1. 名词解释
FFN
- FFN : Feedforward Neural Network,前馈神经网络
- 馈神经网络是一种基本的神经网络架构,也称为多层感知器(Multilayer Perceptron,MLP)
- FFN 一般主要是包括多个全连接层(FC)的网络,其中,全连接层间可以包含 : 激活层、BN层、Dropout 层。
MLP 与 FFN 的区别
在机器学习和深度学习中,MLP(多层感知机)和 FFN(前馈神经网络)在很大程度上可以视为同义词,都指代了一个具有多个层的前馈神经网络结构。
- MLP(多层感知机)更偏向于表达网络结构(多个全连接层)
- FFN(前馈神经网络)更偏向于表达数据以前馈的方式流动
MLP 和 FFN 通常指的是只包含全连接层 和激活函数的神经网络结构。这两者都是基本的前馈神经网络类型,没有包含卷积层或其他复杂的结构。
Logit
“Logit” 通常指的是神经网络中最后一个隐藏层的输出,经过激活函数之前的值。比如:
- 对于二分类问题,logit 是指网络输出的未经过 sigmoid 函数处理的值
- 对于多分类问题,logit 是指网络输出的未经过 softmax 函数处理的值
NLL
NLL 是 Negative Log-Likelihood(负对数似然)的缩写。
在深度学习中,特别是在分类问题中,NLL 经常与交叉熵损失(Cross-Entropy Loss)等价使用。
Anchor Box 与 Anchor Point
- Anchor box 通常表示 一个包含位置和大小信息的四元组 ( x , y , w , h ) (x, y, w, h) (x,y,w,h),而 Anchor point 通常表示 一个二元组 ( x , y ) (x, y) (x,y)。 其中, x x x和 y y y表示框的中心坐标, w w w 和 h h h表示框的宽度和高度。
- Anchor box 是目标检测中用于定义目标位置和大小的一种方式。而 Anchor point 主要用于在图像上生成 anchor box 的位置,生成的 anchor box 会在 anchor point 的周围不同尺寸和宽高比的情况下进行缩放,形成一系列不同形状的框。
parameter efficient
参数效率高,指的是网络在达到良好性能的同时所使用的参数数量较少。
Deep Supervision
Deep Supervision 是一种训练策略,旨在提高网络的梯度流动,并促使网络更快地收敛,并且有助于缓解梯度消失问题。Deep Supervision 的核心思想是在网络的不同层中引入额外的监督信号,而不仅仅在最后一层输出进行监督训练。具体来说:Deep Supervision 会使用网络的中间层输出,计算出一部分损失函数,然后和网络最后一层的损失函数一起,对网络的参数进行优化。
DP 与 DDP
DP : DataParallel,数据并行
DDP :Distributed Data Parallel,分布式数据并行
感受野(Receptive Field)
1、介绍
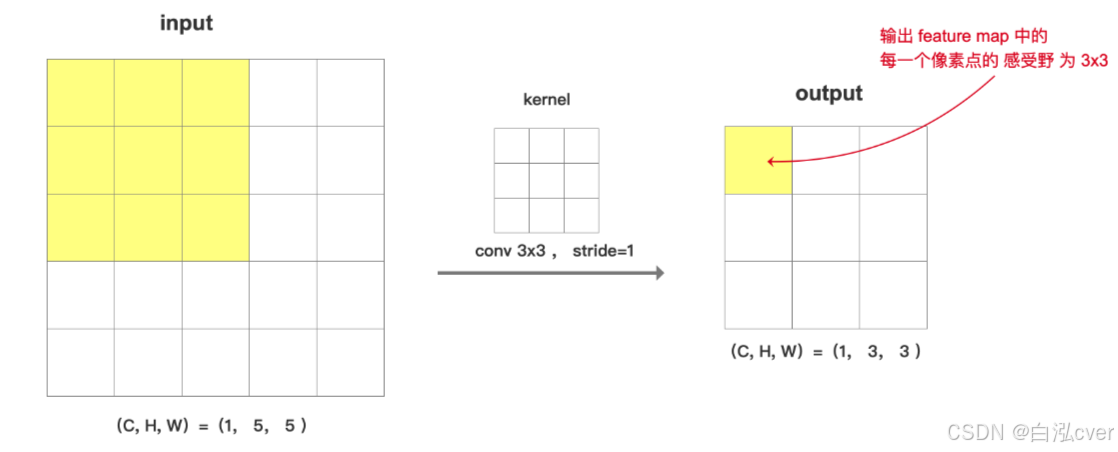
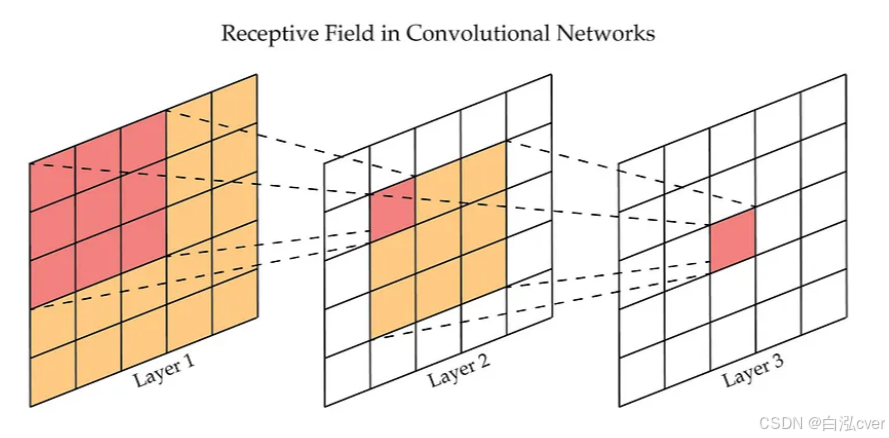
感受野(receptive field)是卷积神经网络输出特征图上的像素点在原始图像上所能看到的(映射的)区域的大小,它决定了该像素对输入图像的感知范围(获取信息的范围)。较小的感受野可以捕捉到更细节的特征,而较大的感受野可以捕捉到更全局的特征。
如果连续进行 2次卷积操作,卷积核大小都为 3x3,stride=1, padding=0, 如下图,layer3上的每一个像素点在 layer1上的感受野 为 5x5
2、感受野计算公式
感受野计公式 :
F
(
i
)
=
(
F
(
i
+
1
)
−
1
)
×
S
t
r
i
d
e
+
K
s
i
z
e
F(i)=(F(i+1)-1)\times Stride + Ksize
F(i)=(F(i+1)−1)×Stride+Ksize 或
F
i
n
=
(
F
o
u
t
−
1
)
×
S
t
r
i
d
e
+
K
s
i
z
e
F_{in}=(F_{out}-1)\times Stride + Ksize
Fin=(Fout−1)×Stride+Ksize
其中:
- F ( i ) F(i) F(i) :在第 i i i层的感受野
- S t r i d e Stride Stride:第 i i i层步距
- K s i z e Ksize Ksize:第 i i i层卷积或池化的 kernel size
3、计算举例
求 :layer3 上的每个像素在 layer1 上的感受野。
1)先来计算 layer3 上的一个像素(
F
(
3
)
=
1
F(3)=1
F(3)=1)在 layer2 上的感受野 :
F
(
2
)
=
(
F
(
3
)
−
1
)
×
S
t
r
i
d
e
+
K
s
i
z
e
=
(
1
−
1
)
×
2
+
2
=
2
F(2) = (F(3)-1) \times Stride + Ksize = (1 -1) \times 2 + 2 = 2
F(2)=(F(3)−1)×Stride+Ksize=(1−1)×2+2=2
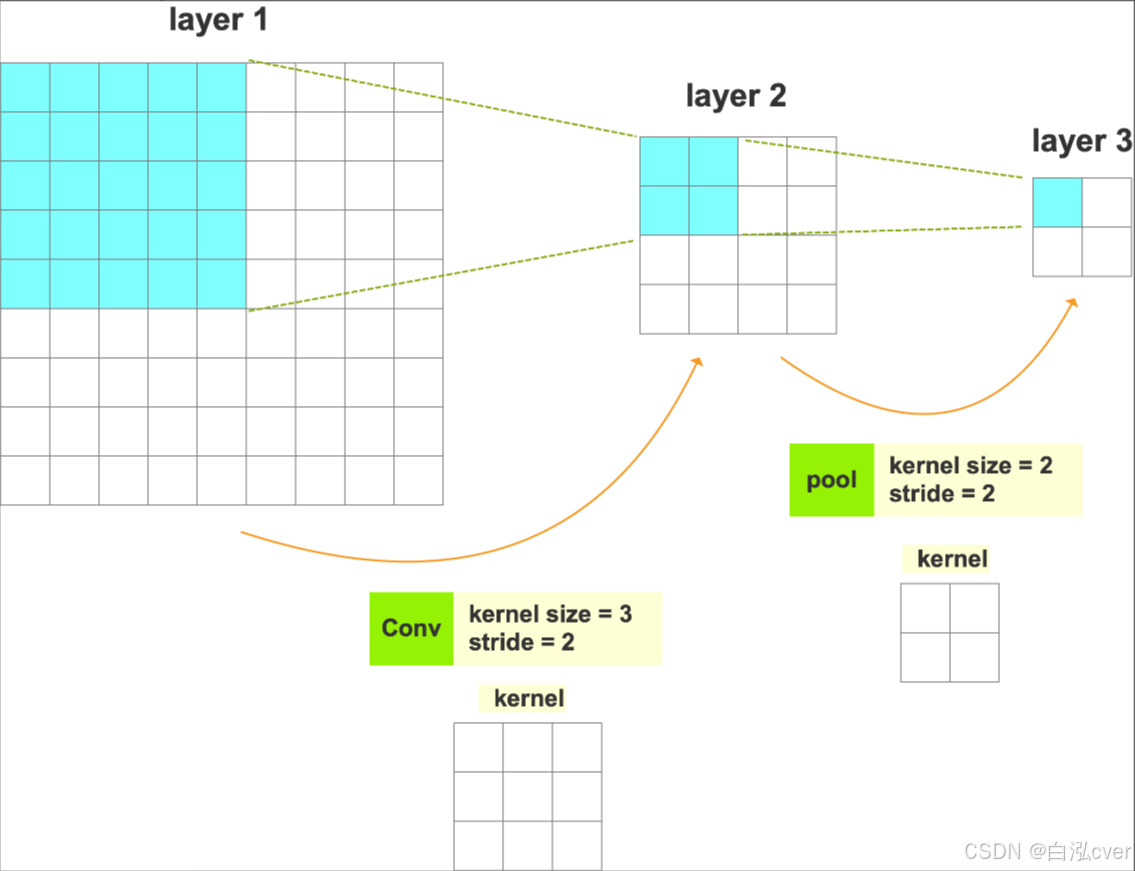
2)计算 layer3 上的一个像素(
F
(
3
)
=
1
,
F
(
2
)
=
2
F(3)=1, \; F(2)=2
F(3)=1,F(2)=2 )在 layer1 上的感受野 :
F
(
1
)
=
(
F
(
2
)
−
1
)
×
S
t
r
i
d
e
+
K
s
i
z
e
=
(
2
−
1
)
×
2
+
3
=
5
F(1)=(F(2)-1)\times Stride + Ksize =(2 -1)\times 2 + 3 = 5
F(1)=(F(2)−1)×Stride+Ksize=(2−1)×2+3=5
如果仅计算 layer2 上的一个像素( F(2)=1 )在 layer1 上的感受野 :
F
(
1
)
=
(
F
(
2
)
−
1
)
×
S
t
r
i
d
e
+
K
s
i
z
e
=
(
1
−
1
)
×
2
+
3
=
3
F(1)=(F(2)-1)\times Stride + Ksize = (1 -1)\times 2 + 3 = 3
F(1)=(F(2)−1)×Stride+Ksize=(1−1)×2+3=3
2. tensor 相关
tensor 内部存储结构
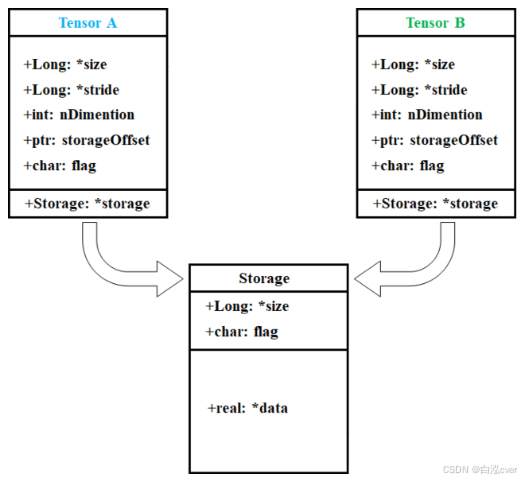
1、数据区域和元数据
PyTorch 中的 tensor 内部结构通常包含了 数据区域(Storage) 和 元数据(Metadata) :
- 数据区域 : 存储了 tensor 的实际数据,且数据被保存为连续的数组。比如: a = torch.tensor([[1, 2, 3], [4, 5, 6]]),它的数据在存储区的保存形式为 [1, 2, 3, 4, 5, 6]
- 元数据 :包含了 tensor 的一些描述性信息,比如 : 尺寸(Size)、步长(Stride)、数据类型(Data Type) 等信息
占用内存的主要是 数据区域,且取决于 tensor 中元素的个数, 而元数据占用内存较少。
采用这种 【数据区域 + 元数据】 的数据存储方式,主要是因为深度学习的数据动辄成千上万,数据量巨大,所以采取这样的存储方式以节省内存
2、查看 tensor 的存储区数据: storage()
虽然 .storage() 方法即将被弃用,而是改用 .untyped_storage(),但为了笔记中展示方便,我们仍然使用 .storage() 方法。.untyped_storage() 方法的输出太长了,不方便截图放在笔记中。
a = torch.tensor([[1, 2, 3],
[4, 5, 6]])
print(a.storage())

3、查看 tensor 的步长: stride()
stride() : 在指定维度 (dim) 上,存储区中的数据元素,从一个元素跳到下一个元素所必须的步长
a = torch.randn(3, 2)
print(a.stride()) # (2, 1)
解读:
在第 0 维,想要从一个元素跳到下一个元素,比如从 a[0][0] 到 a[1][0] ,需要经过 2个元素,步长是 2
在第 1 维,想要从一个元素跳到下一个元素,比如从 a[0][0] 到 a[0][1], 需要经过 1个元素,步长是 1

4、查看 tensor 的偏移量:storage_offset()
表示 tensor 的第 0 个元素与真实存储区的第 0 个元素的偏移量
a = torch.tensor([1, 2, 3, 4, 5])
b = a[1:] # tensor([2, 3, 4, 5])
c = a[3:] # tensor([4, 5])
print(b.storage_offset()) # 1
print(c.storage_offset()) # 3
- b 的第 0 个元素与 a 的第 0 个元素之间的偏移量是 1
- c 的第 0 个元素与 a 的第 0 个元素之间的偏移量是 3
5、代码举例
-
一般来说,一个 tensor 有着与之对应的 storage, storage 是在 data 之上封装的接口。
-
不同 tensor 的元数据一般不同,但却可能使用相同的 storage。
-
data_ptr():- 返回的是张量数据 (storage 数据)存储的实际内存地址,确切来说是张量数据的起始内存地址。
- data_ptr 中的 ptr 是 pointer(指针)的缩写,对应于 C 语言中的指针,因为 Python 的底层就是由 C 实现的
-
id(a):- 返回的是 a 在 Python 内存管理系统中的唯一标识符。虽然这个标识符通常与对象的内存地址有关,但它并不直接表示内存地址。
1)观察一
import torch
a = torch.arange(0, 6)
print('a = {}\n'.format(a))
print('tensor a 存储区的数据内容 :{}\n'.format(a.storage()))
print('tensor a 相对于存储区数据的偏移量 :{}\n'.format(a.storage_offset()))
print('*'*20, '\n')
b = a.view(2,3)
print('b = {}\n'.format(b))
print('tensor b 存储区的数据内容 :{}\n'.format(b.storage()))
print('tensor b 相对于存储区数据的偏移量 :{}\n'.format(b.storage_offset()))
2)观察二
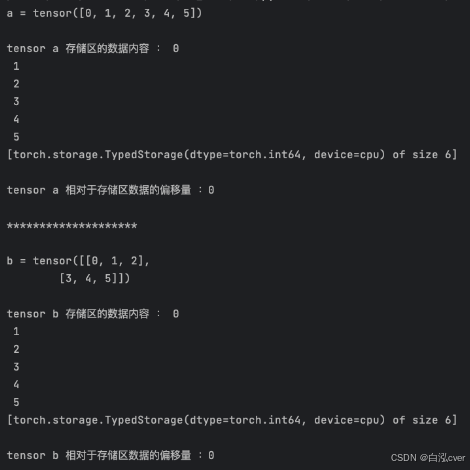
import torch
a = torch.tensor([1, 2, 3, 4, 5, 6])
b = a.view(2, 3)
print(a.data_ptr()) # 140623757700864
print(b.data_ptr()) # 140623757700864
print(id(a)) # 4523755392
print(id(b)) # 4602540464
a.data_ptr()与b.data_ptr()一样,说明 tensor a 和 tensor b 共享相同的存储区,即,它们指向相同的底层数据存储对象。id(a)和id(b)不一样,是因为虽然 a 和b 共享storage 数据,但是 它们 有不同的 size 或者 strides 、 storage_offset 等其他属性
3)观察三
import torch
a = torch.tensor([1, 2, 3, 4, 5, 6])
c = a[2:]
print(c.storage())
print('\n', '*'*20, '\n')
print('tensor a 首元素的内存地址 : {}'.format(a.data_ptr()))
print('tensor c 首元素的内存地址 : {}'.format(c.data_ptr()))
print(c.data_ptr() - a.data_ptr())
print('\n', '*'*20, '\n')
c[0] = -100
print(a)
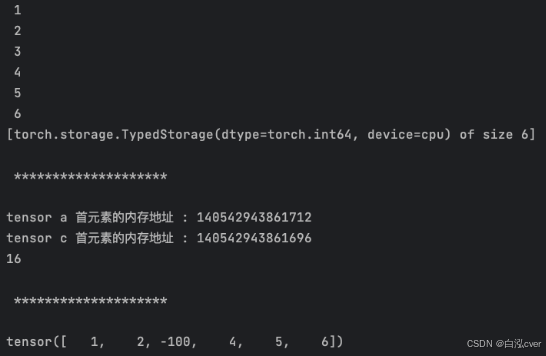
data_ptr()返回 tensor 首元素的内存地址- c 和 a 的首元素内存地址相差 16,每个元素占用 8 个字节(LongStorage), 也就是首元素相差两个元素
- 改变 c 的首元素, a 对应位置的元素值也被改变
6、总结
- 由上可知,绝大多数操作并不修改 tensor 的数据,只是修改了 tensor 的元数据,比如修改 tensor 的 offset 、stride 和 size ,这种做法更节省内存,同时提升了处理速度。
- 有些操作会导致 tensor 不连续,这时需要调用 torch.contiguous 方法将其变成连续的数据,该方法会复制数据到新的内存,不再与原来的数据共享 storage。