通过采集招聘网站大数据职位信息、利用数据清洗、数据分析、jieba分词、数据挖掘完成整体项目的开发工作。任务包含爬取招聘网站大数据职位信息、使用BeautifulSoup清洗职位信息网页、使用PySpark对智联数据进行分析、对招聘职位信息进行探索分析、使用结巴分词对岗位描述进行分词并将关键词统计、利用Echarts将职位分析结果进行可视化、建立职位模型对应聘人员进行相似度的计算。
目录
1 爬取招聘网站大数据职位信息
爬取智联招聘网页
1.1 知识前述
1.网络爬虫是捜索引擎抓取系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地形成一个互联网内容的镜像备份。
网络爬虫的基本工作流程如下:
(1)首先选取目标URL;
(2)将目标URL放入待抓取URL队列;
(3)从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
(4)分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环。
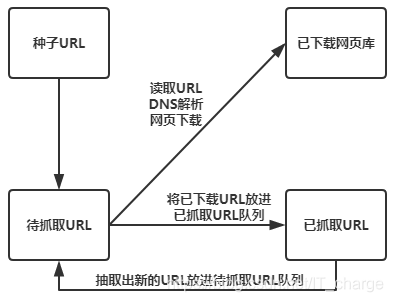
2.在爬虫系统中,待抓取URL队列是很重要的一部分。待抓取URL队列中的URL以什么样的顺序排列也是一个很重要的问题,因为这涉及到先抓取那个页面,后抓取哪个页面。而决定这些URL排列顺序的方法,叫做抓取策略。
常见的抓取策略:
(1)深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。它的遍历的路径:A-F-G E-H-I B C D,如下图:
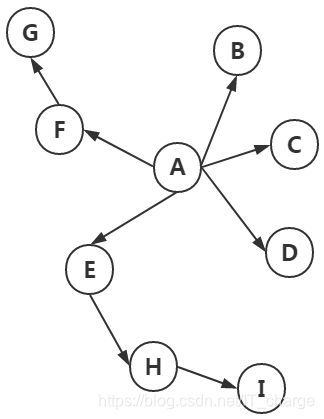
宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取URL队列的末尾。也就是指网络爬虫会先抓取起始网页中链接的所有网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。它的遍历路径:A-B-C-D-E-F G H I
(3)反向链接数策略
反向链接数是指一个网页被其他网页链接指向的数量。反向链接数表示的是一个网页的内容受到其他人的推荐的程度。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。
(4)Partial PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于已经下载的网页,连同待抓取URL队列中的URL,形成网页集合,计算每个页面的PageRank值,计算完之后,将待抓取URL队列中的URL按照PageRank值的大小排列,并按照该顺序抓取页面。
(5)OPIC策略
该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面P之后,将P的现金分摊给所有从P中分析出的链接,并且将P的现金清空。对于待抓取URL队列中的所有页面按照现金数进行排序。
(6)大站优先策略
对于待抓取URL队列中的所有网页,根据所属的网站进行分类。对于待下载页面数多的网站,优先下载。这个策略也因此叫做大站优先策略。
1.2 代码详解
导入程序所用的外包
import urllib
from urllib.parse import *
from bs4 import BeautifulSoup
import string
import random
import pandas as pd
import os
将爬虫伪装成浏览器,防止网站针对爬虫的限制:
headers = [
"Mozilla/5.0 (Windows NT 6.1; Win64; rv:27.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:27.0) Gecko/20100101 Firfox/27.0"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:10.0) Gecko/20100101 Firfox/10.0"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/21.0.1180.110 Safari/537.36"
"Mozilla/5.0 (X11; Ubuntu; Linux i686 rv:10.0) Gecko/20100101 Firfox/27.0"
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/34.0.1838.2 Safari/537.36"
"Mozilla/5.0 (X11; Ubuntu; Linux i686 rv:27.0) Gecko/20100101 Firfox/27.0"
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
]
模拟登陆获取网址
def get_content(url, headers,str):
'''''
@url:需要登录的网址
@headers:模拟的登陆的终端
*********************模拟登陆获取网址********************
'''
random_header = random.choice(headers)
req = urllib.request.Request(url)
req.add_header("User-Agent", random_header)
req.add_header("Get", url)
req.add_header("Host", "{0}.zhaopin.com".format(str))
req.add_header("refer", "http://{0}.zhaopin.com/".format(str))
try:
html = urllib.request.urlopen(req)
contents = html.read()
# print(contents)
# 判断输出内容contents是否是字节格式
if isinstance(contents, bytes):
# 转成字符串格式
contents = contents.decode('utf-8')
else:
print('输出格式正确,可以直接输出')
##输出的是字节格式,需要将字节格式解码转成’utf-8‘
return (contents)
except Exception as e:
print(e)
获取全部子网页地址
def get_links_from(job, city, page):
'''''
@job:工作名称
@city:网址中城市名称
@page:表示第几页信息
@urls:所有列表的超链接,即子页网址
****************此网站需要模拟登陆**********************
返回全部子网页地址
'''
urls = []
for i in range(page):
url='http://sou.zhaopin.com/jobs/searchresult.ashx?jl={0}&kw={1}&p={2}&isadv=0'.format(str(city),str(job),i)
url = quote(url, safe=string.printable)
info = get_content(url, headers,'sou')
soup = BeautifulSoup(info, "lxml") # 设置解析器为“lxml”
# print(soup)
link_urls = soup.select('td.zwmc a')
for url in link_urls:
urls.append(url.get('href'))
# print(urls)
获取招聘网页信息,并保存
def get_recuite_info(job, city, page):
'''''
获取招聘网页信息
'''
urls = get_links_from(job, city, page)
path='/data/zhilian/'
if os.path.exists(path)==False:
os.makedirs(path)
for url in urls:
print(url)
file=url.split('/')[-1]
print(file)
str=url.split('/')[2].split('.')[0]
html = get_content(url, headers, str)
if html!=None and file!='':
with open(path+file,'w') as f:
f.write(html)
1.3 完整代码
import urllib
from urllib.parse import *
from bs4 import BeautifulSoup
import string
import random
import pandas as pd
import os
headers = [
"Mozilla/5.0 (Windows NT 6.1; Win64; rv:27.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:27.0) Gecko/20100101 Firfox/27.0"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:10.0) Gecko/20100101 Firfox/10.0"
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/21.0.1180.110 Safari/537.36"
"Mozilla/5.0 (X11; Ubuntu; Linux i686 rv:10.0) Gecko/20100101 Firfox/27.0"
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/34.0.1838.2 Safari/537.36"
"Mozilla/5.0 (X11; Ubuntu; Linux i686 rv:27.0) Gecko/20100101 Firfox/27.0"
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
]
def get_content(url, headers,str):
'''''
@url:需要登录的网址
@headers:模拟的登陆的终端
*********************模拟登陆获取网址********************
'''
random_header = random.choice(headers)
req = urllib.request.Request(url)
req.add_header("User-Agent", random_header)
req.add_header("Get", url)
req.add_header("Host", "{0}.zhaopin.com".format(str))
req.add_header("refer", "http://{0}.zhaopin.com/".format(str))
try:
html = urllib.request.urlopen(req)
contents = html.read()
# print(contents)
# 判断输出内容contents是否是字节格式
if isinstance(contents, bytes):
# 转成字符串格式
contents = contents.decode('utf-8')
else:
print('输出格式正确,可以直接输出')
##输出的是字节格式,需要将字节格式解码转成’utf-8‘
return (contents)
except Exception as e:
print(e)
def get_links_from(job, city, page):
'''''
@job:工作名称
@city:网址中城市名称
@page:表示第几页信息
@urls:所有列表的超链接,即子页网址
****************此网站需要模拟登陆**********************
返回全部子网页地址
'''
urls = []
for i in range(page):
url='http://sou.zhaopin.com/jobs/searchresult.ashx?jl={0}&kw={1}&p={2}&isadv=0'.format(str(city),str(job),i)
url = quote(url, safe=string.printable)
info = get_content(url, headers,'sou')
soup = BeautifulSoup(info, 'lxml') # 设置解析器为“lxml”
# print(soup)
link_urls = soup.select('td.zwmc a')
for url in link_urls:
urls.append(url.get('href'))
# print(urls)
return (urls)
def get_recuite_info(job, city, page):
'''''
获取招聘网页信息
'''
urls = get_links_from(job, city, page)
path='/data/zhilian/'
if os.path.exists(path)==False:
os.makedirs(path)
for url in urls:
print(url)
file=url.split('/')[-1]
print(file)
str=url.split('/')[2].split('.')[0]
html = get_content(url, headers, str)
if html!=None and file!='':
with open(path+file,'w') as f:
f.write(html)
'''
*********************获取招聘信息***************************
'''
if __name__ == '__main__':
city='北京%2b上海%2b广州%2b深圳'
get_recuite_info('大数据', city, 100)
2 对招聘职位信息进行探索分析
2.1 知识前述
1.matplotlib是基于Python语言的开源项目,旨在为Python提供一个数据绘图包。我将在这篇文章中介绍matplotlib API的核心对象,并介绍如何使用这些对象来实现绘图。实际上,matplotlib的对象体系严谨而有趣,为使用者提供了巨大的发挥空间。用户在熟悉了核心对象之后,可以轻易的定制图像。matplotlib的对象体系也是计算机图形学的一个优秀范例。即使你不是Python程序员,你也可以从文中了解一些通用的图形绘制原则。
matplotlib使用numpy进行数组运算,并调用一系列其他的Python库来实现硬件交互。matplotlib的核心是一套由对象构成的绘图API。
2.为项目设置matplotlib参数
在代码执行过程中,有两种方式更改参数:使用参数字典(rcParams)、调用matplotlib.rc()命令 通过传入关键字元祖,修改参数如果不想每次使用matplotlib时都在代码部分进行配置,可以修改matplotlib的文件参数。可以用matplot.get_config()命令来找到当前用户的配置文件目录。
配置文件包括以下配置项:
axex: 设置坐标轴边界和表面的颜色、坐标刻度值大小和网格的显示
backend: 设置目标暑促TkAgg和GTKAgg
figure: 控制dpi、边界颜色、图形大小、和子区( subplot)设置
font: 字体集(font family)、字体大小和样式设置
grid: 设置网格颜色和线性
legend: 设置图例和其中的文本的显示
line: 设置线条(颜色、线型、宽度等)和标记
patch: 是填充2D空间的图形对象,如多边形和圆。控制线宽、颜色和抗锯齿设置等。
savefig: 可以对保存的图形进行单独设置。例如,设置渲染的文件的背景为白色。
verbose: 设置matplotlib在执行期间信息输出,如silent、helpful、debug和debug-annoying。
xticks和yticks: 为x,y轴的主刻度和次刻度设置颜色、大小、方向,以及标签大小。
2.2 代码详解
一、实例一
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
fontPath ="/usr/share/fonts/truetype/wqy/wqy-zenhei.ttc"
font = fm.FontProperties(fname=fontPath, size=10)
data=pd.read_csv('/data/python_pj3/bigdata',)
print(data.shape,data.columns)
data.loc[(data.经验=='3年以上'),'经验']='3-5年'
#公司规模分布情况
plt.figure(figsize=(12,10))
plt.subplot2grid((2,3),(0,0))
a=data['公司规模'].value_counts().plot(kind='barh',title='公司规模分布情况',color='pink')
a.xaxis.get_label().set_fontproperties(font)
a.yaxis.get_label().set_fontproperties(font)
a.legend(loc='best',prop=font)
for label in ([a.title]+a.get_xticklabels()+a.get_yticklabels()):
label.set_fontproperties(font)
#公司性质分布情况
plt.subplot2grid((2,3),(0,1))
b=data['公司性质'].value_counts().plot(kind='barh',title='公司性质分布情况',color='red')
b.xaxis.get_label().set_fontproperties(font)
b.yaxis.get_label().set_fontproperties(font)
b.legend(loc='best',prop=font)
for label in ([b.title]+b.get_xticklabels()+b.get_yticklabels()):
label.set_fontproperties(font)
#经验分布情况
# plt.subplot2grid((2,2),(1,0),colspan=2)
plt.subplot2grid((2,3),(0,2))
c=data['经验'].value_counts().plot(kind='barh',title='经验分布情况',color='lightskyblue')
c.xaxis.get_label().set_fontproperties(font)
c.yaxis.get_label().set_fontproperties(font)
c.legend(loc='best',prop=font)
for label in ([c.title]+c.get_xticklabels()+c.get_yticklabels()):
label.set_fontproperties(font)
#公司行业分布情况
plt.subplot2grid((2,3),(1,0))
d=data['公司行业'].value_counts().sort_values(ascending=False).head(10).plot(kind='barh',title='公司行业分布情况',color='yellowgreen')
d.xaxis.get_label().set_fontproperties(font)
d.yaxis.get_label().set_fontproperties(font)
d.legend(loc='best',prop=font)
for label in ([d.title]+d.get_xticklabels()+d.get_yticklabels()):
label.set_fontproperties(font)
#职位类别分布情况
plt.subplot2grid((2,3),(1,1))
d=data['职位类别'].value_counts().sort_values(ascending=False).head(10).plot(kind='barh',title='职位类别分布情况',color='green')
d.xaxis.get_label().set_fontproperties(font)
d.yaxis.get_label().set_fontproperties(font)
d.legend(loc='best',prop=font)
for label in ([d.title]+d.get_xticklabels()+d.get_yticklabels()):
label.set_fontproperties(font)
#工作地点分布情况
plt.subplot2grid((2,3),(1,2))
d=data['工作地点'].str.split('-',expand=True)[0].value_counts().plot(kind='bar',title='工作地点分布情况',color='yellow',label='工作地点')
d.xaxis.get_label().set_fontproperties(font)
d.yaxis.get_label().set_fontproperties(font)
d.legend(loc='best',prop=font)
# print(d.get_legend_handles_labels())
for label in ([d.title]+d.get_xticklabels()+d.get_yticklabels()):
label.set_fontproperties(font)
plt.show()
二、实例二
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import matplotlib.font_manager as fm
fontPath ="/usr/share/fonts/truetype/wqy/wqy-zenhei.ttc"
font = fm.FontProperties(fname=fontPath, size=10)
data=pd.read_csv('/data/python_pj3/bigdata')
print(data.shape)
print(data.columns)
# print([data.职位类别.value_counts().index if data.职位类别.value_counts()<10==False:])
data.loc[((data.职位类别=='客户代表')|(data.职位类别=='电话销售')|(data.职位类别=='大客户销售代表')),'职位类别']='销售代表'
月工资=data['月工资'].str.strip('元/月').str.split('-',expand=True)
月工资.columns=['月工资_min','月工资_max']
data['月工资_min']=月工资['月工资_min']
data['月工资_max']=月工资['月工资_max']
data.loc[(data.月工资_min=='面议'),'月工资_min']=0
data.loc[(data.月工资_min=='1000元/月以下' ),'月工资_min']=1
data.loc[(data.月工资_min=='100000元/月以上'),'月工资_min']=7
data.loc[(data.月工资_max.isnull()),'月工资_max']=0
print('****************************************************')
data.月工资_min=data.月工资_min.astype(int)
data.月工资_max=data.月工资_max.astype(int)
月工资_mean=(data.月工资_min+data.月工资_max)/2
data.loc[((data.月工资_min==0) & (data.月工资_max==0) & (data.月工资.notnull()) ),'月工资']=0
data.loc[((data.月工资_min==1) & (data.月工资_max==0) & (data.月工资.notnull()) ),'月工资']=1
data.loc[((data.月工资_min8)),'月工资'] = 1
data.loc[((((data.月工资_min>=6000) & (data.月工资_max<=8000)) | ((6000<月工资_mean)&(月工资_mean=8000) & (data.月工资_max<=10000)) | ((8000<=月工资_mean)&(月工资_mean=10000) & (data.月工资_max<=20000)) | ((10000<=月工资_mean)&(月工资_mean=15000) & (data.月工资_max=20000) & (data.月工资_max<=30000)) | ((20000<=月工资_mean)&(月工资_mean=30000) & (data.月工资_max<=50000)) | ((30000<=月工资_mean)&(月工资_mean=50000) | (50000<=月工资_mean)) & (data.月工资.notnull()) ),'月工资']=7
data.loc[((data.月工资_min==7) & (data.月工资_max==0) & (data.月工资.notnull()) ),'月工资']=7
print(data.月工资.value_counts(sort=False))
#月工资分布情况
fig=plt.figure()
fracs=data.月工资.value_counts(sort=False)
labels=['面议','6000元/月以下','6000-8000元/月','8000-10000元/月','10000-20000元/月','20000-30000元/月','30000-50000元/月','500000元/月以上 ']
colors = ['purple','yellowgreen','lightskyblue','pink','coral','orange','green','lightyellow']
explode=[0,0,0,0,0.05,0,0,0]
patchs,l_text,p_text=plt.pie(x=fracs,explode=explode, labels=labels,colors=colors, autopct='%3.1f %%',
shadow=True, labeldistance=1.1, startangle=0, pctdistance=0.6)
plt.title('月工资分布情况',fontproperties=font)
for t in (l_text+p_text):
t.set_fontproperties(font)
#各经验等级的月工资情况
data.loc[(data.经验=='3年以上'),'经验']='3-5年'
print("****************************************************")
df=pd.DataFrame([data.经验[data.月工资==i].value_counts().rename(i) for i in range(8)])
print(df)
df.plot(kind='bar',colors=['yellowgreen','lightskyblue','pink','coral','orange','green','palegreen'])
plt.legend(loc='best',prop=font)
plt.xticks(df.index,labels,rotation=15,fontproperties=font)
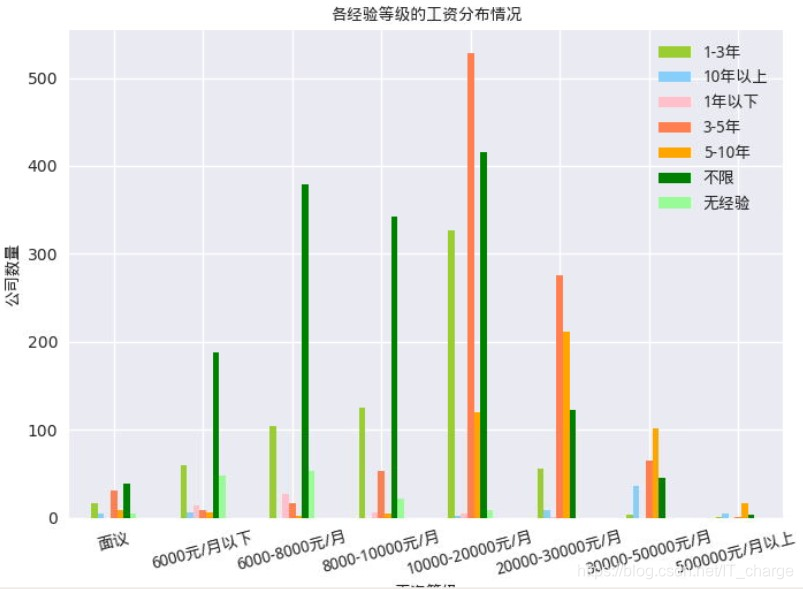
plt.title('各经验等级的工资分布情况',fontproperties=font)
plt.xlabel('工资等级',fontproperties=font)
plt.ylabel('公司数量',fontproperties=font)
#月工资与学历
print("****************************************************")
df=pd.DataFrame([data.最低学历[data.月工资==i].value_counts().rename(i) for i in range(8)])
print(df)
df.plot(kind='bar',stacked=True,colors=colors)
plt.legend(loc='best',prop=font)
plt.xticks(df.index,labels,rotation=15,fontproperties=font)
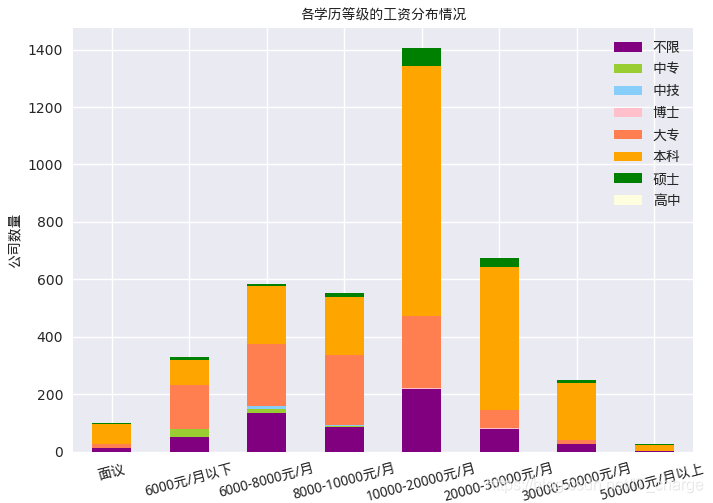
plt.title('各学历等级的工资分布情况',fontproperties=font)
plt.xlabel('工资等级',fontproperties=font)
plt.ylabel('公司数量',fontproperties=font)
#月工资与工作地点
print("****************************************************")
df=pd.DataFrame([data.工作地点.str.split('-',expand=True)[0][data.月工资==i].value_counts().rename(i) for i in range(8)]).T
print(df)
colors=['burlywood','yellowgreen','lightskyblue','pink','coral','orange','plum','oldlace']
d=df.plot(kind='bar',stacked=True,colors=colors)
plt.legend(loc='best',prop=font,labels=labels)
print(d.get_legend_handles_labels())
plt.xticks([i for i in range(len(df.index))],df.index,rotation=15,fontproperties=font)
plt.title('工作地点的工资分布情况',fontproperties=font)
plt.xlabel('工资等级',fontproperties=font)
plt.ylabel('公司数量',fontproperties=font)
print(df.values)
plt.show()
2.3 运行结果
一、实例一
二、实例二
2.4 结果分析
一、实例一
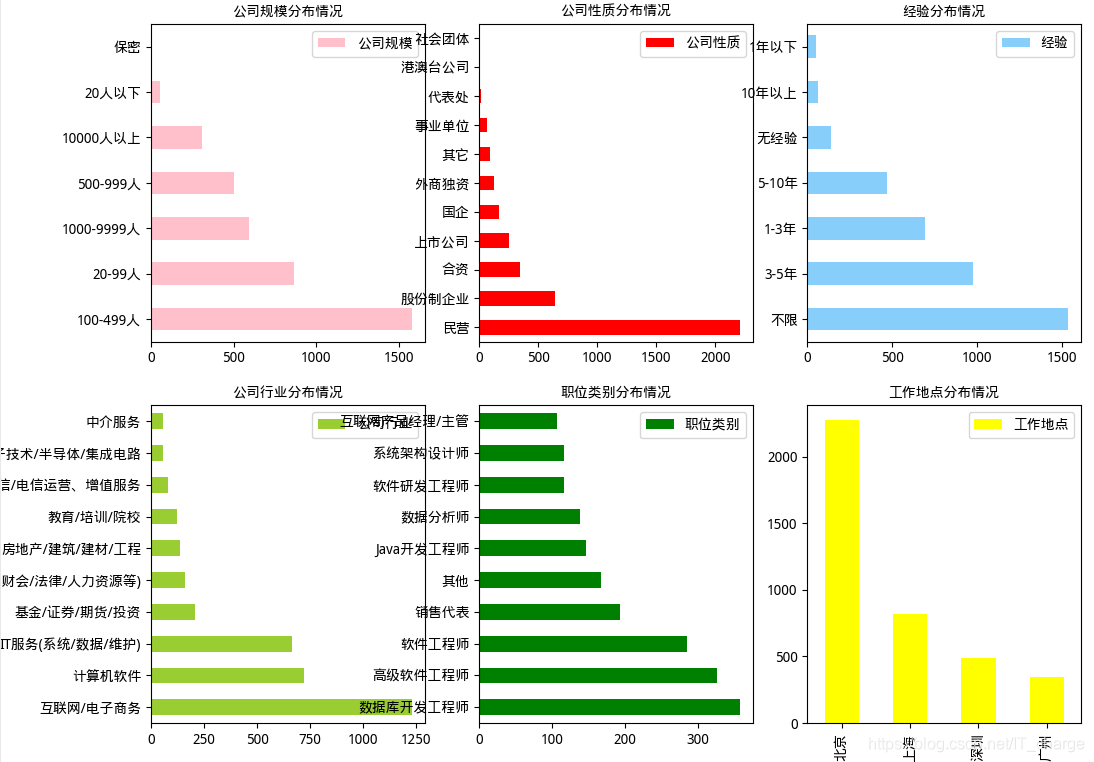
由上图可知:
公司规模在100-499人的公司招聘的大数据岗位最多。
公司性质为民营企业招聘的大数据岗位最多
经验要求大部分没有明确说明,剩下的基本上集中在1-5年之间
招聘公司主营行业主要集中在互联网、计算机、IT服务等行业
职位类别主要侧重于数据库开发,软件工程师等岗位
工作地点主要分布在北京,广东最少
二、实例二
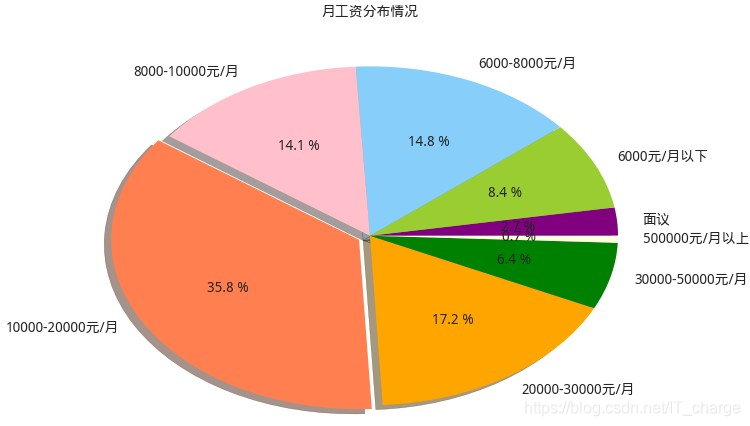
由上图可知:
公司招聘时,给的月工资主要集中在10000-20000元/月为35.8%,其次是20000-30000,10000-8000或6000-8000的也占很大比重,50000元/月以上的所占比例最小为0.7%,几乎可以省略。
薪资在1万元/月以下,经验要求由高到低的是1-3年,1-3年、无经验
薪资在1-2万元/月,经验要求由高到低的是3-5年,1-3年、5-10年
薪资在2-3万元/月,经验要求由高到低的是3-5年,5-10年、1-3年
薪资在3-5万元/月,经验要求由高到低的是5-10年,3-5年、10年以上
薪资在5万元/月以上,经验要求由高到低的是5-10年,3-5年、10年以上。
3 建立职位模型对应聘人员进行相似度的计算
3.1 知识前述
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
1.LDA生成过程
对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
1.对每一篇文档,从主题分布中抽取一个主题;
2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
3.重复上述过程直至遍历文档中的每一个单词。
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
2.LDA整体流程
先定义一些字母的含义:文档集合D,主题(topic)集合T
D中每个文档d看作一个单词序列<w1,w2,…,wn>,wi表示第i个单词,设d有n个单词。(LDA里面称之为wordbag,实际上每个单词的出现位置对LDA算法无影响)
D中涉及的所有不同单词组成一个大集合VOCABULARY(简称VOC),LDA以文档集合D作为输入,希望训练出的两个结果向量(设聚成k个topic,VOC中共包含m个词):
对每个D中的文档d,对应到不同Topic的概率θd<pt1,…,ptk>,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。
对每个T中的topict,生成不同单词的概率φt<pw1,…,pwm>,其中,pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topict的VOC中第i个单词的数目,N表示所有对应到topict的单词总数。
LDA的核心公式如下:p(w|d)=p(w|t)*p(t|d)
直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利用φt计算得到。
实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w|d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。
3LDA学习过程(方法之一)
LDA算法开始时,先随机地给θd和φt赋值(对所有的d和t)。然后上述过程不断重复,最终收敛到的结果就是LDA的输出。再详细说一下这个迭代的学习过程:
1.针对一个特定的文档ds中的第i单词wi,如果令该单词对应的topic为tj,可以把上述公式改写为:pj(wi|ds)=p(wi|tj)*p(tj|ds)
2.现在我们可以枚举T中的topic,得到所有的pj(wi|ds),其中j取值1~k。然后可以根据这些概率值结果为ds中的第i个单词wi选择一个topic。最简单的想法是取令pj(wi|ds)最大的tj(注意,这个式子里只有j是变量),即argmax[j]pj(wi|ds)
3.然后,如果ds中的第i个单词wi在这里选择了一个与原先不同的topic,就会对θd和φt有影响了(根据前面提到过的这两个向量的计算公式可以很容易知道)。它们的影响又会反过来影响对上面提到的p(w|d)的计算。对d中所有的w进行一次p(w|d)的计算并重新选择topic看作一次迭代。这样进行n次循环迭代之后,就会收敛到LDA所需要的结果了。
3.2 代码详解
做文档预处理, 将每篇文档,生成相应的token_list 。
#-*- coding:utf-8
from nltk.tokenize import WordPunctTokenizer
import traceback
import jieba
from nltk.corpus import stopwords
from nltk.stem.lancaster import LancasterStemmer
from collections import defaultdict
import re
# 分词 - 英文
def tokenize(document):
try:
token_list = WordPunctTokenizer().tokenize(document)
#print("[INFO]: tokenize is finished!")
return token_list
except Exception as e:
print(traceback.print_exc())
# 分词 - 中文
def tokenize_chinese(document):
try:
token_list = jieba.cut( document, cut_all=False )
#print("[INFO]: tokenize_chinese is finished!")
return token_list
except Exception as e:
print(traceback.print_exc())
# 去除停用词 -英文
def filtered_stopwords_en(token_list):
try:
token_list_without_stopwords = [ word for word in token_list if word not in stopwords.words("english")]
#print("[INFO]: filtered_words is finished!")
return token_list_without_stopwords
except Exception as e:
print(traceback.print_exc())
# 去除停用词 - 中文
def filtered_stopwords_ch(token_list,stopwords):
try:
token_list_without_stopwords = [word for word in token_list if word not in stopwords]
# print("[INFO]: filtered_words is finished!")
return token_list_without_stopwords
except Exception as e:
print(traceback.print_exc())
# 去除标点
def filtered_punctuations(token_list):
try:
punctuations = ['', '\n', '\t', ',', '.', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%','xa0',',']
token_list_without_punctuations = [word for word in token_list if word not in punctuations]
#print("[INFO]: filtered_punctuations is finished!")
return token_list_without_punctuations
except Exception as e:
print(traceback.print_exc())
# 过滤出中 - 英文
def filtered_chinese_english_words(token_list):
try:
r1 = re.compile(r'\w') # 使用正则表达式,筛选[A-Za-z0-9_]
r2 = re.compile(r'[^\d]') # 使用正则表达式,筛选[0-9_]
r4 = re.compile(r'[^_]')
r3 = re.compile(r'[\u4e00-\u9fa5]')
token_list = [word.lower() for word in token_list if (r3.match(word) != None) or (r3.match(word) == None and r1.match(word) and r2.match(word) and r4.match(word))]
# print("[INFO]: filtered_punctuations is finished!")
return token_list
except Exception as e:
print(traceback.print_exc())
# 词干化 -英文
def stemming( filterd_token_list ):
try:
st = LancasterStemmer()
stemming_token_list = [ st.stem(word) for word in filterd_token_list ]
#print("[INFO]: stemming is finished")
return stemming_token_list
except Exception as e:
print(traceback.print_exc())
# 去除低频单词
def low_frequence_filter( token_list ):
try:
word_counter = defaultdict(int)
for word in token_list:
word_counter[word] += 1
threshold = 0
token_list_without_low_frequence = [ word
for word in token_list
if word_counter[word] > threshold]
#print "[INFO]: low_frequence_filter is finished!"
return token_list_without_low_frequence
except Exception as e:
print(traceback.print_exc())
"""
功能:预处理
@ document: 文档
@ token_list: 预处理之后文档对应的单词列表
"""
def pre_process( document,ch_stopwords ):
try:
# token_list = tokenize(document)
token_list = tokenize_chinese(document)
token_list=filtered_chinese_english_words(token_list )
token_list = filtered_stopwords_ch(token_list, ch_stopwords)
token_list= filtered_punctuations(token_list)
#print("[INFO]: pre_process is finished!")
return token_list
except Exception as e:
print(traceback.print_exc())
"""
功能:预处理
@ document: 文档集合
@ token_list: 预处理之后文档集合对应的单词列表
"""
def documents_pre_process( documents,ch_stopwords ):
try:
documents_token_list = []
for document in documents:
token_list = pre_process(document,ch_stopwords)
documents_token_list.append(token_list)
print("[INFO]:documents_pre_process is finished!")
return documents_token_list
except Exception as e:
print(traceback.print_exc())
#-----------------------------------------------------------------------
def test_pre_process(documents,ch_stopwords):
# documents = ["he,he,he,we are happy!",
# "he,he,we are happy!",
# "you work!"]
documents_token_list = []
for document in documents:
token_list = pre_process(document,ch_stopwords)
documents_token_list.append(token_list)
for token_list in documents_token_list:
print(token_list)
# test_pre_process()
import pandas as pd
INPUT_PATH = "/data/python_pj6/bigdata"
ch_stopkeyword=[line.strip() for line in open('/data/python_pj6/stopword').readlines()] #加载停用词
data=pd.read_csv(INPUT_PATH)
test_pre_process(data.岗位描述,ch_stopkeyword)
根据预处理的结果,训练lda模型
#-*- coding:utf-8
'''
lda_model.py
这个文件的作用是lda模型的训练
根据预处理的结果,训练lda模型
'''
from pre_process import documents_pre_process
from gensim import corpora, models, similarities
import traceback
# 训练tf_idf模型
def tf_idf_trainning(documents_token_list):
try:
# 将所有文章的token_list映射为 vsm空间
dictionary = corpora.Dictionary(documents_token_list)
# 每篇document在vsm上的tf表示
corpus_tf = [ dictionary.doc2bow(token_list) for token_list in documents_token_list ]
# 用corpus_tf作为特征,训练tf_idf_model
tf_idf_model = models.TfidfModel(corpus_tf)
# 每篇document在vsm上的tf-idf表示
corpus_tfidf = tf_idf_model[corpus_tf]
#print "[INFO]: tf_idf_trainning is finished!"
return dictionary, corpus_tf, corpus_tfidf
except Exception as e:
print(traceback.print_exc())
# 训练lda模型
def lda_trainning( dictionary, corpus_tfidf, K ):
try:
# 用corpus_tfidf作为特征,训练lda_model
lda_model = models.LdaModel( corpus_tfidf, id2word=dictionary, num_topics = K )
# 每篇document在K维空间上表示
corpus_lda = lda_model[corpus_tfidf]
#print "[INFO]: lda_trainning is finished!"
return lda_model, corpus_lda
except Exception as e:
print(traceback.print_exc())
'''
功能:根据文档来训练一个lda模型,以及文档的lda表示
训练lda模型的用处是来了query之后,用lda模型将queru映射为query_lda
@documents:原始文档raw material
@K:number of topics
@lda_model:训练之后的lda_model
@corpus_lda:语料的lda表示
'''
def get_lda_model( documents, K , stopkeyword):
try:
# 文档预处理
documents_token_list = documents_pre_process( documents, stopkeyword)
# print(documents_token_list)
# 获取文档的字典vsm空间,文档vsm_tf表示,文档vsm_tfidf表示
dict, corpus_tf, corpus_tfidf = tf_idf_trainning( documents_token_list)
# print(corpus_tfidf)
# 获取lda模型,以及文档vsm_lda表示
lda_model, corpus_lda = lda_trainning( dict, corpus_tfidf, K )
print("[INFO]:get_lda_model is finished!")
return lda_model, corpus_lda, dict, corpus_tf, corpus_tfidf
except Exception as e:
print(traceback.print_exc())
#-*- coding:utf-8
'''
similarity.py
这个文件的作用是训练后的的lda模型,对语料进行相似度的计算
'''
from gensim import corpora, models, similarities
import traceback
'''
这个函数没有用到
'''
# 基于lda模型的相似度计算
def lda_similarity( query_token_list, dictionary, corpus_tf, lda_model ):
try:
# 建立索引
index = similarities.MatrixSimilarity( lda_model[corpus_tf] )
# 在dictionary建立query的vsm_tf表示
query_bow = dictionary.doc2bow( query_token_list )
# 查询在K维空间的表示
query_lda = lda_model[query_bow]
# 计算相似度
# simi保存的是 query_lda和corpus_lda的相似度
simi = index[query_lda]
query_simi_list = [ item for _, item in enumerate(simi) ]
return query_simi_list
except Exception as e:
print(traceback.print_exc())
'''
功能:语聊基于lda模型的相似度计算
@ corpus_tf:语聊的vsm_tf表示
@ lda_model:训练好的lda模型
'''
def lda_similarity_corpus( corpus_tf, lda_model ):
try:
# 语料库相似度矩阵
lda_similarity_matrix = []
# 建立索引
index = similarities.MatrixSimilarity( lda_model[corpus_tf] )
# 计算相似度
for query_bow in corpus_tf:
# K维空间表示
query_lda = lda_model[query_bow]
# 计算相似度
simi = index[query_lda]
# 保存
query_simi_list = [item for _, item in enumerate(simi)]
lda_similarity_matrix.append(query_simi_list)
print("[INFO]:lda_similarity_corpus is finished!")
return lda_similarity_matrix
except Exception as e:
print(traceback.print_exc())
保存结果
#-*- coding:utf-8
'''
save_result.py
这个文件的作用是保存结果
'''
import traceback
def save_similarity_matrix(matrix, output_path):
try:
outfile = open( output_path, "w" )
for row_list in matrix:
line = ""
for value in row_list:
line += ( str(value) + ',' )
outfile.write(line + '\n')
outfile.close()
print("[INFO]:save_similarity_matrix is finished!")
except Exception as e:
print(traceback.print_exc())
汇总前面各部分代码,对文档进行基于lda的相似度计算。
#-*- coding:utf-8
'''
train_lda_main.py
这个文件的作用是汇总前面各部分代码,对文档进行基于lda的相似度计算
'''
from lda_model import get_lda_model
from similarity import lda_similarity_corpus
from save_result import save_similarity_matrix
import traceback
import pandas as pd
INPUT_PATH = "/data/python_pj6/bigdata"
OUTPUT_PATH = "/data/python_pj6/lda_simi_matrix.txt"
# data=pd.read_csv(INPUT_PATH)
# print(data.岗位描述)
# print(data.info())
def train(documents,stopword):
try:
# 语料
# documents = ["Shipment of gold damaged in a fire",
# "Delivery of silver arrived in a silver truck",
# "Shipment of gold arrived in a truck"]
# 训练lda模型
K = 2 # number of topics
lda_model, _, _,corpus_tf, _ = get_lda_model(documents, 50,stopword )
# 计算语聊相似度
lda_similarity_matrix = lda_similarity_corpus( corpus_tf, lda_model )
# 保存结果
save_similarity_matrix( lda_similarity_matrix, OUTPUT_PATH )
return lda_similarity_matrix
except Exception as e:
print(traceback.print_exc())
def main(document):
INPUT_PATH = "/data/python_pj6/bigdata"
data = pd.read_csv(INPUT_PATH)
stopword = [line.strip() for line in open('/data/python_pj6/china_stopword').readlines()] # 加载停用词
frames=[document,data]
df = pd.concat(frames)
# print(df)
similiry=train(df.岗位描述, stopword)
for index,simi in enumerate(similiry[0]):
if simi>0.99:
print(data[index:index+1][['工作名称','公司名称','岗位描述']])
# print(index,'---',simi)
test_data=pd.read_csv('/data/python_pj6/test_data')
main(test_data)
