评论区有同学提出来中文过滤的问题,之前的版本确实没有想到,请参考最新应用正则表达式过滤的版本:
package com.test;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Test {
public static void main(String[] args) {
try {
showCounts();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void showCounts() throws IOException {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
System.out.println("Please input something:");
String str=br.readLine();
char[] chs=str.toCharArray();
int chineseCount=0;
int letterCount=0;
int digitalCount=0;
int spaceCount=0;
int otherCount=0;
for(char ch:chs) {
if((ch+"").matches("[\u4e00-\u9fa5]")) {
chineseCount++;
}else if((ch+"").matches("[a-zA-Z]")) {
letterCount++;
}else if((ch+"").matches("[0-9]")) {
digitalCount++;
}else if((ch+"").matches(" ")) {
spaceCount++;
}else {
otherCount++;
}
}
System.out.println("中文字符:"+chineseCount);
System.out.println("英文字符:"+letterCount);
System.out.println("数字字符:"+digitalCount);
System.out.println("空格字符:"+spaceCount);
System.out.println("其他字符:"+otherCount);
}
}
console测试
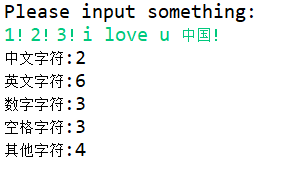
这是朴实无华的分割线,下面的代码已过时
package t6;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
public class Test {
public static void test() {
BufferedReader br=new BufferedReader(new InputStreamReader(System.in));
String str="";
System.out.println("请输入一行字符:");
try {
str = br.readLine();
} catch (IOException e) {
e.printStackTrace();
}
char[] charArr=str.toCharArray();
int letterCount=0;
int spaceCount=0;
int digitalCount=0;
int otherCount=0;
for(char ch:charArr) {
if(Character.isLetter(ch)) {
letterCount++;
}else if(Character.isSpace(ch)) {
spaceCount++;
}else if(Character.isDigit(ch)) {
digitalCount++;
}else {
otherCount++;
}
}
System.out.println("英文字数:"+letterCount);
System.out.println("空格字数:"+spaceCount);
System.out.println("数字字数:"+digitalCount);
System.out.println("其他字数:"+otherCount);
}
}