XPath入门 Selenium使用Xpath定位
什么是Xpath
XPath 使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。XPath 用于在 XML 文档中通过元素和属性进行导航,XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言
什么是XML
XML是一种格式,XML是标准通用标记语言,它是一种简单的数据存储语言,使用一系列简单的标记描述数据,XML的宗旨传输数据的,而与其同属标准通用标记语言的HTML主要用于显示数据
XML 与 HTML 的主要差异
XML 不是 HTML 的替代
XML 和 HTML 为不同的目的而设计:
XML 被设计为传输和存储数据,其焦点是数据的内容
HTML 被设计用来显示数据,其焦点是数据的外观
HTML 旨在显示信息,而 XML 旨在传输信息
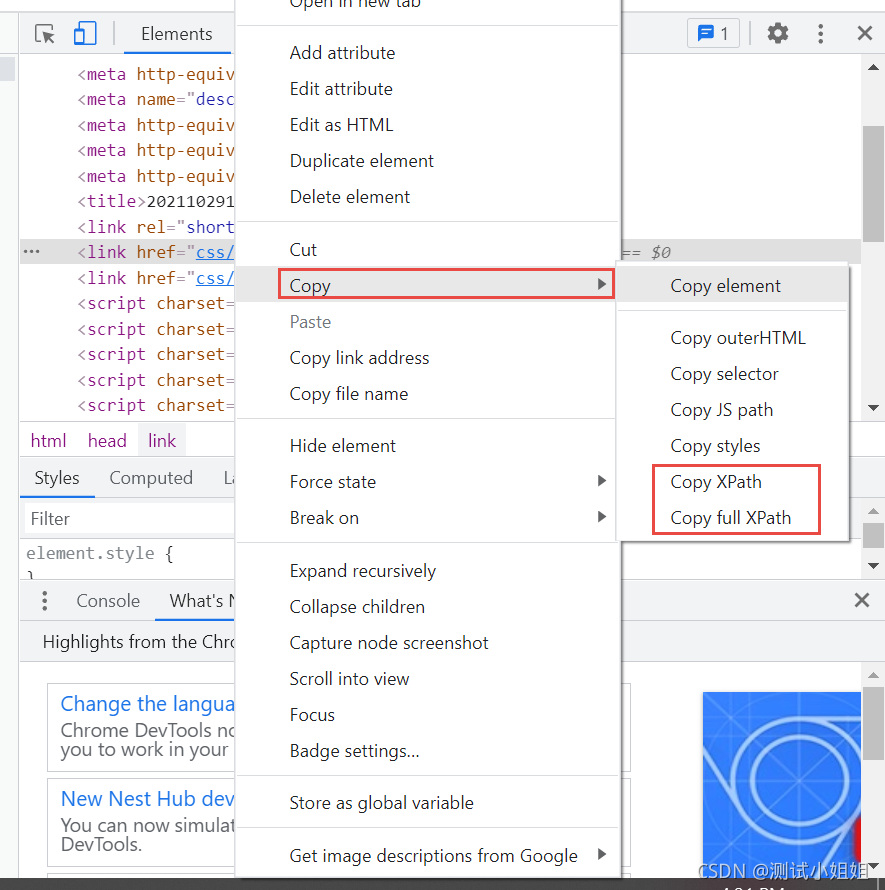
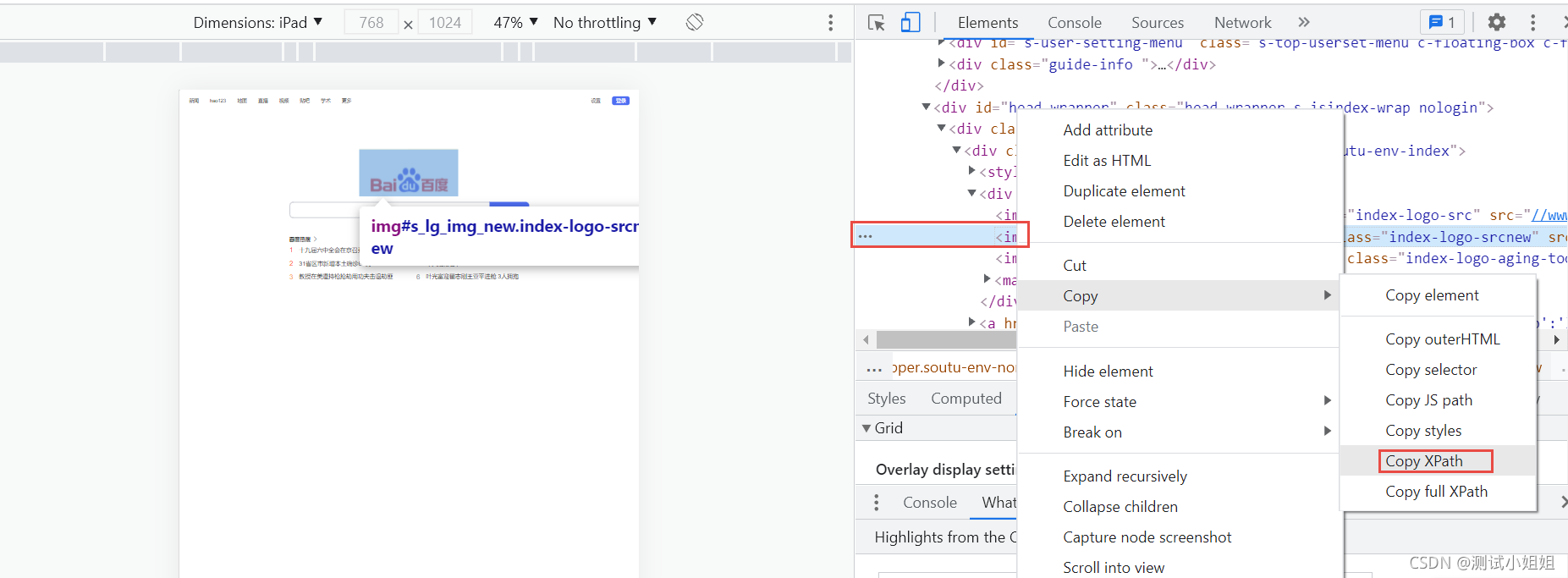
如何来获取想要的Xpath路径
谷歌浏览器为例
使用谷歌浏览器获取需要抓取元素的xpath路径
把自动生成的路径: //*[@id=“s_lg_img_new”]
掌握基本语法,以下列的HTML为例,抓取不同的节点
<html>
<body>
<div>
<a href="http://www.baidu.com">
<a href="http://test.com"><img src="xx" alt="文章" /></a>
</div>
<body>
<html>
节点以及节点之间的关系,用上述的HTML来说明
父节点(Parent)
元素div是元素a的父节点;第二个元素a也是元素img的父节点
子节点(Children)
元素a是元素div的子节点;元素img是子节点
兄弟/同胞节点(Sibling)
兄弟节点在HTML中的地位相等,它们有相同的父节点。如上面例子中,两个a元素互为兄弟节点
先辈节点(Descendant)
对于img元素来说,它的父节点(第二个a元素),和它的父节点的父节点(元素div)统称为img的先辈节点。在一个HTML文件中,先辈节点一般不唯一,比如这里的例子中,元素img的先辈节点包含两个元素
后代节点(Descendant)
对于img元素来说,它的子节点(第二个a元素),和它的子节点的子节点(元素img)统称为div的后代节点
在使用Xpath中,搞清楚节点间的关系是很重要
XPath数据类型
XPath可分为四种数据类型:
节点集(node-set)
节点集是通过路径匹配返回的符合条件的一组节点的集合。其它类型的数据不能转换为节点集。
布尔值(boolean)
由函数或布尔表达式返回的条件匹配值,与一般语言中的布尔值相同,有true和 false两个值。布尔值可以和数值类型、字符串类型相互转换。
字符串(string)
字符串即包含一系列字符的集合,XPath中提供了一系列的字符串函数。字符串可与数值类型、布尔值类型的数据相互转换。
数值(number)
在XPath 中数值为浮点数,可以是双精度64位浮点数。另外包括一些数值的特殊描述,如非数值NaN(Not-a-Number)、正无穷大infinity、负无 穷大-infinity、正负0等等。number的整数值可以通过函数取得,另外,数值也可以和布尔类型、字符串类型相互转换。
XPath节点类型
由于XPath包含的是对文档结构树的一系列操作,一个XML文件可以包含元素、CDATA、注释、处理指令等逻辑要素,其中元素还可以包含属性,并可以利用属性来定义命名空间。在XPath 中,将节点划分为七种节点类型:
根节点(Root Node)
根节点是一棵树的最上层,根节点是唯一的。树上其它所有元素节点都是它的子节点或后代节点。对根节点的处理机制与其它节点相同。在XSLT中对树的匹配总是先从根节点开始
元素节点(Element Nodes)
元素节点对应于文档中的每一个元素,一个元素节点的子节点可以是元素节点、注释节点、处理指令节点和文本节点。可以为元素节点定义一个唯一的标识id。元素节点都可以有扩展名,它是由两部分组成的:一部分是命名空间URI,另一部分是本地的命名
文本节点(Text Nodes)
文本节点包含了一组字符数据,即CDATA中包含的字符。任何一个文本节点都不会有紧邻的兄弟文本节点,而且文本节点没有扩展名
属性节点(Attribute Nodes)
每 一个元素节点有一个相关联的属性节点集合,元素是每个属性节点的父节点,但属性节点却不是其父元素的子节点。这就是说,通过查找元素的子节点可以匹配出元 素的属性节点,但反过来不成立,只是单向的。再有,元素的属性节点没有共享性,也就是说不同的元素节点不共有同一个属性节点
命名空间节点(Namespace Nodes)
每一个元素节点都有一个相关的命名空间节点集。在XML文档中,命名空间是通过保留属性声明的,因此,在XPath中,该类节点与属性节点极为相似,它们与父元素之间的关系是单向的,并且不具有共享性
处理指令节点(Processing Instruction Nodes)
处理指令节点对应于XML文档中的每一条处理指令。它也有扩展名,扩展名的本地命名指向处理对象,而命名空间部分为空
注释节点(Comment Nodes)
注释节点对应于文档中的注释
xpath的语法
选取节点
nodename----选取此标签及所有子标签
/ ----从根节点开始找
// ----从任意位置开始找,不考虑他们的位置
. ----当前节点
… ----父节点
@----选取属性
text()----选取内容
谓语的作用:限定
[]----写在元素后面,用来限定这个元素
[@class=“abc”]----class属性为abc的元素
[@id=“aaa”]----id属性为aaa的元素
[@class]----选取有class属性的元素
[1]----第一个
[last()]----选最后一个
[last()-1]----倒数第二个
[position()>2]----选取位置大于2
book[position()>2—从第三本书开始选取
[contains(属性名a,属性值b)]属性a包含b的标签
book[contains(@href,‘baidu’)]
通配符
*匹配任何元素节点
@*匹配任何属性节点
选取若干路径
//title|//price —选取所有的title和price标签
总结
XPath的优势在于它的速度,这是因为它把html以树形的结构进行存储,在你通过层级关系查找节点的时候,并不需要对所有字符串进行遍历,它的底层是通过libxml构建一棵DOM树实现的查找
XPath其实并不容易掌握(深入掌握),它的语法和函数都非常多,学习起来成本也比较高,但是在普通的抓取业务中,只需要掌握一些基本的就足够了
Selenium自动化测试中使用Xpath定位
一、xpath基本定位用法
1.使用id定位 – driver.find_element_by_xpath(’//input[@id=“kw”]’)
2.使用class定位 – driver.find_element_by_xpath(’//input[@class=“s_ipt”]’)
二、xpath相对路径/绝对路径定位
1.相对定位 – 以// 开头 如://form//input[@name=“phone”]
2. 绝对定位 – 以/ 开头,但是要从根目录开始,比较繁琐,一般不建议使用 如:/html/body/div/a
三、xpath文本、模糊、逻辑定位
1.【文本定位】使用text()元素的text内容 如://button[text()=“登录”]
2. 【模糊定位】使用contains() 包含函数 如://button[contains(text(),“登录”)]、//button[contains(@class,“btn”)] 除了contains不是=等于
3. 【模糊定位】使用starts-with – 匹配以xx开头的属性值;ends-with – 匹配以xx结尾的属性值 如://button[starts-with(@class,“btn”)]、//input[ends-with(@class,"-special")]
4. 使用逻辑运算符 – and、or;如://input[@name=“phone” and @datatype=“m”]