一、摘要
本文介绍由Meta和芝加哥大学合作发表的代码开源论文《Beyond Reward Hacking: Causal Rewards for Large Language Model Alignment》,论文引入了一种将因果正则化纳入训练过程的奖励建模因果框架,使模型能够从虚假关系中学习 “真实” 因果关系,从而让模型生成结果更可靠地与人类偏好对齐。

译文:
大型语言模型(LLMs)的最新进展在执行复杂任务方面取得了显著进步。虽然人类反馈强化学习(RLHF)在使 LLMs 与人类偏好对齐方面是有效的,但它容易受到奖励建模中的虚假相关性的影响。因此,它经常引入偏差,如长度偏差、谄媚、概念偏差和歧视,这些偏差阻碍了模型捕捉真实因果关系的能力。为了解决这个问题,我们提出了一种新颖的因果奖励建模方法,它整合了因果推理来减轻这些虚假相关性。我们的方法强制实施反事实不变性,确保在不相关变量改变时奖励预测保持一致。通过在合成数据集和真实数据集上的实验,我们表明我们的方法有效地减轻了各种类型的虚假相关性,从而使 LLMs 与人类偏好的对齐更加可靠和公平。作为对现有 RLHF 工作流程的即插即用增强,我们的因果奖励建模为提高 LLM 微调的可信度和公平性提供了一种实用的方法。
二、核心创新点
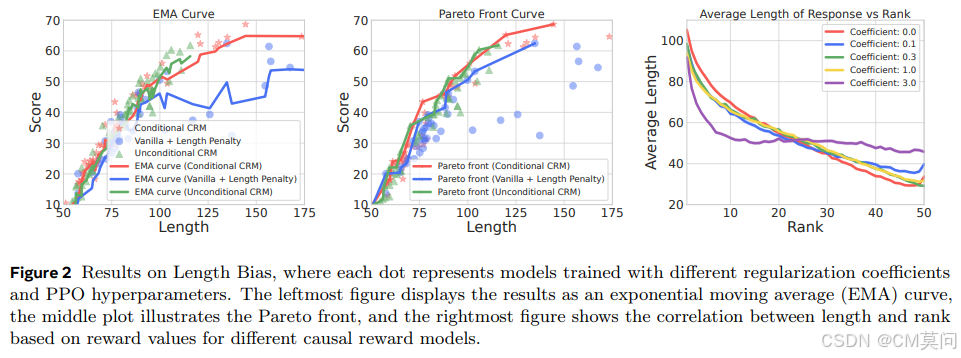
在探讨论文创新点之前,我们首先需要了解如下两个概念。这里,令Z表示对应于虚假变异因素(例如长度)的随机变量,T表示包含提示-响应对(prompt-response pair)的随机变量:
- 反事实不变性(counterfactual invariance):论文指出,理想的无偏奖励模型应该直观地对虚假的变化因素保持不变性。例如,为了消除长度偏差,奖励模型应该对响应长度的变化表现出不变性,为了形式化这个概念,学界定义为“反事实不变性”。
- 因果分解:提示-响应对 T 可以根据它们与虚假因素 Z 的关系分解为潜在成分。具体来说,令
定义为 T 的一个成分,它不受 Z 的因果影响。即,
1、针对独立性的最大均值差异(MMD)正则化
为了强制执行论文中所提到的独立性条件,作者采用了一种基于核的统计度量——MMD,用于量化两个概率分布之间的差异。形式上,给定两个分布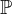
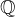
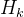
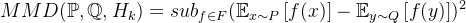
其中,F表示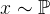
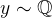
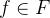
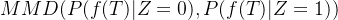
当Z跨越一个大的或者连续的空间,例如响应长度时,直接应用MMD会在计算上变得复杂,因此作者将Z划分为M个离散的区间,并计算所有区间对之间的MMD。令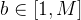
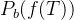
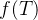
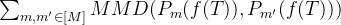
这种分区方法确保了MMD在高维或者连续设置中的适用性,同时保留了捕获Z变化的能力。论文中,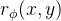
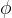
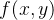

为了正则化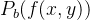
其中,是sigmoid函数,