前言
在本篇博客中,作者将会带领你使用C++语言来实现一个哈希表。
一.什么是哈希表
在实现哈希表之前,我们先来学习一下什么是哈希表。
在传统的数据结构中,例如数组,链表和二叉平衡树等数据结构,这些数据结构的元素关键码与其存储位置之间没有对应的关系,因此在这些数据结构中进行查找的时候,必须要经过关键码的多次比较来实现,使得顺序的数据结构的查找时间复杂度为O(n),平衡树的查找时间复杂度为O(logn),它们的搜索效率都取决于比较的次数。
那么我们能不能设计出一种数据结构,不需要通过关键码的比较就可以直接定位到我们需要搜索的元素呢?
就这样哈希表诞生了。
哈希表通过一种哈希函数使得元素的存储位置(value)和关键码(key)之间建立一一映射的关系,使其查找的时间复杂度为O(1)。
举例
如果你还是不是很明白,那么请看下面这个例子。
假设现在我需要存储一堆int类型的数据,通过哈希表的方式来存储,我们可以先设计出一个hash函数: hash(key) = key % m。(%为取模)
其中,key为我们需要存储的int数据,m为哈希表的长度,这个哈希表的本质是一个数组,所以说也就是数组的长度,通过key是m算出来的值为key这个数据的存储位置。
如下图所示:

如上就是哈希表的存储方式。
二.哈希表的分类
哈希表又分为闭散列哈希和开散列哈希,如上面的图就是一个闭散列的哈希,那么闭散列哈希和开散列哈希又有什么区别呢。
闭散列哈希本质就是一个数组,将我们需要存储的值,直接存入数组中,但是这样会有一个问题,如上面的图所示,17已经被我们存入到了7下标的位置,如果现在我们需要存27呢?
27经过hash函数计算后,得到的结果还是存在7下标的位置,而这个时候7下标的位置已经又17呢,这样就会引发哈希冲突的问题。
如下图所示:

哈希冲突
对于哈希冲突的解决方法,我们可以通过优化哈希函数来解决,但是这种方法只能减少函数冲突,而不能完全避免哈希冲突,所以在这里,对于哈希函数的优化就不过多讲解。
那么我们还可以怎么解决哈希冲突呢,于是就有了闭散列哈希和开散列哈希两种哈希表。
闭散列哈希
所谓的闭散列哈希表,就是我们上图中的哈希表一样,哈希表就是一个简单的数组,当发生哈希冲突的时候,我们从当前位置开始进行向后探测,直到找到空位,就将该数进行插入。
如下图所示:
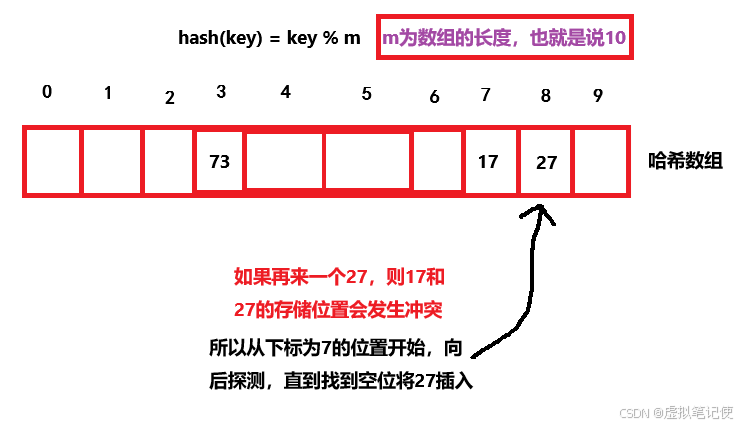
当插入其他数据时,如果发生哈希冲突,解决方法也一样,当向后探测到末尾时,将从0下标位置开始探测,即形成一个环形探测。同时,如果哈希表已满,将会对哈希表进行扩容,但是扩容后还需要又重新映射的操作,在这里先不解释,在后面的开散列哈希中进行讲解。
开散列哈希
从闭散列哈希中,可以看出,闭散列哈希的缺陷是很大的,在极限情况下,闭散列哈希的查找,可能就变成了数组的查找,使其时间复杂度变为O(n),所以为了避免这种情况,就引出了开散列哈希。
在开散列哈希中, 我们不再简单的使用一个数组来存储数据,而是通过链表的方式来存储数据,当不同的数据通过哈希函数算出来的位置相同时,我们将这一类数据归类为一个集合,每一个子集也称为一个桶,各个桶中的元素通过链表的方式链接起来,每个链表的头节点保存到哈希数组中。
如下图所示。
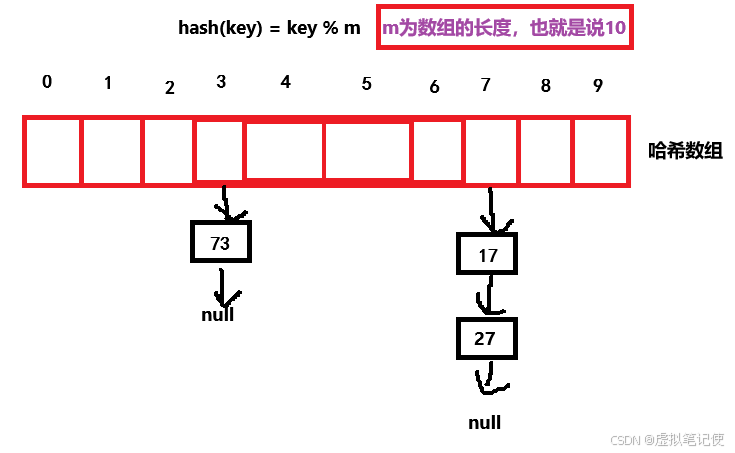
通过上面的这种方式,我们就可以很好的解决哈希冲突问题。
三.哈希表的实现
在本篇博客中,只实现开散列,因为开散列更实用。
哈希结点类的定义
首先我们来定义一下一个hash结点的结构体,看看一个结点中需要有那些变量。
//定义哈希结点
template<class T>
struct hash_node
{
T _val;//存储的数据
hash_node* _next;//指向下一个结点
//构造函数
hash_node(const T* val)
:_val(val), _next(nullptr)
{}
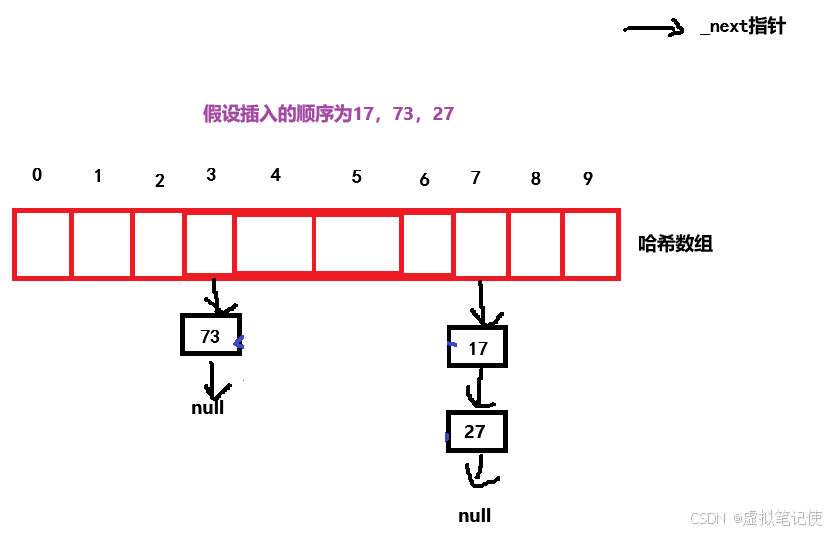
};哈希结点的定义非常简单,就是一个存储数据的val和指向下一个结点的指针
所以整个哈希表的结构如下图所示:
哈希表类定义
定义完了哈希结点,接下来就可以来定义我们的哈希表类了。
//哈希表,其中Val为我们存储数据的类型,Hash我为哈希函数
template<class Val, class Hash = Hash<Val>>
class hash
{
typedef hash_node<Val> Node;
private:
std::vector<Node*> _vec;//哈希数组
size_t _nums;//有效数据个数
};在哈希表类中,有两个成员变量,一个是哈希数组,数组中的元素都是一个哈希结点的指针,_nums代表哈希表中已经有多少个数据。
接下来看一下模板参数,第一个模板参数为插入数据的类型,第二个模板参数为一个哈希函数,因为我需要使用这个哈希函数来将数据类型转换为整数,方便我们计算出映射位置。
例如:如果我需要存储的val是一个string类型的数据,那么字符串不能直接计算出映射位置,需要将这个string类型转换为整数才能计算出映射位置。
int类型的哈希函数
同时由于我们的哈希函数是一个缺省参数,即我们需要在我们的实现中,有一个自己的哈希函数,这里我们先来实现一个适用于普通类型的哈希函数。
这里的哈希函数其实是一个仿函数,如果你不知道仿函数,可以先去了解一下什么是仿函数。
//符合int要求的哈希函数(仿函数)
template<class K>
struct Hash
{
size_t operator()(const K& tmp)
{
return (size_t)tmp;
}
};对于处理int类型的哈希函数来说,非常简单,我们直接将int值返回就好了。
例如,如果我需要存储14,通过哈希函数后,返回的就是14,后续插入的时候,在通过这个14计算映射下标即可。
构造函数和析构函数
对于构造函数来说,我们只需要给成员变量进行一个初始化即可。
这里的_vec成员变量,我们默认这个数组初始化为10的大小,同时内容都为nullptr。
//构造函数
hash()
:_nums(0)
, _vec(10, nullptr)//哈希数组默认大小为10
{}
//析构函数
~hash()
{}insert插入函数
下面是插入函数的实现。
我们在插入数据之前,需要先判断该数据存不存在哈希表中,如果已经存在就不再插入了,
同时要判断,如果此时有效数据的个数==数组的长度,我们需要给哈希数组进行一个扩容,避免哈希冲突过多时,导致同一个桶中链接的结点越来越多,链接越来越长,从而影响查找的效率。
//增
bool insert(const Val& data)
{
Hash hash_func;//定义哈希函数类对象
//先判断,做一个去重
Node* cur = find(data);//这里find还没实现,后面会实现
if (cur != nullptr)
return false;
if (_vec.size() == _nums)//插入之前判断是否需要扩容
{
reserve();//这里reserve也没有实现,后面会实现
}
Node* new_node = new Node(data);//开辟一个新的哈希结点
new_node->_val = data;
//找到需要插入的位置,并将结点链接到哈希表中
size_t index = hash_func(data) % _vec.size();
new_node->_next = _vec[index];
_vec[index] = new_node;
_nums++;//有效数据个数加1
return true;
}reserve扩容函数
对于扩容操作,我们默认将哈希数组扩容一个二倍。
注意!!!
扩容不单单只是将哈希数组扩大二倍,还需要将原来的结点重新计算映射位置,插入到新的哈希数组中。
如下图所示。
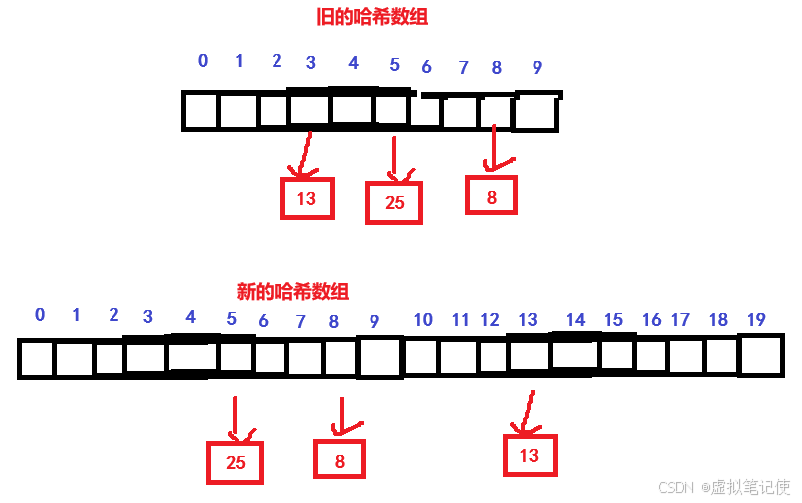
从图中我们可以看到,在旧的哈希数组中,结点13是在3下标里面的,当扩容了新的哈希数组后,结点13是在13下标里面的,也就是说,扩容后,原来结点的映射位置会发生变化,所以我们需要将所有的结点都重新计算一遍映射位置,重新插入。
//扩容
void reserve()
{
Hash hash_func;
size_t new_capacity = 2 * _vec.size();//扩容扩2倍
//先开辟一块更大的数组
std::vector<Node*> new_vec(new_capacity, nullptr);
//遍历原来的哈希数组,将结点链接到新的数组中
for (auto& tmp : _vec)
{
while (tmp != nullptr)
{
//保存tmp的下一个结点
Node* tmp_next = tmp->_next;
//计算新的映射位置,并插入结点
size_t index = hash_func(tmp->_val) % new_vec.size();
tmp->_next = new_vec[index];
new_vec[index] = tmp;
tmp = tmp_next;
}
}
//与原来的旧数组进行交换
_vec.swap(new_vec);
}erase删除函数
对于删除函数来说,我们需要先找到删除数据的映射位置,然后在这个桶里面去找到我们需要删除的结点。
//删
bool erase(const Val& data)
{
Hash hash_func;
//先找到映射位置
size_t index = hash_func(data) % _vec.size();
Node* cur = _vec[index];
Node* prev = nullptr;
while (cur != nullptr)
{
if (cur->_val == data)
{
if (prev == nullptr)//说明要删除的结点就是桶中的第一个结点
_vec[index] = cur->_next;
else
prev->_next = cur->_next;
delete cur;
_nums--;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}find查找函数
对于查找函数来说,就比较简单了,先计算出映射位置,然后再该位置的桶中去查找即可。
//查,返回查找结点的指针
Node* find(const Val& data)
{
Hash hash_func;
//先查找映射位置
size_t index = hash_func(data) % _vec.size();
Node* cur = _vec[index];
while (cur != nullptr)
{
if (cur->_val == data)
return cur;
else
cur = cur->_next;
}
return nullptr;
}string类型的哈希函数
在上面的实现中,我们的哈希表基本上只能用来存储int类型的数据,如果我们想要存储string类型的数据的时候怎么办,因为哈希表的存储是需要整数值计算下标的,而string字符串类型无法直接得出一个整数值,所以我们需要自己实现一个关于string类型的哈希函数,即通过string类型,得出一个整数值。
注意!!!
这里需要用到模板的特化,不了解模板的特化的可以先看下面这篇博客。
//符合string要求的哈希函数
template<>
struct Hash<std::string>
{
size_t operator()(const std::string& str)
{
size_t count = 0;
for (auto ch : str)
{
count = count * 131 + (size_t)ch;
}
return count;
}
};在这个哈希函数中,我们可以先遍历每一个字符,将每一个字符转换为整型,然后再加一个值,最后我们就可以得到一个count整型,就能通过count这个整型计算对应的映射位置。
对应字符串类型的哈希函数,为什么这样设计,为什么要乘131,我是参考别人来完成的,具体内容可以下面这篇博客。
四.所有源代码
blog_hash.h
#pragma once
#include <vector>
#include <string>
#include <iostream>
namespace blog_hash
{
//定义哈希结点
template<class T>
struct hash_node
{
T _val;//存储的数据
hash_node* _next;//指向下一个结点
//构造函数
hash_node(const T& val)
:_val(val), _next(nullptr)
{}
};
//符合int要求的哈希函数(仿函数)
template<class K>
struct Hash
{
size_t operator()(const K& tmp)
{
return (size_t)tmp;
}
};
//符合string要求的哈希函数
template<>
struct Hash<std::string>
{
size_t operator()(const std::string& str)
{
size_t count = 0;
for (auto ch : str)
{
count = count * 131 + (size_t)ch;
}
return count;
}
};
//哈希表
template<class Val, class Hash = Hash<Val>>
class hash
{
typedef hash_node<Val> Node;
private:
std::vector<Node*> _vec;//哈希数组
size_t _nums;//有效数据个数
public:
//构造函数
hash()
:_nums(0)
, _vec(10, nullptr)//哈希数组默认大小为10
{}
//析构函数
~hash()
{}
//增
bool insert(const Val& data)
{
Hash hash_func;
//先判断,做一个去重
Node* cur = find(data);
if (cur != nullptr)
return false;
if (_vec.size() == _nums) //插入之前判断是否需要扩容
{
reserve();
}
Node* new_node = new Node(data);//开辟一个新的哈希结点
new_node->_val = data;
//找到需要插入的位置,并将结点链接到哈希表中
size_t index = hash_func(data) % _vec.size();
new_node->_next = _vec[index];
_vec[index] = new_node;
_nums++;//有效数据个数加1
return true;
}
//删
bool erase(const Val& data)
{
Hash hash_func;
//先找到映射位置
size_t index = hash_func(data) % _vec.size();
Node* cur = _vec[index];
Node* prev = nullptr;
while (cur != nullptr)
{
if (cur->_val == data)
{
if (prev == nullptr)//说明要删除的结点就是桶中的第一个结点
{
_vec[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
_nums--;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
//改
//查,返回查找结点的指针
Node* find(const Val& data)
{
Hash hash_func;
//先查找映射位置
size_t index = hash_func(data) % _vec.size();
Node* cur = _vec[index];
while (cur != nullptr)
{
if (cur->_val == data)
return cur;
else
cur = cur->_next;
}
return nullptr;
}
//打印函数,方便我们做调试
void Print()
{
for (auto tmp : _vec)
{
while (tmp != nullptr)
{
std::cout << tmp->_val << " ";
tmp = tmp->_next;
}
}
std::cout << std::endl;
}
//私有成员函数
private:
//扩容
void reserve()
{
Hash hash_func;
size_t new_capacity = 2 * _vec.size();//扩容扩2倍
//先开辟一块更大的数组
std::vector<Node*> new_vec(new_capacity, nullptr);
//遍历原来的哈希数组,将结点链接到新的数组中
for (auto& tmp : _vec)
{
while (tmp != nullptr)
{
//保存tmp的下一个结点
Node* tmp_next = tmp->_next;
//计算新的映射位置,并插入结点
size_t index = hash_func(tmp->_val) % new_vec.size();
tmp->_next = new_vec[index];
new_vec[index] = tmp;
tmp = tmp_next;
}
}
//与原来的旧数组进行交换
_vec.swap(new_vec);
}
};
}
test.cpp
#include"blog_hash.h"
using namespace blog_hash;
using Node = blog_hash::hash_node<int>;
void Test1()
{
blog_hash::hash<int> h;
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(13);
h.insert(23);
h.insert(33);
h.insert(5);
h.insert(6);
h.Print();
}
void Test2()
{
blog_hash::hash<int> h;
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(13);
h.insert(23);
h.insert(33);
h.insert(5);
h.insert(6);
//测试查找
Node* ret = h.find(23);
std::cout << ret->_val << std::endl;
}
void Test3()
{
blog_hash::hash<int> h;
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(3);
h.insert(13);
h.insert(23);
h.insert(33);
h.insert(5);
h.insert(6);
//测试删除
h.erase(7);
h.erase(8);
h.Print();
}
void Test4()
{
blog_hash::hash<std::string> h;
h.insert("abc");
h.insert("abc");
h.insert("bca");
h.insert("cba");
h.insert("asdgfas");
h.insert("wqer");
h.insert("zxv");
h.Print();
}
int main()
{
Test1();
Test2();
Test3();
Test4();
return 0;
}