该文章参考宋宝华老师的内存管理课程,详细可以去听阅码场宋老师的课程。
本文将从 从硬件原理 到内核实现 配置内存的参数(内存什么时候回收,脏数据什么时候收回?) 从应用程序上的内存泄漏 还有工程中一些常遇见的问题 ,比如 DMA 的内存从哪里来?连续内存分配器?来理解内存管理。
1、硬件原理和分页管理

几个概念:
内存空间和内存的区别
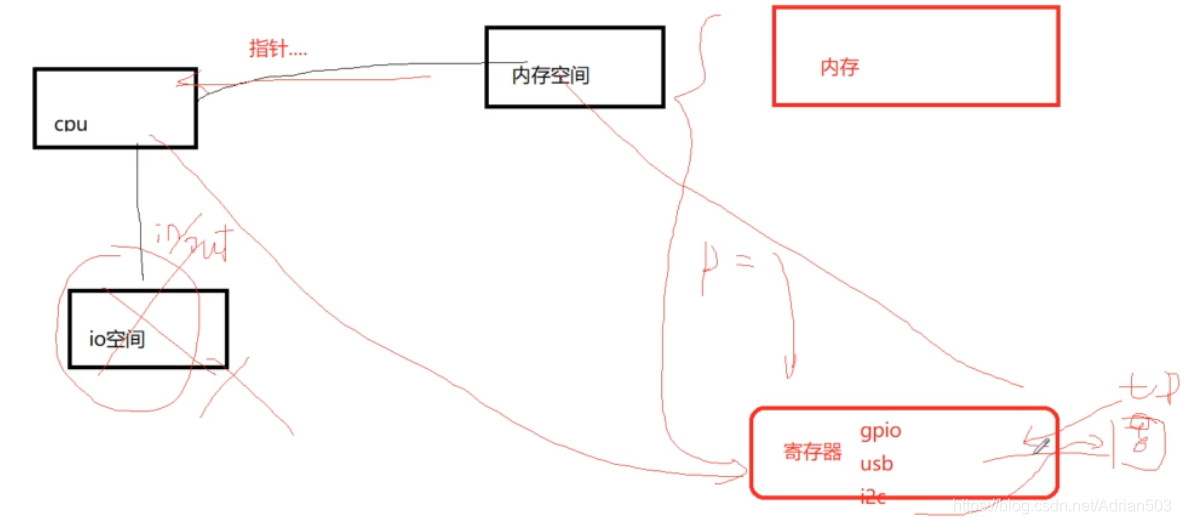
CPU 访问外面的资源,有两种方法,第一种是通过 指针地址的方式去访问内存空间,另外一种是通过 IN/OUT 的方式去访问 IO空间(有一些寄存器),这一种方式是X86所特有的,在RISC中没有。
内存空间分为两部分,内存和寄存器,寄存器就是cpu 里常见的 usb gpio i2c spi 等控制器,由此可见,内存和内存空间不是一回事。如果通过 i2c 又接一个外设,那外设的寄存器和 内存没有半毛钱的关系,因为它的寄存器是通过 cpu 的i2c 控制器访问的,和 内存没有直接的关系。
虚拟地址 / 物理地址
mmu 是一个硬件,负责把虚拟地址转化为物理地址。
所谓一花一世界,一叶一菩提,相同的事物在不同的角度可能会有不同的看法,对于物理地址,虚拟地址的概念也是如此。
物理地址是MMU的视角所看到的内存地址。虚拟地址是存在MMU的前提下CPU和程序员所看到的内存地址,我们实际编程的时候操作的就是虚拟地址。
内存里面有很多页表,这个页表的基地址都会存在 MMU 里的寄存器上,当cpu 切到 QQ 程序的时候,MMU 就会把页表切换到 QQ的页表,
当cpu 切到 wechat 程序的时候,MMU 就会把页表切换到 wechat 的页表 , 每次切换的时候,MMU里的基地址都会被重写,MMU 就是负责查找页表,将cpu的虚拟地址 和 物理地址的映射关系找出来,由此可见,同样的虚拟地址,int a ; 的地址是 1G, QQ 和 Wechat都有一个1G的虚拟地址,但是它们的物理地址是不一样的。这也是为什么每个进程都有一个4G的虚拟地址空间,那是因为进程切换的时候,页表就切换了。总之,一旦开启了MMU , cpu 就只知道虚拟地址,不知道物理地址,谁来做物理地址和虚拟地址的转换呢?这是硬件MMU来做的。一定是硬件来做的,不是cpu来做的,这个查找页表的过程一定是硬件来做的,软件是做不了的,CPU来做,负担太重了,CPU 每看到一个变量a , 都要去查它的页表吗,这是不可能的,都是MMU硬件帮它去查的。
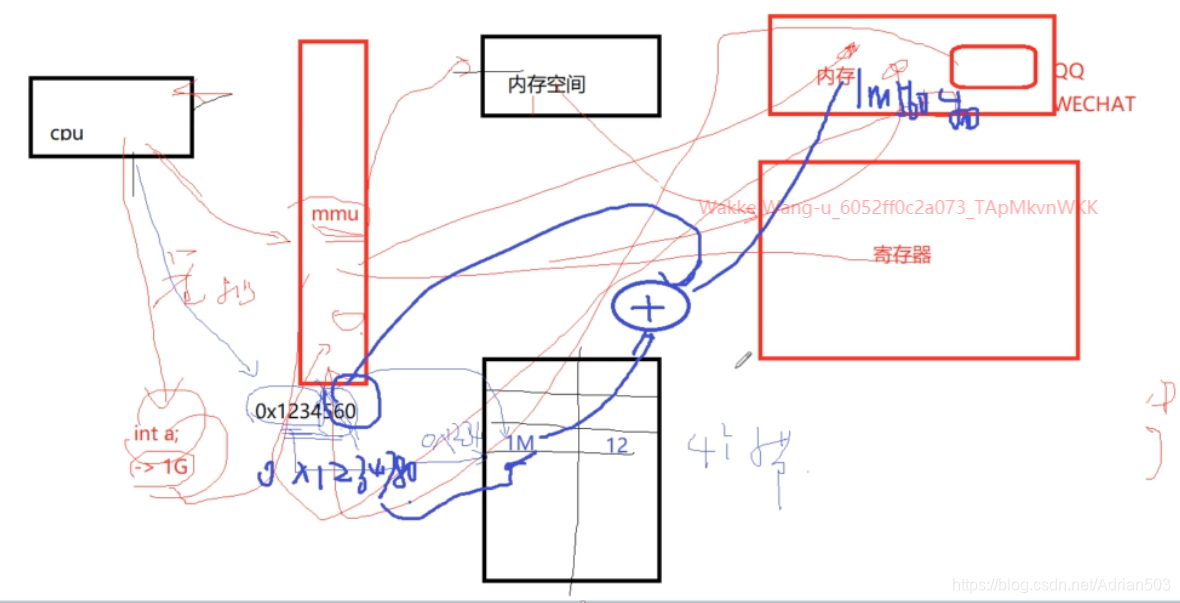
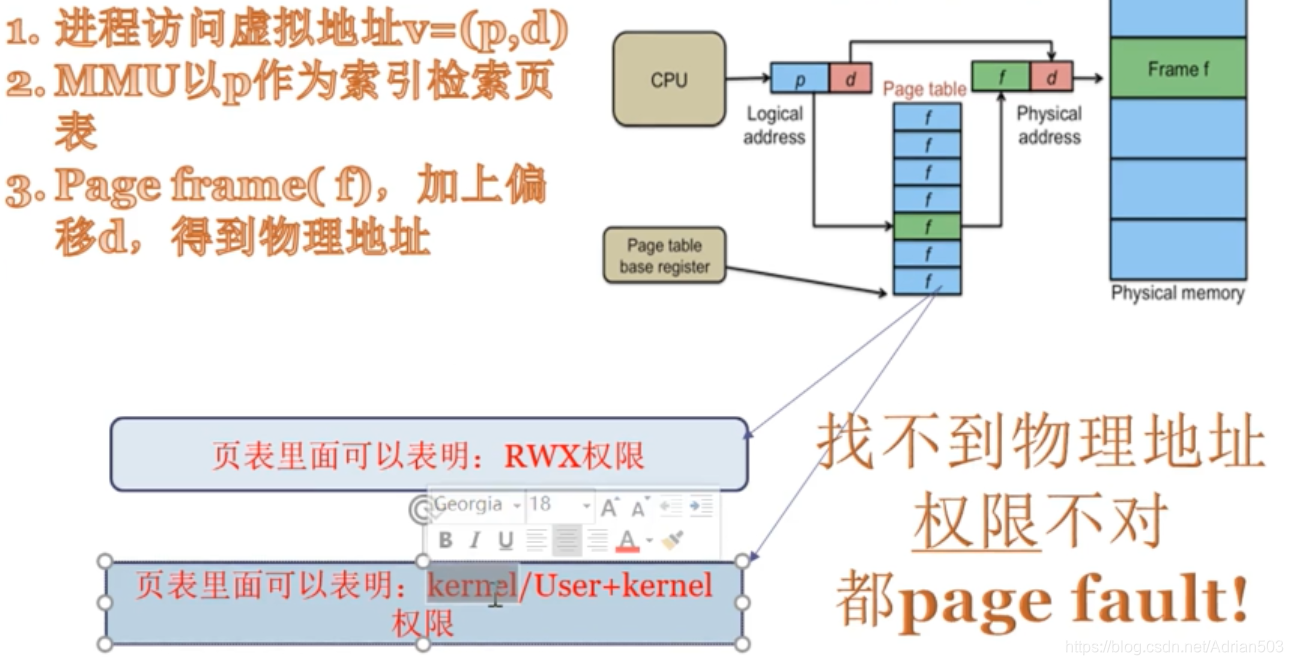
最简单的页表就是一个1维数组,页表一般都是2维 3 4 维的,为了方便理解原理,我们把页表想象成1维的,当我们CPU去访问一个地址 0x1234560 (这里注意,CPU发出的地址一定是 虚拟地址)的时候,一般的页表里面,每一页都是4k,
所以 560正好12位,显然是页内偏移,CPU在访问的时候,会直接把页内偏移直接删掉,那MMU就去查这个一维数组的第 0x1234行,每一行4个字节(32位处理器),比如说查到的物理地址是 1M ,那么实际的物理地址就是
1M + 页内偏移560 .
注意:CPU发出的地址一定是 虚拟地址 , int * p =1M . 指针一定是虚拟地址,物理地址不是一个指针,是一个整数!大家可以看内核里面,关于物理地址的定义,都是一个 u32 或者 u64类型的一个整数。指针都是cpu的角度去发出的一个地址,
CPU 不肯能直接通过物理地址访问到寄存器,也不可能直接通过物理地址访问到内存,反正内存空间的东西,CPU 只能通过MMU来访问,一切都要通过虚拟地址。当然虚拟地址是可以等于物理地址的,这只是在页表里填的地址和物理地址一样而已。
MMU 通过查页表就将虚拟地址转化为了物理地址。
页表的结构,一个32位的处理器,高20位是来存储物理地址的,比如我们去访问一个 0x1234560的虚拟地址的时候,页内偏移是 560 ,也就是 页表中只需要存储 高20位的物理地址就行,那页表中剩余的12位存储什么呢?是非常重要的东西。
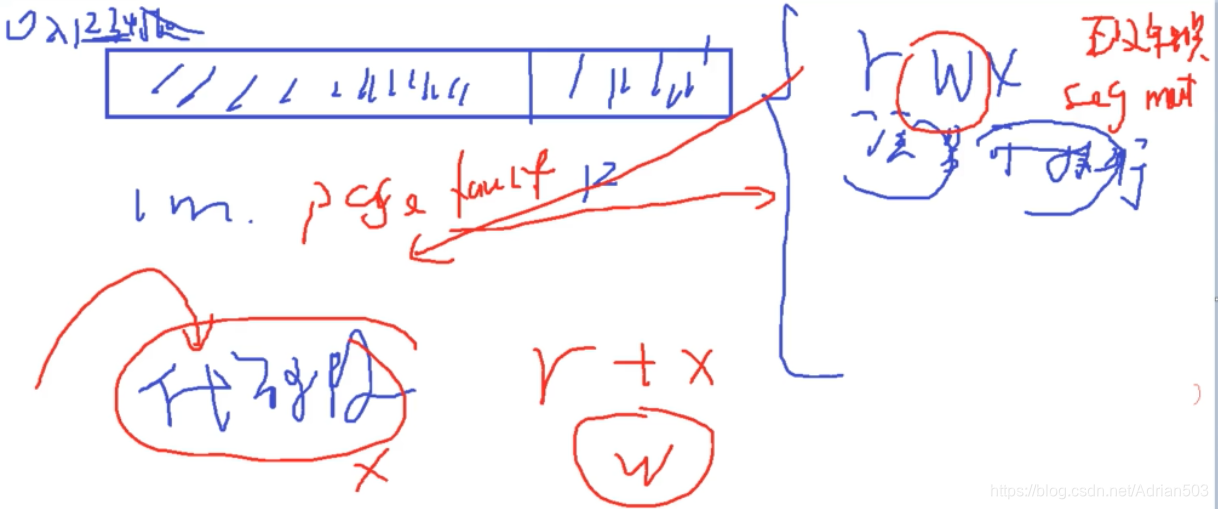
存储物理地址的权限,RWX , 还有 kernel/ user + kernel 权限 。当你非法操作的时候,就会导致一个 page_fault ,segment fault , 这里的内存管理系统中的 权限管理是非常重要的,这里举一个栈溢出,产生page fault的例子,也是黑客进行缓存攻击的一个案例
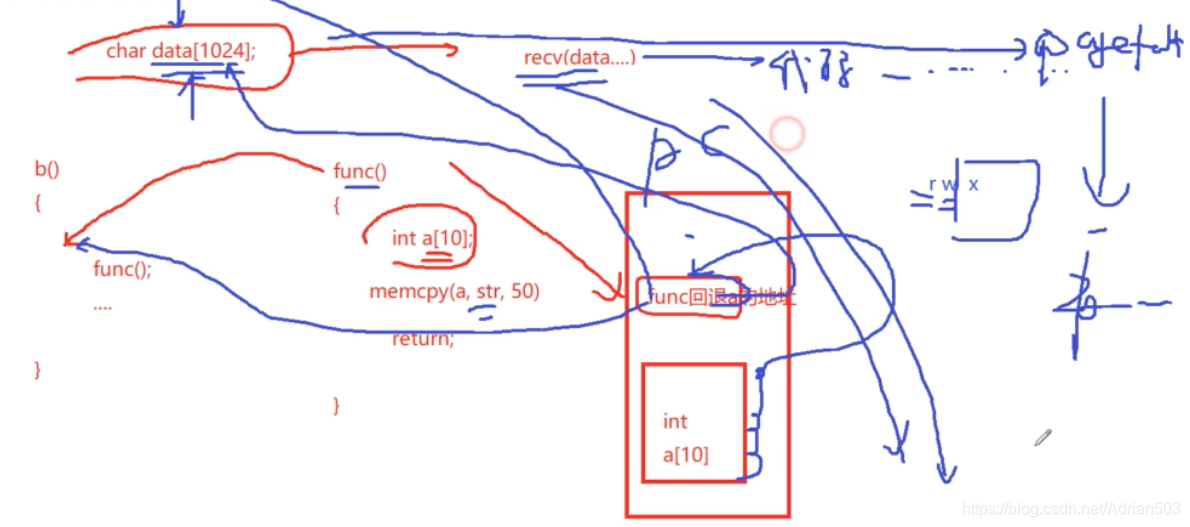
我的主程序 一直在接收报文,其中的一个函数 func 中,定义了一个数组a, 它最多能够存储40个字节,如果下面的操作,往a地址拷贝了更多的数据,因为栈是向上增长的,可能会改变到 func的返回值,如果这个写的缓存够大,
覆盖到你的报文 data 中去了,当然你写的缓存可能是一串可执行的代码,可能是盗取密码,盗取密钥的代码,你想去执行,但是 data 是存在数据段上的,数据段在内存上的权限是 RW , 没有可执行的权限,这时内核就会报一个 pagefault
你的程序就挂掉了,这是内存管理安全性的一个保障。
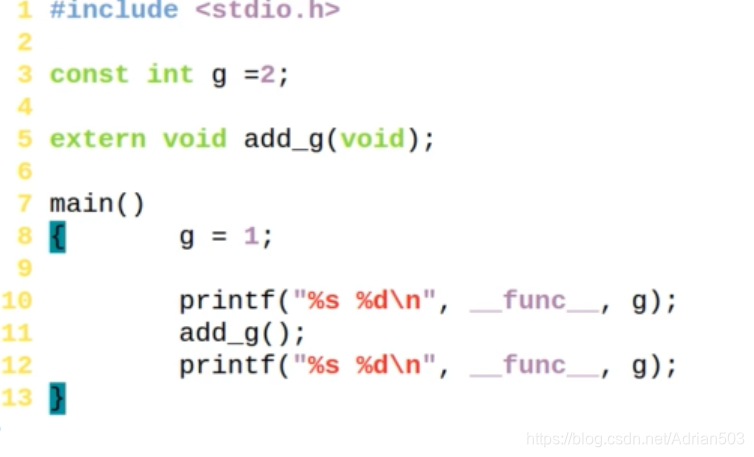
另外一个例子,两个文件 main.c g.c
main.c 如下
g.c 如下
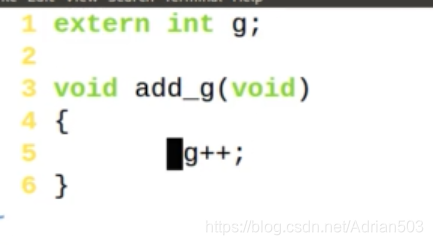
编译 gcc main.c g.c

这个结果是 main.c 里对一个 const变量进行操作,被编译器拦截了。如果把 main.c 的 g=1 注释掉 重新编译,就可以编译通过(g.c 中不知道 g是const的)。但是在执行的时候会有 segment fault.
后面是内存管理来做的。segment falut 就是 应用程序收到了内核发出的 信号11 SIGGEGV (kill -l 可以查看)
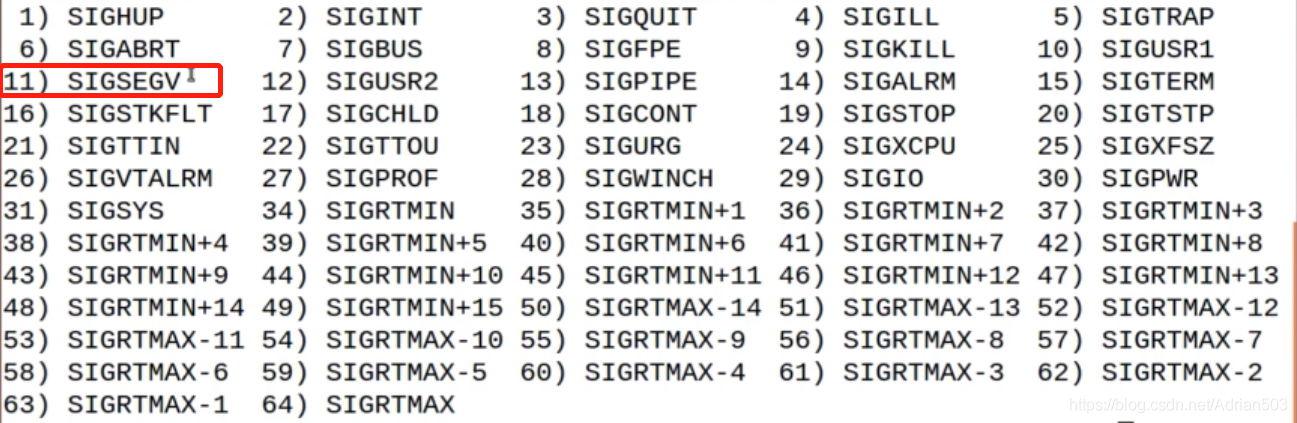
如果要证实程序就是死在这一句呢,可以用 gdb来跑一下,要学会自己调试。

这里总结一下:
在linux 里面 不同于实时系统的 非常重要的一点就是 内核就是内核,应用就是应用 ,内核空间是用户空间里剥离出来的。
用户空间的程序在跑的时候,你是不能访问内核里面的东西的,如果应用程序能够随便进到内核的话,很容易把内核搞挂,影响到别的程序。
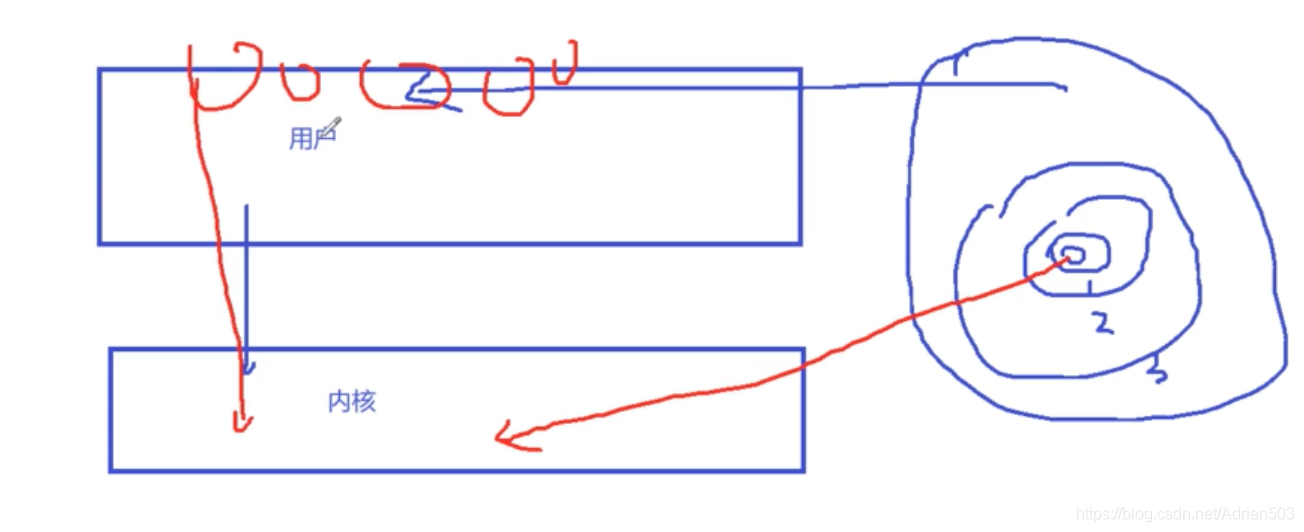
内核相当于给应用提供了一个虚拟的环境,所以在linux里面,一定要坚信一点,只要kernel 挂了,一定是kernel 的 bug , 有的时候,我极其的牛逼啊,我写个应用程序把内核搞挂了,请问这是不是我应用程序的bug?
还有我写了一个驱动,人家应用程序一调用,驱动挂了,他说人家应用层调用的不对,这些都是不对的。你写了一个内核程序,就要无条件保证,无论人家以多变态的方法去调用你,挂的都是那个应用。只要挂的是kenel ,就是kernel的bug。
因为你内核要提供一个无条件,透明的一个环境,来保证应用程序可以跑。1个进程跑100个线程,只要有1个线程挂掉了,整个进程就挂掉了。用户态是跑在三环的,内核是在0环的,如果要交互,只能通过特定的方法,系统调用 proc netlink 等方法。
所以在页表里,不仅会标注 RWX, 也会标注 user / kernel 的权限。
2 案例 - meldown 熔断漏洞

理论上来讲,我从一个应用层的程序,去访问一个内核空间的值,这是非法的。
基于时间的旁路攻击 Side-channel attack
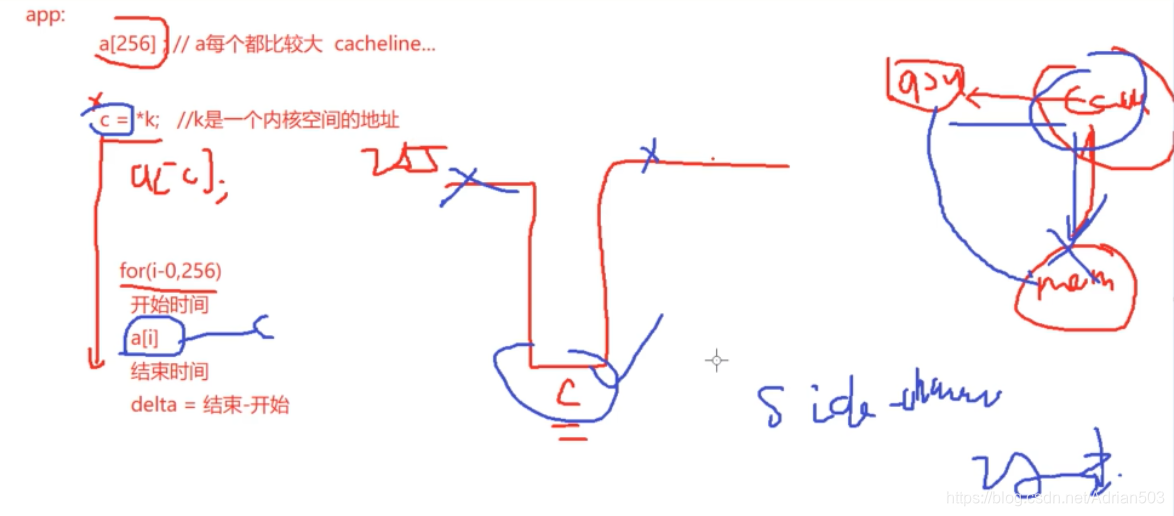
c=*k, 其实c 是拿不到具体的真实值的,因为访问的是一个内核空间的地址,但是由于CPU的这种狂奔的特点,它还是会继续往下执行的,执行完 c=*k 之后,我们会访问一下 a[c] ,
因为a[256] 中的值都比 cacheline 大,所以 cache 会命中 a[c] , 我们知道 cpu 访问cache的时间要比访问内存的时间要少很多,这样的话 ,我们就可以挨个访问a[256],然后记录访问的时间,根据时间来判断出c的具体值。
具体的原理呢,江湖中有个李小璐买汉堡问题的传说。可以看出CPU 的漏洞。

这就是基于时间的旁路攻击,大家写代码的时候,千万不要这样写,是很不安全的,这是基本的常识
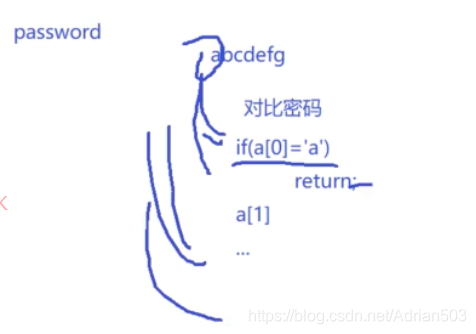
像这个对比密码的函数,攻击者可以一个一个试,因为第一个字母不对了,你就返回了,这个时间是很短的,对的时候你才会比较第二个字母,时间就更长,这很容易遭到旁路攻击。同样的方法,人家就可以探测出你的每一个密码是什么。
Meltdown 漏洞怎么修复呢?
注意:
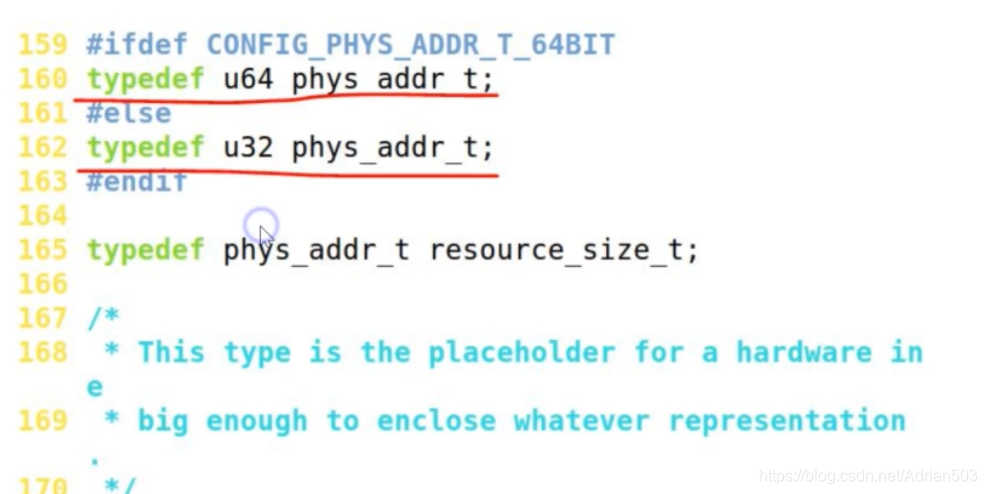
在内核中 物理地址是一个整数!不是指针,一般来说 32位的处理器,物理地址是 32位的,64位的处理器,物理地址是64位的,但是不一定都是这样!
32位的处理器,它的虚拟地址空间肯定是32位的,但是它的物理地址可以远大于32位,只要 MMU 里的页表支持可以映射到更多位的物理地址就可以。这叫大的地址扩展。一个32位的处理器,它的内存条是可以大于4G的,
3 内存分ZONE的问题
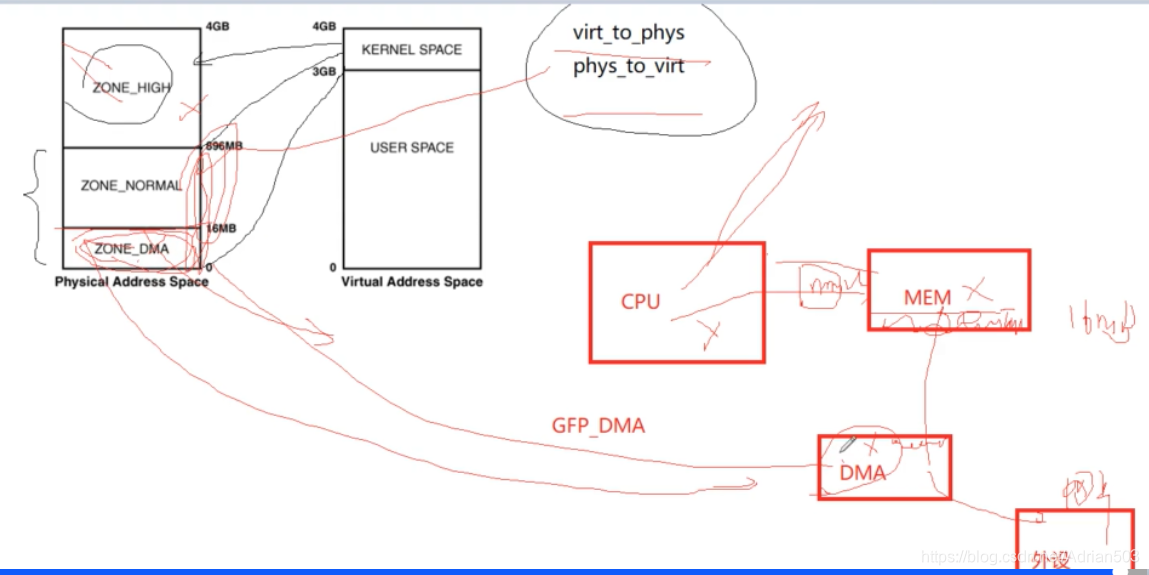
比如有一个大小4G的内存条,它的物理地址是 0-4G , 我们经常把它分为三个区域,
ZONE_HIGH 高端内存( 896M - 4G) ,在内核中一般不使用,如果要使用,通过 kmap映射。
ZONE_NORMAL
ZONE_DMA
我们要理解原理,像现在很多64位的处理器,已经没有 ZONE_HIGH , ZONE_DMA 也不一定有,这是有硬件决定的,有的硬件DMA引擎无法access 所有的内存,所以才制造出一个 ZONE_DMA的概念。
在64位处理器里面,可能还有 ZONE_DMA32 等等,
这里注意,如果你的DDR是 256M 512M ,那么是没有 高端内存的概念的。
当系统一上电,就会把一段低端内存 0 - 896M 线性映射到 虚拟地址 3G+0 -- 3G+896M 的内核空间中。这里注意,为什么映射一段,是因为整个4G我是映射不了的,这个896M 也不一定非得是896M , ZONE_HIGH的大小是可以配置的。
现在很多64位的处理器,已经没有896M的问题了,ZONE_HIGH 并不是浪费掉了,只是内核一般不访问 ZONE_HIGH,当然也有办法访问,通过kmap映射。它不像低端内存 ZONE_NORMAL ZONE_DMA 一开机就线性映射好了,
CPU访问这些物理地址很简单的啊,直接通过虚拟地址就好了。在内核里的两个宏,virt_to_phys 和 phys_to_virt ,这两个都是简单的线性偏移,只对部分的低端内存可以用,ZONE_HIGH是不行的。
ZONE_DMA 也不一定有,它存在的原因就是 DMA硬件有缺陷,有的硬件DMA引擎无法access 所有的内存,比如只可以访问0-16M的内存,或者 0-32M的内存。所以才有了 ZONE_DMA 或者 ZONE_DMA16 或者 ZONE_DMA32的概念。
一般来说DMA可以与内存直接交互的,但是也有一些比较牛逼的DMA引擎是有MMU的,注意 DMA的出现就是可以让CPU闲出来,可以干别的事情,它不会让你的外设变快,快不快是由于你的总线频率决定的,跟你CPU访问 还是DMA访问没有半毛钱的关系。
有缺陷的DMA在申请内存的时候 ,会用到 GFP_DMA 的标志,但是 并不是只要 DMA引擎才可以申请 ZONE_DMA, 鬼都可以申请,而且 DMA申请的内存 也不一定是在ZONE_DMA,这是由硬件决定的。
void *dma_alloc_coherent( struct device *dev, size_t size,dma_addr_t *dma_handle,gfp_t gfp);
这个函数申请的内存 也不一定来自 ZONE_DMA, 别看它名字里面有个DMA,那到底是来自哪里,完全取决你的外设, 它第一个参数就是device结构体 ,里面你会填写DMA的访问范围的啊,由这个决定的。
这里注意,CPU 和 程序员的视角是一样的,所以CPU 只关注虚拟地址连续就可以了,因为有了MMU,我们只要关系虚拟地址的连续就可以,物理地址连续不连续对我们来说不重要。
只有 DMA 会关注 物理地址的连续性,因为一般的DMA引擎是没有MMU的!
4 Buddy算法
理解完这些之后,我们要了解一个算法,Buddy算法

Buddy 算法直面物理内存,32位的处理器,可能内存条上来就分为了三个zone ,Buddy 的算法就管理这个ZONE,你不可能跨越两个ZONE去申请内存。
每个页是4K,每一个ZONE都有很多的4k页, buddy算法会把这个空闲的页都管理起来,把1页空闲的都放在一个链表上,2页空间的都放在一个链表上,
4页空间的都放在一个链表上,8页空间的都放在一个链表上,然后不停的进行拆分合并。
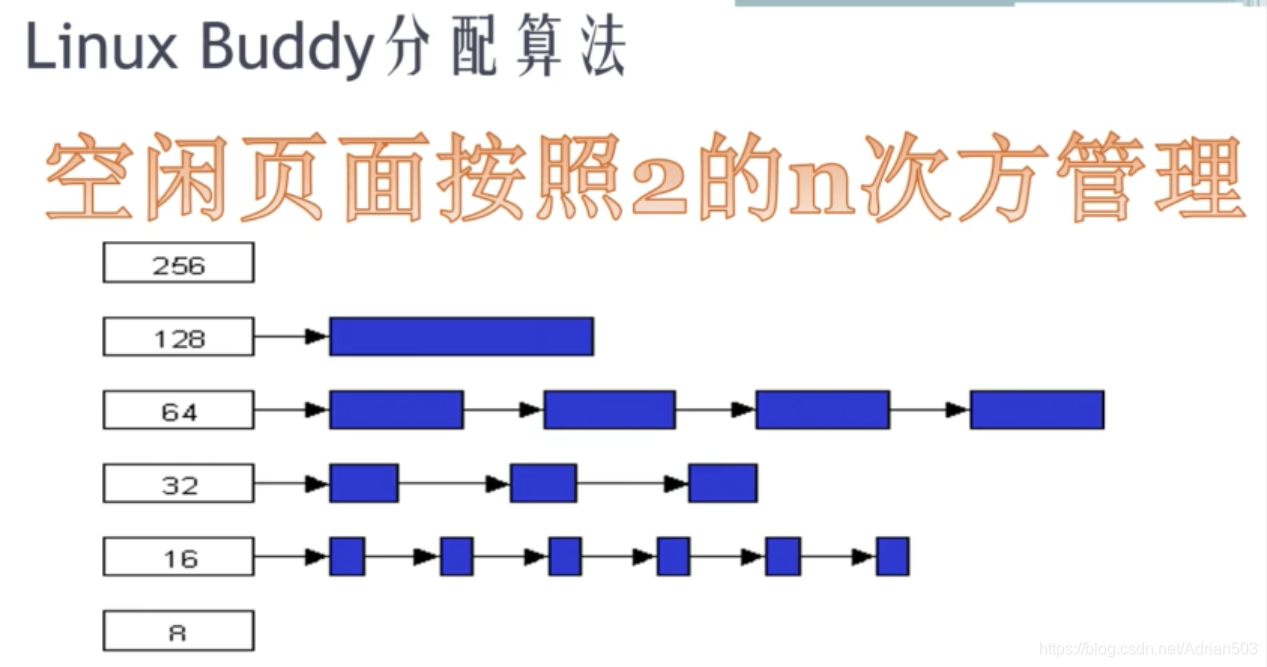
比如现在有 16页的空闲页,2^4 , 这个时候会有一个人来申请1页,现在就只有15个页,就分成了 8 + 4 + 2 + 1 ,就这样不停的拆分 合并,
Buddy 牛逼的地方就在于,全世界的正整数都可以拆分成2^n 的和的。那如何在系统里查看这些 空闲的页呢 , cat /proc/buddyinfo
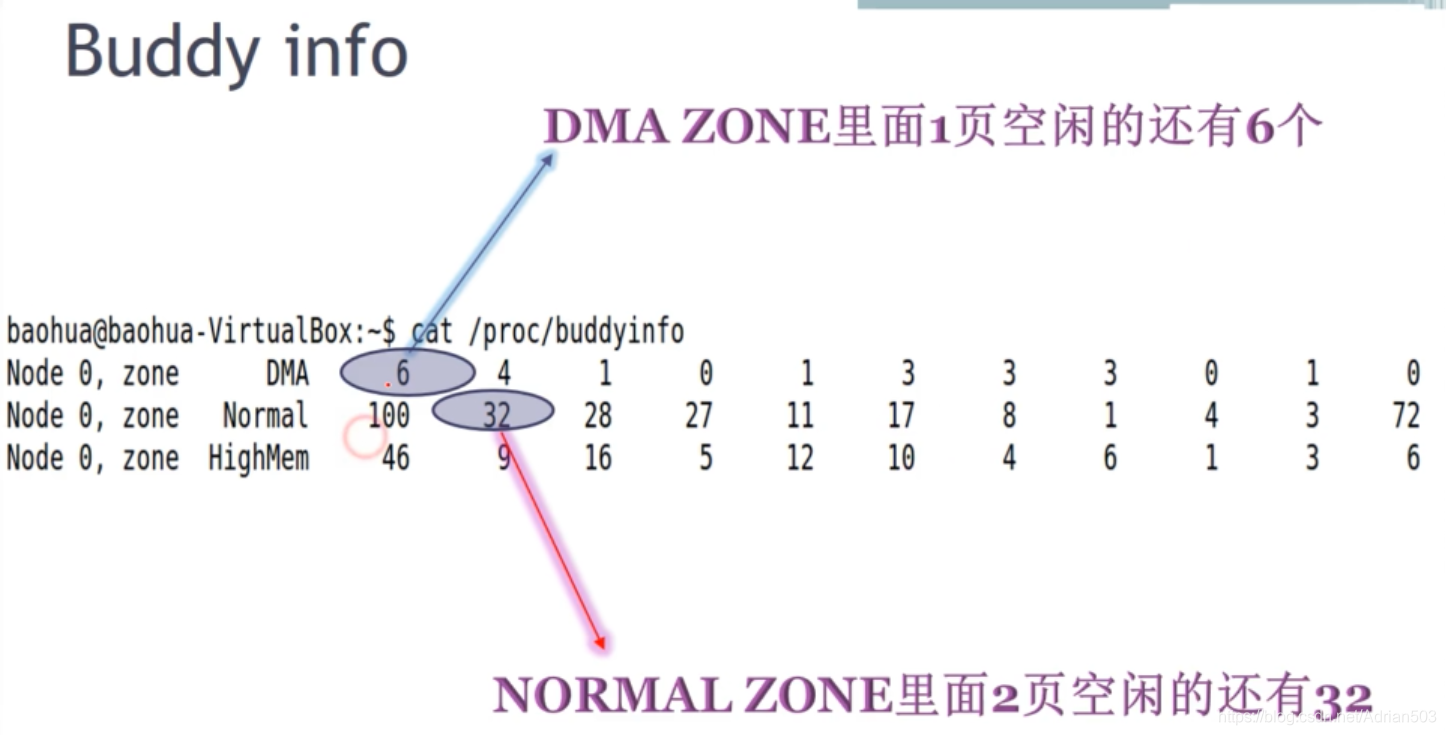
分别代表的是 DMA_ZONE中,1页空闲的还有6个,2页空闲的还有4个,4页空闲的还有1个,8页空闲的还有0............
Buddy 牛逼但是无法避免一个情况。你的内存还有很大,但是你的连续空闲的内存确很小。因为随着buddy算法的不断的拆分合并,会出现 buddyinfo 中前面很多,后面很少的情况,这会影响到会使用物理连续的情况。
但是谁会申请连续物理内存呢?有人说了应用程序,malloc(10M), 这是不对的!CPU 和 程序员的视角是一样的,所以CPU 只关注虚拟地址连续就可以了,因为有了MMU,我们只要关系虚拟地址的连续就可以,物理地址连续不连续对我们来说不重要。
只有 DMA 会关注 物理地址的连续性,因为一般的DMA引擎是没有MMU的!
比如有一个摄像头,拍摄了一张1080p的图像 8M,想通过DMA引擎传过去,但是这个DMA引擎是没有MMU的,它就无法搞清楚虚拟地址和物理地址的关系,它只能给它一个连续的物理地址,好了,我现在cpu上有100M空闲的内存,但是没有一个8M连续的内存,
怎么办?
早期人们是怎么解决的呢?是通过预留内存的方法解决的,比如你买的手机是1G的内存,但是看起来只要800M ,其实是有一部分是预留起来了,可能20M给摄像头,20M给显示器,50M给GPU啊等等。但是这样会有浪费的情况存在啊。
5 CMA连续内存分配器
后来三星公司有一个工程师,提出了一个非常天才的设计,叫CMA 连续内存分配器
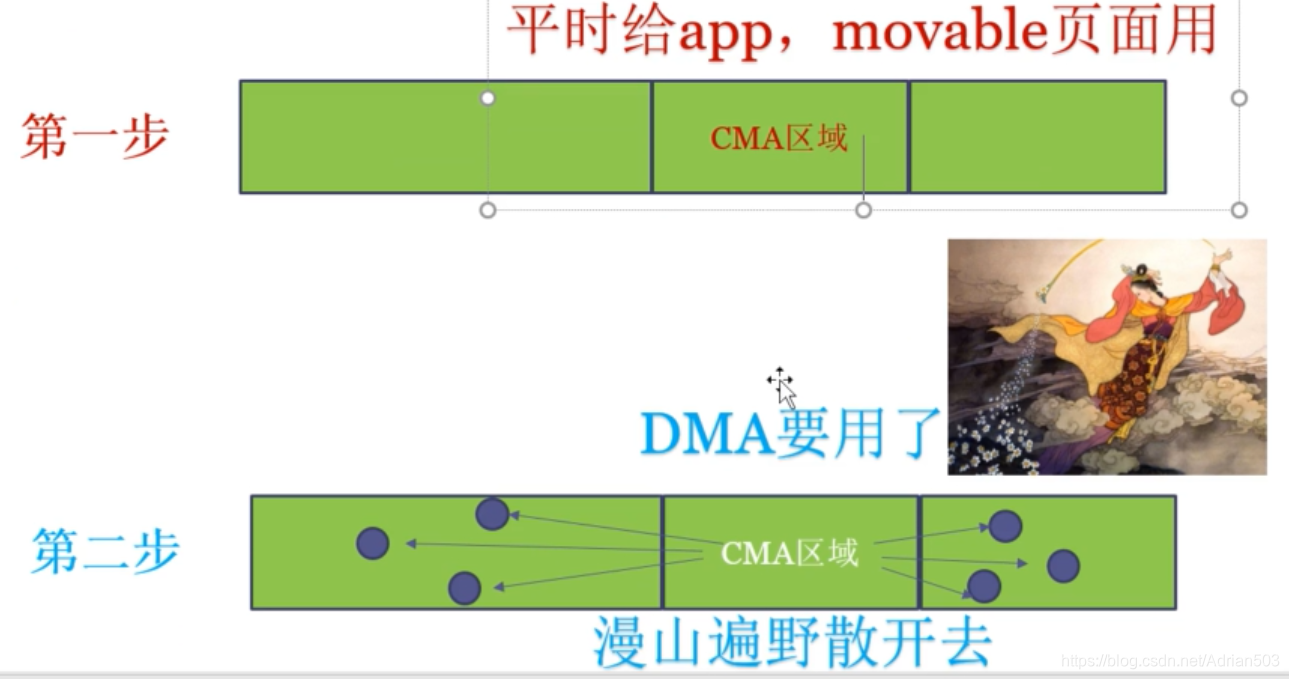
还是原来的例子,我开辟了一个32M的CMA的区域,本来是要给摄像头用的,平时用不到,就分配给了其他app使用,现在摄像头突然要传输一个8M的图片,但是32M的区域里并没有一个连续的空间,怎么办呢?
MMU会在内存空间里疯狂的寻找空闲的页面,将原来分配给其他app的页面交换出去,让CMA的区域空闲下来,这里注意,这个交换只需要MMU 更改一下虚拟地址和物理地址的映射关系即可,CPU和程序员是感受不到这个变化的。这样的话,预留的内存就不会浪费掉了。
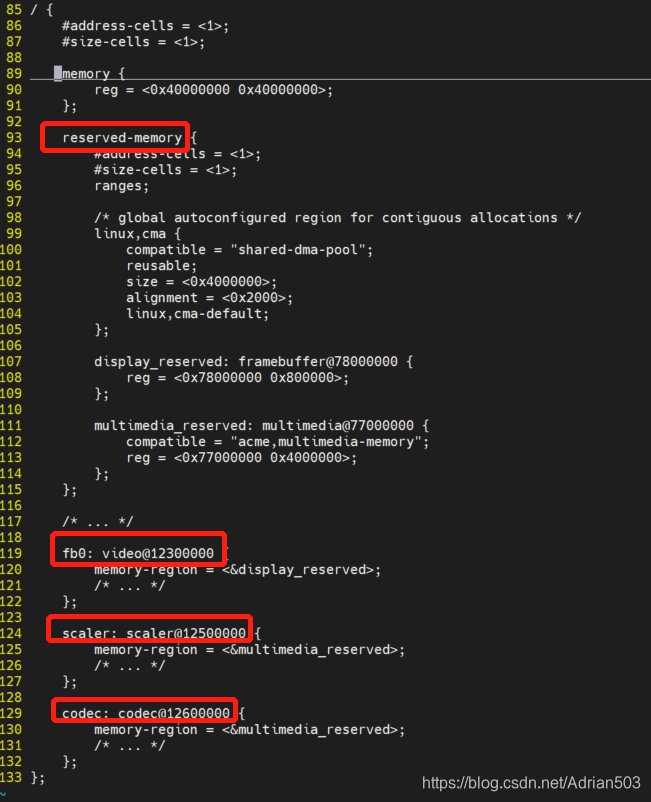
关于如何申请一个预留的CMA内存呢,可以参考 linux/Documentation/devicetree/bindings/reserved-memory
这里可以为一个单独的DMA设备,指定一块CMA区域,也可以几个DMA设备,公用一块CMA区域,都是可以在devicetree里配置的。
配置好了 dma_alloc_coherent 就会为你分配到这个区域
一定要读一下宋宝华老师的下面的文章,