欢迎浏览高耳机的博客
希望我们彼此都有更好的收获
感谢三连支持!

 https://blog.csdn.net/Chunfeng6yugan/article/details/144005872?spm=1001.2014.3001.5502
https://blog.csdn.net/Chunfeng6yugan/article/details/144005872?spm=1001.2014.3001.5502🙉在(上)篇博客中,我们初步了解了HTTP协议的基本工作原理,包括它的工作过程,学习了如何使用Fiddler这个强大的抓包工具来捕捉和分析网络请求与响应。现在让我们继续深入,探讨与URL、HTTP方法(Method)、Cookie以及状态码等更为细节的内容。
目录
URL 唯一资源定位符
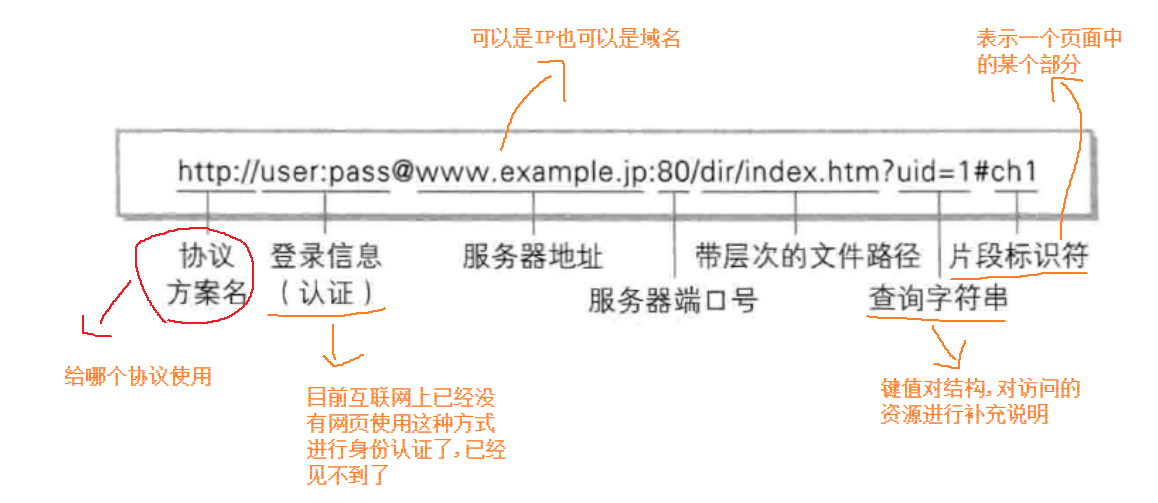
🍍平时大家俗称的“网址”其实就是指URL(Uniform Resource Locator 统一资源定位符)。
互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。
URL的详细规则由因特网标准RFC1738进行了约定 RFC 1738 - Uniform Resource Locators (URL)
URL encode

🥥自定义查询字符串通常是为了处理特定情况或绕过某些限制。在处理中文字符(如UTF-8或GBK编码)时,可能会遇到一个问题:某些中文字符的某个字节与特殊字符的ASCII码值相同。这可能会导致在URL中传递参数时出现混淆或错误。如果直接将这些字符作为查询字符串的一部分,可能会导致服务器端解析错误或数据丢失。
像 / ? : + 等这样的字符,已经被URL当做特殊意义理解了。因此这些字符不能随意出现。 参数中需要带有这些特殊字符,就必须先对特殊字符进行转义。
转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
例如:
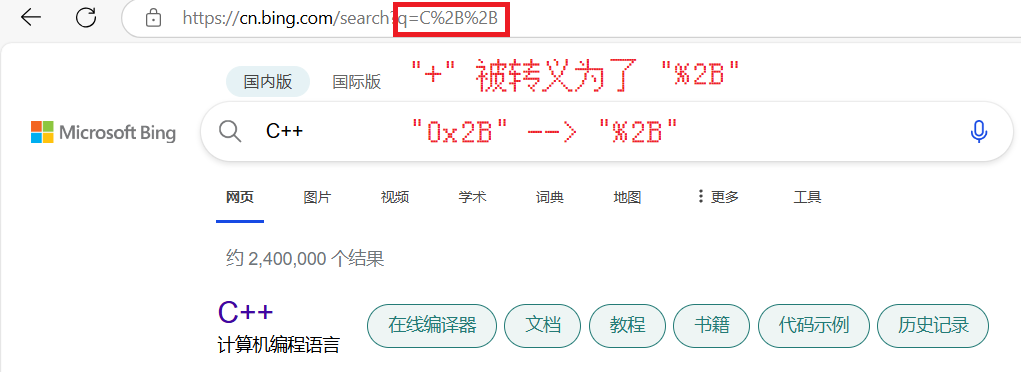
搜索 "C++" :
搜索 "冰冷的蓝色" :
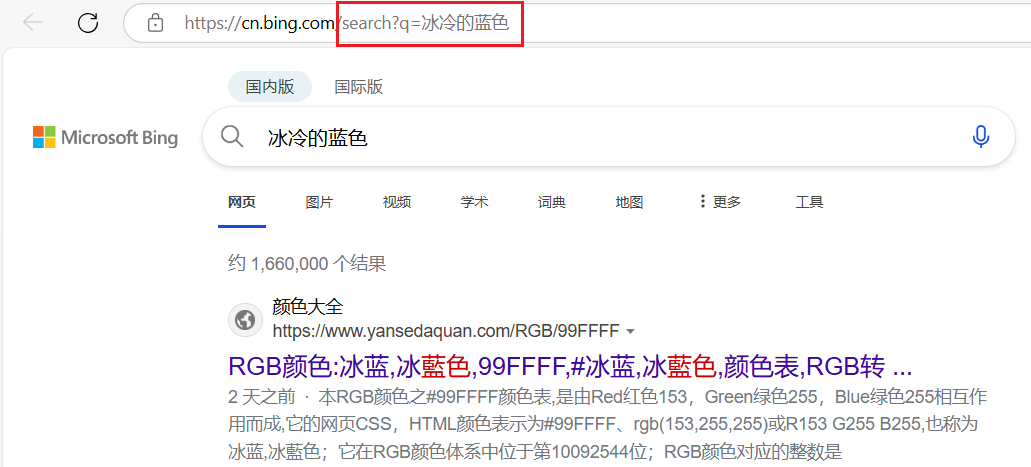
🍑此时地址栏并没有显示转义后的数据,这里的显示其实是浏览器的特殊处理,实际网络传输的URL还是encode之后的。
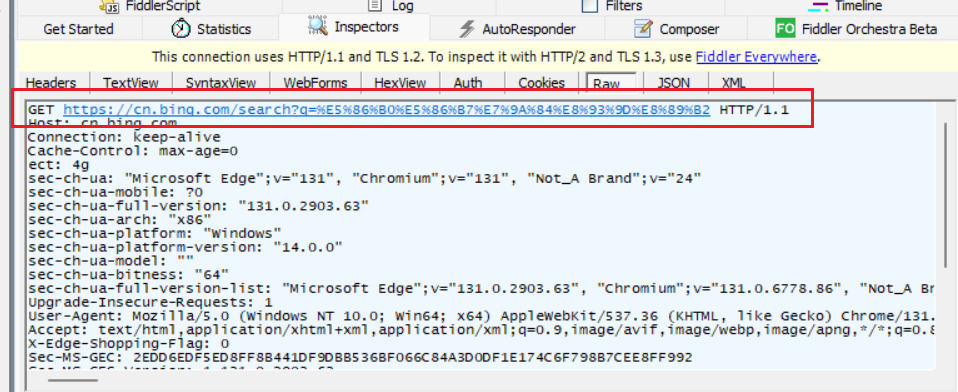
通过Fiddler对本次搜索进行抓包,可以获取到 GET 请求的真实数据。
通过在线小工具进行手动转义查看 : UrlEncode编码/UrlDecode解码 - 站长工具
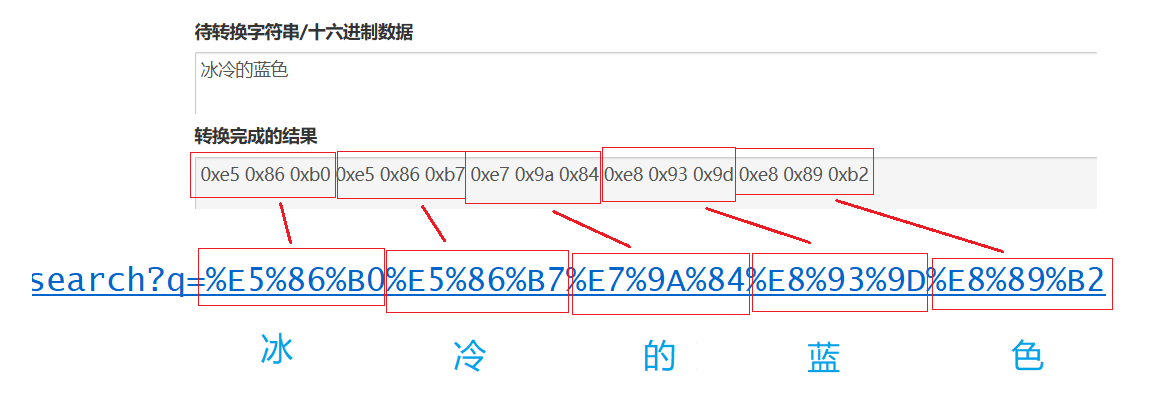
验证了查询字符串的确已被转义
HTTP方法 Method
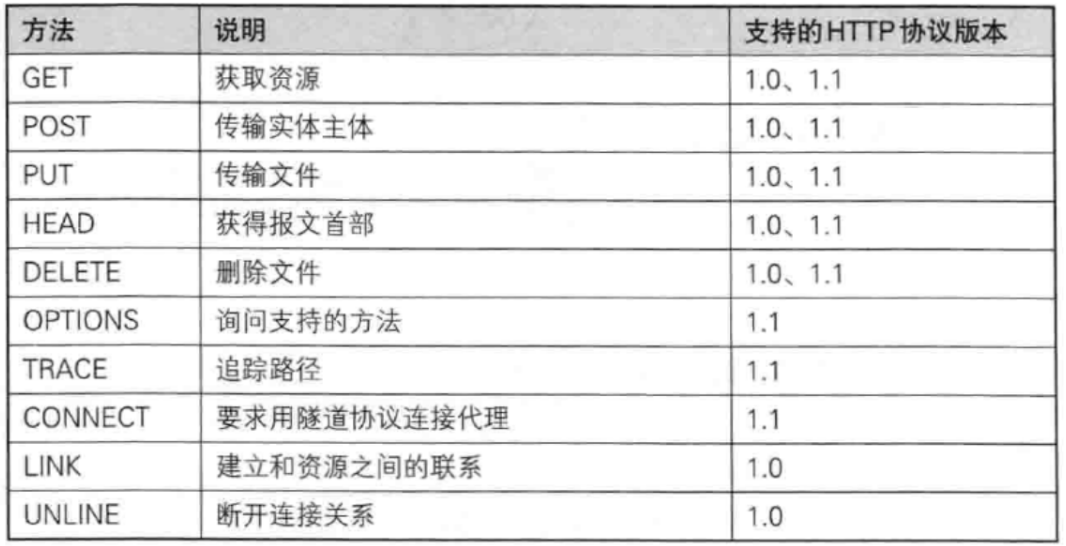
方法 描述了HTTP请求的 "动作"
🥑东晋谢灵运有云:
“天下才共十斗,曹子建(曹植)独得八斗,我得一斗,自古及今共分一斗。”
🍓而如今的HTTP方法的使用率也是如此:
“HTTP方法共十斗,GET独得八斗,POST得一斗,其余共分一斗。”
因此对于其余方法,仅作了解。
GET 方法
🫐GET是最常用的HTTP方法,常用于获取服务器上的某个资源。 在浏览器中直接输入URL,此时浏览器就会发送出一个GET请求。
另外,HTML中的link、img、script等标签,也会触发GET请求。以及JavaScript中的ajax也能构造GET请求。
使用 Fiddler 观察 GET 请求 🍎访问CSDN首页,观察抓包结果 :
1) 直接在浏览器中输入一个URL,此时就会触发 GET 请求
2) HTML页面中的很多元素会进一步触发 GET 请求
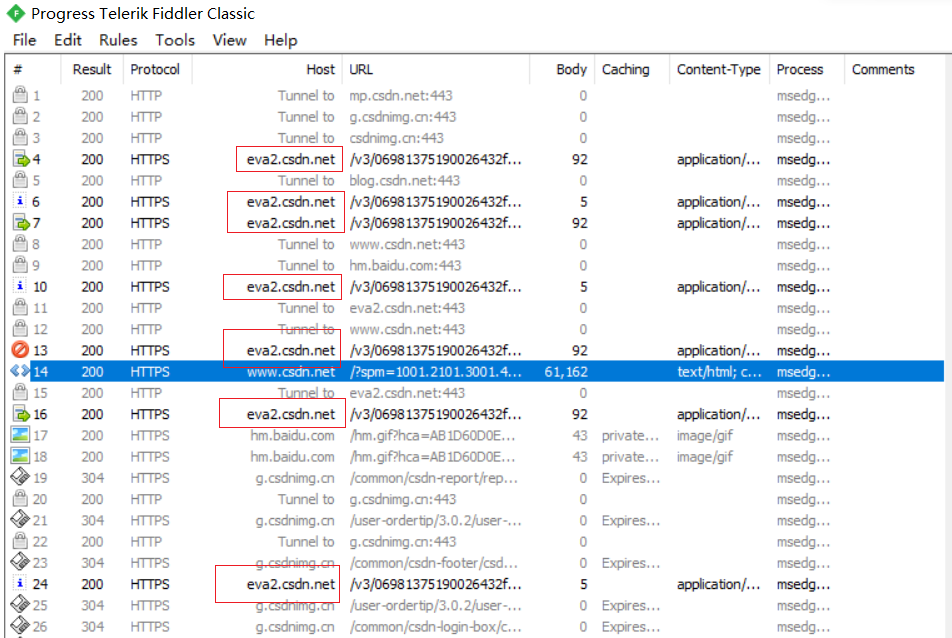
凡是域名中带有 csdn 字样的,都是访问 CSDN 首页时进一步出发的请求~~
3) 使用 Ctrl + F5 刷新首页:
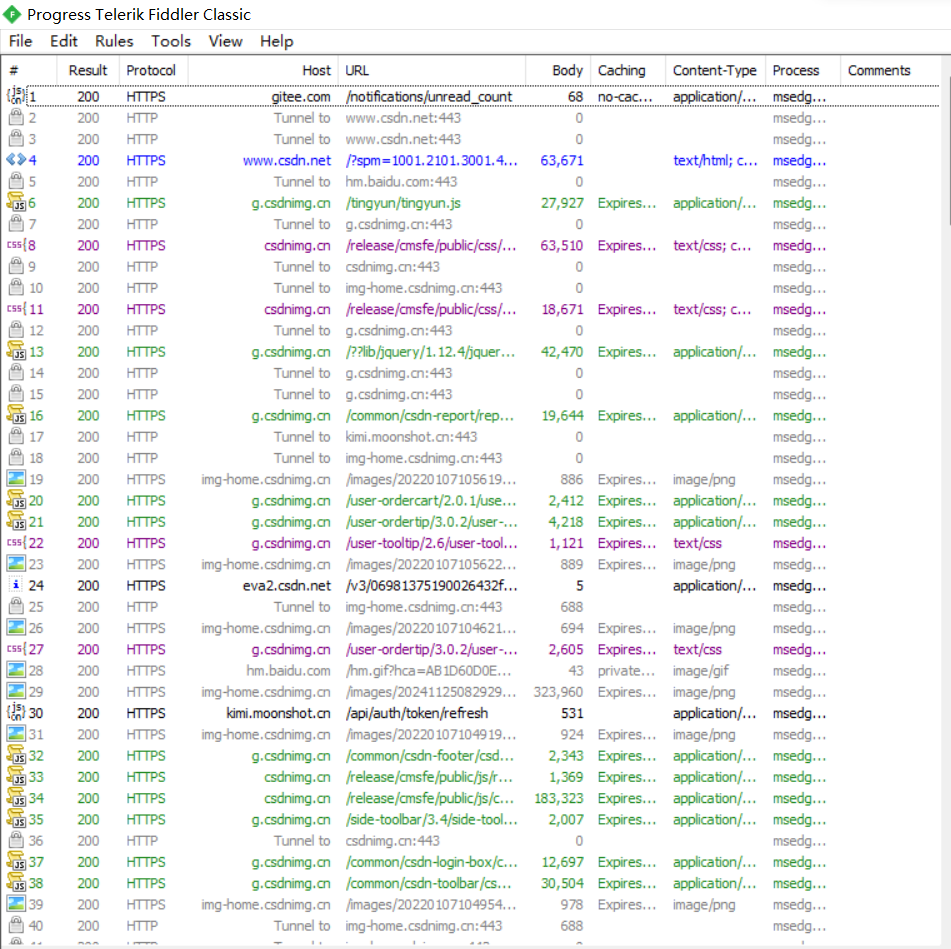
🥝可以明显观察到,这一次通过Ctrl + F5访问首页,相较于上一次抓取了更多的GET请求数据。
这是因为,使用 Ctrl + F5 会忽略本地缓存,强制从服务器重新读取数据。而上述请求得到的内容,大多是一些CSS文件、JavaScript文件、图片字体文件等...
这些内容一般都是固定的,改变的频率非常低。因此只需要第一次访问CSDN首页时,将上述固定的资源都保存下来(硬盘),后续再进行访问时,就没有必要重复获取上述内容了。浏览器缓存机制,节省了服务器的带宽,加快了页面展示的速度。
POST 方法
🍇POST方法也是一种常见的方法。多用于提交用户输入的数据给服务器。 通过HTML中的form标签可以构造POST请求,或者使用JavaScript的ajax也可以构造POST请求。
使用 Fiddler 观察 POST 请求
1) 登录/注册
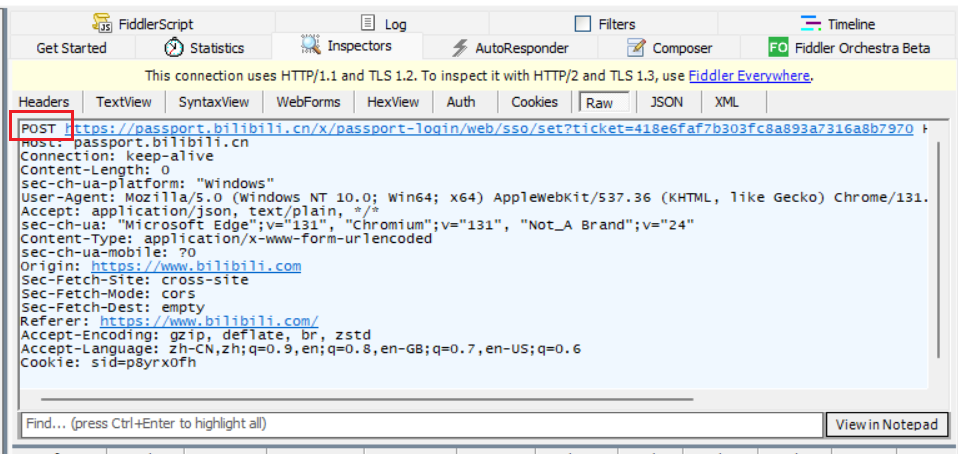
2) 上传文件
换头像时上传图片:

选择图片上传,抓包
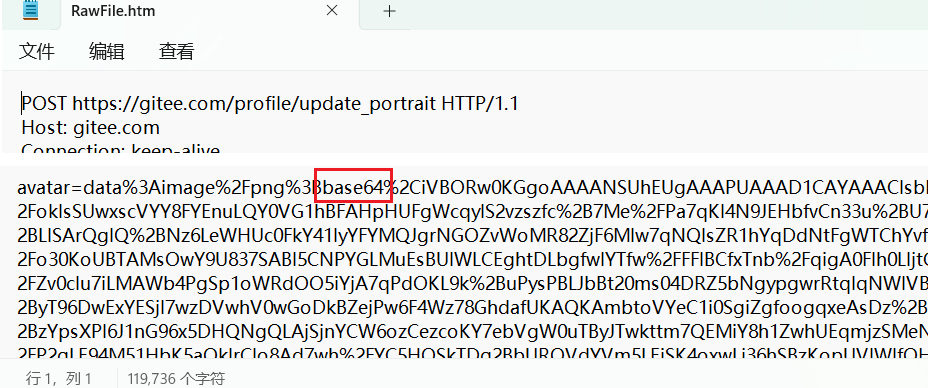
🍉这里body中的数据,就是头像图片的二进制内容(base 64转码)。
图片数据本身是二进制的,HTTP协议虽然也可以传输二进制,但是大部分情况会将二进制进行转码。(不一定使用URL encode,还有一种转码方式,即base 64编码)
3) POST方法的其他使用场景,如更改状态、支付信息等等,这里不再举例。
谈谈 GET 与 POST / 区别 ?
🍊首先抛出明确结论: 这两个方法,其实没有本质区别。(它们双方的使用场景,都可以互换,只不过一般不这样做)。
没有本质区别,但在使用习惯上,还是有区别的 !
1) 语义不同,方法表示的含义
GET 表示从服务器获取数据;
POST表示向服务器提交数据;
🍍(如果就想使用 GET 提交数据, POST 获取数据,可以但没必要~~)
2) 传递数据的方式不同
GET 传递数据通过 查询字符串(query string) 把自定义数据交给服务器;
POST 传递数据通过 正文(body) 把自定义数据交给服务器;
3) 幂等性的要求不同
在HTTP协议中,幂等性是一个重要的概念,它指的是多次执行同一个操作,结果都是相同的。它有助于确保系统的一致性和可预测性。
GET 方法对应的请求,通常设计成"幂等"的;
POST 方法对应的请求,对于"幂等性"则无要求;
4) 承接幂等性
GET 如果设计成幂等的,此时 GET 的结果应该是可以被缓存的;(上面提到的浏览器缓存机制)
POST 不设计成幂等性, POST 就不应该被缓存;
其他方法
| PUT | 与POST相似,只是具有幂等特性,一般用于更新。 |
| DELETE | 删除服务器指定资源。 |
| OPTIONS | 返回服务器所支持的请求方法。 |
| HEAD | 类似于GET,响应体不返回,只返回响应头。 |
| TRACE | 回显服务器端收到的请求。 |
| CONNECT | 预留,暂无使用。 |
🥑至此,本篇博客的内容就已介绍完毕了。由于篇幅原因和精力有限(博主不幸感冒),我们未能在本文中涵盖所有开头所提及的内容。不过,未尽的话题将在(下)篇博客中得到详尽的阐述。还请多多支持!
希望这篇博客能为你使用Fiddler抓包观察URL以及Method提供一些帮助
如有不足之处请多多指出
我是高耳机