下面我将以 MNIST 手写数字识别模型为例,从 剪枝 (Pruning) 和 量化 (Quantization) 两个常用方法出发,提供一套可实际动手操作的模型优化流程。此示例基于 TensorFlow/Keras 环境,示范如何先训练一个基础模型,然后对其进行剪枝和量化,最后验证优化后的模型性能。
目录
1. 整体流程概览
在之前博客中已经可以训练一个基础 MNIST 模型(train_mnist.py)并成功获得 mnist_model.h5 的前提下,通常会按照以下顺序进行优化:
在模型训练好后,可以在mnist_project文件夹下找到mnist_model.h5,如下:
- 剪枝 (Pruning):减小模型大小、去除不重要的权重,生成
pruned_mnist_model.h5。 - (可选)量化 (Quantization):将浮点模型转化为 INT8 等低比特模型,大幅减小模型体积,并提升推理速度,生成
mnist_model_quant.tflite。
在此过程中,我们需要:
- 修改已有脚本或新增脚本来执行剪枝和量化的操作。
- 确保虚拟环境已安装必要库(
tensorflow-model-optimization、tensorflow-lite等)。 - 反复验证模型的大小、推理速度、准确率,找到最适合部署需求的平衡点。
2. 模型剪枝 (Pruning)
2.1 安装依赖库
- TensorFlow Model Optimization Toolkit:其中包含
tfmot.sparsity.keras模块,可用于剪枝、量化感知训练等。
在激活的虚拟环境(tf_env 等)下,输入:
pip install tensorflow-model-optimization
如果已经安装过,可以跳过此步骤;若版本较旧,建议 pip install --upgrade tensorflow-model-optimization。
2.2 修改训练脚本实现剪枝
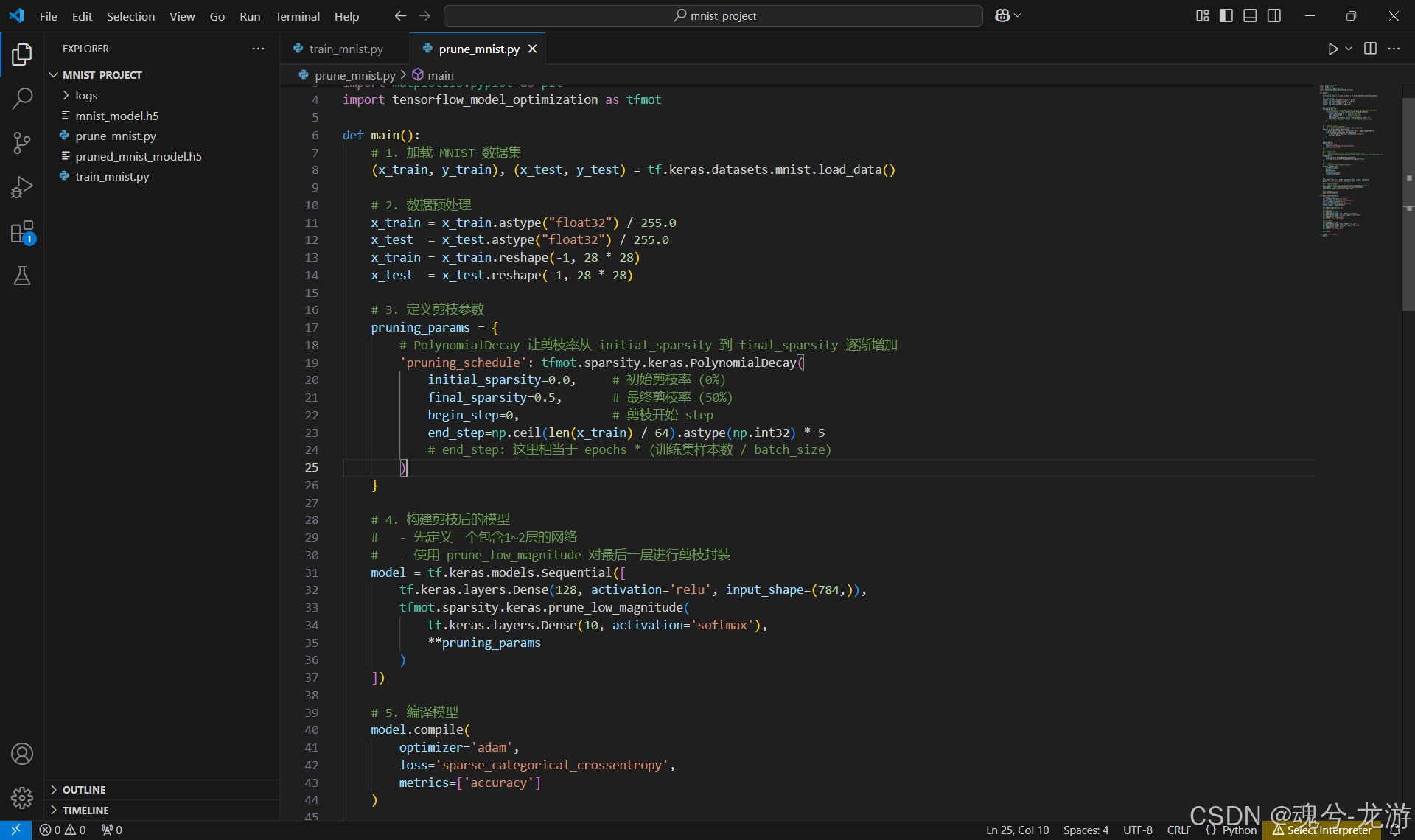
这里给出的示例代码可放在一个新的脚本(如 prune_mnist.py),或者在原 train_mnist.py 中替换。示例如下:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_model_optimization as tfmot
def main():
# 1. 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 2. 数据预处理
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
x_train = x_train.reshape(-1, 28 * 28)
x_test = x_test.reshape(-1, 28 * 28)
# 3. 定义剪枝参数
pruning_params = {
# PolynomialDecay 让剪枝率从 initial_sparsity 到 final_sparsity 逐渐增加
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(
initial_sparsity=0.0, # 初始剪枝率 (0%)
final_sparsity=0.5, # 最终剪枝率 (50%)
begin_step=0, # 剪枝开始 step
end_step=np.ceil(len(x_train) / 64).astype(np.int32) * 5
# end_step: 这里相当于 epochs * (训练集样本数 / batch_size)
)
}
# 4. 构建剪枝后的模型
# - 先定义一个包含1~2层的网络
# - 使用 prune_low_magnitude 对最后一层进行剪枝封装
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),
tfmot.sparsity.keras.prune_low_magnitude(
tf.keras.layers.Dense(10, activation='softmax'),
**pruning_params
)
])
# 5. 编译模型
model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 6. 设置剪枝回调
# - UpdatePruningStep:在每个批次/epoch后更新剪枝进度
# - PruningSummaries:可选,将剪枝信息写入到指定 log_dir,配合 TensorBoard 查看
callbacks = [
tfmot.sparsity.keras.UpdatePruningStep(),
tfmot.sparsity.keras.PruningSummaries(log_dir='logs')
]
# 7. 训练模型
# - epochs=5 可以根据需要加大或减少
history = model.fit(
x_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.1,
callbacks=callbacks
)
# 8. 模型评估
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=2)
print(f"\n测试集上的准确率: {test_acc:.4f}")
# 9. 保存剪枝后的模型
# - 先使用 strip_pruning 去除剪枝包装器,得到最终“瘦身”模型
final_model = tfmot.sparsity.keras.strip_pruning(model)
final_model.save("pruned_mnist_model.h5")
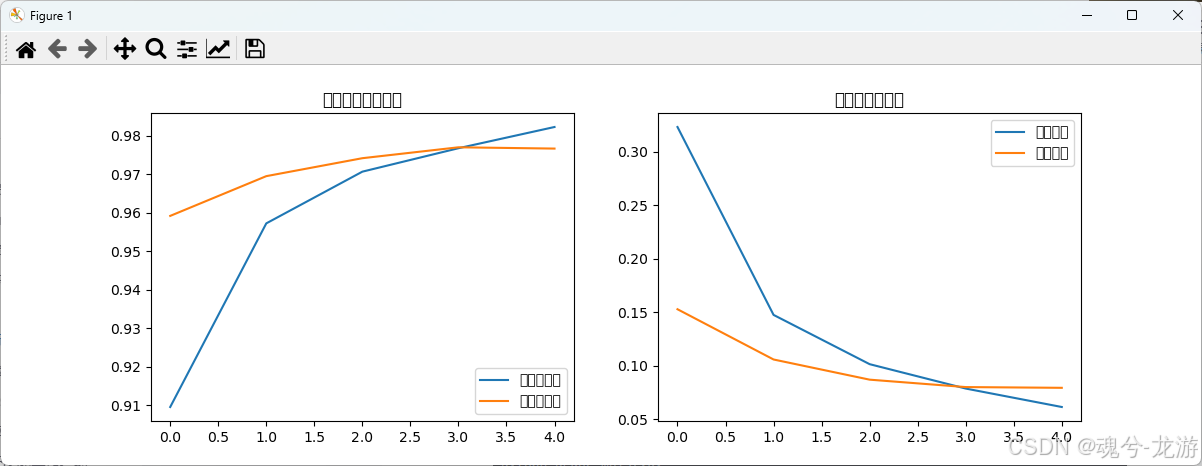
# 10. 可视化训练过程
plot_history(history)
def plot_history(history):
"""可视化训练曲线"""
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(12, 4))
# 绘制准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='训练准确率')
plt.plot(epochs_range, val_acc, label='验证准确率')
plt.legend(loc='lower right')
plt.title('训练和验证准确率')
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='训练损失')
plt.plot(epochs_range, val_loss, label='验证损失')
plt.legend(loc='upper right')
plt.title('训练和验证损失')
plt.show()
if __name__ == "__main__":
main()
代码要点:
tfmot.sparsity.keras.PolynomialDecay:定义从 0% 到 50% 的剪枝率逐渐增加的策略。prune_low_magnitude(...):对目标层进行剪枝包装。可以只对某些关键层做剪枝,也可对网络所有层做封装。strip_pruning(...):剪枝训练完后,需要去掉剪枝相关的“假”节点,才能得到真正稀疏的权重以减小体积。
2.3 如何运行剪枝脚本
- 确保已经训练过一个基础模型(可选,如果想微调原模型);或者像示例这样直接在脚本里构建一个新的网络。
- 打开 Anaconda Prompt(或终端),激活虚拟环境:
conda activate tf_env - 导航到脚本所在目录:
cd C:\Users\FCZ\Desktop\Projects\mnist_project - 运行脚本:
python prune_mnist.py
训练过程结束后,会打印出测试集准确率,并在目录下生成 pruned_mnist_model.h5。
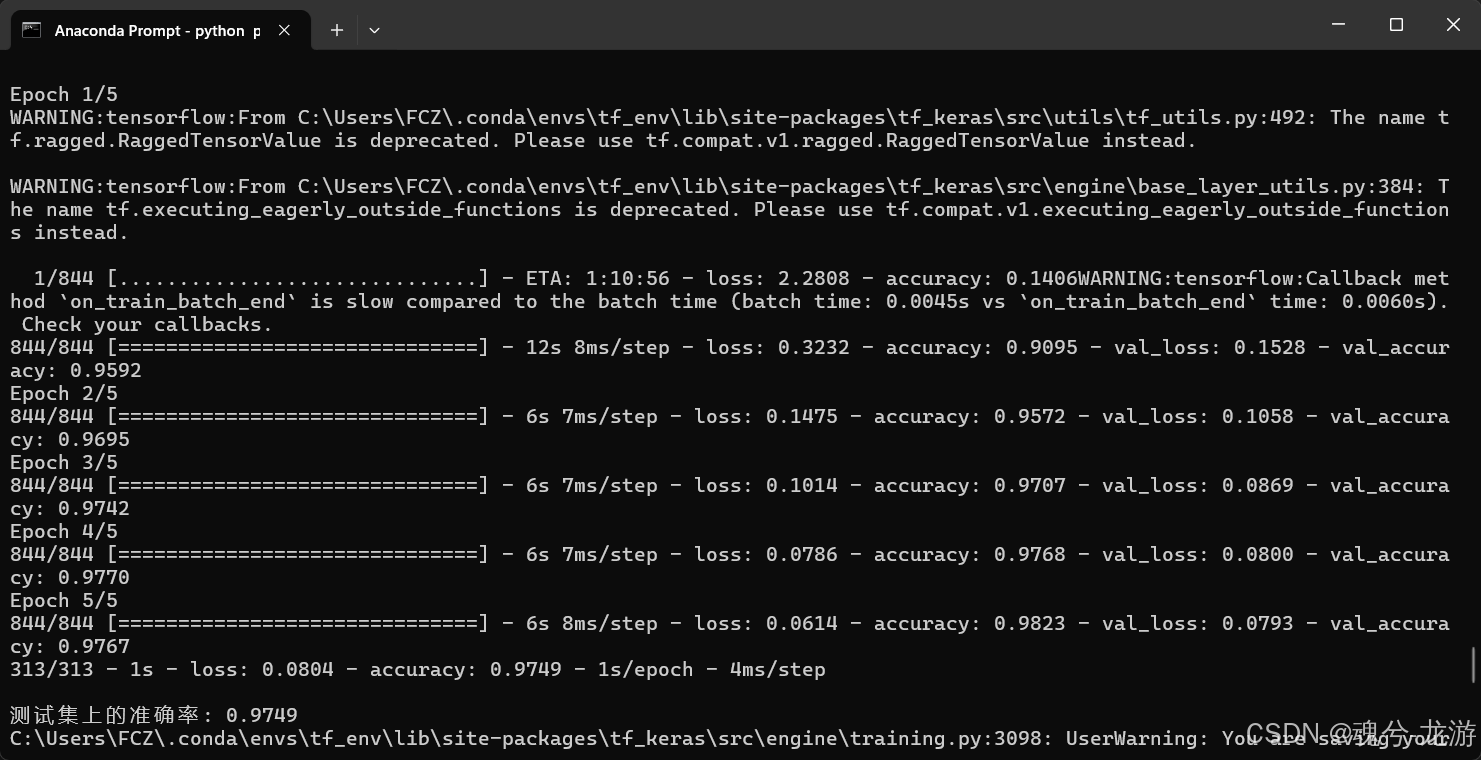
2.4 检查与验证剪枝后模型
- 模型体积:相较原始不剪枝模型,
pruned_mnist_model.h5通常会更小,但因 HDF5 格式本身包含稀疏权重的表示方式,实际文件大小并不总是线性减少。关键是剪枝会让权重矩阵变得稀疏,后续可以配合特定框架(如 STM32Cube.AI)进行再处理。 - 准确率:可能略有降低,一般会在 0.97~0.98 附近。若下降过多,可调整
final_sparsity(如从 0.5 改为 0.3) 或增加微调 epochs。 - 后续可做量化:将剪枝后模型再进行量化,可实现进一步体积和推理速度的提升。
3. 模型量化 (Quantization)
3.1 原理与应用场景
- 量化:把模型中的权重(和激活)从 float32 转化成 int8、float16 等低位格式,典型方式是使用 TensorFlow Lite 的离线量化。
- 适用场景:需要在嵌入式或移动端部署,同时希望降低模型大小和加速推理。
- 代价:可能带来少量精度损失。如果需要减小精度损失,可用量化感知训练(QAT)。
3.2 在脚本中添加量化步骤
当我们在 train_mnist.py 训练完基础模型后,在prune_mnist.py完成剪枝操作后,接下来完成量化操作,编写单独脚本 quantize_mnist.py:将 训练、剪枝、量化 三个步骤整合在一起
"""
quantize_mnist.py
-----------------
在同一个脚本中完成:
1. MNIST 基础模型训练
2. 剪枝 (Pruning)
3. 量化 (Quantization)
依赖:
- tensorflow>=2.5
- tensorflow-model-optimization
- numpy, matplotlib (可选, 用于可视化)
"""
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_model_optimization as tfmot
def load_mnist_data():
"""加载 MNIST 数据,并做基本预处理。"""
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
# 展开 28x28 -> 784
x_train = x_train.reshape(-1, 28 * 28)
x_test = x_test.reshape(-1, 28 * 28)
return (x_train, y_train), (x_test, y_test)
def create_base_model():
"""构建一个简单的全连接 MNIST 模型。"""
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, activation='softmax')
])
return model
def plot_history(history, title_prefix=""):
"""可视化训练曲线"""
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(len(acc))
plt.figure(figsize=(12, 4))
# 准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='训练准确率')
plt.plot(epochs_range, val_acc, label='验证准确率')
plt.legend(loc='lower right')
plt.title(f'{title_prefix} 训练和验证准确率')
# 损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='训练损失')
plt.plot(epochs_range, val_loss, label='验证损失')
plt.legend(loc='upper right')
plt.title(f'{title_prefix} 训练和验证损失')
plt.show()
def main():
# =======================================
# 1. 数据准备
# =======================================
(x_train, y_train), (x_test, y_test) = load_mnist_data()
# =======================================
# 2. 训练基线模型
# =======================================
print("\n--- 步骤1: 训练基线模型 ---")
base_model = create_base_model()
base_model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
history_base = base_model.fit(
x_train, y_train,
epochs=5,
batch_size=64,
validation_split=0.1
)
test_loss_base, test_acc_base = base_model.evaluate(x_test, y_test, verbose=0)
print(f"基线模型测试集准确率: {test_acc_base:.4f}")
# 可视化基线模型训练过程
plot_history(history_base, title_prefix="基线模型")
# 保存基线模型
base_model.save("mnist_model.h5")
# =======================================
# 3. 剪枝 (Pruning)
# =======================================
print("\n--- 步骤2: 剪枝模型 ---")
# 定义剪枝参数:从0%渐增到50%的剪枝率
pruning_params = {
'pruning_schedule': tfmot.sparsity.keras.PolynomialDecay(
initial_sparsity=0.0,
final_sparsity=0.5,
begin_step=0,
end_step=np.ceil(len(x_train) / 64).astype(np.int32) * 5
)
}
# 用之前的 base_model 权重来构造可剪枝模型
# 也可直接对 base_model 做 prune_low_magnitude,但这里分开写更清晰
pruned_model = tf.keras.models.Sequential([
tf.keras.layers.Dense(128, activation='relu', input_shape=(784,)),
tfmot.sparsity.keras.prune_low_magnitude(
tf.keras.layers.Dense(10, activation='softmax'),
**pruning_params
)
])
# 把 base_model 的第一层权重复制到 pruned_model 第1层
pruned_model.layers[0].set_weights(base_model.layers[0].get_weights())
# 编译可剪枝模型
pruned_model.compile(
optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy']
)
# 设置回调:更新剪枝步数 + 记录日志
callbacks = [
tfmot.sparsity.keras.UpdatePruningStep(),
tfmot.sparsity.keras.PruningSummaries(log_dir='logs')
]
history_pruned = pruned_model.fit(
x_train, y_train,
epochs=3, # 可以适当增加训练轮数
batch_size=64,
validation_split=0.1,
callbacks=callbacks
)
test_loss_pruned, test_acc_pruned = pruned_model.evaluate(x_test, y_test, verbose=0)
print(f"剪枝后模型测试集准确率: {test_acc_pruned:.4f}")
plot_history(history_pruned, title_prefix="剪枝模型")
# strip_pruning: 得到真正稀疏的权重
final_pruned_model = tfmot.sparsity.keras.strip_pruning(pruned_model)
final_pruned_model.save("pruned_mnist_model.h5")
# =======================================
# 4. 量化 (Quantization)
# =======================================
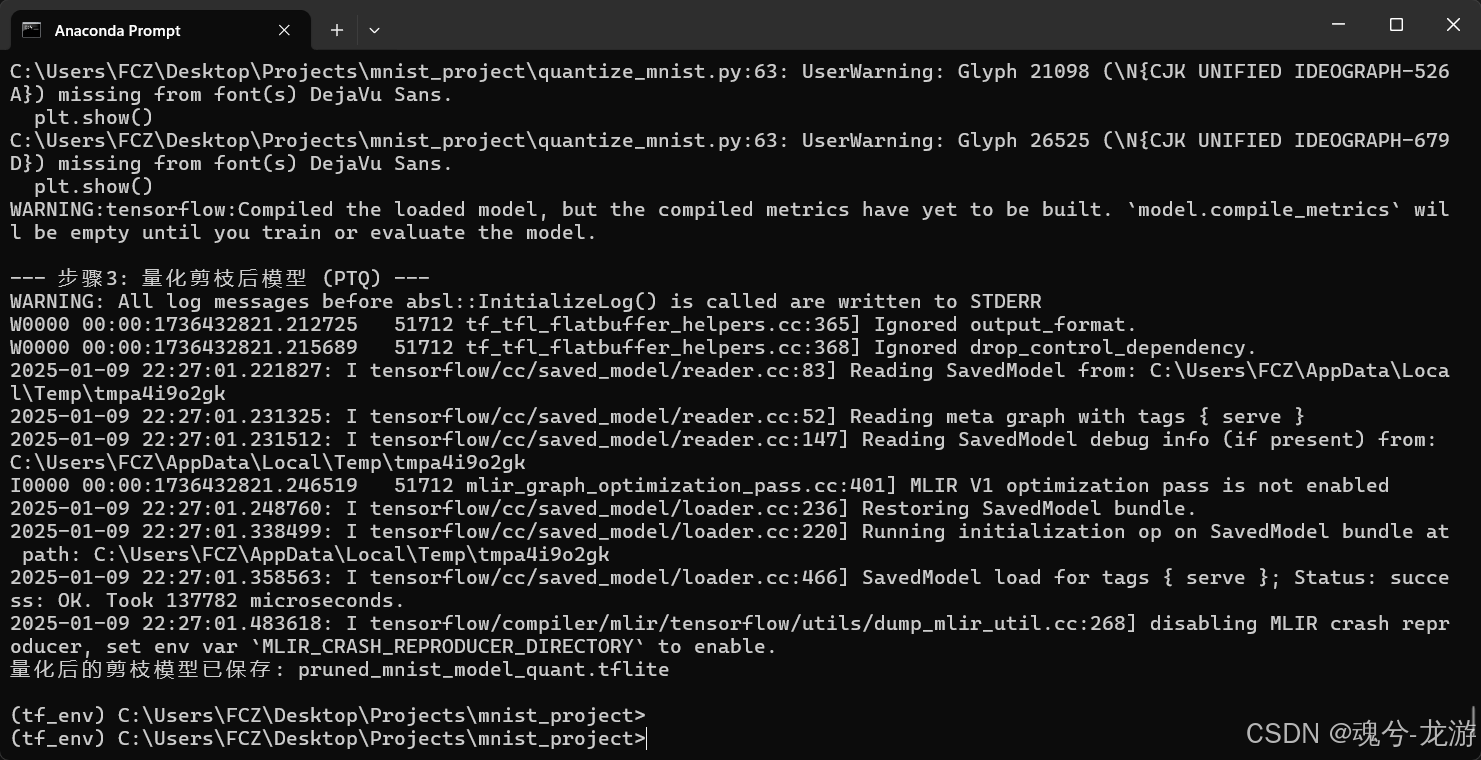
print("\n--- 步骤3: 量化剪枝后模型 (PTQ) ---")
# 您也可以对 base_model 做量化,这里演示对 剪枝后的模型 做量化
converter = tf.lite.TFLiteConverter.from_keras_model(final_pruned_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 如需要 representative_dataset 来校准,可添加:
# converter.representative_dataset = ...
# 转换为 TFLite
tflite_quant_model = converter.convert()
# 保存量化后的 TFLite 文件
with open('pruned_mnist_model_quant.tflite', 'wb') as f:
f.write(tflite_quant_model)
print("量化后的剪枝模型已保存: pruned_mnist_model_quant.tflite")
# 如有需要,可使用 tflite interpreter 测试推理
# 这里仅演示到生成 TFLite 文件即可
if __name__ == "__main__":
main()
注意:
- 量化完成后,记得在 PC 或嵌入式设备上进行推理测试,查看最终精度。
3.3 运行量化脚本
- 依旧在 Anaconda Prompt 中激活环境:
conda activate tf_env - 导航到脚本所在目录
- 执行:
python quantize_mnist.py - 观察输出:若无异常,脚本会提示
"量化后的模型已保存为 mnist_model_quant.tflite"。
-
结果文件
-
mnist_model.h5:基线模型(未剪枝、未量化)。pruned_mnist_model.h5:剪枝后且 strip_pruning 的 Keras 模型。pruned_mnist_model_quant.tflite:剪枝后再量化的 TFLite 模型,通常体积最小,速度也更快(具体依赖硬件支持)。 - 训练基线模型:训练 5 轮得到
mnist_model.h5。 - 剪枝模型:基于基线模型的权重进行剪枝,训练 3 轮得到
pruned_mnist_model.h5。 - 量化模型:将剪枝后的模型转换为
.tflite格式,并保存为pruned_mnist_model_quant.tflite。
总结
接下来对优化后的模型进行验证。