随着网络的普及和信息爆炸式增长,我们可以通过网络来获取各种各样的数据。而Python作为一门强大而灵活的编程语言,可以帮助我们快速地从HTML网页中提取数据。本文将介绍Python爬虫的入门知识,并详细讲解如何使用Python爬虫来爬取HTML网页上的数据。
在做数据抓取前我们需要从下面几个方法来入手:
1.了解HTML和网页结构
2.安装和导入相关依赖库
3.发送http请求获取网页内容
4.解析HTML网页内容
5.定位内容和提取数据
6.保存抓取的数据
一、了解HTML和网页结构
在开始编写爬虫之前,了解HTML和网页的结构是非常重要的。HTML是一种标记语言,用来描述网页的结构,它由各种标签(tag)和属性组成。在爬取HTML网页时,我们需要了解网页的结构,明确要爬取的数据所在的标签和属性。
\1. DOCTYPE声明:位于网页的顶部,用来指定网页所使用的HTML版本。
\2. head部分:位于DOCTYPE声明之后,用来定义网页的元数据和链接外部文件,包括标题(title)、引入CSS样式表、引入JavaScript脚本等。
\3. body部分:位于head部分之后,用来定义网页的实际内容。可以包括标题、段落、图片、链接、表格、列表等。
HTML标签通过尖括号(<>)进行标记,有两种类型的标签:起始标签和结束标签。起始标签用来标记元素的开始,结束标签用来标记元素的结束。例如,<p>是一个段落的起始标签,</p>是一个段落的结束标签。
标签可以包含属性,用来提供更多的信息。属性以键值对的形式出现在标签的起始标签中,例如<img src="image.jpg" alt="图片">,其中src和alt就是img标签的属性。
另外,HTML还有一些常见的元素,如链接元素(<a>)、图片元素(<img>)、标题元素(<h1>到<h6>)、列表元素(<ul>、<ol>和<li>)等,这些元素可以用来构建网页的结构和内容。
通过理解HTML和网页的结构,我们可以更好地进行数据爬取。可以通过使用BeautifulSoup库或者查看网页源代码来分析网页的结构,找到我们需要爬取的数据所在的标签和属性,进而进行相应的数据提取。
二、安装和导入相关库
Python有很多库可以用来进行网页爬取,最常见的是BeautifulSoup库和requests库。我们需要先安装这些库,并在代码中导入它们。
# -*- coding: UTF-8 -*-import osimport timeimport requestsfrom bs4 import BeautifulSoupfrom openpyxl import Workbook
三、发送HTTP请求获取网页内容
演示网页地址:https://www.maigoo.com/news/484526.html
(注:演示地址为真实网页地址,请勿做非法侵入,如有侵权请联系本人删除文章。)
使用requests库可以发送HTTP请求来获取网页的内容。我们可以使用get方法发送一个HTTP GET请求,并将网页的内容保存到一个变量中。
# 创建Excel文件wb = Workbook()ws = wb.active
*#* *爬取地址
*
url = f'https://www.maigoo.com/news/484526.html'
*#* *请求**header
*header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/112.0.0.0 Safari/537.36',
'cookie': '__yjs_duid=1_b1ac9fc87dce4de5552d7cf0924fb4981686228951567; u=b0281776fd75d3eefeb3562b2a5e6534; '
'__bid_n=1889b14047a51b2b754207; '
'FPTOKEN=qU+ieOMqkW6y6DlsOZ+D/T'
'+SCY6yS3dYvGXKibFoGBijKuUuSbc3ACFDzjlcC18wuDjNLENrw4ktAFAqnl3Akg492Lr4fbvNrkdJ'
'/ZQrluIdklkNDAKYnPrpcbe2H9y7AtX+/b+FCTkSTNv5+qB3OtQQ3BXXsEen72oEoAfK+H6'
'/u6ltZPdyHttJBJiXEDDS3EiUVt+S2w+8ozXENWbNt/AHeCgNUMmdeDinAKCR+nQSGK/twOoTLOU/nxBeSAazg'
'+wu5K8ooRmW00Bk6XAqC4Cb829XR3UinZHRsJxt7q9biKzYQh'
'+Yu5s6EHypKwpA6RPtVAC1axxbxza0l5LJ5hX8IxJXDaQ6srFoEzQ92jM0rmDynp+gT'
'+3qNfEtB2PjkURvmRghGUn8wOcUUKPOqg==|mfg5DyAulnBuIm/fNO5JCrEm9g5yXrV1etiaV0jqQEw=|10'
'|dcfdbf664758c47995de31b90def5ca5; PHPSESSID=18397defd82b1b3ef009662dc77fe210; '
'Hm_lvt_de3f6fd28ec4ac19170f18e2a8777593=1686322028,1686360205; '
'history=cid%3A2455%2Ccid%3A2476%2Ccid%3A5474%2Ccid%3A5475%2Ccid%3A2814%2Cbid%3A3667; '
'Hm_lpvt_de3f6fd28ec4ac19170f18e2a8777593=1686360427'}
response = requests.get(url, headers=header)
time.sleep(0.01)# print(response)
四、解析HTML内容
通过F12打开网页自带的调试功能,找到需要抓取数据的内容。
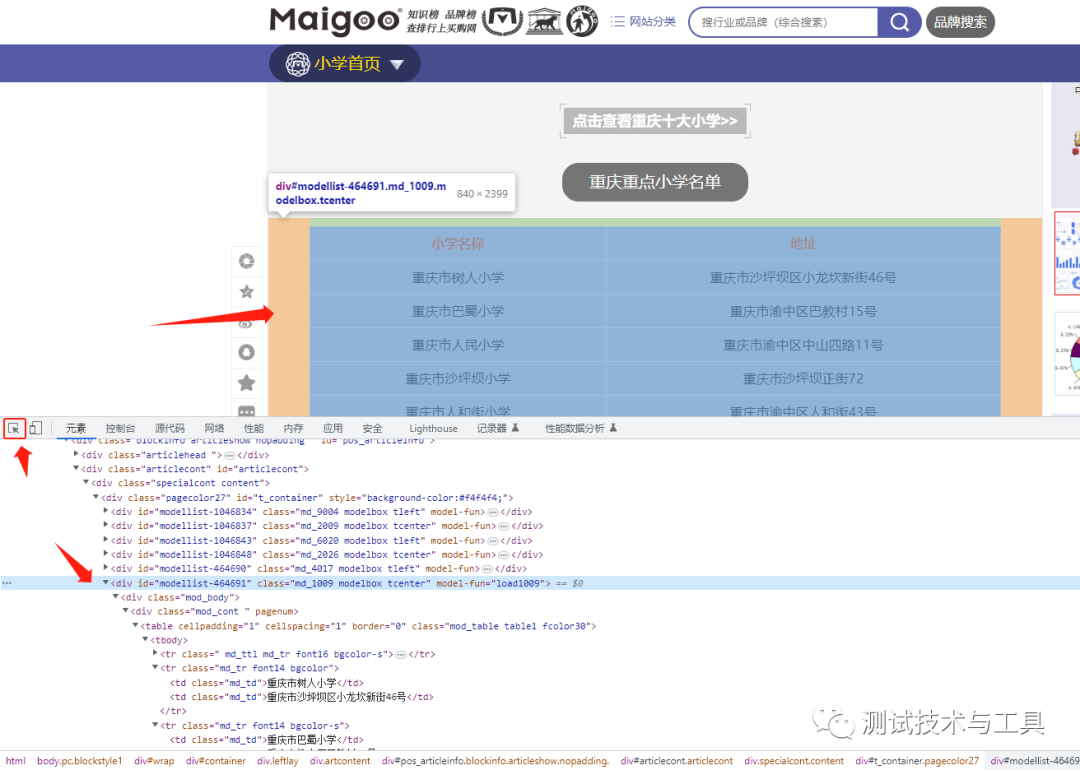
通过BeautifulSoup库可以对HTML内容进行解析。我们可以将网页的内容传入BeautifulSoup的构造函数中,并指定解析器。解析后的内容可以通过调用BeautifulSoup对象的方法来访问和过滤。
# 获取网页信息# soup = BeautifulSoup(response.content, 'lxml')soup = BeautifulSoup(response.content, 'html.parser')# print(soup)# 解析网页数据# tr_tags = soup.find('div', class_="md_1009 modelbox tcenter").get_text()tr_tags = soup.find_all('div', class_="md_1009 modelbox tcenter")# print(tr_tags)
五、定位和提取数据
通过分析网页的结构,我们可以找到要爬取的数据所在的标签和属性。在使用BeautifulSoup库时,可以使用CSS选择器或XPath语法来定位和提取数据。通过调用相应的方法,我们可以获取到所需的数据,例如获取文本内容、获取属性值等。
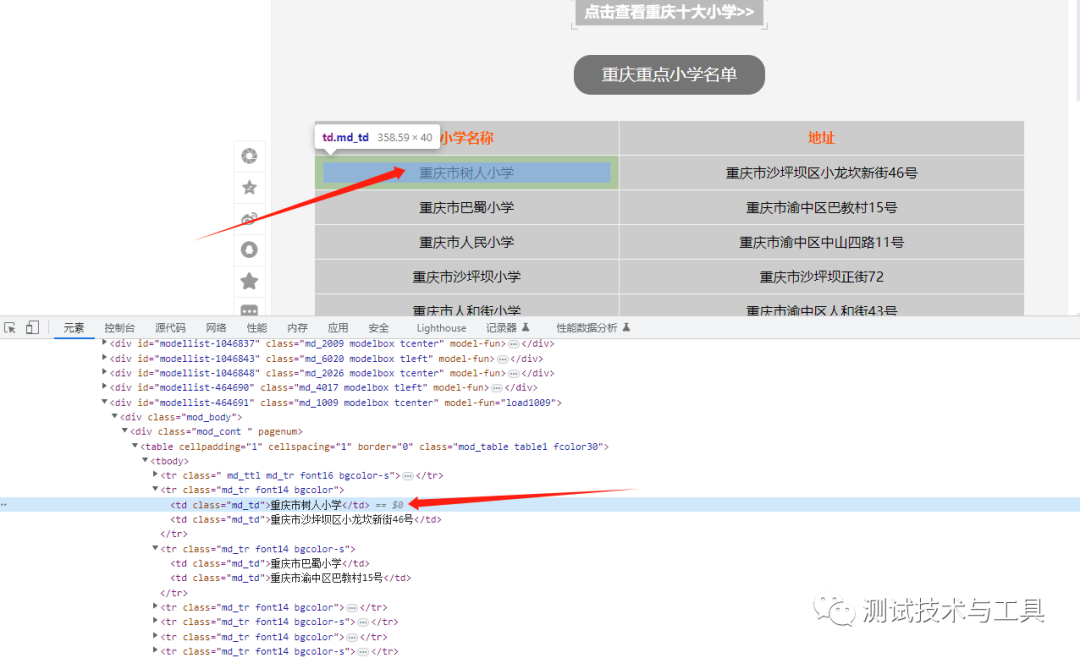
# 循环遍历获取tr标签下的td标签文本td_tags = soup.select('tr td')for i in range(0, len(td_tags), 2): school_name = td_tags[i].get_text() address = td_tags[i + 1].get_text() # score = td_tags[i + 2].get_text() time.sleep(0.1) print(f'正在爬取:--{school_name}--{address}--') # 将数据项转换为一个元组 row = (school_name, address) # 将数据行写入 Excel 表格 ws.append(row)
六、保存爬取的数据
最后,我们可以将爬取到的数据保存到本地文件或数据库中。可以使用Python的文件操作来保存数据到文件中,也可以使用数据库操作库来保存数据到数据库中。
# # 将文件保存到桌面desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")file_path = os.path.join(desktop_path, "学校数据爬取.xlsx")wb.save(file_path)
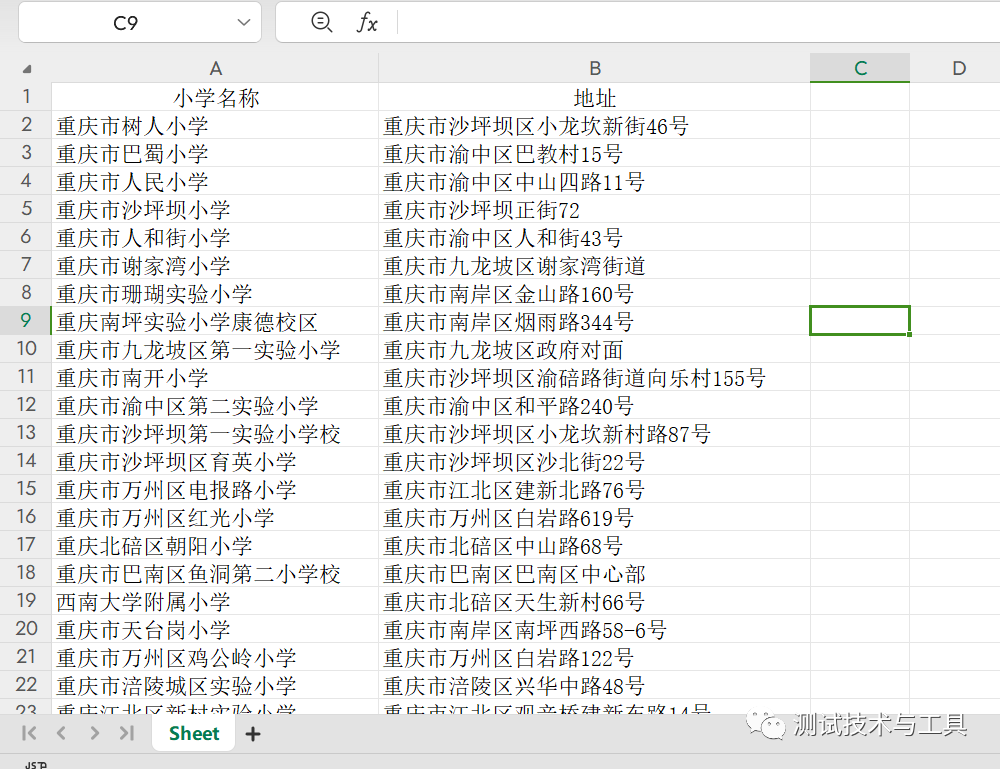
打开桌面爬取的Excel数据,我们想要的数据已经全部爬取到Excel文件中了。
七、注意事项
在进行网页爬取时,需要遵守网站的规则和法律法规。不要频繁发送请求,以免给目标网站造成过大的负担。此外,获取到的数据应该进行合法和合规的使用。
八、完整源码分享
如有需要同学可以拿去看看,源码开箱即用,但需要注意Python环境的搭建和相关依赖库的安装。
# -*- coding: UTF-8 -*-import osimport timeimport requestsfrom bs4 import BeautifulSoupfrom openpyxl import Workbook# 创建Excel文件wb = Workbook()ws = wb.active# 爬取地址url = f'https://www.maigoo.com/news/484526.html'# 请求headerheader = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/112.0.0.0 Safari/537.36', 'cookie': '__yjs_duid=1_b1ac9fc87dce4de5552d7cf0924fb4981686228951567; u=b0281776fd75d3eefeb3562b2a5e6534; ' '__bid_n=1889b14047a51b2b754207; ' 'FPTOKEN=qU+ieOMqkW6y6DlsOZ+D/T' '+SCY6yS3dYvGXKibFoGBijKuUuSbc3ACFDzjlcC18wuDjNLENrw4ktAFAqnl3Akg492Lr4fbvNrkdJ' '/ZQrluIdklkNDAKYnPrpcbe2H9y7AtX+/b+FCTkSTNv5+qB3OtQQ3BXXsEen72oEoAfK+H6' '/u6ltZPdyHttJBJiXEDDS3EiUVt+S2w+8ozXENWbNt/AHeCgNUMmdeDinAKCR+nQSGK/twOoTLOU/nxBeSAazg' '+wu5K8ooRmW00Bk6XAqC4Cb829XR3UinZHRsJxt7q9biKzYQh' '+Yu5s6EHypKwpA6RPtVAC1axxbxza0l5LJ5hX8IxJXDaQ6srFoEzQ92jM0rmDynp+gT' '+3qNfEtB2PjkURvmRghGUn8wOcUUKPOqg==|mfg5DyAulnBuIm/fNO5JCrEm9g5yXrV1etiaV0jqQEw=|10' '|dcfdbf664758c47995de31b90def5ca5; PHPSESSID=18397defd82b1b3ef009662dc77fe210; ' 'Hm_lvt_de3f6fd28ec4ac19170f18e2a8777593=1686322028,1686360205; ' 'history=cid%3A2455%2Ccid%3A2476%2Ccid%3A5474%2Ccid%3A5475%2Ccid%3A2814%2Cbid%3A3667; ' 'Hm_lpvt_de3f6fd28ec4ac19170f18e2a8777593=1686360427'}response = requests.get(url, headers=header)time.sleep(0.01)# print(response)# 获取网页信息# soup = BeautifulSoup(response.content, 'lxml')soup = BeautifulSoup(response.content, 'html.parser')# print(soup)# 解析网页数据# tr_tags = soup.find('div', class_="md_1009 modelbox tcenter").get_text()tr_tags = soup.find_all('div', class_="md_1009 modelbox tcenter")# print(tr_tags)# 循环遍历获取tr标签下的td标签文本td_tags = soup.select('tr td')for i in range(0, len(td_tags), 2): school_name = td_tags[i].get_text() address = td_tags[i + 1].get_text() # score = td_tags[i + 2].get_text() time.sleep(0.1) print(f'正在爬取:--{school_name}--{address}--') # 将数据项转换为一个元组 row = (school_name, address) # 将数据行写入 Excel 表格 ws.append(row)# # 将文件保存到桌面desktop_path = os.path.join(os.path.expanduser("~"), "Desktop")file_path = os.path.join(desktop_path, "重庆市小学爬取.xlsx")wb.save(file_path)print('数据爬取完成!')
-END-
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、机器学习、自动化测试带你从零基础系统性的学好Python!
👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)
👉Python学习大礼包👈
👉Python学习路线汇总👈
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取哈)
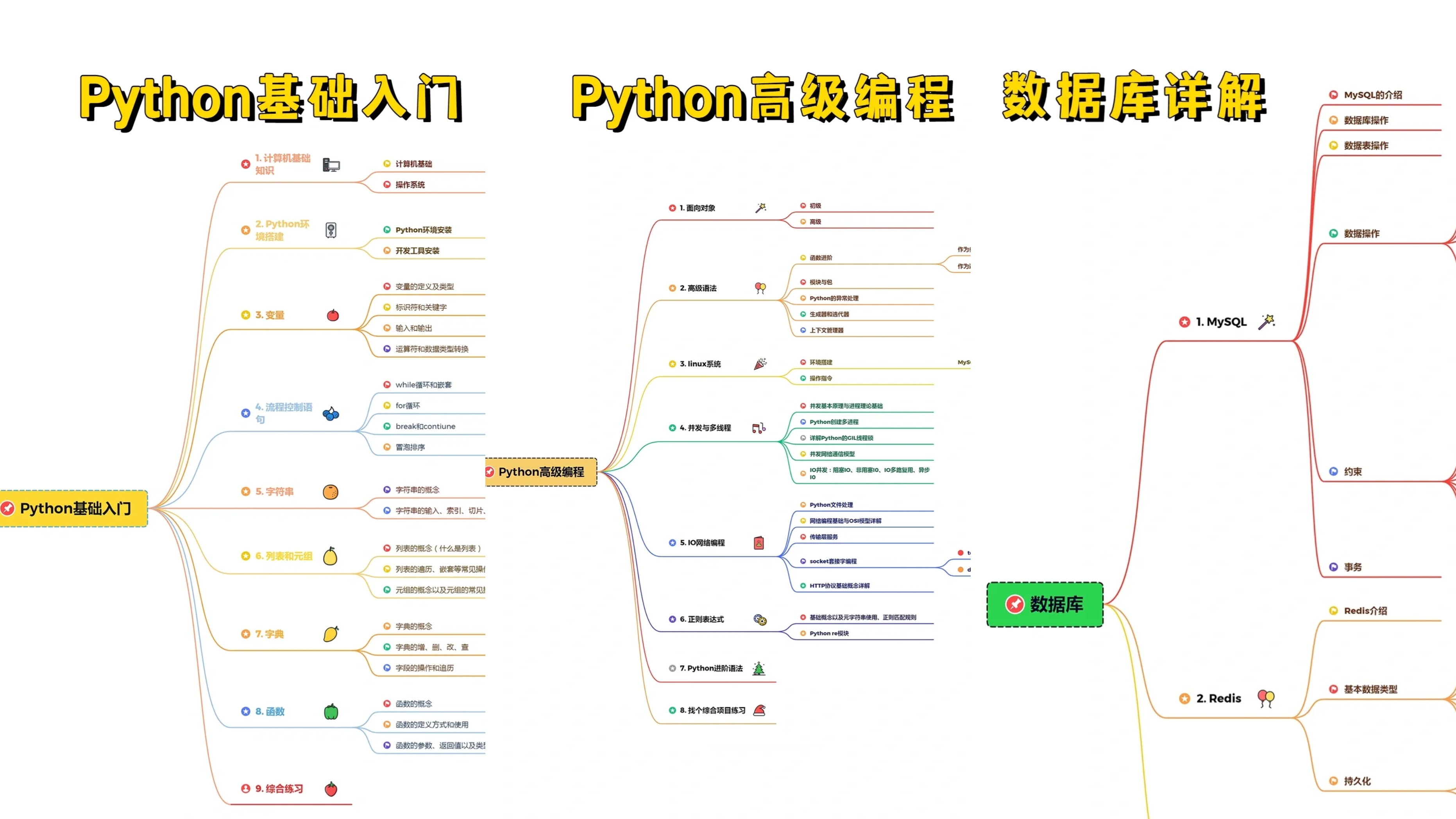
👉Python必备开发工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python书籍和视频合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉Python面试刷题👈
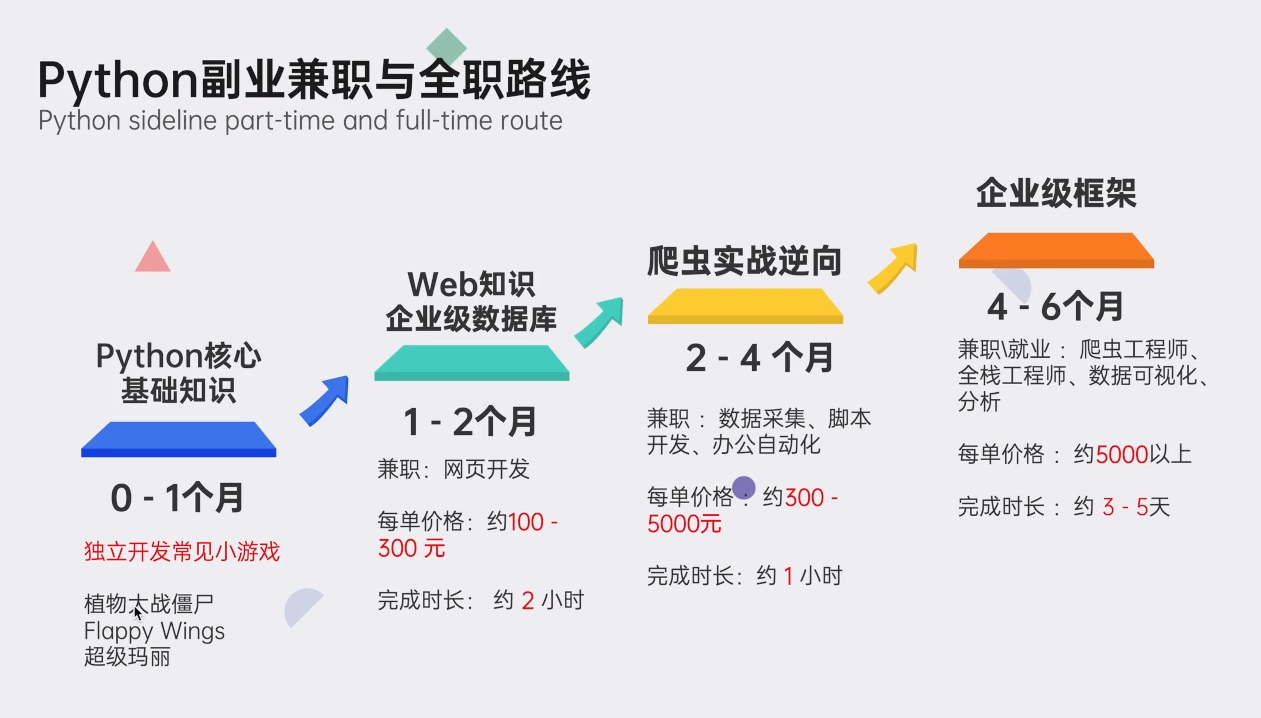
👉Python副业兼职路线👈
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以点击链接免费领取或者保存图片到wx扫描二v码免费领取 【保证100%免费】

👉[CSDN大礼包:《python安装工具&全套学习资料》免费分享](安全链接,放心点击)
