一些细节和补充
define和const的区别
角度1:
就定义常量说的话:
const 定义的常数是变量 也带类型, #define 定义的只是个常数 不带类型。
角度2: 就起作用的阶段而言: define是在编译的预处理阶段起作用,而const是在 编译、运行的时候起作用。
角度3: 就起作用的方式而言:
define只是简单的字符串替换,没有类型检查。而const有对应的数据类型,是要进行判断的,可以避免一些低级的错误。
#define N 2+3 //我们预想的N值是5,我们这样使用N
double a = N/2; //我们预想的a的值是2.5,可实际上a的值是3.0
角度4: 就空间占用而言: 例如:
#define PI 3.14 //预处理后 占用代码段空间 const float PI=3.14; //本质上还是一个 float,占用数据段空间 1 2
角度5: 从代码调试的方便程度而言: const常量可以进行调试的,define是不能进行调试的,因为在预编译阶段就已经替换掉了
角度6: 从是否可以再定义的角度而言:
const不足的地方,是与生俱来的,const不能重定义,而#define可以通过#undef取消某个符号的定义,再重新定义。
角度7: 从某些特殊功能而言: define可以用来防止头文件重复引用,而const不能,可以参看下面代码:
#ifndef xxx//如果没有定义xxx #define xxx//定义xxx //这里是你的代码 #endif //结束如果
define和typedef的区别
define是预处理指令,用来定义常量或者宏。typedef是类型定义指令,用来定义类型别名。
例如:
#define PI 3.14
它相当于把PI替换成3.14,
而
typedef int age;
则是定义了一种类型叫做age,它是int类型.
这两个指令最主要的区别在于define是简单的文本替换,而typedef是类型定义。
初始化memset
this指针
this 实际上是成员函数的一个形参,在调用成员函数时将对象的地址作为实参传递给 this。不过 this 这个形参是隐式的,它并不出现在代码中,而是在编译阶段由编译器默默地将它添加到参数列表中。
this指针是类的指针,指向对象的首地址。
this指针只能在成员函数中使用,在全局函数、静态成员函数中都不能用this。
this指针只有在成员函数中才有定义,且存储位置会因编译器不同有不同存储位置。
this指针只能在一个类的成员函数中调用,它表示当前对象的地址
使用情景
1.用于同名情况 参数的优先级高于数据成员
当形参数与成员变量名相同时用于区分,如this->n = n (不能写成n = n)
通过this指针访问自身
2.在类的非静态成员函数中返回类对象本身的时候,直接使用 return *this;

特点
(1)this只能在成员函数中使用,全局函数、静态函数都不能使用this。实际上,成员函数默认第一个 参数为T * const this
class A{
public:
int func(int p){} 4 };
//其中,func的原型在编译器看来应该是:
int func(A * const this,int p);
(2)由此可见,this在成员函数的开始前构造,在成员函数的结束后清除。这个生命周期同任何一个 函数的参数是一样的,没有任何区别。当调用一个类的成员函数时,编译器将类的指针作为函数的this 参数传递进去。如:
A a;
a.func(10);
//此处,编译器将会编译成:
4 A::func(&a,10);
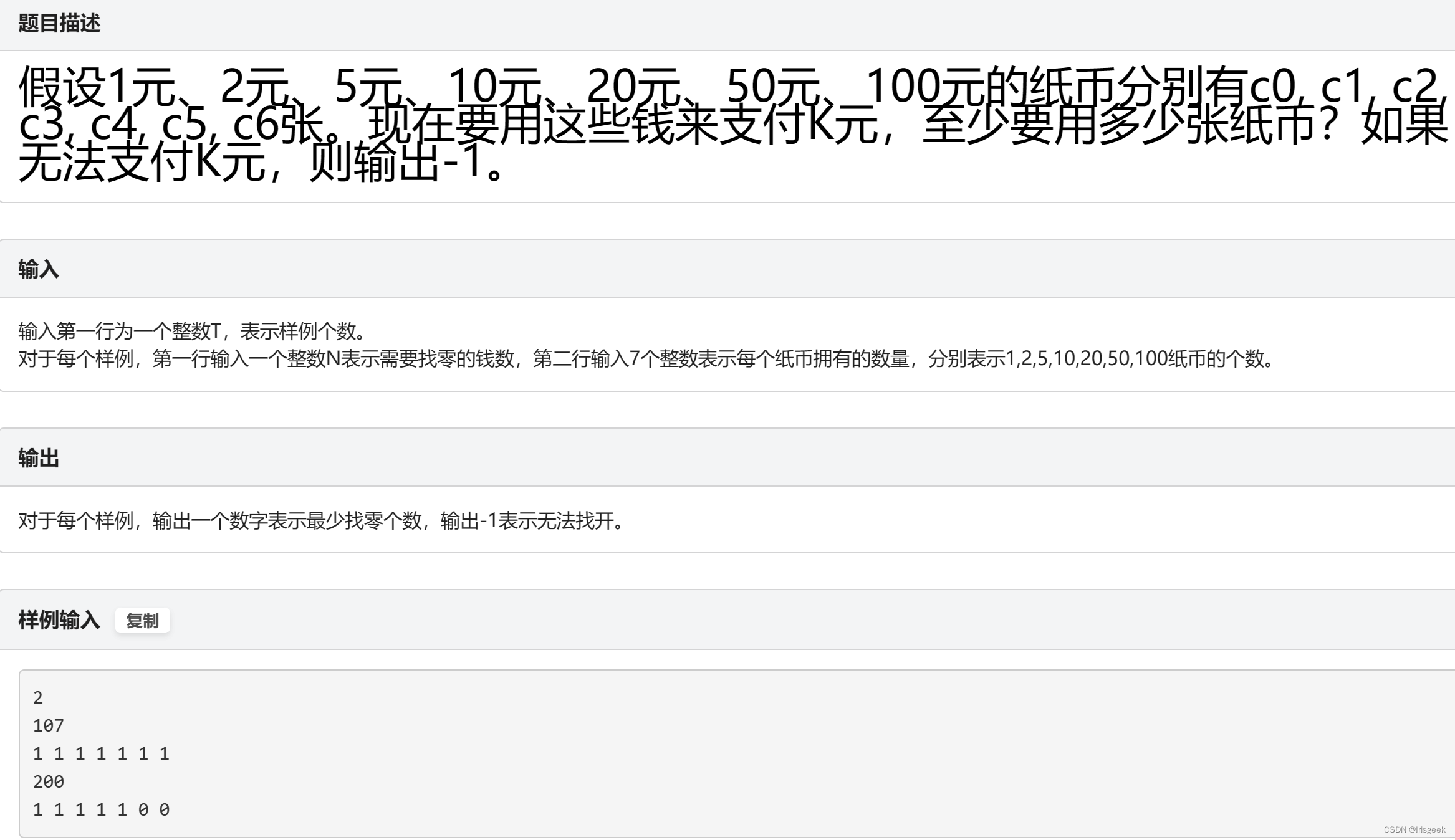
static members
静态变量是属于一个class的 而不是属于某个具体的变量 可以被类所有的对象访问 该内存是共享的 本质上和全局变量无区别 但静态变量只能被class访问

private:
static int NumbeOfObjects;
static double getNumberOfObjects();
使用:
类名::变量名/成员函数名
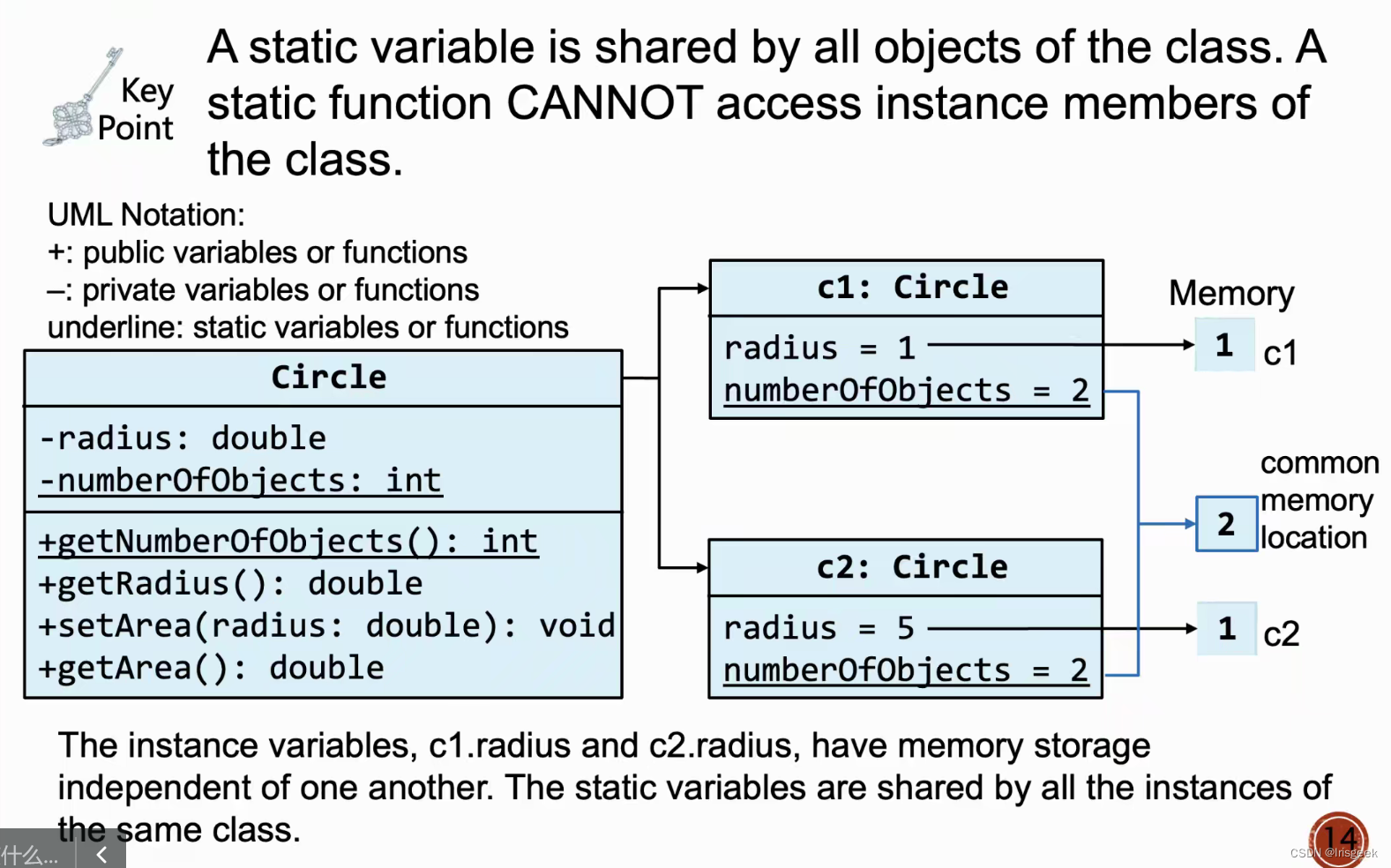

const
const member function常量成员函数
- 在成员函数后加const 则该函数不会修改内部数据
class Circle
{
public:
double getArea()const;
}
constant pointer常量指针
指针是常量 指针所指不可改
double r=5,s;
double* const p=&r;
p=&s;//错
*p=6;//对
constant data指针常量
指针所指的地址 内容不能改
double r=5,s;
const double* p=&r;
p=&s;//对
*p=6;//错
const离谁近修饰谁
const (int*)修饰int 顾指针所指地址的数值内容不能改
(int*)const修饰指针 所以指针指向不能改
new动态内存分配
new
- 指针所指的内存会一直存在,直到退出程序
int *p1=new int(4);
int *p2=new int[10];
- 若内存一直不释放,会造成内存泄漏,因此需要主动释放
delete
delete p1;
delete []p2;//数组的内存释放要加方括号
- delete只能删除new出来的内存空间
int x=10;
int *p=&x;
delete p;//错 变量x不是通过new定义的
- 指针p指向新空间前必须先delete
int *p=new int;
*P=45;
p=new int;//存放45的内存空间没释放 导致内存泄漏
- delete后若不指向新地址尽量将p指向NULL 防止不小心访问它
int*p=new int(10);
delete p;
p=NULL;
- 不要delete两次
数学函数
取两位小数(四舍五入)
double i = 2.235687;
double j = round(i * 100) / 100;
取整
- 向下取整
1.整数除法运算符 / 代表向下取整, 常用于计算当中(适用于正数,对于负数计算来说,只是在正数的结果上加了个负号) 例如:5 / 2 = 2, -5 / 2 = -2
2.floor()函数, floor(x)返回一个小于或等于x的最大整数 例如:floor(2.5) = 2, floor(-2.5) = -3
3.直接舍去小数部分,赋值给整数变量(适用于正数) 例如:int a = 2.5, b = int(2.5), a, b数值都是2
- 向上取整
1.ceil()函数, ceil(x)返回一个大于x的最小正数 例如:ceil(2.5) = 3, ceil(-2.5) = -2
2.公式 x = (a-1) / b + 1, 变形一下得 x = (a + b - 1) / b 直接舍去小数 部分,赋值给整数变量(适用于负数) 例如:int a = -2.5, b = int(-2.5), a, b数值都是-2
取绝对值
int abs(int x)
double fabs(double x)
开方与次幂
sqrt(x);
pow(x,n);
指针与数组
字符型指针
将字符串赋给字符型指针时,指针指向第一个字符的地址。
不同于字符型数组的是,字符型指针可以不在初始化时赋值
char *p;
*p="abcde";
指针数组
:数组中的每个元素都是指针变量
int *p[10];
堆内存分配/动态内存分配(new)
int *p;
p=new int(666);//可以在动态申请的同时初始化
delete p;//使用完后要用delete释放,才能再次赋值
int size;
cin>>size;
p=new int [size] ;//数组长度可以是变量,但数组不能在动态申请时初始化
函数
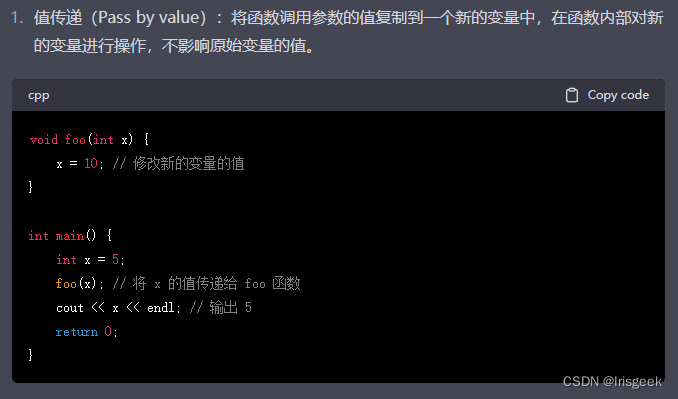
参数的传递
值传递
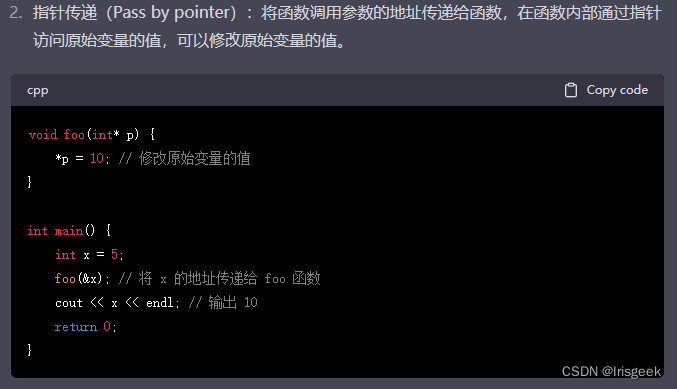
指针传递
指针的引用
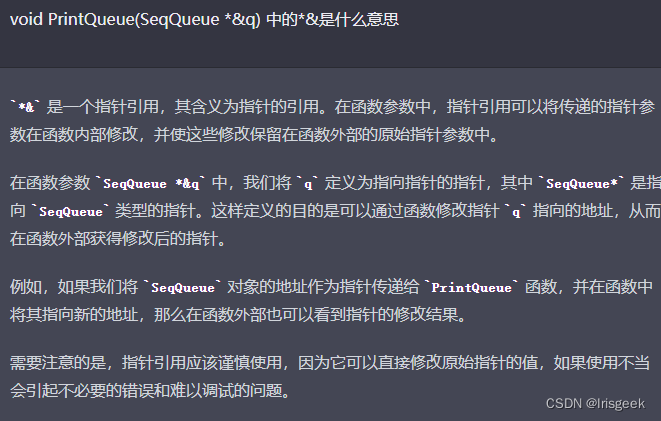
引用传递
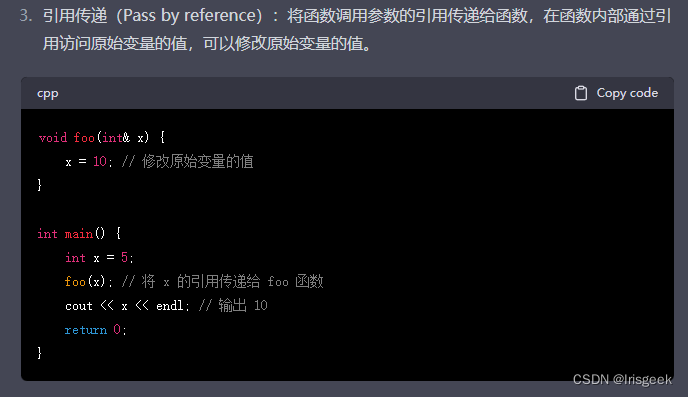
右值引用传递
函数的递归调用(自调用)recursive function
满足条件:
1.用相同方法解决子问题
2.参数是递增或递减的(一般是递减的)
3.有一个或多个终止条件
ps:函数内必须设置调用终止的条件,不能无休止地进行下去。大部分情况,递归执行效率不比非递归高,只是看起来简洁。
- 直接递归(自己调用自己)
先在栈里分配空间(栈的特点是先进后出),栈为空为止这个函数结束
求n的阶层
long fact(int n)//求n!
{
if(n=0)//Base case
return 1;
else
return n*fact(n-1);//自调用
}
斐波那契数列
int fib (int index)
{
if(index==0)//Base case(终止条件)
return 0;
else if(index==1)//Base case
return 1;
else
return fib(index-1)+fib(index-2);
}
汉诺塔
- 间接递归(F1调用F2,F2又调用F1)
指针函数
可用于返回多个顺序存放的值(如数组,字符串等)
定义形式:
类型*函数名(参数)
char*fun(int n)
{
static char *p[]={"one","two","three"};//static防止函数返回后变量消失
return p[n-1];
}
int main()
{
int n;
cin>>n;
cout<<fun(n)<<endl;
return 0;
}
内联函数
一般只将那些短小的、频繁调用的函数声明为内联函数。
函数调用是有时间和空间开销的。程序在执行一个函数之前需要做一些准备工作,要将实参、局部变量、返回地址以及若干寄存器都压入栈中,然后才能执行函数体中的代码;函数体中的代码执行完毕后还要清理现场,将之前压入栈中的数据都出栈,才能接着执行函数调用位置以后的代码。
如果函数体代码比较多,需要较长的执行时间,那么函数调用机制占用的时间可以忽略;如果函数只有一两条语句,那么大部分的时间都会花费在函数调用机制上,这种时间开销就就不容忽视。
为了消除函数调用的时空开销,C++
提供一种提高效率的方法,即在编译时将函数调用处用函数体替换,类似于C语言中的宏展开。这种在函数调用处直接嵌入函数体的函数称为内联函数(Inline Function),又称内嵌函数或者内置函数。
指定内联函数的方法很简单,只需要在函数定义处增加 inline 关键字。
注意,要在函数定义处添加 inline 关键字,在函数声明处添加 inline 关键字虽然没有错,但这种做法是无效的,编译器会忽略函数声明处的 inline 关键字。
inline int Add(int x, int y) {
return x + y;
}
int main() {
cout<<"5 + 8 = "<<Add(5, 8)<<endl;
cout<<"10 + 20 = "<<Add(10, 20)<<endl;
return 0;
}
在代码执行时是这样的:
int main() {
cout<<"5 + 8 = "<<5 + 8<<endl;
cout<<"10 + 20 = "<<10 + 20<<endl;
return 0;
}
关于字符串的重载函数
string s1;
getline(cin,s1);
s1.size();
s1.length();```
s1.assign("abcdefg");//abcdefg
s1.assign("abcdefg",2,3);//cde( ,第二位开始,长度为3)
s1.assign("abcdefg",5);//abcde( ,第0-5位)
s1.assign(4,'G');//GGGG
string s1("abcdefgh");
s1.at(2);//c
s1.clear();//s1变成空了
s1.erase(3,2);//abcfgh(第三位开始,擦除长度为2)
s1.empty();//0 若s1为空 则输出1
string s1("abcdefg"),s2("abzdefg";
s1.compare(s2);//-1 只比较第一个不同的字符 s1小于输出-1
s2.compare(s1);//1 大于输出1
s1.compare("abcdefg");//0 等于输出0
string s1("abcdefg");
s1.substr(1,2);//bc,2表示长度
s1.substr(3);//defg 输出除去前三个字符的s1(或者说从第三位开始输出一直到最后)
string s1("abcdefgcdee");
s1.find("cd");//2
s1.find('c',2);//2从第二位开始查找‘c’ (包括第二位)
s1.find('c',3);//7
s1.find(s2);
s1.rfind('c');//7 查找最后一次出现的位置
s1.rfind("cd");//7 查找的是最后一次出现cd,输出c的位置
s1.find_first_of("zmc");//2 查找的是括号中任意一个字符
s1.find_last_of();
s1.find_first_not_of("abce");//3 查找第一个不是a,b,c或d的位置
append追加只能在最后
string s1("hello");
s1.append("Iris.");//helloIris.
s1.append("I am Mike.",1,5);//hello am M
s1.append("abcdefg",5);//helloabcde
s1.append(4,'a');//helloaaaa
insert插入可以在任意位置
string s1("abcdefg");
s1.insert(2,"mmmm");//abmmmmcdefg 在第二位之前插入mmmm
s1.insert(1,4,'s');//assssbcdefg
replace 替换可擦除s1中的某些字符
string s1("abcdef");
s1.replace(2,3,"mmmm");//abmmmmf (从第二位开始,长度为3,替换为“mmmm”)
string s1("abBcd");
toupper(s1);//ABBCD
tolower(s1);//abbcd
类
类:实际上是一种新的用户自定义的数据类型
对象=数据+操作
类不占用内存空间
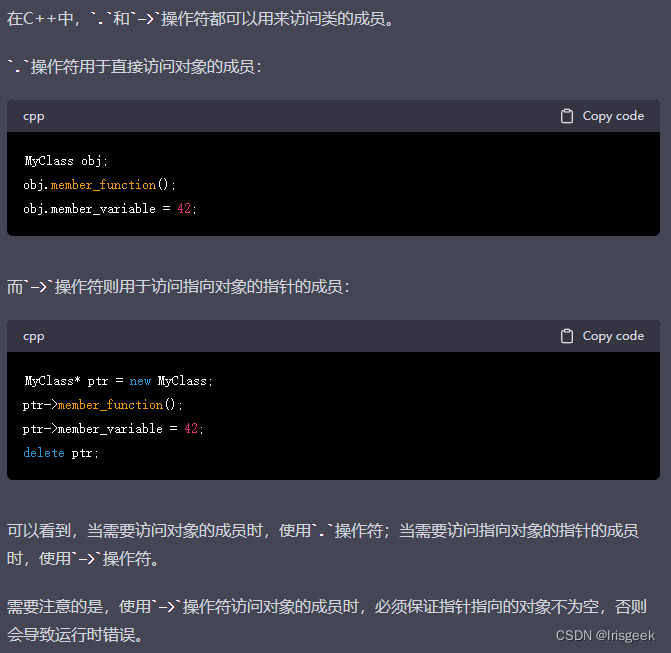
类成员的访问
class定义类
-
抽象包括数据抽象和控制抽象
-
任何一个数据类型包括值域(domain)和操作
抽象数据类型(abstract data type)(ADT)
给出数据类型的定义 -
公有成员函数
-
类成员包含两种。
1.数据成员 【静态属性】,一般是私有的
2.成员函数(函数成员)【动态行为】,一般是公有的 -
私有的类成员(如数据成员)只能被成员函数或友元函数访问,而客户端代码无法访问。
-
类的范围:
成员函数可以访问另外的成员(数据成员或成员函数),不论它们放在什么位置。 -
进行类操作
用. (成员选择操作符)调用 -
引用方法 :对象名.成员名 或 对象名.成员函数名
-
通过指针访问时 用->
-
定义类的数据成员和成员函数放在".h"文件(specification file)
将成员函数的实现放在 ".cpp"文件中(implementation file) -
“.cpp"文件中首先要包含类的定义”.h"
-
若从文件中输入输出 头文件应用 fstream(文件流) ifstream(输入文件流) ofstream(输出文件流)
-
cin和cout也是类的对象 get和ignore是它的成员函数 cin.getline()
-
公共成员函数为客户代码和类对象提供了接口 类似库函数
-
不同类的成员函数可以有相同的名字 类.成员函数名()
-
实现文件(".cpp"文件)中定义时 前面要给类名 作用域
依 setPoint 成员函数来说, 在类内声明的形式为 void setPoint(int x, int y); 那么在类外对其定义时函数头就应该是 void Point::setPoint(int x, int y) 这种形式, 其返回类型、成员函数名、参数列表都要与类内声明的形式一致。
返回类型 类名::成员函数名(参数列表)
{
//函数体
}
#include <iostream>
using namespace std;
class Point
{
public:
void setPoint(int x, int y); //在类内对成员函数进行声明
void printPoint();
private:
int xPos;
int yPos;
};
void Point::setPoint(int x, int y) //通过作用域操作符 '::' 实现setPoint函数
{
xPos = x;
yPos = y;
}
void Point::printPoint() //实现printPoint函数
{
cout<< "x = " << xPos << endl;
cout<< "y = " << yPos << endl;
}
int main()
{
Point M; //用定义好的类创建一个对象 点M
M.setPoint(10, 20); //设置 M点 的x,y值
M.printPoint(); //输出 M点 的信息
return 0;
}
- 当成员函数只使用数据成员而不改变数据成员的值时 可加const 防止误操作
void time::write() const
{
}
- #开头的是命令行
#include表示将头文件包含进来
#define宏定义
#ifndef 是if not define 的简写,是宏定义的一种,实际上确切的说,这应该是预处理功能三种(宏定义、文件包含、条件编译)中的一种----条件编译。在c++语言中,#ifdef的作用域只是在单个文件中。所以如果h文件里定义了全局变量,即使采用#ifdef宏定义,多个c文件包含同一个h文件还是会出现全局变量重定义的错误。使用#ifndef可以避免下面这种错误:如果在h文件中定义了全局变量,一个c文件包含同一个h文件多次,如果不加#ifndef宏定义,会出现变量重复定义的错误;如果加了#ifndef,则不会出现这种错误。
#ifndef x //先测试x是否被宏定义过
#define x
程序段1 //如果x没有被宏定义过,定义x,并编译程序段 1
#endif
程序段2 //如果x已经定义过了则编译程序段2的语句,“忽视”程序段 1`
条件指示符#ifndef 的最主要目的是防止头文件的重复包含和编译。
#ifndef 和 #endif 要一起使用,如果丢失#endif,可能会报错。
- “.h"文件中放的是一个类的规范说明,只有声明,没有实现。函数的实现放在”.cpp"文件中
//time.h
//Specification file
#ifndef TIME_H
#define TIME_H
class Time
{
public://下面是三个成员函数
void set(int hours,int minutes,int seconds);
void write() const;//const表示这个函数对数据成员不进行修改
bool equal(Time othertime) const;//参数是另一个对象
//以下是两个构造函数(用于给对象初始化的)(无返回值类型)
Time (int hours,int minutes,int seconds);//构造函数带参数
Time();
~Time();//析构函数
private://以下是三个数据成员
int hrs;
int mins;
int secs;
};
#endif
//time.cpp
//implementation file
#include"time.h"
Time::Time()
{
hrs=0;
mins=0;
secs=0;
}
Time::Time(int hours,int minutes,int seconds)
{
hrs=hours;
mins=minutes;
secs=seconds;
}
//client.cpp
//appointment program
#include "time.h"
int main()
{
Time departureTime;//调用了无参的构造函数
Time movieTime(19,30,0);//调用了带三个参数的构造函数
}
构造函数
- 本质上是一个成员函数
- 构造函数的名字和类名相同,且没有返回值类型
- 一个类可以有多个构造函数(构造函数可重载),用其所带的不同参数将它们区分
- 若没有人为构造函数,系统会默认构造一个无参的函数
- 构造函数在定义对象时会被自动调用
- 初始化

析构函数
//Circle.h
class Circle
{
public:
circle(double r);//构造函数
~circle();//析构函数无需参数
}
//Circle.cpp
circle::~Circle()
{
}
结构体类型定义类
- struct定义类
结构体类型的声明通常会放在头文件中#include “animaltype.h”
//结构体类型的声明
struct animaltype
{
long id;
string name;
int age;
float weight;//id,name,age,weight称为结构体成员
};//一定要记得加分号
//访问结构体里的成员 结构体名.结构体成员名
animaltype.id=12138;
animaltype.age=3;
结构体数组
- 函数的返回值类型也可以是结构体类型变量
层次结构体类型(嵌套)
- 一个结构体类型的成员是另一个结构体
- 作用:结构体中的成员可以是另一个个结构体
- `#include
using namespace std;
#include
//学生结构体定义
struct student
{
//成员列表
string name; //姓名
int age; //年龄
int score; //分数
};
//教师结构体定义
struct teacher
{
//成员列表
int id; //职工编号
string name; //教师姓名
int age; //教师年龄
struct student stu; //子结构体 学生
};
int main() {
struct teacher t1;
t1.id = 10000;
t1.name = "老王";
t1.age = 40;
t1.stu.name = "张三";
t1.stu.age = 18;
t1.stu.score = 100;
cout << "教师 职工编号: " << t1.id << " 姓名: " << t1.name << " 年龄: " << t1.age << endl;
cout << "辅导学员 姓名: " << t1.stu.name << " 年龄:" << t1.stu.age << " 考试分数: " << t1.stu.score << endl;
system("pause");
return 0;
}
`
例如:每个老师辅导一个学员,一个老师的结构体中,记录一个学生的结构体
union共用体定义类
在程序运行时只会存其中一个成员
继承
继承Inheritance
基类(父类)和派生类(子类)
派生类可访问它对应的基类中的protect 数据成员
class Circle(派生名):public GeometricObject(基类名)
{
//Circle中专属的函数
}
访问权限
- 所有的父类私有在子类不可访问
公共继承 保持不变
保护继承 变保护
私有继承 变私有
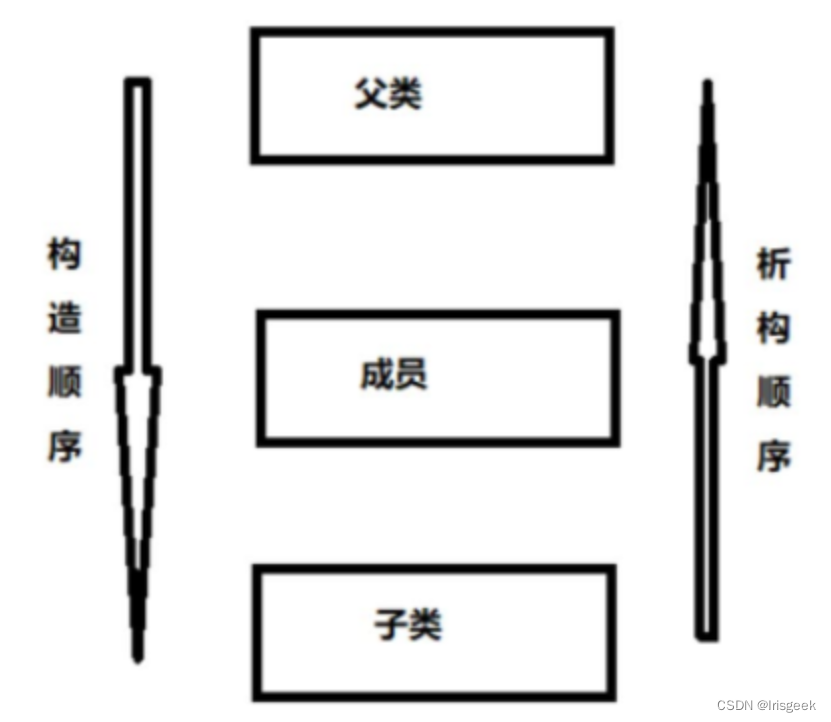
顺序
- 子类构造析构顺序
多继承
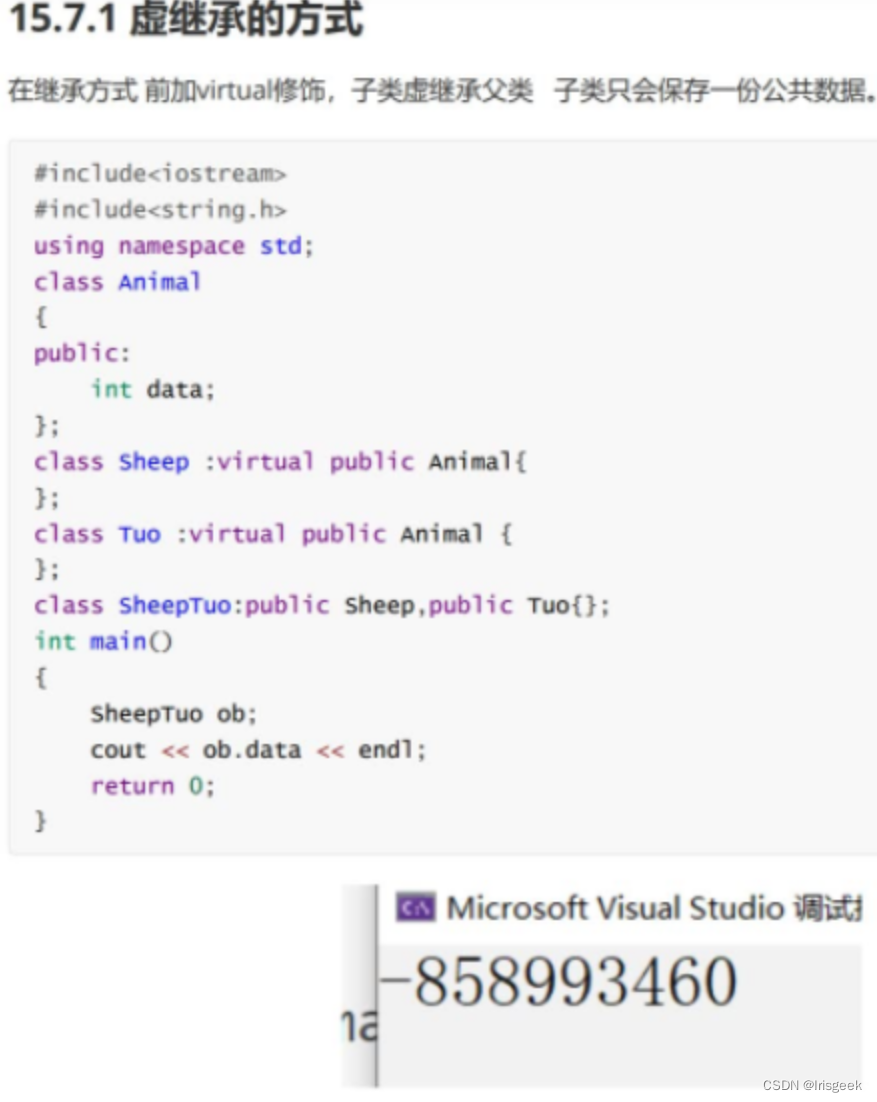
虚继承
多态
静态多态
- 编译时多态,早绑定:函数重载、运算符重载、重定义

动态多态
- 运行时多态,晚绑定:虚函数
虚函数的定义
- 多态条件:有继承、子类重写父类的虚函数,父类的指针指向子类空间。
- 虚函数(virtual functions 本质是函数指针)
在父类中的成员函数前加virtual
虚函数动态绑定时必须用引用传递或指针传递
纯虚函数与抽象类
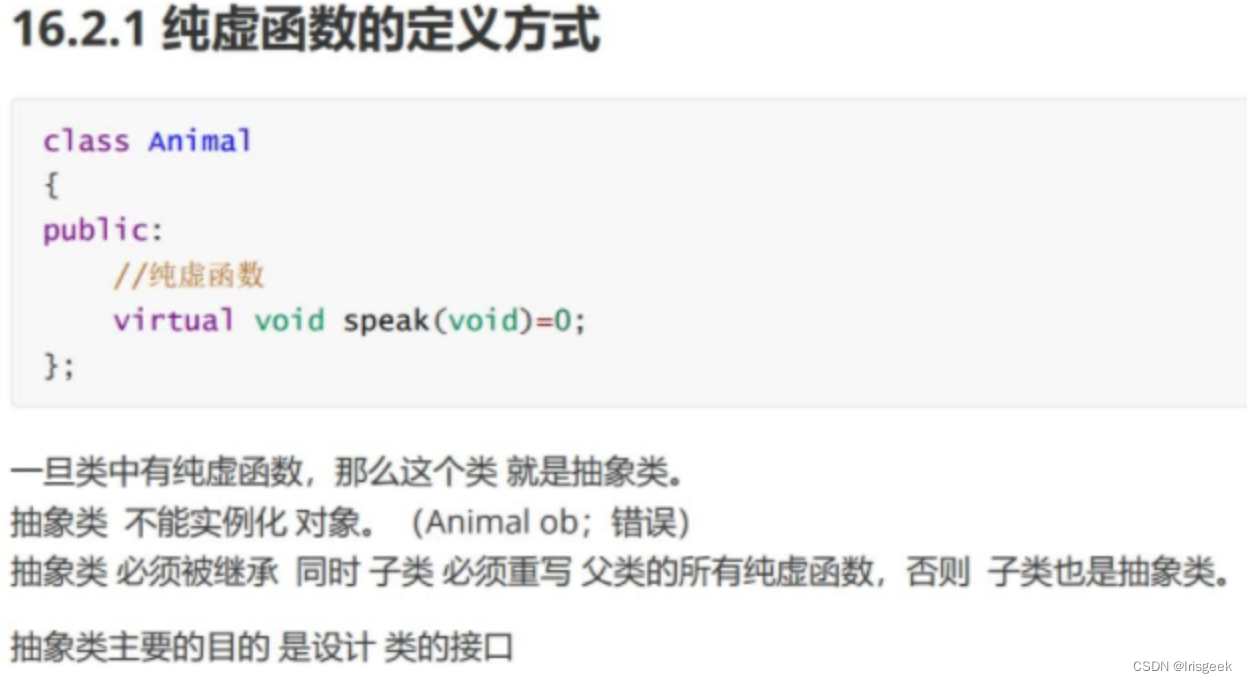
该函数在父类内不实现(说白了就是只定义不实现)子类必须重写父类的所有纯虚函数
virtual double getArea() const=0;
虚函数与纯虚函数的区别

虚析构函数与纯虚析构函数
- 虚析构函数

- 纯虚析构函数
- 区别


代码示例
#include <iostream>
#include <string>
using namespace std;
class GeometricObject{
public:
GeometricObject(){
//cout << "construct GeometricObject" << endl;
}
bool isfilled;
string color;
string getColor() const{
return color;
}
virtual string toString() const {
return "GeometricObject";
}
~GeometricObject(){
//cout << "destrcut GeometricObject" << endl;
}
};
class Circle : public GeometricObject {
public:
double radius;
string toString() const {
return "Circle";
}
};
class Rect : public GeometricObject{
public:
string toString() const {
return "Rect";
}
};
void printColor(const GeometricObject b){
cout << "color: " << b.getColor() << endl;
}
void print(const GeometricObject & b){
cout << "In print: "<< b.toString() << endl;
}
void printWithPointer(GeometricObject * b){
cout << "In printWithPointer: "<< b->toString() << endl;
}
int main(){
GeometricObject b;
Circle c;
Rect r;
b.color = "green base";
c.color= "red circle";
r.color="yellow rect";
cout << b.toString() << endl;
cout << c.toString() << endl;
cout << r.toString() << endl;
print(b);
print(c);
print(r);
printWithPointer(&b);
printWithPointer(&c);
printWithPointer(&r);
printColor(b);
printColor(c);
printColor(r);
return 0;
}
泛型编程
https://blog.csdn.net/weixin_45423515/article/details/126593257?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166746376216782395325017%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=166746376216782395325017&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-126593257-null-null.142v62control_1,201v3add_ask,213v1control&utm_term=%E6%B3%9B%E5%9E%8B%E7%BC%96%E7%A8%8B&spm=1018.2226.3001.4187
STL/标准模板库
#include<iostream>
#include<vector>//或 <list> <queue>
#include<algorithm>
- 对象是通过指针连接在一起的
程序=数据结构+算法
- 数据结构:包括逻辑结构和物理结构
- 物理/存储结构:包括顺序存储结构(占连续的空间eg:vector)和链式存储结构(eg:链表list)
容器
是被模板化了的数据结构
- 每个容器有相应的成员函数
公用成员函数
顺序容器sequence container
线性数据结构
向量vector
是大小可改变的数组,用于替代内置数组。
- 定义:
vector<T>v
vector <int> v1(100),
vector<int> v2(100,val)//定义了100个,每个的元素都是val
vector<int>
vector<int *>
vector<类名>
//用向量b给向量a赋值,a的值完全等价于b的值
vector<int>a(b);
//将向量b中从0-2(共三个)的元素赋值给a,a的类型为int型
vector<int>a(b.begin(),b.begin+3);
//从数组中获得初值
int b[7]={1,2,3,4,5,6,7};
vector<int> a(b,b+7);
- 成员函数
#include<vector>
vector<int> a,b;
//b为向量,将b的0-2个元素赋值给向量a
a.assign(b.begin(),b.begin()+3);
//a含有4个值为2的元素
a.assign(4,2);
//返回a的最后一个元素
a.back();
//返回a的第一个元素
a.front();
//返回a的第i元素,当且仅当a存在
a[i];
//清空a中的元素
a.clear();
//判断a是否为空,空则返回true,非空则返回false
a.empty();
//删除a向量的最后一个元素
a.pop_back();
//删除a中第一个(从第0个算起)到第二个元素,也就是说删除的元素从a.begin()+1算起(包括它)一直到a.begin()+3(不包括它)结束
a.erase(a.begin()+1,a.begin()+3);
//在a的最后一个向量后插入一个元素,其值为5
a.push_back(5);
//在a的第一个元素(从第0个算起)位置插入数值5,
a.insert(a.begin()+1,5);
//在a的第一个元素(从第0个算起)位置插入3个数,其值都为5
a.insert(a.begin()+1,3,5);
//b为数组,在a的第一个元素(从第0个元素算起)的位置插入b的第三个元素到第5个元素(不包括b+6)
a.insert(a.begin()+1,b+3,b+6);
//返回a中元素的个数
a.size();
//返回a在内存中总共可以容纳的元素个数
a.capacity();
//将a的现有元素个数调整至10个,多则删,少则补,其值随机
a.resize(10);
//将a的现有元素个数调整至10个,多则删,少则补,其值为2
a.resize(10,2);
//将a的容量扩充至100,
a.reserve(100);
//b为向量,将a中的元素和b中的元素整体交换
a.swap(b);
//b为向量,向量的比较操作还有 != >= > <= <
a==b;
v.begin()//返回第一个元素的位置
v.end()//返回最后一个元素后面的一个位置(实际不存在)
v.rend()//返回第一个元素的前导位置(实际上是该容器反转后的end())
v.size()//返回元素数量
v.empty()//判断向量是否为空
v.capacity()//返回最大容量
v.push_back()//在最后插入一个元素
v.pop_back()//删除最后一个元素
v.front()//返回第一个元素
v.back()//返回最后一个元素
v.insert(位置,100)//在位置前插入100
v.insert(位置,2,100)//在位置前插入两个100
v.insert(位置,v2.begin(),v2.begin()+3)//插入v2的一段(包括头不包括尾)
v.erase(v.begin()+5);//擦除第v.begin()+5个
v.erase( , )//擦除区间(左开右闭)
clear()//清除
- 使用
#include<vector>
//数组方式引用向量
const int N=10;
vector<int>ivec(N);
for(int i=0;i<10;i++)
{
cin>>ivec[i];
}
int ia[N];
for(int i=0;i<10;i++)
{
ia[i]=ivec[i];
}
//STL方式
vector<string>svec;
while(cin>>word)
{
svec.push_back(word);//在最后插入
}
vector<int>::iterator it=c.begin()//迭代器方式 it相当于是一个指针
- 错误的赋值方式
vector<int>a;
for(int i=0;i<10;++i){a[i]=i;}
//下标只能用来获取已经存在的元素
链表list
- 是线性元素的集合 可变长度(能增加删除)
- 是双向链表 可在任何位置进行插入和删除操作
- 除了最后一个元素 都有唯一的直接后继 除了第一个元素 都有唯一的直接前区
- 双向迭代器 有头尾两个指针
- 与vector的区别
- vector底层实现是驻足;list是双向链表。 vector支持随机访问,list不支持。 vector是顺序内存,list不是。
- vector在中间节点进行插入删除会导致内存拷贝,list不会。
- vector一次性分配好内存,不够时才进行扩容;list每次插入新节点都会进行内存申请。
- vector随机访问性能好,插入删除性能差;list随机访问性能差,插入删除性能好。
- vector和list的使用场景
- 如果需要高效的随机存取,而不在乎插入和删除的效率(很少使用插入和删除操作),选用vector
- 如果需要大量的插入和删除的操作,随机存取很少使用,选用list。
- 成员函数
操作 功能
void merge( list& other ); 归并二个已排序链表为一个。链表应以升序排序。
void splice( const_iterator pos, list& other ); 从 other 转移所有元素到 *this 中。元素被插入到 pos 所指向的元素之前。操作后容器 other 变为空。
void splice( const_iterator pos, list& other, const_iterator it ); 从 other 转移 it 所指向的元素到 *this 。元素被插入到 pos 所指向的元素之前。
void splice( const_iterator pos, list& other, const_iterator first, const_iterator last); 从 other 转移范围 [first, last) 中的元素到 *this 。元素被插入到 pos 所指向的元素之前。
void remove( const T& value ); 移除所有满足特定标准的元素。value - 要移除的元素的值
void reverse(); 逆转容器中的元素顺序。
void unique(); 从容器移除所有相继的重复元素。只留下相等元素组中的第一个元素。
void sort(); 以升序排序元素。保持相等元素的顺序。用 operator< 比较元素
template< class Compare >
void sort( Compare comp ); 以升序排序元素。保持相等元素的顺序。用给定的比较函数 comp 。
修改器 功能
void clear(); 从容器擦除所有元素。此调用后 size() 返回零。
iterator insert( iterator pos, const T& value ); 在 pos 前插入 value 。
void insert( iterator pos, size_type count, const T& value ); 在 pos 前插入 value 的 count 个副本。
template< class InputIt >
void insert( iterator pos, InputIt first, InputIt last); 在 pos 前插入来自范围 [first, last) 的元素
iterator insert( const_iterator pos, std::initializer_list ilist ); 在 pos 前插入来自 initializer_list ilist 的元素
iterator erase( iterator pos ); 移除位于 pos 的元素。
iterator erase( iterator first, iterator last ); 移除范围 [first; last) 中的元素。
void pop_back(); 移除容器的末元素。
void push_front( const T& value ); 前附给定元素 value 到容器起始。
void push_back( const T& value ); 后附给定元素 value 到容器尾。
void pop_front(); 移除容器首元素。
void resize( size_type count ); 重设容器大小以容纳 count 个元素。
void resize( size_type count, T value = T() ); count - 容器的大小,value - 用以初始化新元素的值
void swap( list& other ); 将内容与 other 的交换。
简
assign()给list赋值
back() 返回最后一个元素
begin() 返回指向第一个元素的迭代器
clear() 删除所有元素
empty() 如果list是空的则返回true
end() 返回末尾的迭代器
erase() 删除一个元素
front() 返回第一个元素
get_allocator() 返回list的配置器
insert() 插入一个元素到list中
max_size() 返回list能容纳的最大元素数量
merge() 合并两个list
pop_back() 删除最后一个元素
pop_front() 删除第一个元素
push_back() 在list的末尾添加一个元素
push_front() 在list的头部添加一个元素
rbegin() 返回指向第一个元素的逆向迭代器
remove(a) 从list删除元素a
remove_if() 按指定条件删除元素
rend() 指向list末尾的逆向迭代器
resize() 改变list的大小
size() 返回list中的元素个数
reverse() 把list的元素倒转
sort() 给list排序
splice() 合并两个list
swap() 交换两个list
unique() 从容器移除所有相继的重复元素。只留下相等元素组中的第一个元素```
- 迭代器
```cpp
list<T>::iterator it;
it=listname.begin();
it++ //指针指向下一个元素
it-- //
*it //访问元素
==,<,>,!= //比较大小
双端队列deque
deque容器为一个给定类型的元素进行线性处理,像向量一样,它能够快速地随机访问任一个元素,并且能够高效地插入和删除容器的尾部元素。但它又与vector不同,deque支持高效插入和删除容器的头部元素,因此也叫做双端队列。
- 每个元素都可通过随机访问的迭代器访问
- 可在两端扩展
deque<T> dq;
deque<T> first(3,100);
(1) 构造函数
deque():创建一个空deque
deque(int nSize):创建一个deque,元素个数为nSize
deque(int nSize,const T& t):创建一个deque,元素个数为nSize,且值均为t
deque(const deque &):复制构造函数
(2) 增加函数
void push_front(const T& x):双端队列头部增加一个元素X
void push_back(const T& x):双端队列尾部增加一个元素x
iterator insert(iterator it,const T& x):双端队列中某一元素前增加一个元素x
void insert(iterator it,int n,const T& x):双端队列中某一元素前增加n个相同的元素x
void insert(iterator it,const_iterator first,const_iteratorlast):双端队列中某一元素前插入另一个相同类型向量的[forst,last)间的数据
(3) 删除函数
Iterator erase(iterator it):删除元素,并返回下个元素位置
Iterator erase(iterator first,iterator last):删除双端队列中[first,last)中的元素并返回下个元素位置
void pop_front():删除双端队列中最前一个元素
void pop_back():删除双端队列中最后一个元素
void clear():清空元素
(4) 遍历函数
reference at(int pos):返回pos位置元素的引用
reference front():返回首元素的引用
reference back():返回尾元素的引用
iterator begin():返回向量头指针,指向第一个元素
iterator end():返回指向向量中最后一个元素下一个元素的指针(不包含在向量中)
reverse_iterator rbegin():反向迭代器,指向最后一个元素
reverse_iterator rend():反向迭代器,指向第一个元素的前一个元素
(5) 判断函数
bool empty() const:向量是否为空,若true,则向量中无元素
(6) 大小函数
Int size() const:返回向量中元素的个数
int max_size() const:返回最大可允许的双端对了元素数量值
(7) 其他函数
void swap(deque&):交换两个同类型向量的数据
void assign(int n,const T& x):向量中第n个元素的值设置为x
关联容器
set
multiset
映射map
multimap
容器适配器
栈stack
- 是同类元素的集合list
- 插入和删除只在一端,允许插入和删除的一端称为栈顶
- 是先进后出/后进先出的一种数据结构
- push进栈(添加元素)pop出栈(删除元素)
- 实现方式1.顺序结构:vector 2.链式结构:list,deque(默认)
声明
#include<stack>

队列queue
- 队尾插入,队头删除
- 先进先出,后进后出
- 用list或deque实现

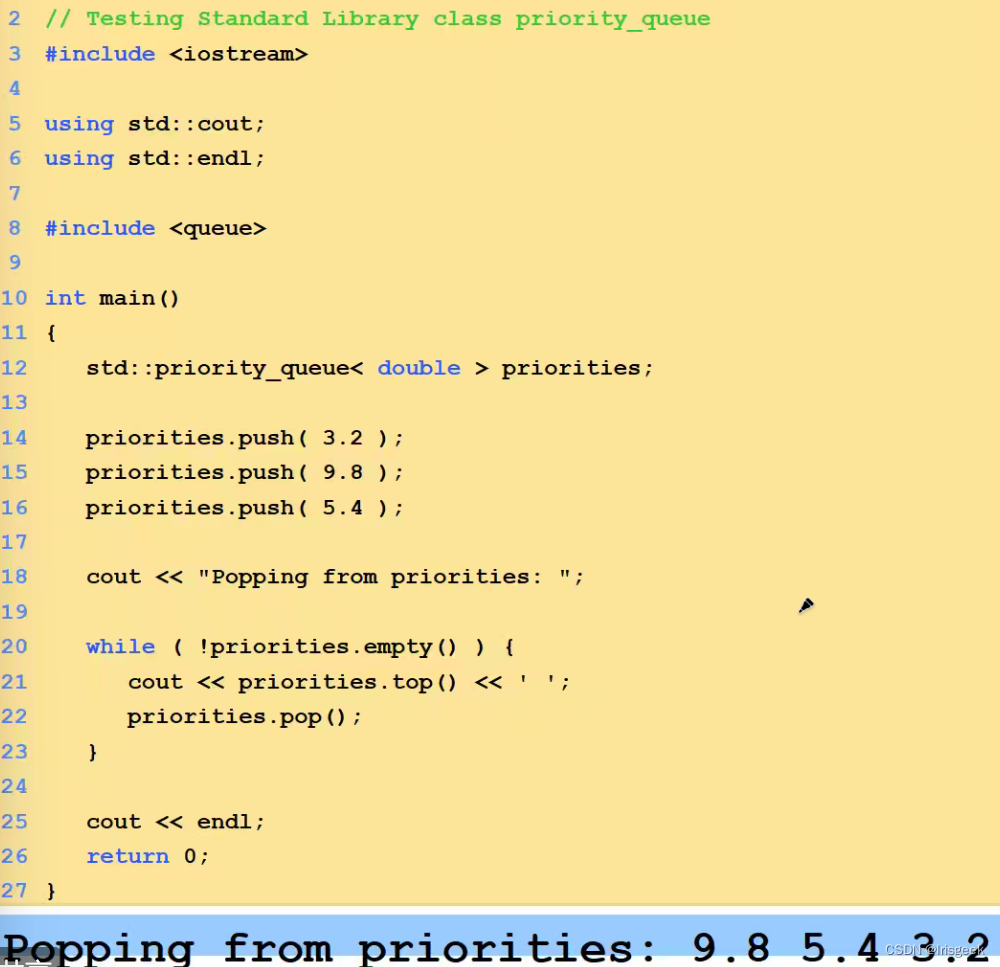
优先队列priority_queue
- 插入时有排序的序列(如升序),删除是队头(优先级最高)
- 默认降序
- 能取出最值,且可插入元素
- 只能删除最大元素,不能删除任意元素
- 若要取最小元素时,可以把元素加负号,取出队首时再加个负号变回来

- 优先队列比较除了int类型 用重载运算符

P.top();//读取队头
上面没用using namespace std;
用5,6行代替 分开说明也可
迭代器Iterators
很像指针,用于程序来操作每个元素
- 成员函数begin返回容器的第一个元素
- 成员函数end返回容器的最后一个元素后面的元素
对于反向迭代器,++ 运算将访问前一个元素,-- 运算则访问下一个元素。
int main() {
std::vector<int> vec{0,1,2,3,4,5,6,7,8,9};
vector<int>::reverse_iterator r_iter;
for (r_iter = vec.rbegin(); // 迭代器指向最后一个元素
r_iter != vec.rend(); // rend() 指向第一个元素的前一个
++r_iter) // ++操作访问前一个元素
std::cout << *r_iter << " "; // prints 9,8,7,...0
std::cout << "\n";
return 0;
}
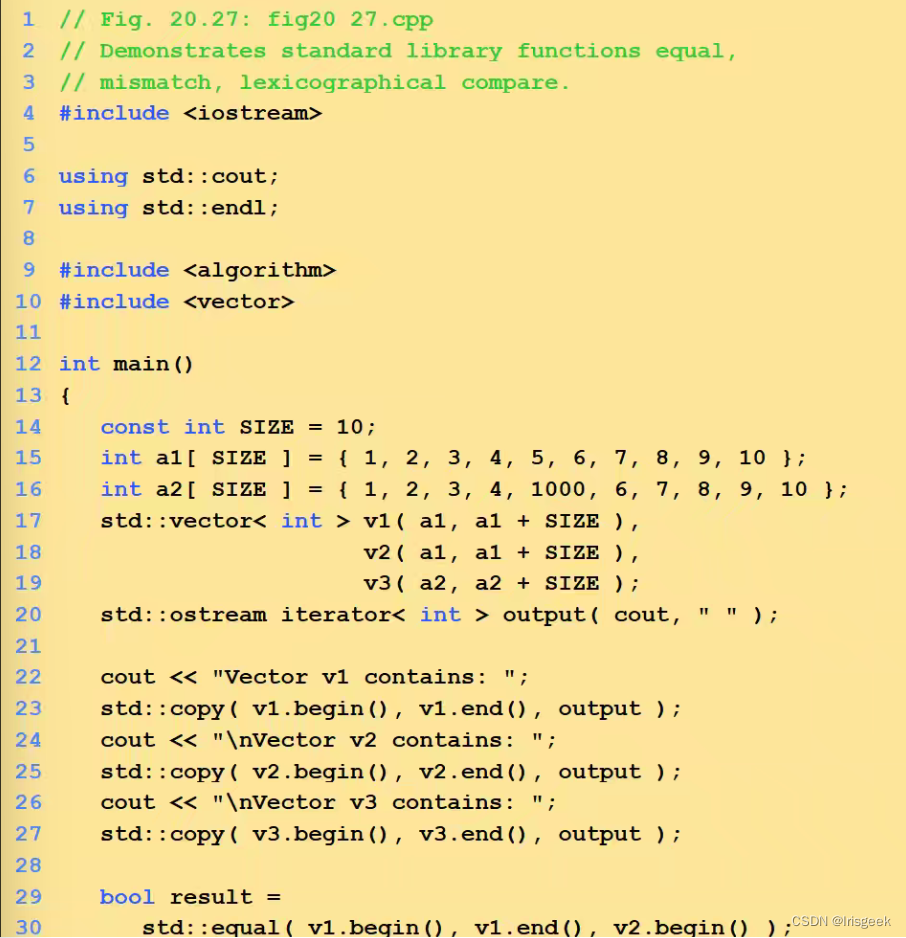
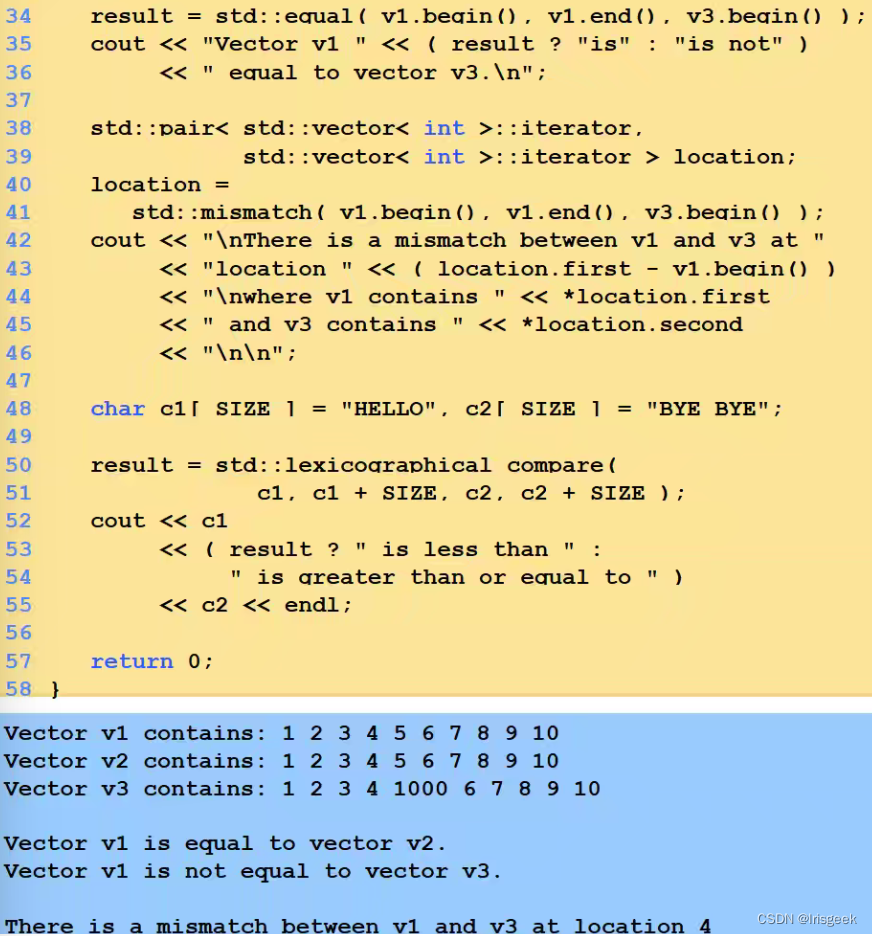
算法Algorithms
其实就是函数,用来进行通用的数据操作,如排序比较等
迭代器的类型决定可使用的算法
很多操作于顺序容器的算法会定义两个迭代器(一个在头,一个在尾)
算法结果会返回迭代器
- 常用算法
#include<algorithm>
//对a中的从a.begin()(包括它)到a.end()(不包括它)的元素进行从小到大排列
sort(a.begin(),a.end());
//对a中的从a.begin()(包括它)到a.end()(不包括它)的元素倒置,但不排列,如a中元素为1,3,2,4,倒置后为4,2,3,1
reverse(a.begin(),a.end());
//把a中的从a.begin()(包括它)到a.end()(不包括它)的元素复制到b中,从b.begin()+1的位置(包括它)开始复制,覆盖掉原有元素
copy(a.begin(),a.end(),b.begin()+1);
//在a中的从a.begin()(包括它)到a.end()(不包括它)的元素中查找10,若存在返回其在向量中的位置
find(a.begin(),a.end(),10);
修改
比较



删除

替换
查找,排序,二分查找
交换









下题答案错误(是0-90 位置4)
主要看思路方法


模板
- 模板函数
template<typename T>//<>里也可写class T
T maxValue(T a,T b){
if(a>b)
return a;
else
return b;
};
int main(){
cout<<maxValue(1,3);//3
cout<<maxValue(1.5,0.2);//1.5
cout<<maxValue('A','N');//N
cout<<maxValue(string("NBC"),string("ABC"));//NBC
template<class T1,class T2>
template<class T,int i=0>
template<class T1,typename T2>
- 类模板
要将类的定义和实现放在同一个文件里(.h),因为模板类的编译实际上没有实现
将template前缀放在每个函数头前面
template<class T>
void Swap(T&a,T&b) {
T c = a;
a = b;
b = c;
}
template<typename T>
class Stack{
public:
int aaa();
T peek() const;//const的含义是这个函数不会修改该类内的数据成员(只读状态)
int getSize() const;
void push(T value);
private:
T elements[100];
};
int Stack::aaa(){
}
template<typename T>
T Stack<T>::peek() const{
}
template<typename T>
T Stack<T>::push(T value){
//...
}
int main(){
Stack<int> s;
cout<<maxValue<int>(1,2);//2
}
IO
输入/输出转向(File Input and Output)
使用文件三步骤
1.打开
2.读写
3.关闭
#include<iostream>
- cin和cout是标准输入输出流
- fstream既可以读又可以写 故若对一个文件有读和写的需求,可用fstream,但要说明打开方式
ios::in //输入
ios::out //覆盖后重写
ios::app //追加
- stream包含字符流和字节流
Writing Data to a File
ofstream可以向文件里写数据
#include<iostream>
#include<fstream>//fstream.h
int main()
{
ofstream output;//create file若文件本来有内容,会被覆盖
output.open("scores.txt");//打开文件 之后的output都指scores.txt
output<<"John"<<" "<<"T"<<""<<"Smith"<<""<<90<<endl;//输出到文件中,屏幕上没有显示
output.close();//只要关闭就会保存
cout<<"Done"<<endl;//输出到屏幕上
return 0;
}
若scores.txt原来已经存在,程序会自动覆盖,原来的内容会消失,如不想丢失,可追加
若忘记close,则可能保存失败
1.绝对路径的文件名(c:\example\scores.txt):(依靠平台)要包含完整路径和驱动器字符c:\example是路径scores.txt是文件名但c++中\要用\\(两个)表示故 output.(c:\\example\\scores.txt)或者用左斜杠也可
2.相对路径的文件名(\windows\Debug_Build for Borland C++Builder):无驱动器字符,常在IDE(集成开发环境)中被指定
Reading Data from a File
#include<iostream>
#include<fstream>//fstream.h
int main()
{
ifstream input;
input.open("scores.txt");//open a file 将对象与文件链接
if(input.fail()){
cout<<"File does not exist"<<endl;
cout<<"Exit program"<<endl;
return 0;
}
//以下提取算子
char firstname[80];
char mi;
char lastname[80];
int score;
while(!input.eof()){//若不是最后一行则继续读入
input>>firstname>>mi>>lastname>>score;
cout<<firstname<<mi<<lastname<<score;//检验是否输入,可没有
}
input.close();
cout<<"Done"<<endl;//输出到屏幕上
return 0;
}
如文件不存在,可能生成错误的结果。故可在open函数后用fail()函数检验是否存在,若返回True,则文件不存在。
若不知道文件多少行,想把文件都读出来。可用eof()函数检测是否到文件尾(TestEndofFile)
data format(数据格式)
Formatting Output规范输出
#include<iostream>
#include<iomanip> // ****
#include<fstream>//fstream.h
int main()
{
ofstream output;//create file若文件本来有内容,会被覆盖
output.open("formattedscores.txt");
output<<setw(6)<<"John"<<setw(2)<<"T"<<setw(6)<<"Smith"<<""<<setw(4)<<90<<endl;//setweith
output.close();
cout<<"Done"<<endl;
return 0;
}
getline,get,put
空白符:空格符,制表符,换行符,及转义字符’/r’ ‘/t’ ‘/f’ ‘/n’ ‘/v’
get
输入流对象名.get()
输入流对象名.get(c)//获取一个字符并存在变量c中
输入流对象名.get(s,n,指定结束符)//最多获取n-1个字符 默认换行符也为结束符(插入到字符串尾)
getline(读入多行时使用)
不会跳过空格,tab,换行。遇到回车/n读入结束(回车不作本身字符串的内容)eg:读abc/n 实际上是abc
getline(char array[ ],int size,char delimitChar)
input.getline(city,40,'#');
//读取一行到city数组里,数组长度只有40,以#为结束提示符
读入/输出一个字符可以用get/put(原来的c语言中有专门的getchar和putchar)
循环get不会跳过空格,换行。
eg:读abc/n
getline
返回值和cin的返回值相同,是读入了数据的一个新的流。
注意如果先使用cin来读取的话,接下来如果需要使用getline读取,需要先将换行符读掉。
int a;
string line;
cin >> a;
getchar(); // 读掉换行符
getline(cin , line); // 再使用getline读取
CopyFile复制文件
int main(){
const int FileName_SIZE=40;
//Enter a source file
cout<<"Enter a source file name:";
char inputFilename[FileName_SIZE];
cin>>inputFilename;
//Enter a target file
cout<<"Enter a target file name";
char outputFilename[FileName_SIZE];
cin>>outputFilename;
ifstream input;
ofstream output;
//Open a file
input.open(inputFilename);
output.open(outputFilename);
if(input.fail()){
cout<<"File does not exist"<<endl;
cout<<"Exit program"<<endl;
return 0;
}
while(!input.eof()){//若不是最后一行则继续读入
input>>firstname>>mi>>lastname>>score;
cout<<firstname<<mi<<lastname<<score;//检验是否输入,可没有
}
input.close();
output.close();
cout<<"\nCopy Done"<<endl;
return 0;
}
AppendFile追加
stream.open("city.txt",ios::out|ios::app);//按位或(二进制)
ps:
&&,||是逻辑与,逻辑或
&,|是按位与,按位或(对于二进制)
习题课
OJ常见错误
注意/和\
/0或%0
数组访问超限
无限递归
函数没有返回值
错误50%等(改long long试试)
时间超限:递归次数过多
输出超限改进
while()
{cin>>a;}
改为
while(cin>>)
一些问题
for循环的新用法
while(cin>>a)
直到换行停止
while (cin>>m>>n)
{
waterf(m, n);
}
cin>>
该操作符是根据后面变量的类型读取数据。
输入结束条件 :遇到Enter、Space、Tab键。
对结束符的处理 :丢弃缓冲区中使得输入结束的结束符(Enter、Space、Tab)
数组初始化
int b[100]={0};//当定义的是全局变量时,数组中所有元素都初始化为0
int main()
{
int a[100]={0};//局部变量时 只有a[0]初始化成功了,其它可能为任意值
}
strlen和sizeof
sizeof()
sizeof(…)是运算符,在头文件中typedef为unsigned
int,其值在编译时即计算好了,参数可以是数组、指针、类型、对象、函数等。
它的功能是:获得保证能容纳实现所建立的最大对象的字节大小。
由于在编译时计算,因此sizeof不能用来返回动态分配的内存空间的大小。实际上,用sizeof来返回类型以及静态分配的对象、结构或数组所占的空间,返回值跟对象、结构、数组所存储的内容没有关系。
具体而言,当参数分别如下时,sizeof返回的值表示的含义如下:
数组——编译时分配的数组空间大小;
指针——存储该指针所用的空间大小(存储该指针的地址的长度,是长整型,应该为4);
类型——该类型所占的空间大小;
对象——对象的实际占用空间大小;
函数——函数的返回类型所占的空间大小。函数的返回类型不能是void。
strlen()
strlen(…)是函数,要在运行时才能计算。参数必须是字符型指针(char*)。当数组名作为参数传入时,实际上数组就退化成指针了。
它的功能是:返回字符串的长度。该字符串可能是自己定义的,也可能是内存中随机的,该函数实际完成的功能是从代表该字符串的第一个地址开始遍历,直到遇到结束符NULL。返回的长度大小不包括NULL。
char str[20]="0123456789";
int a=strlen(str);
//a=10;strlen 计算字符串的长度,以\0'为字符串结束标记。
int b=sizeof(str);
//b=20;sizeof 计算的则是分配的数组str[20] 所占的内存空间的大小,不受里面存储的内容影响
char *str1=“absde”;
char str2[]=“absde”;
char str3[8]={‘a’,};
char ss[] = “0123456789”;
输出:
sizeof(str1)=4
sizeof(str2)=6;
sizeof(str3)=8;
sizeof(ss)=11;首先说明一点,char类型占一个字节,所以sizeof(char)是1,这点要理解 str1是一个指针,只是指向了字符串"absde"而已。所以sizeof(str1)不是字符串占的空间也不是字符数组占的空间,而是一个字符型指针占的空间。所以sizeof(str1)=sizeof(char*)=4,在C/C++中一个指针占4个字节
str2是一个字符型数组。C/C++规定,对于一个数组,返回这个数组占的总空间,所以sizeof(str2)取得的是字符串"absde"占的总空间。"absde"中,共有a b s d e \0六个字符,所以str2数组的长度是6,所以sizeof(str2)=6*sizeof(char)=6
str3已经定义成了长度是8的数组,所以sizeof(str3)为8
str4和str2类似,‘0’ ‘1’ … ‘9’加上’\0’共11个字符,所以ss占的空间是11
总之,对于指针,sizeof操作符返回这个指针占的空间,一般是4个字节;
而对于一个数组,sizeof返回这个数组所有元素占的总空间。char与char[]容易混淆,一定要分清,而且char="aaa"的写法现在不被提倡,应予以避免
而strlen不区分是数组还是指针,就读到\0为止返回长度。而且strlen是不把\0计入字符串的长度的。
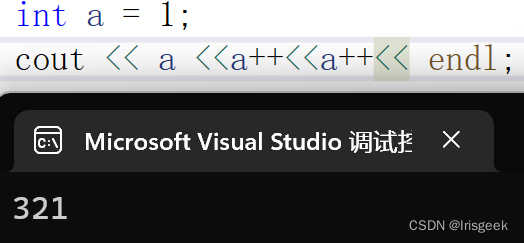
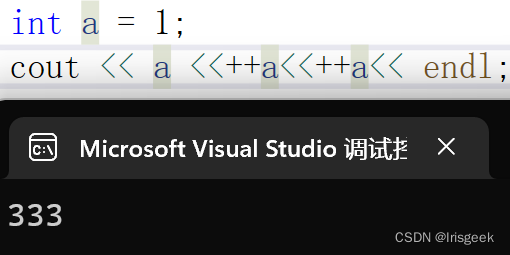
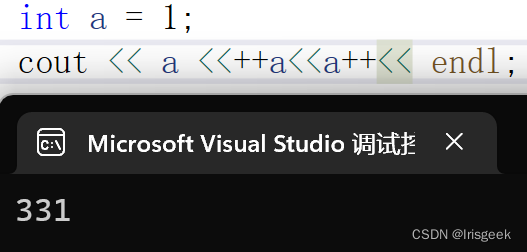
++a 和 a++
- cout时 a++返回的是操作前的值,++a是整串操作后的(见;为一个操作) a返回的也是操作后的值
- cout是从右至左入栈
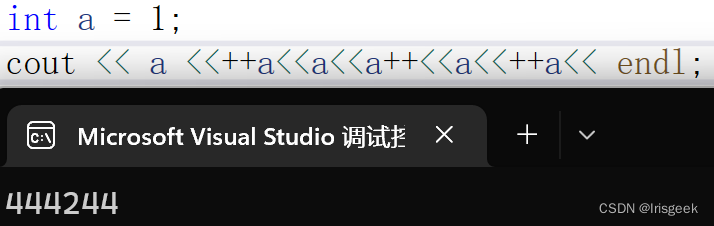
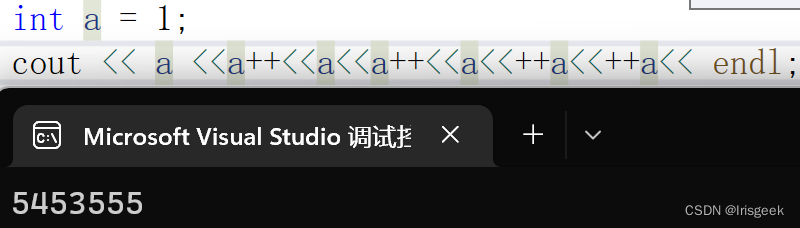
a = b >= c ? d : e;
如果 b>=c 条件成立,那么结果为a=d;
如果 b<c 条件成立,那么结果为a=e;
逗号表达式
表达式1,表达式2,表达式3,… ,表达式n
逗号表达式的要领:
(1) 逗号表达式的运算过程为:从左往右逐个计算表达式。
(2)
逗号表达式作为一个整体,它的值为最后一个表达式(也即表达式n)的值。
(3) 逗号运算符的优先级别在所有运算符中最低。
题目:以下程序的输出结果是:
main()
{
int x,y,z;
x=1;
y=1;
z=x++,y++,++y;
printf(“%d,%d,%d\n”,x,y,z);
}
[A]2,3,3 [B]2,3,2 [C]2,3,1 [D]1,1,1
解析:
x和y的值经过自增以后分别为2和3,D可以排除。剩下3个选项选择什么呢?
如果是(x++,y++,++y)实际上可以看成(1,1,3)整个逗号表达式的值应该是3,那么选A。
如果是(x++,++y,y++)实际上可以看成(1,2,2)整个逗号表达式的值应该是2,那么选B。
但这是错的,这儿还有赋值运算符。赋值运算符的优先级是14,而逗号表达式的优先级是15,也就是说上面的表达式中应该等价于这样的结合:(z=x++),y++,++y;如果这样写的话,则答案很清晰,为:2,3,1
正确答案选C。
||和&&
判断或时,前面出现1(true)就不进行后面的判断了
判断与时,出现0就不往后判断了
int a=0,b=1,c;
c=(a!=b)||(++a==b++);
//执行后a b c分别为0,1,1
十进制转二进制(除二取余法)
不断除二 取余 再倒序输出

long long int totwo(int n) //转换为二进制的函数(除二取余法)
{
long long a = n, b = 0,two=0;
for(long i=0;a>0;i++)
{
b = a % 2;
two += b*pow(10, i);
a /= 2;
}
return two;
}
判断素数的优化(利用取根号)
https://blog.csdn.net/qq_43695957/article/details/116062333
1 .判断(int)sqrt(n)之前的数有无n的约数就可了
时间复杂度:O(sqrt(n))
~
优化原理:素数是因子为1和本身, 如果num不是素数,则还有其他因子,其中的因子,假如为a,b.其中必有一个大于sqrt(num),一个小于sqrt(num)。所以必有一个小于或等于其平方根的因数,那么验证素数时就只需要验证到其平方根就可以了。即一个合数一定含有小于它平方根的质因子。
排序
详见 https://blog.csdn.net/weixin_50886514/article/details/119045154
选择排序
int main()
{
int n, m,a[101],r(0);
cin >> n >> m;
while (n != 0 || m != 0)
{
for (int i = 0;i < n;i++)
{
cin >> a[i];
}
for (int i = 0;i < n;i++)
{
if (m > a[i])
{
r = i;
}
}
for (int i = n;i >r;i--)
{
a[i] = a[i - 1];
}
a[r + 1] = m;
for (int i = 0;i < n;i++)
{
cout << a[i] << " ";
}
cout << a[n];
cin >> n >> m;
}
return 0;
}
插入排序

回文数
法1(倒序输出后比较)
bool hw(int n)//将n倒序得到x
{
int x=0,y=n;
while(y>0)
{
x=x*10+y%10;//
y=y/10;
}
return x==n;
}
法二(转为字符数组)
也可用swap函数 将a倒序变为A 若a==A则是回文数
bool hws(string str)
{
if(str.length()<2)
{
return true;
}
return str[0]==str[str.length()-1] && hws(str.substr(1,str.length()-2));
}
int main()
{
int n;
cin>>n;
if(hws(to_string(n))
{
cout<<n;
}
return 0;
}
字符串拼接
若没有7-8行的初始化 要在拼贴结束后最后加上\0
第10行 \0的ASCII码为0

字符串倒序
第16行非常重要,否则指针找不到结束点

vector
oj16
- 定义n个动态数组
int n;
cin>>n;
vector<vector<int>> vec(n);
vector<int>vec2[1000];
初始化一个二维vector
对于空的二维vector,可能是用{}初始化,也可能是用{{}}初始化,具体用哪一种,得看一下题目在返回空的二维vector时,要求返回的是啥,

如果题目在返回空的二维vector时,返回的是 [],这是我们程序中对应用{};
如果题目在返回空的二维vector时,返回的是 [[]],这是我们程序中对应用{{}};
stack
用map(映射)实现n维stack
将每个int映射成一个stack

sort函数
(二)c++标准库里的排序函数的使用方法
I)Sort函数包含在头文件为#include的c++标准库中,调用标准库里的排序方法可以不必知道其内部是如何实现的,只要出现我们想要的结果即可!
II)Sort函数有三个参数:
(1)第一个是要排序的数组的起始地址。
(2)第二个是结束的地址(最后一位要排序的地址的下一位)
(3)第三个参数是排序的方法,可以是从大到小也可是从小到大,还可以不写第三个参数,此时默认的排序方法是从小到大排序。
Sort函数的第三个参数可以用这样的语句告诉程序你所采用的排序原则
less<数据类型>()//从小到大排序
greater<数据类型>()//从大到小排序
Sort函数使用模板:
Sort(start,end+1,排序方法)
OJ19 D

#include<iostream>
#include<algorithm>
using namespace std;
class Student
{
public:
int ID;
string Name;
int ch, ma, eng,all;
void ALL() {
all = ch + ma + eng;
}
}stu[300];
bool compare(Student a, Student b) {
if (a.all > b.all) return 1;
if (a.all == b.all&&a.ch>b.ch) return 1;
if (a.all == b.all && a.ch == b.ch&&a.ma>b.ma) return 1;
if (a.all == b.all && a.ch == b.ch && a.ma==b.ma&&a.eng>b.eng) return 1;
if (a.all == b.all && a.ch == b.ch && a.ma == b.ma && a.eng== b.eng&&a.ID<b.ID) return 1;
return 0;//不能丢这句
}
int main() {
int n;
cin >> n;
for (int i = 0;i < n;i++)
{
cin >> stu[i].ID>> stu[i].Name>>stu[i].ch>> stu[i].ma>> stu[i].eng;
stu[i].ALL();
}
sort(stu,stu+n,compare);//左闭右开
for (int i = 0;i < 5;i++)
{
cout << stu[i].ID << " " << stu[i].Name << " " << stu[i].all << endl;
}
}