1、一些C++基础知识
模板类string的设计属于底层,其中运用到了很多C++的编程技巧,比如模板、迭代器、友元、函数和运算符重载、内联等等,为了便于后续理解string类,这里先对涉及到的概念做个简单的介绍。C++基础比较扎实的童鞋可以直接跳到第三节。
1.1 typedef
1.1.1 四种常见用法
- 定义一种类型的别名,不只是简单的宏替换。可用作同时声明指针型的多个对象
| 1 2 3 4 5 |
|
顺便说下,*运算符两边的空格是可选的,在哪里添加空格,对于编译器来说没有任何区别。
| 1 2 |
|
- 定义struct结构体别名
在旧的C代码中,声明struct新对象时,必须要带上struct,形式为:struct 结构名 对象名。
| 1 2 3 4 5 6 7 8 |
|
使用typedef来定义结构体StrudentStruct的别名为Student,声明的时候就可以少写一个struct,尤其在声明多个struct对象时更加简洁直观。如下:
| 1 2 3 4 5 6 7 8 |
|
而在C++中,声明struct对象时本来就不需要写struct,其形式为:结构名 对象名。
// C++声明StudentStruct类型对象s1和s2 StudentStruct s1,s2;
所以,在C++中,typedef的作用并不大。了解他便于我们阅读旧代码。
- 定义与平台无关的类型
比如定义一个REAL的浮点类型,在目标平台一上,让它表示最高精度的类型为:
typedef long double REAL;
在不支持long double的平台二上,改为:
typedef double REAL;
在连double都不支持的平台三上,改为:
typedef float REAL;
也就是说,在跨平台时,只要改下typedef本身就行,不要对其他源码做任何修改。
标准库中广泛使用了这个技巧,比如size_t、intptr_t等

1 // Definitions of common types 2 #ifdef _WIN64 3 typedef unsigned __int64 size_t; 4 typedef __int64 ptrdiff_t; 5 typedef __int64 intptr_t; 6 #else 7 typedef unsigned int size_t; 8 typedef int ptrdiff_t; 9 typedef int intptr_t; 10 #endif

-
为复杂的声明定义一个新的简单的别名
在阅读代码的过程中,我们经常会遇到一些复杂的声明和定义,例如:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
|
如果想要定义和a同类型的变量a2,那么得重复书写:
void* (*(*a)(int))[10]; void* (*(*a2)(int))[10];
那怎么避免这种没有价值的重复呢?答案就是用typedef来简化复杂的声明和定义。
// 在之前的定义前边加typedef,然后将变量名a替换为类型名A typedef void* (*(*A)(int))[10]; // 定义相同类型的变量a和a2 A a, a2;
typedef在这里的用法,总结一下就是:任何声明变量的语句前面加上typedef之后,原来是变量的都变成一种类型。不管这个声明中的标识符号出现在中间还是最后。
1.1.2 使用typedef容易碰到的陷进
- 陷进一
typedef定义了一种类型的新别名,不同于宏,它不是简单的字符串替换。比如:
typedef char* PSTR; int mustrcmp(const PSTR, const PSTR);
上边的const PSTR并不是const char*,而是相当于.char* const。原因在于const给予了整个指针本身以常量性,也就是形成常量指针char* const。
- 陷进二
typedef在语法上是一个存储类的关键字(和auto、extern、mutable、static、register等一样),虽然它并不真正影响对象的存储特性。如:
typedef static int INT2;
编译会报错:“error C2159:指定了一个以上的存储类”。
1.2 #define
#define是宏定义指令,宏定义就是将一个标识符定义为一个字符串,在预编译阶段执行,将源程序中的标志符全部替换为指定的字符串。#define有以下几种常见用法:
- 无参宏定义
格式:#define 标识符 字符串
其中的“#”表示这是一条预处理命令。凡是以“#”开头的均为预处理命令。“define”为宏定义命令。“标识符”为所定义的宏名。“字符串”可以是常数、表达式、格式串等。
- 有参宏定义
格式:#define 宏名(形参表) 字符串

1 #define add(x, y) (x + y) //此处要打括号,不然执行2*add(x,y)会变成 2*x + y
2 int main()
3 {
4 std::cout << add(9, 12) << std::endl; // 输出21
5 return 0;
6 }

- 宏定义中的条件编译
在大规模开发过程中,头文件很容易发生嵌套包含,而#ifdef配合#define,#endif可以避免这个问题。作用类似于#pragma once。
#ifndef DATATYPE_H #define DATATYPE_H ... #endif
- 跨平台
在跨平台开发中,也常用到#define,可以在编译的时候通过#define来设置编译环境。

1 #ifdef WINDOWS 2 ... 3 (#else) 4 ... 5 #endif 6 #ifdef LINUX 7 ... 8 (#else) 9 ... 10 #endif

- 宏定义中的特殊操作符
#:对应变量字符串化
##:把宏定义名与宏定义代码序列中的标识符连接在一起,形成一个新的标识符
1 #include <stdio.h>
2 #define trace(x, format) printf(#x " = %" #format "\n", x)
3 #define trace2(i) trace(x##i, d)
4
5 int main(int argc, _TCHAR* argv[])
6 {
7 int i = 1;
8 char *s = "three";
9 float x = 2.0;
10
11 trace(i, d); // 相当于 printf("x = %d\n", x)
12 trace(x, f); // 相当于 printf("x = %f\n", x)
13 trace(s, s); // 相当于 printf("x = %s\n", x)
14
15 int x1 = 1, x2 = 2, x3 = 3;
16 trace2(1); // 相当于 trace(x1, d)
17 trace2(2); // 相当于 trace(x2, d)
18 trace2(3); // 相当于 trace(x3, d)
19
20 return 0;
21 }
22
23 // 输出:
24 // i = 1
25 // x = 2.000000
26 // s = three
27 // x1 = 1
28 // x2 = 2
29 // x3 =3

__VA_ARGS__:是一个可变参数的宏,这个可变参数的宏是新的C99规范中新增的,目前似乎只有gcc支持。实现思想就是宏定义中参数列表的最后一个参数为省略号(也就是三个点)。这样预定义宏__VA_ARGS__就可以被用在替换部分中,替换省略号所代表的字符串,如:

1 #define PR(...) printf(__VA_ARGS__)
2 int main()
3 {
4 int wt=1,sp=2;
5 PR("hello\n"); // 输出:hello
6 PR("weight = %d, shipping = %d",wt,sp); // 输出:weight = 1, shipping = 2
7 return 0;
8 }

附:C++中其他常用预处理指令:

#include // 包含一个源代码文件 #define // 定义宏 #undef // 取消已定义的宏 #if // 如果给定条件为真,则编译下面代码 #ifdef // 如果宏已定义,则编译下面代码 #ifndef // 如果宏没有定义,则编译下面代码 #elif // 如果前面#if给定条件不为真,当前条件为真,则编译下面代码 #endif // 结束一个#if...#else条件编译块 #error // 停止编译并显示错误信息 __FILE__ // 在预编译时会替换成当前的源文件cpp名 __LINE__ // 在预编译时会替换成当前的行号 __FUNCTION__ // 在预编译时会替换成当前的函数名称 __DATE__ // 进行预处理的日期(“Mmm dd yyyy”形式的字符串文字) __TIME__ // 源文件编译时间,格式为“hh:mm:ss”

1.3 typedef VS #define
C++为类型建立别名的方式有两种,一种是使用预处理器#define,一种是使用关键字typedef,格式如下:
#define BYTE char // 将Byte作为char的别名 typedef char byte;
但是在声明一系列变量是,请使用typedef而不是#define。比如要让byte_pointer作为char指针的别名,可将byte_pointer声明为char指针,然后再前面加上typedef:
typedef float* float_pointer;
也可以使用#define,但是在声明多个变量时,预处理器会将下边声明“FLOAT_POINTER pa, pb;”置换为:“float * pa, pb;”,这显然不是我们想要的结果。但是用typedef就不会有这样的问题。
#define FLOAT_POINTER float* FLOAT_POINTER pa, pb;
1.4 using
using关键字常见用法有三:
- 引入命名空间
using namespace std; // 也可在代码中直接使用std::
- 在子类中使用using引入基类成员名称
子类继承父类之后,在public、protected、private下使用“using 可访问的父类成员”,相当于子类在该修饰符下声明了该成员。
- 类型别名(C++11引入)
一般情况下,using与typedef作用等同:
// 使用using(C++11) using counter = long; // 使用typedef(C++03) // typedef long counter;
别名也适用于函数指针,但比等效的typedef更具可读性:

1 // 使用using(C++11)
2 using func = void(*)(int);
3
4 // 使用typedef(C++03)
5 // typedef void (*func)(int);
6
7 // func can be assigned to a function pointer value
8 void actual_function(int arg) { /* ... */ }
9 func fptr = &actual_function;
typedef的局限是它不适用于模板,但是using支持创建类型别名,例如:
template<typename T> using ptr = T*; // the name 'ptr<T>' is now an alias for pointer to T ptr<int> ptr_int;
1.5 typename
- 在模板参数列表中,用于指定类型参数。(作用同class)
template <class T1, class T2>... template <typename T1, typename T2>...
- 用在模板定义中,用于标识“嵌套依赖类型名(nested dependent type name)”,即告诉编译器未知标识符是一种类型。
这之前先解释几个概念:
> 依赖名称(dependent name):模板中依赖于模板参数的名称。
> 嵌套依赖名称(nested dependent name):从属名称嵌套在一个类里边。嵌套从属名称是需要用typename声明的。
template<class T> class X
{
typename T::Y m_y; // m_y依赖于模板参数T,所以m_y是依赖名称;m_y同时又嵌套在X类中,所以m_y又是嵌套依赖名称
};
上例中,m_y是嵌套依赖名称,需要typename来告诉编译器Y是一个类型名,而非变量或其他。否则在T成为已知之前,是没有办法知道T::Y到底是不是一个类型。
- typename可在模板声明或定义中的任何位置使用任何类型。不允许在基类列表中使用该关键字,除非将它用作模板基类的模板自变量。

1 template <class T>
2 class C1 : typename T::InnerType // Error - typename not allowed.
3 {};
4 template <class T>
5 class C2 : A<typename T::InnerType> // typename OK.
6 {};
1.6 template
C++提供了模板(template)编程的概念。所谓模板,实际上是建立一个通用函数或类,其类内部的类型和函数的形参类型不具体指定,用一个虚拟的类型来代表。这种通用的方式称为模板。模板是泛型编程的基础,泛型编程即以一种独立于任何特定类型的方式编写代码。
1.6.1 函数模板
函数模板是通用的函数描述,也就是说,它们使用泛型来定义函数,其中的泛型可用具体的类型(如int或double)替换。通过将类型作为参数传递给模板,可使编译器生成该类型的函数。由于模板允许以泛型方式编程,因此又被称为通用编程。由于类型用参数表示,因此模板特性也被称为参数化类型(parameterized types)。
请注意,模板并不创建任何函数,而只是告诉编译器如何定义函数。一般如果需要多个将同一种算法用于不同类型的函数,可使用模板。
(1)模板定义
template <typename T> // or template <class T>
void f(T a, T b)
{...}
在C++98添加关键字typename之前,用class来创建模板,二者在此作用相同。注意这里class只是表明T是一个通用的类型说明符,在使用模板时,将使用实际的类型替换它。
(2)显式具体化(explicit specialization)
- 对于给定的函数名,可以有非模板函数、模板函数和显示具体化模板函数以及他们的重载版本。
- 他们的优先级为:非模板 > 具体化 > 常规模板。
- 显示具体化的原型与定义应以template<>打头,并通过名称来指出类型。
举例如下:

1 #include <iostream>
2
3 // 常规模板
4 template <typename T>
5 void Swap(T &a, T &b);
6
7 struct job
8 {
9 char name[40];
10 double salary;
11 int floor;
12 };
13
14 // 显示具体化
15 template <> void Swap<job>(job &j1, job &j2);
16
17 int main()
18 {
19 using namespace std;
20 cout.precision(2); // 保留两位小数精度
21 cout.setf(ios::fixed, ios::floatfield); // fixed设置cout为定点输出格式;floatfield设置输出时按浮点格式,小数点后有6为数字
22
23 int i = 10, j = 20;
24 Swap(i, j); // 生成Swap的一个实例:void Swap(int &, int&)
25 cout << "i, j = " << i << ", " << j << ".\n";
26
27 job sxx = { "sxx", 200, 4 };
28 job xt = { "xt", 100, 3 };
29 Swap(sxx, xt); // void Swap(job &, job &)
30 cout << sxx.name << ": " << sxx.salary << " on floor " << sxx.floor << endl;
31 cout << xt.name << ": " << xt.salary << " on floor " << xt.floor << endl;
32
33 return 0;
34 }
35
36 // 通用版本,交换两个类型的内容,该类型可以是结构体
37 template <typename T>
38 void Swap(T &a, T &b)
39 {
40 T temp;
41 temp = a;
42 a = b;
43 b = temp;
44 }
45
46 // 显示具体化,仅仅交换job结构的salary和floor成员,而不交换name成员
47 template <> void Swap<job>(job &j1, job &j2)
48 {
49 double t1;
50 int t2;
51 t1 = j1.salary;
52 j1.salary = j2.salary;
53 j2.salary = t1;
54 t2 = j1.floor;
55 j1.floor = j2.floor;
56 j2.floor = t2;
57 }

(3)实例化和具体化
- 隐式实例化(implicit instantiation):编译器使用模板为特定类型生成函数定义时,得到的是模板实例。例如,上边例子第23行,函数调用Swap(i, j)导致编译器生成Swap()的一个实例,该实例使用int类型。模板并给函数定义,但使用int的模板实例就是函数定义。这种该实例化fangshi被称为隐式实例化。
- 显示实例化(explicit instantiation):可以直接命令编译器创建特定的实例。语法规则是,声明所需的种类(用<>符号指示类型),并在声明前加上关键字template:
template void Swap<int>(int, int); // 该声明的意思是“使用Swap()模板生成int类型的函数定义”
- 显示具体化(explicit specialization):前边以介绍,显示具体化使用下面两个等价的声明之一:
// 该声明意思是:“不要使用Swap()模板来生成函数定义,而应使用专门为int类型显示定义的函数定义” template <> void Swap<int>(int &, int &); template <> void Swap(int &, int &);
注意:显示具体化的原型必须有自己的函数定义。
以上三种统称为具体化(specialization)。下边的代码总结了上边这些概念:

1 template <class T>
2 void Swap(T &, T &); // 模板原型
3
4 template <> void Swap<job>(job &, job &); // 显示具体化
5 template void Swap<char>(char &, char &); // 显式实例化
6
7 int main(void)
8 {
9 short a, b;
10 Swap(a, b); // 隐式实例化
11
12 job n, m;
13 Swap(n, m); // 使用显示具体化
14
15 char g, h;
16 Swap(g, h); // 使用显式模板实例化
17 }

编译器会根据Swap()调用中实际使用的E参数,生成相应的版本。
当编译器看到函数调用Swap(a, b)后,将生成Swap()的short版本,因为两个参数都是short。当编译器看到Swap(n, m)后,将使用为job类型提供的独立定义(显示具体化)。当编译器看到Swap(g, h)后,将使用处理显式实例化时生成的模板具体化。
(4)关键字decltype(C++11)
- 在编写模板函数时,并非总能知道应在声明中使用哪种类型,这种情况下可以使用decltype关键字:
template <class T1, Class T2> void ft(T1 x, T2 y) { decltype(x + y) xpy = x + y; // decltype使得xpy和x+y具有相同的类型 }
- 有的时候我们也不知道模板函数的返回类型,这种情况下显然是不能使用decltype(x+y)来获取返回类型,因为此时参数x和y还未声明。为此,C++新增了一种声明和定义函数的语法:
// 原型 double h(int x, float y); // 新增的语法 auto h(int x, float y) -> double;
该语法将返回参数移到了参数声明的后面。->double被称为后置返回类型(trailing return type)。其中auto是一个占位符,表示后置返回类型提供的类型。
所以在不知道模板函数的返回类型时,可使用这种语法:
template <class T1, Class T2>
auto ft(T1 x, T2 y) -> decltype(x + y)
{
return x + y;
}
1.6.2 类模板
(1)类模板定义和使用

1 // 类模板定义
2 template <typename T> // or template <class T>
3 class A
4 {...}
5
6 // 实例化
7 A<t> st; // 用具体类型t替换泛型标识符(或者称为类型参数)T

程序中仅包含模板并不能生成模板类,必须要请求实例化。为此,需要声明一个类型为模板类对象,方法是使用所需的具体类型替换泛型名。比如用来处理string对象的栈类,就是basic_string类模板的具体实现。
应注意:类模板必须显示地提供所需的类型;而常规函数模板则不需要,因为编译器可以根据函数的参数类型来确定要生成哪种函数。
(2)模板的具体化
类模板与函数模板很相似,也有隐式实例化、显示实例化和显示具体化,统称为具体化(specialization)。模板以泛型的方式描述类,而具体化是使用具体的类型生成类声明。
- 隐式实例化:声明一个或多个对象,指出所需的类型,而编译器使用通用模板提供的处方生成具体的类定义。需要注意的是,编译器在需要对象之前,不会生成类的隐式实例化。
- 显示实例化:使用关键字template并指出所需类型来声明类时,编译器将生成类声明的显示实例化。
1 // 类模板定义 2 template <class T, int n> 3 class ArrayTP 4 {...}; 5 6 // 隐式实例化(生成具体的类定义) 7 ArrayTP<int, 100> stuff 8 9 // 显示实例化(将ArrayTP<string, 100>声明为一个类) 10 template class ArrayTP<string, 100>;


- 显示具体化:是特定类型(用于替换模板中的泛型)的定义。
- 部分具体化(partial specializaiton):即部分限制模板的通用性。
第一:部分具体化可以给类型参数之一指定具体的类型:

1 // 通用模板
2 template <typename T1, typename T2> class Pair {...};
3 // 部分具体化模板(T1不变,T2具体化为int)
4 template <typename T1> class Pair<T1, int> {...};
5 // 显示具体化(T1和T2都具体化为int)
6 template <> calss Pair<int, int> {...};

如果有多种模板可供选择,编译器会使用具体化程度最高的模板(显示 > 部分 > 通用),比如对上边三种模板进行实例化:
Pair<double, double> p1; // 使用通用模板进行实例化 Pair<double, int> p2; // 使用Pair<T1, int>部分具体化模板进行实例化 Pair<int, int> p3; // 使用Pair<T1, T2>显式具体化模板进行实例化
第二:也可以通过为指针提供特殊版本来部分具体化现有的模板:
// 通用模板
template <typename T> class Feeb {...};
// 指针部分具体化模板
template <typename T*> class Feeb {...};
编译器会根据提供的类型是不是指针来选择使用通用模板或者指针具体化模板:
Feeb<char> fb1; // 使用通用模板,T为char类型 Feeb<char *> fb2; // 使用Feeb T*具体化,T为char类型
上述第二个声明使用具体化模板,将T转换为char类型;如果使用的是通用模板,则是将T转换为char*类型。
(3)成员模板
模板可作为结构、类或模板类的成员。下边示例是将另一个模板类和模板函数作为该模板类的成员:
1 #include <iostream>
2 using std::cout;
3 using std::endl;
4
5 template <typename T>
6 class beta
7 {
8 private:
9 template <typename V> // 嵌套的模板类成员(只能在beta类中访问)
10 class hold
11 {
12 private:
13 V val;
14 public:
15 hold(V v = 0) :val(v) {}
16 void show() const { cout << val << endl; }
17 V value() const { return val; }
18 };
19 // beta类使用hold模板声明两个数据成员
20 hold<T> q; // q是基于T类型(beta模板参数)的hold对象
21 hold<int> n; // n是基于int的hold对象
22 public:
23 beta(T t, int i) :q(t), n(i) {}
24 template <typename U> // 模板方法
25 U blab(U u, T t) { return (n.value() + q.value()) * u / t; }
26 void Show() const { (q.show(); n.show(); }
27 };
28
29 int main()
30 {
31 beta<double> guy(3.5, 3);
32 cout << "T was set to double\n";
33 guy.Show();
34 cout << "V was set to T, which id double, then V was set to int\n";
35 cout << guy.blab(10, 2.3) << endl;
36 cout << "U was set to int\n";
37 cout << guy.blab(10.0, 2.3) << endl;
38 cout << "U was set to double\n";
39 cout << "Done\n";
40 return 0;
41 }

(4)将模板用作参数
模板可以包含类型参数(如typename T)和非类型参数(如int n),还可以包含本身就是模板的参数。格式如下:
template <template <typename T> class Type> class B
模板参数为template <typename T> classType,其中emplate <typename T> class是类型,Type是参数。
示例如下:
1 #include <iostream>
2 #include "stacktp.h"
3 template <template <typename T> class Thing>
4 class Crab
5 {
6 private:
7 Thing<int> s1;
8 Thing<double> s2;
9 public:
10 Crab() {};
11 // 假设pop()和push()是Thing类的成员函数
12 bool push(int a, double x) { return s1.push(a) && s2.push(x); }
13 bool pop(int& a, double& x) { return s1.pop(a) && s2.pop(x); }
14 };
15
16 int main()
17 {
18 using std::cout;
19 using std::cin;
20 using std::endl;
21
22 Crab<Stack> nebula;
23 int ni;
24 double nb;
25 while (cin >> ni >> nb && ni > 0 && nb > 0)
26 {
27 if (!nebula.push(ni, nb))
28 break;
29 }
30 while (nebula.pop(ni, nb))
31 cout << ni << ", " << nb << endl;
32 cout << "Done.\n";
33 return 0;
34 }

1.7 迭代器
模板和迭代器都是STL通用方法的重要组成部分,模板使算法独立于存储的数据类型,而迭代器使算法独立于使用的容器类型。
迭代器是一个对象,可以循环C++标准库容器中的元素,并提供对单个元素的访问。C++标准库容器全都提供有迭代器,因此算法可以采用标准方式访问元素,而不必考虑用于存储元素的容器类型。简言之,迭代器就是为访问容器所提供的STL通用算法的统一接口,每个容器类都定义了相应的迭代器类型,通过迭代器就能够实现对容器中的元素进行访问和操作。
可以使用成员和全局函数(例如begin()和end())显式使用迭代器,例如 ++ 和 -- 分别用于向前和向后移动。 还可以将迭代器隐式用于范围 for 循环或 (某些迭代器类型) 下标运算符 []。
在 C++ 标准库中,序列或范围的开头是第一个元素。 序列或范围的末尾始终定义为最后一个元素的下一个位置。 全局函数begin和end将迭代器返回到指定的容器。 典型的显式迭代器循环访问容器中的所有元素,如下所示:

vector<int> vec{ 0,1,2,3,4 };
for (auto it = begin(vec); it != end(vec); it++)
{
// 使用解除引用运算符访问元素
cout << *it << " ";
}

也可使用C++11新增的基于范围的for循环完成相同操作:
for (auto num : vec)
{
// 不使用解除引用运算符
cout << num << " ";
}
STL中定义了5种类型的迭代器:输入迭代器、输出迭代器、正向迭代器、双向迭代器和随机访问迭代器。
1.8 内联函数
内联函数是C++为提高程序运行速度所做的一项改进。常规函数和内联函数之间的主要区别不在于编写方式,而在于C++编译器如何将它们组合到程序中。
我们先来详细看下常规函数的调用过程:
- 执行到函数调用指令时,程序将在函数调用后立即存储该指令的内存地址,并将函数参数复制到堆栈(为此保留的内存块),跳到标记函数起点的内存单元,执行函数代码(也许还需将返回值放入到寄存器中),然后跳回到地址被保存的指令处。
内联函数的编译代码与其他程序代码“内联”起来了,即编译器将使用相应的函数代码替换函数调用。对于内联代码,程序无需跳到另一个位置处执行代码,再跳回来。因此,内联函数运行速度比常规函数稍快,但代价是需要占用更多的内存。所以要权衡实际情况再选择是否使用内联函数。
下图很直观的给出了内联函数与常规函数的区别:
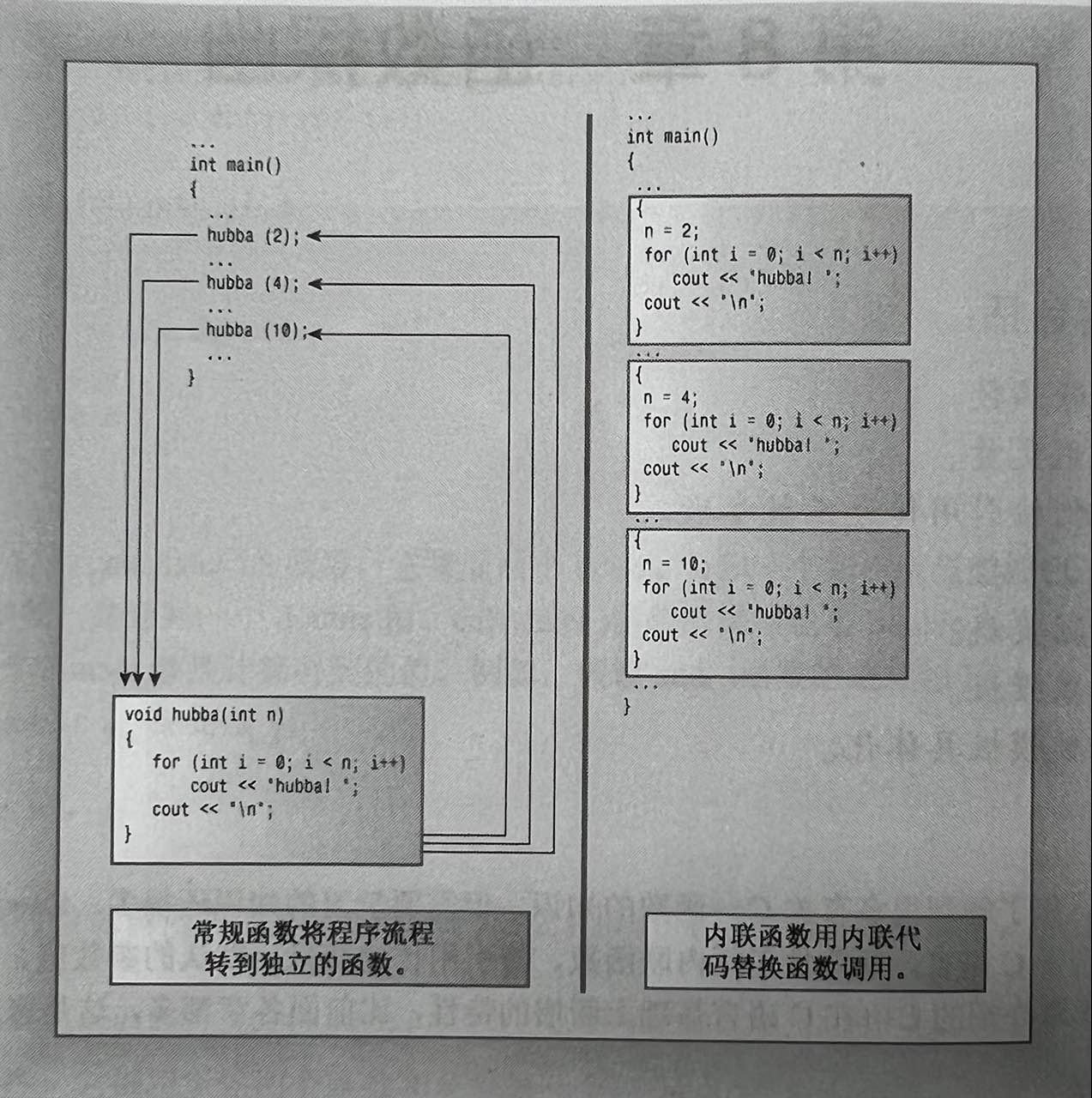
内联函数使用方式很简单,只需要在函数声明和函数定义前加上inline关键字即可。使用内联函数需要注意以下几点:
- 内联函数会增大内存占用,但是不需要承担函数调用时的压栈、跳转、返回的时间和资源开销,所以短小的函数代码片段(尽量不要超过10行)建议使用内联。
- 谨慎对待析构函数,析构函数往往比其表面看起来更长,因为有隐含的成员和基类析构函数被调用。
- 避免将递归函数声明为内联函数。递归调用堆栈的展开并不像循环那么简单,比如递归层数在编译时可能是未知的。
- 内联inline关键字是对编译器采用内联编译的请求,编译器有可能拒绝或忽略(此时就会当成普通函数编译)。
- 有些情况下即便没有inline关键字,但编译器也会视情况采用内联(优化)编译。
内联与宏
内联函数是将语句封装成函数,而宏定义替换只是文本替换,没有经历系统完整的运算规则的规划,有一定异变性。比如:
#define SQUARE(X) X*X a = SQUARE(2 + 3) // 相当于 a = 2 + 3 * 2 + 3
1.9 运算符重载
运算符重载是一种形式的C++多态。我们可以定义多个函数名相同但特征标(参数列表)不同的函数,称之为函数重载(或函数多态)。运算符重载将重载的概念扩展到运算符上,允许赋予C++运算符更多的含义。
重载运算符需要使用运算符函数,格式如下:
operatorop(argument-list)
其中:op代表运算符,且必须是有效的C++运算符。例如,operator+()表示重载+运算符,operator*()表示重载*运算符。
那具体应该怎么在程序中使用呢?我们来结合下边的例子进行说明:

1 class Time
2 {
3 private:
4 int hours;
5 int minutes;
6 public:
7 Time();
8 Time(int h, int m = 0);
9 void AddMin(int m);
10 void AddHr(int h);
11 void Reset(int h = 0, int m = 0);
12 Time Sum(const Time& t) const; // Sum函数
13 Time operator+ (const Time & t) const; // 使用重载的加法运算符
14 void Show() const;
15 };
16
17 Time::Time()
18 {
19 hours = minutes = 0;
20 }
21
22 Time::Time(int h, int m)
23 {
24 hours = h;
25 minutes = m;
26 }
27
28 void Time::AddMin(int m)
29 {
30 minutes += m;
31 hours += minutes / 60;
32 minutes %= 60;
33 }
34
35 void Time::AddHr(int h)
36 {
37 hours += h;
38 }
39
40 void Time::Reset(int h, int m)
41 {
42 hours = h;
43 minutes = m;
44 }
45
46 // 注意:不要返回指向局部变量或临时对象的引用。函数执行完毕后,局部变量和临时对象将消失,引用将指向不存在的数据。
47 Time Time::Sum(const Time& t) const
48 {
49 Time sum;
50 sum.minutes = minutes + t.minutes;
51 sum.hours = hours + t.hours + t.minutes / 60;
52 sum.minutes %= 60;
53 return sum;
54 }
55
56 Time Time::operator+(const Time& t) const
57 {
58 Time sum;
59 sum.minutes = minutes + t.minutes;
60 sum.hours = hours + t.hours + t.minutes / 60;
61 sum.minutes %= 60;
62 return sum;
63 }
64
65 void Time::Show() const
66 {
67 std::cout << hours << " hours, " << minutes << " minutes";
68 }
69
70 int main()
71 {
72 using std::cout;
73 using std::endl;
74 Time planning;
75 Time coding(2, 40);
76 Time fixing(5, 55);
77 Time total;
78
79 cout << "planning time = ";
80 planning.Show();
81 cout << endl;
82
83 cout << "coding time = ";
84 coding.Show();
85 cout << endl;
86
87 cout << "fixing time = ";
88 fixing.Show();
89 cout << endl;
90
91 // Sum函数
92 total = coding.Sum(fixing);
93 cout << "coding.sum(fixing) = ";
94 total.Show();
95 cout << endl;
96
97 // 使用重载运算符
98 total = coding + fixing; // 与下一句代码等效
99 total = coding.operator+(fixing);
100 cout << "coding + fixing = ";
101 total.Show();
102 cout << endl;
103
104 return 0;
105 }
同Sum()一样,opertor+()也是由Time对象调用的,它将第二个Time对象作为参数,并返回一个Time对象。调用operator+()可使用以下两种等效的方式:
total = coding + fixing; total = coding.operator+(fixing);
operator+()函数的名称使得可以使用函数表示法或运算符表示法来调用它。需要注意的是,在运算符表示法中,运算符左侧的对象是调用对象,运算符右边的对象是作为参数被传递的对象。
重载限制
(1)重载后的运算符必须至有一个操作数是用户定义的类型,这将防止用户为标准类型重载运算符。比如不能将减法运算符(-)重载为两个double类型的和。
(2)使用运算符时不能违反运算符原来的句法规则。也不能修改运算符的优先级。
(3)不能创建新的运算符,例如,不能定义ooperator**()函数来表示求幂。
(4)不能重载下面的运算符:
| sizeof | sizeof运算符 |
| . | 成员运算符 |
| .* | 成员指针运算符 |
| :: | 作用域解析运算符 |
| ?: | 条件运算符 |
| # | 预处理命令:转换为字符串 |
| ## | 预处理命令:拼接 |
| typeid | 一个RTTI运算符 |
| const_cast | 强制类型转换运算符 |
| dynamic_cast | 强制类型转换运算符 |
| reinterpret_cast | 强制类型转换运算符 |
| static_cast | 强制类型转换运算符 |
(5)下边运算符只能通过成员函数进行重载
| = | 赋值运算符 |
| () | 函数调用运算符 |
| [] | 下标运算符 |
| -> | 函数指针访问类成员的运算符 |
附:可重载的运算符:
| + | - | * | / | % | ^ |
| & | | | ~= | ! | = | < |
| > | += | -= | *= | /= | %= |
| ^= | &= | |= | << | >> | >>= |
| <<= | == | != | <= | >= | && |
| || | ++ | -- | , | ->* | -> |
| () | [] | new | delete | new[] | delete[] |
->* 和 -> 用法示例:

1 void (Test::*pfunc)() = &Test::func; 2 Test t1; 3 Test* t2 = new Test(); 4 5 t1.func(); // 正常调用类成员方法 6 (t1.*pfunc)(); // 通过函数指针调用类成员方法 7 8 t2->func(); // 正常调用类成员方法 9 (t2->*pfunc)(); // 通过函数指针调用类成员方法

1.10 友元
通常我们只能通过公有类方法来访问类对象的私有部分,这种限制有时显得过于严格,以致不适合特定的编程问题。C++提供了另一种形式的访问权限:友元。友元有三种:友元函数、友元类和友元成员函数,通过让他们成为类的友元,可以赋予他们与类的成员函数相同的访问权限。
哪些函数、成员函数或类为友元是由类定义的,所以尽管友元被授予从外部访问类的私有部分的权限,但它们并不与OOP的思想相悖。友元声明可以位于公有、私有或保护部分,其所在的位置无关紧要。
1.10.1 友元函数
友元函数是提供特殊访问特权的常规外部函数,它不是类的成员,但是其访问权限与成员函数相同,有权访问该类的私有成员和受保护成员。

1 #include <iostream>
2
3 using namespace std;
4 class Point
5 {
6 friend void ChangePrivate(Point&);
7 public:
8 Point(void) : m_i(0) {} // 构造函数成员初始化列表
9 void PrintPrivate(void) { cout << m_i << endl; }
10
11 private:
12 int m_i;
13 };
14
15 void ChangePrivate(Point& i) { i.m_i++; }
16
17 int main()
18 {
19 Point sPoint;
20 sPoint.PrintPrivate();
21 ChangePrivate(sPoint);
22 sPoint.PrintPrivate();
23 // Output: 0
24 // 1
25 }

1.10.2 友元类
将类作为友元,那么友元类的所有方法都可以访问原始类的私有成员和保护成员。用法和友元函数类似,不多做介绍。
1.10.3 友元成员函数
很多时候,并不是友元类中所有的成员都需要访问原始类的私有成员或受保护成员。这种情况下可以将类的成员声明为原始类的友元。比如:

1 Class Tv; // 前向声明,避免循环依赖
2
3 class Remote
4 {
5 public:
6 void set_chan(Tv & t, int c) {t.channel = c;} // 内联函数
7 ...
8 };
9
10 Class Tv
11 {
12 private:
13 int channel;
14 public:
15 friend void Remote::set_chan(Tv & t, int c);
16 ...
17 };
注:上例中,Tv中包含了Remote的定义,这意味着Remot要定义在Tv之前;Remote的方法也提到了Tv对象,这意味着Tv要定义在Remote之前。为了避开这种循环依赖,可以在Remote定义之前加上 “class Tv;” 作为前向声明(forward declaration)。
1.10.4 彼此互为友元
有的时候,会要求A类和B类能够进行交互,即A类的某些方法能够影响B类的对象,B类的某些方法也能影响A类的对象。这可以让类彼此称为对方的友元来实现,示例如下:

1 Class Tv
2 {
3 friend class Remote;
4 public:
5 void buzz(Remote & r);
6 ...
7 };
8
9 class Remote
10 {
11 friend class Tv;
12 public:
13 void Bool volup(Tv & t) { t.volup(); }
14 ...
15 };
16
17 inline void Tv::buzz(Remote & r)
18 {
19 ...
20 }

1.10.5 共同的友元
存在另一种情况,函数需要访问两个(或多个)类的私有数据。逻辑上来讲,该函数应该是两个(或多个)类的成员函数,显然这是不可能的。此时比较合理的方式就是将该函数作为两个(或多个)类的友元。示例如下:

1 class B; // 前向声明(forward declaration)
2 class A
3 {
4 friend void sync(B& a, const A& p); // sync a to p
5 friend void sync(A& P, const B& a); // sync p to a
6 };
7 class B
8 {
9 friend void sync(B& a, const A& p); // sync a to p
10 friend void sync(A& P, const B& a); // sync p to a
11 };
12
13 // 友元函数定义
14 inline void sync(B& a, const A& p)
15 {
16 ...
17 }
18 inline void sync(A& P, const B& a)
19 {
20 ...
21 }

1.10.6 使用友元需注意的几点
- 友元类的关系是单向的。除非明确指定,否则友元不是相互的。
- 在C++/CLI中,托管类不能有任何友元函数、友元类或者友元接口。
- 友元不能是虚函数,因为友元不是类成员,而只有成员才能是虚函数。
- 友元是不能继承的,比如B是A的友元类,C又是B的友元类,意味着B可以访问A的私有成员,且C可以访问B的私有成员,但是C却没有权限访问A的私有成员。引用官方文档里边的一张图:
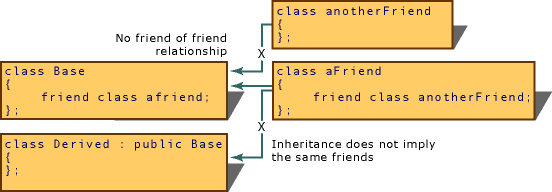
图中有四种类声明:Base,Derived,aFriend、anotherFriend。仅有aFriend类能够直接访问Base类(以及Base可能已继承的所有成员)的私有成员。
2. char类型:字符和小整数
char类型是整形的一种。用来处理字符和比short更小的整形。ASCII码共128个字符,用char类型表示完全足够,而像Unicode这种大型字符集,C++也支持用宽字符类型wchar_t来表示。
2.1 成员函数cout.put()
cout是ostream类的特定对象,put()是ostream的成员函数。只能通过类的特定对象来使用成员函数,所以cout.put()表示通过类对象cout来使用函数oput(),其中句点“.”称为成员运算符。
cout.put() 提供了一种显示字符的方法,可以替代<<运算符。char类型和cout.put()用法示例如下:

1 #include <iostream>
2
3 int main()
4 {
5 using namespace std;
6 char ch = 'M';
7 int i = ch;
8 cout << "The ASCII code for " << ch << " is " << i << endl;
9
10 ch += 1;
11 i = ch;
12 cout << "The ASCII code for " << ch << " is " << i << endl;
13
14 cout << "Displaying char ch using cout.put(ch): ";
15 cout.put(ch);
16
17 cout.put('!');
18 return 0;
19 }

输出:

2.2 char字面值
将字符用单引号''括起来。比如'A'表示65,即字符A的ASCII码。
转义字符:
| 字符名称 | ASCII符号 | C++代码 | 十进制ASCII码 | 十六进制ASCII码 |
| 换行符 | NL(LF) | \n | 10 | 0xA |
| 水平制表符 | HT | \t | 9 | 0x9 |
| 垂直制表符 | VT | \v | 11 | 0xB |
| 退格 | BS | \b | 8 | 0c8 |
| 回车 | CR | \r | 13 | 0xD |
| 振铃 | BEL | \a | 7 | 0x7 |
| 反斜杠 | \ | \\ | 92 | 0x5C |
| 问号 | ? | \? | 63 | 0x3F |
| 单引号 | ' | \' | 39 | 0x27 |
| 双引号 | " | \" | 34 | 0x22 |
转义字符作为字符常量时,应用单引号括起来;将它们放在字符串中时,不要使用单引号。
换行符可代替endl,下边三行代码都起到换行作用:
cout << endl; cout << '\n'; cout << "\n"; // 相当于'\n'在字符串中,不需要加单引号
2.3 signed char和unsigned char
char在默认情况下既不是有符号,也不是无符号,是否有符号由C++实现决定。signed char表示范围为-128~127,unsigned char表示范围为0~255。
2.4 wchar_t
像汉字日文等,无法用一个8位的字节l来表示,这种情况,C++一般有两种处理方式:
(1)将char定义为一个16位或者更长的字节;
(2)用8位的char来表示基本字符集,另外使用wchar_t(宽字符类型)表示扩展字符集。wchar_t流的输入输出工具为wcin和wcout。可通过加前缀L来指示宽字符常量和宽字符串。
wchar_t blb = L'P' wcout << L"tall" << endl;
2.5 char16_t和char32_t(C++11新增)
char16_T和char32_t都是无符号的,前者长16位,后者长32位。通常使用前缀u表示char16_t字符常量和字符串常量;用前缀U表示char32_t字符常量和字符串常量。
3. 模板类string
至此,string类中涉及到的一些C++基础知识也介绍的差不多了,接下来我们就来看看string类到底是如何设计的。
3.1 string类设计原理
- 第一步:basic_string模板类的定义(该模板类中还定义了的一些类型、迭代器和静态常量,便于后续定义方法,以及将STL的算法用于字符串)

1 #define _STD ::std::
2
3 template <class _Elem, // _Elem是存储在字符串中的类型
4 class _Traits = char_traits<_Elem>, // _Traits参数是一个类,定义了类型要被表示为字符串时,所必须具备的特征
5 class _Alloc = allocator<_Elem>> // _Alloc是用于处理字符串内存分配的类
6 class basic_string
7 { // null-terminated transparent array of elements
8 private:
9 friend _Tidy_deallocate_guard<basic_string>;
10 friend basic_stringbuf<_Elem, _Traits, _Alloc>;
11
12 using _Alty = _Rebind_alloc_t<_Alloc, _Elem>;
13 using _Alty_traits = allocator_traits<_Alty>;
14
15 ...
16
17 public:
18 // using源于C++11,等价于C++98的typedef,比如下边第一行代码相当于:typedef _Traits traits_type;
19 using traits_type = _Traits; // _Traits是对应于特定类型(如char_traits<char>)的模板参数
20 using allocator_type = _Alloc;
21
22 using value_type = _Elem;
23 using size_type = typename _Alty_traits::size_type; // 根据存储的类型返回字符串的长度(无符号类型)
24 using difference_type = typename _Alty_traits::difference_type; // 用于度量字符串中两个元素之间的距离(size_type有符号版本)
25 using pointer = typename _Alty_traits::pointer; // 对于char具体化,pointer类型为char *,与基本指针有着相同的特征
26 using const_pointer = typename _Alty_traits::const_pointer;
27 using reference = value_type&; // 对于char具体化,reference类型为char &,与基本引用有着相同的特征
28 using const_reference = const value_type&;
29
30 using iterator = _String_iterator<_Scary_val>; // 迭代器类型
31 using const_iterator = _String_const_iterator<_Scary_val>;
32
33 using reverse_iterator = _STD reverse_iterator<iterator>;
34 using const_reverse_iterator = _STD reverse_iterator<const_iterator>;
35
36 ...
37
38 // 静态常量npos,size_type是无符号的,因此将-1赋给npos相当于将最大的无符号值赋给它,这个值比可能的最大数组索引大1
39 static constexpr auto npos{ static_cast<size_type>(-1) };
40 };

上边定义中用到了另外两个模板类char_traits和allocator,前者又称字符特性模板类,提供最基本的字符特性的统一的方法函数;后者是C++标准库容器都具有一个默认的模板参数,通过使用自定义分配器构造容器可控制该容器的元素的分配和释放。
- 第二步:basic_string类模板的具体化(string类的由来)
即编译器根据所需的类型,使用basic_string类模板提供的处方生成具体的类定义,我们常用的string类便是这么来的。可以看到,basic_string类模板在具体化的过程中还使用了char_traits类模板和allocator类模板的具体化。而就具体化种类(隐式实例化、显示实例化、显示具体化)而言,这里的具体化应属于隐式实例化。string类就相当于basic_string类模板关于char类型的隐式实例化。
using string = basic_string<char, char_traits<char>, allocator<char>>; using wstring = basic_string<wchar_t, char_traits<wchar_t>, allocator<wchar_t>>; using u16string = basic_string<char16_t, char_traits<char16_t>, allocator<char16_t>>; using u32string = basic_string<char32_t, char_traits<char32_t>, allocator<char32_t>>;
- 第三步:string类的使用
string本质上就是basic_string类的char版本,basic_string怎么用string就怎么用。
3.2 string类的构造函数(ctor)
string实际上是模板具体化basic_string<char>的一个typedef,同时省略了与内存管理相关的参数。
| 构造函数 | 描 述 |
| string(const char * s) | 将string对象初始化为s指向的NBTS。NBTS(null-terminated string)表示以空字符结束的字符串——传统的C字符串。 |
| string(size_type n, char c) | 创建一个包含n个元素的string对象,其中每个元素都被初始化为字符c。size_type是一个依赖于实现的整形,在string中定义。 |
| string(const string & str) | 将一个string对象初始化为string对象str(复制构造函数)。 |
| string() | 创建一个默认的string对象,长度为0(默认构造函数)。 |
| string(const char * s, size_type n) | 将string对象初始化为s指向的NBTS的前n个字符,即使超过了NBTS结尾。 |
| template<class Iter> string(Iter begin, Iter end) | 将string对象初始化为区间[begin, end)内的字符,其中begin和end的行为就像指针,用于指定位置,范围包括begin,但不包括end。 |
| string(const string & str, string size_type pos = 0, suze_type n = npos) | 将一个string对象初始化为对象str中从位置pos开始到结尾的字符,或从位置pos开始的n个字符。string类将string::npos定义为字符串的最大长度,通常为 unsigned int 的最大值。 |
| string(string && str) noexcept | C++11新增,将一个string对象初始化为string对象str,并可能修改str(移动构造函数)。 |
| string(initializer_list<char> il) | C++11新增,将一个string对象初始化为初始化列表il中的字符。 |
构造函数用法示例如下:

1 #include <string>
2 #include <iostream>
3
4 int main()
5 {
6 using namespace std;
7
8 string one("SXX Winner!"); // ctor 1,将string对象one初始化为常规的C-风格字符串
9 cout << one << endl;
10
11 string two(20, '$'); // ctor 2,将string对象two初始化为由20个$字符组成的字符串
12 cout << two << endl;
13
14 string three(one); // ctor 3,复制构造函数将string对象three初始化为one
15 cout << three << endl;
16
17 one += " Oops!";
18 cout << one << endl;
19
20 two = "Sorry! That was ";
21 three[0] = 'Y';
22 string four; // ctor 4,默认构造函数创建一个以后可以对其进行赋值的空字符串
23 four = two + three;
24 cout << four << endl;
25
26 char alls[] = "All's well that ends well";
27 string five(alls, 20); // ctor 5, 将five初始化为alls的前20个字符
28 cout << five << "!\n";
29
30 string six(alls + 6, alls + 10);
31 cout << six << ", "; // ctor 6,将string对象six初始化为区间[6,10)内的字符
32
33 string seven(&five[6], &five[10]); // ctor 6, five[6]是一个char值,&five[6]是地址
34 cout << seven << "...\n";
35
36 string eight(four, 7, 16); // ctor 7, 将对象four的部分内容复制到构造的对象中
37 cout << eight << " in motion!" << endl;
38
39 return 0;
40 }
对于ctor 5,当n超过了C-风格字符串的长度,仍将复制请求数目的字符。比如上边的例子中,如果用40代替20,将导致15个无用字符被复制到five的结尾处(即构造函数将内存中位于字符串“All's well that ends well”后面的内容作为字符)。
第33行代码如果写成 string seven(five + 6, five + 10) 是没有意义的,对象名(不同于数组名)不会被看作是对象的地址,因此five不是指针,five + 6也没有意义;而five[6]是一个char值,所以&five[6]是地址。
3.3 string类常用成员函数
| 方 法 | 返 回 值 |
| begin() | 指向字符串第一个字符的迭代器(如下图示) |
| cbegin() | 一个const_iterator,指向字符串的第一个字符(C++11),作用和begin()类似,不同之处在于begin()可改元素值,cbegin()不可改 |
| end() | 超尾值的迭代器,注意它返回的不是指向字符串最后一个字符的迭代器,而是指向字符串最后一个字符的下一位置(称为超尾值)的迭代器 |
| cend() | 为超尾值的const_iterator(C++11) |
| rbegin() | 超尾值的反转迭代器,即指向字符串最后一个字符的迭代器 |
| crbegin() | 为超尾值的反转const_iterator(C++11) |
| rend() | 指向第一个字符的反转迭代器,也就是指向第一个字符的前一位置的迭代器 |
| crend() | 指向第一个字符的反转const_iterator(C++11) |
| size() | 字符串中的元素数,等于begin()到end()之间的距离 |
| length() | 同size()。length()成员来自较早版本的string类,而size()则是为提供STL兼容性而添加的 |
| capacity() | 给字符串分配的元素数。这可能大于实际的字符数,capacity() - size()的值表示在字符串末尾附加多少字符后需要分配更多的内存 |
| reverse() | 为字符串请求内存块,分配空间。很多C++实现分配一个比实际字符串大的内存块,为字符串提供增大空间。如果字符串不断增大,超过了分配给它的内存块大小,程序将分配一个大小为原来两倍的新内存块,以提供足够的增大空间,避免不断地分配新的内存块而导致的效率低下。 |
| max_size() | 字符串的最大长度 |
| data() | 一个指向数组第一个元素的const charT*指针,其第一个size()元素等于*this控制的字符串中对应的元素,其下一个元素为charT类型的charT(0)字符(字符串末尾标记)。当string对象本身被修改后,该指针可能无效 |
| c_str() | 一个指向数组第一个元素的const charT*指针,其第一个size()元素等于*this控制的字符串中对应的元素,其下一个元素为charT类型的charT(0)字符(字符串尾标记)。当string对象本身被修改后,该指针可能无效 |
| get_allocator() | 用于为字符串object分配内存的allocator对象的副本 |

有些方法用来处理内存,如清除内存的内容,调整字符串长度和容量。
| 方 法 | 作 用 |
| void resize(size_type n) | 如果n>npos,将引发out_of_range异常;否则,将字符串的长度改为n,如果n<size(),则截短字符串,如果n>size(),则使用charT(0)中的字符填充字符串 |
| void resize(size_type n, charT c) | 如果n>npos,将引发out_of_range异常;否则,将字符串的长度改为n,如果n<size(),则截短字符串,如果n>size(),则使用字符c填充字符串 |
| void reverse(size_type res_arg = 0) | 将capacity()设置为大于或等于res_arg。由于这将重新分配字符串,因此以前的引用、迭代器和指针将无效。 |
| void shrink_to_fit() | 请求让capacity()的值和size()相同(C++11新增) |
| void clear() noexcept | 删除字符串中所有的字符 |
| bool empty() const noexcept | 如果size()==0,则返回true |
3.4 字符串存取
有4种方法可以访问各个字符,其中两种使用[]运算法,另外两种使用at()方法:
1 // 能够使用数组表示法来访问字符串的元素,可用于检索或更改值 2 reference operator[](size_type pos); 3 // 可用于const对象,但只能用来检索值 4 const_reference operator[](size_type pos) const; 5 // 功能同第一句代码,索引通过函数参数提供 6 reference at(size_type n); 7 // 功能同第二句代码,索引通过函数参数提供 8 const_reference at(size_type n) const;
at()方法执行边界检查,超界会引发out_of_range异常。operator[]()方法不进行边界检查。因此,可以根据安全性(使用at()检测异常)和执行速度(使用数组表示)选择合适的方法。
3.5 字符串搜索
string类提供6种搜索函数,每个函数都有4个原型(重载)
(1)find():用于在字符串中搜索给定的子字符串或字符。有4种重载的find()方法:
- size_type find(const string & str, size_type pos = 0) const noexcept:从字符串的pos位置开始,查找子字符串str。如果找到,则返回该子字符串首次出现时其首字符的索引;否则,返回string:npos
- size_type find(const char * s, size_type pos = 0) const :从字符串的pos位置开始,查找子字符串s。如果找到,则返回该子字符串首次出现时其首字符的索引;否则,返回string:npos
- size_type find(const char * s, size_type pos = 0, size_type n) const :从字符串的pos位置开始,查找s的前n个字符组成的子字符串。如果找到,则返回该子字符串首次出现时其首字符的索引;否则,返回string:npos
- size_type find(char ch, size_type pos = 0) const :从字符串的pos位置开始,查找字符ch。如果找到,则返回该子字符串首次出现时其首字符的索引;否则,返回string:npos
(2)rfind():查找子字符串或字符最后一次出现的位置。
(3)find_first_of():在字符串中查找参数中任何一个字符首次出现的位置。
string snake("cobra");
int where = snake.find_first_of("hark") // 返回r在“cobra”中的位置(即索引3)
(4)find_last_of():在字符串中查找参数中任何一个字符最后一次出现的位置。
string snake("cobra");
int where = snake.find_last_of("hark") // 返回a在“cobra”中的位置(即索引4)
(5)find_first_not_of():在字符串中查找第一个不包含在参数中的字符。
string snake("cobra");
int where = snake.find_first_not_of("hark") // 返回c在“cobra”中的位置(即索引0),因为“hark”中没有c
(6)find_last_not_of():在字符串中查找最后一个不包含在参数中的字符。
string snake("cobra");
int where = snake.find_first_not_of("hark") // 返回b在“cobra”中的位置(即索引2),因为“hark”中没有b
3.6 字符串修改方法
(1)重载的+=运算符或append():将一个字符串追加到另一个字符串的后面。
(2)assign():该方法使得能够将整个字符串、字符串的一部分或由相同字符组成的字符序列赋给string对象。原型之一如下
basic_string& assign(const basic_string& str)
(3)insert():将string对象、字符串数组或几个字符插入到string对象中。
(4)erase():从字符串中删除字符;pop_back():删除字符串中的最后一个字符
(5)replace():替换字符串中指定的内容
(6)copy():将string对象或其中的一部分复制到指定的字符串数组中;swap():使用一个时间恒定的算法来交换两个string对象的内容
// copy()原型,s指向目标数组,n是要复制的字符串,pos指从string对象的什么位置开始复制 size_type copy(charT* s, size_type n, size_type pos = 0) const; // swap()原型 void swap(basic_string& str);
注:copy()方法不追加空值字符,也不检查目标数组的长度是否足够。
3.7 string类输入
对于C-风格字符串,有3中输入方式:
char info[100]; cin >> info; // read a word cin.getline(info, 100); // read a line, discard \n cin.get(info, 100); // read a line, leave \n in queue
对于string对象,有两种方式:
string stuff; cin >> stuff; // read a word getline(cin, stuff); // read a line, discard \n
两个版本的getline()都有一个可选参数,用于指定使用哪个字符来确定输入的边界:
cin.getline(info, 100, ':'); // read up to :, discard : getline(cin, stuff, ':'); // read up to :, discard :
两者之间的主要区别在于,string版本的getline()将自动调整目标string对象的大小,使之刚好能够存储输入的字符;
另一个区别是,读取C-风格字符串的函数是istream类的方法,而string版本是独立的函数。这就是C-风格字符串输入,cin是调用对象;而对于string对象输入,cin是一个函数参数的原因。