准备资源:kafka_2.11-2.4.1
一、Kafka概述
1. 是什么:消息队列
2. 架构图:
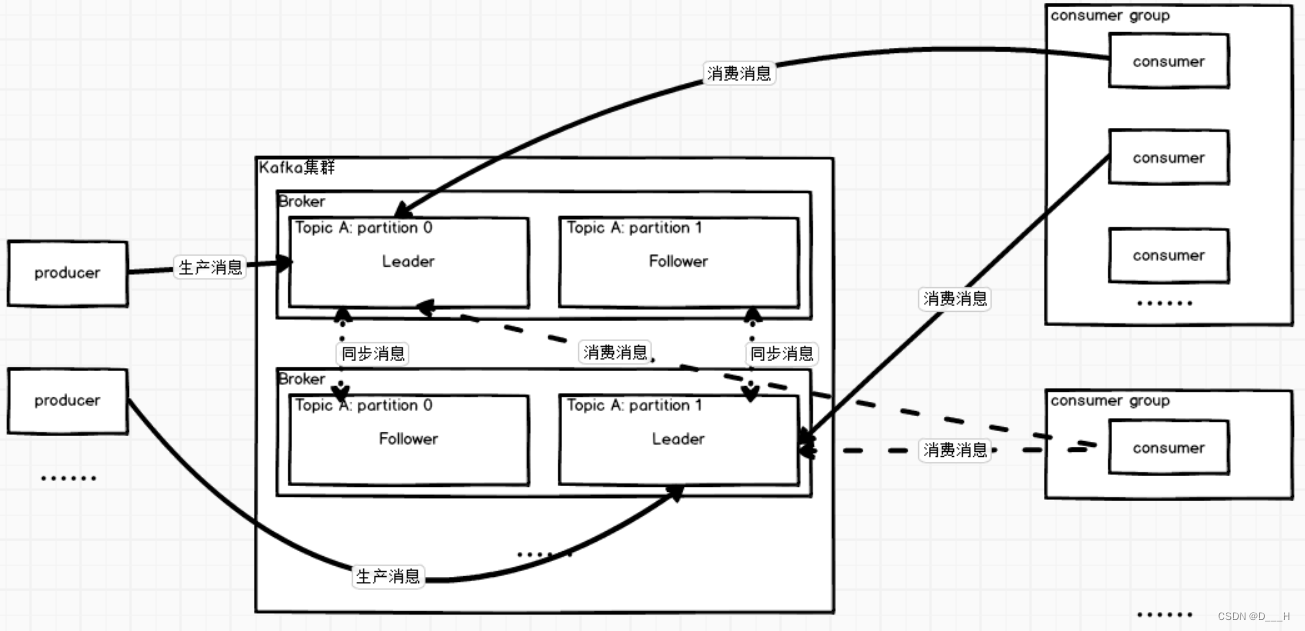
(1) Kafka集群需要搭建在多台服务器上, 每一台服务器称之为Broker,类似于Zookeeper集群中每一台服务器都要有唯一的myid一样,Broker都有唯一不重复的id;
(2) Broker组成的集群需要与Zookeeper协同工作,Zookeeper的作用主要是:帮助Broker集群选出老大(Controller),选举策略采用争抢式,存储Broker集群的信息;
(3) Topic是消息队列,内部还会细分多个分区,producer负责产生消息给Topic,消息具体放在那个分区由一定算法决定;
(4) consumer负责从Topic中消费消息,更正确的说,应该是consumer group中的consumer从Topic中的partition中消费消息;但是消息的消费是面向消费者组的,消息的消费位置是这么记录的:哪一个消费者组消费了哪一个Topic的哪一个分区的位置。这么一来,当有新的消费者加入,这个消费者就可以轻松通过消费者组来获得上一次该组对其他消息队列的消费位置了。
(5) partition类似于Zookeeper,也会有Leader和Follower,producer生产数据、consumer group消费数据都是去寻找分区中的Leader;
(6) partition的多个副本不会同时出现在一台Broker中,一般情况下(服务器够用,一台服务器上一个分区Leader),不同partition的Leader也不会出现在同一台Broker中;
(7) partition中的消息是有序的,即先进先出
(8) 当只有一个消费者组消费时:多个partition可以被一个消费者组中的一个消费者同时消费,每个partition最多同时被一个消费者组中的一个消费者消费;当有多个消费者组消费时:partition可以同时被多个消费者组中的某个消费者消费(一个消费者组中只能有一个消费该分区的consumer);
二、Kafka集群安装部署(默认连接kafkaServer的端口号为:9092)
1.准备机器为:hadoop101、hadoop102、hadoop103
2. 将kafka_2.11-2.4.1上传至hadoop101的/opt/software目录下,并将其解压到/opt/moudle目录下
# 来到/opt/software/目录下
cd /opt/software/
# 解压
tar -zxvf kafka_2.11-2.4.1.tgz -C ../moudle/3. 在hadoop101上配置环境变量
# 打开自己创建的环境变量配置文件
sudo vim /etc/profile.d/my-env.sh
# 新增的环境变量内容为:
# KAFKA环境变量
export KAFKA_HOME=/opt/moudle/kafka_2.11-2.4.1
export PATH=$PATH:$KAFKA_HOME/bin4. 修改hadoop101上的kafaka配置文件
# 打开配置文件
vim /opt/moudle/kafka_2.11-2.4.1/config/server.properties
# 修改内容如下
# 21行,broker的id,集群内所有机器的broker.id不能重复
broker.id=101
# 60行,配置kafka存放消息数据的位置,框架打印日志的位置在$KAFKA_HOME/logs
log.dirs=/opt/moudle/kafka_2.11-2.4.1/data
# 123行,配置zookeeper的连接地址,配置多个表示前面的连不上就连后面的
zookeeper.connect=hadoop101:2181,hadoop102:2181,hadoop103:2181
# 保存退出5. 向其它机器分发环境变量以及kafka,同时在其他机器中修改broker.id
(1) 分发kakfa,修改broker.id
# 分发kafka,操作于hadoop101中
xrsync.sh /opt/moudle/kafka_2.11-2.4.1
# 修改broker.id,于hadoop102种操作
broker.id=102
# 修改broker.id,于hadoop103种操作
broker.id=103
(2) 分发环境变量文件
# 分发环境变量,于hadoop101中操作
# 进入root用户,继承当前用户的环境变量
su
# 分发
xrsync.sh /etc/profile.d/my-env.sh
# 退出root
exit
# 使所有机器的环境变量生效
xcall.sh "source /etc/profile"
6. 启停
(1) 提供的启停命令
| 命令 | 描述 |
| kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties | 启动kafka集群的命令,需要在每台机器上单独使用该命令 |
| kafka-server-stop.sh | 停止kafka集群,需要在每台机器上单独使用该命令 |
(2) 启停脚本编写:
a. 编写java代码并打成jar包,用来从zookeeper中读取节点上的Data
编写pom:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<scope>compile</scope>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.7</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>在resources目录下,新建配置文件log4j.properties:
log4j.rootLogger=OFF, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
项目结构为:
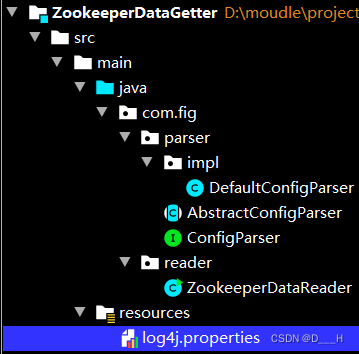
类文件为:
package com.fig.parser;
/**
* 规定解析Zookeeper节点data的类必须实现的方法
*/
public interface ConfigParser {
/**
* 解析方法
* @return data you want
*/
Object parse();
}
package com.fig.parser;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
public abstract class AbstractConfigParser implements ConfigParser {
// JSON格式的字符串
private String configInJSON;
// 含参构造方法
public AbstractConfigParser(String configInJSON){
this.configInJSON = configInJSON;
}
public void setConfigInJSON(String configInJSON){
this.configInJSON = configInJSON;
}
public String getConfigInJSON(){
return this.configInJSON;
}
/**
* 将configInJSON处理成一个类似于Map的JSON对象
* @return JSONObject
*/
private JSONObject parseToJSONObject(){
if (JSON.isValid(this.configInJSON)){
return JSON.parseObject(this.configInJSON);
}
return null;
}
@Override
public Object parse() {
JSONObject jsonObject = parseToJSONObject();
if (jsonObject != null){
Object value = jsonObject.get(getPropertyKey());
return processValue(value);
}
return null;
}
/**
* 抽象方法,留给继承类实现。用来获取由parseToJSONObject()方法生成的jsonObject中对应key的value
* @return key,类型为Object
*/
public abstract Object getPropertyKey();
/**
* 对根据key获取到的value做进一步处理,可能获取到的value又是一个JSONObject或者JASONArray
* @param value 根据key获取到的value
* @return Object
*/
public Object processValue(Object value){
return value;
}
}
package com.fig.parser.impl;
import com.fig.parser.AbstractConfigParser;
/**
* 解析kafka存储在zookeeper中的数据的分析类
*/
public class DefaultConfigParser extends AbstractConfigParser {
private String key;
private DefaultConfigParser(String configInJSON) {
this(configInJSON, null);
}
public DefaultConfigParser(String configInJSON, String key){
super(configInJSON);
this.key = key;
}
public void setKey(String key){
this.key = key;
}
public String getKey(){
return this.key;
}
@Override
public Object getPropertyKey() {
return this.key;
}
}
package com.fig.reader;
import com.fig.parser.AbstractConfigParser;
import com.fig.parser.ConfigParser;
import com.fig.parser.impl.DefaultConfigParser;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.function.Function;
import java.util.function.Predicate;
import java.util.stream.Collectors;
/**
* 从zookeeper中读取data的类
*/
public class ZookeeperDataReader {
// 连接字符串
private String connectString;
// 超时掉线时间
private int sessionTimeput = 20000;
// zk客户端
private ZooKeeper zk;
// 日志打印对象
private Logger logger = LoggerFactory.getLogger(ZookeeperDataReader.class);
public ZookeeperDataReader(String connectString){
try {
this.connectString = connectString;
zk = new ZooKeeper(connectString, sessionTimeput, new Watcher() {
@Override
public void process(WatchedEvent event) {}
});
} catch (IOException e) {
logger.error(e.getMessage());
}
}
public List<String> read(String path, ConfigParser configParser){
List<String> res = null;
try {
Stat stat = zk.exists(path, false);
res = zk.getChildren(path, false, stat).stream().map(new Function<String, String>() {
@Override
public String apply(String s) {
try {
((AbstractConfigParser)configParser).setConfigInJSON(new String(zk.getData(path + "/" + s, false, stat), StandardCharsets.UTF_8));
Object result = configParser.parse();
if (result != null){
return result.toString();
}
} catch (KeeperException e) {
logger.error(e.getMessage());
} catch (InterruptedException e) {
logger.error(e.getMessage());
}
return null;
}
}).filter(new Predicate<String>() {
@Override
public boolean test(String s) {
return s != null && !s.equalsIgnoreCase("");
}
}).collect(Collectors.toList());
} catch (KeeperException e) {
logger.error(e.getMessage());
} catch (InterruptedException e) {
logger.error(e.getMessage());
}finally {
cleanup();
}
return res;
}
public void cleanup(){
try {
this.zk.close();
} catch (InterruptedException e) {
logger.error(e.getMessage());
}
}
public static void main(String[] args) {
/*
* args[0]: connectString
* args[1]: path
* args[2]: key
*/
if (args.length == 3){
ConfigParser configParser = new DefaultConfigParser(null, args[2]);
ZookeeperDataReader reader = new ZookeeperDataReader(args[0]);
List<String> list = reader.read(args[1], configParser);
if (list == null || list.size() == 0){
System.out.println("null");
}else {
list.forEach(System.out::println);
}
}
}
}
通过maven工具,将其打成jar包,上传至任意一台安装了zookeeper和kafka的服务器上,存放位置为:/home/$USER/bin
b. 编写启停脚本
先进入zookeeper的客户端,创建节点:/kafka-brokers/ids/101、/kafka-brokers/ids/102、/kafka-brokers/ids/103,101、102、103分别是三台broker的id,创建的是持久节点,用来供上面写好的jar包读取配置用的,101、102、103节点中的内容分别是JSON字符串,分别为:{"host":"hadoop101"}、{"host":"hadoop102"}、{"host":"hadoop103"};
# 在~/bin目录下新建脚本文件为:kafka.sh
vim kafka.sh
# 脚本内容如下
#!/bin/bash
function hasClosed(){
num=$(cd /home/$USER/bin;java -cp ZookeeperDataGetter-1.0-jar-with-dependencies.jar com.fig.reader.ZookeeperDataReader $connectionString /kafka-brokers/ids host | wc -l)
for host in $(cd /home/$USER/bin;java -cp ZookeeperDataGetter-1.0-jar-with-dependencies.jar com.fig.reader.ZookeeperDataReader $connectionString /kafka-brokers/ids host)
do
if [[ $(ssh $host "jps" | grep -i -E 'kafka' | wc -l) -eq 0 ]]
then
let num--
fi
done
return $num
}
if [[ $# -ne 1 ]]
then
echo "usage: kafka.sh (start|stop)"
exit 1
fi
connectionString=$(awk -F'=' '/zookeeper\.connect=/{print $2}' $KAFKA_HOME/config/server.properties)
case $1 in
start)
for host in $(cd /home/$USER/bin;java -cp ZookeeperDataGetter-1.0-jar-with-dependencies.jar com.fig.reader.ZookeeperDataReader $connectionString /kafka-brokers/ids host)
do
echo "==========$host========="
ssh $host "kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties"
done
;;
stop)
for host in $(cd /home/$USER/bin;java -cp ZookeeperDataGetter-1.0-jar-with-dependencies.jar com.fig.reader.ZookeeperDataReader $connectionString /kafka-brokers/ids host)
do
echo "==========$host========="
ssh $host "kafka-server-stop.sh -daemon $KAFKA_HOME/config/server.properties"
done
hasClosed
while [[ $? -ne 0 ]]
do
sleep 2
hasClosed
done
;;
*)
echo "usage: kafka.sh (start|stop)"
exit 1
;;
esac
# 保存退出,赋予执行权限
chmod +x ~/bin/kafka.sh(3) 启停脚本使用格式
# zookeeper集群需要自己启动,kafka启停脚本只关注kafka的启停
# 启动kafka集群
kafka.sh start
# 停止kafka集群
kafka.sh stop