将此题分为两个步骤:
找出高频词汇
首先我们需要使用python中的jieba库;目前最好的 Python 中文分词组件,它主要有以下 3 种特性:
- 支持 3 种分词模式:精确模式、全模式、搜索引擎模式
- 支持繁体分词
- 支持自定义词典
具体案例:https://www.jianshu.com/p/883c2171cdb5
安装:
使用管理员身份打开CMD:输入pip install jieba下载成功后打开pyCharm->File->Settings->Project Interpreter,如果Package中没有jieba,点击右边的“+”号添加即可。
读取文本文件,我们在第十章学到过:with open(file) as name:** = name.read(),这里同样使用。不过我们需要加上编码格式encoding=“utf-8”。
with open("D:\\Python\\projects\\python_01\\files\\JourneytotheWest.txt", encoding="gb18030") as file:
contents = file.read()
接着我们使用jieba中的方法lcut对文本进行精确分词:导入jieba库
import jieba
# 使用jieba中的方法lcut对文本进行精确分词
words = jieba.lcut(contents)
再自定义一个存储词语及其出现次数的容器,最后遍历。需要注意的是我们要排除单个字。
# 存储词语及其出现的次数
counts = {}
for word in words:
# 单个字排除
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
将键值对转换成list列表,且按照降序的排序顺序。
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
items.sort(key=lambda x: x[1], reverse=True)这个语句中的sort函数用于对原列表就行排序,如果指定参数,则使用比较函数指定的比较函数。reverse=True是降序的意思,反之False为升序。这里的难点是key=lambda x: x[1],这个lambda是一个隐函数,后面的x: x可以自定义两个一样的字母,[0]按照第一维排序,[1]按照第二维排序,[2]按照第三维排序。我们这里排序是根据该词语出现的次数进行排序,我们输出的结果格式是(word,count),count就是次数。
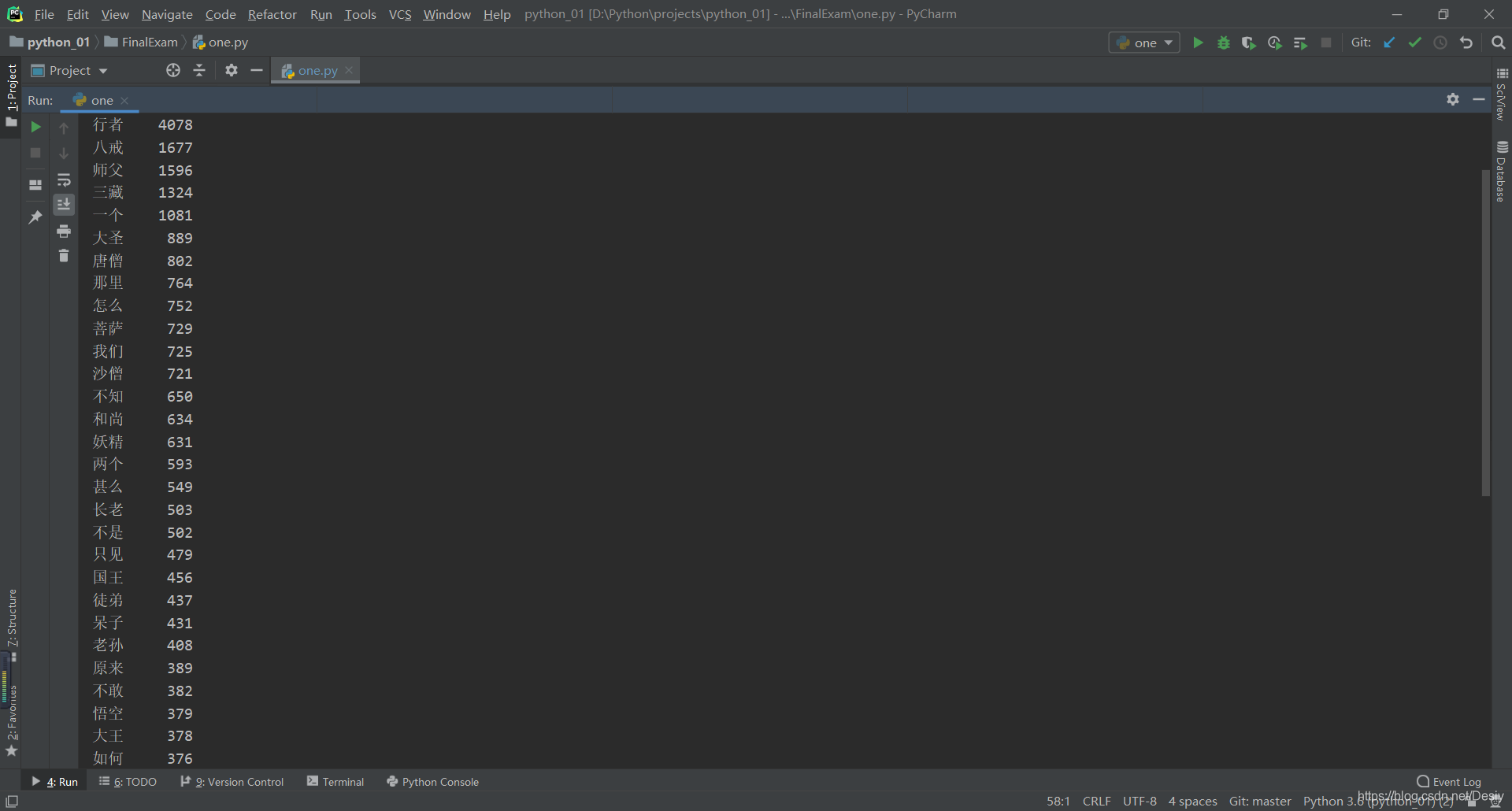
打印输出词频为前50的词语:
for i in range(50):
word, count = items[i]
txt = "{0:<5}{1:>5}".format(word, count)
print(txt)
txt = ("{0:<5}{1:>5}".format(word, count))这个是format方法的格式控制。比如:"{0}{1}".format(name,jack),这里大括号里的数字表示的是位置,也就是0对应的name,1对应的jack。同理,题中0对应的是word,1对应的是count。其次,冒号是引导符,后面跟的是格式控制方法。<表示左对齐,>表示右对齐,数字表示宽度。同理,题中<10表示左对齐,并占10个位置,>5表示右对齐,占5个位置。运行后报错:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xa1 in position 0——这是Python 编码中编码解码的问题,我这个错误就是‘utf-8’不能解码位置0的那个字节(0xa1),也就是这个字节超出了utf-8的表示范围了,我们这里将前面打开文本文件语句中的encoding="utf-8"换成encoding="gb18030"即可。
结果:
最后就是绘图。我们结合第十七章练习完成。练习中是从一个json文件中获取,那么我们可不可以直接使用上一步生成的数据来生成图表呢?练习中我们从json文件中通过遍历取的的值作为图表的参数,这里我们直接省去了json文件遍历,直接使用数据作为图表的参数。
定义储存词汇和次数的空数组,并且在将具体的数据append到空数组中:
names, dicts = [], []
for i in range(50):
word, count = items[i]
txt = "{0:<5}{1:>5}".format(word, count)
# print(txt)
names.append(word)
dicts.append(count)
可视化
my_style = LS('#333366', base_style=LCS)
chart = pygal.Bar(style=my_style, x_label_rotation=45, show_legend=False)
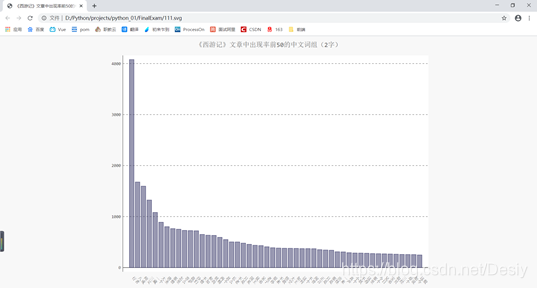
chart.title = '《西游记》文章中出现率前50的中文词组(2字)'
chart.x_labels = names
chart.add('', dicts)
最后在生成图表(svg):
chart.render_to_file('111.svg')
全部代码:
import jieba
import pygal
from pygal.style import LightColorizedStyle as LCS, LightenStyle as LS
with open("D:\\Python\\projects\\python_01\\files\\JourneytotheWest.txt", encoding="gb18030") as file:
contents = file.read()
# 使用jieba中的方法lcut对文本进行精确分词
words = jieba.lcut(contents)
# 存储词语及其出现的次数
counts = {}
for word in words:
# 单个字排除
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
# 将键值对转换成list列表
items = list(counts.items())
# reverse=True降序
items.sort(key=lambda x: x[1], reverse=True)
names, dicts = [], []
for i in range(50):
word, count = items[i]
txt = "{0:<5}{1:>5}".format(word, count)
# print(txt)
names.append(word)
dicts.append(count)
# 可视化
my_style = LS('#333366', base_style=LCS)
chart = pygal.Bar(style=my_style, x_label_rotation=45, show_legend=False)
chart.title = '《西游记》文章中出现率前50的中文词组(2字)'
chart.x_labels = names
chart.add('', dicts)
chart.render_to_file('111.svg')
PS:上文提到的”第十章“”第十七章“均来自图书《Python编程:从入门到实践》。
西游记.txt获取:https://gitee.com/desiy/python_01/blob/master/files/JourneytotheWest.txt