Hadoop生态系统将长期存在。作为近年来最重要的大数据支持技术之一,并且预计未来几年仍将继续发挥重要作用,Hadoop如今已成为通用数据集成系统(如数据虚拟化平台)的关键目标数据源之一。然而,Hadoop不仅仅是一个数据库或一款软件。它是一个复杂的生态系统,由多种高度异构的软件组成,运行于分布式数据环境中——几乎可以看作是一个独立的操作系统。因此,将Hadoop作为数据源进行集成,带来了一系列其他系统所没有的挑战。我们可以从思考将Hadoop作为数据源集成究竟意味着什么开始。
我们可以通过定义一系列独立的集成点来分析这个场景,将其分为两组:基本集成点和专业集成点。这些集成点将赋予数据虚拟化平台使用Hadoop安装的特定部分作为独立数据源的能力,每个部分具有自己的特性和功能。
基本集成点
Hadoop核心的两个最重要组件之一是Hadoop分布式文件系统(HDFS)。HDFS是一个独立于主机操作系统的文件系统,其维护方式使得所有存储在其中的文件都被分布到Hadoop集群的不同节点上。HDFS对于数据虚拟化(DV)平台极为重要,因为所有数据都存储在这里,而这些数据可能被各种Hadoop支持的软件所使用。如果我们执行自定义的MapReduce任务,它们的结果会输出到HDFS文件中;如果我们使用Hive或HBase,它们的数据也会存储在HDFS中;如果我们使用任何Hadoop脚本语言,操作的也是HDFS文件。数据就存储在这里,我们可能需要以某种方式访问它,就像我们可能需要直接访问DV平台主机系统上本地或远程文件夹中的文件一样,无论这些文件的格式或创建它们的软件是什么。
除了命令行,HDFS还提供了一种二进制API库,可以帮助数据虚拟化平台访问其中的数据。这个API支持文件系统中的不同类型的文件以及可以对它们执行的操作。但是,它是一个二进制API,因此使用它时,我们在软件和Hadoop的API之间建立了一个硬链接或依赖关系。当开发定制的内部解决方案时,这并不是什么大问题,但当创建通用的数据集成工具时,要求它们能够在各种不同的场景中开箱即用时,这就构成了一个重要挑战。此外,数据虚拟化系统通常部署在远程的Hadoop集群上,因此,许多时候,使用这些高性能二进制库的好处可能相较于使用更标准的接口有所限制。
大多数Hadoop安装还允许通过REST API访问HDFS及其操作,主要通过两个接口:WebHDFS和HttpFS。它们之间存在一些概念上的差异(例如,WebHDFS会将客户端重定向到数据所在的特定节点,而HttpFS则可以作为单服务器代理),这可能使我们根据特定场景的需求偏好其中一个。不过,通常情况下,它们是互操作的,提供了非常好的性能,最重要的是为外部/远程数据集成软件(如DV)提供了一个基于HTTP协议的标准、解耦的接口来访问数据。
因此,一旦文件系统的访问问题解决,接下来我们可能需要的其他基本/核心集成点是什么呢?安全性,当然!
Hadoop中的安全性几乎成为了一个独立的行业。Hadoop系统中有许多不同的数据加密、身份验证和授权解决方案,这也是必须的,因为我们谈论的是保护大量可能敏感的数据以及处理这些数据的过程。多年来,各个企业级Hadoop发行商都为生态系统贡献了自己的力量,安全性是创新(以及异构化)最为显著的领域之一。
然而,从数据虚拟化平台的角度来看,集成Hadoop(或其部分)作为数据源时,我们通常将Hadoop安全性视为外部/远程客户端,因此,大多数加密和授权机制应该对我们透明。这意味着我们可以专注于身份验证,特别是专注于几乎所有Hadoop服务中最普遍的身份验证机制:Kerberos。
通过设置一个密钥分发中心(KDC),Kerberos能够以集中方式保护Hadoop安装中的所有用户密码,但这要求Hadoop客户端在身份验证过程中能够使用Kerberos协议,即获取并管理特定的身份验证凭证(票证),并将它们发送给Hadoop中的Kerberos化服务。这要求数据虚拟化系统集成(或至少能够与之交互)Kerberos客户端软件,以便能够与Hadoop服务建立安全通信通道。
对于像WebHDFS和HttpFS这样的HTTP REST API,通常会提供一种名为Kerberos SPNEGO的特定机制,数据虚拟化平台可以使用该机制访问这些服务。
通过HDFS和安全性,我们已经涵盖了基本要素:我们可以以安全的方式访问Hadoop安装中的数据。然而,实际上,大多数Hadoop安装并不仅仅运行自定义开发的MapReduce任务,并将文件输出到HDFS。相反,更多复杂的Hadoop支持软件在Hadoop核心上运行,能够更高效地进行数据存储、查询和分析,这些数据虚拟化平台可以作为其数据源,而不必直接访问HDFS。这就是我们离开Hadoop核心并开始讨论专业集成点的地方,也就是与运行在Hadoop系统上的特定数据服务的集成。
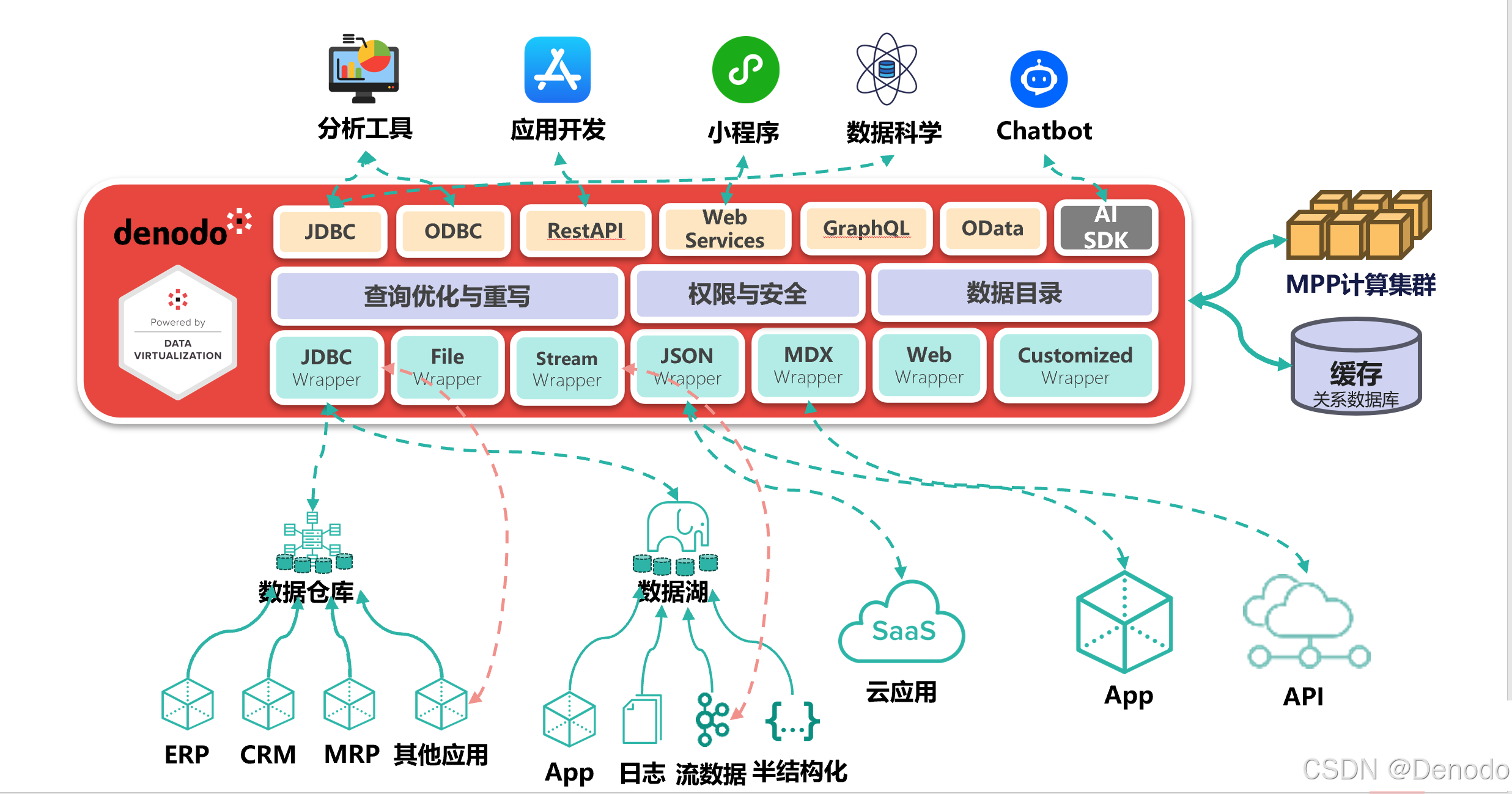
专业集成点
Hadoop是一个非常健康且富有生机的生态系统,有大量不同的数据导向工具可以在Hadoop核心上运行。从数据虚拟化平台的角度来看,许多这些工具可以作为数据源,但它们的异质性使得每一个工具都必须单独研究。从数据消费者的角度来看,没有“与Hadoop集成”这一说法,只有“与Hadoop的X服务集成”这一说法。
让我们简要评论两个最受欢迎的Hadoop数据服务:Apache HBase和Apache Hive。
Apache HBase是一个运行在HDFS上的NoSQL数据存储。它的关键特点是能够提供对存储在HDFS中的数据的随机实时访问(而HDFS本身无法提供这种访问)。它具有类似于Google BigTable设计的键值数据存储形式,并根据具体的Hadoop发行版提供多种访问方式,从二进制API库到REST接口等,采用不同的安全机制(主要基于Kerberos认证)。
从数据虚拟化平台的角度来看,访问HBase通常意味着远程访问。为此,REST API是一个良好的标准且解耦的选择,但出于性能或架构原因,我们可能更倾向于选择二进制API。在这种情况下,和直接访问HDFS一样,我们将面临将代码与这些二进制API的特定版本高度耦合的问题,因此我们实际上是在以性能为代价,换取了维护上的便利。需要注意的是,HBase并不是一个关系型数据存储,因此它并没有(直接)提供任何标准的SQL接口供我们通过标准API(如JDBC或ODBC)远程访问。
Apache Hive是一个针对大数据集的查询和分析工具。它运行在HDFS之上,并提供了类似SQL的接口,适合从数据虚拟化平台进行简单查询。此外,Hive不仅可以直接对HDFS存储的数据集进行操作——实际上,它还可以利用现有的HBase基础设施,借助Hive强大而灵活的数据分析工具对已存储和/或处理的数据进行分析。数据虚拟化平台可以通过标准的JDBC或ODBC驱动程序轻松访问Hive服务,通过Kerberos进行身份验证,并将来自Hadoop安装的数据几乎与任何其他关系型数据库管理系统(DBMS)一样进行集成。
然而,HBase和Hive只是两个(非常流行的)示例。可以作为数据虚拟化数据源使用的Hadoop数据服务非常多,还有许多其他流行的软件包,如Apache Phoenix、Cloudera Impala、Pivotal HAWQ、MapR-DB等。在几乎每种情况下,我们都会发现数据虚拟化系统作为远程客户端,使用二进制库、基于REST的API或SQL API(如JDBC)来检索数据,并使用Kerberos认证。每种接口的选择将在每种情况下决定这些集成的可维护性、性能和开发工作量,最终将根据每种场景采用的方法和架构,帮助数据虚拟化平台从Hadoop大数据系统中提取最大价值。
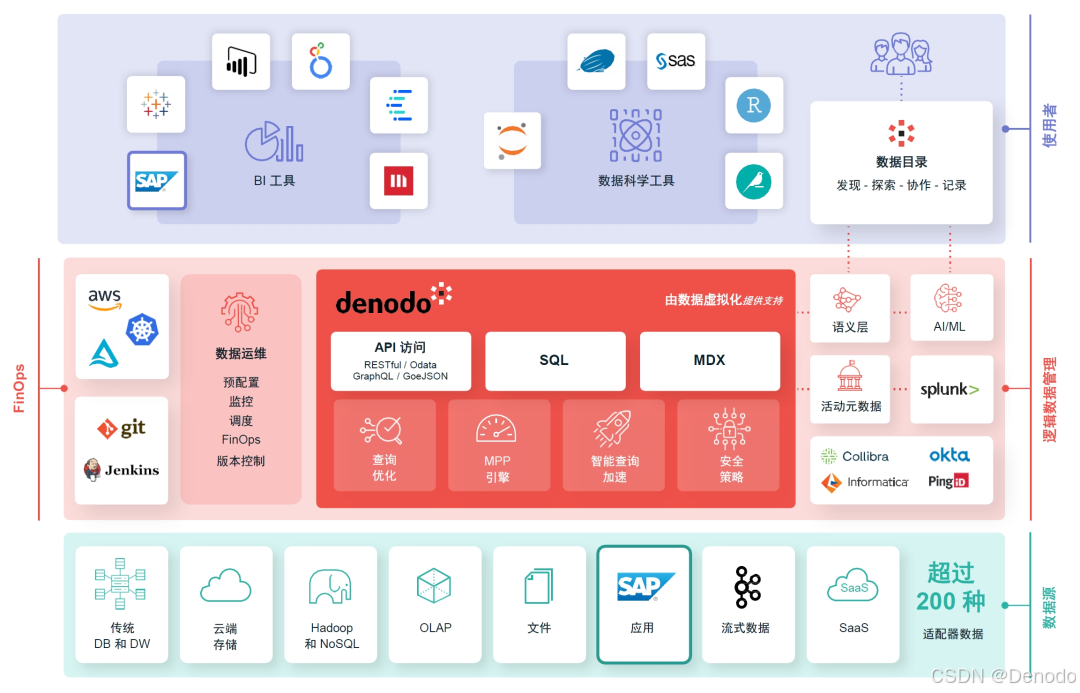
5分钟了解Denodo
 https://github.com/denodo/denodoconnect-hadoop
https://github.com/denodo/denodoconnect-hadoop