Automatic and Accurate Epilepsy Ripple and Fast Ripple Detection via Virtual Sample Generation and Attention Neural Networks
摘要--全世界约有1%的人口患有癫痫。癫痫手术的成功关键取决于术前对致痫区的定位。高频振荡包括波纹(80-250赫兹)和快速波纹(250-500赫兹),通常被用作生物标志物来定位致痫区。最近的文献表明,快速波纹比波纹更能显示致痫区。因此,从脑磁图的波纹信号中准确地检测出快速波纹对于改善癫痫手术的效果至关重要。本文提出了一种自动和准确的波纹和快速波纹检测方法,它采用了虚拟样本生成和具有注意机制的神经网络。我们在具有50个波纹和50个快速波纹的病人数据上评估了我们提出的检测器,这些波纹和快速波纹由两位专家标记。实验结果显示,我们的新检测器优于多种传统的机器学习模型。特别是,我们的方法在50次重复的随机子抽样验证中可以达到89.3%的平均准确率和0.88的平均接收操作特征曲线下面积。此外,我们通过实验证明了虚拟样本生成、注意力机制和神经网络模型架构的有效性。
非侵入性的检测方法被普遍用于致痫区的定位[5-8]。带有尖峰信号的脑磁图(MEG)是一种无创技术,用于癫痫手术前的术前检查[9],它指导iEEG对致痫区进行定位[10]。不幸的是,只有80%的患者在MEG记录中显示出尖峰。此外,即使切除了产生尖峰的脑区,癫痫手术最终也无法减少大约50%的病例的发作频率[4, 11]。幸运的是,各种研究表明,致痫脑产生的高频脑信号被称为高频振荡(HFOs),包括波纹(80-250 Hz)和快速波纹(FRs,250-600 Hz)。癫痫手术的结果关键取决于精确和无创地定位波纹和FRs[9, 12]。有许多研究表明,病理HFO是识别致痫组织的生物标志物,可以改善癫痫患者的术前诊断和手术效果[13]。
Ⅰ Introduction
最近,越来越多的证据表明,在致痫区的定位方面,FR比波纹更有用[14],在多发癫痫病灶的情况下尤其如此。在这方面,准确地检测和区分MEG信号中的波纹和FR对于改善手术效果至关重要。
在目前的临床实践中,外科医生对脑电图中的波纹和FR的视觉检查是常规的。然而,与传统的尖峰相比,涟漪和FRs太弱,不易察觉,特别是,由于FRs持续时间短,振幅低,而且MEG信号数据量大,视觉识别FRs费时费力,主观性强,容易出错[15]。
为了解决上述问题,人们开发了许多方法[16-18]来自动检测和精确识别MEG、EEG和iEEG信号中的波纹和FRs。这些 "老式 "的HFOs检测方法一般都有类似的框架或工作流程:(1)根据观察或统计分析手工生成特征,(2)记录的数据被分成大量的信号段,(3)HFOs检测器自动从这些信号段中提取特征,(4)通过与手工特征的比较对提取的特征进行阈值处理。Klink等人[19]介绍了MEG中的自动HFOs检测和可视化方法,而另一项工作[17]使用手工制作的特征(如高频峰和低频峰)在EEG信号中自动区分HFOs。19]和[17]都要求手工制作的特征在识别HFOs信号段时有一个截止点,导致在将这些检测器应用于不同人群的类似神经影像数据时,不可避免地重新调整手工制作的特征的截止点。这妨碍了对未见过的HFOs的概括性。
机器学习为外科医生提供了一个很有前途的方法来提高检测HFO的性能,同时减少人为干扰。传统的机器学习算法,如逻辑回归,已被用于识别致痫区[20]。我们提出了一个使用神经网络(NN)的SMO检测器来完成同样的任务,并改善了HFOs的分类性能[21]。这样的HFOs检测器需要最小的人为干扰来从地面真实数据集中学习潜在的HFOs模式。然而,NN检测方法仍然存在几个挑战。
一个挑战是训练数据不足。多层NN模型的训练步骤通常需要大量的数据来理解隐藏在高维数据中的复杂模式[22]。然而,由于患者数量有限,单个患者的波纹和FRs实例数量较少,很难收集大量的信号样本进行机器学习模型训练。
另一个挑战是信号分类的性能有限。虽然有脑电图和EEG信号分析工具提供HFOs检测[15, 23],但在癫痫患者的术前操作中,准确分类波纹和FRs仍然是个问题,目前的HFOs检测性能不足以满足临床使用。虽然大多数研究集中在将HFOs信号从尖峰或正常生物信号中分离出来,但它们仍然限制了准确区分HFOs的亚类型(即波纹和FR)。目前还不清楚最先进的HFOs检测模型是否可以直接应用于MEG的涟漪和FRs检测分类。最近,注意力机制被引入深度学习,以提取更好的特征嵌入[24]。Vaswani等人[25]使用唯一的注意力机制为神经机器翻译任务构建了一个序列-序列模型,取得了最先进的质量得分。Shen等人[26]讨论了注意力机制,该机制允许更多的灵活性,并且在建立依赖关系的模型时更注重数据驱动。Zhu等人[27]开发了一个DAN,一个用于新闻推荐的深度注意力神经网络。最近,有人提出整合注意力机制,从视觉诱发的MEG脑信号中对分类的图像进行分类[28]。据我们所知,注意力机制还没有被应用于来自MEG的HFO(即涟漪和FR)检测。
本研究旨在缓解数据不足的问题,提高HFOs信号中FRs检测的性能。具体来说,我们开发了一个波纹和快速波纹(ARF)检测器来自动区分HFOs信号中的波纹。我们的贡献有三个方面。首先,我们引入了一个虚拟样本生成方法,以创建更多的生物医学脑电信号来增加脑电的地面真实数据集。这改善了小的地面真实数据集的训练性能。其次,我们采用注意力机制来创建注意力神经网络(AttNN)模型,以实现准确的FRs检测。此外,这项研究涉及到全新的病人数据,这些数据从未在任何出版物中使用过,而且可能在公共场合无法获得。
本文的其余部分组织如下。第二节描述了脑电图数据和ARF检测器。实验设置显示在第三节,然后是实验结果和讨论,分别在第四节和第五节,最后在第六节总结这项工作。
II. MATERIALS AND METHODS
A. MEG波纹和FRs地面真实数据集
在这项回顾性研究中,研究方案由机构审查委员会(IRB)审查,并根据《赫尔辛基宣言》从每个病人那里获得了IRB正式批准的知情同意书。我们从20名癫痫患者(年龄:6-60岁,平均年龄32岁;10名女性和10名男性)那里获得了脑电图数据,其特点是部分癫痫发作产生于大脑的某一部位。作为手术前评估的一部分,剥夺睡眠和减少抗癫痫药物被用来提高在脑电图记录期间捕获HFO的机会。另外还采用了以下病人的纳入标准。(1)在脑电图记录期间,头部移动小于5毫米,(2)所有脑电图数据的偏移量在6 pT以内(脑电图数据被认为是 "干净的")。这20名患者在结构图像上至少有一个可见的病变,进行了临床颅内记录,并进行了癫痫手术。脑电图记录由一个306通道的全头脑电图系统(VectorView, Elekta Neuromag, Helsinki, Finland)在磁屏蔽室(MSR)进行。在收集脑电图数据的过程中,采样率被设置为4,000赫兹,每个病人都记录了大约一个小时的脑电图数据。
为了确定脑电图系统的噪声,应用了基于实验前刚刚获得的没有病人(空房间)的数据的本底噪声,产生的噪声水平为3-5英尺/赫兹。为了定位癫痫活动(如尖峰、涟漪和FRs),空房间的测量结果也被用来计算噪声协方差矩阵。公共可用的脑电处理器被用于分析传感器层面的脑电数据[29]。
对于基础真实数据集,两位专家从脑电图数据中手动选择波纹和FRs信号段。总共有100个持续时间为1秒的信号片段(50个波纹和50个FRs样本)被组成地面实况数据集,用于模型评估。与涟漪相比,FRs是少数类别。为了提高模型中FRs的检测精度,我们选择了一个平衡数据集来训练我们的模型。
为了测试FRs对致痫区定位的检测性能,我们根据临床 "金标准"(侵入性记录和临床结果)进一步确认信号样本是否来自致痫区,这与这些患者的HFOs来源分析分别显示了一致的位置。如果一个信号样本来自致痫区,它就被标记为来自病灶区,否则就被标记为来自非病灶区。我们有50个FRs信号中的46个来自病灶区,而50个ripples信号中的7个来自病灶区。
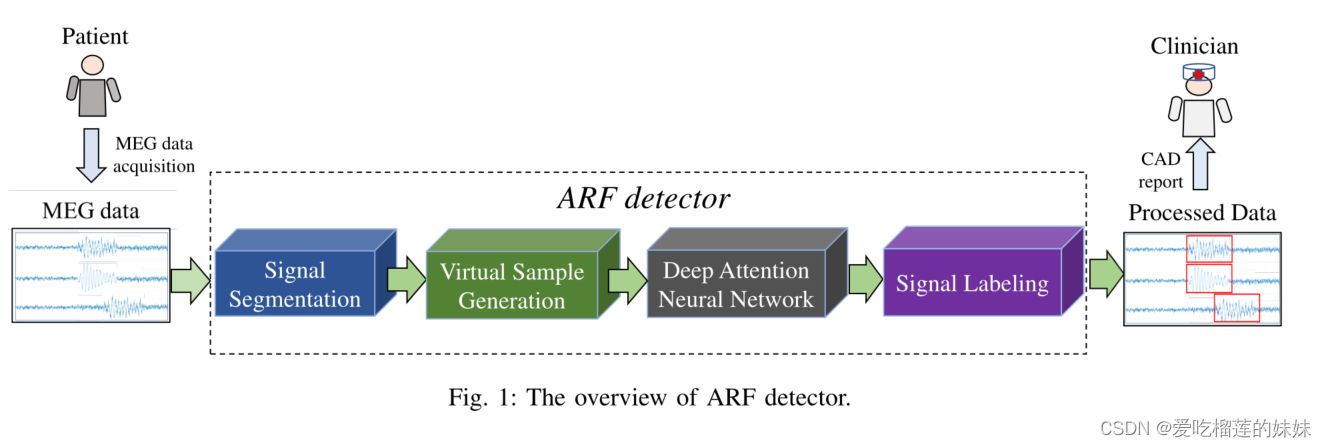
B. ARF检测器概述
ARF检测器的概述在图1中描述。具体来说,该检测器包括信号分割、虚拟样本生成、AttNN和信号标签。ARF检测器包含训练和测试两个阶段。在训练阶段,给定具有一定持续时间(即1000毫秒)的脑电信号片段的黄金标准,使用虚拟样本生成方法来增加纹波和FRs信号的大小。一个AttNN被训练来区分波纹和FRs。在测试过程中,给定一组来自病人的脑电图数据,ARF检测器将数据分离成一系列信号段,用移动窗口进入相同长度的训练数据。然后,训练好的AttNN被用来对这些片段进行分类。分配的标签通常由MEG处理器等软件进行[29]。如上所述,仅仅给HFOs贴标签对数据分析是不够的,分离正常控制和HFOs信号是一个相对简单的任务。在下面的分析中,我们着重于使用ARF检测器进行波纹和FRs分类。
C. 信号分割
通过移动窗口技术[30],多通道MEG信号被分割。为了达到所提出的检测器的模型学习目的,临床癫痫学家使用MEG studio软件(MEG中心,辛辛那提儿童医院医疗中心,Cincinnati, OH, US)根据侵入性记录和手术结果手动选择了一些涟漪和FRs信号段。
图2显示了脑电波波纹和FRs的例子。涟漪和FRs信号段在时域上都是由时间序列向量表示。在这项研究中,我们对处理过的脑电图信号采用了1,000毫秒的窗口大小,没有重叠,因为这个时间长度足以覆盖一个波纹或FR。每个信号段包含一系列的4000个信号时间点。因此,尽管不同受试者的脑电图记录长度不同,但ARF检测器的训练数据被规范化为长度为1,000毫秒的信号段。波纹信号段是用80-250赫兹的带通滤波器在波形中目测出来的,而FR则是用250-500赫兹的带通滤波器分析的[29]。以前的研究[31]表明,这些HFOs与80%以上的病人的慢速尖峰相吻合。当使用基于患者颅内录音的HFOs来源分析[32]时,HFOs被证实。我们比较了MEG的FR和颅内记录的FR在产生HFOs的源头水平[32]。
D. MEG信号的虚拟样本生成
如上所述,本研究涉及应用虚拟样本生成方法来增加NN模型的训练样本的大小。在这里,我们在脑电图数据上使用了一种基于自适应合成(ADASYN)的虚拟样本生成方法[33]。虽然ADASYN最初是为了对不平衡的数据集进行过度取样而提出的,但它也被应用于增加样本大小当机器学习模型的训练样本不足时[34]。ADASYN方法首先计算出少数和多数类别样本之间的不平衡程度。如果该程度的不平衡性小于预设的最大可容忍不平衡性的阈值,它估计将从少数类别中产生的虚拟样本的数量。对于少数群体中的每个样本,该方法根据欧氏距离找到k-最近的邻居(KNN),并计算出给定的少数群体样本的密度分布。最终,根据估计的样本量和密度分布,为每个少数族裔样本生成虚拟样本。
由于ADASYN是针对遗传不平衡数据问题提出的,所以KNN方法中的欧氏距离适用于一般情况。然而,事实证明,欧氏距离并不是一个理想的信号之间的相似度测量。所以,基于ADASYN生成的虚拟样本对于反映波纹和FRs样本的分布可能是次优的。在这项工作中,我们通过引入自适应签名相关指数(ASCI)作为虚拟样本生成过程中的相似性度量来修改ADASYN[35]。ASCI是一个从-1到1的归一化相似性指数,它考虑了信号段之间的振幅差异。因此,我们将ASCI应用到虚拟样本生成中,以找到脑电信号段之间具有高形态相似性的邻居样本。假设ASCI(sa, sb)表示两个MEG信号段之间的ASCI,其中sa和sb是两个MEG信号段的Z-score变换。在两个样本信号之间进行三分法。假设R是信号振幅空间。R分为上部空间Ru、中部空间Rm和下部空间Rl。U=u(i)和L=l(i)是预先定义的在时间瞬间i的截断向量,例如,u(i)=0.25,l(i)=-0.25。然后,我们定义三个子空间为:上层子空间Ru={V>U},中间子空间Rm={L≤V≤U},下层子空间Rl={V<L}。信号sa = {sa(i), 1 ≤ i ≤ N}的三分化Ta = {ta(i)}的计算方法是
如果两个信号样本中的一个在上层子空间,另一个在下层子空间,则称为不和谐的。如果sa(i)和sb(i)在同一个子空间,它们被定义为一致的一对。否则,它们被称为不协调。显然,ASCI值因更多的协和对而增加,因无协和对而未改变,因不协和对而减少。当两个MEG信号段表现出高的形态学相似性时,ASCI接近于1,而当两个MEG信号段具有低的相似性时,ASCI接近于-1。通过这种方式,可以有效地测量两个片段之间的形态学相似度。我们定义sa和sb之间的MEG信号距离。
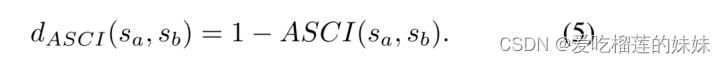
如果sa和sb具有较高的形态相似性,则信号距离dASCI(sa,sb)接近于0。如果两个信号段表现出较低的形态相似性,则信号距离dASCI(sa,sb)接近于2。
在下面的样本生成程序中,我们使用方程(5)中所示的ASCI距离,而不是ADASYN中使用的欧氏距离。为了给我们的平衡脑电图数据集生成虚拟样本,我们设计了如下的3个步骤程序。
- 第1步:我们从我们的地面真实数据中创建一个不平衡的数据集。具体来说,波纹和FRs样本被分成N个仓,每个仓里有m个样本。然后,将一个类别的样本仓和另一个类别的N个样本仓合并为一个不平衡数据集,不平衡度为1:N。
- 第二步:我们应用基于ASCI的ADASYN方法,为临时不平衡数据集生成虚拟波纹样本。这种方法计算波纹和FRs样本之间的不平衡程度,并估计要从少数类中生成的虚拟样本的数量(例如,(N - 1)×m)。对于少数类中的每个样本,该方法根据ASCI距离找到5个最接近的样本,并计算所选样本的加权平均值。权重在[0, 1]之间随机产生,权重之和为1。
- 第3步:我们重复这个程序,直到生成预先定义的虚拟样本数量。例如,我们定义虚拟样本生成因子为1,000,以合成1,000次的波纹和FRs训练样本。
E. 注意力神经网络
基于先前的研究[36],为涟漪和FRs分类开发了一个AttNN模型。在AttNN模型中使用了注意力机制(图3)。它由一个输入层、密集层、批量归一化层、自我注意层和作为输出层的softmax层组成。AttNN包含四个密集层,每个密集层都有不同数量的完全连接的节点。我们将这四层中的节点数量定义为[512, 128, 32, 8],用于数据降维。每个节点的非线性激活函数是一个整顿的线性单元(ReLU)。
图3:AttNN模型的结构。密集的。全连接层;括号中列出了节点的数量和激活函数的类型。输入是MEG信号段,输出是给定段属于波纹或FRs组的概率。
在四个密集层中的每一个之后都有一个批量归一化层,并提高了AttNN的速度、性能和稳定性。每个密集层的输出都被归一化,以扩大激活度,这就缓解了内部协变量转移的问题。
在第二个致密层之后使用了一个自我注意层。给定一个输入的MEG信号,可以表示为x = [x1, x2, ..., xn]和一个查询q∈Rd的表示,原始的注意力机制使用一个兼容函数f(xi, q)来计算q和每个元素xi之间的对齐分数。最常见的兼容函数f(-)是加法,定义为:f(xi, q) = wT σ(W (1)xi + W (2)q), (6) 其中W (1) ∈ Rd×d, W (2) ∈ Rd×d, w∈ Rd是NN的可训练权值,d是xi的维度,σ(-)是非线性激活函数ReLU。虽然加法注意力需要消耗大量的内存,但它通常能取得更好的分类性能,并在本研究中使用。此外,自我注意[37]能够调查每个信号特征相对于整个MEG信号段的重要性,提供了一个涟漪-FRs分类任务。在自我关注中,q被从兼容函数中移除,并由以下定义。
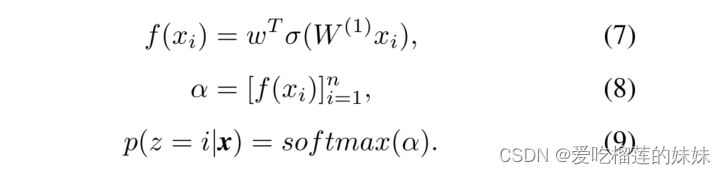
自我注意层的输出si是一个根据其重要性而加权的元素,定义为
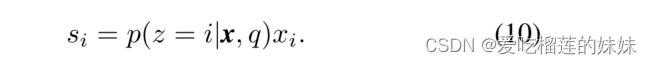
经自我注意层转换为更好的脑电信号特征表示的输出si,被连接到另一个全连接层。因此,在NN模型中加入了一个自我注意机制。然后,我们将另一个有8个节点的全连接层和一个softmax层连接起来,用于波纹和FRs分类。
F . 信号标记
在一个信号段被确定为波纹或FR信号后,我们用可视化软件对信号进行标记。例如,我们将脑电信号分割成1000毫秒的片段,并通过训练的ARF检测器对其进行分类。然后,如图1所示,1000毫秒的信号被标记为一个红框。
III. 实验设计
我们使用提议的ARF检测器对波纹和FRs信号进行分类,并描述其实现、同行机器学习模型和验证方案。
A. 实施
我们的AttNN模型的结构在层的类型和每层的节点数量(例如,[8,16,32,64,128,256,512])方面进行了优化。在测试了几个经验值[0.001, 0.01, 0.1, 0.5]之后,学习率被设定为0.1。
我们从多个经验值[8, 16, 32, 64, 128]中设置批处理大小为64。超参数是在AttNN模型与验证数据成功收敛后确定的。我们通过定制Keras包的注意力层来实现自我注意机制,同时使用带有Nesterov动量技术的随机梯度下降法进行权重优化,全连接层的权重使用Glorot均匀分布进行初始化。历时的数量被设定为20个,并有一个早期停止机制,如果连续三个历时返回相同的损失错误,则终止优化过程。
所提出的模型是在Python 3.6环境下使用带有TensorFlow(2.0.0-rc1)后端的keras实现的。所有的实验都是在一个拥有10核英特尔酷睿i9处理器、64GB内存和一个GPU(Nvidia TITAN Xp,12GB内存)的工作站上进行,以加速模型的训练。
B. 同行机器学习模型
在这项研究中,我们将提议的ARF检测器与多个同行机器学习模型进行比较。这些模型使用scikit-learn 0.20.2 Python机器学习库[38]实现。
- K-近邻[39]。最近的邻居的数量从5到10进行优化。我们使用欧氏距离作为信号段之间的相似度测量。
- Logistic回归[40]。使用最大似然估计算法来优化逻辑回归模型的系数。
- 正则化线性模型[41]。对于正则化线性模型,我们选择LASSO和Elastic Net模型来完成分类任务。这两个模型的超参数根据验证数据进行了优化。
- 线性和非线性支持向量机[42]。对于线性SVM模型,我们用经验值[2-5, 2-4, ..., 24, 25]搜索边际惩罚。对于非线性SVM,我们采用径向基函数(RBF)核。通过网格搜索法,我们优化了边际惩罚[2-5, 2-4, ..., 24, 25],以及核规模伽玛[0.5, 1.0, 1.5, 2.0, 2.5]。
- L1规范SVM[43]。我们应用一个线性核,用经验值[0.2, 0.4, 0.6, 0.8, 1.0]来搜索边际惩罚。
- SMO检测器[21]。我们实现了一个4层的基于SSAE的NN,有一个输入层,三个隐藏层和一个输出层。三个隐藏层的节点数被设定为30。使用带有L2正则化和稀疏性正则化项的损失函数[44]。超参数稀疏比例从[0.1, 0.2, 0.3, 0.4, 0.5]中选择,L2正则化权重从[0.1, 0.2, 0.3, 0.4, 0.5]中决定。学习率被设定为0.01。如果模型在连续三个 epochs 中在验证数据上返回相同的损失,则停止训练。
C. 随机子抽样验证
由于地面真实数据集有限,我们在本研究中进行了反复的随机子抽样验证,并将整个涟漪和FRs数据集分成三部分。第一部分包括整个数据集的60%作为训练数据。第二部分包含整个数据集的20%作为验证数据,用于超参数选择。第三部分(即剩下的20%的数据)被当作测试数据。这种分离重复50次。对于每次重复的随机子抽样验证,我们计算模型的准确性、敏感性、特异性和接受者操作特征曲线下的面积(AUC)。计算50次重复的平均值和标准差来评估分类性能。
IV. 结果
A. 与同行模型的分类性能比较
我们首先测试并比较所提出的ARF检测器与同行模型的分类性能(表I)。
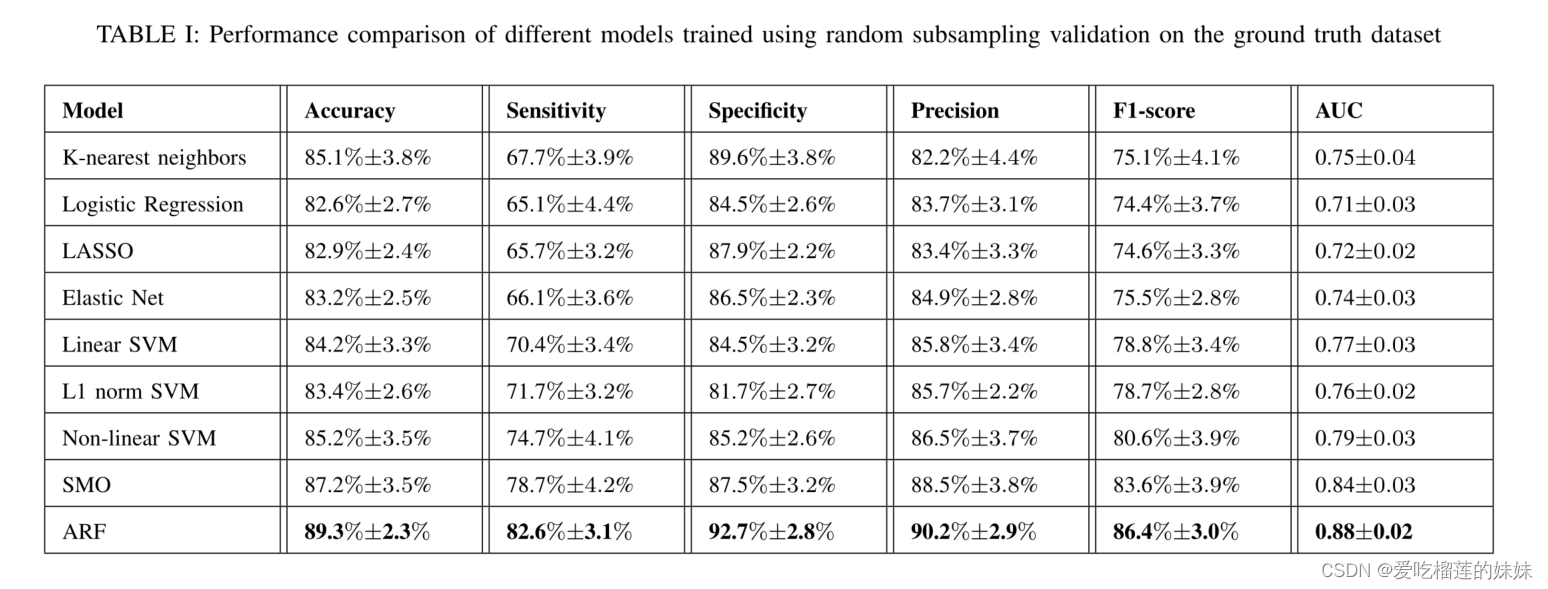
为了创造一个公平的比较,同样的随机子采样在所有的模型上都使用了验证,包括相同的分割和虚拟样本生成。逻辑回归模型的性能最低,而正则化(即LASSO和Elastic Net)方法在我们的任务中影响有限。与线性模型相比,SVM模型提高了性能,非线性核给出了最好的性能,平均精度为85.2%,平均AUC为0.79。KNN模型获得了85.1%的平均准确率,与SVM模型非常接近。我们之前的SMO检测器提供了87.2%的平均准确率和0.84的平均AUC。这与我们以前的工作[21]以及许多最近的研究相一致,表明NN技术通常会提高分类性能。在同样的虚拟样本生成方法下,ARF模型取得了最好的性能,平均准确率为89.3%,平均AUC为0.88(表I)。ARF检测器的这种改进性能归功于注意力机制。
B. 虚拟样本生成方法的影响
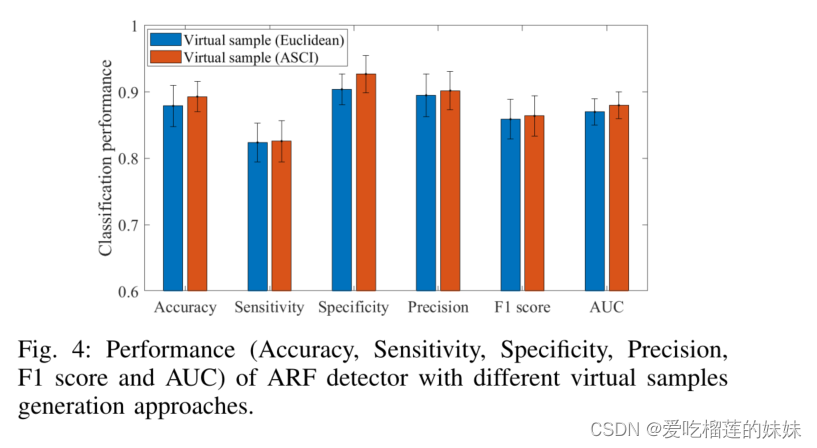
我们测试虚拟样本生成方法的影响。我们使用相同的ARF模型结构(图1)并比较三种情况。(1) 没有虚拟样本生成方法,(2) 使用欧氏距离(即ADASYN)的虚拟样本生成方法,以及(3) 使用ASCI距离的虚拟样本生成方法。图4显示,基于ASCI的方法使平均准确率提高了1.4%,平均AUC提高了0.01,表明基于ASCI的方法比基于欧氏的方法生成的虚拟样本更好。
C. 虚拟样本生成因素的影响
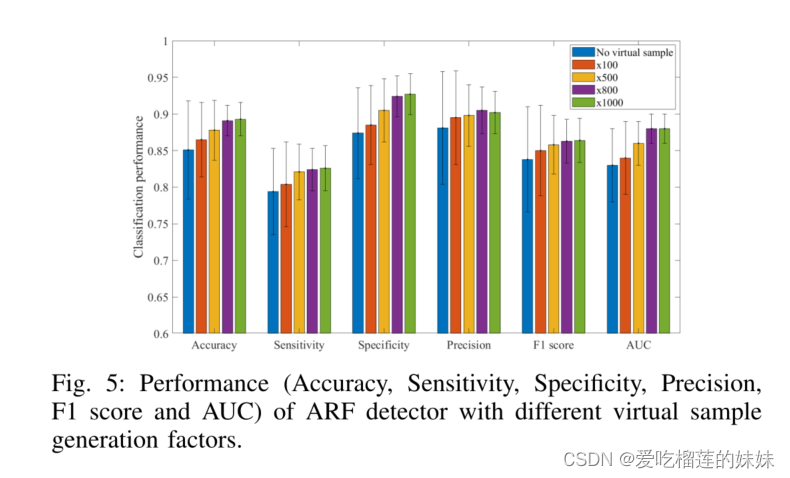
虚拟样本生成因素对模型训练很重要。这里,我们探讨了虚拟样本生成因素的影响。我们比较了由不同因子[0, 100, 500, 800, 1000]训练的ARF检测器的性能。如图5所示,没有任何虚拟样本生成的模型显示出最低的性能。此外,如果没有适当的样本增强,训练后的模型的性能有更大的标准偏差。随着更多的虚拟样本被生成,该模型实现了更好的平均性能和更小的性能变化。然而,我们注意到,生成因子为800的模型(89.1%的准确率和0.88的AUC)与生成因子为1000的模型(89.3%的准确率和0.88的AUC)的性能非常相似。
D. 注意机制的影响
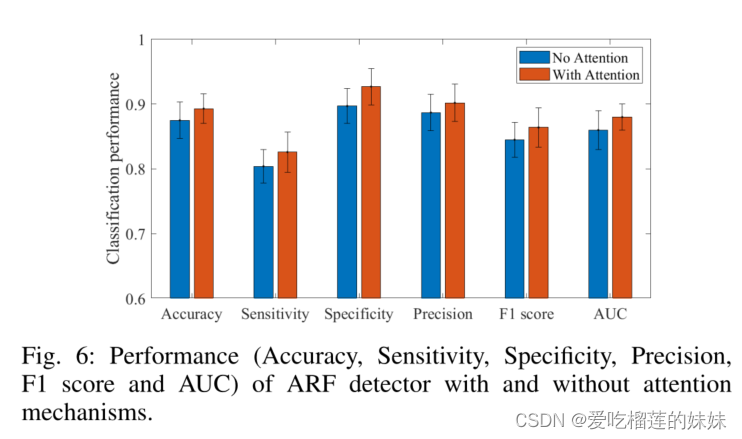
我们通过比较有和没有自我注意层的两个模型,进一步探讨注意机制是否能改善波纹和FR的分类。如图6所示,去掉注意层后,模型取得了较低的性能,平均准确率为87.5%,灵敏度为80.4%,特异性为89.7%,AUC为0.86。两个模型的标准偏差相似。
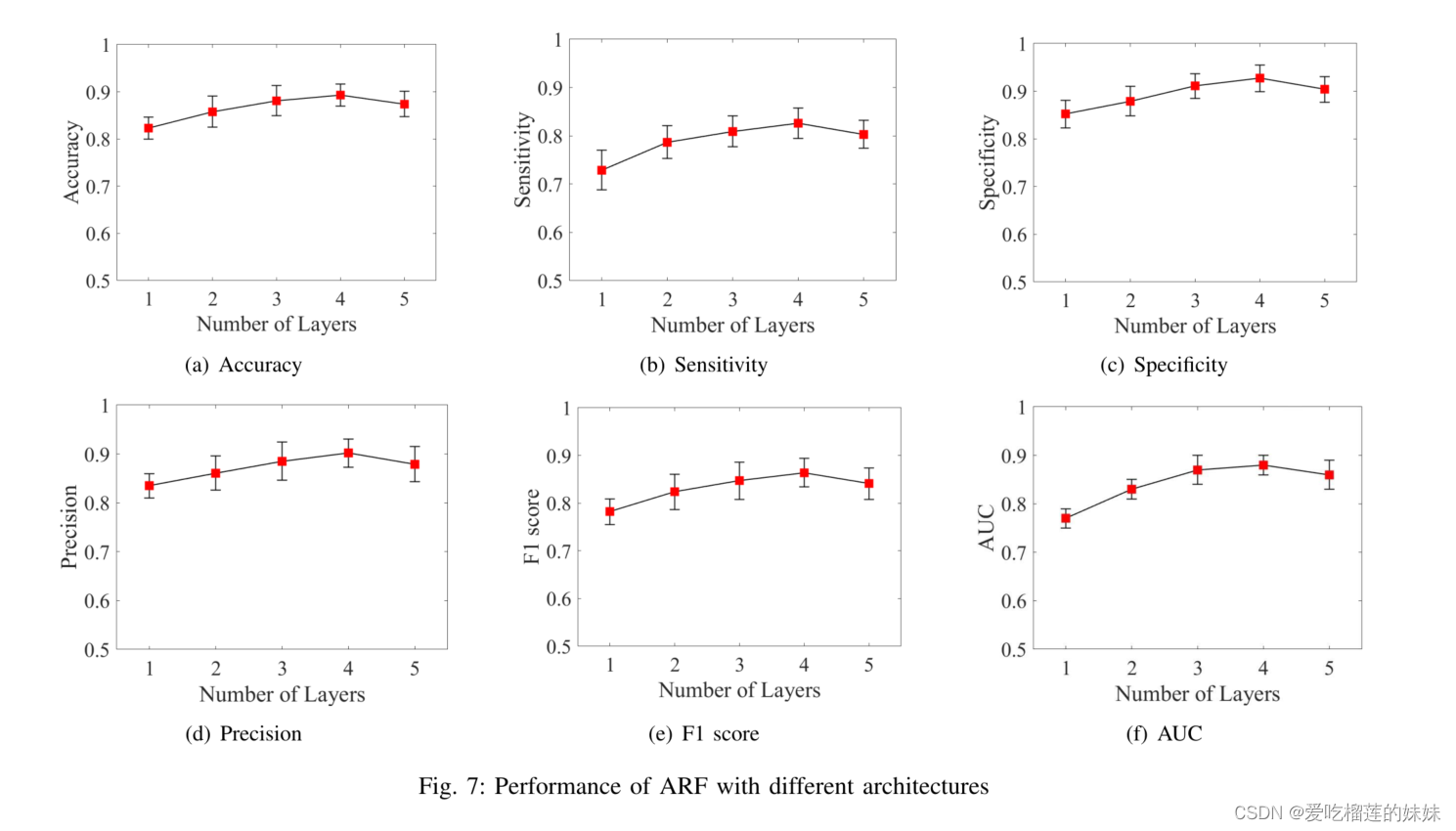
E. AttNN架构的影响
最后,我们测试NN架构的影响。具体来说,我们分别用1到5的密集层数量来优化模型的架构。密集层等于[128],[256,32],[256,64,8],以及[512,128,64,32,8],分别对应于1,2,3,5层模型。从图7中可以看出,当层数增加时,开始时的性能是增加的。但在4层模型中再增加一层后,性能就会下降。
F . 焦点区检测的性能比较
使用提出的ARF模型,我们继续测试FR信号是否能区分焦点区和非焦点区。我们使用信号属于波纹或FRs组的概率作为特征来区分焦点区和非焦点区。作为一种比较方法,我们还实施了延迟互变熵(DPE)方法[45],该方法最初是在脑电数据上提出的,用于区分病灶区和非病灶区的脑电片段。对于DPE方法,我们首先根据DPE指数来优化延迟滞后δ。延迟滞后δ=12可获得最佳的病灶区检测精度。
ARF和DPE方法的混淆矩阵显示在图8中。提出的ARF方法在焦点区检测上达到了93%的准确率,而比较的方法DPE的准确率为88%。这证明了ARF在检测致痫区方面的有效性。

V. 讨论:
对HFOs信号中的波纹和FR进行分类是实现癫痫患者精准医疗的关键一步。通过地面真实训练数据集,ARF检测器在波纹和FRs分类任务上达到了89.3%的准确性。这揭示了使用人工智能,特别是神经网络技术的可行性。
在结果的支持下,ARF检测器得益于虚拟样本生成和注意力机制。神经网络模型需要大量的训练数据[22]。事实上,第一个研究表明,NN模型比传统机器学习模型的强大潜力高度受益于ImageNet的大规模图像数据集[46]。很明显,NN模型的表现优于传统的模型如果存在足够的训练数据,就可以建立模型。另一方面,NN经常面临数据不足的问题。在我们的案例中,两位专家只收集了50个涟漪和50个FRs信号段。为了编制这样一个训练数据集,两位专家首先要分别确定目标信号段,然后讨论以保持标准不变。此外,确定的信号必须由iEEG记录确认,这是另一项耗时和昂贵的任务。有了这样一个小的训练集,虚拟样本生成方法提供了一个机会来训练一个可靠的NN模型。我们生成1,000次的训练样本,以便训练该模型。
这种大量的训练样本使得ARF模型有可能胜过同行的传统模型。更重要的是,我们用ASCI距离取代了欧氏距离。欧氏距离反映了两个样本在欧氏空间中的相似性,而ASCI距离则同时测量两个样本之间的线性关系和振幅差异。就MEG信号而言,ASCI量化了有意义的形态学相似性。这一点得到了结果的支持(图4)。
注意力机制是另一种提升ARF检测器性能的技术。尽管注意力机制最初是为自然语言处理提出的[24],但它已被扩展到其他应用中[47]。
MEG信号是有噪声的,并且包含用于信号分类的冗余信息。ARF检测器中的自我注意层能够根据内部提供的权重对某些信号特征重新加权。这种注意机制指导NN模型选择它应该注意哪些特征。自我注意层调整分配给各个信号特征的权重。在波纹和FRs分类任务中,自我注意层探索每个特征对整个脑电信号片段的重要性。换句话说,它优化了监督学习期间的特征提取。
这个自我注意层引导模式关注输入信号的某些部分,并将信号编码为更好的特征表示(图3)。我们的结果支持了这一点,与没有自我注意层的NN模型相比,注意机制提高了ARF的性能(图6)。
如图7所示,我们注意到,当模型具有相对简单的结构时,它能够学习和分类波纹和FRs信号模式,性能相对较低(例如,准确率为82.3%,AUC为0.77)。
当我们增加AttNN的层数时,涟漪和FRs的分类性能得到改善。在四层的情况下,所提出的模型能够将准确性提高到89.3%,AUC提高到0.88。(图7)这表明简单结构的模型没有足够的复杂性来学习涟漪和FRs信号的模式,而增加层数可以改善这种情况。(例如,准确率为87.4%,AUC为0.86)。当AttNN模型的结构对任务来说过于复杂时,该模型很容易被过度拟合。图7显示,用于波纹和FRs分类的AttNN模型的最佳结构是4层结构。
本研究有几个局限性。首先,我们的癫痫患者队列很小。我们只能从20个病人身上收集100个样本。虽然虚拟样本生成方法缓解了不足的问题,但更大的队列可能提供更好的生物品种。第二,根据临床常规,我们预先定义了脑电信号片段的持续时间为1秒。其他信号持续时间(如0.5-2秒)可能为信号分类提供额外的信息。最后,只对一个机构的一组数据进行了内部验证。需要从外部数据站点获得更多的数据集,以测试我们检测器的普遍性。
VI. 结论
这项工作引入了一种虚拟样本生成方法,通过创建更多的生物医学MEG信号来提高小型地面真实数据集的训练性能。当数据不足的问题被解决后,开发了一个ARF检测器,它采用了注意力机制来创建AttNN模型,以提高HFOs信号中FRs检测的性能。使用地面真实数据集,ARF检测器实现了89.3%的准确性和0.88的AUC,超过了SMO检测器和其他机器学习模型。最后,我们验证了FRs检测对致痫区定位的有效性。实验结果表明,我们的自动检测器是一个有前途的计算机辅助诊断工具,可用于临床应用。未来的工作包括ARF在其他神经电磁数据上的外部验证和临床应用,如EEG和iEEG的数据。