作者介绍:10年大厂数据\经营分析经验,现任大厂数据部门负责人。
会一些的技术:数据分析、算法、SQL、大数据相关、python
欢迎加入社区:码上找工作
作者专栏每日更新:
LeetCode解锁1000题: 打怪升级之旅
python数据分析可视化:企业实战案例
python源码解读
程序员必备的数学知识与应用
备注说明:方便大家阅读,统一使用python,带必要注释,公众号 数据分析螺丝钉 一起打怪升级
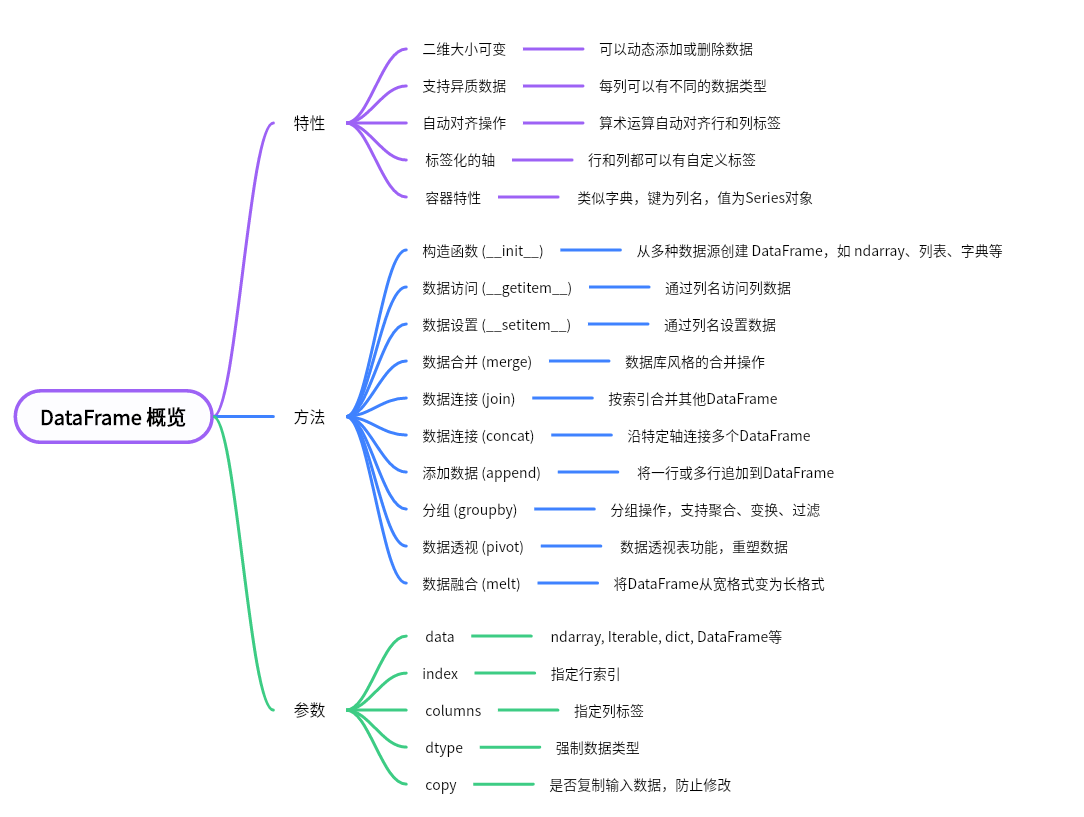
探索Pandas的心脏—— DataFrame
引言
Pandas 的 DataFrame 是现代数据科学工具箱中的一块基石,提供了强大且灵活的数据结构来支持各种复杂的数据操作。作为 Python 最受欢迎的数据处理库之一,Pandas 通过 DataFrame 类实现了一个功能丰富的两维数据表格。这个表格不仅能够处理尺寸可变的异质类型数据,还包含了标签化的轴(行和列),使得数据操作既直观又便捷。
DataFrame源码 在pandas/core/frame.py里
DataFrame 概览
接下来,我们将深入探讨 DataFrame 类中几个关键方法的作用、示例和对应的输出结果,方便更清晰地理解每个方法的实际应用和功能。
1. 构造函数 __init__
功能说明
用于创建一个新的 DataFrame 对象。
示例:
import pandas as pd
# 创建 DataFrame 使用字典
data = {'col1': [1, 2], 'col2': [3, 4]}
df = pd.DataFrame(data)
print(df)
输出:
col1 col2
0 1 3
1 2 4
源码说明
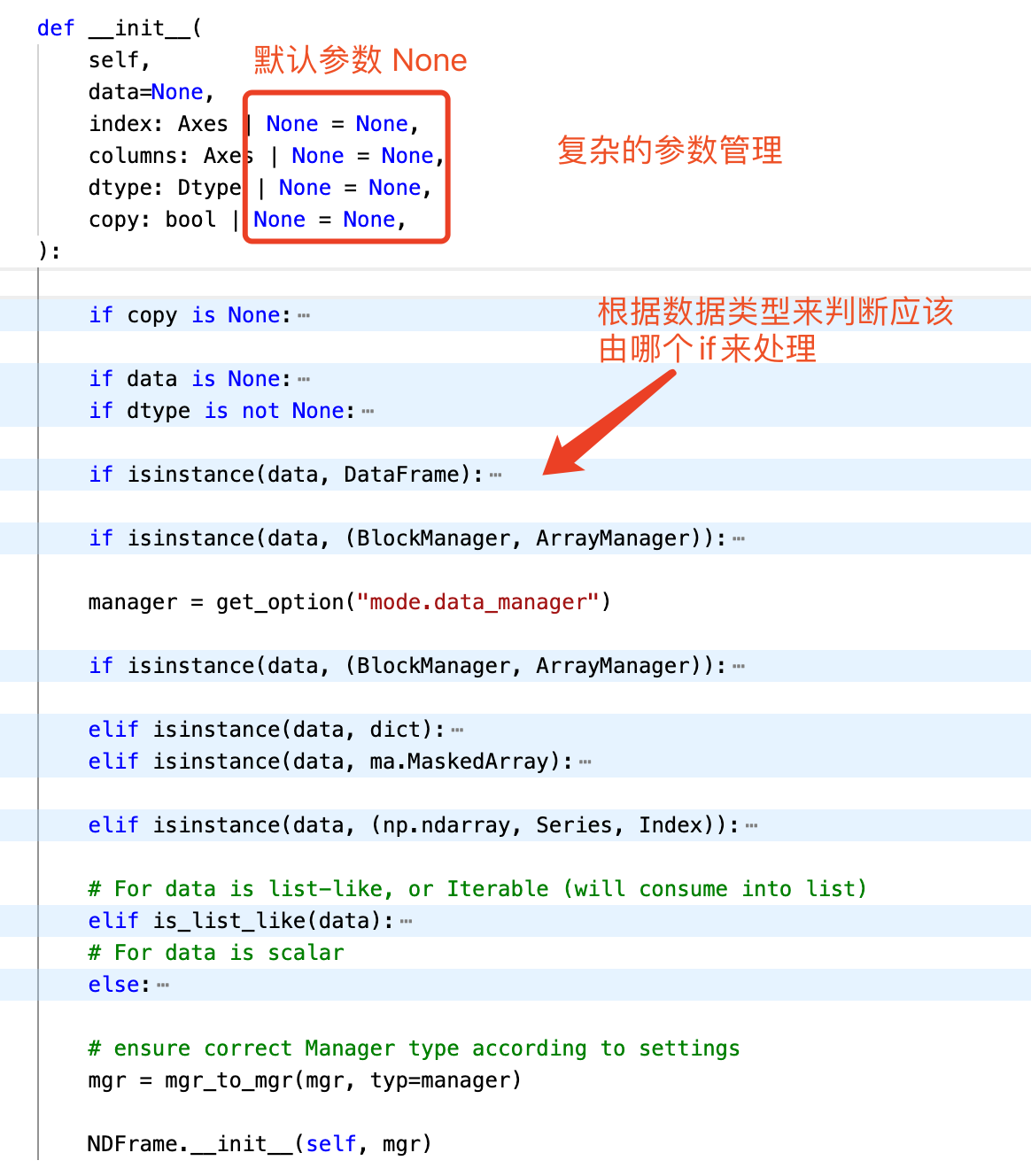
Pandas 的 DataFrame 构造函数 __init__ 是一个典型的示例,展示了如何在日常编程中处理多源数据输入、类型检测、条件判断以及数据管理。代码中广泛使用了 if-else 语句来根据不同的数据类型和条件执行不同的逻辑。这种模式非常适用于处理具有多种输入可能性的函数。
- 类型检测:通过
isinstance()检查数据类型,根据数据类型的不同选择不同的处理流程。 - 参数默认值的智能处理:根据输入数据的类型和是否已指定某些参数来动态设置默认值。
知识点 按需import
可以看到在616行有一个 import,这里的import放在了elif里面可以减少程序启动的时间,减少不必要的依赖和循环引用,只有在特定条件下才会被触发,在一些大型项目中能有效减少常规操作的开销

源码逐行解析
def __init__(
self,
data=None,
index: Axes | None = None,
columns: Axes | None = None,
dtype: Dtype | None = None,
copy: bool | None = None,
):
# 根据数据类型确定是否需要复制数据,默认情况下,字典和未指定数据源的情况下复制
if copy is None:
if isinstance(data, dict) or data is None:
copy = True
else:
copy = False
# 如果未提供数据,则初始化为空字典
if data is None:
data = {}
# 如果指定了dtype,则验证和转换数据类型
if dtype is not None:
dtype = self._validate_dtype(dtype)
# 如果数据已经是DataFrame类型,直接使用其内部管理器
if isinstance(data, DataFrame):
data = data._mgr
# 如果数据是管理器类型(BlockManager或ArrayManager)
if isinstance(data, (BlockManager, ArrayManager)):
if index is None and columns is None and dtype is None and not copy:
NDFrame.__init__(self, data)
return
# 根据设置决定使用哪种数据管理器
manager = get_option("mode.data_manager")
# 初始化数据管理器
if isinstance(data, (BlockManager, ArrayManager)):
mgr = self._init_mgr(
data, axes={"index": index, "columns": columns}, dtype=dtype, copy=copy
)
# 如果数据是字典类型
elif isinstance(data, dict):
mgr = dict_to_mgr(data, index, columns, dtype=dtype, copy=copy, typ=manager)
# 如果数据是遮盖数组(MaskedArray)
elif isinstance(data, ma.MaskedArray):
import numpy.ma.mrecords as mrecords
if isinstance(data, mrecords.MaskedRecords):
mgr = rec_array_to_mgr(
data, index, columns, dtype, copy, typ=manager,
)
warnings.warn(
"Support for MaskedRecords is deprecated and will be removed in a future version. Pass {name: data[name] for name in data.dtype.names} instead.",
FutureWarning,
stacklevel=2,
)
else:
data = sanitize_masked_array(data)
mgr = ndarray_to_mgr(
data, index, columns, dtype=dtype, copy=copy, typ=manager,
)
# 如果数据是 NumPy 数组、Series 或 Index
elif isinstance(data, (np.ndarray, Series, Index)):
if data.dtype.names:
data = cast(np.ndarray, data)
mgr = rec_array_to_mgr(
data, index, columns, dtype, copy, typ=manager,
)
elif getattr(data, "name", None) is not None:
mgr = dict_to_mgr(
{data.name: data}, index, columns, dtype=dtype, typ=manager,
)
else:
mgr = ndarray_to_mgr(
data, index, columns, dtype=dtype, copy=copy, typ=manager,
)
# 如果数据是列表或其他可迭代对象
elif is_list_like(data):
if not isinstance(data, (abc.Sequence, ExtensionArray)):
data = list(data)
if len(data) > 0:
if is_dataclass(data[0]):
data = dataclasses_to_dicts(data)
if treat_as_nested(data):
if columns is not None:
columns = ensure_index(columns)
arrays, columns, index = nested_data_to_arrays(
data, columns, index, dtype,
)
mgr = arrays_to_mgr(
arrays, columns, index, columns, dtype=dtype, typ=manager,
)
else:
mgr = ndarray_to_mgr(
data, index, columns, dtype=dtype, copy=copy, typ=manager,
)
else:
mgr = dict_to_mgr(
{}, index, columns, dtype=dtype, typ=manager,
)
# 如果数据是标量
else:
if index is None or columns is None:
raise ValueError("DataFrame constructor not properly called!")
index = ensure_index(index)
columns = ensure_index(columns)
if not dtype:
dtype, _ = infer_dtype_from_scalar(data, pandas_dtype=True)
if isinstance(dtype, ExtensionDtype):
values = [
construct_1d_arraylike_from_scalar(data, len(index), dtype)
for _ in range(len(columns))
]
mgr = arrays_to_mgr(
values, columns, index, columns, dtype=None, typ=manager
)
else:
arr2d = construct_2d_arraylike_from_scalar(
data, len(index), len(columns), dtype, copy,
)
mgr = ndarray_to_mgr(
arr2d, index, columns, dtype=arr2d.dtype, copy=False, typ=manager,
)
# 确保使用正确的数据管理器类型
mgr = mgr_to_mgr(mgr, typ=manager)
NDFrame.__init__(self, mgr)
2. 数据访问 __getitem__
功能说明
通过列名访问数据。
示例:
# 访问列 'col1'
print(df['col1'])
输出:
0 1
1 2
Name: col1, dtype: int64
源码说明
__getitem__ 方法
这是一个非常核心的函数,用于索引和选择数据。这个方法支持多种类型的键(key),处理逻辑相对复杂。我们逐行解析,补充每行代码的功能和作用的注释。

知识点 数组转切片
使用 lib.maybe_indices_to_slice

这个方法是理解 Pandas 数据获取逻辑的一个很好的例子,展示了在实际项目中如何处理复杂和多变的数据访问需求。在 Pandas 的源代码中,lib.maybe_indices_to_slice 函数是一个优化函数,其目的是尝试将一个整数数组转换成一个更为高效的切片对象(slice 对象)。这种转换在处理大型数据集时尤其有用,因为使用切片通常比使用等价的整数数组索引具有更高的性能。
为什么使用切片比整数数组索引更高效?
切片操作只需要定义起点、终点和步长,无论数据集有多大,切片描述的复杂性都不增加,Python 也可以优化这些操作。相反,整数数组索引需要存储每个索引点,其内存消耗和处理时间与索引数量直接相关,尤其是在大数据集上进行随机访问时。
功能解释
lib.maybe_indices_to_slice 函数的工作原理是检查提供的整数数组是否可以表示为一个简单的切片。如果可以,函数将返回一个对应的 slice 对象;如果不可以,函数将返回原始数组。这个检查基于以下几点:
- 连续性:数组中的值是否形成一个连续的序列,即每两个相邻值的差是常数。
- 边界:序列的起始和结束点必须明确。
具体应用
在 DataFrame 的 __getitem__ 方法中使用这个函数可以提高数据选择的效率。例如,如果你想选择 DataFrame 中的第 100 到第 200 行,理论上直接使用 df[100:201](使用切片)要比 df[list(range(100, 201))](使用整数数组)更有效率。lib.maybe_indices_to_slice 是一个用于优化数据索引的工具,尤其在处理大型数据集和需要频繁数据访问的应用中非常有用。理解这个函数的工作原理可以帮助开发者编写更高效、更可扩展的 Pandas 应用。
源码逐行解析
def __getitem__(self, key):
key = lib.item_from_zerodim(key) # 处理零维数组,转换成标量
key = com.apply_if_callable(key, self) # 如果key是可调用的,则传递self
if is_hashable(key): # 检查key是否可以哈希,即是否可以作为字典的键
if self.columns.is_unique and key in self.columns: # 如果列名是唯一的并且key在列名中
if isinstance(self.columns, MultiIndex): # 如果列是多级索引
return self._getitem_multilevel(key) # 使用多级索引获取项
return self._get_item_cache(key) # 使用缓存获取项
# 尝试将key转换为可以索引的切片对象
indexer = convert_to_index_sliceable(self, key)
if indexer is not None:
if isinstance(indexer, np.ndarray): # 如果索引器是ndarray
indexer = lib.maybe_indices_to_slice(
indexer.astype(np.intp, copy=False), len(self) # 尝试将索引转换为切片
)
if isinstance(indexer, np.ndarray):
return self.take(indexer, axis=0) # 使用ndarray索引取数据
return self._slice(indexer, axis=0) # 使用切片或部分字符串日期索引获取数据
if isinstance(key, DataFrame): # 如果key是DataFrame
return self.where(key) # 返回布尔索引DataFrame
if com.is_bool_indexer(key): # 如果key是布尔索引
return self._getitem_bool_array(key) # 使用布尔数组获取项
# 解释元组作为键的集合,仅对非多级索引的情况
is_single_key = isinstance(key, tuple) or not is_list_like(key)
if is_single_key:
if self.columns.nlevels > 1:
return self._getitem_multilevel(key) # 对多级索引使用键
indexer = self.columns.get_loc(key) # 获取键的位置
if is_integer(indexer): # 如果位置是整数
indexer = [indexer] # 转换为列表
else:
if is_iterator(key): # 如果键是迭代器
key = list(key) # 转换为列表
indexer = self.loc._get_listlike_indexer(key, axis=1)[1] # 获取类似列表的索引器
if getattr(indexer, "dtype", None) == bool:
indexer = np.where(indexer)[0] # 获取布尔索引的位置
data = self._take_with_is_copy(indexer, axis=1) # 根据索引器取数据
if is_single_key:
if data.shape[1] == 1 and not isinstance(self.columns, MultiIndex):
return data._get_item_cache(key) # 如果是单个键,则尝试从缓存获取
return data # 返回索引得到的数据
从这段代码能学习到什么?
- 灵活的索引支持:这段代码展示了如何支持从简单的列名到复杂的布尔索引和多级索引等多种索引方式。
- 类型检查与转换:代码中频繁进行类型检查和转换,这是处理不确定输入时的常见做法。
- 错误和特殊情况的处理:方法中包含了对错误情况的预判和处理,如输入类型的验证和转换。
- 代码的模块化:通过调用 _getitem_multilevel、_get_item_cache、_slice 等方法,代码避免了冗长和重复,提高了可读性和可维护性。
3. 数据设置 __setitem__
功能说明
通过列名设置列数据。
示例:
# 添加新列 'col3'
df['col3'] = [5, 6]
print(df)
输出:
col1 col2 col3
0 1 3 5
1 2 4 6
源码说明
这段代码是 Pandas DataFrame 的 __setitem__ 方法,负责处理对 DataFrame 对象的索引赋值操作。这个方法支持多种数据类型作为键(key)和值(value),其复杂性体现在如何正确地将值分配到指定的键。下面是对该方法的逐行解析,包括补充的注释,解释每行代码的功能和作用。
知识点 处理重复列名
虽然我们能够通过 iloc 正确地更新重复列名的数据,但在实际应用中,最好避免在 DataFrame 中使用重复的列名,因为这会导致数据操作的复杂性显著增加,并增加出错的风险。如果可能,应该在数据处理的早期阶段清理或修改列名,确保每个列名的唯一性。
在第3604行开始 是对列名的判断,可以看到
elif (
is_list_like(value) # 如果value是列表或类似列表结构
and not self.columns.is_unique # 并且列名不唯一
# key对应多列并且value的长度与之匹配
and 1 < len(self.columns.get_indexer_for([key])) == len(value)
):
# 如果要设置的列名是重复的
self._setitem_array([key], value)
else:
# 将列表形式的value赋值到重复的列名上 所有重复的都会被重新赋值
self._set_item(key, value)
让我们通过一个具体的代码示例来展示如何在 DataFrame 中处理不唯一列名的情况。在这个例子中,我们将创建一个包含重复列名的 DataFrame,然后演示如何正确地更新其中的数据以维护数据一致性。
示例代码
假设我们有一个数据集,其中某些列的名字是重复的,现在我们需要更新这些列的数据会导致所有的所有这个列名的值。
import pandas as pd
import numpy as np
# 创建一个具有重复列名的DataFrame
data = {
"A": [1, 2, 3],
"B": [4, 5, 6],
"A": [7, 8, 9] # 重复的列名 "A"
}
df = pd.DataFrame(data)
print("Original DataFrame with duplicate column names:")
print(df)
# 尝试更新第二个 "A" 列的数据
try:
# 这会引起歧义,因为有两个 "A" 列
df['A'] = [10, 11, 12]
except Exception as e:
print(f"Error: {e}")
print("\nDataFrame after attempting to update 'A':")
print(df)
# 正确的更新方法
# 我们先获取所有名为"A"的列的索引,然后指定要更新的列
columns = df.columns.get_loc("A")
df.iloc[:, columns] = [13, 14, 15]
print("\nDataFrame after correctly updating 'A' columns:")
print(df)
下图输入直接变更重复列名的值,被异常捕获了,虽然也能执行成功,但是应该尽量避免

源码逐行解析
def __setitem__(self, key, value):
key = com.apply_if_callable(key, self) # 如果key是可调用的,应用它并更新key
# 尝试将key转换为可以对行进行切片的索引器
indexer = convert_to_index_sliceable(self, key)
if indexer is not None:
# 如果indexer是一个切片或者可以转换为切片(例如部分字符串日期索引)
return self._setitem_slice(indexer, value) # 使用切片进行赋值
# 如果key是DataFrame或者具有两个维度(ndim==2),例如二维数组
if isinstance(key, DataFrame) or getattr(key, "ndim", None) == 2:
self._setitem_frame(key, value) # 使用DataFrame或二维结构设置多个值
elif isinstance(key, (Series, np.ndarray, list, Index)):
self._setitem_array(key, value) # 如果key是一维数组或类似结构,使用数组方式赋值
elif isinstance(value, DataFrame):
self._set_item_frame_value(key, value) # 如果value是DataFrame,按DataFrame赋值
elif (
is_list_like(value) # 如果value是列表或类似列表结构
and not self.columns.is_unique # 并且列名不唯一
and 1 < len(self.columns.get_indexer_for([key])) == len(value) # key对应多列并且value的长度与之匹配
):
# 如果要设置的列名是重复的
self._setitem_array([key], value) # 将列表形式的value赋值到重复的列名上
else:
# 最基本的情况,设置单一列
self._set_item(key, value) # 在DataFrame中设置单个列的值
从这段代码能学习到什么?
-
灵活的参数处理:
__setitem__方法展示了如何处理不同类型的键和值,这包括可调用对象、数据结构(如DataFrame和Series),以及标量值。这种多样性的处理能力是处理复杂数据结构时的一项重要技能。 -
条件逻辑的应用:该方法通过多个
if-elif分支来确定如何处理不同的键和值类型。这种条件逻辑是编写能够应对多种情况的健壮代码的基础。 -
复杂的数据赋值逻辑:处理键值对赋值时,考虑了列名是否唯一、数据维度、以及数据类型等因素,展示了在复杂环境中如何安全地修改数据。
-
数据一致性的维护:在设置数据时考虑了列名的唯一性和数据的对齐问题,这是维护数据一致性和避免数据错误的关键环节。
-
错误和特殊情况的处理:通过对特殊情况的预判和处理,如列名重复或键值对不匹配的情况,增强了方法的健壮性。
4. 数据合并 merge
功能说明
执行类似数据库的表合并操作。
示例:
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2'], 'A': ['A0', 'A1', 'A2']})
df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2'], 'B': ['B0', 'B1', 'B2']})
# 合并 df1 和 df2
result = pd.merge(df1, df2, on='key')
print(result)
输出:
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
源码说明
merge方法本身并不执行合并逻辑,而是将所有参数及自身作为参数传递给另一个负责实际合并操作的函数。这种设计模式(委托)有助于保持代码的组织性和可维护性,尤其是在功能逻辑复杂或可能在多个地方被重用时
我们来看一下merge操作类源码,发现有很多内部的方法,这里做了一些标记,可以看到整体的结构按 输入、输出 - 功能 - 检验 来覆盖所有的方法。此外这里有单一职责原则(每个函数只做一件事情),以及封装(将复杂的逻辑封装在方法内部,对外提供简洁的接口)。通过学习这些方法,在自己的项目中实施类似的模式,提高代码的健壮性和可维护性。
在get_result中,使用 concatenate_block_managers 函数合并左右两侧的数据块管理器,这是合并过程中的核心操作,负责物理合并数据


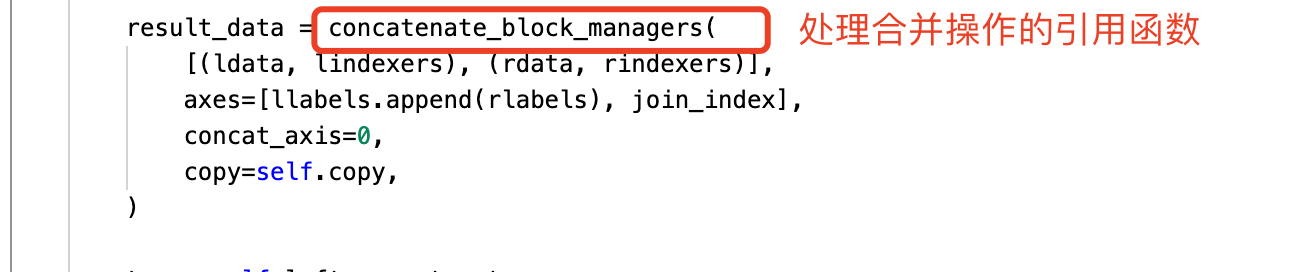
知识点 列表推导式
列表推导式是 Python 中一个非常强大和表达丰富的特性,用于创建列表。这种方式可以将循环和条件判断结合在一起,生成列表,使得代码既简洁又高效。在 concatenate_block_managers 函数中使用的列表推导式是一个很好的例子,展示了如何在实际应用中利用这个特性。
concat_plans = [
get_mgr_concatenation_plan(mgr, indexers) for mgr, indexers in mgrs_indexers
]
这里,concat_plans 通过遍历 mgrs_indexers 列表(每个元素都是一个包含 BlockManager 和索引器的元组)并对每个元素应用 get_mgr_concatenation_plan 函数来构建。
步骤分解
-
输入数据:
mgrs_indexers是一个列表,每个元素都是一个元组,其中包含两个元素:mgr(一个BlockManager对象)和indexers(一个字典,包含索引信息)。 -
循环和映射:这个列表推导式遍历
mgrs_indexers列表中的每个元组。对于每个元组,它将元组中的两个元素分别赋给mgr和indexers。 -
函数应用:对于每个
(mgr, indexers)对,列表推导式调用get_mgr_concatenation_plan函数。这个函数的作用是基于提供的BlockManager(mgr) 和索引字典 (indexers) 生成一个合并计划。 -
输出列表:列表推导式最终生成一个新的列表,该列表包含对每个
mgrs_indexers元素应用get_mgr_concatenation_plan函数后的结果。这意味着每个输入元组都转换成了一个合并计划。
列表推导式的优点
- 简洁性:列表推导式通过一行代码完成了循环遍历、元素处理和列表创建三个任务。
- 可读性:对于熟悉 Python 的开发者来说,列表推导式提供了一种易于理解和直观的方式来表达复杂的逻辑。
- 性能:在许多情况下,列表推导式比等效的传统循环实现更高效,因为它是优化过的 C 语言级别的实现。
使用场景
列表推导式适用于需要从一个列表或任何可迭代对象生成新列表的场景,特别是当生成逻辑包含应用函数、条件过滤等操作时。然而,当逻辑过于复杂或推导式变得难以阅读时,使用传统的循环可能更合适,以保持代码的可读性和维护性。
总的来说,列表推导式是 Python 程序员必备的工具,理解和掌握它可以大大提高编程效率和代码质量。在处理数据处理和转换任务时,它尤其有用,如在数据科学、机器学习等领域。
源码逐行解析
下面是 concatenate_block_managers 函数的逐行解析,包括每行代码的作用和相关注释:
def concatenate_block_managers(mgrs_indexers, axes, concat_axis, copy):
"""
Concatenate block managers into one.
Parameters
----------
mgrs_indexers : list of (BlockManager, {axis: indexer,...}) tuples
axes : list of Index
concat_axis : int
copy : bool
"""
# 创建合并计划,每个元素代表一个BlockManager的合并策略
concat_plans = [
get_mgr_concatenation_plan(mgr, indexers) for mgr, indexers in mgrs_indexers
] # 列表推导:对每个BlockManager及其索引器生成合并计划
# 组合所有的合并计划为一个总的合并计划
concat_plan = combine_concat_plans(concat_plans, concat_axis) # 将多个合并计划合成一个统一计划
# 初始化存储最终合并生成的数据块列表
blocks = [] # 数据块列表,存储最终合并后的各个数据块
# 遍历合并计划中的所有放置位置和参与单位
for placement, join_units in concat_plan:
# 如果只有一个参与单位并且没有索引器
if len(join_units) == 1 and not join_units[0].indexers:
b = join_units[0].block # 获取单个数据块
values = b.values # 获取数据块的值
if copy:
values = values.copy() # 如果需要复制,进行深复制
elif not copy:
values = values.view() # 如果不复制,创建一个视图
b = b.make_block_same_class(values, placement=placement) # 创建同类的新数据块
# 如果所有参与单位都是相同类型
elif is_uniform_join_units(join_units):
b = join_units[0].block.concat_same_type(
[ju.block for ju in join_units], placement=placement # 连接相同类型的数据块
)
else:
# 使用参与单位的数据块创建一个新的数据块
b = make_block(
concatenate_join_units(join_units, concat_axis, copy=copy), # 连接参与单位
placement=placement, # 设置数据块的放置位置
)
# 将创建的新数据块添加到blocks列表中
blocks.append(b) # 向数据块列表中添加新数据块
# 创建并返回一个新的BlockManager,管理所有合并后的数据块
return BlockManager(blocks, axes) # 使用合并后的数据块和轴创建一个新的BlockManager
5. 分组 groupby
功能说明
按条件分组数据,并支持聚合、变换、过滤。
示例:
df = pd.DataFrame({
'Animal': ['Falcon', 'Falcon', 'Parrot', 'Parrot'],
'Max Speed': [380., 370., 24., 26.]
})
# 按 'Animal' 列分组并获取最大速度的平均值
mean_speed = df.groupby('Animal')['Max Speed'].mean()
print(mean_speed)
输出:
Animal
Falcon 375.0
Parrot 25.0
Name: Max Speed, dtype: float64
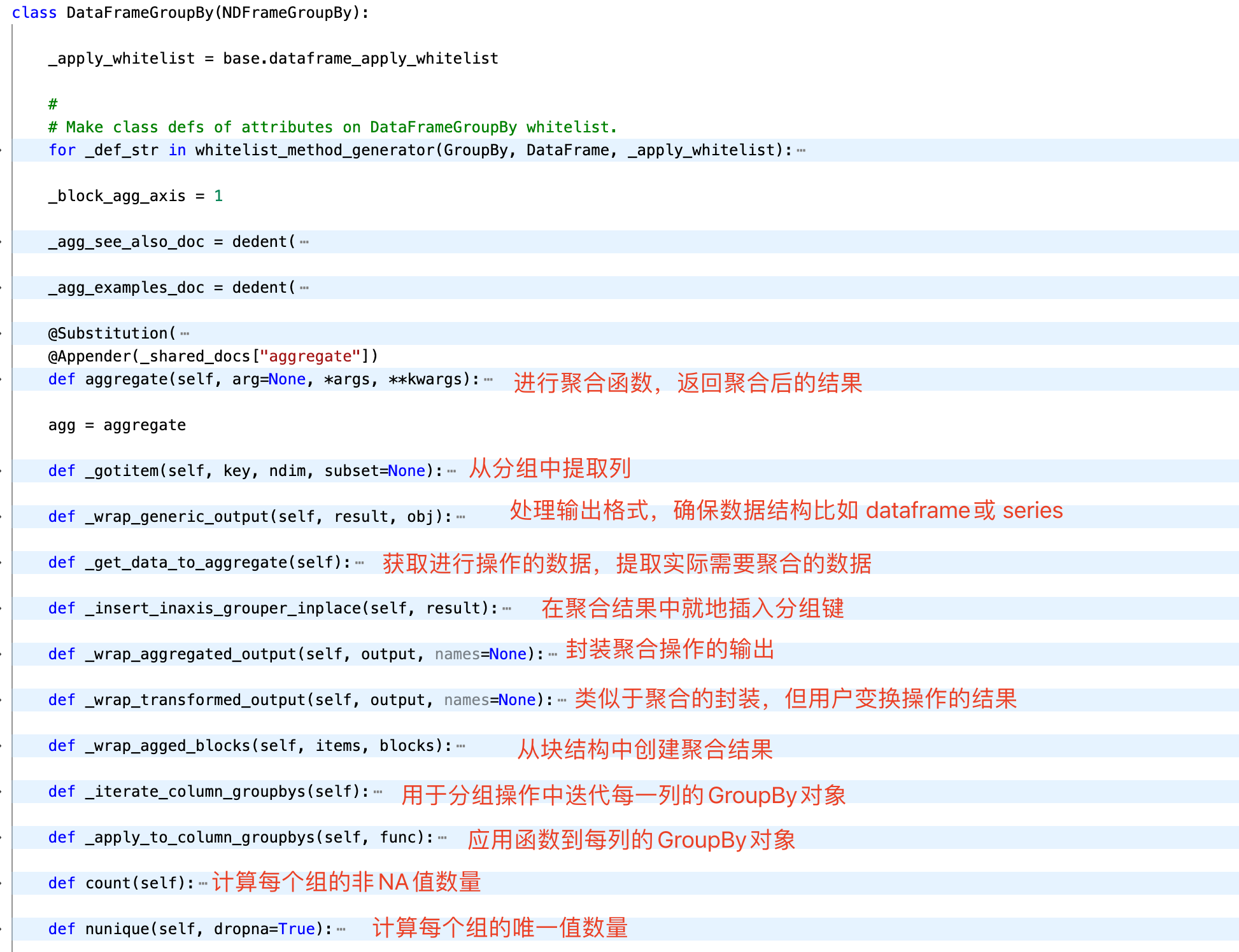
知识点 继承父类
这段是聚合函数,使用了super对父类进行调用

在 Pandas 的源码中,DataFrameGroupBy 类通常继承自 GroupBy 类。GroupBy 类提供了广泛的分组操作的基本功能,包括聚合、过滤、转换和应用(apply)等方法。DataFrameGroupBy 是这些功能的一个具体实现,专门用于处理 DataFrame 对象。
GroupBy: 这是一个更一般的基类,提供了大多数分组操作的实现。它定义了分组操作的通用逻辑,如何聚集数据、如何应用函数等。DataFrameGroupBy: 这个类继承自GroupBy,专门针对DataFrame对象。它可能会添加或重写一些方法以适应DataFrame的特定需求,但大部分功能仍然依赖于GroupBy类提供的实现。
职责与功能:
-
GroupBy类 的主要职责是提供一个高效的接口来处理所有 Pandas 对象(如Series、DataFrame)的分组操作。它处理数据的分割,应用组函数,然后可能将结果合并回一个合适的数据结构中。 -
DataFrameGroupBy类 继承了GroupBy的所有功能,并且针对DataFrame的特定情况进行了优化。例如,它会处理列与列之间的关系,确保在聚合或变换过程中列的对齐和数据完整性。
方法重载:
在 DataFrameGroupBy 中,有些方法可能会被重载以提供更针对 DataFrame 的行为,例如处理列名的冲突、保留索引等。而通过使用 super() 调用,DataFrameGroupBy 可以保留 GroupBy 类的原始行为,并在此基础上添加或修改功能,以适应 DataFrame 的特殊需求。
这种设计模式不仅使得 Pandas 库具有很高的灵活性和扩展性,同时也提供了很高的代码复用性和维护性,允许不同类型的 Pandas 对象共享大量的代码和逻辑,同时保留了进行特定优化的空间。
源码逐行解析
6. 数据透视 pivot
功能说明
用于创建数据透视表,重塑数据。
示例:
df = pd.DataFrame({
'foo': ['one', 'one', 'one', 'two', 'two', 'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']
})
pivot_df = df.pivot(index='foo', columns='bar', values='baz')
print(pivot_df)
输出:
bar A B C
foo
one 1 2 3
two 4 5 6
知识点 使用 MultiIndex 和索引操作
解读:
- Pandas 中的
MultiIndex允许在一个轴上有多个(两个以上)索引级别。这在处理复杂的数据结构时非常有用,特别是当你需要在单个轴上表达更多维度的层次结构时。 - 在这段代码中,
MultiIndex.from_arrays([index, data[columns]])创建了一个两级的索引,这使得每个数据点都可以通过一个由index和columns参数确定的复合键来唯一标识。这对于数据透视非常重要,因为它允许用户根据两个维度来重塑数据。
应用:
- 使用
MultiIndex可以极大地增强数据分析的灵活性和数据表示的丰富性。例如,在金融数据分析中,可以使用MultiIndex来同时按日期和股票代码索引数据。 - 在
pivot函数中,这种索引策略使得将数据从长格式转换为宽格式变得可能,为后续的数据分析和可视化提供了便利。
总结:
这段代码不仅展示了如何使用 Pandas 进行数据透视操作,还突出了 MultiIndex 在实现复杂数据操作中的应用。通过合理使用索引技术,可以有效地提升数据处理任务的效率和灵活性。
源码逐行解析
在这段代码中,我们看到了 Pandas 中的 pivot 函数实现,该函数用于将长格式数据转换成宽格式数据
@Appender(_shared_docs["pivot"], indents=1) # 使用装饰器添加文档字符串,提高代码可维护性和文档的一致性
def pivot(data, index=None, columns=None, values=None):
if values is None: # 当未指定 values 参数时
cols = [columns] if index is None else [index, columns] # 确定用作新索引的列
append = index is None # 决定是否将现有索引保留在结果DataFrame中
indexed = data.set_index(cols, append=append) # 设置新索引,可能保留旧索引
else: # 当指定了 values 参数时
if index is None: # 如果没有明确指定 index,则使用 DataFrame 的当前索引
index = data.index
else: # 如果指定了 index,则从 data 中获取这个 index 列
index = data[index]
index = MultiIndex.from_arrays([index, data[columns]]) # 创建一个多级索引
if is_list_like(values) and not isinstance(values, tuple): # 检查 values 是否为列表类型但不是元组
# 创建一个新的 DataFrame,将指定的 values 列作为数据,多级索引为索引,values 名称作为列名
indexed = data._constructor(
data[values].values, index=index, columns=values
)
else: # 对于单个值字段,使用 _constructor_sliced 创建一个 Series
indexed = data._constructor_sliced(data[values].values, index=index)
return indexed.unstack(columns) # 对指定的 columns 列执行 unstack 操作,将长格式转换为宽格式
7. 数据连接 join
功能说明
join 是用于按照索引合并不同 DataFrame 的方法,它提供了一个便捷的接口来合并多个 DataFrame。
示例:
import pandas as pd
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
df2 = pd.DataFrame({'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']},
index=['K0', 'K2', 'K3'])
# 使用 join 进行连接
result = df1.join(df2)
print(result)
输出:
A B C D
K0 A0 B0 C0 D0
K1 A1 B1 NaN NaN
K2 A2 B2 C1 D1
知识点 错误处理
在这段代码中,错误处理是一个重要的部分。处理错误的方式能够确保函数的健壮性,防止在错误的使用条件下执行不当的操作。
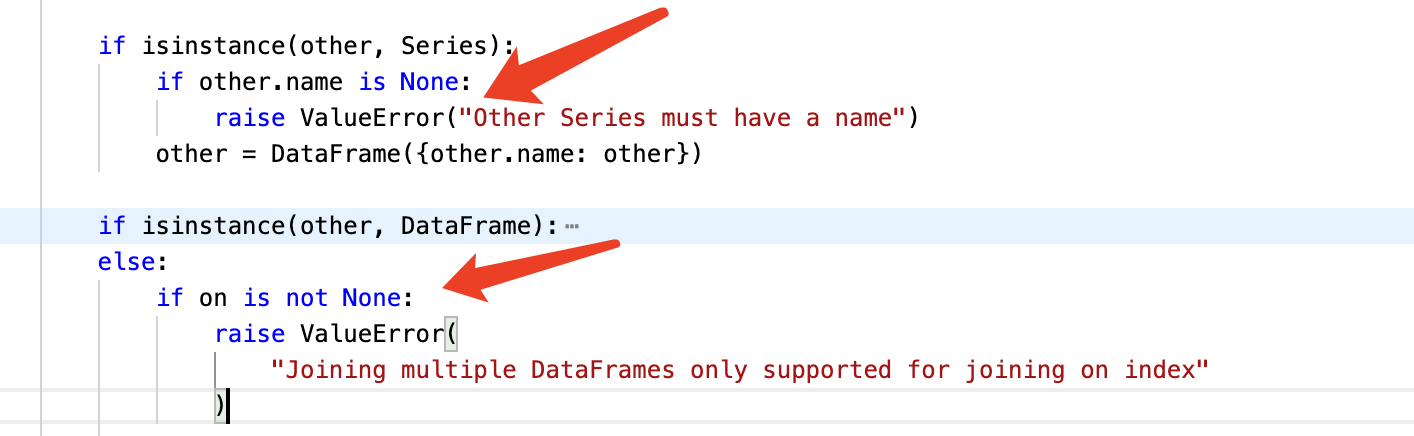
解读:
- 错误检查使用了条件语句来判断
other对象的类型和状态(例如,检查Series是否有名字,检查on是否非空)。 - 通过抛出具体的错误信息(
ValueError),开发者可以立即理解问题所在,这对于调试和使用函数的用户来说都是非常有帮助的。
应用:
- 在实际开发中,合适的错误检查和异常处理可以防止数据损坏和应用崩溃,提高应用的可靠性。
- 通过明确的错误消息,用户可以更快地诊断问题,提高开发效率。
这段代码展示了如何实现复杂的数据合并逻辑,还体现了良好的错误处理和代码结构设计的重要性
源码逐行解析
这段代码定义了一个名为 _join_compat 的方法,用于合并 DataFrame 或 Series 对象。其中还调用了merge和concat下面是逐行解析和注释,以说明每行代码的功能:
def _join_compat(
self,
other: FrameOrSeriesUnion,
on: IndexLabel | None = None,
how: str = "left",
lsuffix: str = "",
rsuffix: str = "",
sort: bool = False,
):
from pandas.core.reshape.concat import concat # 用于拼接数据帧
from pandas.core.reshape.merge import merge # 用于合并数据帧
if isinstance(other, Series): # 检查 other 是否为 Series
if other.name is None: # Series 必须有名字才能进行合并
raise ValueError("Other Series must have a name")
other = DataFrame({other.name: other}) # 将 Series 转换为 DataFrame
if isinstance(other, DataFrame): # 检查 other 是否为 DataFrame
if how == "cross": # 如果合并方式为 cross
return merge(
self,
other,
how=how,
on=on,
suffixes=(lsuffix, rsuffix),
sort=sort,
) # 使用 pandas 的 merge 函数进行交叉合并
return merge(
self,
other,
left_on=on,
how=how,
left_index=on is None,
right_index=True,
suffixes=(lsuffix, rsuffix),
sort=sort,
) # 使用 merge 进行合并,可能使用索引或指定的键
else:
if on is not None:
raise ValueError(
"Joining multiple DataFrames only supported for joining on index"
) # 如果 on 参数非空但 other 不是 DataFrame,抛出错误
frames = [self] + list(other) # 将 self 和 other 组成列表
can_concat = all(df.index.is_unique for df in frames) # 检查所有数据帧的索引是否唯一
# 如果索引唯一,使用 concat 进行拼接
if can_concat:
if how == "left":
res = concat(
frames, axis=1, join="outer", verify_integrity=True, sort=sort
) # 使用 outer 方式拼接,保留所有索引
return res.reindex(self.index, copy=False) # 重新索引到 self 的索引上
else:
return concat(
frames, axis=1, join=how, verify_integrity=True, sort=sort
) # 根据 how 参数决定拼接方式
joined = frames[0] # 初始化 joined 为第一个数据帧
for frame in frames[1:]: # 遍历除第一个外的所有数据帧
joined = merge(
joined, frame, how=how, left_index=True, right_index=True
) # 使用 merge 基于索引进行合并
return joined # 返回最终合并后的结果
8. 数据连接 concat
功能说明
concat 用于沿一定轴将多个对象堆叠到一起。此函数提供了多种选项来处理索引和其他轴上的关系。
示例:
df3 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],
'B': ['B3', 'B4', 'B5']},
index=['K3', 'K4', 'K5'])
df4 = pd.DataFrame({'A': ['A6', 'A7', 'A8'],
'B': ['B6', 'B7', 'B8']},
index=['K6', 'K7', 'K8'])
# 使用 concat 连接
result = pd.concat([df1, df3, df4])
print(result)
输出:
A B
K0 A0 B0
K1 A1 B1
K2 A2 B2
K3 A3 B3
K4 A4 B4
K5 A5 B5
K6 A6 B6
K7 A7 B7
K8 A8 B8
源码说明
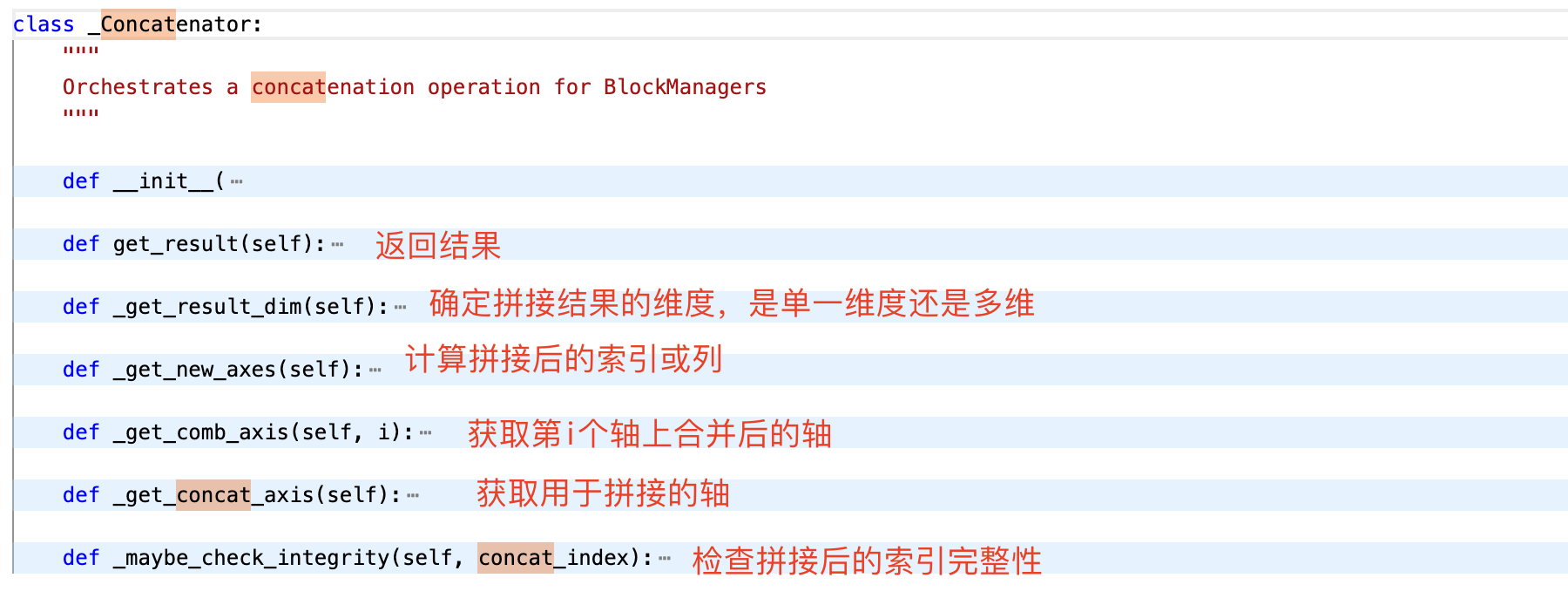
引用了_Concatenator类
知识点 内存管理
在处理 _Concatenator 类的 get_result 方法时,涉及到了条件性数据复制和就地数据操作,这对内存管理非常关键。以下是一段关键代码:

-
条件性数据复制:
concatenate_block_managers函数接收一个copy参数,这允许根据需要控制是否进行数据复制。如果copy设置为False,则尽可能通过引用而非复制来操作数据块,这有助于减少内存消耗。
-
就地合并 (
_consolidate_inplace方法):- 在不复制数据的情况下,
_consolidate_inplace()方法被调用以就地优化和重组内部的数据块结构,这有助于提高内存利用效率。这个方法尝试在不增加额外内存负担的情况下,整合和压缩数据块,从而减少内存碎片和整体内存占用。
- 在不复制数据的情况下,
编程启发
-
使用条件性复制:
- 在设计涉及数据处理和转换的函数时,考虑引入可选的复制控制,让调用者根据需要选择是否进行数据复制。这不仅可以提供灵活性,还能在处理大数据集时提高内存效率。
-
优化内部数据结构:
- 在处理复杂或大型的数据结构时,考虑实现像
_consolidate_inplace这样的方法,对内部数据进行就地优化。这样的方法应该旨在减少数据冗余和内存占用,同时保持数据完整性和访问效率。
- 在处理复杂或大型的数据结构时,考虑实现像
-
延迟数据操作:
- 尽可能延迟数据修改和重整操作直到确实需要,以避免不必要的计算和内存开销。例如,在数据拼接或合并操作中,可以集中处理而非逐步执行,从而利用更有效的数据结构和算法优化性能。
这些策略和编程思想不仅适用于数据处理库的开发,也可以应用于任何需要高效内存管理的软件开发场景中,特别是在处理大规模数据时。
源码逐行解析
def get_result(self):
# series only
if self._is_series: # 判断是否只处理 Series 对象
# stack blocks
if self.axis == 0: # 如果是沿着 index 轴拼接
name = com.consensus_name_attr(self.objs) # 获取 Series 的统一名称
mgr = self.objs[0]._data.concat(
[x._data for x in self.objs], self.new_axes
) # 对所有 Series 的数据块进行拼接
cons = _concat._get_series_result_type(mgr, self.objs) # 获取拼接后的 Series 类型
return cons(mgr, name=name).__finalize__(self, method="concat") # 创建并返回新的 Series 对象
# combine as columns in a frame
else: # 如果是沿着 columns 轴拼接
data = dict(zip(range(len(self.objs)), self.objs)) # 将 Series 对象转换为字典
cons = _concat._get_series_result_type(data) # 获取结果类型
index, columns = self.new_axes # 获取新的索引和列
df = cons(data, index=index) # 创建 DataFrame
df.columns = columns # 设置列名
return df.__finalize__(self, method="concat") # 返回最终的 DataFrame
# combine block managers
else: # 处理 DataFrame 或含 BlockManager 的情况
mgrs_indexers = []
for obj in self.objs:
mgr = obj._data # 获取每个对象的数据管理器
indexers = {}
for ax, new_labels in enumerate(self.new_axes):
if ax == self.axis:
continue # 如果是拼接轴,则跳过重索引
obj_labels = mgr.axes[ax] # 获取当前轴的标签
if not new_labels.equals(obj_labels):
indexers[ax] = obj_labels.reindex(new_labels)[1] # 重新索引并存储索引器
mgrs_indexers.append((obj._data, indexers)) # 存储每个对象的数据管理器和索引器
new_data = concatenate_block_managers(
mgrs_indexers, self.new_axes, concat_axis=self.axis, copy=self.copy
) # 使用 concatenate_block_managers 拼接数据管理器
if not self.copy:
new_data._consolidate_inplace() # 如果不复制数据,则就地合并数据块
cons = _concat._get_frame_result_type(new_data, self.objs) # 获取结果类型
return cons._from_axes(new_data, self.new_axes).__finalize__(
self, method="concat"
) # 创建并返回最终的 DataFrame
9. 添加数据 append
功能说明
append 是一个将一行或多行数据快速追加到 DataFrame 的方法。
示例:
new_row = pd.DataFrame({'A': ['A9'], 'B': ['B9']}, index=['K9'])
result = df1.append(new_row)
print(result)
输出:
A B
K0 A0 B0
K1 A1 B1
K2 A2 B2
K9 A9 B9
源码说明
这段代码定义了 append 方法,用于将数据(DataFrame,Series,字典或列表)追加到现有的 DataFrame 后面,返回一个新的 DataFrame 对象(实际是引用 cconat函数进行操作)。逐行分析如下:
def append(
self,
other,
ignore_index: bool = False,
verify_integrity: bool = False,
sort: bool = False,
) -> DataFrame:
"""
[这里是详细的文档字符串,解释方法的功能和参数]
"""
if isinstance(other, (Series, dict)): # 检查 other 是否为 Series 或字典
if isinstance(other, dict): # 如果 other 是字典
if not ignore_index: # 如果不忽略索引,则抛出错误
raise TypeError("Can only append a dict if ignore_index=True")
other = Series(other) # 将字典转换为 Series 对象
if other.name is None and not ignore_index: # 如果 Series 没有名字且未设置忽略索引
raise TypeError("Can only append a Series if ignore_index=True or if the Series has a name")
index = Index([other.name], name=self.index.name) # 创建一个新索引
idx_diff = other.index.difference(self.columns) # 找出 other 中有而 self 中没有的列
combined_columns = self.columns.append(idx_diff) # 合并列
other = (
other.reindex(combined_columns, copy=False) # 重排 other 以匹配列顺序
.to_frame() # 将 Series 转换为 DataFrame
.T.infer_objects() # 转置并推断对象类型
.rename_axis(index.names, copy=False) # 重命名轴
)
if not self.columns.equals(combined_columns): # 如果列不相等,则重新索引 self
self = self.reindex(columns=combined_columns)
elif isinstance(other, list): # 如果 other 是列表
if not other: # 如果列表为空,不做任何操作
pass
elif not isinstance(other[0], DataFrame): # 如果列表的第一个元素不是 DataFrame
other = DataFrame(other) # 将列表转换为 DataFrame
if (self.columns.get_indexer(other.columns) >= 0).all(): # 如果列完全匹配
other = other.reindex(columns=self.columns) # 重排列以匹配 self
from pandas.core.reshape.concat import concat # 导入 concat 函数
if isinstance(other, (list, tuple)): # 如果 other 是列表或元组
to_concat = [self, *other] # 创建一个列表包含 self 和 other 的所有元素
else:
to_concat = [self, other] # 创建一个列表包含 self 和 other
return (
concat(
to_concat,
ignore_index=ignore_index,
verify_integrity=verify_integrity,
sort=sort,
)
).__finalize__(self, method="append") # 调用 concat,然后使用 __finalize__ 处理结果
10. 数据融合 melt
功能说明:melt 用于将 DataFrame 从宽格式变为长格式,通常用于将多个列融合为一个,非常适用于数据重塑和可视化。
示例:
df = pd.DataFrame({
'A': ['John', 'Alice'],
'B': [28, 24],
'C': ['New York', 'Los Angeles']
})
melted = pd.melt(df, id_vars=['A'], value_vars=['B', 'C'])
print(melted)
输出:
A variable value
0 John B 28
1 Alice B 24
2 John C New York
3 Alice C Los Angeles
总结
除了掌握基本的用法外,通过深入的解析pandas的DataFrame,学习源码的编码习惯和用法能够对我们自己的代码精进有很大帮助,同时整体的代码结构和引用也很复杂后续会继续更新,如果对你有帮助欢迎关注收藏,避免迷路