Hive离线数仓结构

首先,在数据源部分,包括源业务库、用户日志、爬虫数据和系统日志,这些都是数据的源头。这些数据通过Sqoop、DataX或 Flume 工具进行提取和导入操作。这些工具负责将不同来源的数据传输到基于 Hive 的离线数据仓库中。
在离线数据仓库中,数据会依次经过多个处理层。最开始是 ODS(操作数据存储)层,这里存储的是从数据源导入的原始数据。接着数据流向 DWD(数据仓库明细)层,在此层对原始数据进行清洗和预处理,确保数据质量。之后是 DWM(数据仓库中间)层,在这一层进行数据的聚合和整合,生成中间结果。然后是 DWS(数据仓库服务)层,该层主要是为数据分析和应用提供数据服务。最后是DM(数据集市)层,针对特定业务需求进行数据定制和汇总。
在数据仓库处理过程中,分布式离线计算起到了关键作用。图中展示了几种常用的分布式计算框架,包括MapReduce、Hive SQL、Impala和 Spark SQL。这些框架用于处理和分析数据仓库中的数据,确保数据处理的高效性和准确性。
数仓分层
为什么分层?
作为一名数据的规划者,我们肯定希望自己的数据能够有秩序地流转,数据的整个生命周期能够清晰明确被设计者和使用者感知到。直观来讲就是如图这般层次清晰、依赖关系直观。但是,大多数情况下,我们完成的数据体系却是依赖复杂、层级混乱的。在不知不觉的情况下,我们可能会做出一套表依赖结构混乱,甚至出现循环依赖的数据体系。
因此,我们需要一套行之有效的数据组织和管理方法来让我们的数据体系更有序,这就是谈到的数据分层。数据分层并不能解决所有的数据问题,但是,数据分层却可以给我们带来如下的好处:
-
清晰数据结构:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解。
-
复杂问题简单化:将一个复杂的任务分解成多个步骤来完成,每一层解决特定的问题。
-
便于维护:当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
-
减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少重复开发的工作量。
-
高性能:数据仓库的构建将大大缩短获取信息的时间,数据仓库作为数据的集合,所有的信息都可以从数据仓库直接获取,尤其对于海量数据的关联查询和复杂查询,所以数据仓库分层有利于实现复杂的统计需求,提高数据统计的效率。
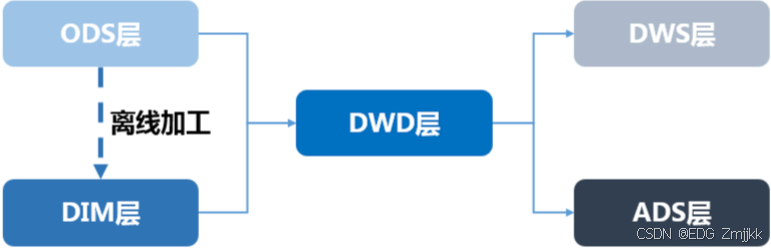
ODS层(操作数据层,Operational Data Store)
数据来源与特点
数据来源广泛:直接从各个业务系统的数据库中抽取而来,如企业的ERP系统、CRM系统、电商平台的交易数据库等。这些数据基本保持了业务系统中原始数据的原貌,包括数据的格式、精度、编码等。
数据实时性强:能够快速获取业务系统中的最新数据,通常是按照一定的时间周期(如每小时、每天)进行增量抽取,以保证数据仓库中的数据与业务系统数据的同步性在可接受范围内。
功能作用
数据集成:将不同业务系统、不同类型的数据整合到一起,解决了数据分散在多个系统中的问题,为后续的数据处理提供了统一的数据基础。
数据缓冲:作为业务数据进入数据仓库的第一层,起到了缓冲的作用,避免了直接对业务系统数据库的频繁查询和读取,减轻了业务系统的压力。
支持快速查询:可以满足一些对实时性要求较高、查询相对简单的业务需求,如实时监控业务数据的变化、快速获取当天的业务订单数量等。
DIM层(维度层,Dimension)
数据构成与特性
维度数据丰富:主要包含了描述业务事实的各种维度信息,如时间维度(年、月、日、时等)、地理维度(国家、地区、城市等)、产品维度(产品类别、品牌、型号等)、客户维度(客户类型、年龄、性别等)。
数据相对稳定:维度数据一旦确定,通常不会频繁更改,具有较高的稳定性。例如,产品的类别和品牌一般不会经常变动。
功能作用
提供分析维度:为数据分析和决策支持提供了丰富的维度视角,通过与其他层的数据进行关联,可以从不同的维度对业务事实进行分析和挖掘。
数据标准化:对维度数据进行统一的编码、分类和标准化处理,确保在整个数据仓库中维度信息的一致性和准确性,便于进行跨部门、跨业务的数据分析和比较。
支持数据钻取:方便用户在数据分析过程中进行维度的上卷和下钻操作,例如从年维度钻取到月维度,或者从产品类别维度下钻到具体的产品型号维度,以满足不同层次的分析需求。
DWD层(明细数据层,Data Warehouse Detail)
数据处理与特征
数据清洗与转换:对从ODS层抽取上来的数据进行清洗,去除噪声数据、重复数据,处理缺失值等,并根据业务规则进行数据转换,如数据类型的统一、字段的拆分和合并等。
明细数据存储:以业务过程为单位,存储经过清洗和转换后的详细业务数据,这些数据能够完整地反映每个业务过程的细节信息,如每一笔订单的详细信息、每一次客户访问的记录等。
功能作用
数据质量提升:通过清洗和转换操作,提高了数据的质量,为后续的数据分析和应用提供了准确、可靠的数据基础。
支持明细查询:能够满足对业务数据进行详细查询和分析的需求,例如查询某一订单的具体交易信息、某一客户在特定时间段内的所有访问记录等。
为数据聚合做准备:作为数据聚合的基础层,为DWS层和ADS层提供了详细的数据支持,便于进行各种维度的汇总和统计分析。
DWS层(汇总数据层,Data Warehouse Summary)
数据汇总方式与特点
基于维度汇总:根据预先定义的业务规则和分析需求,按照一定的维度对DWD层的明细数据进行汇总,如按天、周、月等时间维度对订单金额进行汇总,或者按地区、产品类别等维度对销售量进行汇总。
轻度汇总数据:汇总的程度相对较轻,一般保留了关键的维度信息和汇总指标,既能满足一定的分析需求,又不至于丢失过多的细节信息,具有较好的灵活性和扩展性。
功能作用
提高查询效率:通过预先的汇总计算,大大减少了查询时需要处理的数据量,提高了数据分析的效率,能够快速响应用户的分析请求,如快速获取某个月的销售总额、某个地区的客户活跃度等。
支持综合分析:为企业的综合数据分析和决策支持提供了有力的数据支持,能够从多个维度对业务数据进行综合分析,发现业务的趋势、规律和问题。
数据共享与复用:作为企业内部分享和复用的数据层,不同的业务部门和分析团队可以基于DWS层的数据进行各自的分析和应用开发,减少了重复的数据处理工作。
ADS层(应用数据层,Application Data Store)
数据应用导向与特性
面向应用场景:根据具体的业务应用需求和决策场景而构建,数据具有很强的针对性和实用性,如为营销活动提供目标客户名单、为财务报表提供数据支持、为运营监控提供关键指标数据等。
数据形式多样:可以是报表、仪表盘、数据接口等多种形式,以满足不同用户和业务场景的需求。
功能作用
支持业务决策:直接为企业的业务决策提供数据支持,通过对数据的分析和展示,帮助决策者快速了解业务现状、发现问题、制定决策方案。
数据交付与输出:作为数据仓库与业务应用的接口层,将经过处理和分析的数据以合适的形式交付给业务用户,实现了数据仓库与业务应用的有效衔接,促进了数据的价值转化和应用落地。