1.1 系统内置函数
1.查看系统自带的函数
hive (default)> show functions;2.显示自带的函数的用法
hive (default)> desc function upper;3.详细显示自带的函数的用法
hive (default)> desc function extended upper;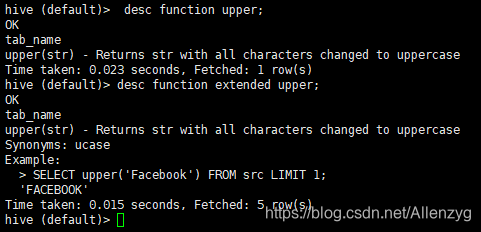
1.2 自定义函数
1)Hive 自带了一些函数,比如:max/min 等,但是数量有限(大概二、三百个),自己可以通过自定义 UDF来方便的扩展。
2)当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出
如 lateral view explore()
4)官方文档地址
HivePlugins - Apache Hive - Apache Software Foundation
5)编程步骤:
(1)继承 org.apache.hadoop.hive.ql.UDF
(2)需要实现 evaluate 函数;evaluate 函数支持重载;
(3)在 hive 的命令行窗口创建函数
a)添加 jar :add jar linux_jar_path
b)创建 function,
create [temporary] function [dbname.]function_name AS class_name;(4)在 hive 的命令行窗口删除函数
Drop [temporary] function [if exists] [dbname.]function_name;6)注意事项
UDF 必须要有返回类型,可以返回 null,但是返回类型不能为 void;
1.3 自定义 UDF 函数
案例一:大写字母变成小写字母
1.创建一个 Maven 工程 Hive
2.导入依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>3.创建一个类
package com.allen.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}4.打成 jar 包上传到服务器/opt/jar/udf.jar
使用rz命令或者winscp等其他工具上传到你想上传的目录即可
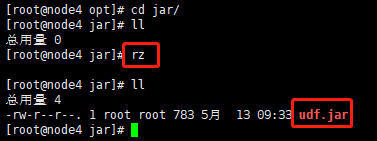
5.将 jar 包添加到 hive 的 classpath
hive (default)> add jar /opt/jar/udf.jar;6.创建临时函数与开发好的 java class 关联
hive (default)> create temporary function mylower as "com.allen.hive.Lower";7.即可在 hql 中使用自定义的函数 strip
hive (default)> select ename, mylower(ename) lowername from emp;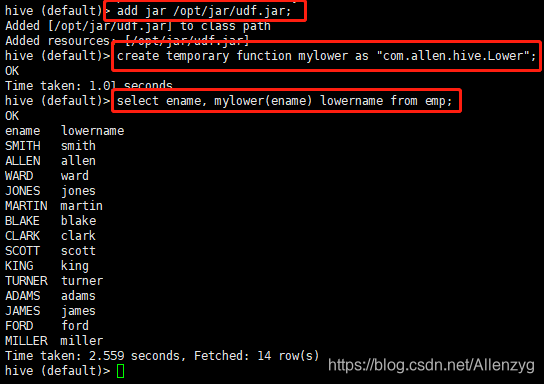
下面的案例就不再一一截图了,提供一下代码,有兴趣的可以自己实践。
案例二:修改数据类型使之成为想要的类型
package com.allen.hive;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import org.apache.hadoop.hive.ql.exec.UDF;
//1.定义一个类继承UDF,然后添加一个方法:evaluate,这个方法的参数和返回类型和函数的输入输出一致
//2.把项目打成jar包,然后放到hive的classPath下,或者在hive里面:add jar /opt/jar/myudf.jar
//3.在hive里面新建一个function然后指定到我们新建的类型:create function mydateparse as 'com.allen.hive.MyDateParser';
//4.使用方法:select mydateparser(time) from apache-log limit 10;
public class MyDataParser extends UDF{
//hive自定义函数,继承UDF类之后,还需要定义一个
//evaluate方法,这个方法的参数和hive函数接受的参数个数和数据类型一致
//方法的返回值和hive函数的返回值类型一致
//这里接受的参数,[29/April/2016:17:38:20 +0800]
//返回的结果:2016-4-28 20:40:39
public String evaluate(String s){
SimpleDateFormat format=new SimpleDateFormat("dd/MMMMM/yyyy:HH:mm:ss Z",Locale.ENGLISH);
if(s.indexOf("[")>-1){
s=s.replace("[", "");
}if(s.indexOf("]")>-1){
s=s.replace("]", "");
}
try {
//将输入的string转换成date数据类型
Date date=format.parse(s);
SimpleDateFormat rformat=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
return rformat.format(date);
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return "";
}
}
}步骤同案例一
案例三:把一个字段拆分成多个字段
package com.allen.hive;
import java.util.ArrayList;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyRequestParser extends GenericUDTF{
@Override
public StructObjectInspector initialize(ObjectInspector[] argIOs) throws UDFArgumentException {
if(argIOs.length!=1){
throw new UDFArgumentException("参数不正确");
}
ArrayList<String> filedNames=new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs=new ArrayList<ObjectInspector>();
filedNames.add("rool1");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
filedNames.add("rool2");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
filedNames.add("rool3");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//将返回字段设置到该UDTF的返回值类型中
return ObjectInspectorFactory.getStandardStructObjectInspector(filedNames, fieldOIs);
}
@Override
public void close() throws HiveException {
}
//process方法是我们处理函数的输入并且输出结果的过程定义方法
@Override
public void process(Object[] args) throws HiveException {
String input =args[0].toString();
//去掉两头的“"”,\是转义字符。即两头的“"”,用空来代替“”
input=input.replace("\"", "");
String[] result=input.split(" ");
//如果解析错误或失败,则返回三个字段的内容是“--”
if(result.length!=3){
result[0]="--";
result[1]="--";
result[2]="--";
}
forward(result);
}
}步骤同案例一
案例四:求和函数
package com.allen.hive;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;
public class MaxFlowUDAF extends UDAF {
public static class MaxNumberUDAFEvaluator implements UDAFEvaluator{
private IntWritable result;
public void init(){
result=null;
}
//聚合的多行中每行的被聚合的值都会被调用一次iterate方法,所以在这个方法里面我们来定义聚合规则
public boolean iterate(IntWritable value){
if(value==null){
return false;
}if(result==null){
result=new IntWritable(value.get());
}else{
//需求是求出流量最大值,在这里进行流量值的比较,将最大值放入result
result.set(Math.max(result.get(), value.get()));
}
return true;
}
//hive需要部分聚合结果时会调用该方法,返回当前的result作为hive取部分聚合值得结果
public IntWritable terminatePartial(){
return result;
}
//聚合值,新行未被处理的值会调用merge加入聚合,在这里直接调用上面定义的聚合规则方法iterate
public boolean merge(IntWritable other){
return iterate(other);
}
//hive需要最终聚合结果时调用的方法,返回最终结果
public IntWritable terminate(){
return result;
}
}
}步骤同案例一
案例五:排序TopN
package com.allen.hive;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
public class TopnUDAF extends UDAF{
public static class State{
ArrayList<Double> a;//保存topn的结果
int n;//调用该函数的topn的n
}
public static class Evaluator implements UDAFEvaluator{
private State state;
public Evaluator() {
init();
}
//初始化Evaluator对象
public void init() {
if(state==null){
state = new State();
}
state.a = new ArrayList<Double>();
state.n = 0;
}
/**
*map任务每行的值都会被调用一次iterate方法,iterate接收的参数正是调用函数时传入的参数
* @param o 聚合的字段值
* @param n topn的n
* @return
*/
public boolean iterate(Double o,int n){
//升降序topn表示,false表示最大值topn,true表示最小值topn
boolean ascending = false;
state.n = n;
if(o!=null){
//是否插入标志
boolean doInsert = state.a.size()<n;
//如果当前的state.a的元素数量大于或者等于n则需要插入操作
if(!doInsert){
Double last = state.a.get(state.a.size()-1);
if(ascending){
doInsert = o<last;
}else{
doInsert = o>last;
}
}
if(doInsert){
//有顺序的插入o的值
binaryInsert(state.a,o,ascending);
if(state.a.size()>n){
state.a.remove(state.a.size()-1);
}
}
}
return true;
}
//将value的值按照ascending的顺序插入到List中相应的位置处
static <T extends Comparable<T>> void binaryInsert(List<T> list,T value,boolean ascending){
//根据顺序获取value在list中的位置
int position = Collections.binarySearch(list, value,getComparator(ascending,(T)null));//!!!!
if(position<0){
position = (-position) - 1;
}
list.add(position, value);
}
//比较器方法
static <T extends Comparable<T>> Comparator<T> getComparator(boolean ascending,T dummy){
Comparator<T> comp;
if(ascending){
comp = new Comparator<T>(){
public int compare(T o1,T o2){
return o1.compareTo(o2);
}
};
}else{
comp = new Comparator<T>(){
public int compare(T o1,T o2){
return o2.compareTo(o1);
}
};
}
return comp;
}
//一个map端执行结束后的输出值,这个值会被送到merge去合并
public State terminatePartial(){
if(state.a.size()>0){
return state;
}else{
return null;
}
}
/**
* reduce端,将map端的输出结果,即terminatePartial的返回值,进行合并操作
* 有多少个map端,reduce将会调用多少次merge方法
* @param o 本次merge合并需要处理的map端terminatePartial方法返回的state对象
* @return
*/
public boolean merge(State o){
//升降序topn表示,false表示最大值topn,true表示最小值topn
boolean ascending = false;
if(o!=null){
state.n = o.n;
state.a = sortedMerge(o.a,state.a,ascending,o.n);
}
return true;
}
static <T extends Comparable<T>> ArrayList<T> sortedMerge(List<T> a1,List<T> a2,boolean ascending,int n){
Comparator<T> comparator = getComparator(ascending,(T)null);
int n1 = a1.size();
int n2 = a2.size();
int p1 = 0;//当前a1的元素
int p2 = 0;//当前a2的元素
//保存结果list,有n个元素
ArrayList<T> output = new ArrayList<T>(n);
//遍历并将a1和a2合并到output中,合并过程中保证output最多有n个元素
while(output.size()<n && (p1<n1 || p2<n2)){
if(p1<n1){
if(p2==n2||comparator.compare(a1.get(p1), a2.get(p2))<0){
output.add(a1.get(p1++));
}
}
if(output.size()==n){
break;
}
if(p2<n2){
if(p1==n1||comparator.compare(a2.get(p2), a1.get(p1))<0){
output.add(a2.get(p2++));
}
}
}
return output;
}
public ArrayList<Double> terminate(){
if(state.a.size()>0){
return state.a;
}else{
return null;
}
}
}
}步骤同案例一
附加:pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.allen.hive</groupId>
<artifactId>Hive_Test</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-contrib -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-contrib</artifactId>
<version>2.1.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-jdbc -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency>
</dependencies>
</project>1.4 IDEA连接Hive,执行select简单测试
package com.allen.hive;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class HiveTest {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.hive.jdbc.HiveDriver");
Connection conn=DriverManager.getConnection("jdbc:hive2://node4:10000","root","123qwe");
try{
Statement st=conn.createStatement();
ResultSet ret=st.executeQuery("select count(*) from log_table");
if(ret.next()){
System.out.println(ret.getInt(1));
}
}catch(Exception e){
e.printStackTrace();
}finally{
conn.close();
}
}
}因为使用的是hive2,所以要在CLI先使用命令hiveserver2启动10000端口,再执行程序,不然会报错:拒绝连接
结果如下:
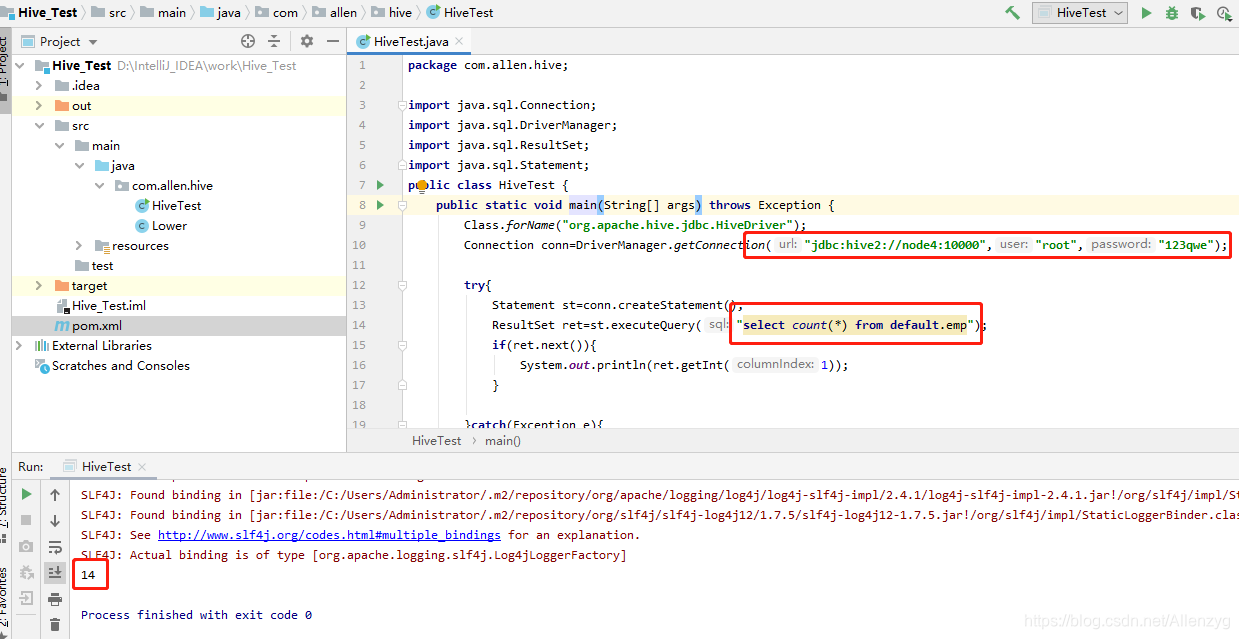
与CLI执行结果一致:
执行程序时遇到的问题:
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
原因:log4j2的配置文件没有导入
解决办法:
尝试导入log4j.properties ,但并不行
需要导入log4j2.xml
在你项目的src下的resources下新建log4j2.xml,eclipse和IDEA会把其配置到WEB-INF的classes下
log4j2的配置
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="STDOUT" target="SYSTEM_OUT">
<PatternLayout pattern="%d %-5p [%t] %C{2} (%F:%L) - %m%n"/>
</Console>
<RollingFile name="RollingFile" fileName="logs/strutslog1.log"
filePattern="logs/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout>
<Pattern>%d{MM-dd-yyyy} %p %c{1.} [%t] -%M-%L- %m%n</Pattern>
</PatternLayout>
<Policies>
<TimeBasedTriggeringPolicy />
<SizeBasedTriggeringPolicy size="1 KB"/>
</Policies>
<DefaultRolloverStrategy fileIndex="max" max="2"/>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="com.opensymphony.xwork2" level="WAN"/>
<Logger name="org.apache.struts2" level="WAN"/>
<Root level="warn">
<AppenderRef ref="STDOUT"/>
</Root>
</Loggers>
</Configuration>