目录
解决哈希表冲突原理:
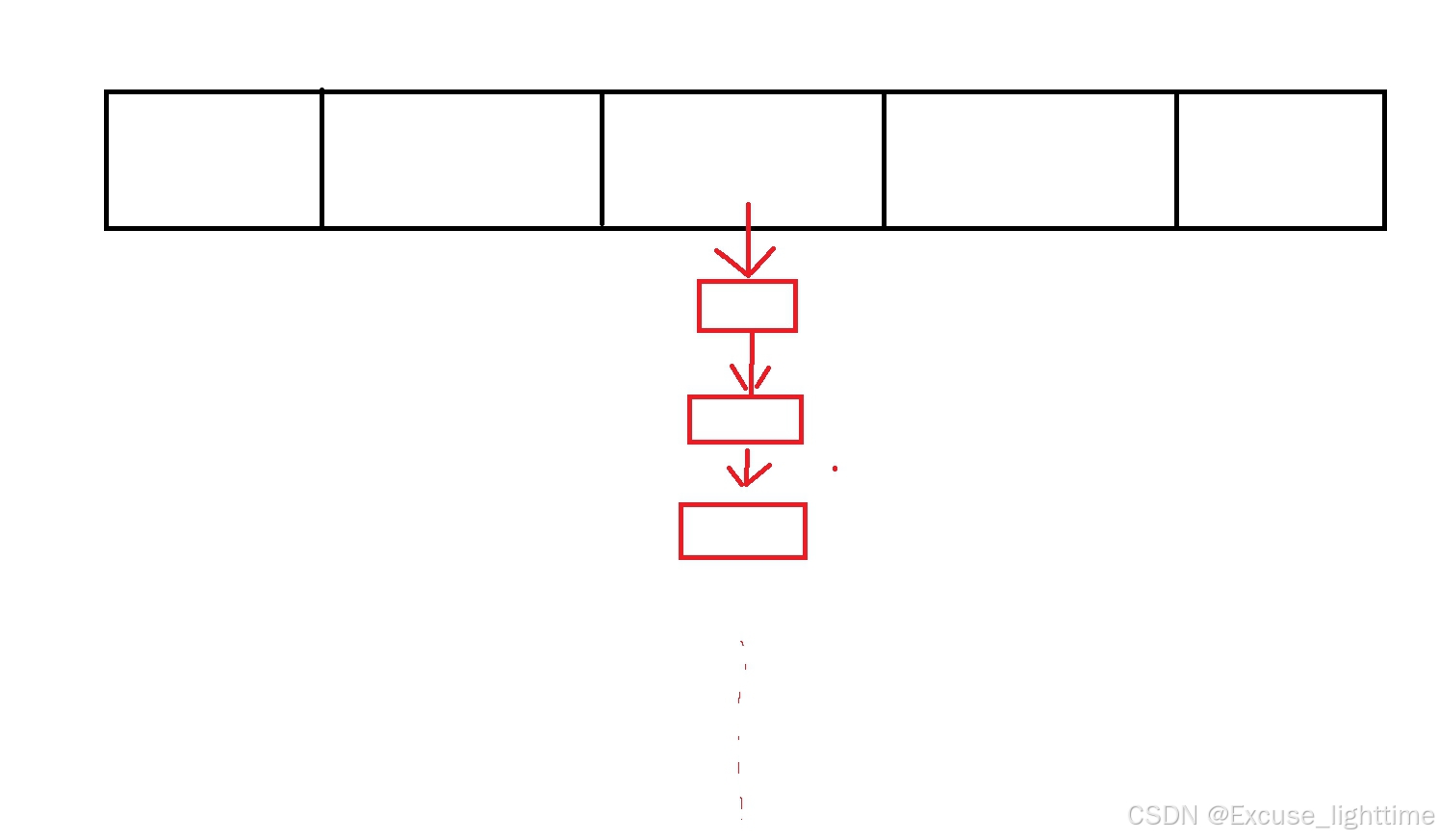
黑色代表一个数组,当 出现哈希冲突时(相同数组下标),该位置下标会变成一个链表(上图红色区域)。这样就能存储了。叫做开散列 / 哈希桶。链表长度超过阈值(默认8)时转为红黑树,优化冲突性能。
虽然哈希表⼀直在和冲突做斗争,但在实际使用过程中,我们认为哈希表的冲突率是不高的,冲突个数是可控的,也就是每个桶中的链表的长度是⼀个常数,所以,通常意义下,我们认为哈希表的插⼊/ 删除/查找时间复杂度是O(1)。
模拟解决哈希表冲突代码:
private static class Node {
private int key;
private int value;
Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private Node[] array;
private int size; // 当前的数据个数
private static final double LOAD_FACTOR = 0.75; //默认最大负载因子
private static final int DEFAULT_SIZE = 8; //默认桶的大小
//初始化哈希桶
public HashBucket() {
array = new Node[DEFAULT_SIZE];
}
//放元素
public int put(int key, int value) {
//1.遍历index数组下的链表,如果有相同的key则更新val
int index = key % array.length;
Node cur = array[index];
while(cur != null) {
if(cur.key == key) {
cur.value = value;
return 1;
}
cur = cur.next;
}
//2.头插法擦插入节点
Node node = new Node(key,value);
node.next = array[index];
array[index] = node;
//3.重新计算当前的负载因子 是不是超过了 我们规定的负载因子
if(loadFactor() >= LOAD_FACTOR) {
//扩容
resize();
}
return -1;
}
//扩容
private void resize() {
// write code here
Node[] newArray = new Node[array.length * 2];
for (int i = 0; i < array.length; i++) {
Node cur = array[i];
while(cur != null) {
int newindex = cur.key % newArray.length;
//把当前节点 放到新的数组的 newindex 位置 头插法
Node curN = cur.next;
cur.next = newArray[newindex];
newArray[newindex] = cur;
cur = curN;
}
}
array = newArray;
}
//计算负载因子
private double loadFactor() {
return size * 1.0 / array.length;
}
//取对应key的value值
public int get(int key) {
// write code here
int index = key % array.length;
Node cur = array[index];
while (cur != null) {
if(cur.key == key) {
return cur.value;
}
cur = cur.next;
}
return -1;
}负载因子:
哈希表中已存储的元素数量(n)与哈希表的容量(m)的比值,通常用公式表示为:
负载因子 = 已存储元素数量哈希表容量 / 哈希表容量。
例如,一个哈希表的容量是 100,当前已经存储了 50 个元素,那么此时该哈希表的负载因子就是 50 / 100 = 0.5
负载因子主要用于衡量哈希表的空间使用程度和性能,它直接影响哈希表的插入、查找和删除操作的效率:
空间利用率:负载因子越大,说明哈希表中存储的元素越满,空间利用率越高;反之,负载因子越小,空间利用率越低,意味着有较多的空闲存储桶。
冲突概率:冲突是指不同的键通过哈希函数计算得到了相同的存储桶索引。负载因子越大,发生冲突的概率就越高。因为随着元素数量的增加,有限的存储桶被占用的比例也在增大,新元素更容易被映射到已经有元素的桶中。
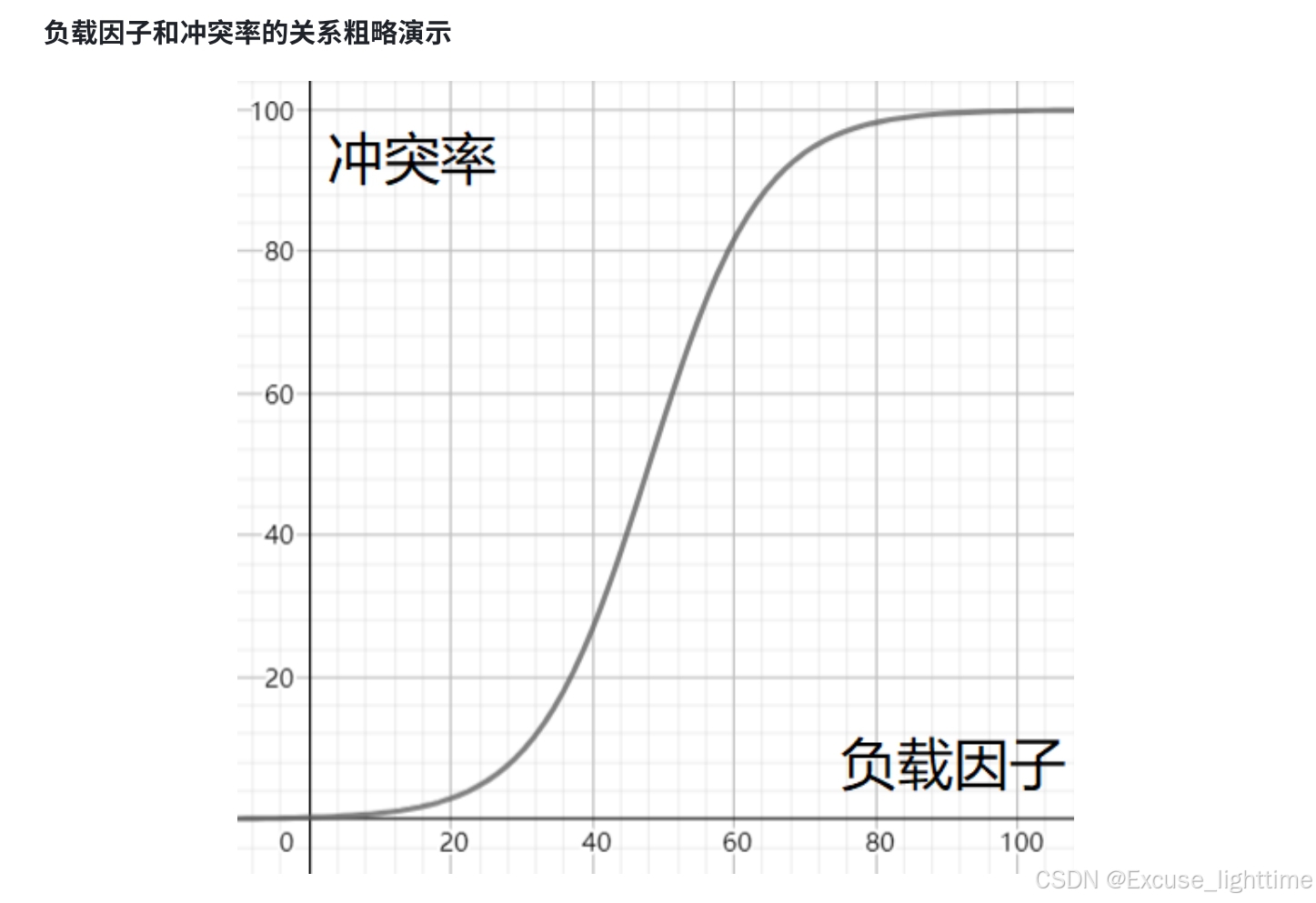
动态扩容:
为了保证哈希表在不同的元素数量下都能保持较好的性能,当负载因子超过某个阈值(通常是默认的负载因子)时,哈希表会进行动态扩容操作。具体步骤如下:
- 创建更大的哈希表:通常新的哈希表容量是原容量的 2 倍。
- 重新哈希:将原哈希表中的所有元素重新计算哈希值,并插入到新的哈希表中。
- 更新引用:将原哈希表的引用指向新的哈希表。
总结:
1.java 中使用的是哈希桶方式解决冲突的。
2.java 会在冲突链表长度大于一定阈值后,将链表转变为搜索树(红黑树)。
3. java 中计算哈希值(相当于计算出的数据应该在数组放的下标位置)实际上是调用的类的 hashCode 方法,进行 key 的相等性比较是调用 key 的 equals 方法。
所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,必须重写 hashCode 和 equals 方法,而且要做到 equals 相等的对象,hashCode ⼀定是⼀致的:
比如:
import java.util.HashMap;
import java.util.Map;
class Person {
private int id;
public Person(int id) {
this.id = id;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return id == person.id;
}
@Override
public int hashCode() {
return id;
}
}
public class HashMapDuplicateKeyExample {
public static void main(String[] args) {
Map<Person, String> map = new HashMap<>();
Person p1 = new Person(1);
Person p2 = new Person(1);
map.put(p1, "Alice");
map.put(p2, "Bob");
System.out.println(map.size()); // 输出: 1
}
}代码过程:
HashMap 先计算 p1 的哈希码,因为 p1 的 id 是 1,所以哈希码就是 1
根据这个哈希码找到对应的哈希桶,把键值对 (p1, "Alice") 存进去。
HashMap 计算 p2 的哈希码,由于 p2 的 id 也是 1,所以哈希码同样是 1,和 p1 的哈希码一样,会对应到同一个哈希桶。
接着,HashMap 会用 equals() 方法比较 p1 和 p2,因为 p1 和 p2 的 id 相等,equals() 方法返回 true,这表明 p1 和 p2 是相同的键。
此时,HashMap 不会再新增一个键值对,而是用新的值 "Bob" 覆盖掉原来键 p1(和 p2 视为相同键)对应的值 "Alice"。
由于 p1 和 p2 被 HashMap 判定为相同的键,所以 HashMap 里实际上只有一个键值对,调用 map.size() 就会输出 1。
此段代码我们知道:
hashCode 方法用于确定键对象在哈希表中的存储位置。
如果两个键的 hashCode 相同,并且 equals 方法返回 true,则认为这两个键是相同的,后插入的键值对会覆盖之前的。
HashMap和HashSet的总结:
| 特性 | HashMap | HashSet | |
| 存储结构 | 键值对(Key-Value) | 单一对象(Key) | |
| 重复元素 | 键唯一,值(value)可重复 | 元素唯一 | |
| null支持 | 1个null键,多个null值 | 1个null元素 | |
| 底层原理 | 哈希表(数组+链表 / 红黑树) | HashMap | |
| 核心方法 | put(), get(), remove() | add(), remove(), contains() | |
| 应用场景 | 键值映射、缓存 |
|