本篇文章是CVPR2019的一篇Anchor-Free的文章,是一篇很好的Anchor Free的目标检测的文章,目前基于anchor的目标检测方法,大多采用不同的level预测不同尺度的instance,而分配规则往往是人为设计的,这导致anchor的匹配策略可能不是最优的。那有没有更优的匹配方法?文章从level选取的点进行切入,利用FASF实现不同的instance在不同level的动态分配,实现了level的动态选择,并且anchor free方法取得了较好的mAP,另外作者设计了anchor free跟anchor-based相结合的方法,进一步提升模型效果,取得了可观的结果。
论文名称:Feature Selective Anchor-Free Module for Single-Shot Object Detection
作者:Chenchen Zhu & Yihui He & Marios Savvides
论文链接:https://arxiv.org/abs/1903.00621
Back Ground
目标检测的一个挑战在于尺度的变化,目前解决问题的方法包括:特征金字塔、multi-level、anchor boxes等。特征金字塔以及anchor-based已经取得了不错的效果。但是存在一定的限制:
- 启发式的特征选择。
- 重叠的anchor的选择。
目前基于anchor的目标检测方法,大多采用不同的level预测不同尺度的instance,而分配规则往往是人为设计的,这导致anchor的匹配策略可能不是最优的。本文提出了feature selective anchor-free module来解决这个限制。并且FASF可以与anchor-based 分支协同并行工作,提高模型效果。在COCO上,可以达到44.6%的mAP
Feature Selective Anchor Free
Network Architecture
FSAF的结构展示如下图,作者的实验是以RetinaNet为基础,所以下图的主干部分代表的是RetinaNet的FPN结构,同样的从P3-P7引出subnets进行分类与预测,如下图所示,P3-P7对应的分辨率 1 / 2 l 1/2^l 1/2l。
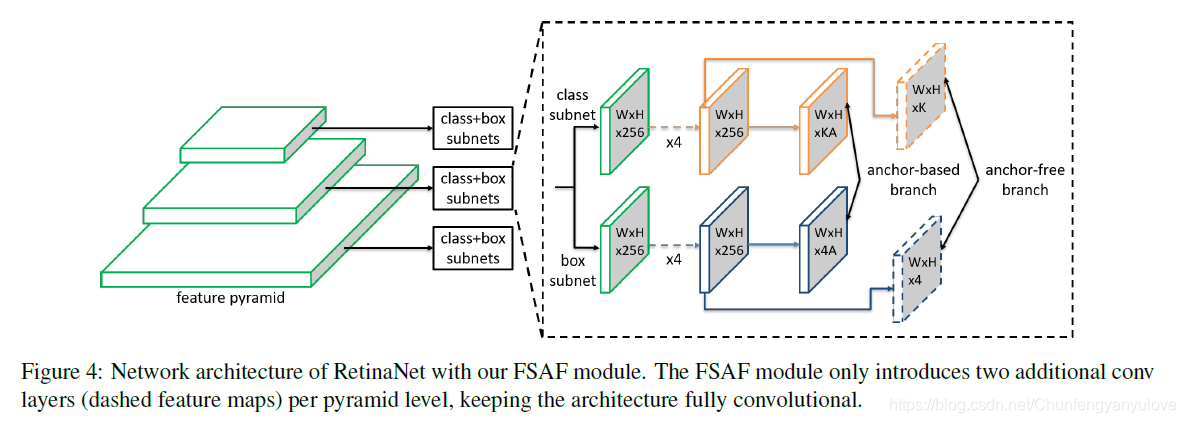
FSAF重点是下图中引出来的Anchor-Free branch,分类的分支,通过一个3x3的卷积以及sigmoid得到WxHxK的特征图,用于预测K个类别,至于回归分支,通过一个3x3的卷积以及ReLU得到WxHx4的特征图,用于预测每个实例的坐标框。
Ground Truth and Loss
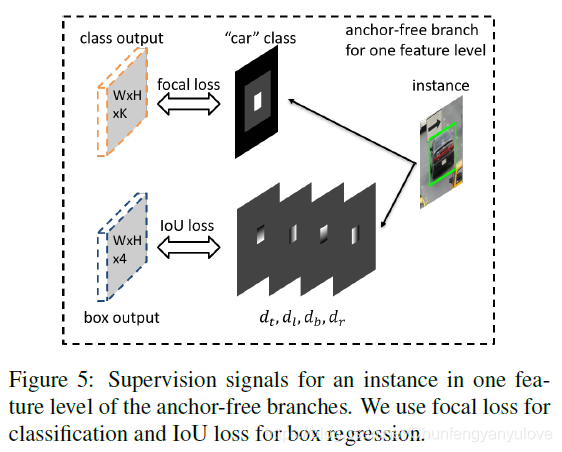
首先,如何定义正负样本呢?如下图所示,Groud Truth是汽车的蓝框,正样本便是中间图中白色的部分,当然除了正样本也不全是负样本,在正负样本之间还有一部分忽略样本,论文中正样本占比为宽度的0.2,忽略部分界限占比为宽度的0.5,所以每个level在宽度比例0.2-0.5的一圈是不加入训练,另外,不同level的界限间的像素也同样不加入训练,用公式表示是: ( b e i − b e l ) ; ( b i l − 1 , b i l + 1 ) (b^{i}_{e}-b^{l}_{e});(b_{i}^{l-1},b_{i}^{l+1}) (bei−bel);(bil−1,bil+1)(其实不加入训练这里,论文描述的挺复杂,其实计算后发现,就是每层的Ground Truth往外扩一圈),其余的就为负样本。并且如果两个实例在同一个level重合了,以小的那个为主。
训练的时候分类采用的是Focal loss,box回归的是边界的上下左右,这里使用的是IOU Loss
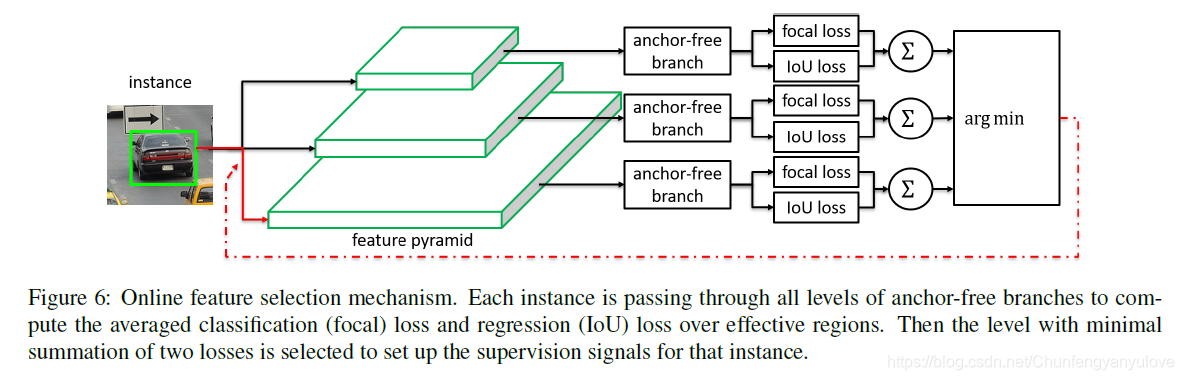
Online Feature Selection
这部分是本篇文章的精髓所在,如果自动去给不同的instance分配合适的level进行预测呢?
其实答案也很简单,就如下图所示,作者分别对不同的level的分支结果求loss,然后选择loss最小的那个作为该实例的分支。
Joint Inference and Training
这部分将介绍,如何将anchor-based与anchor-free方法结合起来,如上面图Figure 4所示。
首先,在训练的时候,保持anchor-based的分支超参数不变。然后anchor-based与anchor-free的loss进行求和,如下: L = L a b + λ ( L c l s a f + L r e g a f ) L=L^{ab}+\lambda(L_{cls}^{af}+L_{reg}^{af}) L=Lab+λ(Lclsaf+Lregaf),其中, λ = 0.5 \lambda=0.5 λ=0.5。
在inference的时候,将anchor based得到的box以及anchor free得到的box一起用非极大值一致的方法,得到最终的结果。
实验
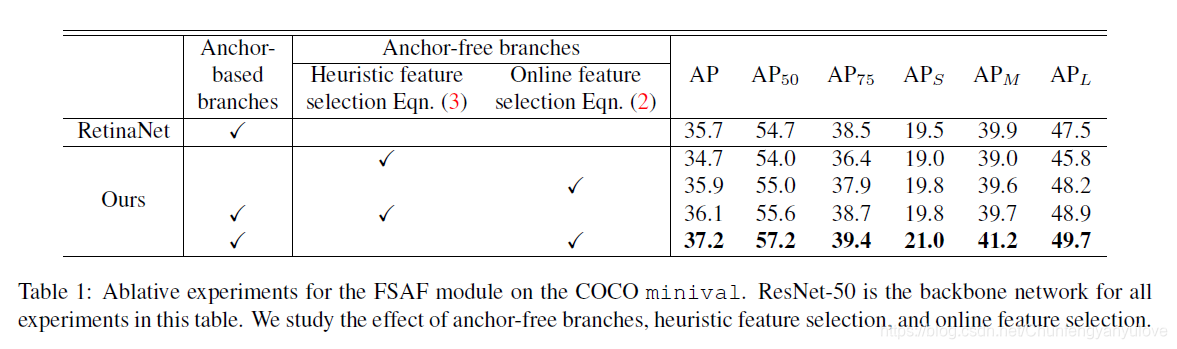
FASF 模块的效果以及online feature selection的重要性。
下图是在RetinaNet上使用FASF模块的效果,可以看出,其实只使用FASF的效果已经要好于RetinaNet了,并且在实验中可以看出,如果不使用online feature selection 效果也不错的,但是没有使用online feature selection效果好,相差了大约10个点。
FASF选择的level到底怎么样?
实验表明,大部分的检测框还是遵循原来的设计的,前面的level检测小目标,后面的level检测大目标,但是也有特例,就是下图中红色框框住的那些就是,level发生了变化。

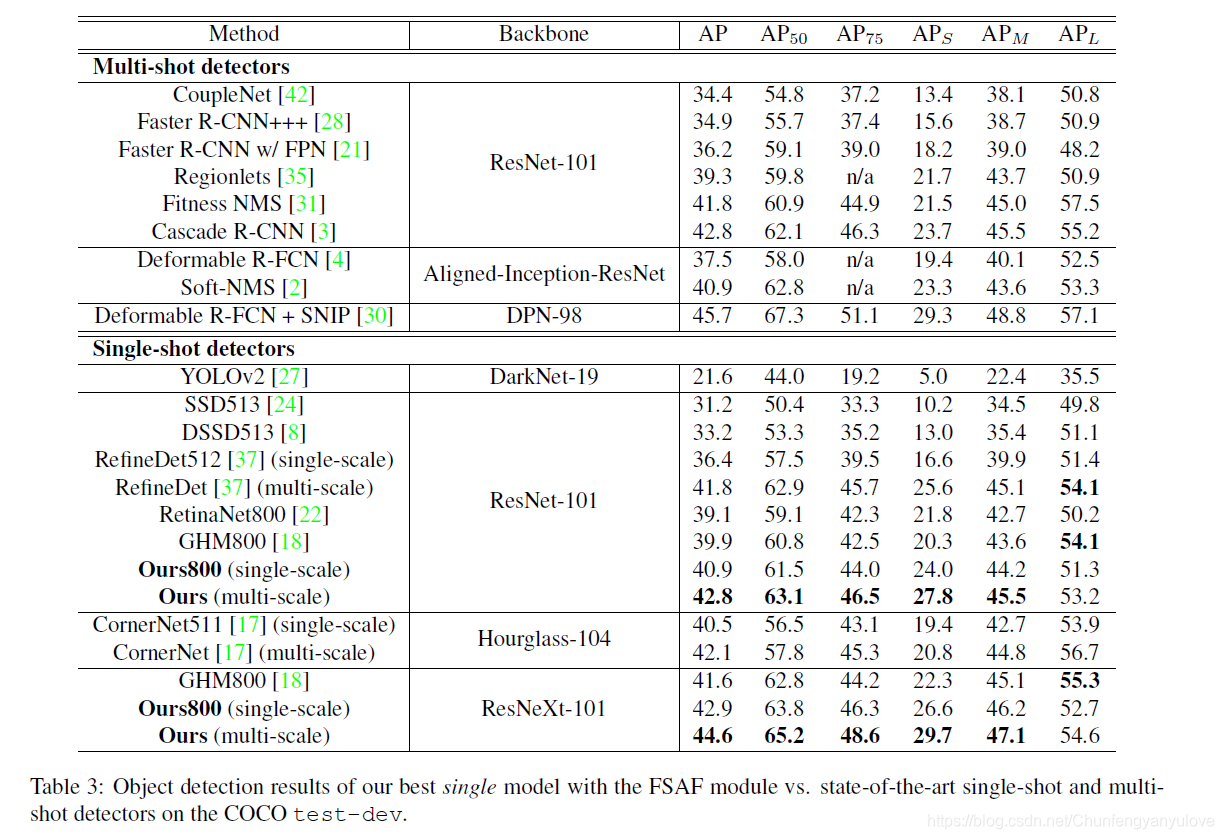
FASF与SOTA相比较
总结
这篇文章同样是一篇很好的Anchor Free的目标检测的文章,文章从level选取的点进行切入,利用Anchor实现不同的instance在不同level的动态分配,设计了FASF方法进行level的动态选择,并且设计了anchor free跟anchor-based相结合,提升模型效果,取得了可观的结果。