前言
回车换行:
CR(Carriage Return)表示回车
LF(Line Feed)表示换行
Dos和Windows采用回车+换行(CR+LF)表示下一行
而UNIX/Linux采用换行符(LF)表示下一行
苹果机(MAC OS系统)则采用回车符(CR)表示下一行
Windows下编写的Shell脚本,直接放到linux/unix下执行会报错,就是因为行结束符不一样导致的
'\r'是回车,前者使光标到行首,(carriage return)ASCII码(0x0D)
'\n'是换行,后者使光标下移一格,(line feed)ASCII码(0xoA)
\r 是回车,return
\n 是换行,newline
回车换行一般在字符串末尾出现
三种括号:
{n,m}:表示前面的模式至少出现n次,至多出现m次
[abc]:表示出现这些字符的集合,无所谓顺序,只要出现就可以匹配搭配
():匹配这个模式并且获取这个模式
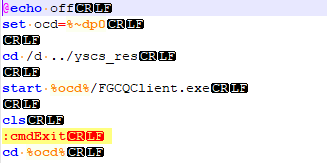
多行匹配:
((.|\n)*?)
.:表示匹配除了换行符以外的字符
\n:匹配换行符
*?:尽可能的少的重复
转义字符:左高右底,倾斜45度,转义字符顾名思义就是将一个字符加上\就表示一个特殊的符号了
时刻牢记:匹配字符串和数字任意组合是加*而不是?
^表示行首
$表示行尾不表示\n
[A-Za-z0-9]*:表示前面匹配若干个这样的组合,没有顺序制约
官方文档的介绍1:[]中括号 表示的是一个集合 我们把想要搜索的字符都放在这个括号里即可,这里没有顺序,比如:[asd],那就会去找本文中含有这些个字符,他们之间没有先后顺序,这一点很重要
1:如果想匹配除了这些字符,可以在前面加一个^,即 [ ^asd]
2:如果想匹配一个区间的字母,可以在中间加一个-,即[a-z],匹配所有的小写字母
[A-Z]匹配所有的大写字母,[A-Za-z]匹配所有的大小写字母,[0-9]匹配所有的数组
[]和{m,n}结合使用
匹配紧挨着的第一个[]
也就是匹配紧挨着的第一个模式
/^Chapter|Section [1-9][0-9][a-z]{1,2}$/
Section 22aa
学好正则表达式,是非常重要的
基础语法
runoo+b,可以匹配 runoob、runooob、runoooooob 等,+ 号代表前面的字符必须至少出现一次(1次或多次)
runoo * b,可以匹配 runob、runoob、runoooooob 等,* 号代表前面的字符可以不出现,也可以出现一次或者多次(0次、或1次、或多次)
colou?r 可以匹配 color 或者 colour,? 问号代表前面的字符最多只可以出现一次(0次、或1次)
.:匹配除了\n换行符以外的任何单个字符
.*:表示贪婪模式匹配,如果在后面加上?表示懒惰匹配,只匹配最短的
.+:表示贪婪模式匹配,如果在后面加上?表示懒惰匹配,只匹配最短的
待匹配的字符串:aabab
表达式:(a.b) 匹配结果:aabab
表达式 (a.?b) 匹配结果:aab ab
表达式:(a.+b) 匹配结果:aabab
表达式:(a.+?b) 匹配结果:aab
感悟1:
.:匹配除换行符 \n 之外的任何单字符
=.*
上面这个表达式匹配以等号作为开头的所有字符串
这个=号可以在一个字符串的任何一个位置开始匹配
感悟2:

*:代表前面的字符串可以出现>=0次
+:代表前面的字符串可以出现>=1次
?:代表前面的字符串可以出现<=1次
.:点号是一个牛逼的符号,在我们进行匹配设定的时候,他是一个匹配开始的符号,例子如下:
[1-9].*:匹配所有以数字开头的字符串,数字的范围是[1-9]
a.*:匹配所有以字符a开头的字符串
():小括号的作用和点号有点像,点号是紧跟在匹配的字符后边的,但有些时候要匹配一个字符串中的存在的一些字符的时候,他们的位置不固定,就要用到小括号,比如[1-9][1-9](.*)from(.*)xyz,要匹配一个字符串中前两个字符是数字,中间含有from,结尾是xyz,表达式就要这么写
感悟3:
以下列出 ?=、?<=、?!、?<! 的使用区别
hzj(?=[\d]{3,3}):放在表达式后面,表示待搜索的内容后面必须有三个连续的数字,注意待搜索的内容是 “hzj”
hzj(?![\d]{3,3}):放在表达式后面,表示待搜索的内容后面必须没有三个连续的数字,注意待搜索的内容是 “hzj”
(?<=[\d]{3,3})hzj:放在表达式前面,表示待搜索的内容前面必须有三个连续的数字,注意待搜索的内容是 “hzj”
(?<![\d]{3,3})hzj:放在表达式前面,表示待搜索的内容前面必须没有三个连续的数字,注意待搜索的内容是 “hzj”
说白了加个<,表示放在前面,不加就放在后面
情景
情景1:
匹配以abc开头,以xyz结尾的字符串
abc(.*)xyz
情景2:
匹配以abc开头,中间含有from,以xyz结尾的字符串
abc(?=.*from)(.*)xyz
其实此处也可以扩展,比如下面这个字符串,我只想把=号后面的部分去掉,
正则表达式也可这么写:=(.*); 然后全局替换即可
this.stencilSep = cpy.stencilSep;
情景3:
替换 rawget(item, ‘end_time’) 为item[“end_time”]
形如:AAA(BBB,“aaa”)==>BBB[“aaa”]
本例子:
匹配表达式:rawget\((\w+)\s*,\s*(.*)\)
替换表达式:$1[$2]
情景4:
替换string.format(‘tihuan id = %d’,“zm”))为tihuan id = %d’.format(“zm”)
形如:AAA.func(“hzj”,“zm”)===>“hzj”.func(“zm”)
string\.format\((.*)\s*,\s*(.*)\)
$1.format($2)
解释:这是一个非常实用的用法
转义字符:. ( )
子表达式1:(.) 这个只可以一行匹配,遇到逗号结束
子表达式1:(.)\s* 这个只可以多行匹配,遇到逗号结束
子表达式2:(.) 这个只可以一行匹配,遇到括号结束
子表达式2:\s(.*) 这个只可以一行匹配,遇到括号结束
string.format(zmwohengni,50) //单行
string.format(zmwohengni, //多行
50)
意思就是:AAA(子表达式1,子表达式2)
$1表示第一个子表达式里的内容,$2表示第二个子表达式
情景5:
将
CrossWorldBossHelper.getParameterStr (keyIndex) {
替换
export function getParameterStr (keyIndex){
正则表达式:CrossWorldBossHelper.(.*).\{
替换表达式:export function $1{
注意:$1 表示的就是(.*)的内容
情景6:
生成get set 方法
public posX:number = 0;
public posY:number = 0;
public posZ:number = 0;
public dirX:number = 0;
public dirY:number = 0;
public dirZ:number = 0;
public colR:number = 0;
public colG:number = 0;
public colB:number = 0;
public colA:number = 1.0;//透明通道
search:public (.*.):number = (.*.)
replace:public get $1():number{return this._$1}; \n public set $1(p:number){this._$1 = p};
情景7
看图说话,我想把下面五个变为最上面的那个格式,
注意到下面五个距离左边框都有一定的空格,还有就是五个当中有两个是‘’,有三个是“”,
OK分析完毕
this.u_cubeCoord_loc = gl.getUniformLocation(_glID, glvert_attr_semantic.CUBE_COORD);
SHADOW_MAP = 'u_shadowMap';
SHADOW_BIAS = 'u_shadowBias';
SHADOW_MIN = "u_shadowMin";
SHADOW_MAX = "u_shadowMax";
SHADOW_SIZE = "u_shadowSize";
解决方案:
仔细观察下面的表达式
第一个小括号里(\S.*.);它表示这个匹配的子字符串必须从一个非空的字符串开始,从而可以解决那五个缩进的匹配
第二个括号和第四个里是(‘|"):他表示只有有’或者“都算匹配到,但至少有一个,这是一个或运算
(\S.*.) = ('|")(.*.)('|");
this.$3_loc = gl.getUniformLocation(_glID, glvert_attr_semantic.$1);
情景8
我们在写代码的时候,可能又很多空行,看起来非常的难受,格式化的时候,又无法删掉这些空行,那么可以使用下面这个正则表达式来删除
req:^\s*(?=\r?$)\n 或者 ^\s*$\n
replace:
分析:^这个是表示匹配字符串的开始位置,这个理解非常重要,无论你匹配的结果如何,这个一定是匹配结果字符串的首开始的位置
,而\s表示匹配空白字符,*这个表示前面有若干个要匹配的字符,^\s*表示前面若干个空白字符
?=:这个符号如果结合()来使用的话,就表示继续匹配括号外前面表达式要匹配的字符串,此处的字符串指的是空白字符
$:表示匹配字符串的结尾位置
\r:表示回车符,使光标回到行首
\n:表示换行符,使光标下移一个
?:表示前面要匹配的字符串出现0次以上
^\s*(?=\r?$)\n:那么这句话的意思就是,匹配所有空行
情景9:
cam3DPosY: 2,----------》public static cam3DPosY = 2;
cam3DPosZ: 20,----------》public static cam3DPosZ= 2;
cam3DRotX: 0,----------》public static cam3DRotX= 2;
cam3DRotY: 0,----------》public static cam3DRotY= 2;
cam3DRotZ: 0,----------》public static cam3DRotZ= 2;
cam3DNear: 1,----------》public static cam3DNear= 2;
cam3DFar: 200,----------》public static cam3DFar= 2;
正则表达式:
reg: ^\s*([A-Za-z0-9]*):\s*([0-9.-]*),
replace:public static $1:number = $2;
解释:
^:代表起始字符
^\s*:代表起始字符前面都是空格
[A-Za-z0-9]:表示匹配大小写字母,匹配数字
[A-Za-z0-9]*:表示前面匹配若干个这样的组合,没有顺序制约
([A-Za-z0-9]*)::这是一个元表达式,以:这个号结尾
\s*:表示上一次匹配结束到中间所有的空格
[0-9.-]*:表示匹配所有的数字包含整数
收获:
[0-9.-]:[]这个中括号表示匹配范围,里面的值都是要匹配的参数,可以随意添加,哈哈就是这么简单
情景10
源:
TimelineType[TimelineType["rotate"] = 0] = "rotate";
TimelineType[TimelineType["translate"] = 1] = "translate";
TimelineType[TimelineType["scale"] = 2] = "scale";
TimelineType[TimelineType["shear"] = 3] = "shear";
TimelineType[TimelineType["attachment"] = 4] = "attachment";
TimelineType[TimelineType["color"] = 5] = "color";
TimelineType[TimelineType["deform"] = 6] = "deform";
TimelineType[TimelineType["event"] = 7] = "event";
TimelineType[TimelineType["drawOrder"] = 8] = "drawOrder";
TimelineType[TimelineType["ikConstraint"] = 9] = "ikConstraint";
TimelineType[TimelineType["transformConstraint"] = 10] = "transformConstraint";
TimelineType[TimelineType["pathConstraintPosition"] = 11] = "pathConstraintPosition";
TimelineType[TimelineType["pathConstraintSpacing"] = 12] = "pathConstraintSpacing";
TimelineType[TimelineType["pathConstraintMix"] = 13] = "pathConstraintMix";
TimelineType[TimelineType["twoColor"] = 14] = "twoColor";
目标:
"rotate": 0,
0: "rotate",
"translate": 1,
1: "translate",
"scale": 2,
2: "scale",
"shear": 3,
3: "shear",
"attachment": 4,
4: "attachment",
"color": 5,
5: "color",
"deform": 6,
6: "deform",
"event": 7,
7: "event",
"drawOrder": 8,
8: "drawOrder",
"ikConstraint": 9,
9: "ikConstraint",
"transformConstraint": 10,
10: "transformConstraint",
"pathConstraintPosition": 11,
11: "pathConstraintPosition",
"pathConstraintSpacing": 12,
12: "pathConstraintSpacing",
"pathConstraintMix": 13,
13: "pathConstraintMix",
"twoColor": 14,
14: "twoColor",
reg:
TimelineType\[TimelineType\[(.*.)\] = ([0-9]*)\](.*.)
replace:$1:$2,\n$2:$1,
情景11–多行匹配
遇到的js情况
var ShearTimeline = (function (_super) {
__extends(ShearTimeline, _super);
function ShearTimeline(frameCount) {
return _super.call(this, frameCount) || this;
}
ShearTimeline.prototype.getPropertyId = function () {
return (TimelineType.shear << 24) + this.boneIndex;
};
}(TranslateTimeline));
想要改成ts的情况
export class ShearTimeline extends TranslateTimeline {
.......
}
使用正则表达式
req:var\s*(.*.)\s?=\s?\(function\s?\((.*.)?\)\s?\{((.|\n)*?)\}\s?\((.*.)?\)\);
replace:export class $1 extends $5 {$3}
解释:
(.|\n)*?:表示多行
((.|\n)*?):在外面再多加一个小括号,表示把多行内容包起来按照上面的内容,我们可以通过$3取到多行的内容
情景12–排除某字符串
遇到的情况:
var position = 0;
PathConstraintPositionTimeline.ENTRIES = 2;
PathConstraintPositionTimeline.PREV_TIME = -2;
PathConstraintPositionTimeline.PREV_VALUE = -1;
PathConstraintPositionTimeline.VALUE = 1;
想要改成的情况:
static ENTRIES = 2;
static PREV_TIME = -2;
static PREV_VALUE = -1;
static VALUE = 1;
使用正则表达式:
req:^\s?\s?^(?!.*var)(.*.)\.(.*.) = ([0-9.-]*);
replace:static $2 = $3;
解释:这里面过滤了var字符串
(?!.*var):过滤var字符串
情景13:排除某个字符串
let str = "你要排除的字符串"
正则表达式:^(?!\s*str).*$ --每一行中开头开始 只允许出现空格 一直遇到指定字符串截止,最后取反
正则表达式:^(?!.*.str) --排除字符串中可能存在某个字符串
情景14:js---->ts
let fs = require("fs")
var jsDir = "./";
var tsDir = "../../src/core/renderer/base/spine/source/";
var js_code = fs.readFileSync(jsDir+"spine.js").toString();
//var jsout = js_code.replace(/var\s*(.*.)\s?=\s?\(function\s?\((.*.)?\)\s?\{/gm,"export class $1")
let existClassName = new Array();
let createInit = function (){
//([a-zA-Z\{\}]*)
//
let reg = /spine\.([a-zA-Z]*)\s?=\s?([a-zA-Z\{\}]*)/gm
var result;
var ret = "export namespace sySpine{ \n";
let importData = "\n";
while ((result = reg.exec(js_code)) != null) {
if(existClassName.indexOf(result[1])<0)
{
ret = ret + "export var "+result[1]+":" + result[1]+";\n";
importData = importData + "import { "+result[1]+" } from "+'"./'+result[1]+'"'+"\n";
existClassName.push(result[1]);
}
}
ret = ret +"} \n";
fs.writeFileSync(tsDir+"init.ts",importData+ret);
}
createInit();
//console.log(existClassName);
//替换构造函数
let handleConstructor = function(className,str){
//注意:(.*.) 这个可以匹配任何值 但不包含空值
//有参数
let targetHasParam = "function\\s?"+className+"\\s?\\((.*.)\\)\\s?\\{";
//没有参数
let targetNoParam = "function\\s?"+className+"\\s?\\(\\)\\s?\\{";
let reqHasParam = eval('/'+targetHasParam+'/gm');
let reqNoHasParam = eval('/'+targetNoParam+'/gm');
let replaceContent = str.replace(reqHasParam,"constructor\($1\){");
replaceContent = replaceContent.replace(reqNoHasParam,"constructor\(\){");
return replaceContent;
}
//处理继承
let handleExtends = function(str){
let replaceContent = str.replace(/__extends\((.*.)\);/gm,"");
//_super.call() -->super
replaceContent = replaceContent.replace(/var\s?_this\s?=\s?_super.call\s?\(\s?this\s?,(.*.)\)\s?\|\|\s?this;/gm,"super($1);\n var _this = this;\n");
return replaceContent;
}
//处理原型函数
let handlePrototype = function(className,str){
let target = className+"\\.prototype\\.(\\S*)\\s?=\\s?function\\s\\(";
let req = eval('/'+target+'/gm');
let replaceContent = str.replace(req,"public $1\(");
return replaceContent
}
//处理静态变量
let handleStaticVariant = function(className,str){
let target = "^([\\s]*)"+className+"\\.(\\S*)\\s?=\\s(.*.);\\s?";
let req = eval('/'+target+'/gm');
let replaceContent = str.replace(req,"public static $2 = $3;\n");
return replaceContent
}
//处理静态函数
let handleStaticFunction = function(className,str){
//标准的正则表达式 ^\s*(?!var)\s?(.*.)\.(?!prototype)(.*.)\s?=\s?function\s\((.*.)\)\s\{
//(?!字符串) 表示不包含某个字符串
//开头使用^ 表示从行首开始匹配
let target = "^\\s*(?!var)\\s?"+className+"\\.(?!prototype)(.*.)\\s?=\\s?function\\s\\((.*.)\\)\\s\\{"
let req = eval('/'+target+'/gm');
let replaceContent = str.replace(req,"public static $1\($2\)\{");
return replaceContent
}
//处理一个类结束以后 删除掉return语句
let handleEndReturn = function(className,str){
//标准的正则表达式 \s?return\s?(.*.)
//此处需要注意 ^\s? 这样的使用错误 应该是 ^\s*
let target = "\\s?return\\s?"+className+"\s?;";
let req = eval('/'+target+'/gm');
let replaceContent = str.replace(req,"");
return replaceContent
}
//声明本地变量
let handleLocalVariant = function(className,str){
let localVariant = [];
let mapVariant = {};
let reg = /^\s*this\.([a-zA-Z0-9]*)\s?=\s?(.*.)\s?;/gm;
while ((result = reg.exec(str)) != null) {
let variantName = result[1];
let variantValue = result[2];
localVariant.indexOf(variantName)<0?(localVariant.push(variantName),mapVariant[variantName]=""+variantValue):null;
}
let retData = "";
for(let key in mapVariant)
{
let valueType = "any";
let value = mapVariant[key];
if(value.match(/new\s?Array/))
{
valueType = "Array<any>";
}
else if(value=="true"||value=="false")
{
valueType = "boolean";
}
else if(value.match(/-?[0-9]+\.?[0-9]*/))
{
if(!value.match(/[a-zA-Z]/))
{
valueType = "number";
}
else
{
valueType = "any";
}
}
else
{
valueType = "any";
}
retData = retData +"public "+ key+":"+valueType+";\n";
}
return retData;
}
//处理当前字符串中是否使用到一些类
let handleSomeLocalImportClass = function(className,str){
let localExist = [];
let importUsedData = "";
existClassName.forEach(function(item){
let req = eval("/\s*"+"spine\."+item+"\s*/gm");
let req2 = eval("/\s*"+item+"\s*/gm");
if(className!=item&&localExist.indexOf(item)<0&&(str.match(req)||str.match(req2)))
{
//存在使用这个类
localExist.push(item);
//删掉不合法的使用
//spine.Skin--->Skin
//spine.TwoColorTimeline--->TwoColorTimeline
let reqNew = eval("/"+"spine\."+item+"/gm");
console.log(className,reqNew);
str = str.replace(reqNew,item);
}
});
localExist.forEach(function(item){
importUsedData = importUsedData+"import { "+item+" } from "+'"./'+item+'"'+"\n";
});
return [importUsedData,str];
}
let createFile = function(){
let reg = /var\s*(\S*)\s?=\s?\(function\s?\((.*.)?\)\s?\{\s?((.|\n|\r)*?)\}\s?\((.*.)?\)\);/gm
var result;
while ((result = reg.exec(js_code)) != null) {
//console.log("结果是:" + result[0] + "");
//console.log("$1是:" + result[1] + "");
//console.log("$2是:" + result[2] + "");
let className = result[1];
let centerContent = handleConstructor(className,result[3]);
centerContent = handleExtends(centerContent);
centerContent = handlePrototype(className,centerContent);
centerContent = handleStaticVariant(className,centerContent);
centerContent = handleStaticFunction(className,centerContent);
centerContent = handleEndReturn(className,centerContent);
let localVariant = handleLocalVariant(className,centerContent);
let importExtendsData = "";
let importUsedData = "";
[importUsedData,centerContent] = handleSomeLocalImportClass(className,centerContent);
let classHead = "";//类头
let classFoot = "}\n";//类尾
if(result[5]&&result[5]!="")
{
let extendsClass = result[5].split('.');
if(extendsClass.length>1)
extendsClass = extendsClass[1];
else
extendsClass = extendsClass[0];
//存在继承
classHead = "export class "+className+ " extends "+extendsClass+"{\n";
importExtendsData = "import { "+extendsClass+" } from "+'"./'+extendsClass+'"'+"\n";
}
else
{
classHead = "export class "+className+"{\n";
}
//将字节码写入文件
fs.writeFileSync(tsDir+className+".ts",importExtendsData+importUsedData+classHead+localVariant+centerContent+classFoot);
}
}
createFile();
情景15:匹配lua函数
function\s*(\w*):(\w*)(\(.*\))((.|\n)*?)(?<!.)end
解释
(\w*):类名
(\w*):函数名
((.|\n)*?):多行内容
(?<!.)end:靠近最边上的end
基础使用介绍
1:元字符介绍
"^" :^会匹配行或者字符串的起始位置,有时还会匹配整个文档的起始位置。
"$" :$会匹配行或字符串的结尾
"\b" :不会消耗任何字符只匹配一个位置,常用于匹配单词边界 如 我想从字符串中"This is Regex"匹配单独的单词 "is"
正则就要写成 "\bis\b"
\b 不会匹配is 两边的字符,但它会识别is 两边是否为单词的边界
"\d": 匹配数字,
例如要匹配一个固定格式的电话号码以0开头前4位后7位,如0737-5686123 正则:^0\d\d\d-\d\d\d\d\d\d\d$ 这里
只是为了介绍"\d"字符,实际上有更好的写法会在 下面介绍。
"\w":匹配字母,数字,下划线.
例如我要匹配"a2345BCD__TTz" 正则:"\w+" 这里的"+"字符为一个量词指重复的次数,稍后会详细介绍。
"\s":匹配空格
例如字符 "a b c" 正则:"\w\s\w\s\w" 一个字符后跟一个空格,如有字符间有多个空格直接把"\s" 写成 "\s+"
让空格重复
".":匹配除了换行符以外的任何字符
这个算是"\w"的加强版了"\w"不能匹配 空格 如果把字符串加上空格用"\w"就受限了,
看下用 "."是如何匹配字符"a23 4 5 B C D__TTz" 正则:".+"
"[abc]": 字符组 匹配包含括号内元素的字符
这个比较简单了只匹配括号内存在的字符,还可以写成[a-z]匹配a至z的所以字母就等于可以用来控制只能输入英文了,
2:几种反义
写法很简单改成大写就行了,意思与原来的相反,这里就不举例子了
"\W" 匹配任意不是字母,数字,下划线 的字符
"\S" 匹配任意不是空白符的字符
"\D" 匹配任意非数字的字符
"\B" 匹配不是单词开头或结束的位置
"[^abc]" 匹配除了abc以外的任意字符
3:量词
先解释关于量词所涉及到的重要的三个概念
贪婪(贪心) 如"*"字符 贪婪量词会首先匹配整个字符串,尝试匹配时,它会选定尽可能多的内容,如果 失败则回退一个字符,
然后再次尝试回退的过程就叫做回溯,它会每次回退一个字符,直到找到匹配的内容或者没有字符可以回退。
相比下面两种贪婪量词对资源的消耗是最大的,
懒惰(勉强) 如 "?" 懒惰量词使用另一种方式匹配,它从目标的起始位置开始尝试匹配,每次检查一个字符,
并寻找它要匹配的内容,如此循环直到字符结尾处。
占有 如"+" 占有量词会覆盖事个目标字符串,然后尝试寻找匹配内容 ,但它只尝试一次,不会回溯,就好比先抓一把石头,
然后从石头中挑出黄金
"*"(贪婪) 重复零次或更多
例如"aaaaaaaa" 匹配字符串中所有的a 正则: "a*" 会出到所有的字符"a"
"+"(懒惰) 重复一次或更多次
例如"aaaaaaaa" 匹配字符串中所有的a 正则: "a+" 会取到字符中所有的a字符,
"a+"与"a*"不同在于"+"至少是一次而"*" 可以是0次,
稍后会与"?"字符结合来体现这种区别
"?"(占有) 重复零次或一次
例如"aaaaaaaa" 匹配字符串中的a 正则 : "a?" 只会匹配一次,也就是结果只是单个字符a
"{n}" 重复n次
例如从"aaaaaaaa" 匹配字符串的a 并重复3次 正则: "a{3}" 结果就是取到3个a字符 "aaa";
"{n,m}" 重复n到m次
例如正则 "a{3,4}" 将a重复匹配3次或者4次 所以供匹配的字符可以是三个"aaa"也可以是四个"aaaa"
正则都可以匹配到
"{n,}" 重复n次或更多次
与{n,m}不同之处就在于匹配的次数将没有上限,但至少要重复n次 如 正则"a{3,}" a至少要重复3次
把量词了解了之后之前匹配电话号码的正则现在就可以改得简单点了^0\d\d\d-\d\d\d\d\d\d\d$
可以改为"^0\d+-\d{7}$"。这样写还不够完美如果因为前面的区号没有做限定,以至于可以输入很多们,
而通常只能是3位或者4位,现在再改一下 "^0\d{2,3}-\d{7}"如此一来区号部分就可以匹配3位或者4位的了
4:懒惰限定符
"*?" 重复任意次,但尽可能少重复
如 "acbacb" 正则 "a.*?b" 只会取到第一个"acb" 原本可以全部取到但加了限定符后,
只会匹配尽可能少的字符 ,而"acbacb"最少字符的结果就是"acb"
"+?" 重复1次或更多次,但尽可能少重复
与上面一样,只是至少要重复1次
"??" 重复0次或1次,但尽可能少重复
如 "aaacb" 正则 "a.??b" 只会取到最后的三个字符"acb"
"{n,m}?" 重复n到m次,但尽可能少重复
如 "aaaaaaaa" 正则 "a{0,m}" 因为最少是0次所以取到结果为空
"{n,}?" 重复n次以上,但尽可能少重复
如 "aaaaaaa" 正则 "a{1,}" 最少是1次所以取到结果为 "a"
5:捕获分组
先了解在正则中捕获分组的概念,其实就是一个括号内的内容 如 "(\d)\d" 而"(\d)" 这就是一个捕获分组,可以对捕获分组进
行 后向引用 (如果后而有相同的内容则可以直接引用前面定义的捕获组,以简化表达式) 如(\d)\d\1 这里的"\1"就是对"(\d)"
的后向引用
那捕获分组有什么用呢看个例子就知道了
如 "zery zery" 正则 \b(\w+)\b\s\1\b 所以这里的"\1"所捕获到的字符也是 与(\w+)一样的"zery",为了让组名更有
意义,组名是可以自定义名字的
"\b(?<name>\w+)\b\s\k<name>\b" 用"?<name>"就可以自定义组名了而要后向引用组时要记得写成 "\k<name>";自定义组
名后,捕获组中匹配到的值就会保存在定义的组名里
下面列出捕获分组常有的用法
"(exp)" 匹配exp,并捕获文本到自动命名的组里
"(?<name>exp)" 匹配exp,并捕获文本到名称为name的组里
"(?:exp)" 匹配exp,不捕获匹配的文本,也不给此分组分配组号
以下为零宽断言
"(?=exp)" 匹配exp前面的位置
如 "How are you doing" 正则"(?<txt>.+(?=ing))" 这里取ing前所有的字符,并定义了一个捕获分组名字为
"txt" 而"txt"这个组里的值为"How are you do";
"(?<=exp)" 匹配exp后面的位置
如 "How are you doing" 正则"(?<txt>(?<=How).+)" 这里取"How"之后所有的字符,并定义了一个捕获分组名字
为 "txt" 而"txt"这个组里的值为" are you doing";
"(?!exp)" 匹配后面跟的不是exp的位置
如 "123abc" 正则 "\d{3}(?!\d)"匹配3位数字后非数字的结果
"(?<!exp)" 匹配前面不是exp的位置
如 "abc123 " 正则 "(?<![0-9])123" 匹配"123"前面是非数字的结果也可写成"(?!<\d)123"
常用库
一、校验数字的表达式
数字:^[0-9]*$
n位的数字:^\d{n}$
至少n位的数字:^\d{n,}$
m-n位的数字:^\d{m,n}$
零和非零开头的数字:^(0|[1-9][0-9]*)$
非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(\.[0-9]{1,2})?$
带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})$
正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
有两位小数的正实数:^[0-9]+(\.[0-9]{2})?$
有1~3位小数的正实数:^[0-9]+(\.[0-9]{1,3})?$
非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
非负整数:^\d+$ 或 ^[1-9]\d*|0$
非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
校验字符的表达式
汉字:^[\u4e00-\u9fa5]{0,}$
英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
长度为3-20的所有字符:^.{3,20}$
由26个英文字母组成的字符串:^[A-Za-z]+$
由26个大写英文字母组成的字符串:^[A-Z]+$
由26个小写英文字母组成的字符串:^[a-z]+$
由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?
InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
手机号码:^(13[0-9]|14[5|7]|15[0|1|2|3|4|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$
电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号): ((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$)
身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])[a-zA-Z0-9]{8,10}$
强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
日期格式:^\d{4}-\d{1,2}-\d{1,2}
一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
钱的输入格式:
有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
中文字符的正则表达式:[\u4e00-\u9fa5]
双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
空白行的正则表达式:\n\s*\r (可以用来删除空白行)
HTML标记的正则表达式:<(\S*?)[^>]*>.*?|<.*? /> ( 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))