目录
3. 支持节点健康状态检查(Health Checking)
4. 实现LVS负载均衡调度服务器 节点服务器的高可用性(HA)
1. Keepalived通过什么判断哪台主机为主服务器,通过什么方式配置浮动IP?
LVS+Keepalived 高可用集群
在这个高度信息化的 IT 时代,企业的生产系统、业务运营、销售和支持,以及日常管理等环节越来越依赖于计算机信息和服务,对高可用(HA)技术的应用需求不断提高,以便提供持续的、不间断的计算机系统或网络服务。
Keepalived是一个基于VRRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题。
一、Keepalived工具和功能
专为LVS和HA设计的一款健康检查工具
1. 管理 LVS 负载均衡软件
keepalived可以通过读取自身的配置文件,实现通过更低层端的接口直接管理LVS配置以及服务的启动 停止功能 这会使LVS应用更加简便
2. 支持故障自动切换(Failover)
① 两台主机同时安装号keepalived并且启动服务
当启动的时候master主机获得所有资源并且对用户提供服务(请求)当校色backup的主机作为master热备
当master主机挂了 出现故障时,backup主机将自动接管master主机所有工作,包括接管VIP资源及响应的资源服务
② 当master主机故障修复后,又会自动接管回他的原来处理工作,backup主机则同时释放master主机失效时接管的工作,此时此刻,两台将恢复到最初的启动时各自的原始角色以及工作状态
抢占模式:master从故障恢复后,会将VIP从backup节点中抢占过来
非抢占:master从故障恢复后,不抢占backup,backup升级为master后的VIP
3. 支持节点健康状态检查(Health Checking)
keepalived.conf文件配置LVS的节点IP和相关参数来实现对LVS直接管理
如果几个节点服务器同时发生故障无法提供服务,keepalived服务会自动将那个失效节点服务器从LVS正常转发列中清除出去,并将请求调度到别的正常的节点服务器上,从而保证用户的访问不受影响:当故障的节点服务器修复以后,keepalived服务又会把他们加入到正常的转发列中,对外面客户提供服务
4. 实现LVS负载均衡调度服务器 节点服务器的高可用性(HA)
一般企业集群需要满足的三个特点:负载均衡、健康检查、故障切换,使用 LVS + Keepalived 完全可以满足需求
二、工作原理
在一个LVS服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务器,但是对外表现为一个虚拟IP,主服务器会发送VRRP通告信息给备份服务器,当备份服务器收不到VRRP消息的时候,即主服务器异常的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
Keepalived高可用之间是通过VRRP进行通信的,VRRP是通过竞选机制来确定主备的,主的优先级高于备,因此,工作时主会优先获得所有的资源,备节点处于等待状态,当主挂了的时候,备节点就会接管主节点的资源,然后顶替主节点对外提供服务。
在Keepalived服务之间,只有作为主的服务器会一直发送VRRP广播包,告诉备它还活着,此时备不会抢占主,当主不可用时,即备监听不到主发送的广播包时,就会启动相关服务接管资源,保证业务的连续性。接管速度最快可以小于1秒。
三、Keepalived实现原理
Keepalived采用VRRP热备份协议实现Linux服务器的多机热备功能
四、Keepalived主要模块
keepalived体系架构中主要有三个模块,分别是core、check和vrrp。
core模块:为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析。
vrrp模块:是来实现VRRP协议的。
check模块:负责健康检查,常见的方式有端口检查及URL检查。
五、VRRP(虚拟路由冗余协议)
- 是针对路由器的一种备份解决方案
- 由多台路由器组成一个热备组,通过共用的虚拟IP地址对外提供服务
- 每个热备组内同时只有一台主路由器提供服务,其他路由器处于冗余状态
- 若当前在线的路由器失效,则其他路由器会根据设置的优先级自动接替虚拟IP地址,继续提供服务
VRRP通信原理:
VRRP也就是虚拟路由冗余协议,协议号:112,它的出现就是为了解决静态路由的单点故障。
VRRP是通过一种竞选协议机制来将路由任务交给某台VRRP路由器的。
VRRP用IP多播的方式(默认多播地址:224.0.0.18 )实现高可用之间通信。
工作时主节点发包,备节点接包,当备节点接收不到主节点发的数据包的时候,就启动接管程序接管主节点的资源。备节点可以有多个,通过优先级竞选,但一般Keepalived系统运维工作中都是一对。
在keepalive服务正常工作时,主(master)节点会不断的向备(backup)节点发送(多播的方式)心跳消息,用意告诉备节点自己还活着,当主节点发生故障时,就无法发型萧条消息,备节点也就因此无法检测到来自主节点的心跳,于是调用自身的接管程序,接管主节点的IP资源及服务。当主节点恢复时,备节点又会释放主节点故障时自身接管的IP资源及服务,恢复到原来的备用角色。
VRRP使用了加密协议加密数据,但Keepalived官方目前还是推荐用明文的方式配置认证类型和密码。
vrrp会把多台路由器组成一个虚拟路由组vrid,vrrp会生成一个虚拟路由(包含虚拟IP和虚拟MAC,局域网内用户不关心哪一个是主哪一个是备,它们只用虚拟路由器的虚拟IP作为它们的网关)实际上虚拟IP就是承载master路由器上,也就是说实际的数据是通过master转发的。
backup是通过优先级来决定哪个是master路由,优先级最大的那台就是master,backup只是用来监听master定时发来的vrrp报文,如果超时未收到master发来的vrrp报文backup就会抢占master,虚拟IP也会漂移到backup头上。
六、故障转移机制
Keepalived高可用服务之间的故障切换转移,是通过VRRP 来实现的。
在 Keepalived服务正常工作时,主 Master节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备Backup节点自己还活着,当主 Master节点发生故障时,就无法发送心跳消息,备节点也就因此无法继续检测到来自主 Master节点的心跳了,于是调用自身的接管程序,接管主Master节点的 IP资源及服务。
而当主 Master节点恢复时,备Backup节点又会释放主节点故障时自身接管的IP资源及服务,恢复到原来的备用角色。
七、Keepalived脑裂及解决方法
1. keepalived脑裂
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
2. 脑裂的原因
高可用服务器对之间心跳线链路发生故障,导致无法正常通信。如心跳线坏了(包括断了,老化)。
因网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)。
因心跳线间连接的设备故障(网卡及交换机)。
因仲裁的机器出问题(采用仲裁的方案)。
高可用服务器上开启了 iptables防火墙阻挡了心跳消息传输。
Keepalived配置里同一 VRRP实例如果 virtual_router_id两端参数配置不一致也会导致裂脑问题发生。
vrrp实例名字不一致、优先级一致。
3. 解决对策
添加冗余的心跳线,例如:双线条线(心跳线也HA),尽量减少“裂脑”发生几率
启用磁盘锁。正在服务一方锁住共享磁盘,“裂脑”发生时,让对方完全“抢不走”共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动“解锁”,另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了“智能”锁。即:正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下参考IP,不通则表明断点就出在本端。不仅“心跳”、还兼对外“服务”的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
八、Keepalived高可用群集的搭建步骤
主DR:192.168.174.10 虚拟网卡ens33:0 192.168.174.60
备DR:192.168.174.20 虚拟网卡ens33:0 192.168.174.60
web 1 : 192.168.174.30
web 2 : 192.168.174.40
1. 配置负载调度器 (主、备相同)
主DR:

备DR:

2. 配置keeplived
主DR


备DR

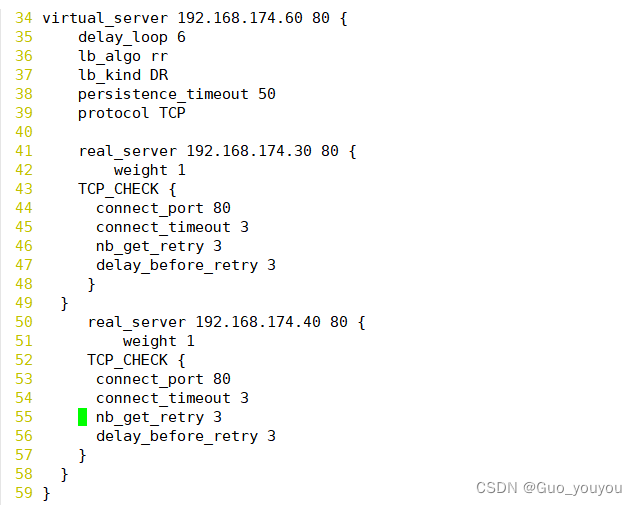
3. 配置vip(虚拟IP)

主DR


备DR

4. 启动 ipvsadm 服务
主DR


备DR



5. 配置节点服务器





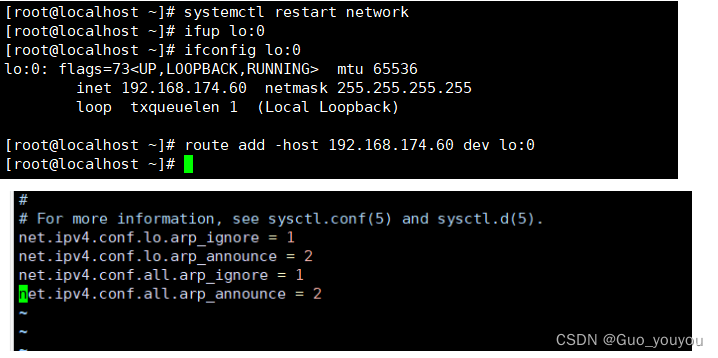

6. 验证

七、总结
1. Keepalived通过什么判断哪台主机为主服务器,通过什么方式配置浮动IP?
Keepalived首先做初始化先检查state状态,master为主服务器,backup为备服务器。
然后再对比所有服务器的priority,谁的优先级高谁是最终的主服务器。
优先级高的服务器会通过ip命令为自己的电脑配置一个提前定义好的浮动IP地址。
2. keepalived的抢占与非抢占模式
抢占模式即MASTER从故障中恢复后,会将VIP从BACKUP节点中抢占过来。
非抢占模式即MASTER恢复后不抢占BACKUP升级为MASTER后的VIP
非抢占式俩节点state必须为bakcup,且必须配置nopreempt。
注意:这样配置后,我们要注意启动服务的顺序,优先启动的获取master权限,与
优先级没有关系了。