第五章 Kubernetes调度
1、创建一个Pod的工作流程
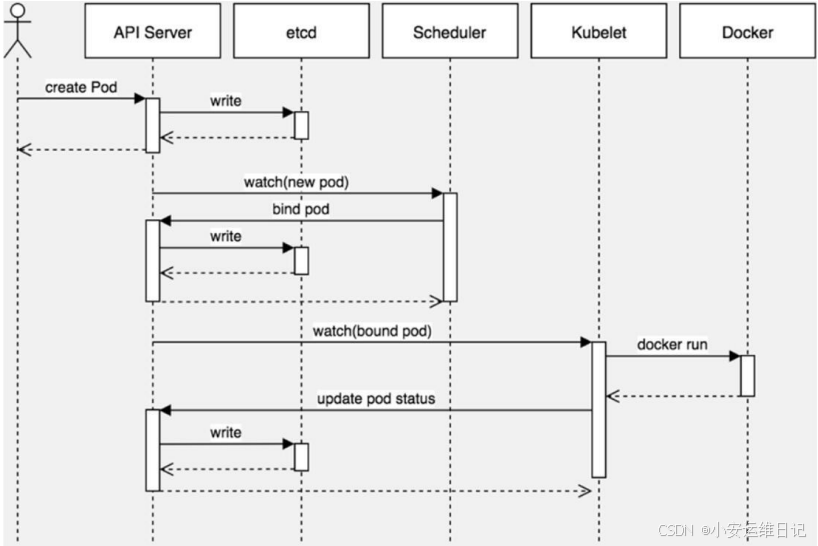
Kubernetes基于 list-watch 机制的控制器架构,实现组件间交互 的解耦。
其他组件监控自己负责的资源,当这些资源发生变化时,kube-apiserver会通知这些组件,这个过程类似于发布与订阅。
工作流程详解:
① 首先用户通过 Kubectl 提交创建 Pod 的 Yaml 的文件,向Kubernetes 系统发起资源请求,该资源请求被提交到 Kubernetes 系统中,由 APIServer 负责接收客户端发送的“POST” 创建 Pod 请求。
② APIServer 接收到请求后把创建 Pod 的信息存储到 Etcd 中,从集群运行那一刻起,资源调度系统 Scheduler 就会定时去监控 APIServer。
③ 通过 APIServer 得到创建 Pod 的信息,Scheduler 采用 watch 机制,一旦 Etcd 存储 Pod 信息成功便会立即通知 APIServer,APIServer会立即把Pod创建的消息通知Scheduler,Scheduler发现 Pod 的属性中 Dest Node 为空时(Dest Node=””)便会立即触发调度流程进行调度。而这一个创建Pod对象,在调度的过程当中有3个阶段:节点预选、节点优选、节点选定,从而筛选出最佳的节点
- 节点预选:基于一系列的预选规则对每个节点进行检查,将那些不符合条件的节点过滤,从而完成节点的预选
- 节点优选:对预选出的节点进行优先级排序,以便选出最合适运行Pod对象的节点
- 节点选定:从优先级排序结果中挑选出优先级最高的节点运行Pod,当这类节点多于1个时,则进行随机选择
2、Pod中影响调度的主要属性
① 资源请求和限制(resources):
定义了 CPU 和内存的请求和限制,确保调度器能够根据资源需求选择合适的节点。
② 节点选择器(nodeSelector):
指定了 Pod 应该调度到带有 disktype=ssd 标签的节点上。
③ Pod 反亲和性(podAntiAffinity):
定义了 Pod 应该尽量避免调度到同一个节点上的其他相同标签的 Pod,以提高可用性。
④ 污点容忍(tolerations):
定义了 Pod 可以容忍带有特定污点的节点,允许 Pod 调度到这些节点上。
YAML示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
namespace: default
spec:
...
containers:
- image: lizhenliang/java
-demo
name: java
-demo
imagePullPolicy: Always
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 20
tcpSocket:
port: 8080
resources: {} //资源调度依据
restartPolicy: Always
## 调度策略
schedulerName: default-scheduler //调度器
nodeName: ""
nodeSelector: {} //标签选择器
affinity: {} //亲和性
tolerations: [] //污点容忍3、资源限制对Pod调度的影响
1)容器资源限制:
- resources.limits.cpu
- resources.limits.memory
2)容器使用的最小资源需求,作为容器调度时资源分配的依据:
- resources.requests.cpu
- resources.requests.memory
K8s会根据Request的值去查找有足够资源的Node来调度此Pod
补充:CPU单位:可以写m(毫核)也可以写浮点数,例如0.5=500m,1=1000m
例如:
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: web
image: nginx
resources:
requests:
memory: "64Mi"
срu: "250m"
limits:
memory: "128Mi"
cpu: "500m"备注:可以通过查看节点的详细描述,来得知是否还有资源可供分配
[root@k8s-master-1-71 ~]# kubectl describe node
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 350m (8%) 0 (0%)
memory 200Mi (11%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
...总结:
- 容器资源请求值(requests) :告诉k8s最小分配的资源,分配的节点必须能够满足requests指定的值;否则将无法进行正常调度;
- 容器资源限制值(limits) :允许最大的使用资源;
- requests 必须小于 limits, 建议一个理论值:requests值小于limits的20%-30%
- limits 尽量不要超过所分配宿主机物理配置的80%,否则没有限制意义
- 每个节点都有可分配的资源,k8s抽象的将这些节点资源统一分配(划分为资源池)
- requests 只是一个预留性质的资源,并非实际的占用,用于k8s合理的分配资源
- requests 会影响pod调度,k8s只能将pod分配到能满足该requests值的节点上
- 容器资源访问并发太大,不应该是去提升 limits,而是通过扩展Pod去提高并发
4、nodeSelector & nodeAffinity
4.1 nodeSelector
用于将Pod调度到匹配 Label 的Node上,如果没有匹配的标签会调度失败。
备注:指定的节点标签,没有节点匹配,Pod的状态会处于Pending,如后续有节点满足,Pod则会运行。
作用:
- 约束Pod到特定的节点运行
- 完全匹配节点标签
应用场景:
- 专用节点:根据业务线将Node分组管理
- 配备特殊硬件:部分Node配有SSD硬盘、GPU
示例:确保Pod分配到具有SSD硬盘的节点上
第一步:给节点添加标签(标准的作用仅仅是声明标记,不用也不会影响)
- 添加Label,命令:kubectl label node =
- 删除Label,命令:kubectl label node -
- 查看Label,命令:kubectl get node/pod/deploy --show-labels
[root@k8s-master-1-71 ~]# kubectl label node k8s-node1-1-72 disktype=ssd
[root@k8s-master-1-71 ~]# kubectl get node k8s-node1-1-72 --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s-node1-1-72 Ready <none> 17d v1.26.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s-node1-1-72,kubernetes.io/os=linux
第二步:添加nodeSelector字段到Pod配置中
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
nodeSelector:
disktype: ssd
containers:
- name: nginx
image: nginx验证:
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-pod-6fbc98b678-42m29 1/1 Running 0 59m 10.244.114.54 k8s-node2-1-73 <none> <none>
test-pod 0/1 ContainerCreating 0 13s <none> k8s-node1-1-72 <none> <none>
删除节点标签:
[root@k8s-master-1-71 ~]# kubectl label node k8s-node1-1-72 disktype-
补充:如果有多个节点匹配,将参考其它的策略从节点中选择一个进行调度。
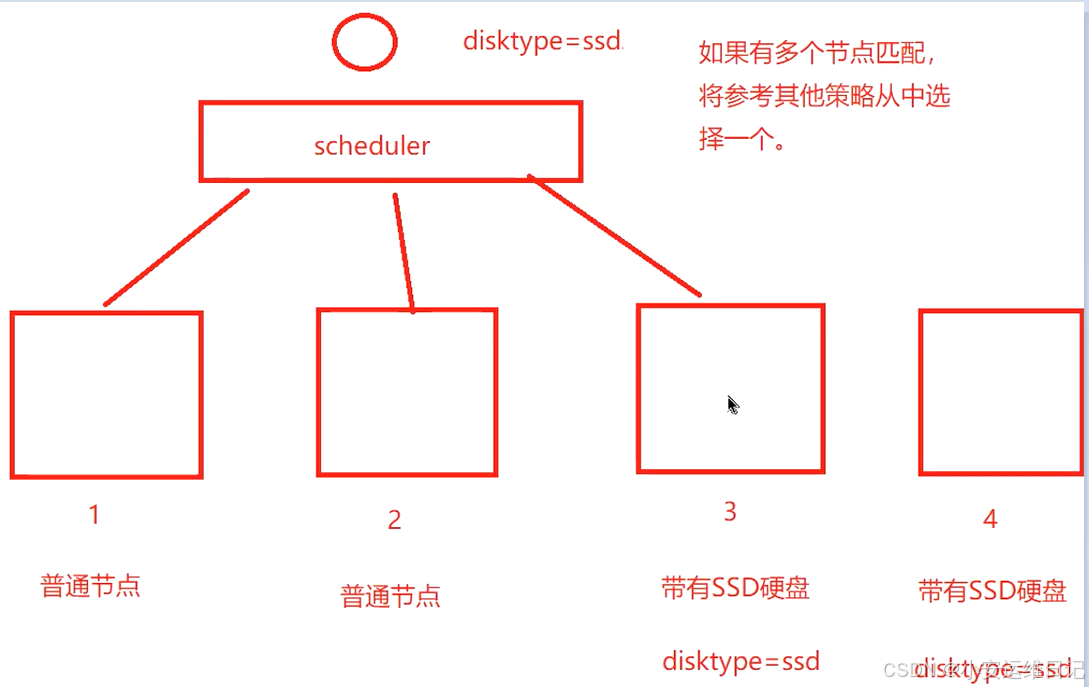
补充:指定的节点标签,没有节点可匹配,Pod将处于Pending状态,但如果后续有节点满足标签需求,调度器监听后,则Pod会重新调度并运行。
4.2 nodeAffinity
节点亲和 类似于nodeSelector,可以根据节点上 的标签来约束Pod可以调度到哪些节点。
相比nodeSelector:
① 匹配有更多的逻辑组合,不只是字符串的完全相等,支持的操作 符有:In、NotIn、Exists、DoesNotExist、Gt、Lt
② 调度分为软策略和硬策略,而不是硬性要求
- 硬(required):必须满足
- 软(preferred):尝试满足,但不保证
选项:weight: 1 // 权重值1-100,分数高则被分配到几率大
required(硬策略)配置示例:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginxpreferred(软策略)配置示例:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd
containers:
- name: nginx
image: nginx两种策略可以写在1个Pod中,但建议1个Pod一种策略,其次两种策略类似取其并集。
示例:required硬策略 和 preferred软策略 对比
# 设置节点标签为 disktype=ssd
[root@k8s-master-1-71 ~]# kubectl label node k8s-node1-1-72 disktype=ssd
# 设置required硬策略
[root@k8s-master-1-71 ~]# kubectl apply -f required-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: required-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disktype
operator: In
values:
- ssd2 //设置ssd2
containers:
- name: nginx
image: nginx
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
required-pod 0/1 Pending 0 109s <none> <none> <none> <none>
# 设置preferred软策略
[root@k8s-master-1-71 ~]# kubectl apply -f preferred-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: preferred-pod
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: disktype
operator: In
values:
- ssd2
containers:
- name: nginx
image: nginx
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
preferred-pod 1/1 Running 0 84s 10.244.114.55 k8s-node2-1-73 <none> <none>结论:硬策略类似于nodeSelector,硬性要求标签匹配,而软策略会尝试满足,但不保证匹配,所以在以上测试中,preferred帮忙调度到了节点并运行了
5、Taints(污点) & Tolerations(污点容忍)
基于节点标签分配是站在Pod的角度上,通过在Pod上添加属性,来确定Pod是否要调度到指定的Node上,其实也可以站在 Node的角度上,通过在Node上添加污点属性,来避免Pod被分配到不合适的节点上。
- Taints污点:避免Pod调度到特定Node上
- Tolerations污点容忍:允许Pod调度到持有Taints的Node上
备注:Master节点默认打了Taints污点,任何Pod都不会参与调度到Master,一是提高安全性,二是专门跑Master组件使用提高稳定性。
第一步:给节点添加污点
- 添加污点,命令:kubectl taint node [node] key=value:[effect]
- 删除污点,命令:kubectl taint node [node] key:[effect]-
- 查看污点,命令:kubectl describe node [node] |grep Taints
其中 [effect] 可取值:
- NoSchedule :一定不能被调度
- PreferNoSchedule:尽量不要调度,非必须配置容忍
- NoExecute:不仅不会调度,还会驱逐Node上已有的Pod
kubectl taint node k8s-node1 gpu=yes:NoSchedule
kubectl describe node k8s-node1 |grep Taints第二步:如果希望Pod可以被分配到带有污点的节点上,要在Pod配置 中添加污点容忍(tolrations)字段
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: test
image: busybox
tolerations:
- key: "gpu" //容忍的Key
operator: "Equal" //等于
value: "yes" //容忍的value
effect: "NoSchedule" //容忍的effect值删除污点:
kubectl taint node [node] key:[effect]-示例1:污点测试
# 给节点2 添加污点
[root@k8s-master-1-71 ~]# kubectl taint node k8s-node1-1-72 gpu=yes:NoSchedule
[root@k8s-master-1-71 ~]# kubectl describe node k8s-node1-1-72 | grep Taint
Taints: gpu=yes:NoSchedule
[root@k8s-master-1-71 ~]# kubectl run nginx-test --image=nginx
[root@k8s-master-1-71 ~]# kubectl run nginx-test2 --image=nginx
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-test 0/1 ContainerCreating 0 16s <none> k8s-node2-1-73 <none> <none>
nginx-test2 0/1 ContainerCreating 0 3s <none> k8s-node2-1-73 <none> <none>
## 解释:由于节点2添加了污点,调度器无论怎么调度,都不会把Pod放在节点2上
# 再给节点2 添加污点
[root@k8s-master-1-71 ~]# kubectl taint node k8s-node2-1-73 gpu=yes:NoSchedule
[root@k8s-master-1-71 ~]# kubectl describe node | grep Taint
Taints: node-role.kubernetes.io/control-plane:NoSchedule
Taints: gpu=yes:NoSchedule
Taints: gpu=yes:NoSchedule
[root@k8s-master-1-71 ~]# kubectl run nginx-test3 --image=nginx
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
...
nginx-test3 0/1 Pending 0 3s <none> <none> <none> <none>
## 解释:由于节点2和节点3都添加了污点,新的Pod将没有可调度节点,状态为Pending# 在Pod中设置污点容忍
[root@k8s-master-1-71 ~]# kubectl get pods nginx-test3 -o yaml > nginx-test3.yaml
[root@k8s-master-1-71 ~]# kubectl apply -f nginx-test3.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: nginx-test3
name: nginx-test3
spec:
containers:
- image: nginx
name: nginx-test3
tolerations:
- key: "gpu"
operator: "Equal"
value: "yes"
effect: "NoSchedule"
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
...
nginx-test3 1/1 Running 0 5m15s 10.244.117.36 k8s-node1-1-72 <none> <none>
# 解释:添加污点容忍后,即可实现将Pod根据容忍的污点值调度到节点上
删除节点上的污点
[root@k8s-master-1-71 ~]# kubectl taint node k8s-node1-1-72 gpu:NoSchedule-
[root@k8s-master-1-71 ~]# kubectl taint node k8s-node2-1-73 gpu:NoSchedule-思考:为什么调度器在分配节点时,不会将Pod调度到Master节点上?
# vi calico.yaml
tolerations:
# Make sure calico-node gets scheduled on all nodes.
- effect: NoSchedule
operator: Exists
# Mark the pod as a critical add-on for rescheduling.
- key: CriticalAddonsOnly
operator: Exists
- effect: NoExecute
operator: Exists因Master节点也有污点,所以正常情况下无法进行普通Pod的调度,而在 calico.yaml 部署文件中,设置了污点容忍,所以该类型的Pod才能进行分配
# 测试
[root@k8s-master-1-71 ~]# kubectl apply -f nginx-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
tolerations:
- operator: "Exists"
effect: "NoSchedule"
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 2m13s 10.244.76.8 k8s-master-1-71 <none> <none>
补充:在节点2添加污点,将 [effect] 值设置成NoExecute,原节点2上的所有未做容忍机器全部驱逐
[root@k8s-master-1-71 ~]# kubectl taint node k8s-node1-1-72 gpu=yes:NoExecute
node/k8s-node1-1-72 tainted
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
...
nginx-tes1 1/1 Terminating 0 11m 10.244.117.37 k8s-node1-1-72 <none> <none>
nginx-tes2 1/1 Terminating 0 11m 10.244.117.41 k8s-node1-1-72 <none> <none>
nginx-test 1/1 Terminating 0 11m 10.244.117.40 k8s-node1-1-72 <none> <none>
nginx-test2 1/1 Terminating 0 11m 10.244.117.39 k8s-node1-1-72 <none> <none>
6、nodeName
nodeName:指定节点名称,用于将Pod调度到指定的Node上,不经过调度器。
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
nodeName: node节点名称
containers:
- name: web
image: nginx
注意:不经过调度器,即使节点上有污点,都能直接调度过去
[root@k8s-master-1-71 ~]# kubectl apply -f nginx.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
nodeName: k8s-master-1-71
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 9s 10.244.76.9 k8s-master-1-71 <none> <none>
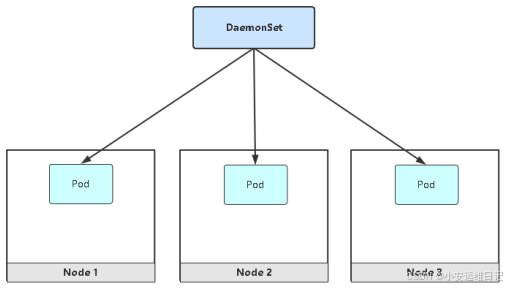
7、DaemonSet控制器
DaemonSet功能:
- 在每一个Node上都会运行一个Pod
- 新加入的Node也同样会自动运行一个Pod
应用场景:网络插件、监控Agent、日志Agent
补充:
- DaemonSet的Pod名称:daemonset名字-随机字符串
- Deployment的Pod名称:deployment名字-RS名称-随机字符串
DaemonSet配置示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
spec:
selector:
matchLabels:
name: filebeat
template:
metadata:
labels:
name: filebeat
spec:
containers:
- name: log
image: elastic/filebeat:7.3.2示例:
[root@k8s-master-1-71 ~]# kubectl apply -f daemonset-web.yaml
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: web
spec:
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
[root@k8s-master-1-71 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
web-jq859 1/1 Running 0 3m11s 10.244.117.43 k8s-node1-1-72 <none> <none>
web-vr67b 1/1 Running 0 3m11s 10.244.117.42 k8s-node2-1-73 <none> <none>
注意:DaemonSet是会经过调度器,会受节点污点影响
# 可在配置中添加污点容忍
tolerations:
- operator: "Exists"
effect: "NoSchedule"删除DaemonSet
[root@k8s-master-1-71 ~]# kubectl delete -f daemonset-web.yaml
8、调度失败原因分析
查看调度结果:
kubectl get pod <NAME> -o wide查看调度失败原因:kubectl describe pod name
- 节点CPU / 内存不足。例如:requests设置过大,node节点无法满足导致无法调度
- 有污点Taint,没容忍tolerations。例如:node节点有污点,pod没有容忍则无法调度
- 没有匹配到节点标签。例如:指定了NodeSelector,但是node没有该标签
课后作业
1、创建一个pod,分配到指定标签node上
- pod名称:web
- 镜像:nginx
- node标签:disk=ssd
2、确保在每个节点上运行一个pod
- pod名称:nginx
- 镜像:nginx
3、查看集群中状态为ready的node数量,并将结果写到指定文件 /opt/test.txt
小结:
本篇为 【Kubernetes CKA认证 Day5】的学习笔记,希望这篇笔记可以让您初步了解到 Pod的工作流程、资源限制对Pod调度的影响、nodeSelector 和 nodeAffinity等;课后还有扩展实践,不妨跟着我的笔记步伐亲自实践一下吧!
Tip:毕竟两个人的智慧大于一个人的智慧,如果你不理解本章节的内容或需要相关笔记、视频,可私信小安,请不要害羞和回避,可以向他人请教,花点时间直到你真正的理解。