Abstract—State-of-the-art【最先进的】 object detection networks depend on region proposal algorithms to hypothesize【假设、推测】 object locations.Advances like SPPnet [1] and Fast R-CNN [2] have reduced the running time of these detection networks, exposing region proposal computation as a bottleneck. In this work, we introduce a Region Proposal Network(RPN) that shares full-image convolutional features with the detection network, thus enabling nearly cost-free region proposals. An RPN is a fully convolutional network that simultaneously predicts object bounds and objectness scores at each position. The RPN is trained end-to-end togenerate high-quality region proposals, which are used by Fast R-CNN for detection. We further merge RPN and Fast R-CNN into a single network by sharing their convolutional features—using the recently popular terminology of neural networks with “attention” mechanisms, the RPN component tells the unified network where to look. For the very deep VGG-16 model [3],our detection system has a frame rate of 5fps (including all steps) on a GPU, while achieving state-of-the-art object detection accuracy on PASCAL VOC 2007, 2012, and MS COCO datasets with only 300 proposals per image. In ILSVRC and COCO2015 competitions, Faster R-CNN and RPN are the foundations of the 1st-place winning entries in several tracks. Code has been made publicly available
摘要
目前最先进的目标检测网络需要先用区域建议算法推测目标位置,像SPPnet[7]和Fast R-CNN[5]这些网络已经减少了检测网络的运行时间,这时计算区域建议就成了瓶颈问题。本文中,我们介绍一种区域建议网络(Region Proposal Network, RPN),它和检测网络共享全图的卷积特征,使得区域建议几乎不花时间。RPN是一个全卷积网络,在每个位置同时预测目标边界和objectness得分。RPN是端到端训练的,生成高质量区域建议框,用于Fast R-CNN来检测。通过共享它们的卷积特征,进一步将RPN和Fast R-CNN合并为一个网络,我们使用最近流行的带有“注意力”机制的神经网络术语RPN组件告诉统一网络该往哪里看。通过一种简单的交替运行优化方法,RPN和Fast R-CNN可以在训练时共享卷积特征。对于非常深的VGG-16模型[19],我们的检测系统在GPU上的帧率为5fps(包含所有步骤),在PASCAL VOC 2007和PASCAL VOC 2012上实现了最高的目标检测准确率(2007是73.2%mAP,2012是70.4%mAP),每个图像用了300个建议框。代码已公开。
1.引言
Recent advances in object detection are driven byt he success of region proposal methods (e.g., [4])and region-based convolutional neural networks (R-CNNs) [5]. Although region-based CNNs were computationally expensive as originally developed in [5],their cost has been drastically reduced thanks to sharing convolutions across proposals [1], [2]. The latest incarnation, Fast R-CNN [2], achieves near real-time rates using very deep networks [3],when ignoring the time spent on region proposals. Now, proposals are the test-time computational bottleneck in state-of-the-artdetection systems.
最近在目标检测中取得的进步都是由区域建议方法(例如[22])和基于区域的卷积神经网络(R-CNN)[6]取得的成功来推动的。基于区域的CNN在[6]中刚提出时在计算上消耗很大,幸好后来这个消耗通过建议框之间共享卷积[7,5]大大降低了。最近的Fast R-CNN[5]用非常深的网络[19]实现了近实时检测的速率,注意它忽略了生成区域建议框的时间。现在,建议框是最先进的检测系统中的计算瓶颈。
Region proposal methods typically rely on inexpensive features and economical inference schemes.Selective Search [4], one of the most popular methods, greedily merges super pixels based on engineered low-level features. Yet when compared to efficient detection networks [2], Selective Search is an order of magnitude slower, at 2 seconds per image in a CPU implementation. EdgeBoxes [6] currently provides the best tradeoff between proposal quality and speed,at 0.2 seconds per image. Nevertheless, the region proposal step still consumes as much running time as the detection network.
区域建议方法典型地依赖于消耗小的特征和经济的推断方案。选择性搜索(Selective Search, SS)[22]是最流行的方法之一,它基于设计好的低级特征贪心地融合超级像素。与高效检测网络[5]相比,SS要慢一个数量级,CPU应用中大约每个图像2s。EdgeBoxes[24]在建议框质量和速度之间做出了目前最好的权衡,大约每个图像0.2s。但无论如何,区域建议步骤花费了和检测网络差不多的时间。
One may note that fast region-based CNNs take advantage of GPUs, while the region proposal methods used in research are implemented on the CPU,making such runtime comparisons inequitable. An obvious way to accelerate proposal computation is to reimplement it for the GPU. This may be an effective engineering solution, but reimplementation ignores the downstream detection network and therefore misses important opportunities for sharing computation.
Fast R-CNN利用了GPU,而区域建议方法是在CPU上实现的,这个运行时间的比较是不公平的。一种明显提速生成建议框的方法是在GPU上实现它,这是一种工程上很有效的解决方案,但这个方法忽略了其后的检测网络,因而也错失了共享计算的重要机会。
In this paper, we show that an algorithmic change—computing proposals with a deep convolutional neural network—leads to an elegant and effective solution where proposal computation is nearly cost-free given the detection network’s computation. To this end, we introduce novel Region Proposal Networks(RPNs) that share convolutional layers with state-of-the-art object detection networks [1], [2]. By sharing convolutions at test-time, the marginal cost for computing proposals is small (e.g., 10ms per image).
本文中,我们改变了算法——用深度网络计算建议框——这是一种简洁有效的解决方案,建议框计算几乎不会给检测网络的计算带来消耗。为了这个目的,我们介绍新颖的区域建议网络(Region Proposal Networks, RPN),它与最先进的目标检测网络[7,5]共享卷积层。在测试时,通过共享卷积,计算建议框的边际成本是很小的(例如每个图像10ms)。
Our observation is that the convolutional feature maps used by region-based detectors, like Fast R-CNN, can also be used for generating region proposals. On top of these convolutional features, we construct an RPN by adding a few additional convolutional layers that simultaneously regress region bounds and objectness scores at each location on a regular grid. The RPN is thus a kind of fully convo-lutional network (FCN) [7] and can be trained end-to-end specifically for the task for generating detection proposals.
我们观察发现,基于区域的检测器例如Fast R-CNN使用的卷积(conv)特征映射,同样可以用于生成区域建议。在这些卷积特征的基础上,我们通过添加几个额外的卷积层来构建RPN,这些卷积层同时回归区域边界和规则网格上每个位置的对象得分。因此,RPN是一种完全卷积网络(FCN)[7],可以针对生成候选框的任务进行端到端训练。
RPNs are designed to efficiently predict region proposals with a wide range of scales and aspect ratios. In contrast to prevalent methods [8], [9], [1], [2] that use pyramids of images (Figure 1, a) or pyramids of filters(Figure 1, b), we introduce novel “anchor” boxes that serve as references at multiple scales and aspect ratios. Our scheme can be thought of as a pyramid of regression references (Figure 1, c), which avoids enumerating images or filters of multiple scales or aspect ratios. This model performs well when trained and tested using single-scale images and thus benefits running speed.
RPN被设计用于有效预测具有广泛尺度和长宽比的区域预测。与使用图像金字塔(图1,a)或滤镜金字塔(图2,b)的流行方法不同,我们引入了新的“锚”框,该框在多个尺度和长宽比下用作参考。我们的方案可以被认为是回归参考的金字塔(图1,c),它避免了对多尺度或纵横比的图像或滤波器进行计数。该模型在使用单尺度图像进行训练和测试时表现良好,因此有利于运行速度。
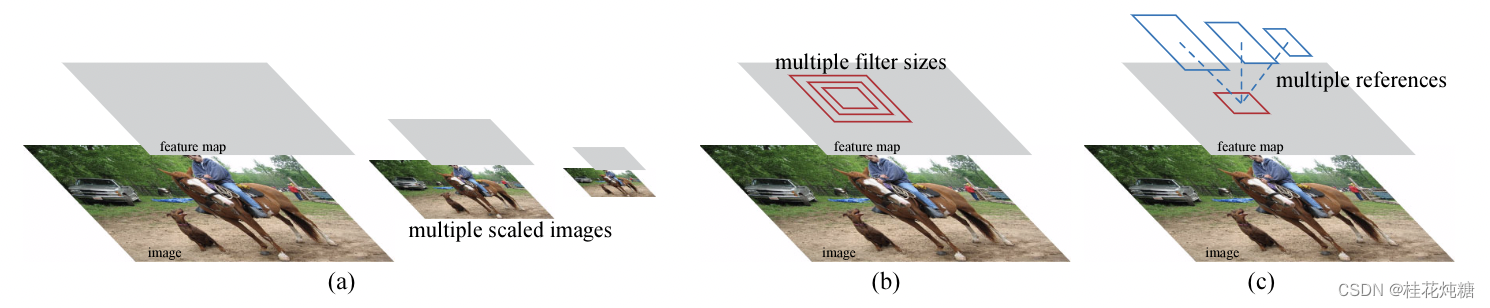
图1:解决多尺度和尺寸问题的不同方案。(a) 建立了图像金字塔和特征图,并在所有尺度上运行分类器。(b) 具有多个比例/大小的过滤器金字塔在要素图上运行。(c) 我们在回归函数中使用参考框的金字塔。
To unify RPNs with Fast RCNN [2] object detection networks, we propose a training scheme that alternates between fine-tuning for the region proposal task and then fine-tuning for object detection, while keeping the proposals fixed. This scheme converges quickly and produces a unified network with convolutional features that are shared between both tasks.
为了统一RPN和Fast R-CNN[5]目标检测网络,我们提出一种简单的训练方案,即保持候选框固定,微调区域建议和微调目标检测之间交替进行。这个方案收敛很快,最后形成可让两个任务共享卷积特征的标准网络。
We comprehensively evaluate our method on the PASCAL VOC detection benchmarks [11] where RPNs with Fast R-CNNs produce detection accuracy better than the strong baseline of Selective Search with Fast R-CNNs. Meanwhile, our method waives nearly all computational burdens of Selective Search at test-time—the effective running time for proposals is just 10 milliseconds. Using the expensive very deep models of [3], our detection method still has a frame rate of 5fps (including all steps) on a GPU,and thus is a practical object detection system interms of both speed and accuracy. We also reportresults on the MS COCO dataset [12] and investigate the improvements on PASCAL VOC using theCOCO data. Code has been made publicly available at https://github.com/shaoqingren/faster_rcnn(in MATLAB) and https://github.com/rbgirshick/py-faster-rcnn(in Python)
我们在PASCAL VOC检测基准上综合评估了我们的方法[11],其中使用快速R-CNN的RPN产生的检测精度比使用快速R-CNN的选择性搜索的强基准更好。同时,我们的方法几乎免除了选择性搜索的所有计算负担——提案的有效运行时间仅为10毫秒。使用[3]中昂贵的深度模型,我们的检测方法在GPU上仍具有5fps的帧速率(包括所有步骤),因此在速度和精度方面都是一个实用的目标检测系统。我们还报告了MS COCO数据集的结果[12],并使用COCO数据对PASCAL VOC的改进进行了研究。代码已公开leathttps://github.com/shaoqingren/faster_rcnn(在MATLAB中)andhttps://github.com/rbgirshick/py-faster-rcnn(在Python中)
A preliminary version of this manuscript was published previously [10]. Since then, the frameworks of RPN and Faster R-CNN have been adopted and generalized to other methods, such as 3D object detection[13], part-based detection [14], instance segmentation[15], and image captioning [16]. Our fast and effective object detection system has also been built in commercial systems such as at Pinterests [17], wit