引言:
本文深入研究一种名为缓存增强生成(CAG)的新技术如何工作并减少/消除检索增强生成(RAG)弱点和瓶颈。
LLMs 可以根据输入给他的信息给出对应的输出,但是这样的工作方式很快就不能满足应用的需要:
因为很多时候回答问题,要么知识不足,让我回答的问题会有错误, 而且很多时候回答问题的信息需要及时更新的,但是大模型的训练却不能进行同步。
为了确保LLMs能够使用最新信息来回答查询,以下技术被广泛使用:
-
模型微调
-
低秩适应(LoRA) 微调
-
检索增强生成(RAG)
最近研究人员刚刚发布了一种新的技术:一种名为缓存增强生成(CAG)的新技术,可以减少对RAG(因此也减少了它的所有缺点)的需求。CAG通过将所有相关知识预先加载到LLM的扩展上下文中,而不是从知识存储中检索它,并在推理时使用这些知识来回答查询它的效果令人惊讶: 当与长上下文LLMs一起使用时,结果表明这种技术在多个基准测试中要么优于RAG,要么可以作为RAG的有效补充。通过下文,我们深入了解缓存增强生成(CAG)的工作原理以及与RAG相比的表现。
一:什么是缓存增强生成(CAG)?
1:技术概述:
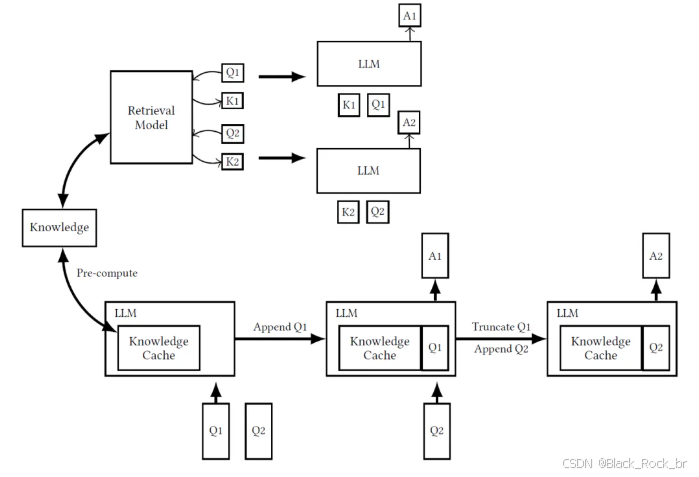
缓存增强生成(Cache-Augmented Generation, CAG)是一种新兴的技术,旨在通过预加载和缓存相关知识,提高大型语言模型(LLMs)的生成效率和响应速度。与传统的检索增强生成(Retrieval-Augmented Generation, RAG)相比,CAG 通过将所有相关知识预先加载到模型的上下文窗口中,并缓存其运行时参数,从而在推理时直接生成响应,无需实时检索。
2:工作执行原理:
CAG 的核心在于两个主要组件:缓存和生成模型。缓存存储了在之前交互或计算过程中生成的文本片段(或知识),这些存储的信息随后用于指导下一步的生成,从而加快生成过程并提高相关性。
具体步骤如下:
-
缓存构建:在模型生成文本时,关键信息(如常用短语、学习到的事实或上下文)被存储在缓存中。这可以在不同级别进行,无论是单词级别、句子级别,还是更抽象的语义级别。
-
缓存查找:当模型被要求生成新文本时,它首先检查缓存以查找相关的信息。如果找到匹配项,模型会检索并将其纳入新生成的内容中,减少从头开始计算的需求。
-
缓存更新:随着时间的推移,模型生成更多文本时,缓存会用新的有用信息进行更新,保持其新鲜感和相关性。



3:RAG技术原理简介:
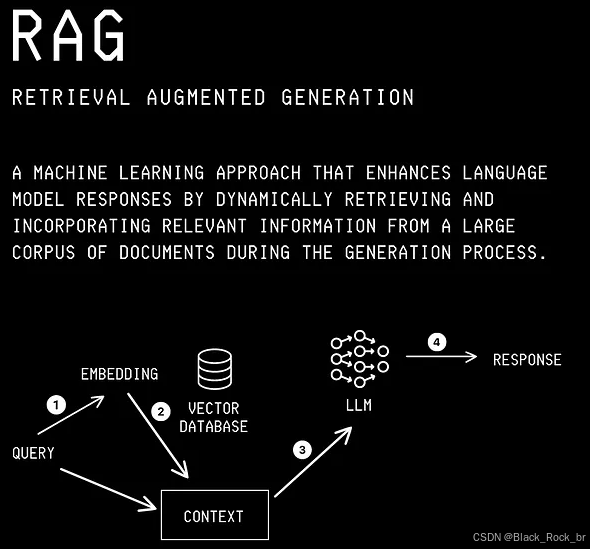
它是一种知识整合和信息检索技术,允许LLM使用特定于用例的私有数据集来产生更准确和最新的响应。
RAG中的技术过程如下:
-
检索:从知识库/特定私有数据集中 检索 相关信息/文档的过程。
-
增强:检索到的信息 添加 到输入上下文的过程。
-
生成:LLM基于原始查询和增强上下文 生成 响应的过程。
RAG-RAG的全称是Retrieval-Augmented Generation-检索增强生成
但RAG并不是一种完美的技术, 它也有非常多的缺点。
•检索延迟:在推断过程中从外部知识库获取信息需要时间, 基本上相当于传统搜索引擎需要的时间, 当然一般情况下还是可以忍受。
•检索错误:由于检索过程中选择了不相关和不完整的文档,可能会导致不准确或不相关的响应, 这就很依赖搜索引擎剧部分的效果。
•知识碎片化:不当的分块和不正确的排名可能导致检索到的文档不连贯且缺乏连贯性。所以很多时候在做RAG的时候如何去分辨如何提前对新型信息进行预处理就非常重要。
•复杂性增加:构建RAG流程需要额外复杂的基础设施,并涉及大量的维护和更新开销。 对,其实要做好RAG,其实跟做好一个受损性是比较类似的,开销都是比较大的。
二:CAG和RAG的表现和优势:
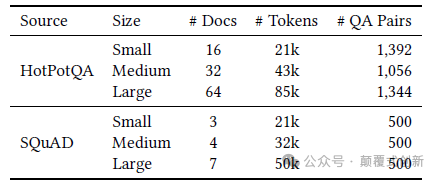
1:用于评估 CAG 性能的考虑了两个问答 Benchmark:
-
斯坦福问答数据集(SQuAD)1.0:由众包工作者在一组维基百科文章上提出的 100,000+ 个问题组成。每个问题的答案是相应阅读段落中的文本片段。
-
HotPotQA:由 113,000 个基于维基百科的问题-答案对组成,需要跨多个文档进行多跳推理。
从每个数据集中创建了三个测试集,其中参考文本的长度不同,增加参考文本的长度会使检索更具挑战性。
研究者使用 Llama 3.1 8-B Instruction model(上下文长度为 128k 个标记)来测试 RAG 和 CAG。
2:CAG 真的能够替代RAG吗?
令人惊讶的是,结果显示CAG 的表现优于稀疏(BM25)和密集(OpenAI Indexes)的 RAG 系统,在大多数评估中获得了最高的 BERT-Score。
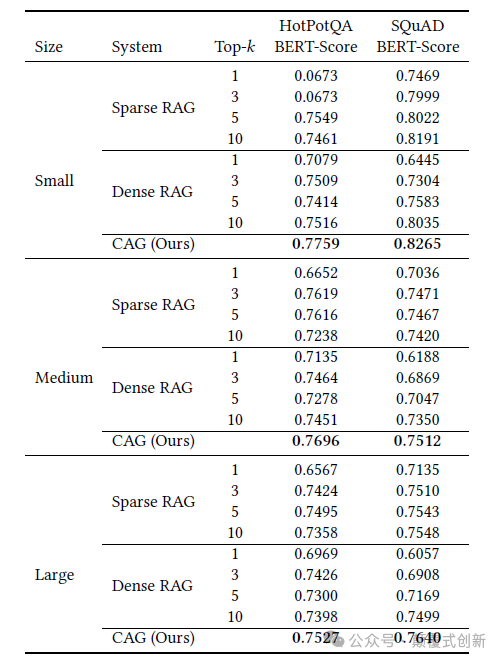
此外,CAG 大大减少了生成时间,特别是随着参考文本长度的增加。
对于最大的 HotpotQA 测试数据集,CAG 比 RAG 快约40.5 倍。这是一个巨大的提升!
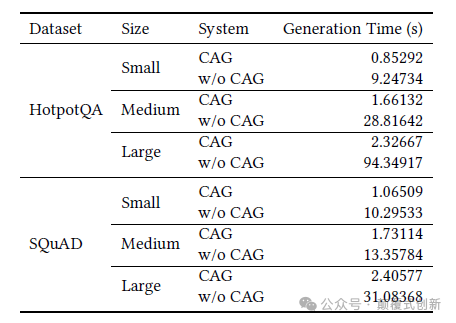
CAG 看起来是一个非常有前途的方法,可以确保在未来 LLM 的上下文长度进一步增加时从中检索到最新的信息(独立使用或与 RAG 结合)。
总结:
1: CAG 的优势
- 低延迟:无需实时检索数据,从而加快推理速度。
- 简化设计:无需向量数据库或嵌入模型,降低了系统复杂性。
- 高吞吐量:对于同一数据集上的重复任务,效率更高。
2: CAG 的局限性
- 知识大小有限:CAG 要求整个知识源必须能够适应模型的上下文窗口,因此对于涉及极其大数据集的任务不太适用。
- 上下文长度限制:LLMs 的性能可能会随着上下文长度的增加而下降。
3: CAG 的应用场景
- 企业文档助手:静态数据集,如员工手册和用户手册。
- 医疗知识检索:医疗指南或治疗协议。
- 法律文件摘要:预加载合同和法律简报以进行快速分析。
- 在线学习平台:预加载静态课程内容以进行动态查询。
4:CAG 的未来展望
随着上下文窗口限制的增加(例如 1M 个标记),CAG 将变得更加可扩展。此外,结合 CAG 和 RAG 的混合架构将平衡静态和动态数据需求,而优化的标记管理将更有效地处理大型数据集。
5:结论
缓存增强生成(CAG)并不是检索增强生成(RAG)的通用替代品,但在具有有界数据集、低延迟要求和静态知识库的场景中表现出色。