
目录
一、自动混合精度训练
混合精度训练利用16位 (FP16) 和32位 (FP32) 浮点格式来保持准确性。通过以16位计算梯度,与使用完整的32位分辨率相比,该过程变得更快,并且内存使用量减少。
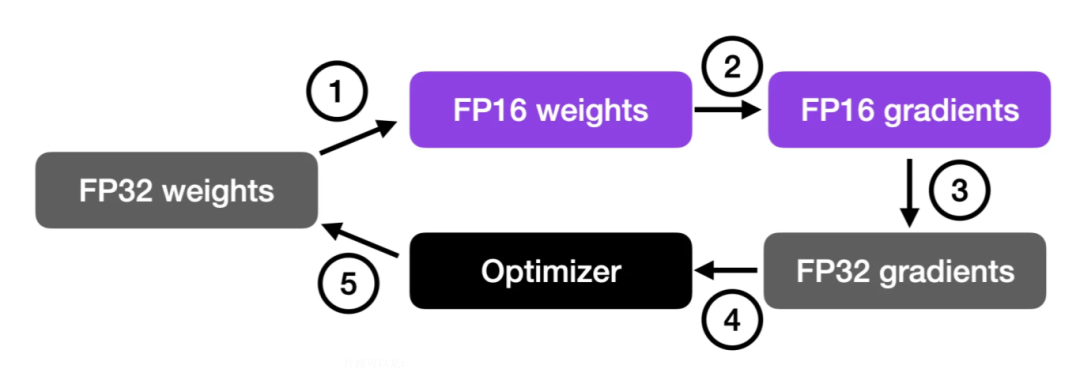
该过程首先将权重转换为较低精度(FP16)以加快计算速度。然后计算梯度,将其转换回更高精度(FP32)以确保数值稳定性,最后使用这些缩放后的梯度来更新原始权重。
使用 torch.cuda.amp.autocast()可轻松实现混合精度训练:
import torch
from torch.cuda.amp import autocast, GradScaler
# Assume your model and optimizer have been defined elsewhere.
model = MyModel().cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
scaler = GradScaler()
for data, target in data_loader:
optimizer.zero_grad()
# Enable mixed precision
with autocast():
output = model(data)
loss = loss_fn(output, target)
# Scale the loss and backpropagate
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()二、低精度训练
由于16位浮点数的表示范围限制,这种方法可能导致NaN值出现。为了进一步降低精度,可采用BF16(Brain Floating Point),该格式相较FP16提供更大的动态范围,使其更适合深度学习应用。

NVIDIA Ampere及更新架构的GPU已支持BF16,用户可使用以下命令检查支持情况:
import torch
print(torch.cuda.is_bf16_supported()) # should print True三、梯度检查点
即使使用混合精度和低精度,这些大型模型也会生成许多中间张量,这些张量会消耗大量内存。梯度检查点(Gradient Checkpointing)通过选择性地存储部分中间激活值,并在反向传播时重新计算其余激活值,以换取计算成本来减少内存占用。
通过策略性地选择要检查哪些层,您可以通过动态重新计算激活而不是存储它们来减少内存使用量。这种权衡对于具有深度架构的模型尤其有益,因为中间激活占内存消耗的很大一部分。如何使用它的简单代码片段如下:
import torch
from torch.utils.checkpoint import checkpoint
def checkpointed_segment(input_tensor):
# This function represents a portion of your model
# which will be recomputed during the backward pass.
# You can create a custom forward pass for this segment.
return model_segment(input_tensor)
# Instead of a conventional forward pass, wrap the segment with checkpoint.
output = checkpoint(checkpointed_segment, input_tensor)四、使用梯度累积减少批次大小
简单减小批量大小虽然能显著降低内存消耗,但往往会对模型准确率产生不良影响。
梯度累积(Gradient Accumulation)通过累积多个小批量的梯度,以实现较大的“虚拟”批次大小,从而降低对GPU内存的需求。其核心原理是为较小的批量计算梯度,并在多次迭代中累积这些梯度(通常通过求和或平均),而不是在每个批次后立即更新模型权重。
然而需要注意,这种技术的主要缺点是显著增加了训练时间。
五、张量分片和分布式训练
对于超大规模模型,可以使用完全分片数据并行(FSDP)技术,将模型参数、梯度和优化器状态拆分至多个GPU,以降低单 GPU 的内存压力。
FSDP不会在每个GPU上维护模型的完整副本,而是将模型的参数划分到可用设备中。执行前向或后向传递时,只有相关分片才会加载到内存中。这种分片机制大大降低了每个设备的内存需求,与上述任何一种技术相结合,在某些情况下甚至可以实现高达10倍的减少。
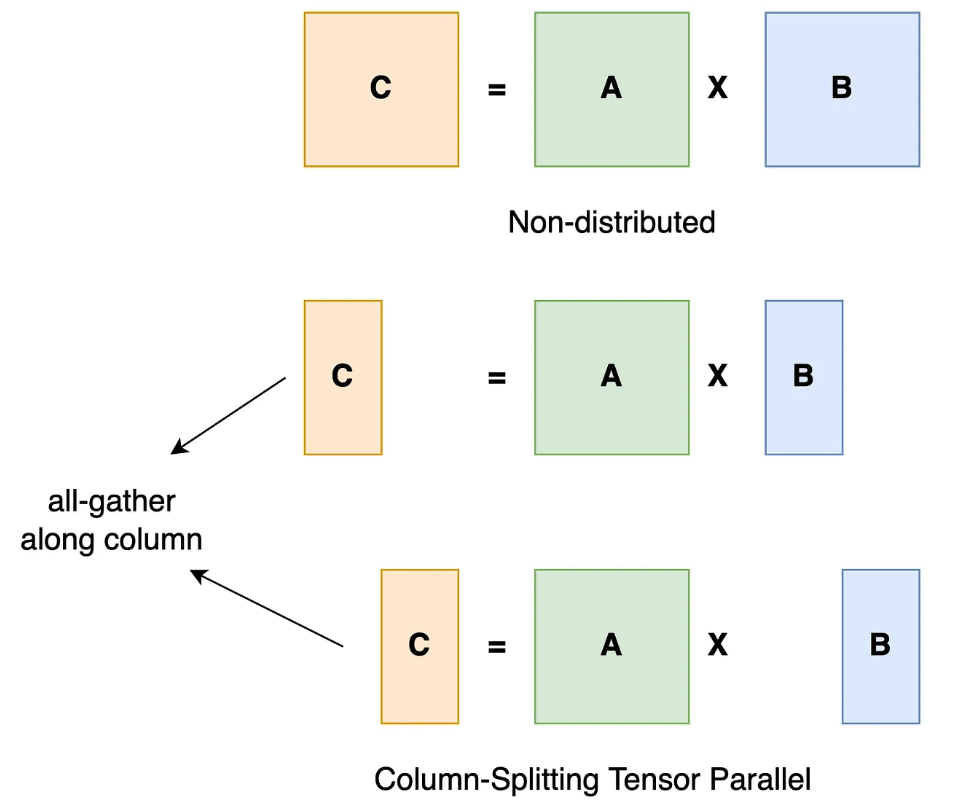
使用以下方式启用它:
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
# Initialize your model and ensure it is on the correct device.
model = MyLargeModel().cuda()
# Wrap the model in FSDP for sharded training across GPUs.
fsdp_model = FSDP(model)六、高效的数据加载
内存优化中常被忽视的一个方面是数据加载效率。虽然大部分优化关注点集中在模型内部结构和计算过程,但低效的数据处理同样可能造成不必要的瓶颈,影响内存利用和计算速度。作为经验法则,当处理数据加载器时,应始终启用Pinned Memory和配置适当的Multiple Workers,如下所示:
from torch.utils.data import DataLoader
# Create your dataset instance and then the DataLoader with pinned memory enabled.
train_loader = DataLoader(
dataset,
batch_size=64,
shuffle=True,
num_workers=4, # Adjust based on your CPU capabilities
pin_memory=True # Enables faster host-to-device transfers
)七、使用原地操作
避免不必要的张量复制,可以通过原地操作减少临时内存分配。例如:
import torch
x = torch.randn(100, 100, device='cuda')
y = torch.randn(100, 100, device='cuda')
# Using in-place addition
x.add_(y) # Here x is modified directly instead of creating a new tensor八、激活和参数卸载
对于非常大的模型,即使采用了上述所有技术,由于中间激活次数过多,您仍可能会达到GPU内存的极限。
此外,可以策略性地将一些激活和/或参数卸载到主机内存(CPU), GPU 内存保留下来仅用于关键计算。将部分激活转移到CPU以节省GPU内存,如使用DeepSpeed进行自动管理:
def offload_activation(tensor):
# Move tensor to CPU to save GPU memory
return tensor.cpu()
def process_batch(data):
# Offload some activations explicitly
intermediate = model.layer1(data)
intermediate = offload_activation(intermediate)
intermediate = intermediate.cuda() # Move back when needed
output = model.layer2(intermediate)
return output九、使用更精简的优化器
各种优化器在内存消耗方面存在显著差异。例如,广泛使用的Adam优化器为每个模型参数维护两个额外状态参数(动量和方差),这意味着更多的内存消耗。将Adam替换为无状态优化器(如SGD)可将参数数量减少近2/3,这在处理LLM等大型模型时尤为重要。
标准SGD的缺点是收敛特性较差。为弥补这一点,可引入余弦退火学习率调度器以实现更好的收敛效果。实现示例:
# instead of this
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
# use this
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
num_steps = NUM_EPOCHS * len(train_loader)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=num_steps)十、进阶优化技术
除上述基础技术外,以下高级策略可进一步优化GPU内存使用,充分发挥硬件潜能:
-
内存分析和缓存管理
精确测量是有效优化的前提。PyTorch提供了多种实用工具用于监控GPU内存使用情况:
import torch
# print a detailed report of current GPU memory usage and fragmentation
print(torch.cuda.memory_summary(device=None, abbreviated=False))
# free up cached memory that’s no longer needed by PyTorch
torch.cuda.empty_cache()-
使用TorchScript进行JIT编译
PyTorch的即时编译器(JIT)可让使用TorchScript将Python 模型转换为优化的可序列化程序。通过优化内核启动并减少开销,此转换可同时提高内存和性能:
import torch
# Suppose `model` is an instance of your PyTorch network.
scripted_model = torch.jit.script(model)
# Now, you can run the scripted model just like before.
output = scripted_model(input_tensor)-
自定义内核融合
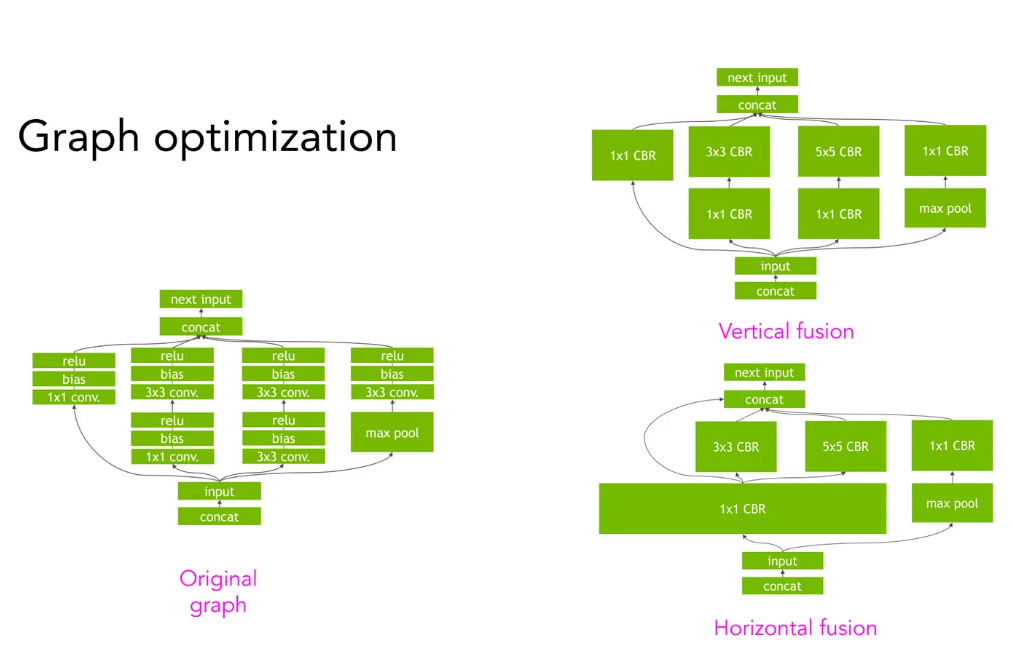
编译的另一个主要好处是将多个操作融合(如上文所述)到单个内核中。这有助于减少内存读写并提高整体吞吐量。融合操作如下所示:
-
使用 torch.compile() 进行动态内存分配
进一步利用编译技术,JIT编译器可通过编译时优化改进动态内存分配效率。结合跟踪和计算图优化技术,这种方法可在大型模型和Transformer架构中实现更显著的内存和性能优化。
总结
通过合理组合以上优化策略,可以大幅降低GPU内存占用,提高训练效率,使得大规模深度学习模型能在有限资源下运行。随着硬件技术和深度学习框架的不断发展,进一步探索新方法将有助于更高效地训练AI模型。如果您有更好的技术方式,欢迎在评论区讨论!
