注意:该项目只展示部分功能,如需了解,文末咨询即可。
1.开发环境
开发语言:Python
所用技术:TensorFlow深度学习框架和LSTM(长短期记忆网络)模型
数据库:MySQL
开发环境:Pycharm
2 系统设计
2.1 设计背景
在大数据时代背景下,股票市场产生了海量的交易数据,这些数据蕴含着丰富的市场信息和投资机会。然而,传统的股票分析方法难以有效处理如此庞大和复杂的数据集,无法充分挖掘其中的价值。随着人工智能和机器学习技术的快速发展,特别是深度学习算法在金融领域的广泛应用,为股票数据的分析和预测提供了新的思路和工具。Python作为一种强大的数据处理和分析语言,结合TensorFlow深度学习框架和LSTM(长短期记忆网络)模型,为构建高效的股票数据分析与预测系统提供了理想的技术平台。本系统的开发正是基于这一背景,旨在充分利用大数据和人工智能技术,提升股票市场分析的深度和广度。
开发基于Python的股票数据分析与预测系统具有重要的实践意义和研究价值,该系统能够自动化地从多个数据源获取和处理大量股票相关数据,大大提高了数据收集和预处理的效率。通过应用先进的数据挖掘和机器学习算法,系统可以从海量数据中发现隐藏的模式和趋势,为投资决策提供更加科学和客观的依据。特别是利用LSTM模型对股票价格进行预测,有助于投资者更好地把握市场动向,降低投资风险。系统的可视化分析功能使复杂的数据分析结果更加直观和易于理解,有利于提高决策的透明度和可解释性。从学术角度来看,该系统的开发也为金融大数据分析和人工智能在金融领域的应用提供了有价值的实践案例和研究素材。
2.2 设计内容
股票数据分析与价格预测系统的设计内容涵盖了从数据采集到分析预测的完整流程,利用Scrapy爬虫框架实现对大众点评等平台的数据抓取,确保数据的全面性和时效性。然后通过一系列数据处理技术,包括数据清洗、转换和去重,提高数据质量和可用性。在数据分析阶段,系统运用聚类、分类和关联分析等方法,深入挖掘股票数据的多个维度,如股票管理、标题词云、价格趋势、成交量与成交额关系等。核心的预测功能则基于TensorFlow框架和LSTM模型,实现对股票收盘价的精确预测。最后,系统整合了Web开发技术和Echarts可视化框架,构建了一个功能强大的大屏展示平台,使分析结果更加直观和易于理解。这种全面而系统的设计不仅满足了专业投资者的需求,也为普通用户提供了便捷的股票市场分析工具。
3 系统页面展示
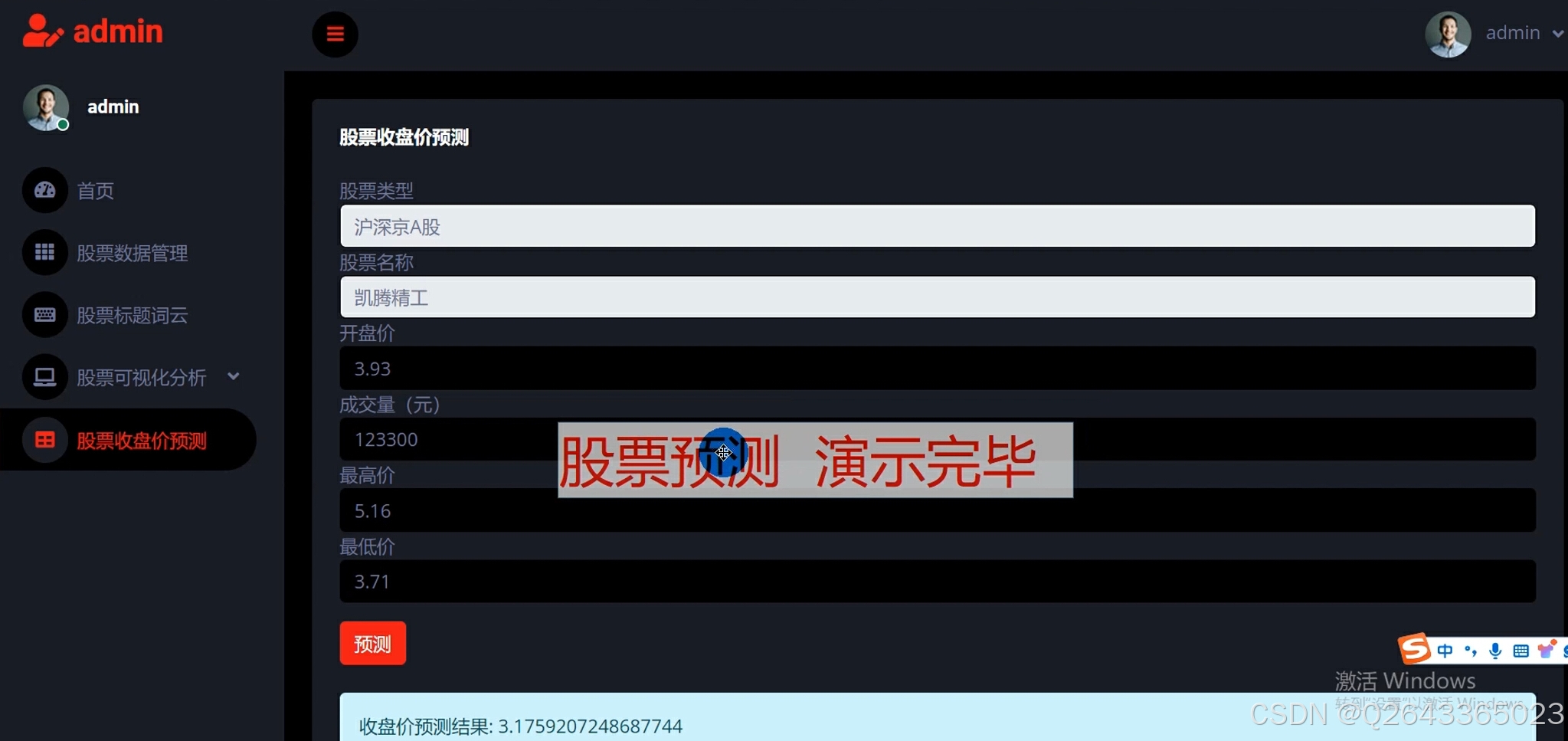
3.1 预测页面
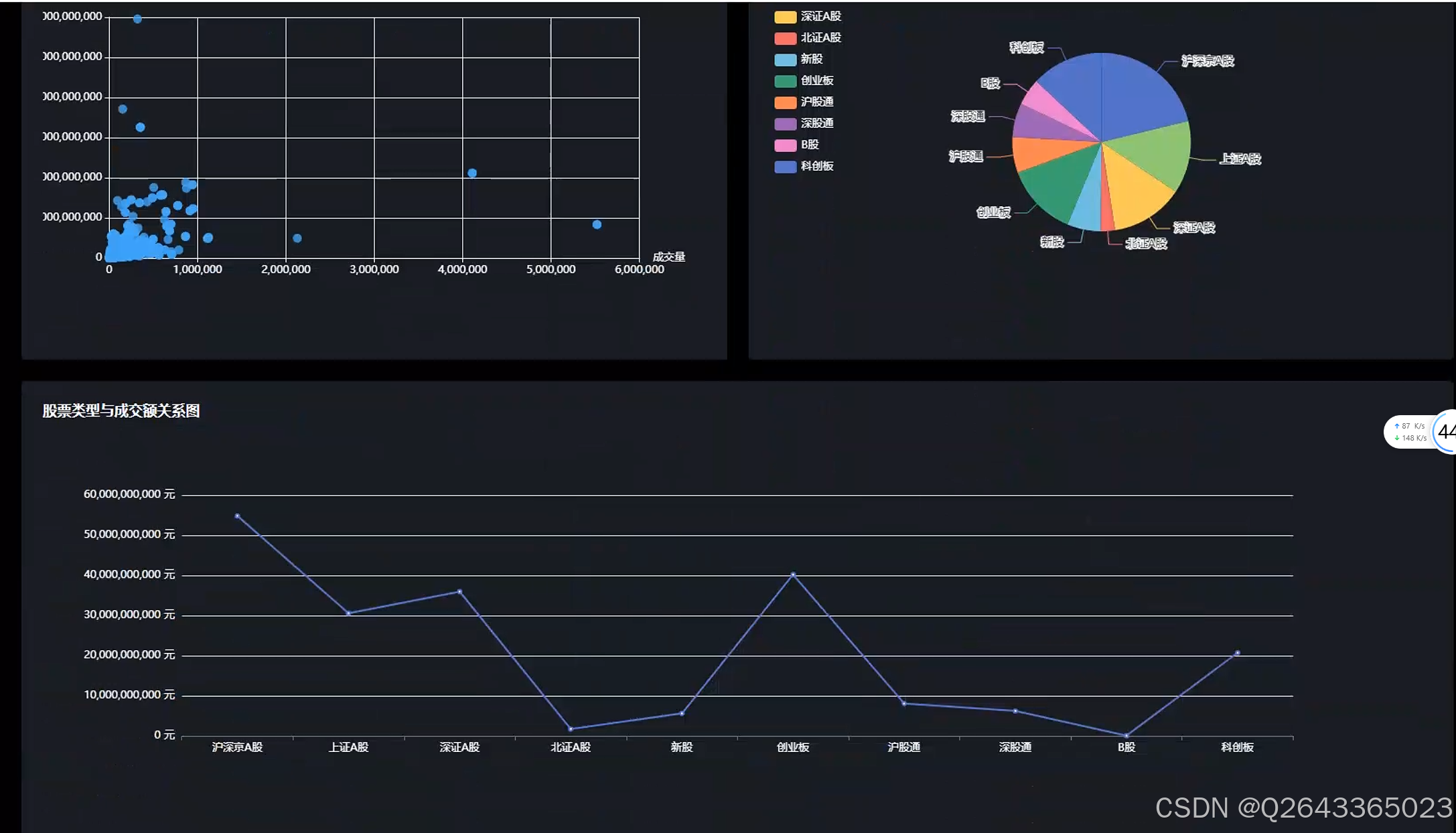
3.2 可视化页面


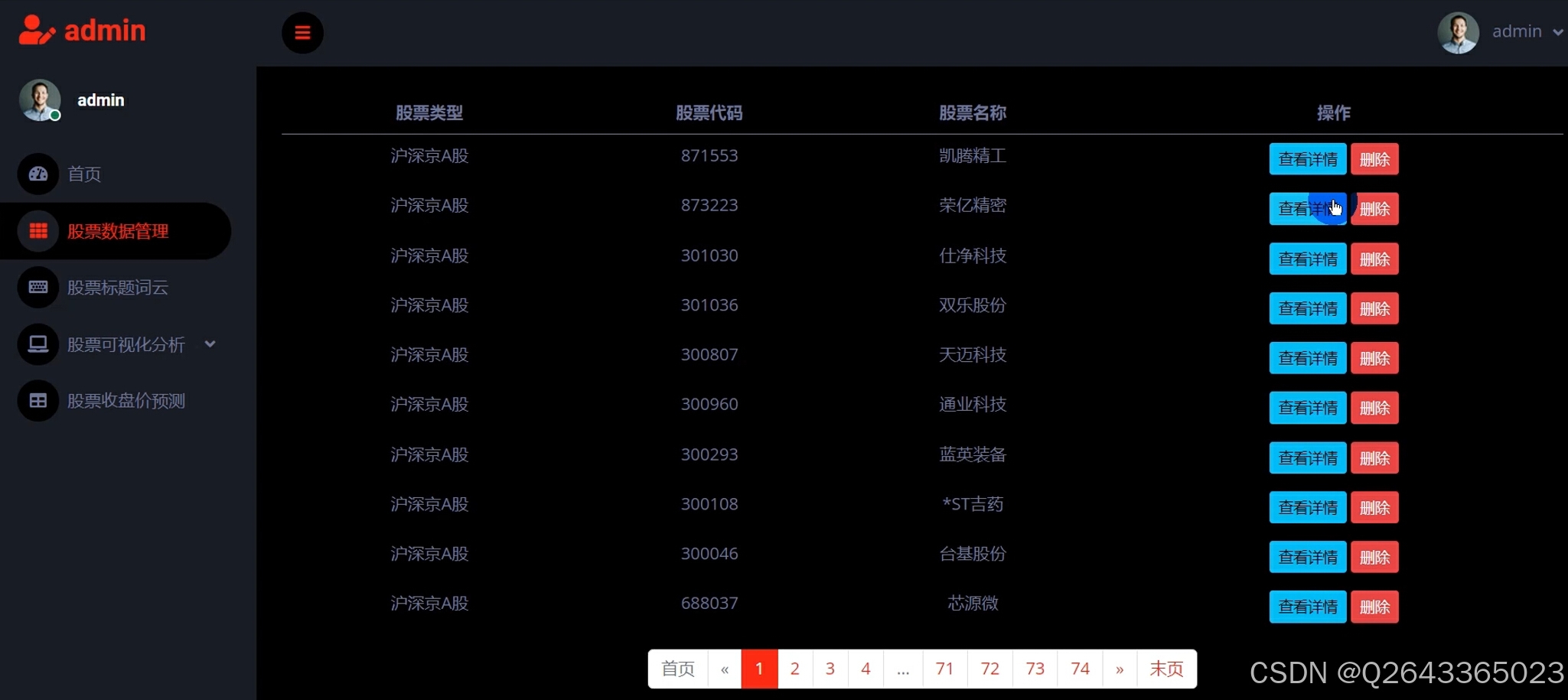
3.3 管理页面
3.4 功能展示视频
tensorflow+LSTM算法的股票价格预测与分析可视化
4 更多推荐
计算机毕设选题精选汇总
基于Hadoop大数据电商平台用户行为分析与可视化系统
基于python+爬虫的新闻数据分析及可视化系统
基于python+爬虫的高考数据分析与可视化系统
基于Spark大数据的餐饮外卖数据分析可视化系统
Django+Python数据分析岗位招聘信息爬取与分析
基于python爬虫的商城商品比价数据分析
5 部分功能代码
5.1 爬虫部分代码
import scrapy
from scrapy.http import Request
import json
class StockSpider(scrapy.Spider):
name = 'stock_spider'
allowed_domains = ['xueqiu.com']
def start_requests(self):
url = 'https://stock.xueqiu.com/v5/stock/batch/quote.json?symbol=SH000001,SZ399001,SZ399006&_=1597100000000'
yield Request(url, callback=self.parse, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
})
def parse(self, response):
data = json.loads(response.text)
for item in data['data']['items']:
stock = item['quote']
yield {
'symbol': stock['symbol'],
'name': stock['name'],
'current': stock['current'],
'percent': stock['percent'],
'open': stock['open'],
'high': stock['high'],
'low': stock['low'],
'volume': stock['volume'],
'amount': stock['amount'],
'market_capital': stock['market_capital'],
'time': stock['time']
}
5.2 预测部分代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
import tensorflow as tf
# 设置随机种子以确保结果可复现
np.random.seed(42)
tf.random.set_seed(42)
# 加载数据
df = pd.read_csv('stock_data.csv') # 假设你的股票数据保存在这个CSV文件中
data = df.filter(['close']).values # 我们只使用收盘价进行预测
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
# 准备训练数据
train_size = int(len(scaled_data) * 0.8)
train_data = scaled_data[:train_size]
def create_sequences(data, time_steps):
X, y = [], []
for i in range(len(data) - time_steps):
X.append(data[i:(i + time_steps), 0])
y.append(data[i + time_steps, 0])
return np.array(X), np.array(y)
time_steps = 60 # 使用过去60天的数据来预测下一天
X_train, y_train = create_sequences(train_data, time_steps)
# 重塑输入为LSTM期望的格式:[samples, time steps, features]
X_train = np.reshape(X_train, (X_train.shape[0], X_train.shape[1], 1))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X_train.shape[1], 1)))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dense(units=25))
model.add(Dense(units=1))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
history = model.fit(X_train, y_train, batch_size=32, epochs=100, validation_split=0.1, verbose=1)
# 准备测试数据
test_data = scaled_data[train_size - time_steps:]
X_test, y_test = create_sequences(test_data, time_steps)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
# 使用模型进行预测
predictions = model.predict(X_test)
predictions = scaler.inverse_transform(predictions)
# 计算均方根误差
rmse = np.sqrt(np.mean((predictions - scaler.inverse_transform(y_test.reshape(-1, 1)))**2))
print(f"Root Mean Squared Error: {rmse}")
# 绘制结果
train = data[:train_size]
valid = data[train_size:]
valid['Predictions'] = predictions
plt.figure(figsize=(16,8))
plt.title('Model')
plt.xlabel('Date')
plt.ylabel('Close Price USD ($)')
plt.plot(train)
plt.plot(valid[['close', 'Predictions']])
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right')
plt.show()
# 预测未来30天的股价
last_60_days = scaled_data[-60:]
X_future = []
for i in range(30):
X_future.append(last_60_days[-time_steps:])
prediction = model.predict(np.array(X_future[i]).reshape(1, time_steps, 1))
last_60_days = np.append(last_60_days, prediction)
future_predictions = scaler.inverse_transform(last_60_days[-30:].reshape(-1, 1))
print("未来30天的预测股价:", future_predictions)
源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流!!