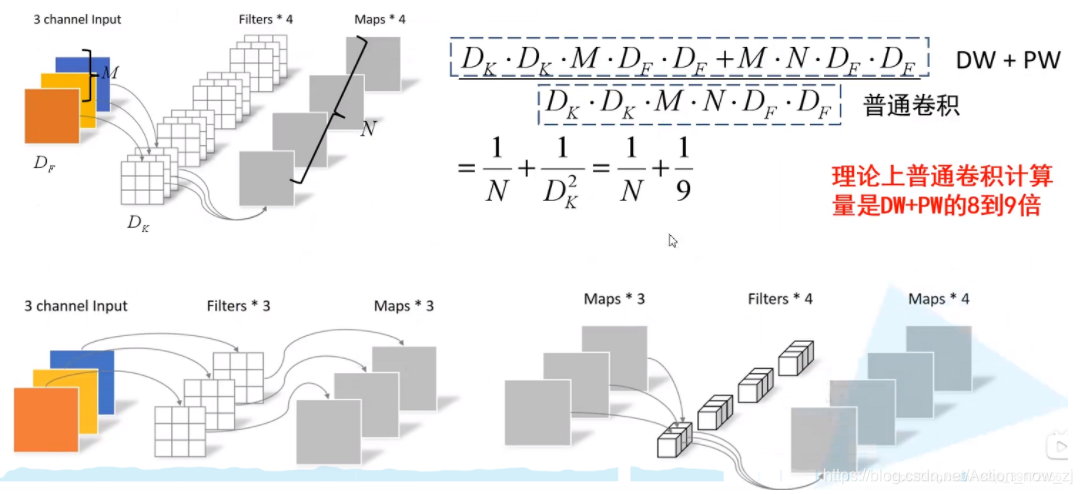
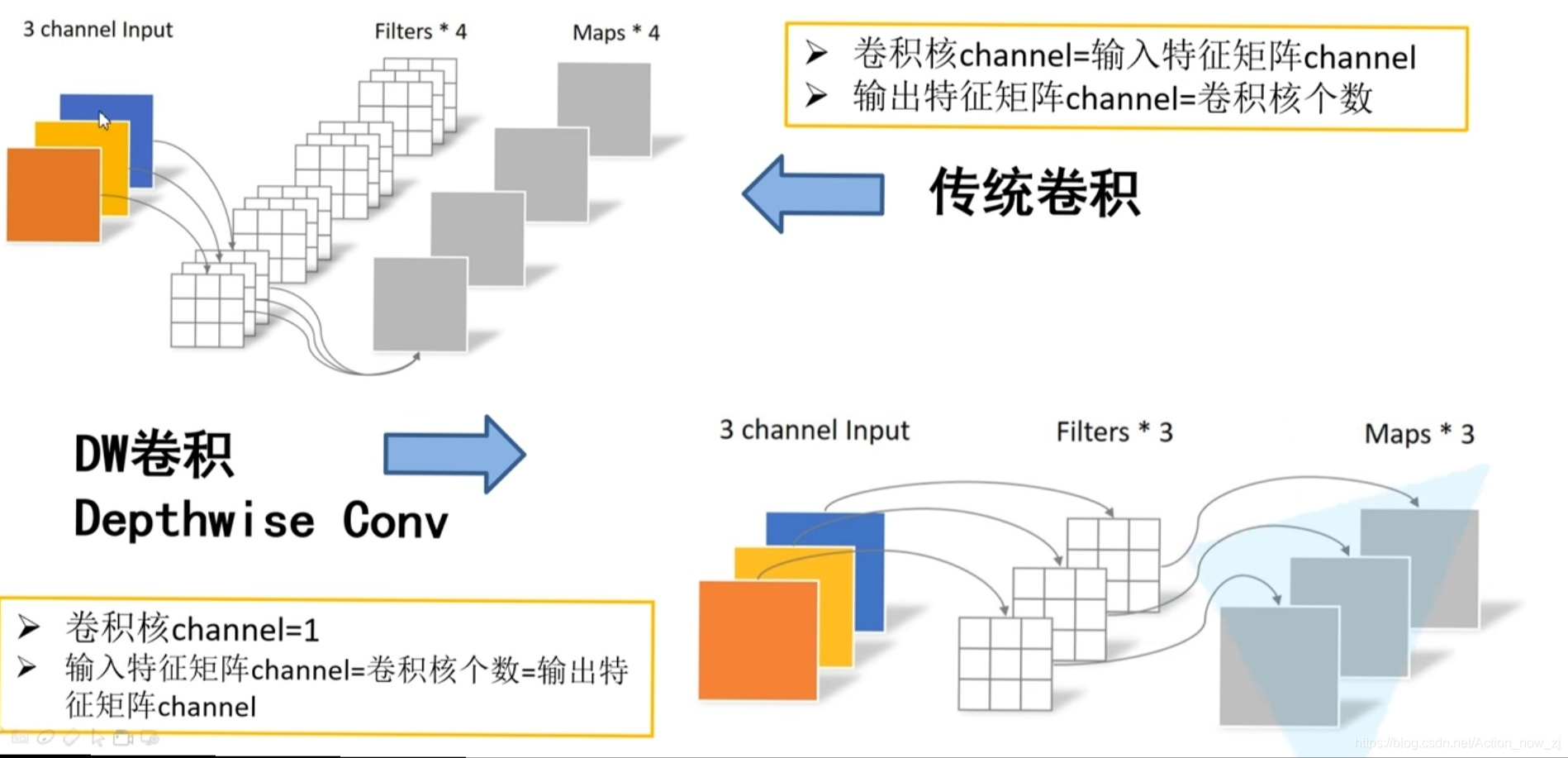
1、DW卷积
2、增加超参数 α 、β (人为设定)
DW卷积的 输入特征矩阵channel = 输出特征矩阵channel=卷积核个数
深度可分离卷积(Depthwise Separable Conv)
由DW(Depthwise Conv)卷积和PW(Pointwise Conv)卷积组成
MobileNet V2
idea:
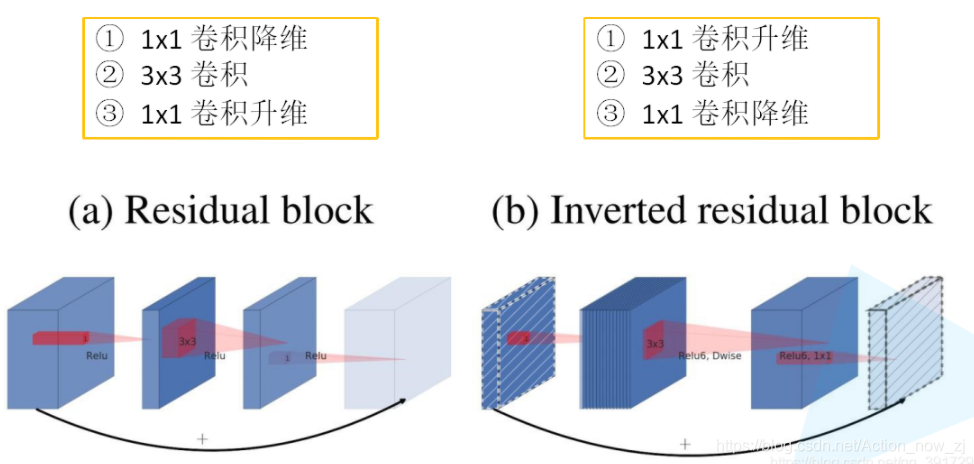
1、Inverted Residuals(倒残差结构)
2、Linear Bottlenecks
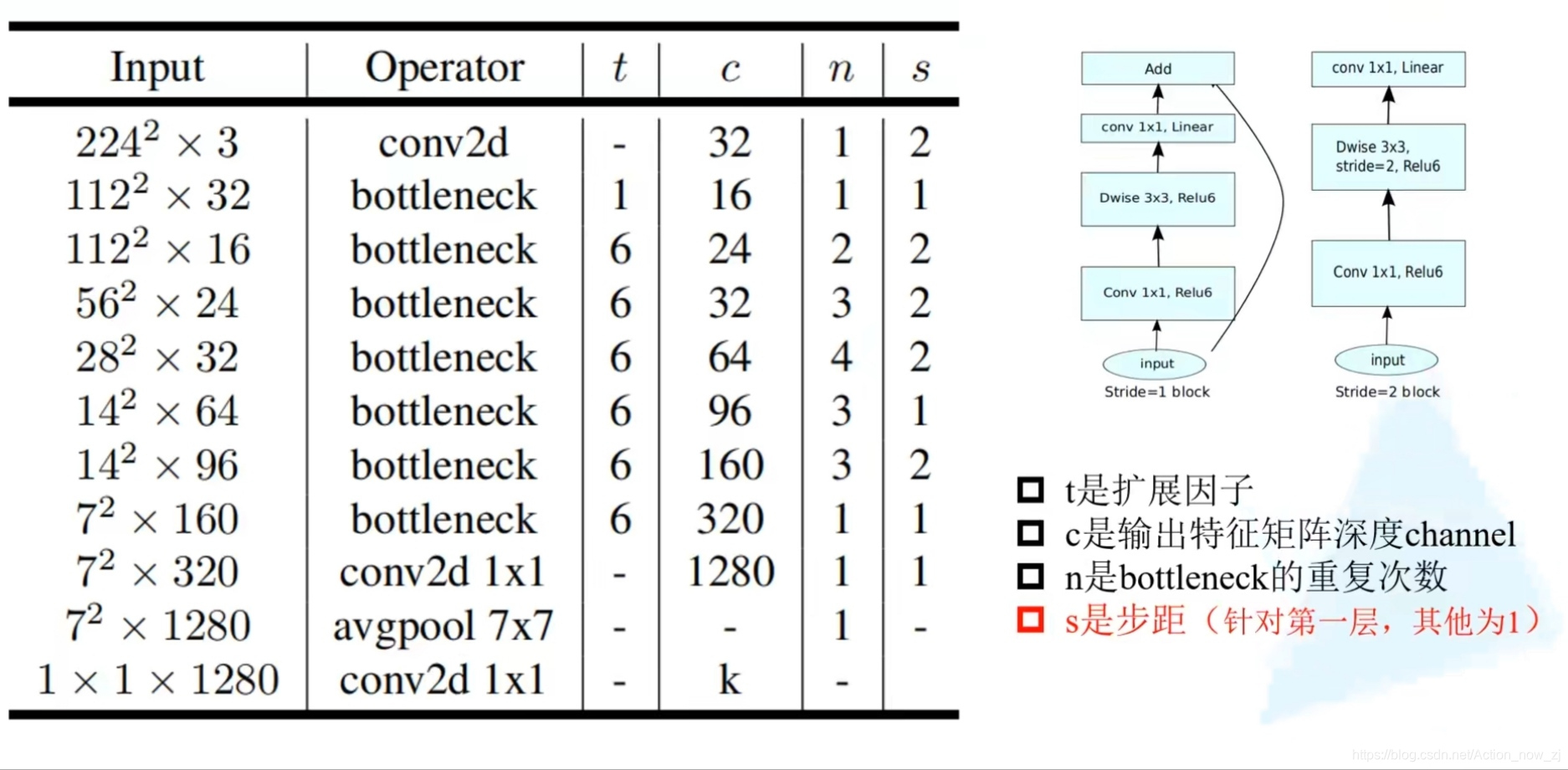
- MobileNet V2中的bottleneck为什么在1*1卷积之后使用Linear激活函数?
因为在激活函数之前,已经使用1*1卷积对特征图进行了压缩,而ReLu激活函数对于负的输入值,输出为0,会进一步造成信息的损失,所以使用Linear激活函数。
- MobileNet V2中的bottleneck为什么先扩张通道数在压缩通道数呢?
因为MobileNet网络结构的核心就是Depth-wise,此卷积方式可以减少计算量和参数量。而为了引入shortcut结构,若参照Resnet中先压缩特征图的方式,将使输入给Depth-wise的特征图大小太小,接下来可提取的特征信息少,所以在MobileNet
V2中采用先扩张后压缩的策略。
1.model.py
from torch import nn
import torch
'''_make_divisible()作用将卷积核个数调整到8的整数倍。'''
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
'''
定义网络结构,每一个卷积操作
group=1表示是普通卷积,group=2表示Depthwise(DW)卷积
padding有kernel size大小决定
'''
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
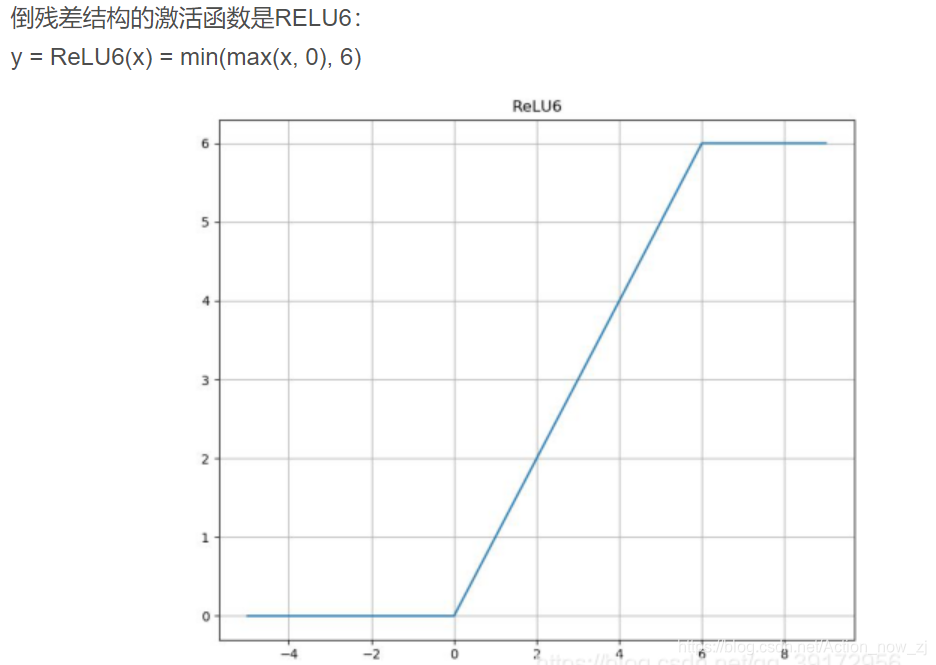
nn.ReLU6(inplace=True)
)
'''
倒残差结构
1.expand_ratio表示扩展因子。
2.hidden_channel = in_channel * expand_ratio中的hidden_channel表示输出深度也是卷积核数量。
3.use_shortcut判断是否在正向传播过程中使用Mobile的捷径分支,bool值。
4.stride == 1 and in_channel == out_channel判断使用捷径分支条件:stride == 1并且输入深度等于输出深度。
5. if expand_ratio != 1 判断扩展因子是不是等于1,不等于1就添加一个1x1的卷积层。等于1的话就没有1x1的卷积层。
forward()如果use_shortcut为TRUE的话使用捷径分支,返回卷积结果和捷径分支的和。如果为FALSE返回主分支卷积结果
'''
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self