一、简介
1、适用场景
- 同时注重吞吐量(
Throughput)和低延迟(Low latency),默认的暂停目标是200ms - 超大堆内存,会将堆划分为多个大小相等的
Region(对JVM空间进行了重新个规划) - 整体上是
标记+整理算法,两个区域之间是复制算法 JDK9时,默认启用G1
2、相关参数
-XX:+UseG1GC 开启G1
-XX:G1HeapRegionSize=size 设置region的大小,一般默认为1248m
-XX:MaxGCPauseMillis=time 设置单次STW最长时间,单位毫秒
二、工作原理
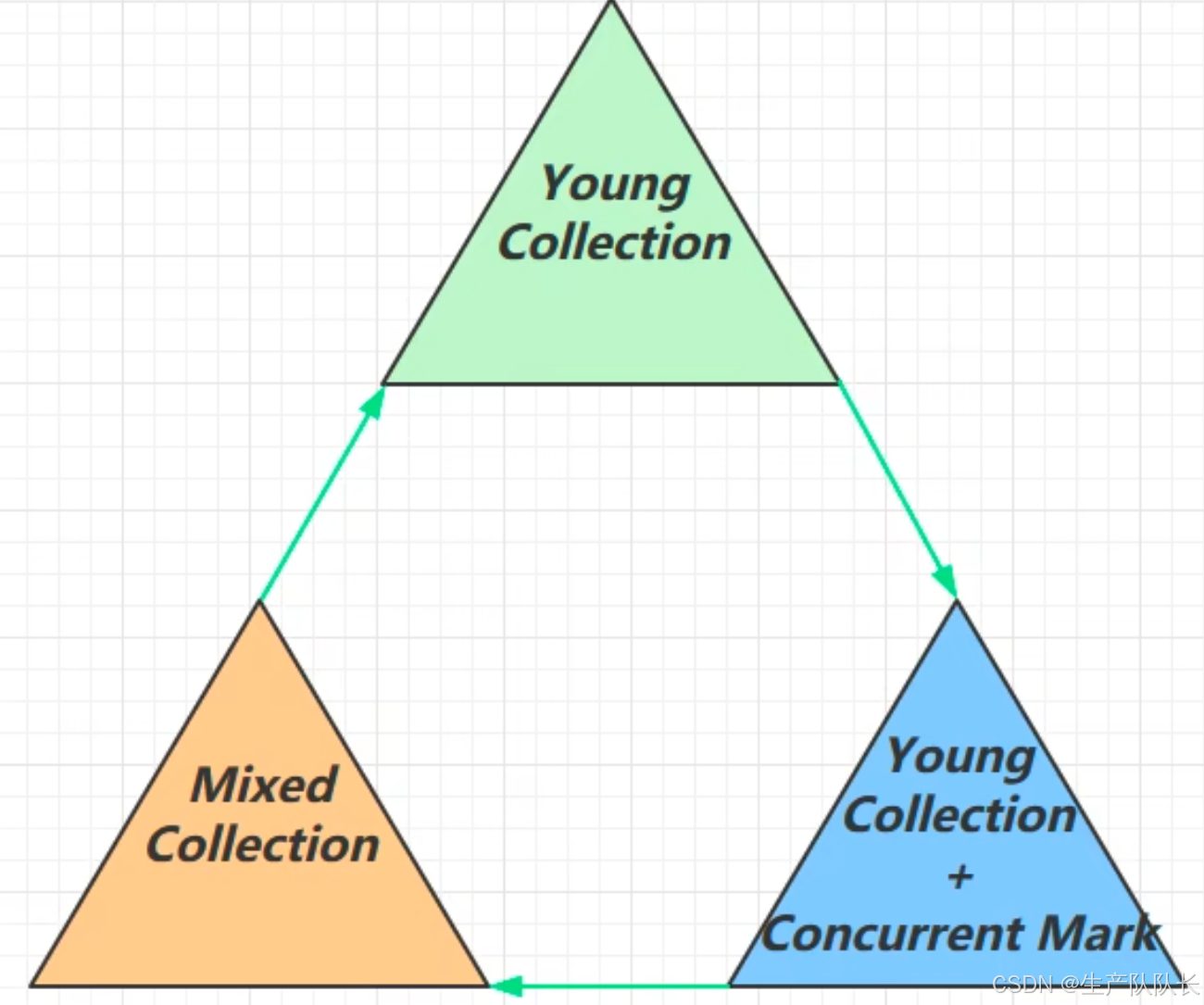
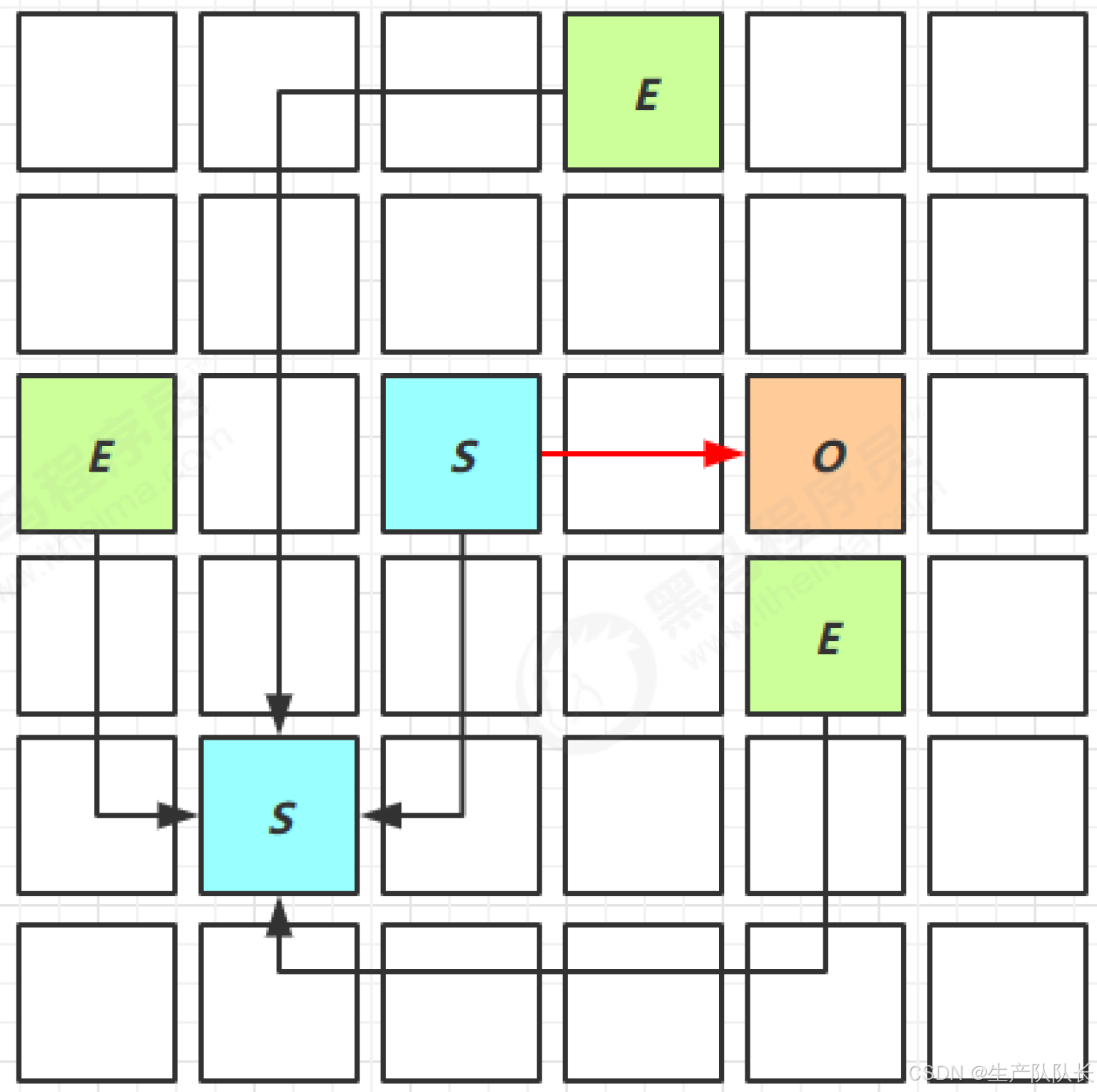
1、大致流程图
分为三个循环阶段
- 年轻代的垃圾收集
- 年轻代的垃圾收集 + 并发标记
- 混合收集
2、Young Collection - 这个阶段,会发生
STW
新创建的对象会存入Eden区域
当Eden逐渐增多后,会发生一次Minor GC,并将存活的对象存入S区(Survivor)
当多次Minor GC之后,S区对象的年龄达到一定阈值,默认15岁,则晋升到老年代,并将其他存活的对象复制到另外一个S区。
3、Young Collection + CM - 在
Young GC时会进行GC Root的初始标记,初始标记会STW,并且只会发生在Young GC中。 - 老年代占用堆空间比例达到阈值时(
-XX:InitiatingHeapOccupancyPercent,默认45%),进行并发标记(不会STW)
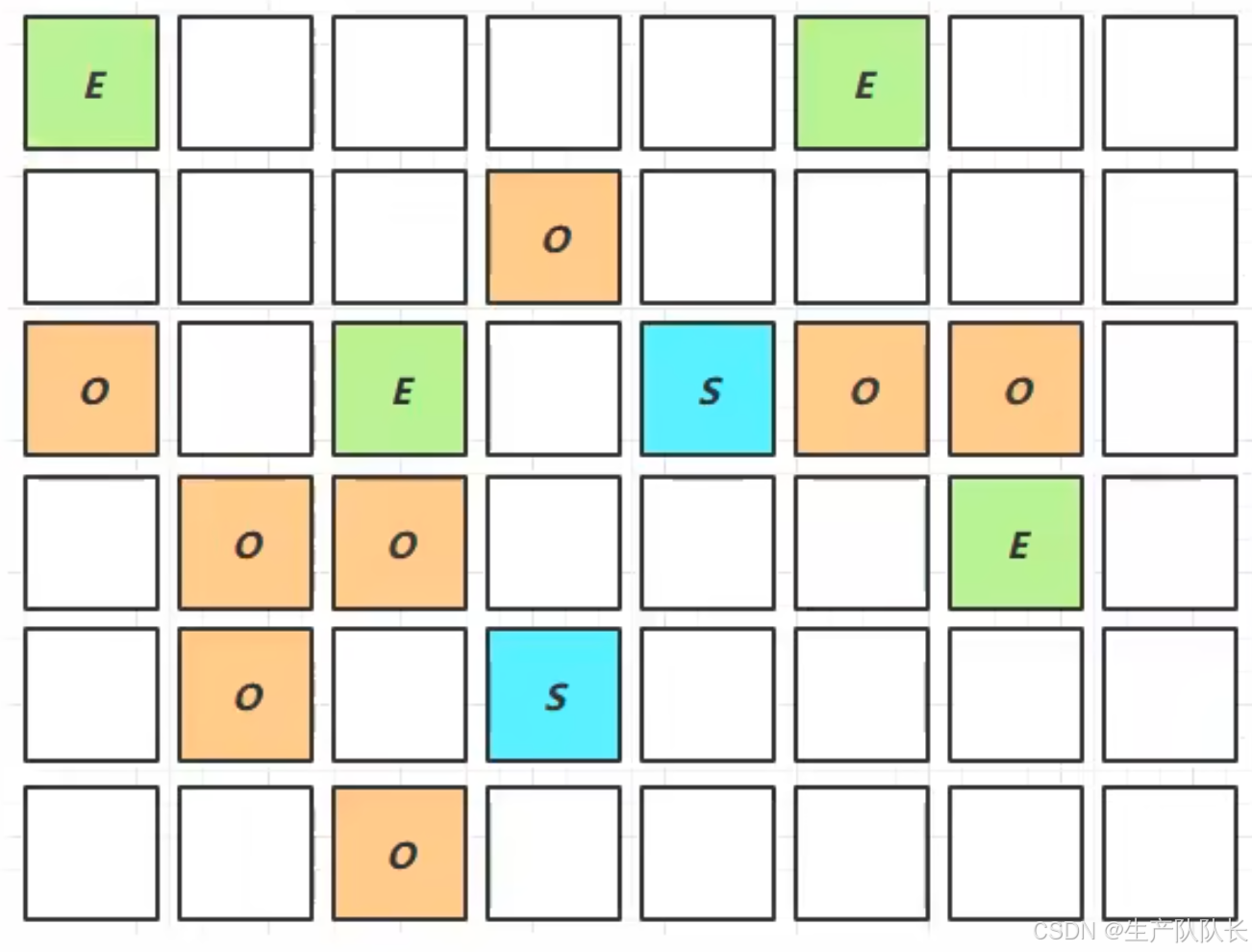
4、Mixed Collection
会对 E、S、O 进行全面垃圾回收,类似之前的Ful GC,但是,这里不能称之为Full GC。 - 最终标记(Remark)会 STW
- 拷贝存活(Evacuation)会 STW
- -XX:MaxGCPauseMillis=ms
当老年代占用的比例达到阈值时,会触发Mixed Collection
过程如下:
先进行年轻代的Minor GC,然后,对老年代进行垃圾收集,因为,存在MaxGCPauseMillis这个参数的限制,所以,每次的回收STW时间不能超过它,就决定了,每次的回收量有限。
这时候,G1会优先回收O区垃圾较多的Region,这就是G1名称的由来原因。
并将O区存活的对象,拷贝到另外一个O区。
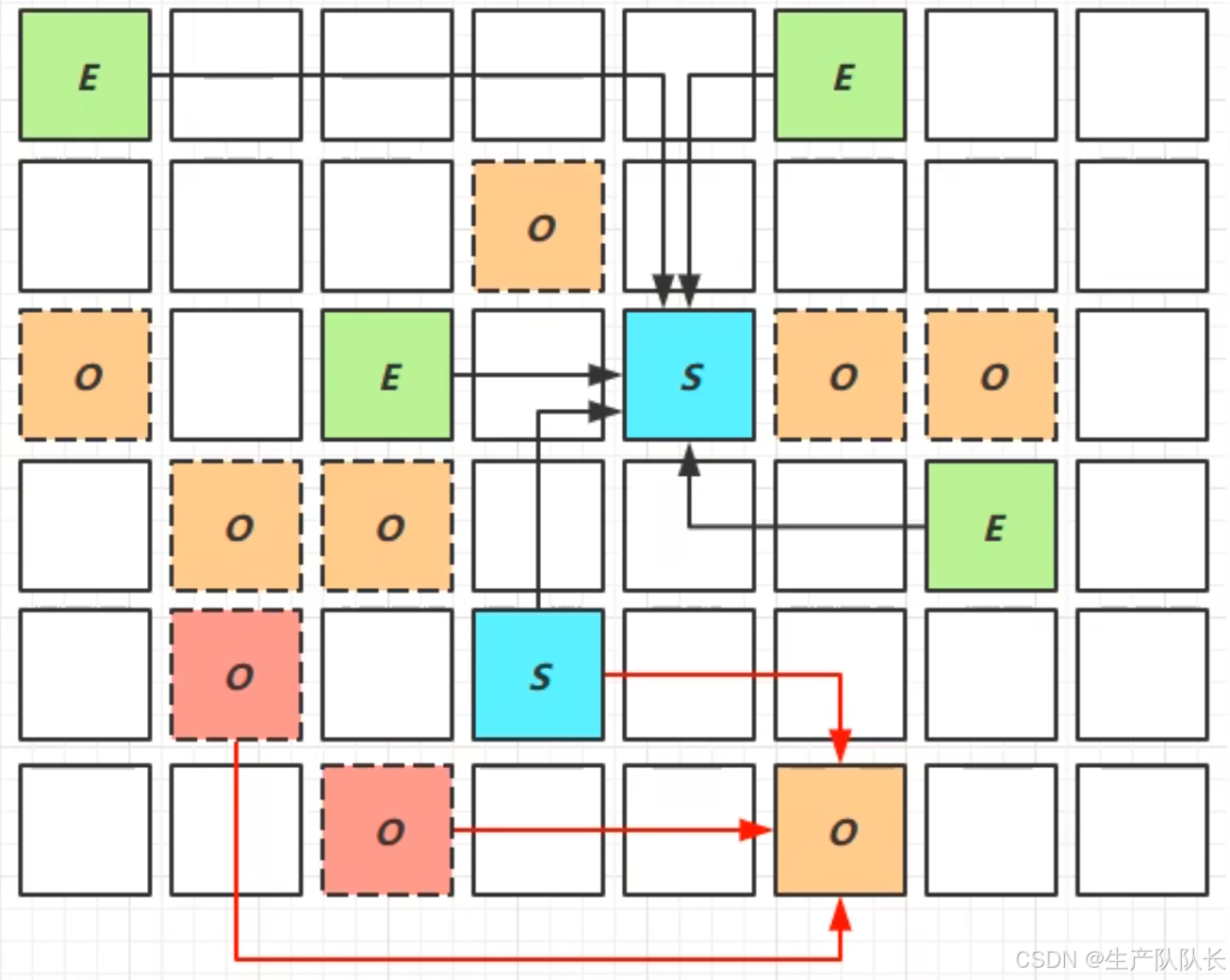
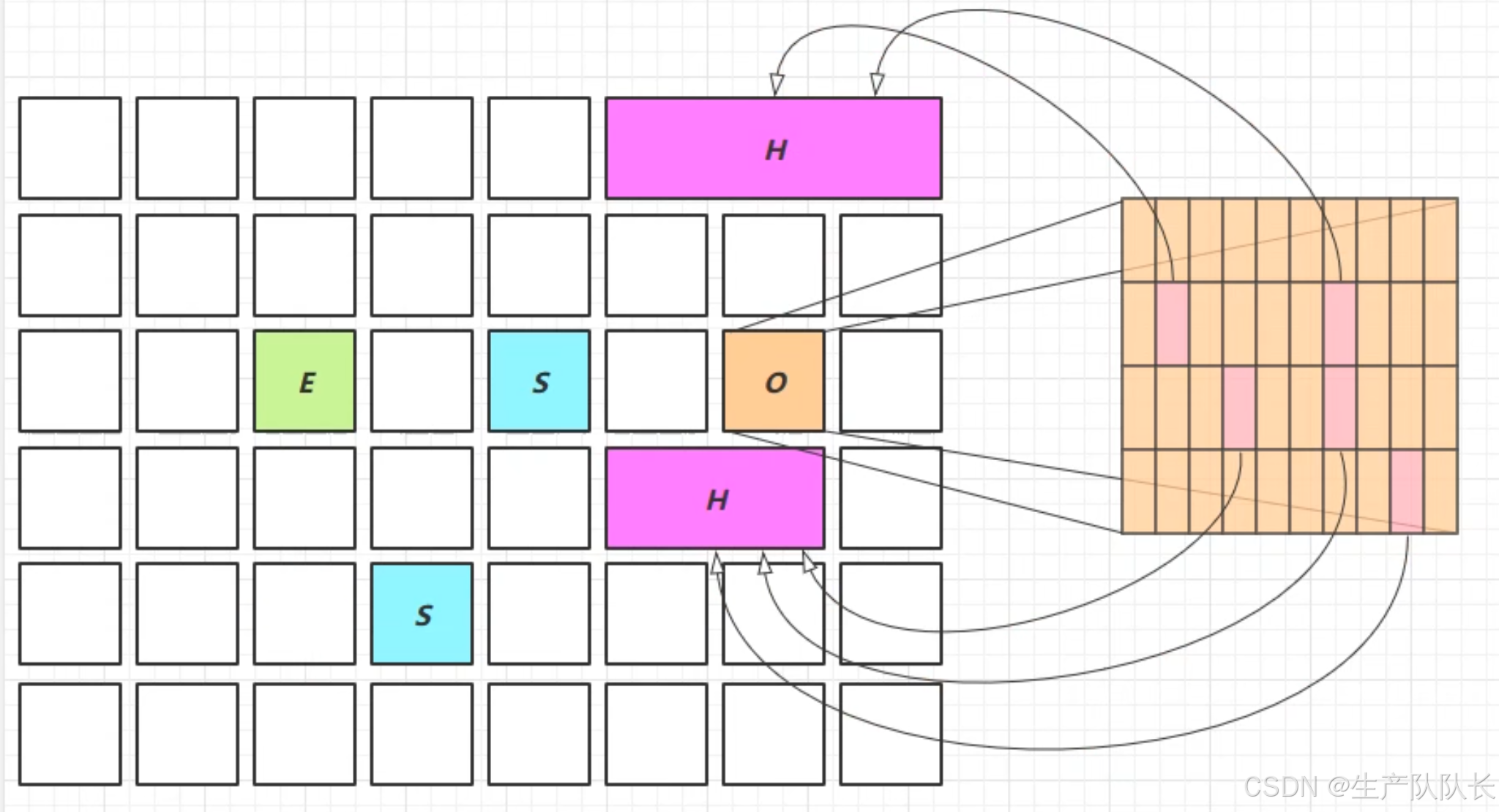
三、Young Collection 跨代引用
新生代回收的跨代引用(老年代引用新生代)问题
问题是这样的:
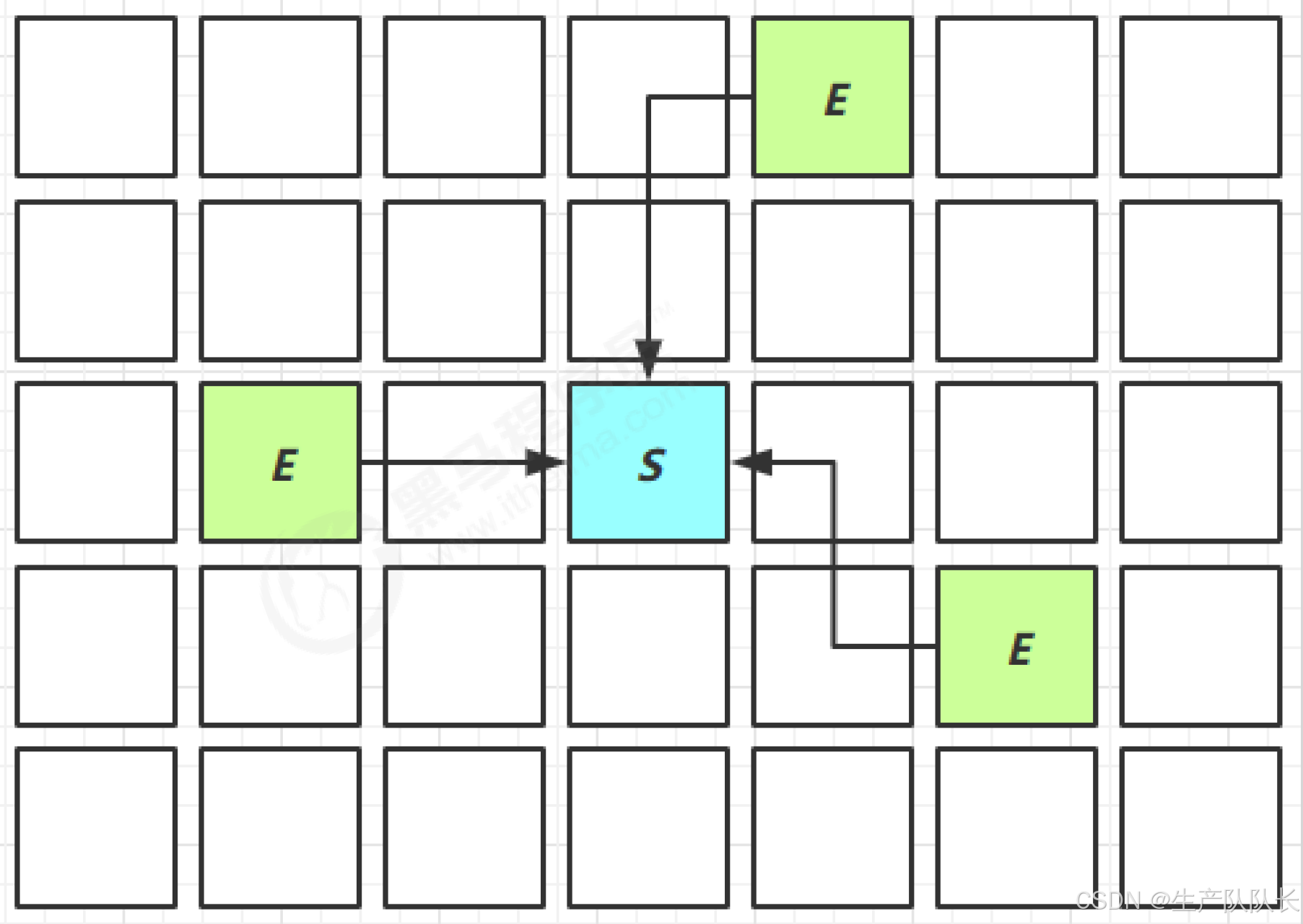
由于O区对象非常多,新生代对象被O区引用,那么,在判断GC Root时,就要遍历整个O区,这样就非常影响性能。
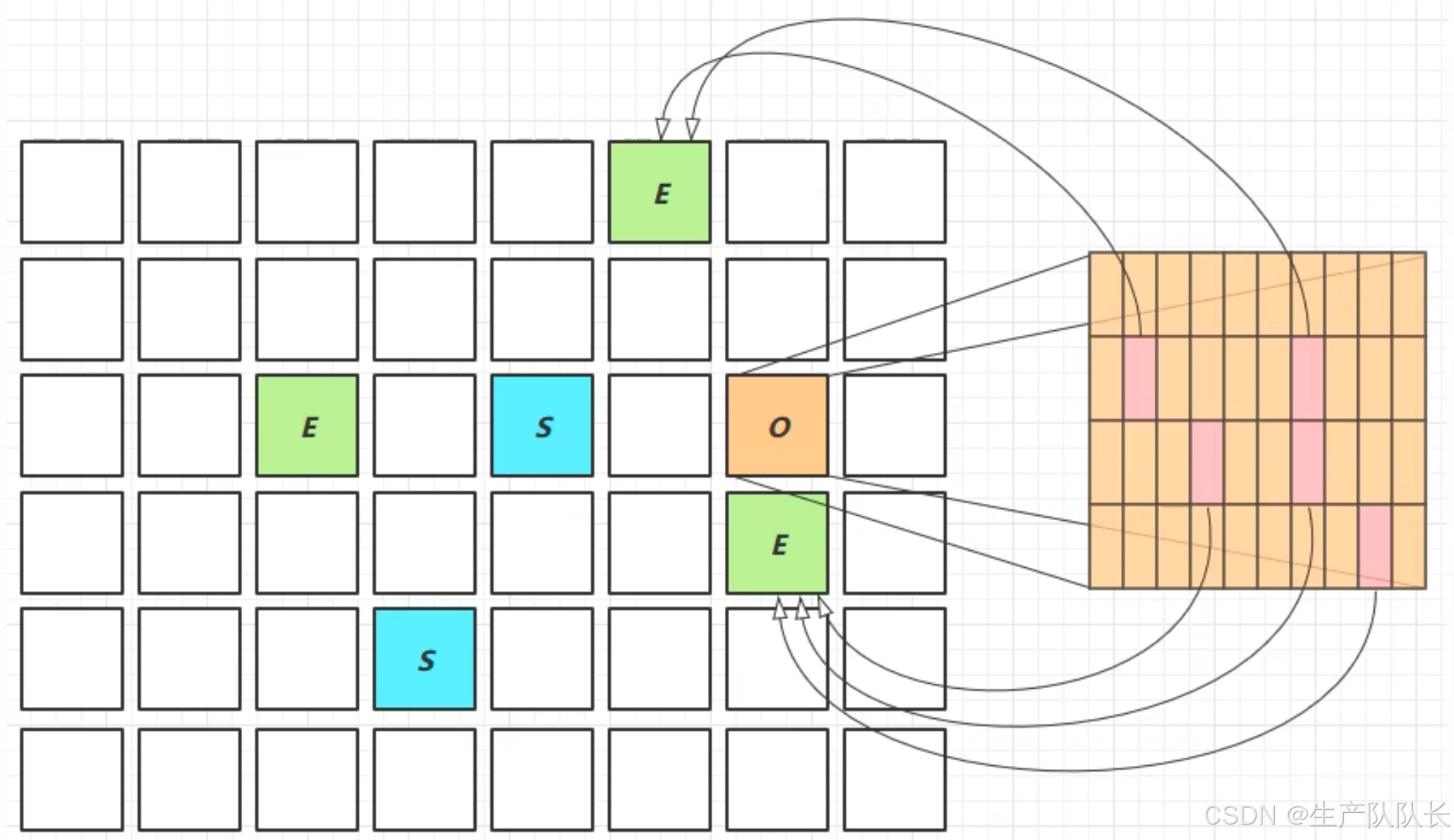
所以,这里为了优化性能,引入了卡表技术与Remembered Set
当老年代引用了新生代对象时,这个老年代对象存放的区域就被标记为脏卡区域。
从而,在遍历GC Root时,直接去脏卡区域查找,节省了大量时间。
那么,有人会问,此处为什么不用队列存放所有O区跨代引用的对象了?
我想,一方面队列也是对象,另外,这样违背GC Root的定义。
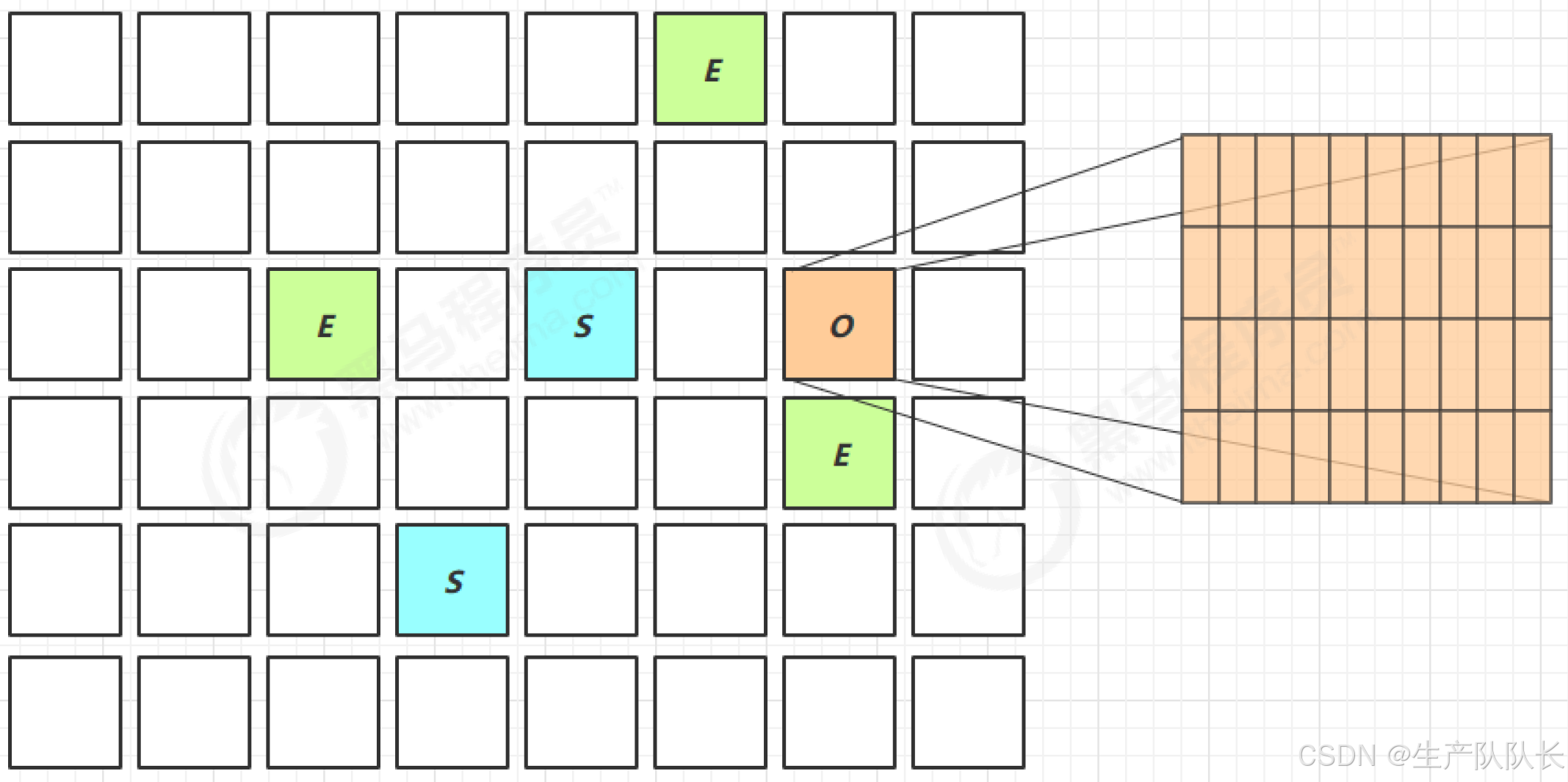
四、大对象问题
我想,对算法方案比较擅长的同学,应该会有这样一个问题。
G1将JVM空间划分为Region区域,那么,如果一个巨型对象来了,如何存放?
这Region是不是就类似前面的内存碎片了?
定义:一个对象大于 region 的一半时,称之为巨型对象
巨型对象的存储:
如何回收?
G1 不会对巨型对象进行拷贝,并且回收时被优先考虑
一般情况下,不会把巨型对象放在内存中很久的。