1、String 编译期间的优化
String a = "a" + "b" +"1";
String b = "ab1";
a == b 会是true还是false呢?答案显而易见的是true!为什么?我们之前学习java的时候知道String 如果创建了2个一样的字符串的话,这2个字符串的引用地址其实是同一个来的,而不会创建2个对象!那么为什么java是怎么去判断的呢?
在JVM里,考虑到垃圾回收(Garbage Collection)的方便,将 heap 划分为三部分: young generation (新生代)、 tenured generation(old generation)(旧生代)和 permanent generation( permgen )(永久代),而这里要说的就是永久代。
再通过 a = "ab1" 这样的方式去创建字符串变量的时候,在编译期间的时候 jvm会做一次编译优化,把字符串常量放进永久代里面的常量池里面,而后面一样的字符串常量都会去这个常量池里面查找是否存在这个常量,如果存在的话就直接引用,如果不存在则创建一个并且放进这个常量池里面。
那编译期优化是怎么优化的呢? 如 String a = "a" + "b" +"1"; jvm编译的时候会 会直接编译成 String a = "ab1"; 这个时候会创建一个字符串并且放在常量池里面,当定义 String b = "ab1"; 这个时候因为在常量池里面已经存在 “ab1” 这个常量,b 会直接引用 这个常量的地址,所以a==b等于 true;这里可以看下编译前后的代码来对比:
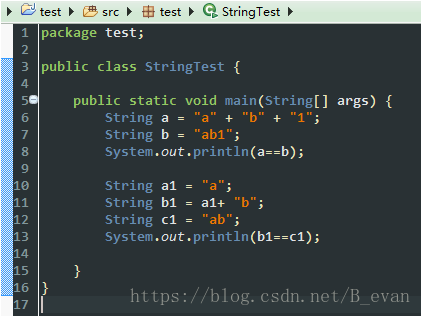
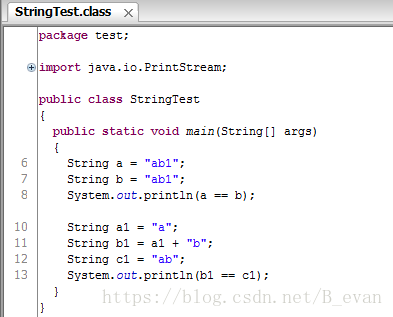
可以看出,再编译期间,如果是常量则会优化成一个字符串,而如果是变量则不会!那这里如果想要使a1+b1 也跟上面一样编译期间就优化怎么办呢?有办法:
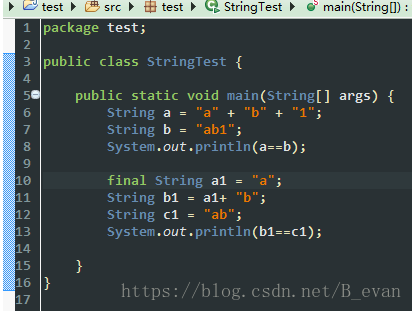
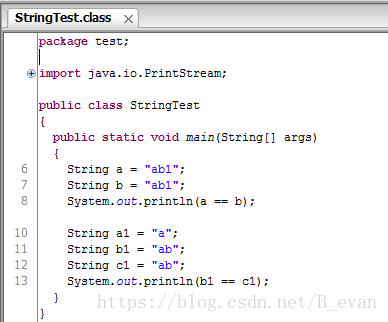
同个加上 final 修饰符,final修饰符有2种用法,一种是修饰类,被修饰后的类是不能继承的,String就是被final修饰的类,一种是修饰String字符串,当使a1被修饰成常量后,只能被赋值一次,所以在编译期间就可以做编译优化!
2、String + String 跟 StringBuilder.append的对比
我们平常编码的时候经常有用到String b = a + "c"等连接字符串的办法,也知道可以用StringBuilder.append("b")这样的办法去连接,那2种连接字符串有什么区别呢?jvm在编译 b = a + "c" 的时候其实会创建一个StringBuilder对象来进行拼接字符串,例如:
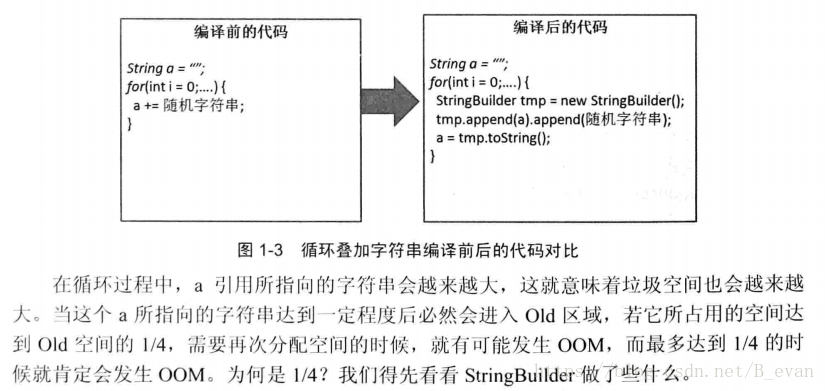
这样循环拼接字符串会导致频繁的创建StringBuilder对象,当之前旧的对象没有的时候就会GC掉,这样就会到此频繁的GC,影响性能。上面说的什么意思呢,当StringBuilder对象拼接字符串如果空间够用则向后添加元素,而如果空间不够则至少会分配原来对象2倍的空间。例如:
young = 128K old = 512K
16K + 16K = 32K StringBuilder对象等于32K young最少会占用(16K + 32K + 32K = 80K 剩余 48K)
32K + 16K = 48K StringBuilder对象等于64K young最少会占用(假设(32K、16K)的空间被GC 32K + 64K + 64K = 160K 不够空间会进入old区域)
48K + 16K = 64K StringBuilder对象等于64K(因为空间容量够所以并不会扩展)
64K + 16K = 80K StringBuilder对象等于128K old最少会占用(64K + 128K + 128K = 320K 剩余 192K)
... ... ...
128K + 16 K = 142K StringBuilder对象等于256K old最少会占用(128K + 256K + 256K = 640K 超出128K)
StringBuilder.append 源码:
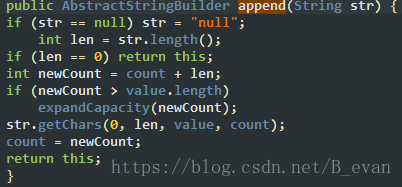
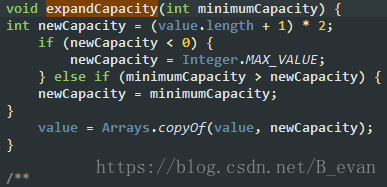
需要注意的是count这里指的不是cat[]数组的总长度,而是当前StringBuilder的有效个数。value.length是当前StringBuilder的总长度如果相加的字符串长度超过StringBuilder的总长度,则会扩展长度!
3、intern/equals()
在上面我们说过字符串常量会存放在永久代的常量池里面,所以可以用==对比,而String的equals是继承与Object然后重写过的!我们都知道String的equals是对比值的,那equals具体是怎么对比2个字符串的数据的呢?
我们看下源码:
JDK 1.6 String JDK 1.7 String
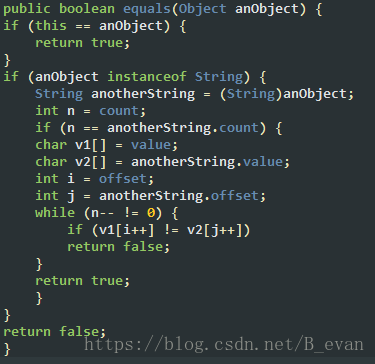
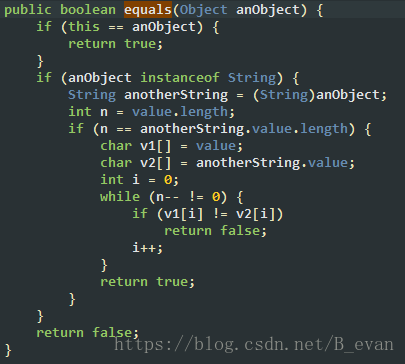
从源码上不能看的出equals的对比是先对比判读字符串长度,然后在一个个字符去对比的!从这里可以看的出用equlas的对比其实并没有我们想象中的那么快的!对比的速度取决于字符串的长度!
String a = "a";
String b = a + "b";
String c = "ab";
String d = new String(b);
System.out.println(b == c) false
System.out.println(c == d) false
System.out.println(c == d.intern()) true
System.out.println(b.intern() == d.intern()) true
变量a跟c在因为是常量所以会存放在永久代的常量池里面,当d创建字符串的时候这个时候虽然“ab”已经存在常量池里面了,但发生new String(b)的时候仅仅是进行了char[]数组的拷贝,所以是不同的地址,而当用intern()操作的时候会去永久代的常量池里面查找是否存在这个常量,如果存在则返回常量池里面这个对象的地址!
而这里我们就不得不说一下new String("abc") 跟 ="abc"的区别了

1、栈区(stacksegment) 由编译器自动分配释放,存放函数的参数值,局部变量的值等,具体方法执行结束之后,系统自动释放JVM内存资源
2、堆区(heapsegment) 一般由程序员分配释放,存放由new创建的对象和数组,jvm不定时查看这个对象,如果没有引用指向这个对象就回收
3、静态区(datasegment) 存放全局变量,静态变量和字符串常量,不释放
所以:
String a = new String("abc");
String b = new String("abc");
System.out.println(a==b); false
4、关于hashCode
简单的说hashCode就是返回一个对象的hashCode的值,那hashCode这个到底有什么用处呢?
hashCode的作用是为了产生一个可以标识对象的数字,然后可以快速的找到对象,如hashMap在进行存取的时候就会把key转成hashCode的值进行存取
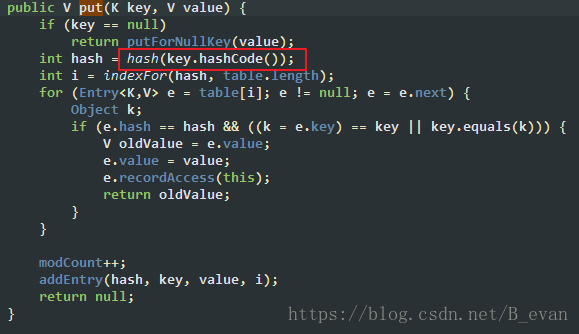
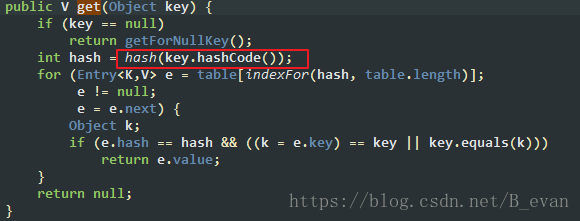
但是要说明hashCode的值并不是唯一的,例如:
String a = new String("abc");
String b = new String("abc");
String c = "abc";
System.out.println(a.hashCode()); 96354
System.out.println(b.hashCode()); 96354
System.out.println(c.hashCode()); 96354
System.out.println(a==b); false
System.out.println(a==c); false
在hash算法中通过hashCode的值定位都具体的链表后还需要进一步循环链表然后通过equals去对比key的值是否一样,hashCode的存在是为了算法而存在的,而equals的为了对比值而存在的。在重写了equals之后是否需要重写hashCode并没有强制上的需求,这个需要看具体的业务情况来判断
5、关于JDK 1.6 String 的 offset
String对象被当作一个char数组来存储,在String类中有3个域:char[] value、int offset、int count,分别用来存储真实的字符数组,数组的起始位置,String的字符数。由这3个变量就可以决定一个字符串。当substring方法被调用的时候,它会创建一个新的字符串,但是上述的char数组value仍然会使用原来父数组的那个value。父数组和子数组的唯一差别就是count和offset的值不一样

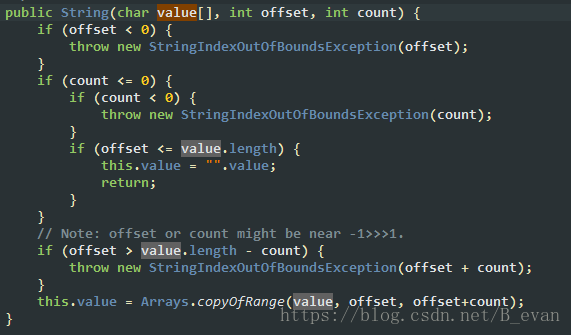
1.6 里面是直接改变当前对象的offset跟count的值,但是实际上value的chat[]并没有变过还是同一个,而1.7是直接copy一份新的chat[]数组