书接上文库内AI引擎:模型管理&数据集管理,从模型管理与数据集管理两方面介绍了GaussDB库内AI引擎,本篇将从智能优化器方面解读GaussDB高智能技术。
4 智能优化器
随着数据库与AI技术结合的越来越紧密,相关技术在学术界的数据库各大顶会中出现井喷现象。如下图所示,从2019年至2022年,AI优化器、AI配置调优、AI存储管理及DB4AI等领域的论文逐年递增,越来越多的技术实现从规则到智能的转换、从人工到自治的转换、从经验到数据的转换、从离线到在线的转换。
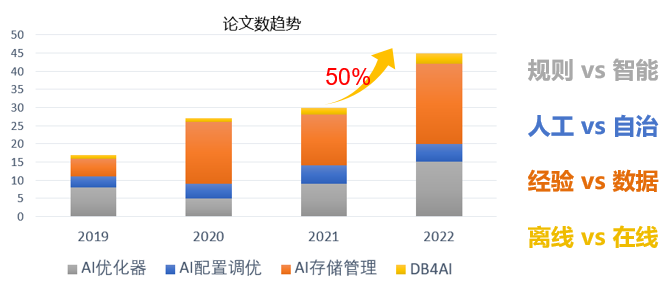
通过对学术界和工业界在各方面的技术分析,我们可以获悉,在AI优化器领域,通过AI技术可以实现从规则到智能的技术创新,在生成计划的准确性和质量上有质的飞越。例如DB2落地证明AI模型能够有效提升基数估计准确性,已支持单点、范围、in等多种谓词,基数估计的准确率由30%提升到99%;AI代价模型Cost估计误差减少10%到60%;AI计划生成TPS平均提升43%。在AI配置调优领域,逐渐实现由人工到自治的转变,由AI技术,自动调优内存设置、缓存设置、优化器参数、并发度等,效果接近、甚至超过DBA调优,调优时间由天级下降到分钟级。在AI存储领域,通过IO技术极大加速IO的读写效率,通过智能缓存淘汰算法,有效避免缓存计划使用错误;通过学习型index设置,index评价查找长度由O(logn)下降为O(1)。
尽管AI技术在数据库内核层面探索的功能项很多,但鲜有真正落地的商业产品。突出的技术难点是如何做到模型的普适性,在一个场景或者负载下训练有效的模型,是否可在任意场景或者负载下均有效;另一个难点是推理效率快捷且占用资源低,在交易型数据库场景下,执行效率仍有保障。
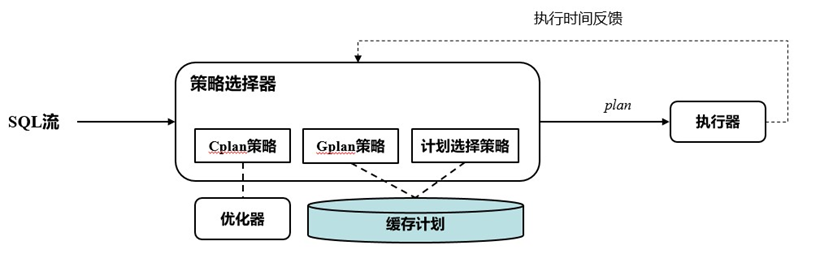
GaussDB创新型提出利用轻量级库内机器学习模型结合数据库内核模块构建智能的优化器。其设计的主体架构如下图所示:
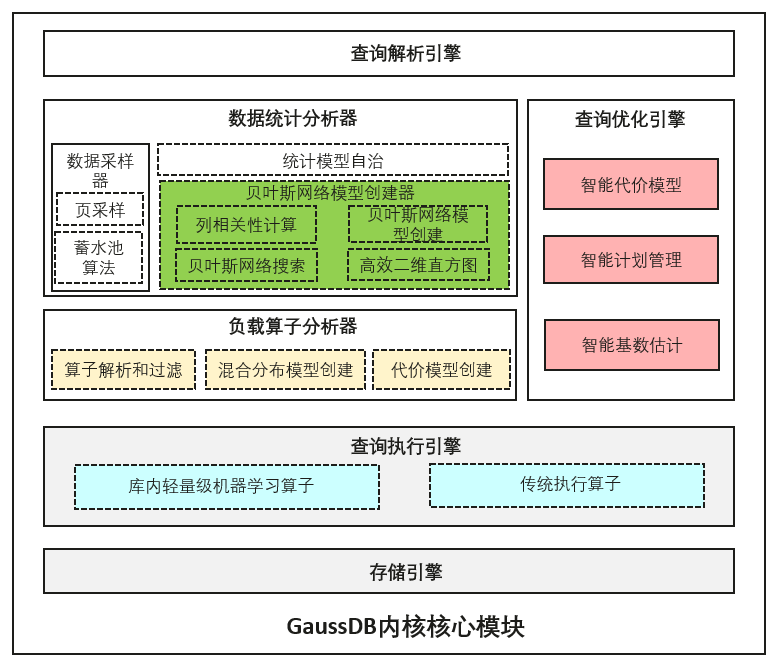
其中智能基数估计方案将轻量概率图模型融合进GaussDB的传统统计信息模块,在统计收集阶段进行模型训练,并且将模型保存在系统表中供优化器使用。此方案相比于友商的外挂式模型训练方案来说,具有高安全和高性能的优势。高安全在于数据不需要导出数据库系统安全边界,高性能在于原生的数据获取和模型训练和推理十分高效。主要思路是数据库接受特定分析查询语句,判断语句是否包含多列并且调用数据统计模块;数据统计模块在接收指令之后首先针对包含的列进行数据采样,然后针对数据样本进行数据统计;如果数据统计模块发现智能统计GUC参数开启,则进行贝叶斯网络模型的创建,包括利用聚合操作统计并计算出列两两之间的相关性、使用chow-liu算法生成一个树型贝叶斯网络结构、调用贝叶斯网络算子通过遍历数据样本进行模型参数训练,并且将模型参数已二进制的形式存入系统模型表中。
智能计划管理是利用机器学习算法,将数据库中的执行语句匹配到最佳计划中。主要思路是先计算出查询涉及到的基表选择率,然后使用K近邻算法选择缓存的计划。如果输入的查询基数特征超出缓存的范围,那么就进行计划探测,利用优化器生成自适应的执行计划并且存在计划缓存中。而后系统自动对查询执行时间进行记录和分析并且自动选择是否启用自适应计划选择,并且针对不适用多计划选择的场景,也会自动为其选择使用gplan还是cplan;计划管理模块接受到SQL后,首选对query的选择率信息进行提取,包括基表选择率,索引选择率,和limit offset取值等信息;后续基于query的选择率信息进行计划匹配。如果选择成功,则返回计划给执行器;如果尚无缓存计划、或匹配失败,则调用优化器进行计划探测(硬解析);如果探测计划尚未加入缓存,则尝试加入缓存(最多10个);如果已在缓存中,则尝试更新模型以提升准确率。最后,将探测计划传递给执行器。
4.1 智能基数估计
智能基数估计的总体思路是在模型中加入高频值统计。复用MCV逻辑产生的高频行以及对应行数,包装成数据获取接口供贝叶斯网络模型调用,贝叶斯网络模型中将高频值序列化到模型系统表中,并且对剩余数据进行贝叶斯统计建模;在选择率估计阶段,优化器首先检查输入查询条件是否匹配高频值,如果匹配,直接返回结果;否则使用贝叶斯网络模型进行估计;高频值统计利用哈希表加速查询并且利用缓存技术避免访存和反序列化代价。
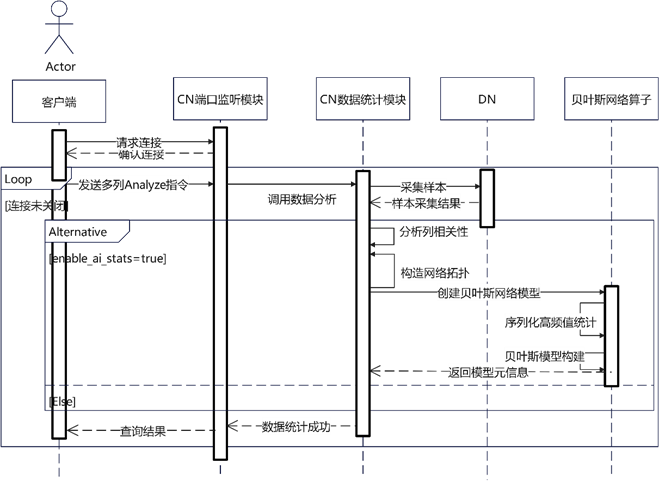
(1)模型创建
如下图所示,本功能通过用户提交ANALYZE命令或者auto-analyze触发,通过CN样本采集器获取内存中数据样本结构并且包装成数据源结构体。数据源结构体汇总包含两部分信息,一部分是可能存在的高频值统计信息,另一部分是全量数据样本信息。高频值信息包含频度大于1的值(如果等于1,则不认为是高频值),而全量样本信息则是压平为序列一条一条发送给模型。因此模型可以通过获取到的频度判断当前读到的数据是否是高频值或者是普通样本数据。对于高频值统计数据,模型算子直接将其序列化保存到模型中,而对于普通样本数据,则对其不属于高频值的部分做贝叶斯网络模型统计。
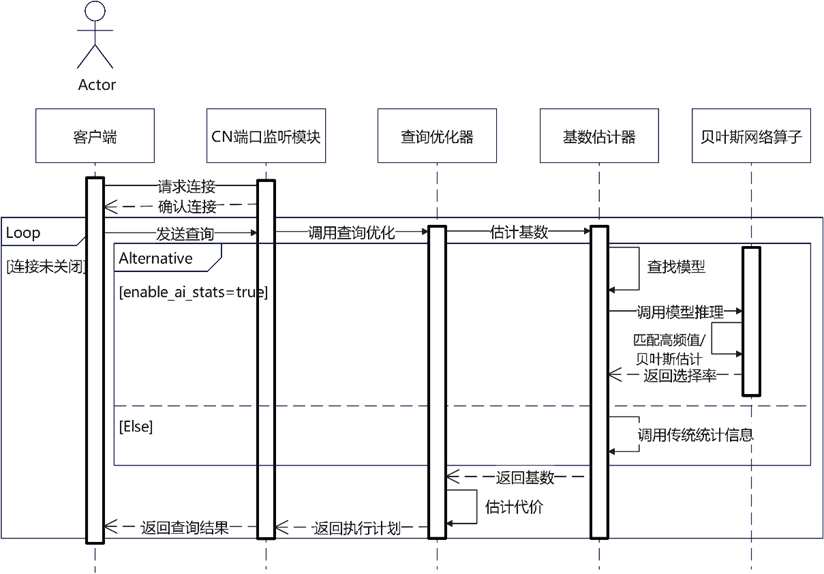
(2)模型推理
如下图所示,在基数估计阶段,系统首先将模型从磁盘中读到内存中,然后将模型进行反序列化成为内存结构并且使用独立内存上下文缓存起来;对于每条多列等值查询,首先查找高频值哈希表,如果找到则直接返回选择率P1(t),否则计算查询条件在贝叶斯网络模型中的选择率P2(t),最后返回P2(t) / (1.0-SUM(P1)),其中SUM(P1)是所有高频值选择率的和。使用本功能之后,GaussDB中的多列等值选择率估计优先级为,有高频值优先从高频值哈希表中获取,非高频值通过贝叶斯网络获得选择率,如果上述模型都未创建或者覆盖,则尝试使用多列ndv进行估计,如果统计信息和查询列未匹配,那么采用多列函数依赖。如果上述统计信息均未创建,则将clause条件加回不匹配条件中,然后使用单列+独立性假设的方式估计。
(3)模型信息显示
创建一个新的系统函数gs_ai_stats_explain(relid, stakeys),其中参数relid是一个整型,stakeys是一个数组。该系统函数获得输入参数之后会和系统表pg_statistic_ext中的统计信息进行匹配,查找类型为BAYESNET类型的统计信息行,如果找不到,那么直接反馈失败;否则调用相应的模型解释框架函数,也就是贝叶斯网络的explain函数,从磁盘中读取模型,反序列化之后将信息重新组合成可读类型,构建成数组返回给系统函数。其中主要包含的内容有贝叶斯网络拓扑,高频值及其选择率,单列上的分桶类型以及直方图或者mcv边界值,以及每个分桶中的每个可能值的概率值。其余还包括一些模型通用信息,比如模型训练时间,模型超参数,模型创建时间等。
4.2 智能计划管理
当前的执行计划主要通过cplan(customer plan),gplan(generic plan)或者aplan(adaptive plan)产生,但是这三种计划都存在问题,gplan由于无法做到变量窥视导致计划无法适应不同查询,cplan由于需要多次进行路径选择优化代价很高,aplan支持的场景有限,因此需要在这三种计划策略中进行选择。本特性首先对不同候选策略(cplan、aplan、gplan)进行一定数量的尝试,并根据各策略的执行反馈信息确定最高效的策略。核心问题有两个:
策略尝试方案:依次尝试cplan、gplan、aplan若干次,并记录各策略的平均执行时间。为避免尝试可能带来的性能下降,各策略的尝试次数是算法动态确定。此外当选中策略性能明显下降时,其他候选策略的尝试会自动重启(重启时机根据算法确定)。
策略选择:将cplan作为性能基准,依次将gplan、aplan与cplan的执行时间进行比较。如果gplan/aplan性能高于(或接近)cplan, 则选择该策略。可见gplan在优先级高于aplan。注意,该策略是基于已有策略决策的二次选择。安全起见,在已有策略做出使用cplan决定时,本策略不做任何改变。
计划选择整体流程如下图所示:
针对cplan、gplan和多计划选择,不同的计划选择策略在内存消耗、解析代价及执行性能的分析如下:
| 策略 | 描述 | 内存消耗 | 解析代价 | 执行性能 |
| cplan | 调用优化器生成计划 | 中 | 高 | 不同场景下最优策略不同,存在不确定性。但一般认为cplan性能最优。 |
| gplan | 利用默认参数生成的通用计划 | 低 | 无 | |
| 多计划选择 | 根据选择率,从多个缓存计划中选择最匹配的计划 | 高 | 低 |
在选择合适的执行计划后,计划生成策略切换的时序图如下:
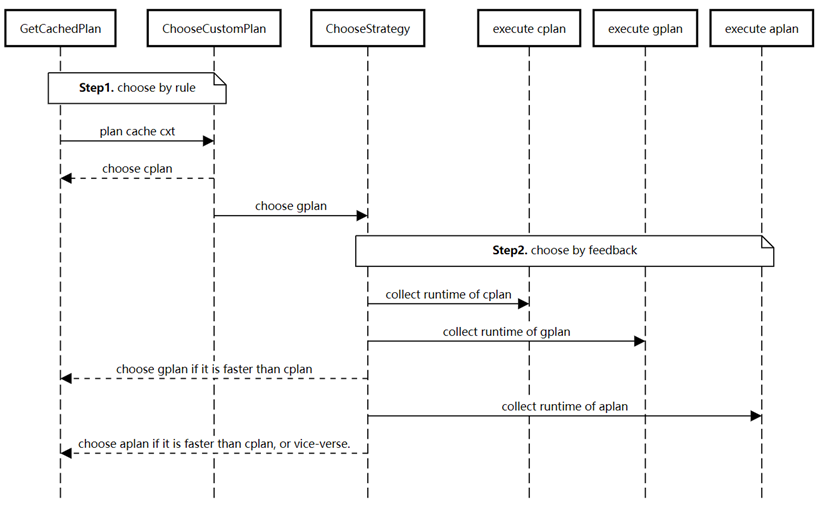
针对每种查询模板,默认会走10次cplan作为基准执行成本,然后会有一定的概率进行其他计划策略的探索,如果发现有其他策略的估计执行时间期望小于当前策略,则发生切换,具体的探索频率按照大数定理进行决策,让估计期望和整体期望的误差小于一个界。
在计划自适应选择中,核心功能包括两个,即自适应策略选择及自适应探测次数。
(1)自适应策略选择
策略选择器会尝试不同策略,并根据各策略反馈的性能指标(执行时间)进行选择。初始化cplan,gplan,aplan策略的性能指标为0。当一条查询到来后,其计划的选择策略选优过程如下:
步骤1:如果cplan的执行次数<10,返回cplan。
步骤2:如果已统计的gplan的性能指标小于cplan,返回gplan;否则转到步骤3。
步骤3:如果已统计的aplan的性能指标小于cplan,返回aplan;否则返回cplan。
说明:每次执行都会反馈并更新当前策略的执行时间;执行10次cplan的目的是获取执行性能基准。因此,gplan和aplan只有当其执行效率不低于cplan时才会被选中。此外,gplan的优先级要高于aplan,这是由于aplan需要变量窥探,相较于gplan选择消耗更多算力和内存资源。
自适应策略选择机制,如果识别出cplan整体性能较高,会倾向于执行cplan。
(2)自适应探测次数
gplan或者aplan在探测次数较少时,可能因为性能抖动导致被淘汰。为避免该问题,本方案通过概率置信度算法确定探测次数是否足够。如果探测次数不足,则进行更多探测,从而获得gplan、aplan更准确的性能指标。
设执行n次候选策略(gplan/aplan)的平均时间为x,并假设cplan执行任意n次性能为x的期望概率为p。如果p 小于阈值,说明cplan不大可能性能为x,则可以放心淘汰候选策略;否则,说明x可能是随机误差导致的性能低估,则进行更多探测。期望概率p根据大数定律计算:
其中u为cplan的平均执行时间,X为候选策略的平均执行时间,偏差σ = X/u;采用次数c = n。公式显示:当采样次数c增加时,σ将以指数级速度接近1。
当该算法发现cplan性能下降时,将给与cplan/aplan更多探测机会。从而有效的避免了由于探测随机性,或者性能波动导致的cplan/aplan误淘汰。此公式计划依赖的输入值都可以高效获取,计算效率不是主要性能瓶颈。
4.3 反馈自适应优化器
反馈自适应代价优化器通过查询反馈动态矫正错误的估计基数或者是代价模型,实现优化器能够及时随着负载变化,数据变化以及运行环境变化做自适应调整,其中主要依赖反馈基数估计和反馈代价矫正两个关键特性。
(1)反馈式优化器会采集数据库系统中SQL查询计划算子运行信息,当前包括Join算子和Scan算子,运行信息包括算子类型,算子结果行数,以及该算子所有孩子节点的查询条件(针对Join);针对每种算子,依据Join条件和基表过滤条件形成的等价类计算出算子的哈希值,该哈希值相同表示算子的模式(pattern)是等价的,只有模式等价的算子才能共用同一个基数估计模型;历史算子中抽取出查询条件以及对应的数值,用查询条件构造出超方体,超方体的维度对应查询模式的每个条件,而其面积由实际条件的上下限构成;接着从每个查询超方体中均匀采样一定数量的点,利用K-means聚类算法找出K个中心点,然后以每个点作为中心,最近的若干点的距离均值作为每个维度的变长构造一系列的采样超方体;最后假设每个采样超方体内部是均匀分布,每个查询由不同的均匀分布加权叠加,通过拟合每个查询的选择率学习出权重,从而获得均匀分布模型参数。整个过程可以使用命令手动触发,也可以依赖后台线程自动触发;查询优化阶段,优化器首先根据当前估计算子的特征哈希值抽取对应的反馈基数模型,根据当前的查询条件范围选择是否选用当前模型;否则利用数据驱动模型。接着优化器利用反馈自适应确定的代价模型参数,结合基数输入计算出算子代价,并且支撑当前优化器计划路径决策。
(2)代价参数矫正模块会采集数据库系统中的缓存读取IO时间和SQL查询计划算子运行信息,当前收集的包括SeqScan算子,矫正的参数包含cpu_tuple_cost, cpu_index_tuple_cost, cpu_operator_cost, seq_page_cost, random_page_cost。每个设备上的数据库各自维护自己的代价参数。通过在每个页面读取开始和结束时计时,估算出平均每个页面读取的IO时间。进一步,通过调用计划开始前后的缓存信息,筛选出对没有发生缓存读取的SQL语句中(在TPC-H和JOB跑到第二轮之后占比90%以上),对其中的SeqScan算子进行数据采集,建立CPU参数和运算时间的回归模型,进而给出CPU参数的估计。查询优化阶段,优化器对有反馈基数模型的路径(即路径涉及到的每个基数估计都来自反馈基数模型),利用矫正的代价参数和AQO基数,额外维护一个新代价,但也保留生成该路径的结果集的最优旧代价。对每个有反馈基数模型的子路径,使用新代价选择最优执行方案;如果路径连接中至少有一方的基数不来自反馈基数,则停止维护新代价,并且在之后的连接中使用旧代价,确保不会劣化。