目录
Meta的LLaMA大模型是一种基于深度学习技术的先进自然语言处理模型,它拥有巨大的参数规模和丰富的知识库,能够理解和生成自然语言文本。这种模型采用了先进的神经网络架构和训练算法,具有强大的智能处理能力,可以应用于各种语言理解和生成任务。

福利:文末有chat-gpt纯分享,无魔法,无限制
Abstract
本文介绍了LLaMA模型,这是一组参数范围从7B到65B的基础语言模型。作者使用数万亿个数据来训练文中模型,并展示了可公开使用数据集就可以训练出先进的模型,而无需使用专有和不可访问的数据集。特别的,LLaMA-13B在大多数基准测试中表现优于GPT-3模型。
Introduction
先前的研究表明,最佳的模型性能不是由最大的模型实现的,而是在更多数据上训练的小型模型实现。尽管训练大型模型来达到一定性能可能更加便宜,在训练时间较长的小型模型推理会更加容易。
文中工作的重点是训练一系列语言模型,通过使用比通常使用的更多数据来进行训练,在不同的推理预算下实现尽可能好的性能。由此产生的模型称为LLaMA,其参数范围从7B到65吧,与现有的最佳LLM相比具有竞争力。例如,LLaMA-13B在大多数基准测试上都优于GPT-3,尽管它的参数规模比GPT-3小10倍。
与GPT-3模型不同,文中训练模型只使用公开可用的数据,而目前大多数现有模型依赖于不公开可用或未标记的数据。
Approach
作者使用标准优化器在大量文本数据上训练大型Transformer模型。
Pre-training Data
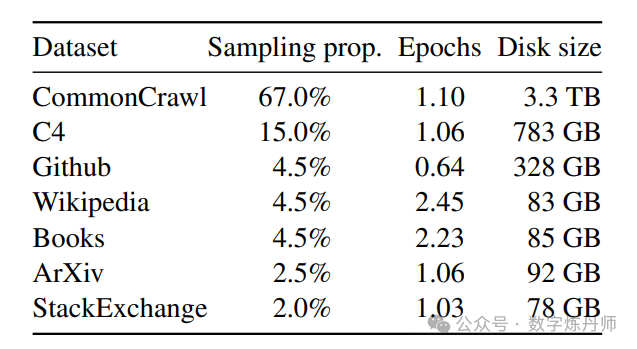
预训练数据集是几个来源的混合,涵盖了各种领域,在多数情况下,重用已被用来训练其他LLM的数据源,但仅限于使用公开且可用于开源兼容的数据。
Tokenizer
作者使用字节对编码算法对数据进行分词,使用PensionPiece来标记数据,作者将所有数据拆分为单个数字,并使用字节以分解未知的UTF-8字符。总体而言,文中的训练数据集在标记化后包含大约1.4T的标记,每个标记在训练期间只使用一次。
Architecture
文中的架构基于Transformer架构,并提出了优化方法,在不同的模型中使用。
Pre-normalization
预规范化,为了提高训练稳定性,作者多每个Transformer子层的输入进行归一化,而不是对输出进行归一化。
SwiGLU激活函数
作者使用了SwiGLU激活函数取代了ReLU函数,以提高性能。
Rotary Embeddings
旋转位置嵌入,作者删除了绝对位置嵌入,而是在网络的每一层添加了旋转位置嵌入。
Optimizer
作者使用AdamW优化器进行模型训练,使用以下超参数:

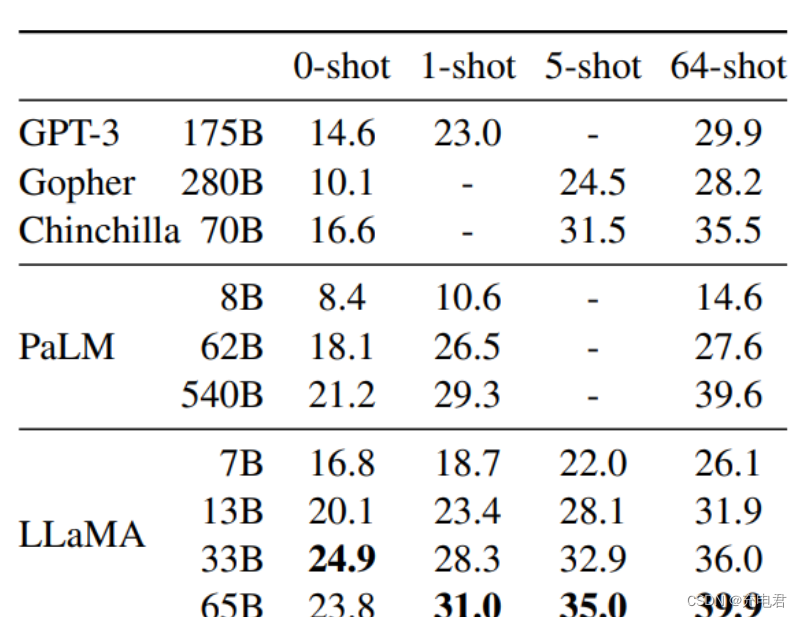
Main results
总结
l总的来说,Meta的LLaMA大模型是一种功能强大、性能卓越的自然语言处理模型,它的出现为人工智能技术的发展注入了新的活力,推动了人工智能技术在自然语言处理、计算机视觉、语音识别等领域的广泛应用,为人类带来了更多的便利和创新。