1. 引言
布隆过滤器是由布隆于1970年提出的一种数据结构,用来判断一个元素是否可能在一个集合中存在。它的基本原理是使用一系列哈希函数和一个位数组来表示集合中的元素,通过将元素经过多个哈希函数得到的位下标设为1来表示元素的存在,从而判断一个元素是否存在于集合中。布隆过滤器可以在空间和时间上获得很好的性能,因此在实际应用中被广泛使用。
在实际应用中,需要判断一个元素是否在一个大规模的集合中存在是一个常见的问题,如在搜索引擎中判断一个URL是否已经被索引,或者在网络爬虫中判断一个网页是否已经被抓取过。传统的方法是使用散列表或者二叉树等数据结构,但是这些数据结构在空间和时间上的开销都比较大。布隆过滤器就是为了解决这个问题。
2. 布隆过滤器原理
2.1 基本原理
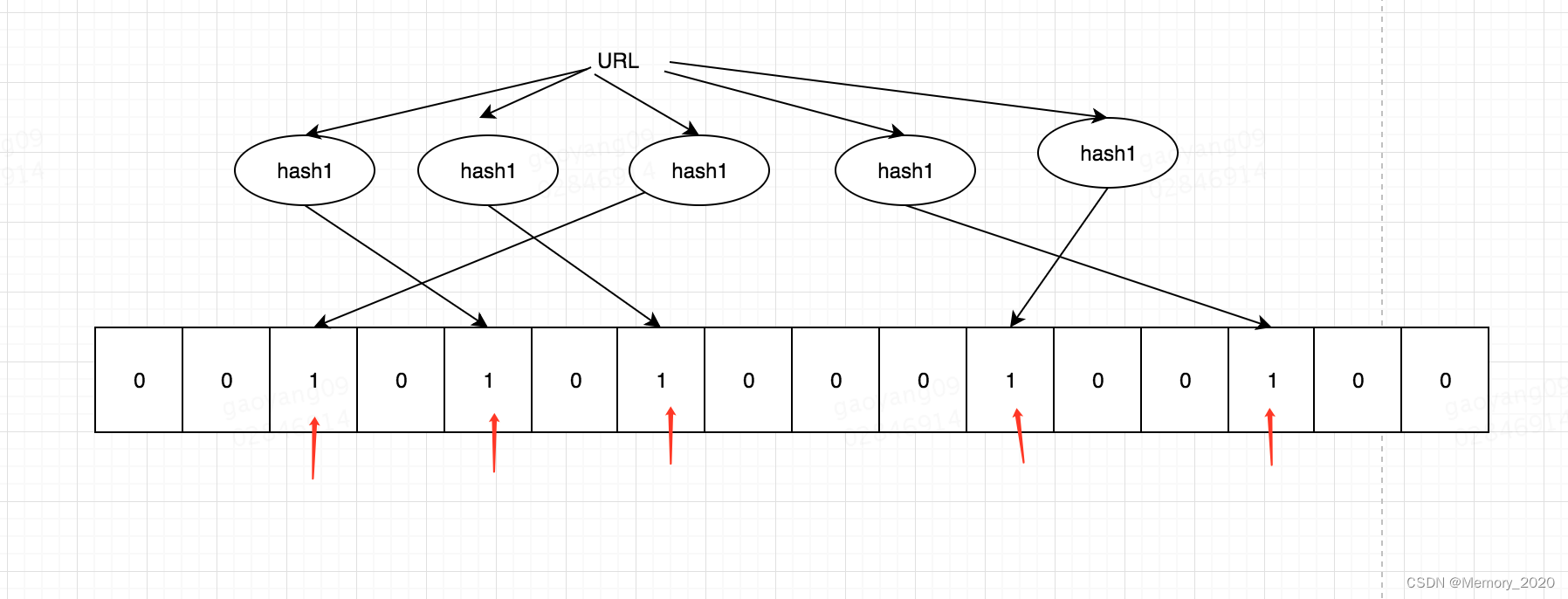
布隆过滤器基于一系列哈希函数和一个位数组实现。基本原理如下:
- 初始化时,创建一个长度为 m 的位数组,并初始化所有位为 0。
- 针对每个要插入的元素,通过 k 个不同的哈希函数将元素映射到位数组上的 k 个位置,并将这些位置的位设置为 1。
- 对于查询操作,将要查询的元素通过相同的 k 个哈希函数映射到位数组上的 k 个位置,如果所有位置的位都为 1,则认为该元素可能存在于集合中。
2.2 插入和查询操作
-
插入操作:将要插入的元素通过 k 个不同的哈希函数映射到位数组上的 k 个位置,并将这些位置的位设置为 1。这样做的目的是为了标记该元素在布隆过滤器中的存在。
-
查询操作:将要查询的元素通过相同的 k 个哈希函数映射到位数组上的 k 个位置,然后检查这些位置的位是否都为 1。如果所有位置的位都为 1,则说明该元素可能存在于布隆过滤器中;如果任何一个位置的位为 0,则可以确定该元素一定不存在于布隆过滤器中。
布隆过滤器的查询操作具有高效的特点,因为查询时只需计算哈希函数并检查位数组的对应位置,而不需要实际存储元素的值,这大大提高了查询速度。
插入流程

查询流程
3. 应用场景及代码示例
Java 项目中使用布隆过滤器,可以使用 Google Guava 提供的 BloomFilter 工具类。在 Maven项目中添加 Guava 依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1.1-jre</version>
</dependency>
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterExample {
public static void main(String[] args) {
int expectedInsertions = 1000000;
double falsePositiveProbability = 0.01;
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), expectedInsertions, falsePositiveProbability);
// 在布隆过滤器中插入数据
bloomFilter.put("test1");
bloomFilter.put("test2");
// 判断数据是否在布隆过滤器中
System.out.println(bloomFilter.mightContain("test1")); // true
System.out.println(bloomFilter.mightContain("test3")); // false
}
}
3.1 缓存去重
布隆过滤器在缓存系统中常用于去重操作,以避免缓存穿透和缓存击穿问题。通过布隆过滤器可以快速判断一个请求是否已经在缓存中存在,如果存在则直接返回缓存数据,如果不存在则继续向后端系统请求数据并缓存,从而避免了重复请求对系统造成的压力。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class CacheDeduplication {
private static final int EXPECTED_INSERTIONS = 1000000;
private static final double FPP = 0.01;
private static BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), EXPECTED_INSERTIONS, FPP);
public static void main(String[] args) {
// 假设从数据库中查询得到的数据
String data = "Some data to be cached";
// 判断数据是否已经在缓存中
if (!bloomFilter.mightContain(data)) {
// 数据不在缓存中,进行后续操作并将数据加入缓存
// addToCache(data);
bloomFilter.put(data);
} else {
// 数据已经在缓存中,直接返回缓存数据
// return getFromCache(data);
}
}
}
3.2 网络爬虫 URL 过滤
在网络爬虫系统中,布隆过滤器常用于对已经抓取过的URL进行去重操作,避免重复抓取同一个URL。通过布隆过滤器可以快速判断一个URL是否已经被抓取过,如果已经抓取过则跳过,否则进行抓取并加入布隆过滤器中。
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class WebCrawler {
private static final int EXPECTED_INSERTIONS = 1000000;
private static final double FPP = 0.01;
private static BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), EXPECTED_INSERTIONS, FPP);
public static void main(String[] args) {
// 假设从网页中解析得到的URL
String url = "https://memoryab.cn/#/article/1";
// 判断URL是否已经被抓取过
if (!bloomFilter.mightContain(url)) {
// 抓取URL并处理页面内容
// fetchAndProcessPage(url);
bloomFilter.put(url);
} else {
// URL已经被抓取过,跳过
}
}
}
3.3 数据同步中的应用
在分布式系统中,布隆过滤器常用于数据同步中,以避免重复同步相同的数据。通过布隆过滤器可以快速判断一个数据是否已经在其他节点同步过,如果已经同步过则跳过,否则进行数据同步并将数据加入布隆过滤器中。
// Java示例代码
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class DataSync {
private static final int EXPECTED_INSERTIONS = 1000000;
private static final double FPP = 0.01;
private static BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(), EXPECTED_INSERTIONS, FPP);
public static void main(String[] args) {
// 假设从其他节点同步得到的数据
String data = "Some data to be synchronized";
// 判断数据是否已经在本地节点同步过
if (!bloomFilter.mightContain(data)) {
// 进行数据同步并处理数据
// syncAndProcessData(data);
bloomFilter.put(data);
} else {
// 数据已经在本地节点同步过,跳过
}
}
}
其实上面三段代码基本上都是同样的逻辑,都是通过布隆过滤器来判断元素是否存在,如果有类似的场景,都可以用布隆过滤器来实现。
4. 优缺点分析
4.1 优点总结
布隆过滤器具有以下优点:
-
空间效率高:布隆过滤器使用位数组和哈希函数实现,相比传统的数据结构,它的存储空间通常要小很多。
-
查询速度快:布隆过滤器的查询操作只需要计算哈希函数并检查位数组的对应位置,时间复杂度为 O(k),其中 k 是哈希函数的个数,与集合大小无关。
-
可扩展性好:布隆过滤器支持动态插入和删除操作,可以根据需要动态调整位数组的大小和哈希函数的个数。
-
误判率可控:通过合理设置位数组的大小和哈希函数的个数,可以在一定范围内控制布隆过滤器的误判率,使其满足实际应用需求。
4.2 缺点讨论
布隆过滤器也存在一些缺点,主要包括以下几点:
-
存在误判:由于哈希函数的映射可能存在冲突,因此布隆过滤器会存在一定的误判率,即判断一个元素不存在于集合中时,可能会误判为存在。
-
不支持删除操作:布隆过滤器不支持直接删除单个元素,因为位数组中的位可能被多个元素共享,删除一个元素可能会影响其他元素的判断结果。
-
无法存储原始数据:布隆过滤器只能判断一个元素是否可能存在于集合中,但不能存储原始数据,因此无法直接获取元素的具体信息。
-
哈希函数设计要求高:布隆过滤器的性能依赖于哈希函数的设计,需要选择合适的哈希函数以保证位数组的均匀分布,这对于非专业人员来说可能会有一定难度。
5. 注意事项
在第三章介绍了应用场景,这里在做下总结:
-
缓存去重:在缓存系统中,使用布隆过滤器可以避免重复请求对后端系统造成的压力,提高系统的性能和稳定性。
-
网络爬虫 URL 过滤:在网络爬虫系统中,使用布隆过滤器可以避免重复抓取同一个URL,提高抓取效率并减少系统资源的消耗。
-
数据同步中的应用:在分布式系统中,使用布隆过滤器可以避免重复同步相同的数据,减少网络流量和系统负载。
在使用布隆过滤器时,需要注意以下几点实践经验:
-
合理选择哈希函数:选择合适的哈希函数是使用布隆过滤器的关键,需要保证哈希函数的均匀分布和低碰撞率,以降低误判率。
-
设置合适的位数组大小:位数组的大小决定了布隆过滤器的容量和误判率,需要根据预期插入元素的数量和误判率要求来设置合适的大小。
-
定期更新布隆过滤器:随着元素的插入和查询操作,位数组中的位可能会不断被设置为1,导致误判率增加,因此需要定期更新布隆过滤器,重新初始化位数组。
在实际应用中,布隆过滤器的性能和效果受到多个因素的影响,可以通过以下方法进行配置和调优:
-
调整位数组大小:根据实际场景和需求,可以调整位数组的大小来控制误判率。位数组大小越大,误判率越低,但相应的存储空间也会增加。
-
增加哈希函数个数:增加哈希函数的个数可以降低误判率,但会增加计算哈希函数的时间开销。需要根据实际需求权衡利弊。
-
监控和调整误判率:定期监控布隆过滤器的误判率,并根据实际情况调整位数组大小和哈希函数个数,以保证误判率在可接受的范围内。
-
结合其他数据结构:布隆过滤器可以与其他数据结构结合使用,如散列表或红黑树等,以提高查询的准确性和效率。
更多文章