近年来,大模型技术突飞猛进,全球各大科技公司纷纷投入研发,形成了一系列成熟的主流大模型。以下是目前国内外最具代表性的大模型:
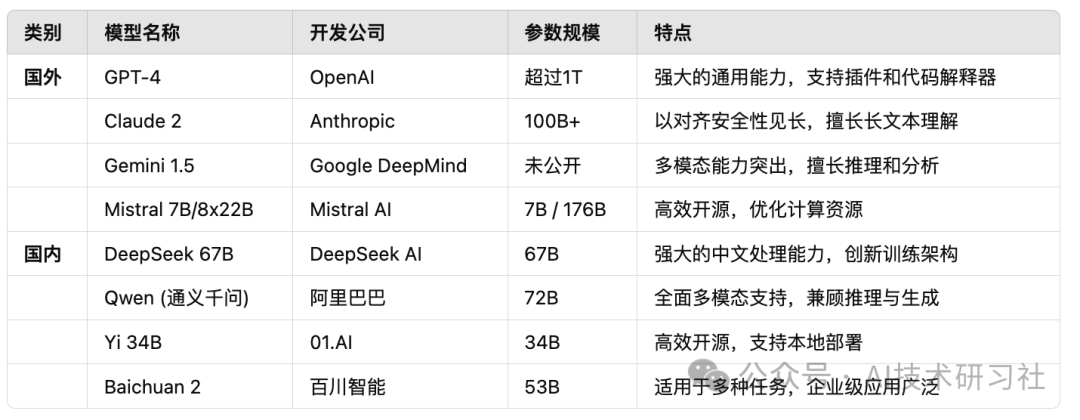
从上表可以看出,国内大模型在中文理解方面更具优势,同时涌现出大量开源方案,为用户提供了更灵活的部署选择。
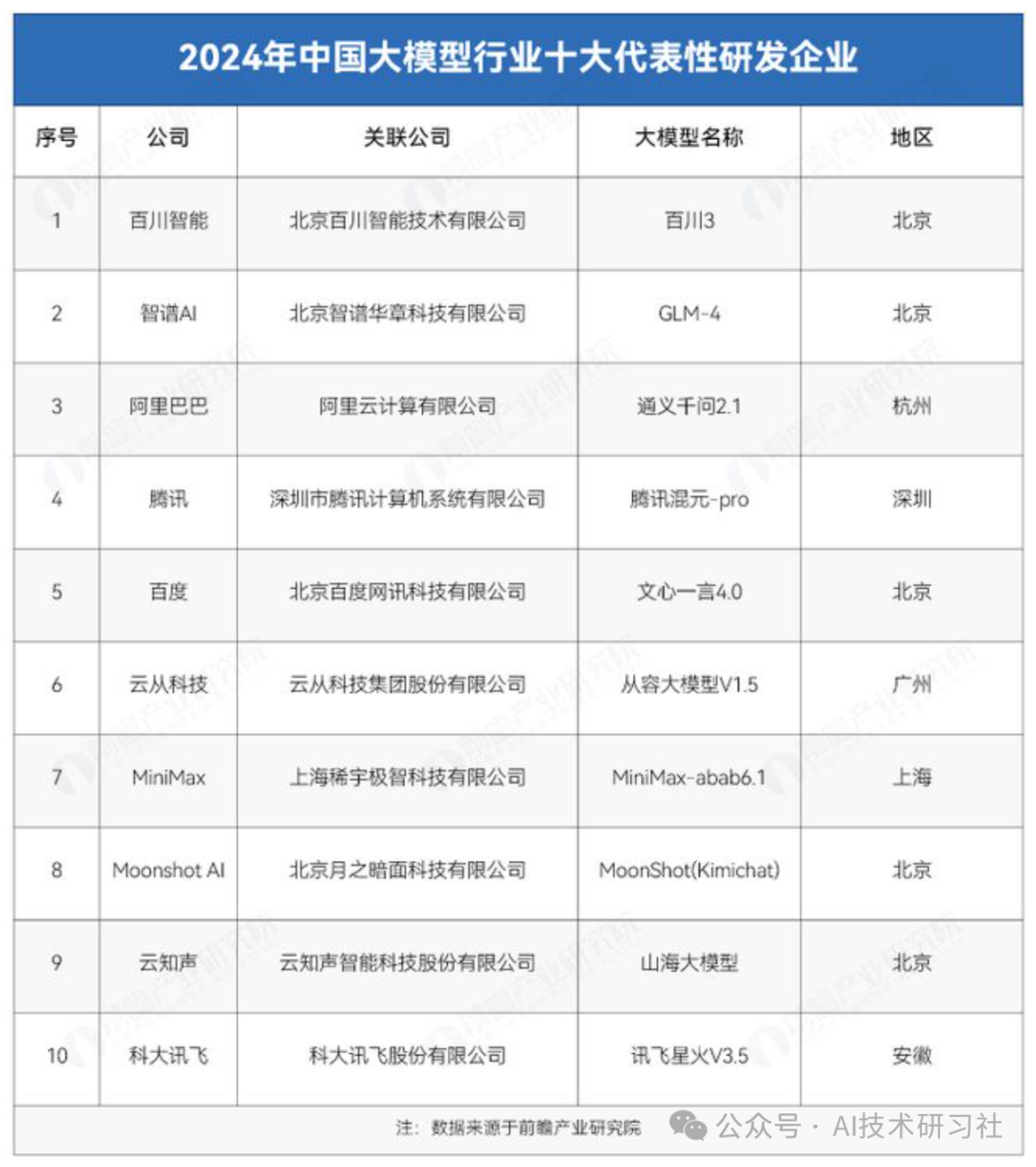
此外,根据SuperCLUE最新发布的大语言模型排行榜,国内大模型主要供应商如下:
下面回答一个最近用户提问比较多的问题,为什么国内外有这么多大模型了,DeepSeek还能这么火爆呢?
DeepSeek 之所以能在短时间内火爆出圈,主要得益于以下几点优势:
-
硬件优化创新:DeepSeek 针对国产 GPU 进行了优化,使得推理速度更快,成本更低。
-
高效的训练架构:采用创新的 MoE(Mixture of Experts)架构,在保证计算效率的同时,提高了模型的智能化水平。
-
针对中文的优化:相较于 GPT-4、Claude,DeepSeek 在中文 NLP 任务(如阅读理解、代码生成)上表现更优。
-
开放性与易部署:DeepSeek 提供了 Hugging Face 权重支持,并优化了量化技术,使得普通用户也能尝试本地部署。
AI 时代,我们的思维方式也需要改变。很多人还习惯于传统搜索,但真正的智能时代,应该是与AI 交谈,不断优化问题,直到得到最佳答案。
正如爱因斯坦所说:“我们不能用制造问题时的思维方式来解决问题。”
比如,很多人直接问 AI:❌ "帮我写个市场分析报告。"
但如果优化成:✅ "作为市场经理,我需要对 2024 年 Q4 中国新能源汽车市场做一个简要分析。请结合销量数据、用户评价趋势和政策影响,输出一篇 800 字报告。"
这样,AI 生成的内容不仅更精准,还能真正解决你的需求。
但是,当下很多用户在尝试使用DeepSeek的时候面临一个问题,许多用户反馈,在某些场景下,DeepSeek 访问不稳定,DeepSeek依然未能从服务崩溃中彻底走出来。

这也引出了一个关键问题:当 DeepSeek 不可用时,如何保证你的 AI 工作流不受影响?
解决方案 1:使用其他大模型
如果 DeepSeek 无法访问,可以切换到其他国内外大模型:
-
国内替代:Qwen、Baichuan、Yi-34B 等。
-
国外替代:GPT-4、Claude 2、Gemini 1.5(需要科学上网)。
解决方案 2:自己部署大模型
如果你想长期稳定地使用大模型,并希望掌握更大的自由度,可以考虑自部署。
自己部署大模型需要什么资源?
部署大模型的核心资源是 GPU,不同规模的模型对算力的需求不同,以下是大致的硬件和成本估算:

几种大模型部署方案
1. 本地部署(学习/实验)
如果你只是想体验大模型,学习 RAG(检索增强生成),可以尝试在 笔记本/台式机 上运行小型模型。
示例: