一、1.引言
在当今的网络时代,信息传播趋于自由化且高速发展,无数的信息倾泻而下,可以从互联网获取的信息类型有很多,例如新闻、博客、论坛,乃至小说。对于读者来说,如果能有一种程序它可以自动地从网络上抓取我们需要的小说,那么阅读将会变得更加快捷和便利。为此,我计划设计并实现一个网络爬虫程序,以自动爬取起点中文网的特定小说并下载到本地。
二、2.设计思路
在设计该爬虫程序时,首先需要考虑网站的结构特点和爬取策略。经过调研,我决定使用Python语言实现该爬虫程序,具体采用requests库和BeautifulSoup库。requests库可以方便地进行网络请求,获取网站的源码,BeautifulSoup库则用于解析HTML源码,提取我们需要的信息。
此网络爬虫程序分为两个程序一个为单个的小说的爬取先利用窗口向用户请求网址,方便用户调用。再将爬取下来的文章保存到文件夹。此为基础的实现。
此外,还考虑单个爬取的项目效率过低,我使用Queue作为数据共享方式,ThreadPoolExecutor作为线程管理的方式,用于创建一个线程池,以便在多线程环境下执行任务,用于处理线程和进程的并发。我计划使用线程池实现多线程下载,以提高下载的效率。可看作了进阶的爬取JavaScript渲染的内容、遵循robots.txt规则的爬虫实现
三、基础实现过程
1,首先,导入需要使用的库,包括os,requests,BeautifulSoup,pyautogui 和 time。
import os
import requests
from bs4 import BeautifulSoup
import pyautogui as pg
import time
2,设置 HTTP 请求的 cookies 和 headers。这些信息会被附加到 HTTP 请求中,服务器会解析这些信息以获得请求的一些细节,例如浏览器类型(User Agent),语言偏好等。
设置 HTTP 请求的 cookies 和 headers。这些信息会被附加到 HTTP 请求中,服务器会解析这些信息以获得请求的一些细节,例如浏览器类型(User Agent),语言偏好等。
cookies = {
'e1': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'e2': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'_csrfToken': 'bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7',
'traffic_utm_referer': 'https%3A//www.google.com/',
'_yep_uuid': 'd34769eb-33ab-2ed9-fb36-24ee50ef6100',
'newstatisticUUID': '1718695848_1379700380',
'fu': '898414530',
'e2': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D',
'supportwebp': 'true',
'e1': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D',
'w_tsfp': 'ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,ja;q=0.8,zh-TW;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'e1=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; _csrfToken=bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7; traffic_utm_referer=https%3A//www.google.com/; _yep_uuid=d34769eb-33ab-2ed9-fb36-24ee50ef6100; newstatisticUUID=1718695848_1379700380; fu=898414530; e2=%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; supportwebp=true; e1=%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D; w_tsfp=ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
这些东西怎么多那要是说不想自己写应该如何:
推荐该网站https://curlconverter.com/它可以自动生成请求的 cookies 和 headers
关于起点小说网址的反爬应对措施可参考我的另一部博客https://blog.csdn.net/Du_XiaoNan/article/details/136774768
本篇文章主要讲多线程多进程
3,使用一个死循环来获取用户输入的网址,用于爬取小说。如果输入的网址以指定的字符串开始,则终止循环,否则打印错误信息继续循环。
while True:
users_input = pg.prompt(title="请输入你要爬取的起点小说网址:", text="网址", default="https://www.qidian.com/book/1036526469/")
if users_input.startswith('https://www.qidian.com/book/'):
print("网址正确")
break
else:
print("网址错误")
4,发送包含 cookies 和 headers 的 GET 请求到用户输入的网址,获取网页内容。
response = requests.get(users_input, cookies=cookies, headers=headers)
5,使用 BeautifulSoup 库解析获取到的网页内容。
bs = BeautifulSoup(response.text, 'html.parser')
6,使用 BeautifulSoup 的 find_all 方法找到页面的章节链接,和小说的名字。
ba_a=bs.find_all('a',class_='chapter-name')
7,创建一个和小说名相同的文件夹,用来存放下载的章节文件。
ba_a2 = bs.find_all('h1' ,id="bookName")
main=f'{ba_a2[0].text}'
if not os.path.exists(main):
os.makedirs(main)
8,循环遍历每个章节链接,对每个章节链接执行以下操作:
# 下载章节
k=0
for i in ba_a:
k+=1
print(f"正在下载{i.text}")
url2 =f"https:{i['href']}"
rul = requests.get(url2, cookies=cookies, headers=headers)
bs2 = BeautifulSoup(rul.text, 'html.parser')
bs2_a = bs2.find_all('p')
with open(f'{main}/{i.text}.html','w',encoding='utf-8') as f:
# 写入html基础格式
f.write(f'<!DOCTYPE html>\n<html lang="en">\n<head>\n <meta charset="UTF-8">\n <title>{i.text}</title>\n</head>\n<body>\n')
# 写入章节题目居中
f.write(f'<h1 style="text-align: center">{i.text}</h1>\n')
for j in bs2_a:
f.write(f"<h4>{j.text}</h4>")
f.write('\n')
# 写入上一章
f.write(f'<a href="{ba_a[k-2].text}.html">上一章</a>\n')
#
# 写入下一章
f.write(f'<a href="{ba_a[k].text}.html">下一章</a>\n</body>\n</html>')
完整代码
import os
import requests
from bs4 import BeautifulSoup
import pyautogui as pg
import time
# 设置请求头
cookies = {
'e1': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'e2': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'_csrfToken': 'bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7',
'traffic_utm_referer': 'https%3A//www.google.com/',
'_yep_uuid': 'd34769eb-33ab-2ed9-fb36-24ee50ef6100',
'newstatisticUUID': '1718695848_1379700380',
'fu': '898414530',
'e2': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D',
'supportwebp': 'true',
'e1': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D',
'w_tsfp': 'ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,ja;q=0.8,zh-TW;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'e1=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; _csrfToken=bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7; traffic_utm_referer=https%3A//www.google.com/; _yep_uuid=d34769eb-33ab-2ed9-fb36-24ee50ef6100; newstatisticUUID=1718695848_1379700380; fu=898414530; e2=%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; supportwebp=true; e1=%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D; w_tsfp=ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
while True:
users_input = pg.prompt(title="请输入你要爬取的起点小说网址:", text="网址", default="https://www.qidian.com/book/1036526469/")
if users_input.startswith('https://www.qidian.com/book/'):
print("网址正确")
break
else:
print("网址错误")
# 发送请求
response = requests.get(users_input, cookies=cookies, headers=headers)
# 解析网页
bs = BeautifulSoup(response.text, 'html.parser')
# 获取章节信息
ba_a=bs.find_all('a',class_='chapter-name')
# 创建文件夹
ba_a2 = bs.find_all('h1' ,id="bookName")
main=f'{ba_a2[0].text}'
if not os.path.exists(main):
os.makedirs(main)
# 下载章节
k=0
for i in ba_a:
k+=1
print(f"正在下载{i.text}")
url2 =f"https:{i['href']}"
rul = requests.get(url2, cookies=cookies, headers=headers)
bs2 = BeautifulSoup(rul.text, 'html.parser')
bs2_a = bs2.find_all('p')
with open(f'{main}/{i.text}.html','w',encoding='utf-8') as f:
# 写入html基础格式
f.write(f'<!DOCTYPE html>\n<html lang="en">\n<head>\n <meta charset="UTF-8">\n <title>{i.text}</title>\n</head>\n<body>\n')
# 写入章节题目居中
f.write(f'<h1 style="text-align: center">{i.text}</h1>\n')
for j in bs2_a:
f.write(f"<h4>{j.text}</h4>")
f.write('\n')
# 写入上一章
f.write(f'<a href="{ba_a[k-2].text}.html">上一章</a>\n')
#
# 写入下一章
f.write(f'<a href="{ba_a[k].text}.html">下一章</a>\n</body>\n</html>')
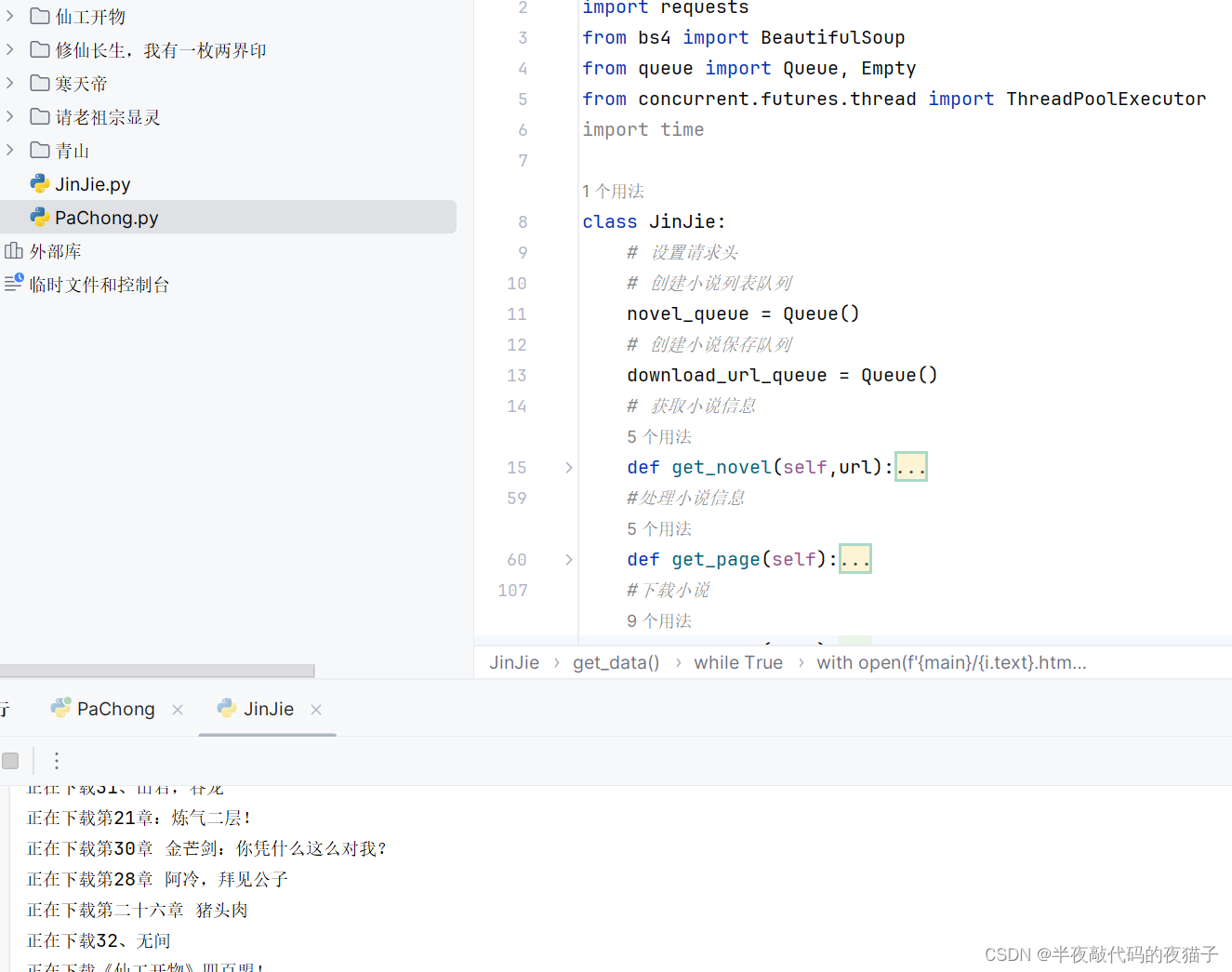
四、进阶实现
下面我们将基于以上的基础程序编写进阶的多线程多进程程序。实现这个网络爬虫程序的整个过程包括了以下几个步骤:
1,类定义:class JinJie:这行代码定义了一个叫做"JinJie"的新类(即一个新的类型)
import os
import requests
from bs4 import BeautifulSoup
from queue import Queue, Empty
from concurrent.futures.thread import ThreadPoolExecutor
import time
class JinJie:
2,def get_novel(self,url):方法中,我们设置请求头,发送一个GET请求获取小说的页数据,然后使用BeautifulSoup解析页面中的小说信息,并把获取到的信息和目录名加入到队列中。
def get_novel(self,url):
cookies = {
'e1': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'e2': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'_csrfToken': 'bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7',
'traffic_utm_referer': 'https%3A//www.google.com/',
'_yep_uuid': 'd34769eb-33ab-2ed9-fb36-24ee50ef6100',
'newstatisticUUID': '1718695848_1379700380',
'fu': '898414530',
'e2': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D',
'supportwebp': 'true',
'e1': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D',
'w_tsfp': 'ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,ja;q=0.8,zh-TW;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'e1=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; _csrfToken=bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7; traffic_utm_referer=https%3A//www.google.com/; _yep_uuid=d34769eb-33ab-2ed9-fb36-24ee50ef6100; newstatisticUUID=1718695848_1379700380; fu=898414530; e2=%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; supportwebp=true; e1=%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D; w_tsfp=ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
# 发送请求
response = requests.get(url, cookies=cookies, headers=headers)
# 解析网页
bs = BeautifulSoup(response.text, 'html.parser')
# 获取章节信息
ba_a = bs.find_all('a', class_='chapter-name')
# 创建文件夹
ba_a2 = bs.find_all('h1', id="bookName")
main = f'{ba_a2[0].text}'
if not os.path.exists(main):
os.makedirs(main)
# self.get_page(cookies, headers,ba_a, main)
var = (ba_a, main)
self.novel_queue.put(var)
3,def get_page(self):方法中,我们从队列中取出小说的信息,然后从每一章的链接发送GET请求,得到每一章的内容,并将这些信息再次放入队列中。
def get_page(self):
cookies = {
'e1': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'e2': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'_csrfToken': 'bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7',
'traffic_utm_referer': 'https%3A//www.google.com/',
'_yep_uuid': 'd34769eb-33ab-2ed9-fb36-24ee50ef6100',
'newstatisticUUID': '1718695848_1379700380',
'fu': '898414530',
'e2': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D',
'supportwebp': 'true',
'e1': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D',
'w_tsfp': 'ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,ja;q=0.8,zh-TW;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'e1=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; _csrfToken=bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7; traffic_utm_referer=https%3A//www.google.com/; _yep_uuid=d34769eb-33ab-2ed9-fb36-24ee50ef6100; newstatisticUUID=1718695848_1379700380; fu=898414530; e2=%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; supportwebp=true; e1=%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D; w_tsfp=ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
# 获取章节信息
while True :
try:
ba_a, main = self.novel_queue.get(timeout=2)
except Empty:
break
# 下载章节
k = 0
for i in ba_a:
k += 1
print(f"正在下载{i.text}")
url2 = f"https:{i['href']}"
rul = requests.get(url2, cookies=cookies, headers=headers)
bs2 = BeautifulSoup(rul.text, 'html.parser')
bs2_a = bs2.find_all('p')
vars= (main,i,bs2_a,ba_a,k)
self.download_url_queue.put(vars)
4,def get_data(self):方法中,我们获取每一章的信息并下载每一章的内容,最后将内容写入html文件。
def get_data(self):
# 获取小说信息
while True:
try:
main,i,bs2_a,ba_a,k = self.download_url_queue.get(timeout=100)
except Empty:
break
# 下载章节
with open(f'{main}/{i.text}.html', 'w', encoding='utf-8') as f:
# 写入html基础格式
f.write(
f'<!DOCTYPE html>\n<html lang="en">\n<head>\n <meta charset="UTF-8">\n <title>{i.text}</title>\n</head>\n<body>\n')
# 写入章节题目居中
f.write(f'<h1 style="text-align: center">{i.text}</h1>\n')
for j in bs2_a:
f.write(f"<h4>{j.text}</h4>")
f.write('\n')
# 写入上一章
f.write(f'<a href="{ba_a[k - 2].text}.html">上一章</a>\n')
# # 写入目录
# f.write(f'<a href="\首页.html">目录</a>\n')
# 写入下一章
f.write(f'<a href="{ba_a[k].text}.html">下一章</a>\n</body>\n</html>')
5,创建一个线程池with ThreadPoolExecutor(max_workers=16)as tp:,max_workers参数规定了线程池中最大可以存在的线程数目,此处设为16。
with ThreadPoolExecutor(max_workers=16)as tp:
6,tp.submit()方法提交任务到线程池。此处分别提交了get_novel,get_page,get_data三种任务,每种任务都提交了多次,是并发执行的,从而实现了多线程爬取小说的目的。
Jin = JinJie()
# 开启一个线程获取小说信息
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1005033997/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1039889503/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1037013658/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1033014772/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1037964722/')
# 开启一个线程处理小说
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
# 开启多个线程下载小说
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
7,if name == ‘main’:这是Python程序的入口点。当你运行这个程序时,这个条件块中的代码将被执行,创建了一个JinJie实例,然后调用了其方法提交任务。
总的来说,这个代码首先通过多线程发送网络请求来爬取小说信息,然后处理这些信息,再通过多线程批量下载小说的内容,并将内容保存到本地文件中。
if __name__ == '__main__':
完整代码
import os
import requests
from bs4 import BeautifulSoup
from queue import Queue, Empty
from concurrent.futures.thread import ThreadPoolExecutor
import time
class JinJie:
# 设置请求头
# 创建小说列表队列
novel_queue = Queue()
# 创建小说保存队列
download_url_queue = Queue()
# 获取小说信息
def get_novel(self,url):
cookies = {
'e1': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'e2': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'_csrfToken': 'bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7',
'traffic_utm_referer': 'https%3A//www.google.com/',
'_yep_uuid': 'd34769eb-33ab-2ed9-fb36-24ee50ef6100',
'newstatisticUUID': '1718695848_1379700380',
'fu': '898414530',
'e2': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D',
'supportwebp': 'true',
'e1': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D',
'w_tsfp': 'ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,ja;q=0.8,zh-TW;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'e1=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; _csrfToken=bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7; traffic_utm_referer=https%3A//www.google.com/; _yep_uuid=d34769eb-33ab-2ed9-fb36-24ee50ef6100; newstatisticUUID=1718695848_1379700380; fu=898414530; e2=%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; supportwebp=true; e1=%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D; w_tsfp=ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
# 发送请求
response = requests.get(url, cookies=cookies, headers=headers)
# 解析网页
bs = BeautifulSoup(response.text, 'html.parser')
# 获取章节信息
ba_a = bs.find_all('a', class_='chapter-name')
# 创建文件夹
ba_a2 = bs.find_all('h1', id="bookName")
main = f'{ba_a2[0].text}'
if not os.path.exists(main):
os.makedirs(main)
# self.get_page(cookies, headers,ba_a, main)
var = (ba_a, main)
self.novel_queue.put(var)
#处理小说信息
def get_page(self):
cookies = {
'e1': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'e2': '%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D',
'_csrfToken': 'bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7',
'traffic_utm_referer': 'https%3A//www.google.com/',
'_yep_uuid': 'd34769eb-33ab-2ed9-fb36-24ee50ef6100',
'newstatisticUUID': '1718695848_1379700380',
'fu': '898414530',
'e2': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D',
'supportwebp': 'true',
'e1': '%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D',
'w_tsfp': 'ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
}
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Accept-Language': 'zh-CN,zh;q=0.9,ja;q=0.8,zh-TW;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
# 'Cookie': 'e1=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%221%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; _csrfToken=bXDKHEWTQK8dlYA2q5YqswLct5n8d5YdIOKQE2Z7; traffic_utm_referer=https%3A//www.google.com/; _yep_uuid=d34769eb-33ab-2ed9-fb36-24ee50ef6100; newstatisticUUID=1718695848_1379700380; fu=898414530; e2=%7B%22l6%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; supportwebp=true; e1=%7B%22l6%22%3A%22%22%2C%22l1%22%3A11%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22qd_A117%22%2C%22l2%22%3A1%7D; w_tsfp=ltvgWVEE2utBvS0Q6KLvnU6mEj07Z2R7xFw0D+M9Os09CKUoVJyN1o9/vdfldCyCt5Mxutrd9MVxYnGJUN8jfxkcR8SYb5tH1VPHx8NlntdKRQJtA86JUFEfce91uDJAf2IKJUDhim1/ItxBnLYz31pasnZ037ZlCa8hbMFbixsAqOPFm/97DxvSliPXAHGHM3wLc+6C6rgv8LlSgW2DugDuLi11A7lL2E2b0CgcG3pV8w2pJbsDal7wcpK9Uv8wrTPzwjn3apCs2RYj4VA3sB49AtX02TXKL3ZEIAtrZUqukO18Lv3wdaN4qzsLVfocTw9DoQsd4+U5/UVOD3nraXSKUPIoslNWFaAN9p6+NA==',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36',
'sec-ch-ua': '"Google Chrome";v="123", "Not:A-Brand";v="8", "Chromium";v="123"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
# 获取章节信息
while True :
try:
ba_a, main = self.novel_queue.get(timeout=2)
except Empty:
break
# 下载章节
k = 0
for i in ba_a:
k += 1
print(f"正在下载{i.text}")
url2 = f"https:{i['href']}"
rul = requests.get(url2, cookies=cookies, headers=headers)
bs2 = BeautifulSoup(rul.text, 'html.parser')
bs2_a = bs2.find_all('p')
vars= (main,i,bs2_a,ba_a,k)
self.download_url_queue.put(vars)
#下载小说
def get_data(self):
# 获取小说信息
while True:
try:
main,i,bs2_a,ba_a,k = self.download_url_queue.get(timeout=100)
except Empty:
break
# 下载章节
with open(f'{main}/{i.text}.html', 'w', encoding='utf-8') as f:
# 写入html基础格式
f.write(
f'<!DOCTYPE html>\n<html lang="en">\n<head>\n <meta charset="UTF-8">\n <title>{i.text}</title>\n</head>\n<body>\n')
# 写入章节题目居中
f.write(f'<h1 style="text-align: center">{i.text}</h1>\n')
for j in bs2_a:
f.write(f"<h4>{j.text}</h4>")
f.write('\n')
# 写入上一章
f.write(f'<a href="{ba_a[k - 2].text}.html">上一章</a>\n')
# # 写入目录
# f.write(f'<a href="\首页.html">目录</a>\n')
# 写入下一章
f.write(f'<a href="{ba_a[k].text}.html">下一章</a>\n</body>\n</html>')
if __name__ == '__main__':
with ThreadPoolExecutor(max_workers=16)as tp:
Jin = JinJie()
# 开启一个线程获取小说信息
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1005033997/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1039889503/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1037013658/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1033014772/')
tp.submit(Jin.get_novel, url='https://www.qidian.com/book/1037964722/')
# 开启一个线程处理小说
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
tp.submit(Jin.get_page)
# 开启多个线程下载小说
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
tp.submit(Jin.get_data)
五、结果展示
经过测试,该爬虫程序能够成功地从起点中文网上抓取到指定小说的所有章节,并且将每个章节内容保存成对应的HTML文件,存储在本地硬盘中。每个章节HTML文件的命名都是按照章节名来命名的,非常方便读者阅读和查找。
因为在设计网络爬虫时模拟的请求已经应对了VIP的限制所以可以查看VIP文章,快去试试吧。