目录
目录
1 目录结构
1.1 查看目录结构
sudo apt-get install tree
tree <目录名> 显示该目录下的子目录、文件的层次结构。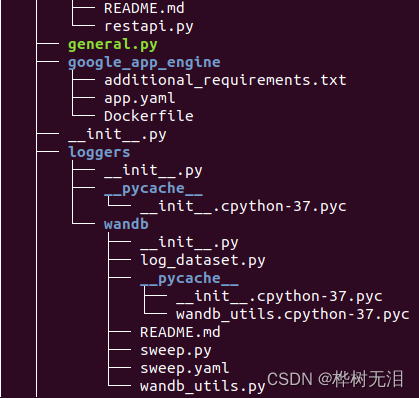
1.2 yolov5目录结构





2 代码解析
2.1 utils/activations.py 激活函数
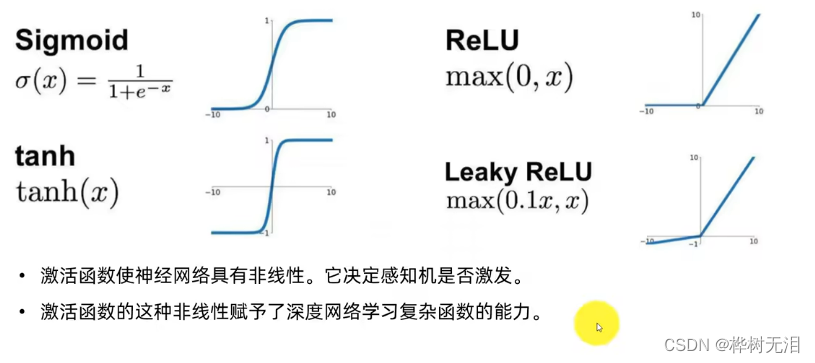
Swish函数
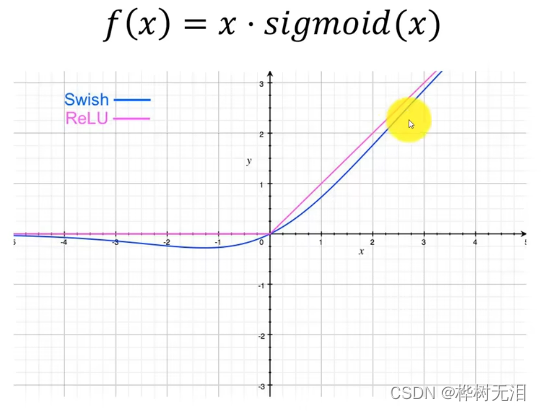
Mish函数
Hardswish函数
mish函数比较复杂,为了简单表达,使用分段函数
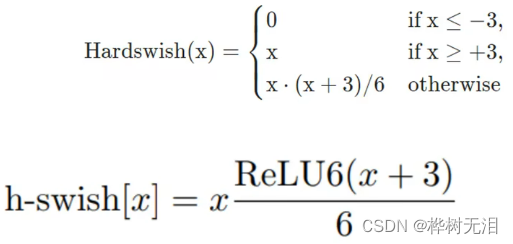
FReLU函数
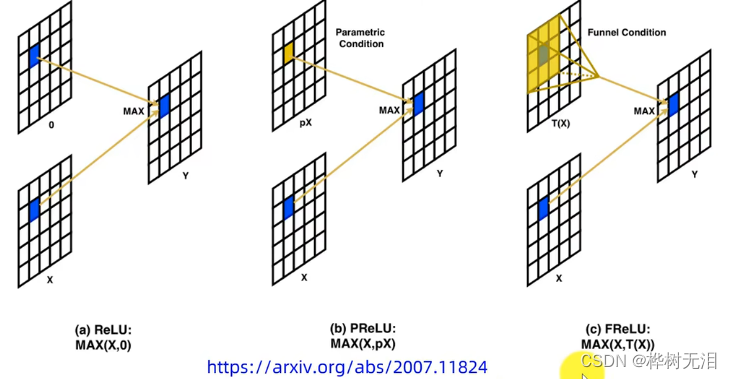
它的激活区域不光是方形,还可以是斜边和带弧形的。


import torch
import torch.nn as nn
import torch.nn.functional as F
# SiLU https://arxiv.org/pdf/1606.08415.pdf ----------------------------------------------------------------------------
#定义了各种激活函数
class SiLU(nn.Module): # export-friendly version of nn.SiLU()
@staticmethod
def forward(x):
return x * torch.sigmoid(x) #Swish函数
class Hardswish(nn.Module): # export-friendly version of nn.Hardswish()
@staticmethod
def forward(x):
# return x * F.hardsigmoid(x) # for TorchScript and CoreML
return x * F.hardtanh(x + 3, 0.0, 6.0) / 6.0 # for TorchScript, CoreML and ONNX
# Mish https://github.com/digantamisra98/Mish --------------------------------------------------------------------------
class Mish(nn.Module):
@staticmethod
def forward(x):
return x * F.softplus(x).tanh() #Mish函数
class MemoryEfficientMish(nn.Module):
class F(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return x.mul(torch.tanh(F.softplus(x))) # x * tanh(ln(1 + exp(x)))
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
sx = torch.sigmoid(x)
fx = F.softplus(x).tanh()
return grad_output * (fx + x * sx * (1 - fx * fx))
def forward(self, x):
return self.F.apply(x)
# FReLU https://arxiv.org/abs/2007.11824 -------------------------------------------------------------------------------
class FReLU(nn.Module):
def __init__(self, c1, k=3): # ch_in, kernel
super().__init__()
#nn.Con2d(in_channels, out_channels, kernel_size, stride, padding, dilation=1, groups=1, bias=True)
self.conv = nn.Conv2d(c1, c1, k, 1, 1, groups=c1, bias=False)
self.bn = nn.BatchNorm2d(c1)
def forward(self, x):
return torch.max(x, self.bn(self.conv(x)))
# ACON https://arxiv.org/pdf/2009.04759.pdf ----------------------------------------------------------------------------
class AconC(nn.Module):
r""" ACON activation (activate or not).
AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1):
super().__init__()
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.beta = nn.Parameter(torch.ones(1, c1, 1, 1))
def forward(self, x):
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(self.beta * dpx) + self.p2 * x
class MetaAconC(nn.Module):
r""" ACON activation (activate or not).
MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network
according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>.
"""
def __init__(self, c1, k=1, s=1, r=16): # ch_in, kernel, stride, r
super().__init__()
c2 = max(r, c1 // r)
self.p1 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.p2 = nn.Parameter(torch.randn(1, c1, 1, 1))
self.fc1 = nn.Conv2d(c1, c2, k, s, bias=True)
self.fc2 = nn.Conv2d(c2, c1, k, s, bias=True)
# self.bn1 = nn.BatchNorm2d(c2)
# self.bn2 = nn.BatchNorm2d(c1)
def forward(self, x):
y = x.mean(dim=2, keepdims=True).mean(dim=3, keepdims=True)
# batch-size 1 bug/instabilities https://github.com/ultralytics/yolov5/issues/2891
# beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(y))))) # bug/unstable
beta = torch.sigmoid(self.fc2(self.fc1(y))) # bug patch BN layers removed
dpx = (self.p1 - self.p2) * x
return dpx * torch.sigmoid(beta * dpx) + self.p2 * x2.2 models/common.py 网络组件
#特征图自动填充函数
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
# 卷积conv+BN归一化+hardswish激活
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x): #正向
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
#深度可分离卷积(yolov5没有使用)
class DWConv(Conv):
# Depth-wise convolution class
def __init__(self, c1, c2, k=1, s=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
class TransformerLayer(nn.Module):
# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads):
super().__init__()
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
x = self.fc2(self.fc1(x)) + x
return x
class TransformerBlock(nn.Module):
# Vision Transformer https://arxiv.org/abs/2010.11929
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*(TransformerLayer(c2, num_heads) for _ in range(num_layers)))
self.c2 = c2
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
b, _, w, h = x.shape
p = x.flatten(2).permute(2, 0, 1)
return self.tr(p + self.linear(p)).permute(1, 2, 0).reshape(b, self.c2, w, h)
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.SiLU()
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):#根据self.add的值来确定是否有shortcut
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
class C3TR(C3):
# C3 module with TransformerBlock()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = TransformerBlock(c_, c_, 4, n)
class C3SPP(C3):
# C3 module with SPP()
def __init__(self, c1, c2, k=(5, 9, 13), n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e)
self.m = SPP(c_, c_, k)
class C3Ghost(C3):
# C3 module with GhostBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
#空间金字塔池化
class SPP(nn.Module):
# Spatial Pyramid Pooling (SPP) layer https://arxiv.org/abs/1406.4729
def __init__(self, c1, c2, k=(5, 9, 13)):#三路最大池化
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
#把宽度w和高度h信息整合到c空间中
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)) #四部分切分、拼接、卷积
# return self.conv(self.contract(x))
class GhostConv(nn.Module):
# Ghost Convolution https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
super().__init__()
c_ = c2 // 2 # hidden channels
self.cv1 = Conv(c1, c_, k, s, None, g, act)
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act)
def forward(self, x):
y = self.cv1(x)
return torch.cat([y, self.cv2(y)], 1)
class GhostBottleneck(nn.Module):
# Ghost Bottleneck https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pw
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(), # dw
GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False),
Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity()
def forward(self, x):
return self.conv(x) + self.shortcut(x)
class Contract(nn.Module):
# Contract width-height into channels, i.e. x(1,64,80,80) to x(1,256,40,40)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
b, c, h, w = x.size() # assert (h / s == 0) and (W / s == 0), 'Indivisible gain'
s = self.gain
x = x.view(b, c, h // s, s, w // s, s) # x(1,64,40,2,40,2)
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # x(1,2,2,64,40,40)
return x.view(b, c * s * s, h // s, w // s) # x(1,256,40,40)
class Expand(nn.Module):
# Expand channels into width-height, i.e. x(1,64,80,80) to x(1,16,160,160)
def __init__(self, gain=2):
super().__init__()
self.gain = gain
def forward(self, x):
b, c, h, w = x.size() # assert C / s ** 2 == 0, 'Indivisible gain'
s = self.gain
x = x.view(b, s, s, c // s ** 2, h, w) # x(1,2,2,16,80,80)
x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # x(1,16,80,2,80,2)
return x.view(b, c // s ** 2, h * s, w * s) # x(1,16,160,160)
#拼接
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super().__init__()
self.d = dimension#沿着哪个维度进行拼接
def forward(self, x):
return torch.cat(x, self.d)
class DetectMultiBackend(nn.Module):
# YOLOv5 MultiBackend class for python inference on various backends
def __init__(self, weights='yolov5s.pt', device=torch.device('cpu'), dnn=False, data=None, fp16=False):
# Usage:
# PyTorch: weights = *.pt
# TorchScript: *.torchscript
# ONNX Runtime: *.onnx
# ONNX OpenCV DNN: *.onnx with --dnn
# OpenVINO: *.xml
# CoreML: *.mlmodel
# TensorRT: *.engine
# TensorFlow SavedModel: *_saved_model
# TensorFlow GraphDef: *.pb
# TensorFlow Lite: *.tflite
# TensorFlow Edge TPU: *_edgetpu.tflite
from models.experimental import attempt_download, attempt_load # scoped to avoid circular import
super().__init__()
w = str(weights[0] if isinstance(weights, list) else weights)
pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs = self.model_type(w) # get backend
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
w = attempt_download(w) # download if not local
fp16 &= (pt or jit or onnx or engine) and device.type != 'cpu' # FP16
if data: # data.yaml path (optional)
with open(data, errors='ignore') as f:
names = yaml.safe_load(f)['names'] # class names
if pt: # PyTorch
model = attempt_load(weights if isinstance(weights, list) else w, map_location=device)
stride = max(int(model.stride.max()), 32) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
model.half() if fp16 else model.float()
self.model = model # explicitly assign for to(), cpu(), cuda(), half()
elif jit: # TorchScript
LOGGER.info(f'Loading {w} for TorchScript inference...')
extra_files = {'config.txt': ''} # model metadata
model = torch.jit.load(w, _extra_files=extra_files)
model.half() if fp16 else model.float()
if extra_files['config.txt']:
d = json.loads(extra_files['config.txt']) # extra_files dict
stride, names = int(d['stride']), d['names']
elif dnn: # ONNX OpenCV DNN
LOGGER.info(f'Loading {w} for ONNX OpenCV DNN inference...')
check_requirements(('opencv-python>=4.5.4',))
net = cv2.dnn.readNetFromONNX(w)
elif onnx: # ONNX Runtime
LOGGER.info(f'Loading {w} for ONNX Runtime inference...')
cuda = torch.cuda.is_available()
check_requirements(('onnx', 'onnxruntime-gpu' if cuda else 'onnxruntime'))
import onnxruntime
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
session = onnxruntime.InferenceSession(w, providers=providers)
elif xml: # OpenVINO
LOGGER.info(f'Loading {w} for OpenVINO inference...')
check_requirements(('openvino-dev',)) # requires openvino-dev: https://pypi.org/project/openvino-dev/
import openvino.inference_engine as ie
core = ie.IECore()
if not Path(w).is_file(): # if not *.xml
w = next(Path(w).glob('*.xml')) # get *.xml file from *_openvino_model dir
network = core.read_network(model=w, weights=Path(w).with_suffix('.bin')) # *.xml, *.bin paths
executable_network = core.load_network(network, device_name='CPU', num_requests=1)
elif engine: # TensorRT
LOGGER.info(f'Loading {w} for TensorRT inference...')
import tensorrt as trt # https://developer.nvidia.com/nvidia-tensorrt-download
check_version(trt.__version__, '7.0.0', hard=True) # require tensorrt>=7.0.0
Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
logger = trt.Logger(trt.Logger.INFO)
with open(w, 'rb') as f, trt.Runtime(logger) as runtime:
model = runtime.deserialize_cuda_engine(f.read())
bindings = OrderedDict()
fp16 = False # default updated below
for index in range(model.num_bindings):
name = model.get_binding_name(index)
dtype = trt.nptype(model.get_binding_dtype(index))
shape = tuple(model.get_binding_shape(index))
data = torch.from_numpy(np.empty(shape, dtype=np.dtype(dtype))).to(device)
bindings[name] = Binding(name, dtype, shape, data, int(data.data_ptr()))
if model.binding_is_input(index) and dtype == np.float16:
fp16 = True
binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
context = model.create_execution_context()
batch_size = bindings['images'].shape[0]
elif coreml: # CoreML
LOGGER.info(f'Loading {w} for CoreML inference...')
import coremltools as ct
model = ct.models.MLModel(w)
else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
if saved_model: # SavedModel
LOGGER.info(f'Loading {w} for TensorFlow SavedModel inference...')
import tensorflow as tf
keras = False # assume TF1 saved_model
model = tf.keras.models.load_model(w) if keras else tf.saved_model.load(w)
elif pb: # GraphDef https://www.tensorflow.org/guide/migrate#a_graphpb_or_graphpbtxt
LOGGER.info(f'Loading {w} for TensorFlow GraphDef inference...')
import tensorflow as tf
def wrap_frozen_graph(gd, inputs, outputs):
x = tf.compat.v1.wrap_function(lambda: tf.compat.v1.import_graph_def(gd, name=""), []) # wrapped
ge = x.graph.as_graph_element
return x.prune(tf.nest.map_structure(ge, inputs), tf.nest.map_structure(ge, outputs))
gd = tf.Graph().as_graph_def() # graph_def
gd.ParseFromString(open(w, 'rb').read())
frozen_func = wrap_frozen_graph(gd, inputs="x:0", outputs="Identity:0")
elif tflite or edgetpu: # https://www.tensorflow.org/lite/guide/python#install_tensorflow_lite_for_python
try: # https://coral.ai/docs/edgetpu/tflite-python/#update-existing-tf-lite-code-for-the-edge-tpu
from tflite_runtime.interpreter import Interpreter, load_delegate
except ImportError:
import tensorflow as tf
Interpreter, load_delegate = tf.lite.Interpreter, tf.lite.experimental.load_delegate,
if edgetpu: # Edge TPU https://coral.ai/software/#edgetpu-runtime
LOGGER.info(f'Loading {w} for TensorFlow Lite Edge TPU inference...')
delegate = {'Linux': 'libedgetpu.so.1',
'Darwin': 'libedgetpu.1.dylib',
'Windows': 'edgetpu.dll'}[platform.system()]
interpreter = Interpreter(model_path=w, experimental_delegates=[load_delegate(delegate)])
else: # Lite
LOGGER.info(f'Loading {w} for TensorFlow Lite inference...')
interpreter = Interpreter(model_path=w) # load TFLite model
interpreter.allocate_tensors() # allocate
input_details = interpreter.get_input_details() # inputs
output_details = interpreter.get_output_details() # outputs
elif tfjs:
raise Exception('ERROR: YOLOv5 TF.js inference is not supported')
self.__dict__.update(locals()) # assign all variables to self
def forward(self, im, augment=False, visualize=False, val=False):
# YOLOv5 MultiBackend inference
b, ch, h, w = im.shape # batch, channel, height, width
if self.pt or self.jit: # PyTorch
y = self.model(im) if self.jit else self.model(im, augment=augment, visualize=visualize)
return y if val else y[0]
elif self.dnn: # ONNX OpenCV DNN
im = im.cpu().numpy() # torch to numpy
self.net.setInput(im)
y = self.net.forward()
elif self.onnx: # ONNX Runtime
im = im.cpu().numpy() # torch to numpy
y = self.session.run([self.session.get_outputs()[0].name], {self.session.get_inputs()[0].name: im})[0]
elif self.xml: # OpenVINO
im = im.cpu().numpy() # FP32
desc = self.ie.TensorDesc(precision='FP32', dims=im.shape, layout='NCHW') # Tensor Description
request = self.executable_network.requests[0] # inference request
request.set_blob(blob_name='images', blob=self.ie.Blob(desc, im)) # name=next(iter(request.input_blobs))
request.infer()
y = request.output_blobs['output'].buffer # name=next(iter(request.output_blobs))
elif self.engine: # TensorRT
assert im.shape == self.bindings['images'].shape, (im.shape, self.bindings['images'].shape)
self.binding_addrs['images'] = int(im.data_ptr())
self.context.execute_v2(list(self.binding_addrs.values()))
y = self.bindings['output'].data
elif self.coreml: # CoreML
im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
im = Image.fromarray((im[0] * 255).astype('uint8'))
# im = im.resize((192, 320), Image.ANTIALIAS)
y = self.model.predict({'image': im}) # coordinates are xywh normalized
if 'confidence' in y:
box = xywh2xyxy(y['coordinates'] * [[w, h, w, h]]) # xyxy pixels
conf, cls = y['confidence'].max(1), y['confidence'].argmax(1).astype(np.float)
y = np.concatenate((box, conf.reshape(-1, 1), cls.reshape(-1, 1)), 1)
else:
k = 'var_' + str(sorted(int(k.replace('var_', '')) for k in y)[-1]) # output key
y = y[k] # output
else: # TensorFlow (SavedModel, GraphDef, Lite, Edge TPU)
im = im.permute(0, 2, 3, 1).cpu().numpy() # torch BCHW to numpy BHWC shape(1,320,192,3)
if self.saved_model: # SavedModel
y = (self.model(im, training=False) if self.keras else self.model(im)[0]).numpy()
elif self.pb: # GraphDef
y = self.frozen_func(x=self.tf.constant(im)).numpy()
else: # Lite or Edge TPU
input, output = self.input_details[0], self.output_details[0]
int8 = input['dtype'] == np.uint8 # is TFLite quantized uint8 model
if int8:
scale, zero_point = input['quantization']
im = (im / scale + zero_point).astype(np.uint8) # de-scale
self.interpreter.set_tensor(input['index'], im)
self.interpreter.invoke()
y = self.interpreter.get_tensor(output['index'])
if int8:
scale, zero_point = output['quantization']
y = (y.astype(np.float32) - zero_point) * scale # re-scale
y[..., :4] *= [w, h, w, h] # xywh normalized to pixels
if isinstance(y, np.ndarray):
y = torch.tensor(y, device=self.device)
return (y, []) if val else y
def warmup(self, imgsz=(1, 3, 640, 640)):
# Warmup model by running inference once
if any((self.pt, self.jit, self.onnx, self.engine, self.saved_model, self.pb)): # warmup types
if self.device.type != 'cpu': # only warmup GPU models
im = torch.zeros(*imgsz, dtype=torch.half if self.fp16 else torch.float, device=self.device) # input
for _ in range(2 if self.jit else 1): #
self.forward(im) # warmup
@staticmethod
def model_type(p='path/to/model.pt'):
# Return model type from model path, i.e. path='path/to/model.onnx' -> type=onnx
from export import export_formats
suffixes = list(export_formats().Suffix) + ['.xml'] # export suffixes
check_suffix(p, suffixes) # checks
p = Path(p).name # eliminate trailing separators
pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, xml2 = (s in p for s in suffixes)
xml |= xml2 # *_openvino_model or *.xml
tflite &= not edgetpu # *.tflite
return pt, jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs
#自动调整输入预处理(yolov5没有用)
class AutoShape(nn.Module):
# YOLOv5 input-robust model wrapper for passing cv2/np/PIL/torch inputs. Includes preprocessing, inference and NMS
conf = 0.25 # NMS confidence threshold 置信度阈值
iou = 0.45 # NMS IoU threshold iou阈值
agnostic = False # NMS class-agnostic
multi_label = False # NMS multiple labels per box
classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
max_det = 1000 # maximum number of detections per image
amp = False # Automatic Mixed Precision (AMP) inference
def __init__(self, model):
super().__init__()
LOGGER.info('Adding AutoShape... ')
copy_attr(self, model, include=('yaml', 'nc', 'hyp', 'names', 'stride', 'abc'), exclude=()) # copy attributes
self.dmb = isinstance(model, DetectMultiBackend) # DetectMultiBackend() instance
self.pt = not self.dmb or model.pt # PyTorch model
self.model = model.eval()
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
if self.pt:
m = self.model.model.model[-1] if self.dmb else self.model.model[-1] # Detect()
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
@torch.no_grad()
def forward(self, imgs, size=640, augment=False, profile=False):
# Inference from various sources. For height=640, width=1280, RGB images example inputs are:
# file: imgs = 'data/images/zidane.jpg' # str or PosixPath
# URI: = 'https://ultralytics.com/images/zidane.jpg'
# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
# PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
# numpy: = np.zeros((640,1280,3)) # HWC
# torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
t = [time_sync()]
p = next(self.model.parameters()) if self.pt else torch.zeros(1) # for device and type
autocast = self.amp and (p.device.type != 'cpu') # Automatic Mixed Precision (AMP) inference
if isinstance(imgs, torch.Tensor): # torch
with amp.autocast(enabled=autocast):
return self.model(imgs.to(p.device).type_as(p), augment, profile) # inference
# Pre-process
n, imgs = (len(imgs), imgs) if isinstance(imgs, list) else (1, [imgs]) # number of images, list of images
shape0, shape1, files = [], [], [] # image and inference shapes, filenames
for i, im in enumerate(imgs):
f = f'image{i}' # filename
if isinstance(im, (str, Path)): # filename or uri
im, f = Image.open(requests.get(im, stream=True).raw if str(im).startswith('http') else im), im
im = np.asarray(exif_transpose(im))
elif isinstance(im, Image.Image): # PIL Image
im, f = np.asarray(exif_transpose(im)), getattr(im, 'filename', f) or f
files.append(Path(f).with_suffix('.jpg').name)
if im.shape[0] < 5: # image in CHW
im = im.transpose((1, 2, 0)) # reverse dataloader .transpose(2, 0, 1)
im = im[..., :3] if im.ndim == 3 else np.tile(im[..., None], 3) # enforce 3ch input
s = im.shape[:2] # HWC
shape0.append(s) # image shape
g = (size / max(s)) # gain
shape1.append([y * g for y in s])
imgs[i] = im if im.data.contiguous else np.ascontiguousarray(im) # update
shape1 = [make_divisible(x, self.stride) if self.pt else size for x in np.array(shape1).max(0)] # inf shape
x = [letterbox(im, new_shape=shape1, auto=False)[0] for im in imgs] # pad
x = np.ascontiguousarray(np.array(x).transpose((0, 3, 1, 2))) # stack and BHWC to BCHW
x = torch.from_numpy(x).to(p.device).type_as(p) / 255 # uint8 to fp16/32
t.append(time_sync())
with amp.autocast(enabled=autocast):
# Inference
y = self.model(x, augment, profile) # forward
t.append(time_sync())
# Post-process
y = non_max_suppression(y if self.dmb else y[0], self.conf, iou_thres=self.iou, classes=self.classes,
agnostic=self.agnostic, multi_label=self.multi_label, max_det=self.max_det) # NMS
for i in range(n):
scale_coords(shape1, y[i][:, :4], shape0[i])
t.append(time_sync())
return Detections(imgs, y, files, t, self.names, x.shape)
class Detections:
# YOLOv5 detections class for inference results
def __init__(self, imgs, pred, files, times=(0, 0, 0, 0), names=None, shape=None):
super().__init__()
d = pred[0].device # device
gn = [torch.tensor([*(im.shape[i] for i in [1, 0, 1, 0]), 1, 1], device=d) for im in imgs] # normalizations
self.imgs = imgs # list of images as numpy arrays
self.pred = pred # list of tensors pred[0] = (xyxy, conf, cls)
self.names = names # class names
self.files = files # image filenames
self.times = times # profiling times
self.xyxy = pred # xyxy pixels
self.xywh = [xyxy2xywh(x) for x in pred] # xywh pixels
self.xyxyn = [x / g for x, g in zip(self.xyxy, gn)] # xyxy normalized
self.xywhn = [x / g for x, g in zip(self.xywh, gn)] # xywh normalized
self.n = len(self.pred) # number of images (batch size)
self.t = tuple((times[i + 1] - times[i]) * 1000 / self.n for i in range(3)) # timestamps (ms)
self.s = shape # inference BCHW shape
def display(self, pprint=False, show=False, save=False, crop=False, render=False, save_dir=Path('')):
crops = []
for i, (im, pred) in enumerate(zip(self.imgs, self.pred)):
s = f'image {i + 1}/{len(self.pred)}: {im.shape[0]}x{im.shape[1]} ' # string
if pred.shape[0]:
for c in pred[:, -1].unique():
n = (pred[:, -1] == c).sum() # detections per class
s += f"{n} {self.names[int(c)]}{'s' * (n > 1)}, " # add to string
if show or save or render or crop:
annotator = Annotator(im, example=str(self.names))
for *box, conf, cls in reversed(pred): # xyxy, confidence, class
label = f'{self.names[int(cls)]} {conf:.2f}'
if crop:
file = save_dir / 'crops' / self.names[int(cls)] / self.files[i] if save else None
crops.append({'box': box, 'conf': conf, 'cls': cls, 'label': label,
'im': save_one_box(box, im, file=file, save=save)})
else: # all others
annotator.box_label(box, label, color=colors(cls))
im = annotator.im
else:
s += '(no detections)'
im = Image.fromarray(im.astype(np.uint8)) if isinstance(im, np.ndarray) else im # from np
if pprint:
LOGGER.info(s.rstrip(', '))
if show:
im.show(self.files[i]) # show
if save:
f = self.files[i]
im.save(save_dir / f) # save
if i == self.n - 1:
LOGGER.info(f"Saved {self.n} image{'s' * (self.n > 1)} to {colorstr('bold', save_dir)}")
if render:
self.imgs[i] = np.asarray(im)
if crop:
if save:
LOGGER.info(f'Saved results to {save_dir}\n')
return crops
def print(self):
self.display(pprint=True) # print results
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {tuple(self.s)}' %
self.t)
def show(self):
self.display(show=True) # show results
def save(self, save_dir='runs/detect/exp'):
save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) # increment save_dir
self.display(save=True, save_dir=save_dir) # save results
def crop(self, save=True, save_dir='runs/detect/exp'):
save_dir = increment_path(save_dir, exist_ok=save_dir != 'runs/detect/exp', mkdir=True) if save else None
return self.display(crop=True, save=save, save_dir=save_dir) # crop results
def render(self):
self.display(render=True) # render results
return self.imgs
def pandas(self):
# return detections as pandas DataFrames, i.e. print(results.pandas().xyxy[0])
new = copy(self) # return copy
ca = 'xmin', 'ymin', 'xmax', 'ymax', 'confidence', 'class', 'name' # xyxy columns
cb = 'xcenter', 'ycenter', 'width', 'height', 'confidence', 'class', 'name' # xywh columns
for k, c in zip(['xyxy', 'xyxyn', 'xywh', 'xywhn'], [ca, ca, cb, cb]):
a = [[x[:5] + [int(x[5]), self.names[int(x[5])]] for x in x.tolist()] for x in getattr(self, k)] # update
setattr(new, k, [pd.DataFrame(x, columns=c) for x in a])
return new
def tolist(self):
# return a list of Detections objects, i.e. 'for result in results.tolist():'
r = range(self.n) # iterable
x = [Detections([self.imgs[i]], [self.pred[i]], [self.files[i]], self.times, self.names, self.s) for i in r]
# for d in x:
# for k in ['imgs', 'pred', 'xyxy', 'xyxyn', 'xywh', 'xywhn']:
# setattr(d, k, getattr(d, k)[0]) # pop out of list
return x
def __len__(self):
return self.n
#把目标检测的结果再次分类 第两级分类
class Classify(nn.Module):
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g) # to x(b,c2,1,1)
self.flat = nn.Flatten()#展平
def forward(self, x):
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
return self.flat(self.conv(z)) # flatten to x(b,c2)2.3 models/yolo.py 整个网络构建
try:
import thop # for FLOPs computation
except ImportError:
thop = None
#对特征图检测
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes 类别数量coco20为例
self.no = nc + 5 # number of outputs per anchor 四个坐标信息+目标得分
self.nl = len(anchors) # number of detection layers 不同尺度特征图层数
self.na = len(anchors[0]) // 2 # number of anchors 每个特征图anchors数
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv x是通道取值 na是3 no是25
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x) #返回预测框坐标、得分和分类
#划分单元网格
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)], indexing='ij')
else:
yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid
#网络模型
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml 获得yaml文件
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, encoding='ascii', errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict 加载yaml文件 以字典的形式
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)
# Build strides, anchors
m = self.model[-1] # 读取Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m) #检查anchor顺序和stride顺序是否一致
self.stride = m.stride
self._initialize_biases() # only run once
# Init weights, biases 初始化
initialize_weights(self)
self.info()
LOGGER.info('')
#在测试时候做数据增强
#python detect.py --weights yolov5s.pt --img 832 --source ./inference/images/ --augment
#--img大小需要大于640设置为832
def forward(self, x, augment=False, profile=False, visualize=False):
if augment:
return self._forward_augment(x) # augmented inference, None
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_augment(self, x):
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max())) #图像尺寸改变
yi = self._forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, 1), None # augmented inference, train
#输入经过网络每一层
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
def _descale_pred(self, p, flips, scale, img_size):
# de-scale predictions following augmented inference (inverse operation)
if self.inplace:
p[..., :4] /= scale # de-scale
if flips == 2:
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
elif flips == 3:
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
else:
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
p = torch.cat((x, y, wh, p[..., 4:]), -1)
return p
def _clip_augmented(self, y):
# Clip YOLOv5 augmented inference tails
nl = self.model[-1].nl # number of detection layers (P3-P5)
g = sum(4 ** x for x in range(nl)) # grid points
e = 1 # exclude layer count
i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
y[0] = y[0][:, :-i] # large
i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
y[-1] = y[-1][:, i:] # small
return y
def _profile_one_layer(self, m, x, dt):
c = isinstance(m, Detect) # is final layer, copy input as inplace fix
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
if c:
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
#初始化detect组件的偏置
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
LOGGER.info(
('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
#卷积和归一化进行融合
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, Detect):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
#解析网络配置文件构建模型
def parse_model(d, ch): # model_dict, input_channels(3)
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
#控制深度的代码
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m is Detect:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
else:
c2 = ch[f]
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--profile', action='store_true', help='profile model speed')
parser.add_argument('--test', action='store_true', help='test all yolo*.yaml')
opt = parser.parse_args()
opt.cfg = check_yaml(opt.cfg) # check YAML
print_args(FILE.stem, opt)
device = select_device(opt.device)
# Create model
model = Model(opt.cfg).to(device)
model.train()
# Profile
if opt.profile:
img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
y = model(img, profile=True)
# Test all models
if opt.test:
for cfg in Path(ROOT / 'models').rglob('yolo*.yaml'):
try:
_ = Model(cfg)
except Exception as e:
print(f'Error in {cfg}: {e}')
# Tensorboard (not working https://github.com/ultralytics/yolov5/issues/2898)
# from torch.utils.tensorboard import SummaryWriter
# tb_writer = SummaryWriter('.')
# LOGGER.info("Run 'tensorboard --logdir=models' to view tensorboard at http://localhost:6006/")
# tb_writer.add_graph(torch.jit.trace(model, img, strict=False), []) # add model graph2.4 输入设定代码
2.4.1 统一输入图片大小
yolo采用保持原图像宽高比

utils/augmentations
#图像缩放:保持图片宽高不变,剩下部分采用灰色填充
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32): #color是填充的颜色
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
#缩放到输入大小的时候,如果没有上采样,则只进行下采样,上采样会使图片模糊,影响性能
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding 计算填充
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle 获取最小的矩阵填充
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
#如果scaleFill=True,则不进行填充,直接由resize改变
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
#计算上下填充大小
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
#什么位置进行填充
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
#进行填充
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)2.4.2 数据增强 data augmentation
通过图片处理方法,人为增加图片数据。(a)剪裁、旋转、色调、比例、亮度


Mosaic方法
yolov5采用Mosaic方法,把几个图拼接一个大图,小图在拼接时候还会进行随机的处理。

untils/datasets.py
def load_mosaic(self, index): #self自定义数据集 index要增强的索引
# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
labels4, segments4 = [], []
s = self.img_size
#随机选取一个中心点
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
#随机取其他三张图片索引
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = self.load_image(index)#load_image 加载图片根据设定的输入大小与图片原大小的比例进行resize
# place img in img4
if i == 0: # top left
#初始化大图
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
#把原图放到左上角
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
#选取小图上的位置 如果图片越界会裁剪
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
#小图上截取的部分贴到大图上
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# 计算小图到大图后的偏移 用来确定目标框的位置
padw = x1a - x1b
padh = y1a - y1b
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
#标签裁剪
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels) #得到新的label的坐标
segments4.extend(segments)
# Concat/clip labels
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img4, labels4 = replicate(img4, labels4) # replicate
# Augment
# 将图片中没目标的 取别的图进行粘贴
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
# 随机变换
img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img4, labels4 #返回数据增强的后的图片和标签加载图片
#加载图片并根据设定输入大小与图片源大小比例进行resize
def load_image(self, i):
# Loads 1 image from dataset index 'i', returns (im, original hw, resized hw)
im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i], #判断有没有这个图片
if im is None: # not cached in RAM
if fn.exists(): # load npy
im = np.load(fn)
else: # read image
im = cv2.imread(f) # BGR
assert im is not None, f'Image Not Found {f}'
h0, w0 = im.shape[:2] # orig hw
r = self.img_size / max(h0, w0) # ratio
#根据r选择不同的插值
if r != 1: # if sizes are not equal
im = cv2.resize(im,
(int(w0 * r), int(h0 * r)),
interpolation=cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA)
return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
else:
return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized色彩变换
#翻转色调
#——————————————————————————————————————————————————————————————————————————————————————————————————
if self.augment:
# Albumentations
#进一步数据增强
img,img2, labels = self.albumentations(img,img2, labels)
nl = len(labels) # update after albumentations
# HSV color-space
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
augment_hsv(img2, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
img2 = np.flipud(img2)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img) #沿轴 1(左/右)反转元素的顺序。
img2 = np.fliplr(img2)
if nl:
labels[:, 1] = 1 - labels[:, 1]
# Cutouts
# labels = cutout(img, labels, p=0.5)
# nl = len(labels) # update after cutout
labels_out = torch.zeros((nl, 6))
if nl:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img2 = img2.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img2 = np.ascontiguousarray(img2)
return torch.from_numpy(img),torch.from_numpy(img2), labels_out, self.im_files[index],self.im_files2[index], shapes,shapes2随机透视变换
随机变换的yaml文件在data/hyps/hyp.scratch-high.yaml
#图像缩放:保持图片宽高不变,剩下部分采用灰色填充
def letterbox(im, new_shape=(640, 640), color=(114, 114, 114), auto=True, scaleFill=False, scaleup=True, stride=32): #color是填充的颜色
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
#缩放到输入大小的时候,如果没有上采样,则只进行下采样,上采样会使图片模糊,影响性能
if not scaleup: # only scale down, do not scale up (for better val mAP)
r = min(r, 1.0)
# Compute padding 计算填充
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle 获取最小的矩阵填充
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
#如果scaleFill=True,则不进行填充,直接由resize改变
elif scaleFill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
#计算上下填充大小
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
#什么位置进行填充
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
#进行填充
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
#随机透视变换
def random_perspective(im, targets=(), segments=(), degrees=10, translate=.1, scale=.1, shear=10, perspective=0.0,
border=(0, 0)):
# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(0.1, 0.1), scale=(0.9, 1.1), shear=(-10, 10))
# targets = [cls, xyxy]
height = im.shape[0] + border[0] * 2 # shape(h,w,c)
width = im.shape[1] + border[1] * 2
# Center
C = np.eye(3) #构造单位阵
C[0, 2] = -im.shape[1] / 2 # x translation (pixels)
C[1, 2] = -im.shape[0] / 2 # y translation (pixels)
# Perspective 透视变换
P = np.eye(3)
P[2, 0] = random.uniform(-perspective, perspective) # x perspective (about y)
P[2, 1] = random.uniform(-perspective, perspective) # y perspective (about x)
# Rotation and Scale
R = np.eye(3)
a = random.uniform(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
s = random.uniform(1 - scale, 1 + scale)
# s = 2 ** random.uniform(-scale, scale)
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear 裁剪的放射矩阵系数
S = np.eye(3)
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Translation 平移矩阵系数
T = np.eye(3)
T[0, 2] = random.uniform(0.5 - translate, 0.5 + translate) * width # x translation (pixels)
T[1, 2] = random.uniform(0.5 - translate, 0.5 + translate) * height # y translation (pixels)
# Combined rotation matrix
#融合所有矩阵 得到最终变换的矩阵
M = T @ S @ R @ P @ C # order of operations (right to left) is IMPORTANT
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if perspective: #透视变换,平行线不再平行
im = cv2.warpPerspective(im, M, dsize=(width, height), borderValue=(114, 114, 114))
else: # affine #放射变换 平行线依旧平行
im = cv2.warpAffine(im, M[:2], dsize=(width, height), borderValue=(114, 114, 114))
# Visualize
# import matplotlib.pyplot as plt
# ax = plt.subplots(1, 2, figsize=(12, 6))[1].ravel()
# ax[0].imshow(im[:, :, ::-1]) # base
# ax[1].imshow(im2[:, :, ::-1]) # warped
#调整标签信息
# Transform label coordinates
n = len(targets)
if n:
use_segments = any(x.any() for x in segments)
new = np.zeros((n, 4))
if use_segments: # warp segments
segments = resample_segments(segments) # upsample
for i, segment in enumerate(segments):
xy = np.ones((len(segment), 3))
xy[:, :2] = segment
xy = xy @ M.T # transform
xy = xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2] # perspective rescale or affine
# clip
new[i] = segment2box(xy, width, height)
else: # warp boxes
xy = np.ones((n * 4, 3))
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform
xy = (xy[:, :2] / xy[:, 2:3] if perspective else xy[:, :2]).reshape(n, 8) # perspective rescale or affine
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
new = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip 剪裁过小的框
new[:, [0, 2]] = new[:, [0, 2]].clip(0, width)
new[:, [1, 3]] = new[:, [1, 3]].clip(0, height)
# filter candidates 目标框过滤
i = box_candidates(box1=targets[:, 1:5].T * s, box2=new.T, area_thr=0.01 if use_segments else 0.10) #最终得到i个目标框
targets = targets[i]
targets[:, 1:5] = new[i]
return im, targets
#找到合适的目标框
def box_candidates(box1, box2, wh_thr=2, ar_thr=100, area_thr=0.1, eps=1e-16): # box1(4,n), box2(4,n)
# Compute candidate boxes: box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
ar = np.maximum(w2 / (h2 + eps), h2 / (w2 + eps)) # aspect ratio
return (w2 > wh_thr) & (h2 > wh_thr) & (w2 * h2 / (w1 * h1 + eps) > area_thr) & (ar < ar_thr) # candidates 宽度高度大于2,面积要大于阈值def cutout(im, labels, p=0.5):
# Applies image cutout augmentation https://arxiv.org/abs/1708.04552
if random.random() < p:
h, w = im.shape[:2]
scales = [0.5] * 1 + [0.25] * 2 + [0.125] * 4 + [0.0625] * 8 + [0.03125] * 16 # image size fraction
for s in scales:
mask_h = random.randint(1, int(h * s)) # create random masks
mask_w = random.randint(1, int(w * s))
# box 切掉的部分
xmin = max(0, random.randint(0, w) - mask_w // 2)
ymin = max(0, random.randint(0, h) - mask_h // 2)
xmax = min(w, xmin + mask_w)
ymax = min(h, ymin + mask_h)
# apply random color mask 随机颜色填充
im[ymin:ymax, xmin:xmax] = [random.randint(64, 191) for _ in range(3)]
# return unobscured labels 更新目标框
if len(labels) and s > 0.03:
box = np.array([xmin, ymin, xmax, ymax], dtype=np.float32)
ioa = bbox_ioa(box, labels[:, 1:5]) # intersection over area
labels = labels[ioa < 0.60] # remove >60% obscured labels
return labels2.4.3 utils/datasets.py
# Parameters
HELP_URL = 'https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data'
IMG_FORMATS = 'bmp', 'dng', 'jpeg', 'jpg', 'mpo', 'png', 'tif', 'tiff', 'webp' # include image suffixes #格式支持的图片
VID_FORMATS = 'asf', 'avi', 'gif', 'm4v', 'mkv', 'mov', 'mp4', 'mpeg', 'mpg', 'ts', 'wmv' # include video suffixes #视频格式
BAR_FORMAT = '{l_bar}{bar:10}{r_bar}{bar:-10b}' # tqdm bar format
# Get orientation exif tag
for orientation in ExifTags.TAGS.keys():
if ExifTags.TAGS[orientation] == 'Orientation':
break
#返回文件列表的hash值
def get_hash(paths):
# Returns a single hash value of a list of paths (files or dirs)
size = sum(os.path.getsize(p) for p in paths if os.path.exists(p)) # sizes
h = hashlib.md5(str(size).encode()) # hash sizes
h.update(''.join(paths).encode()) # hash paths
return h.hexdigest() # return hash
#获取图片宽高
def exif_size(img):
# Returns exif-corrected PIL size
s = img.size # (width, height)
try:
rotation = dict(img._getexif().items())[orientation]#对图片进行旋转
if rotation == 6: # rotation 270
s = (s[1], s[0])
elif rotation == 8: # rotation 90
s = (s[1], s[0])
except Exception:
pass
return s
def exif_transpose(image):
"""
Transpose a PIL image accordingly if it has an EXIF Orientation tag.
Inplace version of https://github.com/python-pillow/Pillow/blob/master/src/PIL/ImageOps.py exif_transpose()
:param image: The image to transpose.
:return: An image.
"""
exif = image.getexif()
orientation = exif.get(0x0112, 1) # default 1
if orientation > 1:
method = {2: Image.FLIP_LEFT_RIGHT,
3: Image.ROTATE_180,
4: Image.FLIP_TOP_BOTTOM,
5: Image.TRANSPOSE,
6: Image.ROTATE_270,
7: Image.TRANSVERSE,
8: Image.ROTATE_90,
}.get(orientation)
if method is not None:
image = image.transpose(method)
del exif[0x0112]
image.info["exif"] = exif.tobytes()
return image
def create_dataloader(path, imgsz, batch_size, stride, single_cls=False, hyp=None, augment=False, cache=False, pad=0.0,
rect=False, rank=-1, workers=8, image_weights=False, quad=False, prefix='', shuffle=False):
if rect and shuffle:
LOGGER.warning('WARNING: --rect is incompatible with DataLoader shuffle, setting shuffle=False')
shuffle = False
with torch_distributed_zero_first(rank): # init dataset *.cache only once if DDP
dataset = LoadImagesAndLabels(path, imgsz, batch_size,
augment=augment, # augmentation
hyp=hyp, # hyperparameters
rect=rect, # rectangular batches
cache_images=cache,
single_cls=single_cls,
stride=int(stride),
pad=pad,
image_weights=image_weights,
prefix=prefix)
batch_size = min(batch_size, len(dataset))
nd = torch.cuda.device_count() # number of CUDA devices
nw = min([os.cpu_count() // max(nd, 1), batch_size if batch_size > 1 else 0, workers]) # number of workers
sampler = None if rank == -1 else distributed.DistributedSampler(dataset, shuffle=shuffle)
loader = DataLoader if image_weights else InfiniteDataLoader # only DataLoader allows for attribute updates
return loader(dataset,
batch_size=batch_size,
shuffle=shuffle and sampler is None,
num_workers=nw,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn), dataset
class InfiniteDataLoader(dataloader.DataLoader):
""" Dataloader that reuses workers
Uses same syntax as vanilla DataLoader
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
object.__setattr__(self, 'batch_sampler', _RepeatSampler(self.batch_sampler))
self.iterator = super().__iter__()
def __len__(self):
return len(self.batch_sampler.sampler) #返回训练集图片个数
def __iter__(self):
for i in range(len(self)):
yield next(self.iterator)
class _RepeatSampler:
""" Sampler that repeats forever
Args:
sampler (Sampler)
"""
def __init__(self, sampler):
self.sampler = sampler
def __iter__(self):
while True:
yield from iter(self.sampler)
class LoadImages:
# YOLOv5 image/video dataloader, i.e. `python detect.py --source image.jpg/vid.mp4`
def __init__(self, path, img_size=640, stride=32, auto=True):
p = str(Path(path).resolve()) # os-agnostic absolute path
if '*' in p:
files = sorted(glob.glob(p, recursive=True)) # glob
elif os.path.isdir(p):
files = sorted(glob.glob(os.path.join(p, '*.*'))) # dir
elif os.path.isfile(p): #如果是文件直接获取
files = [p] # files
else:
raise Exception(f'ERROR: {p} does not exist')
#分别提取图片和视频的路径
images = [x for x in files if x.split('.')[-1].lower() in IMG_FORMATS]
videos = [x for x in files if x.split('.')[-1].lower() in VID_FORMATS]
ni, nv = len(images), len(videos) #获取数量
self.img_size = img_size
self.stride = stride
self.files = images + videos #整个图片视频放一个列表
self.nf = ni + nv # number of files
self.video_flag = [False] * ni + [True] * nv#判断是否为视频,方便后续单独处理
self.mode = 'image'
self.auto = auto
if any(videos): #是否包含视频文件
self.new_video(videos[0]) # new video
else:
self.cap = None
assert self.nf > 0, f'No images or videos found in {p}. ' \
f'Supported formats are:\nimages: {IMG_FORMATS}\nvideos: {VID_FORMATS}'
def __iter__(self): #创建迭代器对象
self.count = 0
return self
def __next__(self): #输出下一项
if self.count == self.nf:
raise StopIteration
path = self.files[self.count]
if self.video_flag[self.count]: #如果为视频
# Read video
self.mode = 'video'
ret_val, img0 = self.cap.read()
while not ret_val:
self.count += 1
self.cap.release()
if self.count == self.nf: # last video
raise StopIteration
else:
path = self.files[self.count]
self.new_video(path)
ret_val, img0 = self.cap.read()
self.frame += 1
s = f'video {self.count + 1}/{self.nf} ({self.frame}/{self.frames}) {path}: '
else:
# Read image
self.count += 1
img0 = cv2.imread(path) # BGR格式
assert img0 is not None, f'Image Not Found {path}'
s = f'image {self.count}/{self.nf} {path}: '
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride, auto=self.auto)[0] #对图片缩放填充
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB #BGR到RGB的转换
img = np.ascontiguousarray(img) #将数组转换为连续,提高速度
return path, img, img0, self.cap, s
def new_video(self, path):
self.frame = 0 #frme记录帧数
self.cap = cv2.VideoCapture(path) #初始化视频对象
self.frames = int(self.cap.get(cv2.CAP_PROP_FRAME_COUNT)) #总帧数
def __len__(self):
return self.nf # number of files
class LoadWebcam: # for inference
# YOLOv5 local webcam dataloader, i.e. `python detect.py --source 0`
def __init__(self, pipe='0', img_size=640, stride=32):
self.img_size = img_size
self.stride = stride
self.pipe = eval(pipe) if pipe.isnumeric() else pipe
self.cap = cv2.VideoCapture(self.pipe) # video capture object
self.cap.set(cv2.CAP_PROP_BUFFERSIZE, 3) # set buffer size
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if cv2.waitKey(1) == ord('q'): # q to quit
self.cap.release()
cv2.destroyAllWindows()
raise StopIteration
# Read frame
ret_val, img0 = self.cap.read()
img0 = cv2.flip(img0, 1) # flip left-right
# Print
assert ret_val, f'Camera Error {self.pipe}'
img_path = 'webcam.jpg'
s = f'webcam {self.count}: '
# Padded resize
img = letterbox(img0, self.img_size, stride=self.stride)[0]
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return img_path, img, img0, None, s
def __len__(self):
return 0
#迭代器
class LoadStreams:
# YOLOv5 streamloader, i.e. `python detect.py --source 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP streams`
def __init__(self, sources='streams.txt', img_size=640, stride=32, auto=True): #sources为一个保存多视频的文件
self.mode = 'stream'
self.img_size = img_size
self.stride = stride
if os.path.isfile(sources):
with open(sources) as f:
sources = [x.strip() for x in f.read().strip().splitlines() if len(x.strip())]
else:
sources = [sources]
n = len(sources)
self.imgs, self.fps, self.frames, self.threads = [None] * n, [0] * n, [0] * n, [None] * n
self.sources = [clean_str(x) for x in sources] # clean source names for later
self.auto = auto
#打印当前视频,视频总数,视频流地址
for i, s in enumerate(sources): # index, source
# Start thread to read frames from video stream
st = f'{i + 1}/{n}: {s}... '
if 'youtube.com/' in s or 'youtu.be/' in s: # if source is YouTube video
check_requirements(('pafy', 'youtube_dl==2020.12.2'))
import pafy
s = pafy.new(s).getbest(preftype="mp4").url # YouTube URL
s = eval(s) if s.isnumeric() else s # i.e. s = '0' local webcam
cap = cv2.VideoCapture(s)
assert cap.isOpened(), f'{st}Failed to open {s}'
#获取视频宽高
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS) # warning: may return 0 or nan
self.frames[i] = max(int(cap.get(cv2.CAP_PROP_FRAME_COUNT)), 0) or float('inf') # infinite stream fallback
self.fps[i] = max((fps if math.isfinite(fps) else 0) % 100, 0) or 30 # 30 FPS fallback
_, self.imgs[i] = cap.read() # guarantee first frame
#创建多线程读取
self.threads[i] = Thread(target=self.update, args=([i, cap, s]), daemon=True)
LOGGER.info(f"{st} Success ({self.frames[i]} frames {w}x{h} at {self.fps[i]:.2f} FPS)")
self.threads[i].start()
LOGGER.info('') # newline
# check for common shapes
#按照矩形推理形状进行填充
s = np.stack([letterbox(x, self.img_size, stride=self.stride, auto=self.auto)[0].shape for x in self.imgs])
self.rect = np.unique(s, axis=0).shape[0] == 1 # rect inference if all shapes equal
if not self.rect:
LOGGER.warning('WARNING: Stream shapes differ. For optimal performance supply similarly-shaped streams.')
def update(self, i, cap, stream):
# Read stream `i` frames in daemon thread
n, f, read = 0, self.frames[i], 1 # frame number, frame array, inference every 'read' frame
while cap.isOpened() and n < f:
n += 1
# _, self.imgs[index] = cap.read()
cap.grab()
if n % read == 0:
success, im = cap.retrieve()
if success:
self.imgs[i] = im
else:
LOGGER.warning('WARNING: Video stream unresponsive, please check your IP camera connection.')
self.imgs[i] = np.zeros_like(self.imgs[i])
cap.open(stream) # re-open stream if signal was lost
time.sleep(1 / self.fps[i]) # wait time
def __iter__(self):
self.count = -1
return self
def __next__(self):
self.count += 1
if not all(x.is_alive() for x in self.threads) or cv2.waitKey(1) == ord('q'): # q to quit
cv2.destroyAllWindows()
raise StopIteration
# Letterbox
img0 = self.imgs.copy()
img = [letterbox(x, self.img_size, stride=self.stride, auto=self.rect and self.auto)[0] for x in img0]
# Stack
img = np.stack(img, 0)
# Convert
img = img[..., ::-1].transpose((0, 3, 1, 2)) # BGR to RGB, BHWC to BCHW
img = np.ascontiguousarray(img)
return self.sources, img, img0, None, ''
def __len__(self):
return len(self.sources) # 1E12 frames = 32 streams at 30 FPS for 30 years
#根据图片找到标签路径
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
return [sb.join(x.rsplit(sa, 1)).rsplit('.', 1)[0] + '.txt' for x in img_paths]
#一、数据处理
class LoadImagesAndLabels(Dataset):
# YOLOv5 train_loader/val_loader, loads images and labels for training and validation
cache_version = 0.6 # dataset labels *.cache version
def __init__(self, path, img_size=640, batch_size=16, augment=False, hyp=None, rect=False, image_weights=False,
cache_images=False, single_cls=False, stride=32, pad=0.0, prefix=''):
#创建参数
self.img_size = img_size
self.augment = augment #是否数据增强
self.hyp = hyp #超参数
self.image_weights = image_weights #图片采样权重
self.rect = False if image_weights else rect #矩阵训练
#mosaic数据增强
self.mosaic = self.augment and not self.rect # load 4 images at a time into a mosaic (only during training)
self.mosaic_border = [-img_size // 2, -img_size // 2]
self.stride = stride #下采样步数
self.path = path
self.albumentations = Albumentations() if augment else None
try:
#1、获取图片
f = [] # image files
for p in path if isinstance(path, list) else [path]:
p = Path(p) # os-agnostic
if p.is_dir(): # dir
f += glob.glob(str(p / '**' / '*.*'), recursive=True)
# f = list(p.rglob('*.*')) # pathlib
elif p.is_file(): # file
with open(p) as t:
t = t.read().strip().splitlines()
parent = str(p.parent) + os.sep #上级目录os.sep是分隔符
f += [x.replace('./', parent) if x.startswith('./') else x for x in t] # local to global path
# f += [p.parent / x.lstrip(os.sep) for x in t] # local to global path (pathlib)
else:
raise Exception(f'{prefix}{p} does not exist')
# 2、过滤不支持格式的图片
self.im_files = sorted(x.replace('/', os.sep) for x in f if x.split('.')[-1].lower() in IMG_FORMATS)
# self.img_files = sorted([x for x in f if x.suffix[1:].lower() in IMG_FORMATS]) # pathlib
assert self.im_files, f'{prefix}No images found'
except Exception as e:
raise Exception(f'{prefix}Error loading data from {path}: {e}\nSee {HELP_URL}')
# Check cache
self.label_files = img2label_paths(self.im_files) # 获取labels
cache_path = (p if p.is_file() else Path(self.label_files[0]).parent).with_suffix('.cache')
try:
cache, exists = np.load(cache_path, allow_pickle=True).item(), True # load dict
assert cache['version'] == self.cache_version # same version
assert cache['hash'] == get_hash(self.label_files + self.im_files) # same hash 判断hash值是否改变
except Exception:
cache, exists = self.cache_labels(cache_path, prefix), False # cache
# Display cache 过滤结果打印
nf, nm, ne, nc, n = cache.pop('results') # found, missing, empty, corrupt, total
if exists:
d = f"Scanning '{cache_path}' images and labels... {nf} found, {nm} missing, {ne} empty, {nc} corrupt"
tqdm(None, desc=prefix + d, total=n, initial=n, bar_format=BAR_FORMAT) # display cache results
if cache['msgs']:
LOGGER.info('\n'.join(cache['msgs'])) # display warnings
assert nf > 0 or not augment, f'{prefix}No labels in {cache_path}. Can not train without labels. See {HELP_URL}'
# Read cache
[cache.pop(k) for k in ('hash', 'version', 'msgs')] # remove items
labels, shapes, self.segments = zip(*cache.values())
self.labels = list(labels)
self.shapes = np.array(shapes, dtype=np.float64)
self.im_files = list(cache.keys()) # update 图片列表
self.label_files = img2label_paths(cache.keys()) # update 标签列表
n = len(shapes) # number of images
bi = np.floor(np.arange(n) / batch_size).astype(np.int) # batch index 将每一张图片batch索引
nb = bi[-1] + 1 # number of batches
self.batch = bi # batch index of image
self.n = n
self.indices = range(n)
# Update labels
#过滤类别
include_class = [] # filter labels to include only these classes (optional)
include_class_array = np.array(include_class).reshape(1, -1)
for i, (label, segment) in enumerate(zip(self.labels, self.segments)):
if include_class:
j = (label[:, 0:1] == include_class_array).any(1)
self.labels[i] = label[j]
if segment:
self.segments[i] = segment[j]
if single_cls: # single-class training, merge all classes into 0 把所有目标归为一类
self.labels[i][:, 0] = 0
if segment:
self.segments[i][:, 0] = 0
# Rectangular Training
#是否采用矩形构造
if self.rect:
# Sort by aspect ratio
s = self.shapes # wh
ar = s[:, 1] / s[:, 0] # aspect ratio #高和宽的比
irect = ar.argsort() #根据ar排序
self.im_files = [self.im_files[i] for i in irect]
self.label_files = [self.label_files[i] for i in irect]
self.labels = [self.labels[i] for i in irect]
self.shapes = s[irect] # wh
ar = ar[irect]
# Set training image shapes 设置训练图片的shapes
# 对同个batch进行尺寸处理
shapes = [[1, 1]] * nb
for i in range(nb):
ari = ar[bi == i]
mini, maxi = ari.min(), ari.max()
if maxi < 1:
shapes[i] = [maxi, 1]
elif mini > 1:
shapes[i] = [1, 1 / mini]
self.batch_shapes = np.ceil(np.array(shapes) * img_size / stride + pad).astype(np.int) * stride
# Cache images into RAM/disk for faster training (WARNING: large datasets may exceed system resources)
self.ims = [None] * n
self.npy_files = [Path(f).with_suffix('.npy') for f in self.im_files]
if cache_images:
gb = 0 # Gigabytes of cached images
self.im_hw0, self.im_hw = [None] * n, [None] * n
fcn = self.cache_images_to_disk if cache_images == 'disk' else self.load_image
results = ThreadPool(NUM_THREADS).imap(fcn, range(n))
pbar = tqdm(enumerate(results), total=n, bar_format=BAR_FORMAT)
for i, x in pbar:
if cache_images == 'disk':
gb += self.npy_files[i].stat().st_size
else: # 'ram'
self.ims[i], self.im_hw0[i], self.im_hw[i] = x # im, hw_orig, hw_resized = load_image(self, i)
gb += self.ims[i].nbytes
pbar.desc = f'{prefix}Caching images ({gb / 1E9:.1f}GB {cache_images})'
pbar.close()
#标签过滤
def cache_labels(self, path=Path('./labels.cache'), prefix=''):
# Cache dataset labels, check images and read shapes
x = {} # dict
nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels..."
with Pool(NUM_THREADS) as pool:
pbar = tqdm(pool.imap(verify_image_label, zip(self.im_files, self.label_files, repeat(prefix))),
desc=desc, total=len(self.im_files), bar_format=BAR_FORMAT)
for im_file, lb, shape, segments, nm_f, nf_f, ne_f, nc_f, msg in pbar:
nm += nm_f
nf += nf_f
ne += ne_f
nc += nc_f
if im_file:
x[im_file] = [lb, shape, segments]# 保存为字典
if msg:
msgs.append(msg)
pbar.desc = f"{desc}{nf} found, {nm} missing, {ne} empty, {nc} corrupt"
pbar.close()
if msgs:
LOGGER.info('\n'.join(msgs))
if nf == 0:
LOGGER.warning(f'{prefix}WARNING: No labels found in {path}. See {HELP_URL}')
x['hash'] = get_hash(self.label_files + self.im_files)
x['results'] = nf, nm, ne, nc, len(self.im_files)
x['msgs'] = msgs # warnings
x['version'] = self.cache_version # cache version
try:
np.save(path, x) # save cache for next time 保存本地方便下次使用
path.with_suffix('.cache.npy').rename(path) # remove .npy suffix
LOGGER.info(f'{prefix}New cache created: {path}')
except Exception as e:
LOGGER.warning(f'{prefix}WARNING: Cache directory {path.parent} is not writeable: {e}') # not writeable
return x
def __len__(self):
return len(self.im_files)
# def __iter__(self):
# self.count = -1
# print('ran dataset iter')
# #self.shuffled_vector = np.random.permutation(self.nF) if self.augment else np.arange(self.nF)
# return self
#二、图片增强
def __getitem__(self, index):#根据每个类别数量获得图片采样权重,获取新的下标
index = self.indices[index] # linear, shuffled, or image_weights
hyp = self.hyp
mosaic = self.mosaic and random.random() < hyp['mosaic']
if mosaic:
# Load mosaic
img, labels = self.load_mosaic(index) #mosaic数据增强的方式加载图片标签
shapes = None
#是否做Mixup数据增强
# MixUp augmentation
if random.random() < hyp['mixup']:
img, labels = mixup(img, labels, *self.load_mosaic(random.randint(0, self.n - 1)))
else:
# Load image resize图片
img, (h0, w0), (h, w) = self.load_image(index)
# Letterbox
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
img, ratio, pad = letterbox(img, shape, auto=False, scaleup=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
labels = self.labels[index].copy()
if labels.size: # normalized xywh to pixel xyxy format
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], ratio[0] * w, ratio[1] * h, padw=pad[0], padh=pad[1])
if self.augment:
img, labels = random_perspective(img, labels,
degrees=hyp['degrees'],
translate=hyp['translate'],
scale=hyp['scale'],
shear=hyp['shear'],
perspective=hyp['perspective'])
nl = len(labels) # number of labels
if nl:
labels[:, 1:5] = xyxy2xywhn(labels[:, 1:5], w=img.shape[1], h=img.shape[0], clip=True, eps=1E-3)
if self.augment:
# Albumentations
#进一步数据增强
img, labels = self.albumentations(img, labels)
nl = len(labels) # update after albumentations
# HSV color-space
augment_hsv(img, hgain=hyp['hsv_h'], sgain=hyp['hsv_s'], vgain=hyp['hsv_v'])
# Flip up-down
if random.random() < hyp['flipud']:
img = np.flipud(img)
if nl:
labels[:, 2] = 1 - labels[:, 2]
# Flip left-right
if random.random() < hyp['fliplr']:
img = np.fliplr(img)
if nl:
labels[:, 1] = 1 - labels[:, 1]
# Cutouts
# labels = cutout(img, labels, p=0.5)
# nl = len(labels) # update after cutout
labels_out = torch.zeros((nl, 6))
if nl:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
return torch.from_numpy(img), labels_out, self.im_files[index], shapes
#加载图片并根据设定输入大小与图片源大小比例进行resize
def load_image(self, i):
# Loads 1 image from dataset index 'i', returns (im, original hw, resized hw)
im, f, fn = self.ims[i], self.im_files[i], self.npy_files[i], #判断有没有这个图片
if im is None: # not cached in RAM
if fn.exists(): # load npy
im = np.load(fn)
else: # read image
im = cv2.imread(f) # BGR
assert im is not None, f'Image Not Found {f}'
h0, w0 = im.shape[:2] # orig hw
r = self.img_size / max(h0, w0) # ratio
#根据r选择不同的插值
if r != 1: # if sizes are not equal
im = cv2.resize(im,
(int(w0 * r), int(h0 * r)),
interpolation=cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA)
return im, (h0, w0), im.shape[:2] # im, hw_original, hw_resized
else:
return self.ims[i], self.im_hw0[i], self.im_hw[i] # im, hw_original, hw_resized
def cache_images_to_disk(self, i):
# Saves an image as an *.npy file for faster loading
f = self.npy_files[i]
if not f.exists():
np.save(f.as_posix(), cv2.imread(self.im_files[i]))
def load_mosaic(self, index): #self自定义数据集 index要增强的索引
# YOLOv5 4-mosaic loader. Loads 1 image + 3 random images into a 4-image mosaic
labels4, segments4 = [], []
s = self.img_size
#随机选取一个中心点
yc, xc = (int(random.uniform(-x, 2 * s + x)) for x in self.mosaic_border) # mosaic center x, y
indices = [index] + random.choices(self.indices, k=3) # 3 additional image indices
#随机取其他三张图片索引
random.shuffle(indices)
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = self.load_image(index)#load_image 加载图片根据设定的输入大小与图片原大小的比例进行resize
# place img in img4
if i == 0: # top left
#初始化大图
img4 = np.full((s * 2, s * 2, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
#把原图放到左上角
x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, yc # xmin, ymin, xmax, ymax (large image)
#选取小图上的位置 如果图片越界会裁剪
x1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, h # xmin, ymin, xmax, ymax (small image)
elif i == 1: # top right
x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, s * 2), yc
x1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h
elif i == 2: # bottom left
x1a, y1a, x2a, y2a = max(xc - w, 0), yc, xc, min(s * 2, yc + h)
x1b, y1b, x2b, y2b = w - (x2a - x1a), 0, w, min(y2a - y1a, h)
elif i == 3: # bottom right
x1a, y1a, x2a, y2a = xc, yc, min(xc + w, s * 2), min(s * 2, yc + h)
x1b, y1b, x2b, y2b = 0, 0, min(w, x2a - x1a), min(y2a - y1a, h)
#小图上截取的部分贴到大图上
img4[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b] # img4[ymin:ymax, xmin:xmax]
# 计算小图到大图后的偏移 用来确定目标框的位置
padw = x1a - x1b
padh = y1a - y1b
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
#标签裁剪
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padw, padh) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
labels4.append(labels) #得到新的label的坐标
segments4.extend(segments)
# Concat/clip labels
labels4 = np.concatenate(labels4, 0)
for x in (labels4[:, 1:], *segments4):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img4, labels4 = replicate(img4, labels4) # replicate
# Augment
# 将图片中没目标的 取别的图进行粘贴
img4, labels4, segments4 = copy_paste(img4, labels4, segments4, p=self.hyp['copy_paste'])
# 随机变换
img4, labels4 = random_perspective(img4, labels4, segments4,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img4, labels4 #返回数据增强的后的图片和标签
def load_mosaic9(self, index):
# YOLOv5 9-mosaic loader. Loads 1 image + 8 random images into a 9-image mosaic
labels9, segments9 = [], []
s = self.img_size
indices = [index] + random.choices(self.indices, k=8) # 8 additional image indices
random.shuffle(indices)
hp, wp = -1, -1 # height, width previous
for i, index in enumerate(indices):
# Load image
img, _, (h, w) = self.load_image(index)
# place img in img9
if i == 0: # center
img9 = np.full((s * 3, s * 3, img.shape[2]), 114, dtype=np.uint8) # base image with 4 tiles
h0, w0 = h, w
c = s, s, s + w, s + h # xmin, ymin, xmax, ymax (base) coordinates
elif i == 1: # top
c = s, s - h, s + w, s
elif i == 2: # top right
c = s + wp, s - h, s + wp + w, s
elif i == 3: # right
c = s + w0, s, s + w0 + w, s + h
elif i == 4: # bottom right
c = s + w0, s + hp, s + w0 + w, s + hp + h
elif i == 5: # bottom
c = s + w0 - w, s + h0, s + w0, s + h0 + h
elif i == 6: # bottom left
c = s + w0 - wp - w, s + h0, s + w0 - wp, s + h0 + h
elif i == 7: # left
c = s - w, s + h0 - h, s, s + h0
elif i == 8: # top left
c = s - w, s + h0 - hp - h, s, s + h0 - hp
padx, pady = c[:2]
x1, y1, x2, y2 = (max(x, 0) for x in c) # allocate coords
# Labels
labels, segments = self.labels[index].copy(), self.segments[index].copy()
if labels.size:
labels[:, 1:] = xywhn2xyxy(labels[:, 1:], w, h, padx, pady) # normalized xywh to pixel xyxy format
segments = [xyn2xy(x, w, h, padx, pady) for x in segments]
labels9.append(labels)
segments9.extend(segments)
# Image
img9[y1:y2, x1:x2] = img[y1 - pady:, x1 - padx:] # img9[ymin:ymax, xmin:xmax]
hp, wp = h, w # height, width previous
# Offset
yc, xc = (int(random.uniform(0, s)) for _ in self.mosaic_border) # mosaic center x, y
img9 = img9[yc:yc + 2 * s, xc:xc + 2 * s]
# Concat/clip labels
labels9 = np.concatenate(labels9, 0)
labels9[:, [1, 3]] -= xc
labels9[:, [2, 4]] -= yc
c = np.array([xc, yc]) # centers
segments9 = [x - c for x in segments9]
for x in (labels9[:, 1:], *segments9):
np.clip(x, 0, 2 * s, out=x) # clip when using random_perspective()
# img9, labels9 = replicate(img9, labels9) # replicate
# Augment
img9, labels9 = random_perspective(img9, labels9, segments9,
degrees=self.hyp['degrees'],
translate=self.hyp['translate'],
scale=self.hyp['scale'],
shear=self.hyp['shear'],
perspective=self.hyp['perspective'],
border=self.mosaic_border) # border to remove
return img9, labels9
@staticmethod
def collate_fn(batch): #如何取样本
im, label, path, shapes = zip(*batch) # transposed
for i, lb in enumerate(label):
lb[:, 0] = i # add target image index for build_targets()
return torch.stack(im, 0), torch.cat(label, 0), path, shapes
@staticmethod
def collate_fn4(batch):
img, label, path, shapes = zip(*batch) # transposed
n = len(shapes) // 4
im4, label4, path4, shapes4 = [], [], path[:n], shapes[:n]
ho = torch.tensor([[0.0, 0, 0, 1, 0, 0]])
wo = torch.tensor([[0.0, 0, 1, 0, 0, 0]])
s = torch.tensor([[1, 1, 0.5, 0.5, 0.5, 0.5]]) # scale
for i in range(n): # zidane torch.zeros(16,3,720,1280) # BCHW
i *= 4
if random.random() < 0.5:
im = F.interpolate(img[i].unsqueeze(0).float(), scale_factor=2.0, mode='bilinear', align_corners=False)[
0].type(img[i].type())
lb = label[i]
else:
im = torch.cat((torch.cat((img[i], img[i + 1]), 1), torch.cat((img[i + 2], img[i + 3]), 1)), 2)
lb = torch.cat((label[i], label[i + 1] + ho, label[i + 2] + wo, label[i + 3] + ho + wo), 0) * s
im4.append(im)
label4.append(lb)
for i, lb in enumerate(label4):
lb[:, 0] = i # add target image index for build_targets()
return torch.stack(im4, 0), torch.cat(label4, 0), path4, shapes4
# Ancillary functions --------------------------------------------------------------------------------------------------
def create_folder(path='./new'):
# Create folder
if os.path.exists(path):
shutil.rmtree(path) # delete output folder
os.makedirs(path) # make new output folder
def flatten_recursive(path=DATASETS_DIR / 'coco128'):
# Flatten a recursive directory by bringing all files to top level
new_path = Path(str(path) + '_flat')
create_folder(new_path)
for file in tqdm(glob.glob(str(Path(path)) + '/**/*.*', recursive=True)):
shutil.copyfile(file, new_path / Path(file).name)
def extract_boxes(path=DATASETS_DIR / 'coco128'): # from utils.datasets import *; extract_boxes()
# Convert detection dataset into classification dataset, with one directory per class
path = Path(path) # images dir
shutil.rmtree(path / 'classifier') if (path / 'classifier').is_dir() else None # remove existing
files = list(path.rglob('*.*'))
n = len(files) # number of files
for im_file in tqdm(files, total=n):
if im_file.suffix[1:] in IMG_FORMATS:
# image
im = cv2.imread(str(im_file))[..., ::-1] # BGR to RGB
h, w = im.shape[:2]
# labels
lb_file = Path(img2label_paths([str(im_file)])[0])
if Path(lb_file).exists():
with open(lb_file) as f:
lb = np.array([x.split() for x in f.read().strip().splitlines()], dtype=np.float32) # labels
for j, x in enumerate(lb):
c = int(x[0]) # class
f = (path / 'classifier') / f'{c}' / f'{path.stem}_{im_file.stem}_{j}.jpg' # new filename
if not f.parent.is_dir():
f.parent.mkdir(parents=True)
b = x[1:] * [w, h, w, h] # box
# b[2:] = b[2:].max() # rectangle to square
b[2:] = b[2:] * 1.2 + 3 # pad
b = xywh2xyxy(b.reshape(-1, 4)).ravel().astype(np.int)
b[[0, 2]] = np.clip(b[[0, 2]], 0, w) # clip boxes outside of image
b[[1, 3]] = np.clip(b[[1, 3]], 0, h)
assert cv2.imwrite(str(f), im[b[1]:b[3], b[0]:b[2]]), f'box failure in {f}'
def autosplit(path=DATASETS_DIR / 'coco128/images', weights=(0.9, 0.1, 0.0), annotated_only=False):
""" Autosplit a dataset into train/val/test splits and save path/autosplit_*.txt files
Usage: from utils.datasets import *; autosplit()
Arguments
path: Path to images directory
weights: Train, val, test weights (list, tuple)
annotated_only: Only use images with an annotated txt file
"""
path = Path(path) # images dir
files = sorted(x for x in path.rglob('*.*') if x.suffix[1:].lower() in IMG_FORMATS) # image files only
n = len(files) # number of files
random.seed(0) # for reproducibility
indices = random.choices([0, 1, 2], weights=weights, k=n) # assign each image to a split
txt = ['autosplit_train.txt', 'autosplit_val.txt', 'autosplit_test.txt'] # 3 txt files
[(path.parent / x).unlink(missing_ok=True) for x in txt] # remove existing
print(f'Autosplitting images from {path}' + ', using *.txt labeled images only' * annotated_only)
for i, img in tqdm(zip(indices, files), total=n):
if not annotated_only or Path(img2label_paths([str(img)])[0]).exists(): # check label
with open(path.parent / txt[i], 'a') as f:
f.write('./' + img.relative_to(path.parent).as_posix() + '\n') # add image to txt file
#标签过滤
def verify_image_label(args):
# Verify one image-label pair
im_file, lb_file, prefix = args
nm, nf, ne, nc, msg, segments = 0, 0, 0, 0, '', [] # number (missing, found, empty, corrupt), message, segments
try:
# verify images
im = Image.open(im_file)
im.verify() # PIL verify
shape = exif_size(im) # image size
assert (shape[0] > 9) & (shape[1] > 9), f'image size {shape} <10 pixels'
assert im.format.lower() in IMG_FORMATS, f'invalid image format {im.format}'
if im.format.lower() in ('jpg', 'jpeg'):
with open(im_file, 'rb') as f:
f.seek(-2, 2)
if f.read() != b'\xff\xd9': # corrupt JPEG
#图片角度旋转矫正
ImageOps.exif_transpose(Image.open(im_file)).save(im_file, 'JPEG', subsampling=0, quality=100)
msg = f'{prefix}WARNING: {im_file}: corrupt JPEG restored and saved'
# verify labels
#标签过滤
if os.path.isfile(lb_file):
nf = 1 # label found
with open(lb_file) as f:
lb = [x.split() for x in f.read().strip().splitlines() if len(x)]
if any(len(x) > 6 for x in lb): # is segment 轮廓点
classes = np.array([x[0] for x in lb], dtype=np.float32) #第一个数是类别
segments = [np.array(x[1:], dtype=np.float32).reshape(-1, 2) for x in lb] # (cls, xy1...)
lb = np.concatenate((classes.reshape(-1, 1), segments2boxes(segments)), 1) # (cls, xywh)
lb = np.array(lb, dtype=np.float32) #保存边框数据
nl = len(lb)
if nl:
assert lb.shape[1] == 5, f'labels require 5 columns, {lb.shape[1]} columns detected'
assert (lb >= 0).all(), f'negative label values {lb[lb < 0]}'
#归一化
assert (lb[:, 1:] <= 1).all(), f'non-normalized or out of bounds coordinates {lb[:, 1:][lb[:, 1:] > 1]}'
_, i = np.unique(lb, axis=0, return_index=True)
if len(i) < nl: # duplicate row check
lb = lb[i] # remove duplicates #去除重复的数据
if segments:
segments = segments[i]
msg = f'{prefix}WARNING: {im_file}: {nl - len(i)} duplicate labels removed'
else:
ne = 1 # label empty
lb = np.zeros((0, 5), dtype=np.float32)
else:
nm = 1 # label missing
lb = np.zeros((0, 5), dtype=np.float32)
return im_file, lb, shape, segments, nm, nf, ne, nc, msg
except Exception as e:
nc = 1
msg = f'{prefix}WARNING: {im_file}: ignoring corrupt image/label: {e}'
return [None, None, None, None, nm, nf, ne, nc, msg]
def dataset_stats(path='coco128.yaml', autodownload=False, verbose=False, profile=False, hub=False):
""" Return dataset statistics dictionary with images and instances counts per split per class
To run in parent directory: export PYTHONPATH="$PWD/yolov5"
Usage1: from utils.datasets import *; dataset_stats('coco128.yaml', autodownload=True)
Usage2: from utils.datasets import *; dataset_stats('path/to/coco128_with_yaml.zip')
Arguments
path: Path to data.yaml or data.zip (with data.yaml inside data.zip)
autodownload: Attempt to download dataset if not found locally
verbose: Print stats dictionary
"""
def round_labels(labels):
# Update labels to integer class and 6 decimal place floats
return [[int(c), *(round(x, 4) for x in points)] for c, *points in labels]
def unzip(path):
# Unzip data.zip TODO: CONSTRAINT: path/to/abc.zip MUST unzip to 'path/to/abc/'
if str(path).endswith('.zip'): # path is data.zip
assert Path(path).is_file(), f'Error unzipping {path}, file not found'
ZipFile(path).extractall(path=path.parent) # unzip
dir = path.with_suffix('') # dataset directory == zip name
return True, str(dir), next(dir.rglob('*.yaml')) # zipped, data_dir, yaml_path
else: # path is data.yaml
return False, None, path
def hub_ops(f, max_dim=1920):
# HUB ops for 1 image 'f': resize and save at reduced quality in /dataset-hub for web/app viewing
f_new = im_dir / Path(f).name # dataset-hub image filename
try: # use PIL
im = Image.open(f)
r = max_dim / max(im.height, im.width) # ratio
if r < 1.0: # image too large
im = im.resize((int(im.width * r), int(im.height * r)))
im.save(f_new, 'JPEG', quality=75, optimize=True) # save
except Exception as e: # use OpenCV
print(f'WARNING: HUB ops PIL failure {f}: {e}')
im = cv2.imread(f)
im_height, im_width = im.shape[:2]
r = max_dim / max(im_height, im_width) # ratio
if r < 1.0: # image too large
im = cv2.resize(im, (int(im_width * r), int(im_height * r)), interpolation=cv2.INTER_AREA)
cv2.imwrite(str(f_new), im)
zipped, data_dir, yaml_path = unzip(Path(path))
with open(check_yaml(yaml_path), errors='ignore') as f:
data = yaml.safe_load(f) # data dict
if zipped:
data['path'] = data_dir # TODO: should this be dir.resolve()?
check_dataset(data, autodownload) # download dataset if missing
hub_dir = Path(data['path'] + ('-hub' if hub else ''))
stats = {'nc': data['nc'], 'names': data['names']} # statistics dictionary
for split in 'train', 'val', 'test':
if data.get(split) is None:
stats[split] = None # i.e. no test set
continue
x = []
dataset = LoadImagesAndLabels(data[split]) # load dataset
for label in tqdm(dataset.labels, total=dataset.n, desc='Statistics'):
x.append(np.bincount(label[:, 0].astype(int), minlength=data['nc']))
x = np.array(x) # shape(128x80)
stats[split] = {'instance_stats': {'total': int(x.sum()), 'per_class': x.sum(0).tolist()},
'image_stats': {'total': dataset.n, 'unlabelled': int(np.all(x == 0, 1).sum()),
'per_class': (x > 0).sum(0).tolist()},
'labels': [{str(Path(k).name): round_labels(v.tolist())} for k, v in
zip(dataset.im_files, dataset.labels)]}
if hub:
im_dir = hub_dir / 'images'
im_dir.mkdir(parents=True, exist_ok=True)
for _ in tqdm(ThreadPool(NUM_THREADS).imap(hub_ops, dataset.im_files), total=dataset.n, desc='HUB Ops'):
pass
# Profile
stats_path = hub_dir / 'stats.json'
if profile:
for _ in range(1):
file = stats_path.with_suffix('.npy')
t1 = time.time()
np.save(file, stats)
t2 = time.time()
x = np.load(file, allow_pickle=True)
print(f'stats.npy times: {time.time() - t2:.3f}s read, {t2 - t1:.3f}s write')
file = stats_path.with_suffix('.json')
t1 = time.time()
with open(file, 'w') as f:
json.dump(stats, f) # save stats *.json
t2 = time.time()
with open(file) as f:
x = json.load(f) # load hyps dict
print(f'stats.json times: {time.time() - t2:.3f}s read, {t2 - t1:.3f}s write')
# Save, print and return
if hub:
print(f'Saving {stats_path.resolve()}...')
with open(stats_path, 'w') as f:
json.dump(stats, f) # save stats.json
if verbose:
print(json.dumps(stats, indent=2, sort_keys=False))
return stats2.5 utils/metrics.py性能指标
def fitness(x):
# Model fitness as a weighted combination of metrics
w = [0.0, 0.0, 0.1, 0.9] # weights for [P, R, [email protected], [email protected]:0.95]
return (x[:, :4] * w).sum(1)
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, save_dir='.', names=(), eps=1e-16):
""" Compute the average precision, given the recall and precision curves.
Source: https://github.com/rafaelpadilla/Object-Detection-Metrics.
# Arguments
tp: True positives (nparray, nx1 or nx10).
conf: Objectness value from 0-1 (nparray).
pred_cls: Predicted object classes (nparray).
target_cls: True object classes (nparray).
plot: Plot precision-recall curve at [email protected]
save_dir: Plot save directory
# Returns
The average precision as computed in py-faster-rcnn.
"""
# Sort by objectness
i = np.argsort(-conf)
tp, conf, pred_cls = tp[i], conf[i], pred_cls[i]
# Find unique classes
unique_classes, nt = np.unique(target_cls, return_counts=True)
nc = unique_classes.shape[0] # number of classes, number of detections
# Create Precision-Recall curve and compute AP for each class
px, py = np.linspace(0, 1, 1000), [] # for plotting
ap, p, r = np.zeros((nc, tp.shape[1])), np.zeros((nc, 1000)), np.zeros((nc, 1000))
for ci, c in enumerate(unique_classes):
i = pred_cls == c
n_l = nt[ci] # number of labels
n_p = i.sum() # number of predictions
if n_p == 0 or n_l == 0:
continue
else:
# Accumulate FPs and TPs
fpc = (1 - tp[i]).cumsum(0)
tpc = tp[i].cumsum(0)
# Recall
recall = tpc / (n_l + eps) # recall curve
r[ci] = np.interp(-px, -conf[i], recall[:, 0], left=0) # negative x, xp because xp decreases
# Precision
precision = tpc / (tpc + fpc) # precision curve
p[ci] = np.interp(-px, -conf[i], precision[:, 0], left=1) # p at pr_score
# AP from recall-precision curve
for j in range(tp.shape[1]):
ap[ci, j], mpre, mrec = compute_ap(recall[:, j], precision[:, j])
if plot and j == 0:
py.append(np.interp(px, mrec, mpre)) # precision at [email protected]
# Compute F1 (harmonic mean of precision and recall)
f1 = 2 * p * r / (p + r + eps)
names = [v for k, v in names.items() if k in unique_classes] # list: only classes that have data
names = {i: v for i, v in enumerate(names)} # to dict
if plot:
plot_pr_curve(px, py, ap, Path(save_dir) / 'PR_curve.png', names)
plot_mc_curve(px, f1, Path(save_dir) / 'F1_curve.png', names, ylabel='F1')
plot_mc_curve(px, p, Path(save_dir) / 'P_curve.png', names, ylabel='Precision')
plot_mc_curve(px, r, Path(save_dir) / 'R_curve.png', names, ylabel='Recall')
i = f1.mean(0).argmax() # max F1 index
p, r, f1 = p[:, i], r[:, i], f1[:, i]
tp = (r * nt).round() # true positives
fp = (tp / (p + eps) - tp).round() # false positives
return tp, fp, p, r, f1, ap, unique_classes.astype('int32')
def compute_ap(recall, precision):
""" Compute the average precision, given the recall and precision curves
# Arguments
recall: The recall curve (list)
precision: The precision curve (list)
# Returns
Average precision, precision curve, recall curve
"""
# Append sentinel values to beginning and end
mrec = np.concatenate(([0.0], recall, [1.0]))
mpre = np.concatenate(([1.0], precision, [0.0]))
# Compute the precision envelope
mpre = np.flip(np.maximum.accumulate(np.flip(mpre)))
# Integrate area under curve
method = 'interp' # methods: 'continuous', 'interp'
if method == 'interp':
x = np.linspace(0, 1, 101) # 101-point interp (COCO)
ap = np.trapz(np.interp(x, mrec, mpre), x) # integrate
else: # 'continuous'
i = np.where(mrec[1:] != mrec[:-1])[0] # points where x axis (recall) changes
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) # area under curve
return ap, mpre, mrec
class ConfusionMatrix:
# Updated version of https://github.com/kaanakan/object_detection_confusion_matrix
def __init__(self, nc, conf=0.25, iou_thres=0.45):
self.matrix = np.zeros((nc + 1, nc + 1))
self.nc = nc # number of classes
self.conf = conf
self.iou_thres = iou_thres
def process_batch(self, detections, labels):
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
detections (Array[N, 6]), x1, y1, x2, y2, conf, class
labels (Array[M, 5]), class, x1, y1, x2, y2
Returns:
None, updates confusion matrix accordingly
"""
detections = detections[detections[:, 4] > self.conf]
gt_classes = labels[:, 0].int()
detection_classes = detections[:, 5].int()
iou = box_iou(labels[:, 1:], detections[:, :4])
x = torch.where(iou > self.iou_thres)
if x[0].shape[0]:
matches = torch.cat((torch.stack(x, 1), iou[x[0], x[1]][:, None]), 1).cpu().numpy()
if x[0].shape[0] > 1:
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 1], return_index=True)[1]]
matches = matches[matches[:, 2].argsort()[::-1]]
matches = matches[np.unique(matches[:, 0], return_index=True)[1]]
else:
matches = np.zeros((0, 3))
n = matches.shape[0] > 0
m0, m1, _ = matches.transpose().astype(np.int16)
for i, gc in enumerate(gt_classes):
j = m0 == i
if n and sum(j) == 1:
self.matrix[detection_classes[m1[j]], gc] += 1 # correct
else:
self.matrix[self.nc, gc] += 1 # background FP
if n:
for i, dc in enumerate(detection_classes):
if not any(m1 == i):
self.matrix[dc, self.nc] += 1 # background FN
def matrix(self):
return self.matrix
def tp_fp(self):
tp = self.matrix.diagonal() # true positives
fp = self.matrix.sum(1) - tp # false positives
# fn = self.matrix.sum(0) - tp # false negatives (missed detections)
return tp[:-1], fp[:-1] # remove background class
def plot(self, normalize=True, save_dir='', names=()):
try:
import seaborn as sn
array = self.matrix / ((self.matrix.sum(0).reshape(1, -1) + 1E-9) if normalize else 1) # normalize columns
array[array < 0.005] = np.nan # don't annotate (would appear as 0.00)
fig = plt.figure(figsize=(12, 9), tight_layout=True)
nc, nn = self.nc, len(names) # number of classes, names
sn.set(font_scale=1.0 if nc < 50 else 0.8) # for label size
labels = (0 < nn < 99) and (nn == nc) # apply names to ticklabels
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress empty matrix RuntimeWarning: All-NaN slice encountered
sn.heatmap(array, annot=nc < 30, annot_kws={"size": 8}, cmap='Blues', fmt='.2f', square=True, vmin=0.0,
xticklabels=names + ['background FP'] if labels else "auto",
yticklabels=names + ['background FN'] if labels else "auto").set_facecolor((1, 1, 1))
fig.axes[0].set_xlabel('True')
fig.axes[0].set_ylabel('Predicted')
fig.savefig(Path(save_dir) / 'confusion_matrix.png', dpi=250)
plt.close()
except Exception as e:
print(f'WARNING: ConfusionMatrix plot failure: {e}')
def print(self):
for i in range(self.nc + 1):
print(' '.join(map(str, self.matrix[i])))
def bbox_iou(box1, box2, x1y1x2y2=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
# Returns the IoU of box1 to box2. box1 is 4, box2 is nx4
box2 = box2.T
# Get the coordinates of bounding boxes
if x1y1x2y2: # x1, y1, x2, y2 = box1
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
else: # transform from xywh to xyxy
b1_x1, b1_x2 = box1[0] - box1[2] / 2, box1[0] + box1[2] / 2
b1_y1, b1_y2 = box1[1] - box1[3] / 2, box1[1] + box1[3] / 2
b2_x1, b2_x2 = box2[0] - box2[2] / 2, box2[0] + box2[2] / 2
b2_y1, b2_y2 = box2[1] - box2[3] / 2, box2[1] + box2[3] / 2
# Intersection area
inter = (torch.min(b1_x2, b2_x2) - torch.max(b1_x1, b2_x1)).clamp(0) * \
(torch.min(b1_y2, b2_y2) - torch.max(b1_y1, b2_y1)).clamp(0)
# Union Area
w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps
w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps
union = w1 * h1 + w2 * h2 - inter + eps
iou = inter / union
if CIoU or DIoU or GIoU:
cw = torch.max(b1_x2, b2_x2) - torch.min(b1_x1, b2_x1) # convex (smallest enclosing box) width
ch = torch.max(b1_y2, b2_y2) - torch.min(b1_y1, b2_y1) # convex height
if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1
c2 = cw ** 2 + ch ** 2 + eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 +
(b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center distance squared
if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47
v = (4 / math.pi ** 2) * torch.pow(torch.atan(w2 / h2) - torch.atan(w1 / h1), 2)
with torch.no_grad():
alpha = v / (v - iou + (1 + eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
return iou - rho2 / c2 # DIoU
c_area = cw * ch + eps # convex area
return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf
return iou # IoU
def box_iou(box1, box2):
# https://github.com/pytorch/vision/blob/master/torchvision/ops/boxes.py
"""
Return intersection-over-union (Jaccard index) of boxes.
Both sets of boxes are expected to be in (x1, y1, x2, y2) format.
Arguments:
box1 (Tensor[N, 4])
box2 (Tensor[M, 4])
Returns:
iou (Tensor[N, M]): the NxM matrix containing the pairwise
IoU values for every element in boxes1 and boxes2
"""
def box_area(box):
# box = 4xn
return (box[2] - box[0]) * (box[3] - box[1])
area1 = box_area(box1.T)
area2 = box_area(box2.T)
# inter(N,M) = (rb(N,M,2) - lt(N,M,2)).clamp(0).prod(2)
inter = (torch.min(box1[:, None, 2:], box2[:, 2:]) - torch.max(box1[:, None, :2], box2[:, :2])).clamp(0).prod(2)
return inter / (area1[:, None] + area2 - inter) # iou = inter / (area1 + area2 - inter)
def bbox_ioa(box1, box2, eps=1E-7):
""" Returns the intersection over box2 area given box1, box2. Boxes are x1y1x2y2
box1: np.array of shape(4)
box2: np.array of shape(nx4)
returns: np.array of shape(n)
"""
box2 = box2.transpose()
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[0], box1[1], box1[2], box1[3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[0], box2[1], box2[2], box2[3]
# Intersection area
inter_area = (np.minimum(b1_x2, b2_x2) - np.maximum(b1_x1, b2_x1)).clip(0) * \
(np.minimum(b1_y2, b2_y2) - np.maximum(b1_y1, b2_y1)).clip(0)
# box2 area
box2_area = (b2_x2 - b2_x1) * (b2_y2 - b2_y1) + eps
# Intersection over box2 area
return inter_area / box2_area
def wh_iou(wh1, wh2):
# Returns the nxm IoU matrix. wh1 is nx2, wh2 is mx2
wh1 = wh1[:, None] # [N,1,2]
wh2 = wh2[None] # [1,M,2]
inter = torch.min(wh1, wh2).prod(2) # [N,M]
return inter / (wh1.prod(2) + wh2.prod(2) - inter) # iou = inter / (area1 + area2 - inter)
# Plots ----------------------------------------------------------------------------------------------------------------
def plot_pr_curve(px, py, ap, save_dir='pr_curve.png', names=()):
# Precision-recall curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
py = np.stack(py, axis=1)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py.T):
ax.plot(px, y, linewidth=1, label=f'{names[i]} {ap[i, 0]:.3f}') # plot(recall, precision)
else:
ax.plot(px, py, linewidth=1, color='grey') # plot(recall, precision)
ax.plot(px, py.mean(1), linewidth=3, color='blue', label='all classes %.3f [email protected]' % ap[:, 0].mean())
ax.set_xlabel('Recall')
ax.set_ylabel('Precision')
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
fig.savefig(Path(save_dir), dpi=250)
plt.close()
def plot_mc_curve(px, py, save_dir='mc_curve.png', names=(), xlabel='Confidence', ylabel='Metric'):
# Metric-confidence curve
fig, ax = plt.subplots(1, 1, figsize=(9, 6), tight_layout=True)
if 0 < len(names) < 21: # display per-class legend if < 21 classes
for i, y in enumerate(py):
ax.plot(px, y, linewidth=1, label=f'{names[i]}') # plot(confidence, metric)
else:
ax.plot(px, py.T, linewidth=1, color='grey') # plot(confidence, metric)
y = py.mean(0)
ax.plot(px, y, linewidth=3, color='blue', label=f'all classes {y.max():.2f} at {px[y.argmax()]:.3f}')
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
plt.legend(bbox_to_anchor=(1.04, 1), loc="upper left")
fig.savefig(Path(save_dir), dpi=250)
plt.close()2.6 utils/loss.py 损失函数
def smooth_BCE(eps=0.1): # https://github.com/ultralytics/yolov3/issues/238#issuecomment-598028441
# return positive, negative label smoothing BCE targets
return 1.0 - 0.5 * eps, 0.5 * eps
class BCEBlurWithLogitsLoss(nn.Module):
# BCEwithLogitLoss() with reduced missing label effects.
def __init__(self, alpha=0.05):
super().__init__()
self.loss_fcn = nn.BCEWithLogitsLoss(reduction='none') # must be nn.BCEWithLogitsLoss()
self.alpha = alpha
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred = torch.sigmoid(pred) # prob from logits
dx = pred - true # reduce only missing label effects
# dx = (pred - true).abs() # reduce missing label and false label effects
alpha_factor = 1 - torch.exp((dx - 1) / (self.alpha + 1e-4))
loss *= alpha_factor
return loss.mean()
class FocalLoss(nn.Module):
# Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super().__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = torch.sigmoid(pred) # prob from logits
p_t = true * pred_prob + (1 - true) * (1 - pred_prob)
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = (1.0 - p_t) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
class QFocalLoss(nn.Module):
# Wraps Quality focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)
def __init__(self, loss_fcn, gamma=1.5, alpha=0.25):
super().__init__()
self.loss_fcn = loss_fcn # must be nn.BCEWithLogitsLoss()
self.gamma = gamma
self.alpha = alpha
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply FL to each element
def forward(self, pred, true):
loss = self.loss_fcn(pred, true)
pred_prob = torch.sigmoid(pred) # prob from logits
alpha_factor = true * self.alpha + (1 - true) * (1 - self.alpha)
modulating_factor = torch.abs(true - pred_prob) ** self.gamma
loss *= alpha_factor * modulating_factor
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss
class ComputeLoss:
# Compute losses
def __init__(self, model, autobalance=False):
self.sort_obj_iou = False
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['cls_pw']], device=device))
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h['obj_pw']], device=device))
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get('label_smoothing', 0.0)) # positive, negative BCE targets
# Focal loss
g = h['fl_gamma'] # focal loss gamma
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
det = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(det.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.ssi = list(det.stride).index(16) if autobalance else 0 # stride 16 index
self.BCEcls, self.BCEobj, self.gr, self.hyp, self.autobalance = BCEcls, BCEobj, 1.0, h, autobalance
for k in 'na', 'nc', 'nl', 'anchors':
setattr(self, k, getattr(det, k))
def __call__(self, p, targets): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device)
tcls, tbox, indices, anchors = self.build_targets(p, targets) # targets
# Losses
for i, pi in enumerate(p): # layer index, layer predictions
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression
pxy = ps[:, :2].sigmoid() * 2 - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1) # predicted box
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness
score_iou = iou.detach().clamp(0).type(tobj.dtype)
if self.sort_obj_iou:
sort_id = torch.argsort(score_iou)
b, a, gj, gi, score_iou = b[sort_id], a[sort_id], gj[sort_id], gi[sort_id], score_iou[sort_id]
tobj[b, a, gj, gi] = (1.0 - self.gr) + self.gr * score_iou # iou ratio
# Classification
if self.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], self.cn, device=device) # targets
t[range(n), tcls[i]] = self.cp
lcls += self.BCEcls(ps[:, 5:], t) # BCE
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
obji = self.BCEobj(pi[..., 4], tobj)
lobj += obji * self.balance[i] # obj loss
if self.autobalance:
self.balance[i] = self.balance[i] * 0.9999 + 0.0001 / obji.detach().item()
if self.autobalance:
self.balance = [x / self.balance[self.ssi] for x in self.balance]
lbox *= self.hyp['box']
lobj *= self.hyp['obj']
lcls *= self.hyp['cls']
bs = tobj.shape[0] # batch size
return (lbox + lobj + lcls) * bs, torch.cat((lbox, lobj, lcls)).detach()
def build_targets(self, p, targets):
# Build targets for compute_loss(), input targets(image,class,x,y,w,h)
na, nt = self.na, targets.shape[0] # number of anchors, targets
tcls, tbox, indices, anch = [], [], [], []
gain = torch.ones(7, device=targets.device) # normalized to gridspace gain
ai = torch.arange(na, device=targets.device).float().view(na, 1).repeat(1, nt) # same as .repeat_interleave(nt)
targets = torch.cat((targets.repeat(na, 1, 1), ai[:, :, None]), 2) # append anchor indices
g = 0.5 # bias
off = torch.tensor([[0, 0],
[1, 0], [0, 1], [-1, 0], [0, -1], # j,k,l,m
# [1, 1], [1, -1], [-1, 1], [-1, -1], # jk,jm,lk,lm
], device=targets.device).float() * g # offsets
for i in range(self.nl):
anchors, shape = self.anchors[i], p[i].shape
gain[2:6] = torch.tensor(p[i].shape)[[3, 2, 3, 2]] # xyxy gain
# Match targets to anchors
t = targets * gain
if nt:
# Matches
r = t[:, :, 4:6] / anchors[:, None] # wh ratio
j = torch.max(r, 1 / r).max(2)[0] < self.hyp['anchor_t'] # compare
# j = wh_iou(anchors, t[:, 4:6]) > model.hyp['iou_t'] # iou(3,n)=wh_iou(anchors(3,2), gwh(n,2))
t = t[j] # filter
# Offsets
gxy = t[:, 2:4] # grid xy
gxi = gain[[2, 3]] - gxy # inverse
j, k = ((gxy % 1 < g) & (gxy > 1)).T
l, m = ((gxi % 1 < g) & (gxi > 1)).T
j = torch.stack((torch.ones_like(j), j, k, l, m))
t = t.repeat((5, 1, 1))[j]
offsets = (torch.zeros_like(gxy)[None] + off[:, None])[j]
else:
t = targets[0]
offsets = 0
# Define
b, c = t[:, :2].long().T # image, class
gxy = t[:, 2:4] # grid xy
gwh = t[:, 4:6] # grid wh
gij = (gxy - offsets).long()
gi, gj = gij.T # grid xy indices
# Append
a = t[:, 6].long() # anchor indices
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
tbox.append(torch.cat((gxy - gij, gwh), 1)) # box
anch.append(anchors[a]) # anchors
tcls.append(c) # class
return tcls, tbox, indices, anch2.7 utils/autoanchor.py 自动锚框
def check_anchor_order(m):
# Check anchor order against stride order for YOLOv5 Detect() module m, and correct if necessary
a = m.anchors.prod(-1).view(-1) # anchor area
da = a[-1] - a[0] # delta a
ds = m.stride[-1] - m.stride[0] # delta s
if da.sign() != ds.sign(): # same order
LOGGER.info(f'{PREFIX}Reversing anchor order')
m.anchors[:] = m.anchors.flip(0)
#自动计算最佳锚框
def check_anchors(dataset, model, thr=4.0, imgsz=640):
#thr阈值
# Check anchor fit to data, recompute if necessary
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # 标签的wh值
def metric(k): # compute metric
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
best = x.max(1)[0] # best_x
aat = (x > 1 / thr).float().sum(1).mean() # anchors above threshold
bpr = (best > 1 / thr).float().mean() # best possible recall
return bpr, aat
anchors = m.anchors.clone() * m.stride.to(m.anchors.device).view(-1, 1, 1) # current anchors
bpr, aat = metric(anchors.cpu().view(-1, 2))
s = f'\n{PREFIX}{aat:.2f} anchors/target, {bpr:.3f} Best Possible Recall (BPR). '
if bpr > 0.98: # threshold to recompute 小于阈值会通过kmeans聚类新的锚框
LOGGER.info(emojis(f'{s}Current anchors are a good fit to dataset ✅'))
else:
LOGGER.info(emojis(f'{s}Anchors are a poor fit to dataset ⚠️, attempting to improve...'))
na = m.anchors.numel() // 2 # number of anchors
try:
anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
except Exception as e:
LOGGER.info(f'{PREFIX}ERROR: {e}')
new_bpr = metric(anchors)[0]
if new_bpr > bpr: # replace anchors
anchors = torch.tensor(anchors, device=m.anchors.device).type_as(m.anchors)
m.anchors[:] = anchors.clone().view_as(m.anchors) / m.stride.to(m.anchors.device).view(-1, 1, 1) # loss
check_anchor_order(m)
s = f'{PREFIX}Done ✅ (optional: update model *.yaml to use these anchors in the future)'
else:
s = f'{PREFIX}Done ⚠️ (original anchors better than new anchors, proceeding with original anchors)'
LOGGER.info(emojis(s))
#对anchors做kmeans聚类
def kmean_anchors(dataset='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
""" Creates kmeans-evolved anchors from training dataset
Arguments:
dataset: path to data.yaml, or a loaded dataset
n: number of anchors
img_size: image size used for training
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
gen: generations to evolve anchors using genetic algorithm
verbose: print all results
Return:
k: kmeans evolved anchors
Usage:
from utils.autoanchor import *; _ = kmean_anchors()
"""
from scipy.cluster.vq import kmeans
npr = np.random
thr = 1 / thr
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1 / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def anchor_fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k, verbose=True):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
s = f'{PREFIX}thr={thr:.2f}: {bpr:.4f} best possible recall, {aat:.2f} anchors past thr\n' \
f'{PREFIX}n={n}, img_size={img_size}, metric_all={x.mean():.3f}/{best.mean():.3f}-mean/best, ' \
f'past_thr={x[x > thr].mean():.3f}-mean: '
for i, x in enumerate(k):
s += '%i,%i, ' % (round(x[0]), round(x[1]))
if verbose:
LOGGER.info(s[:-2])
return k
if isinstance(dataset, str): # *.yaml file
with open(dataset, errors='ignore') as f:
data_dict = yaml.safe_load(f) # model dict
from utils.datasets import LoadImagesAndLabels
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
# Get label wh
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
# Filter
i = (wh0 < 3.0).any(1).sum() #目标框宽高小于3警告
if i:
LOGGER.info(f'{PREFIX}WARNING: Extremely small objects found: {i} of {len(wh0)} labels are < 3 pixels in size')
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# wh = wh * (npr.rand(wh.shape[0], 1) * 0.9 + 0.1) # multiply by random scale 0-1
# Kmeans init
try:
LOGGER.info(f'{PREFIX}Running kmeans for {n} anchors on {len(wh)} points...')
assert n <= len(wh) # apply overdetermined constraint
s = wh.std(0) # sigmas for whitening
k = kmeans(wh / s, n, iter=30)[0] * s # points
assert n == len(k) # kmeans may return fewer points than requested if wh is insufficient or too similar
except Exception:
LOGGER.warning(f'{PREFIX}WARNING: switching strategies from kmeans to random init')
k = np.sort(npr.rand(n * 2)).reshape(n, 2) * img_size # random init
wh, wh0 = (torch.tensor(x, dtype=torch.float32) for x in (wh, wh0))
k = print_results(k, verbose=False)
# Plot
# k, d = [None] * 20, [None] * 20
# for i in tqdm(range(1, 21)):
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
# fig, ax = plt.subplots(1, 2, figsize=(14, 7), tight_layout=True)
# ax = ax.ravel()
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
# fig.savefig('wh.png', dpi=200)
# Evolve
f, sh, mp, s = anchor_fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
v = ((npr.random(sh) < mp) * random.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
kg = (k.copy() * v).clip(min=2.0)
fg = anchor_fitness(kg)
if fg > f: #更好的锚框值
f, k = fg, kg.copy() #使用进化后的锚框
pbar.desc = f'{PREFIX}Evolving anchors with Genetic Algorithm: fitness = {f:.4f}'
if verbose:
print_results(k, verbose)
return print_results(k)